Parameter Isolation method
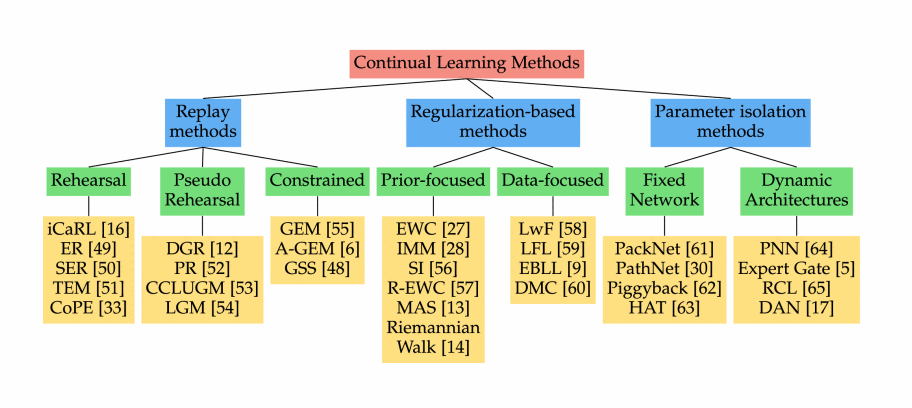
위의 그림에서 Parameter Isolation methods의 부분을 보면 Fixed Network와 Dynamic Architectures approach와 구분이 된다. Dynamic Architectures approach는 Continual Learning(1)에서 다뤘으니 참고하면 좋다.
Parameter Isolation methods는 간단하게 설명하면 모델에 새로운 task branch를 확장하는 기법이다.
Dynamic Architectures approach의 경우 catastrophic forgetting 현상을 막기 위해 각 task에 다른 model parameters를 할당한다. Model architecture의 크기에 제약이 없을 때, 이전 task의 parameter를 고정하거나 각 task에 model 사본을 할당하면서 새로운 task를 위한 새로운 branch들을 확장시킬 수 있다.
Fixed Network approach의 경우에는 고정된 부분들이 각 task에 할당되어 정적인 상태를 유지한다. Parameter level 또는 unit level에서 부과된 새로운 task를 훈련하는 동안 이전 task 부분은 마스크된다. 이 때 일반적으로 예측 중에 해당 마스크 또는 task branch를 활성화하는 작업 oracle이 필요하다. 따라서 task 간에 공유 헤드를 처리할 수 없는 다중 헤드 설정으로 제한되고, Expert Gate는 auto encoder gate 학습을 통해 이 문제를 방지한다.
* PackNet
불필요한 parameter를 제거함으로써 network의 크기와 계산 공간을 줄이는 network 압축 접근법으로부터 시작되었고, weight based pruning 기술을 사용하여 deep network의 모든 layer에 걸쳐 불필요한 parameter를 제거하여 정확도 손실을 최소화하는 접근 방식을 제안했다.
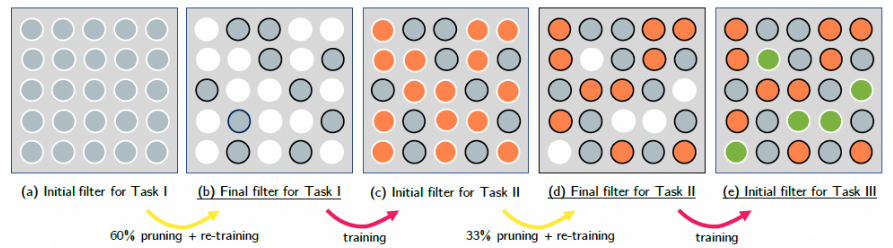
간단하게 설명하면 한 task를 훈련시키고, pruning 시킨 후에 재학습을 한 후 다음 task를 훈련시키는 network이다. 이 접근 방식의 기본 개념은 network pruning 기술을 사용하여 network 용량을 추가하지 않고 새로운 task를 수행할 수 있도록 학습하는 것이다.
PackNet은 pruning을 통해 task별로 parameter mask를 생성시킨 후 parameter subset들을 연속 task에 반복적으로 할당한다. 이를 위해 새로운 task는 2가지 학습 단계로 구분된다. 첫번째 단계로 network는 이전 task의 parameter subsets을 고정시키며 훈련되고, 그 후에는 중요하지 않은 free parameter들은 pruning 된다. 두 번째 단계로는 남은 중요한 parameter들의 나머지 subsets을 재훈련한다.
위의 진행 과정에 대해 다시 말해보면, Task1을 학습한 뒤 pruning을 하면 weight가 줄어들기 때문에 성능이 하락하는데 이를 보완하기 위해 pruning한 뒤에 남아있는 weight들만 task1으로 재학습을 한다. 그 후 새로운 task를 학습할 때 task1에서 학습된 weight들은 고정시키고, pruning된 weight들은 0으로 초기화하여 task2를 학습한다. 이후에는 이전의 방법과 동일하게 진행된다.
Pruning은 weight들을 absolute magnitude로 정렬한 후에 작은 순으로 50% 또는 75%를 제거하는 방법을 사용한다.
Pruning 마스크는 task 성능을 유지하기 위해 향후 작업에 사용할 task parameter subsets을 고정한다. PackNet은 task별로 network 용량을 명시적으로 할당할 수 있으므로 task의 총 수를 본질적으로 제한할 수 있다.
장점으로는 주어진 task에 대해 network를 소량으로 반복적으로 pruning할 수 있고, 현재 task에 대한 정확도의 손실과 이후 task에 대한 free parameter의 공급 사이에서의 trade-off를 달성할 수 있다는 점이 있다. 또한 parameter 수가 적을수록 mask storage overhead가 줄어든다는 장점이 있다.
단점으로는 filter 응답이 sparsity level에 따라 변경되므로 모든 task에 대해 동시에 inference를 수행할 수 없고, ReLU와 같은 activation function을 통과시킨 후에는 더이상 분리할 수 없다는 점이 있다.
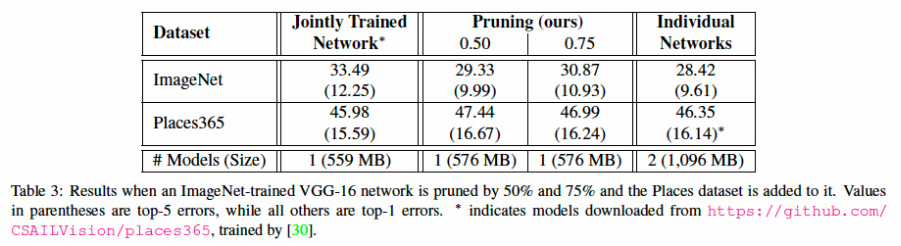
위의 Table 3을 보면 Jointly Trained Networks는 두 개를 통합한 datasets으로 하나의 netwowk를 한 번에 학습한 것을 의미하고, ours는 pruning을 한 논문에서 제시한 모델을 의미하고, Individual Networks는 각각의 task마다 새로운 network로 fine tuning한 것을 의미한다. 이 때, ImageNet dataset에서는 Jointly Trained Network보다 성능이 높은 것을 알 수 있고, Individual Networks보다 훨씬 적은 모델 size로 비슷한 성능을 내는 것을 알 수 있다.
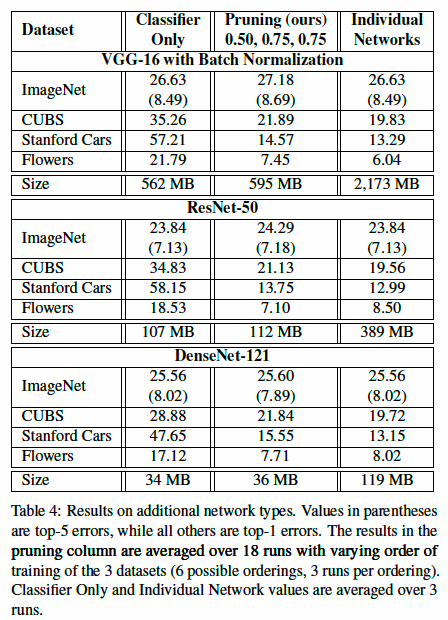
위의 Table 4는 다른 networks를 사용하여 실험해본 결과이다. Classifier Only는 feature extractor는 pretrained 상태로 fix한 뒤 classifier만 해당 task로 학습한 것을 의미한다. Table 4를 보면 더 깊은 모델인 ResNet-50이나 DenseNet-121을 사용하면 pruning에 더 robust 해진다고 한다. 또한 Flowers dataset에 대한 classification의 경우 Individual Networks보다 성능이 우수하다는 것을 알 수 있는데 이는 전체 network를 학습하면 Floser dataset에 overfitting이 되기 때문일 수 있고, pruning 후 사용할 수 있는 parameter 수를 줄임으로써 이 문제를 해결할 수 있다고 한다.
Reference
[1] jihyeonryu.github.io
[2] ImagineOnTheGiants
Google AI Blog
Survey
Online Continual Learning in Image Classificaiton: An Empirical Survey
이 survey는 좀 더 현실적이고 도전적인 문제인 online continual learning에 대해 다루고자 한다.
* Task Incremental, Class Incremental, Domain Incremental

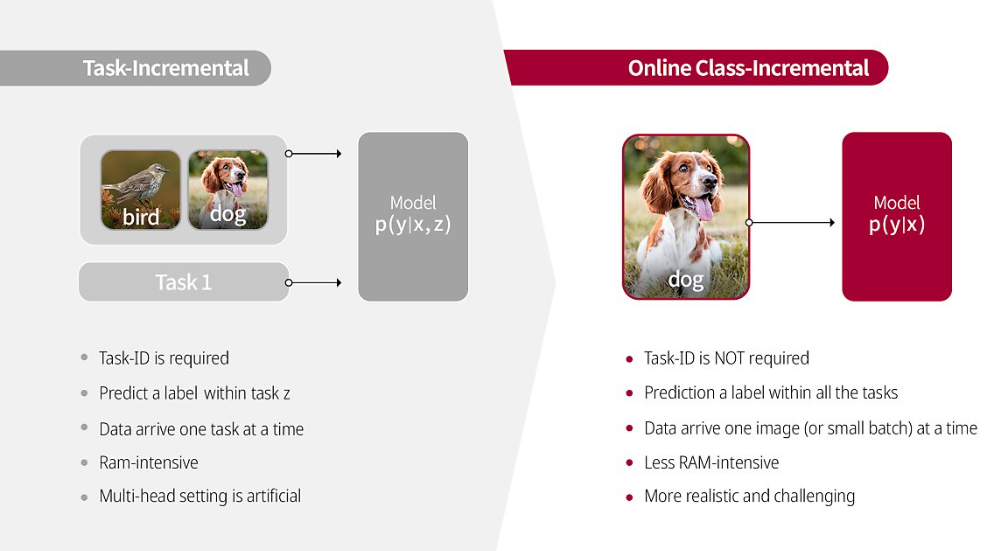
* Task Incremental과 Online Class Incremental의 차이
* Test 결과
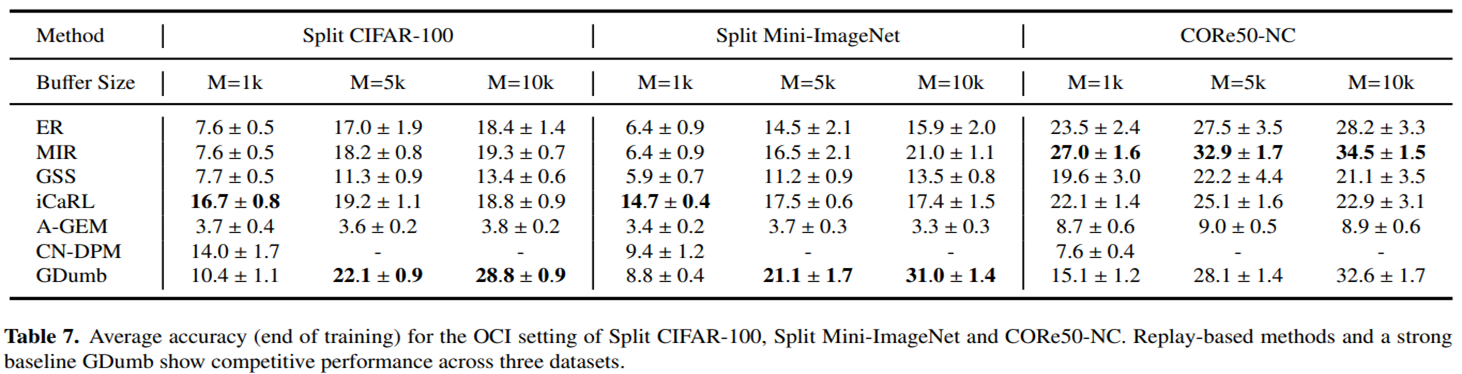
위는 OCI(Online Class Incremental) setting에서 Replay-based methods를 각각 3가지의 buffer size에 따라 3가지 종류의 datasets으로 학습을 시켰을 때의 average accuracy를 나타낸 표이다.
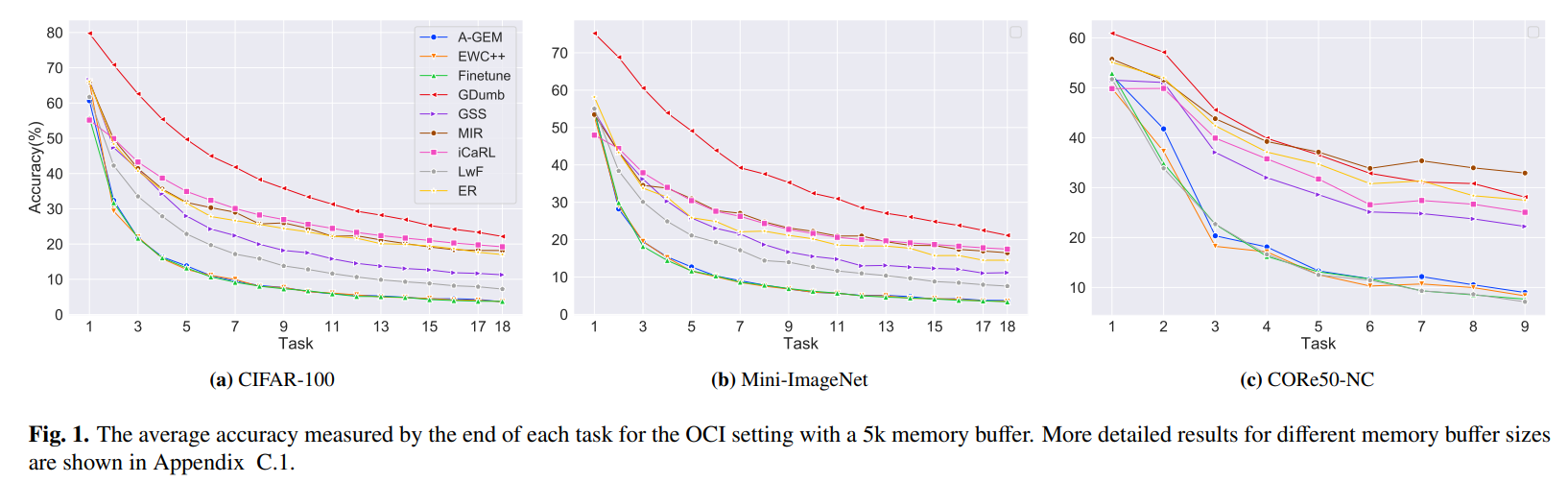
위의 그래프는 OCI(Online Class Incremental) setting에서 Replay-based methods를 각각 3가지 종류의 datasets로 학습시켰을 때 각 task 마다의 average accuracy를 측정한 것이다.
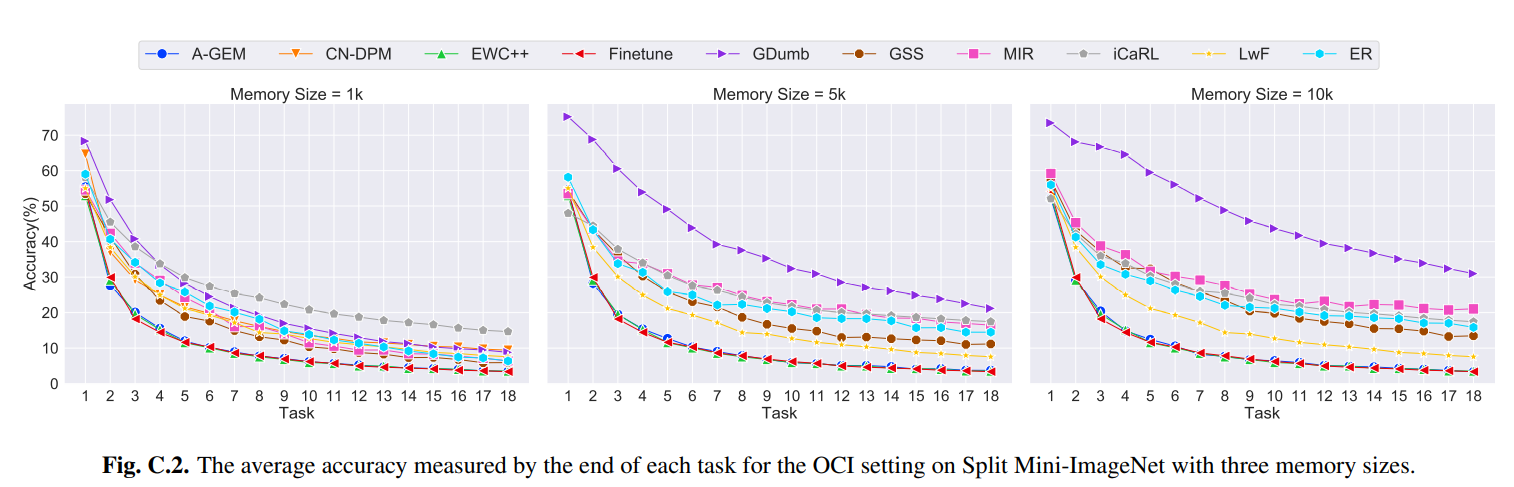
위의 그래프는 OCI(Online Class Incremental) setting에서 3가지 memory buffer size에 따라 Split Mini-ImageNet으로 학습시켰을 때 각 task별로 average accuracy의 변화를 나타낸 것이다.
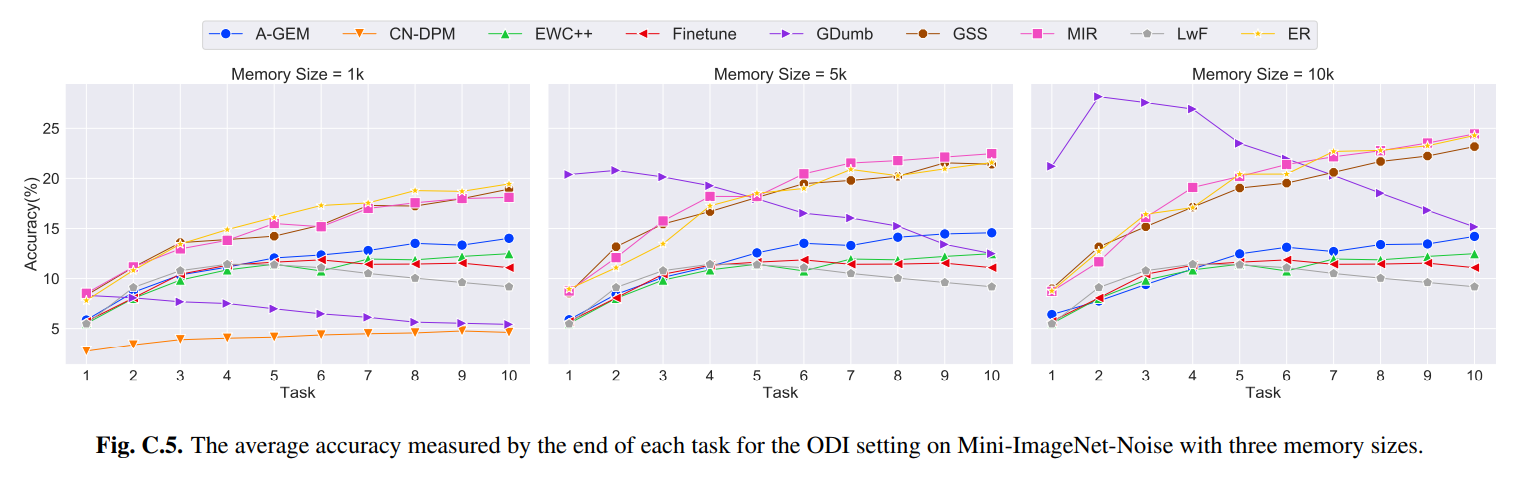
위의 그래프는 ODI(Online Domain Incremental) setting에서 3가지 memory buffer size에 따라 Mini-ImageNet-Noise dataset으로 학습시켰을 때 각 task별로 average accuracy의 변화를 나타낸 것이다.
Survey 내의 성능 정보에 대한 내용을 종합해보았을 때 다음과 같은 결론을 내릴 수 있다.
-
OCI(Online Class Incremental) setting에서는 Larger memory buffer를 가진 경우에 GDumb method가 CIFAL100과 Mini-ImageNet을 학습시킬 때 아주 긴 training time이 요구되지만, 가장 높은 성능을 보이는 것을 알 수 있다. 하지만 ODI(Online Domain Incremental) setting에서는 memory update strategy 때문에 성능이 현저하게 저하되는 것을 확인할 수 있다.
-
OCI(Online Class Incremental) setting에서는 small memory buffer를 가진 경우에 iCaRL이 CIFAR100과 Mini-ImageNet을 학습시켰을 때 가장 높은 성능을 보이는 것을 알 수 있다.
-
OCI(Online Class Incremental) setting에서 더 크고 현실적인 dataset인 CORe50-NC dataset으로 모든 memory buffer size에서 각각 MIR을 학습시켰을 때 일관적으로 성능이 높게 나오는 것을 확인할 수 있다. ODI(Online Domain Incremental) setting에서도 마찬가지로 memory buffer size가 중간 이상일 경우 task가 증가할수록 가장 높은 성능을 보이는 것을 확인할 수 있고, memory buffer size가 작은 경우에도 다른 methods와 비교했을 때 높은 성능을 보이는 것을 확인할 수 있다.
-> MIR method가 다양한 CL setting 상황에서 buffer size와 dataset의 규모에 크게 의존하지 않고 일반적으로 높은 성능을 보이기 때문에 robust하고, 다양한 CL setting 상황에 적용할 수 있는 일반화된 method라는 결론을 내릴 수 있다.
Reference
[Papers With Code] Online Continual Learning in Image Classification: An Empirical Survey
Maximally Interfered Retrieval(MIR, NeurIPS 2019)
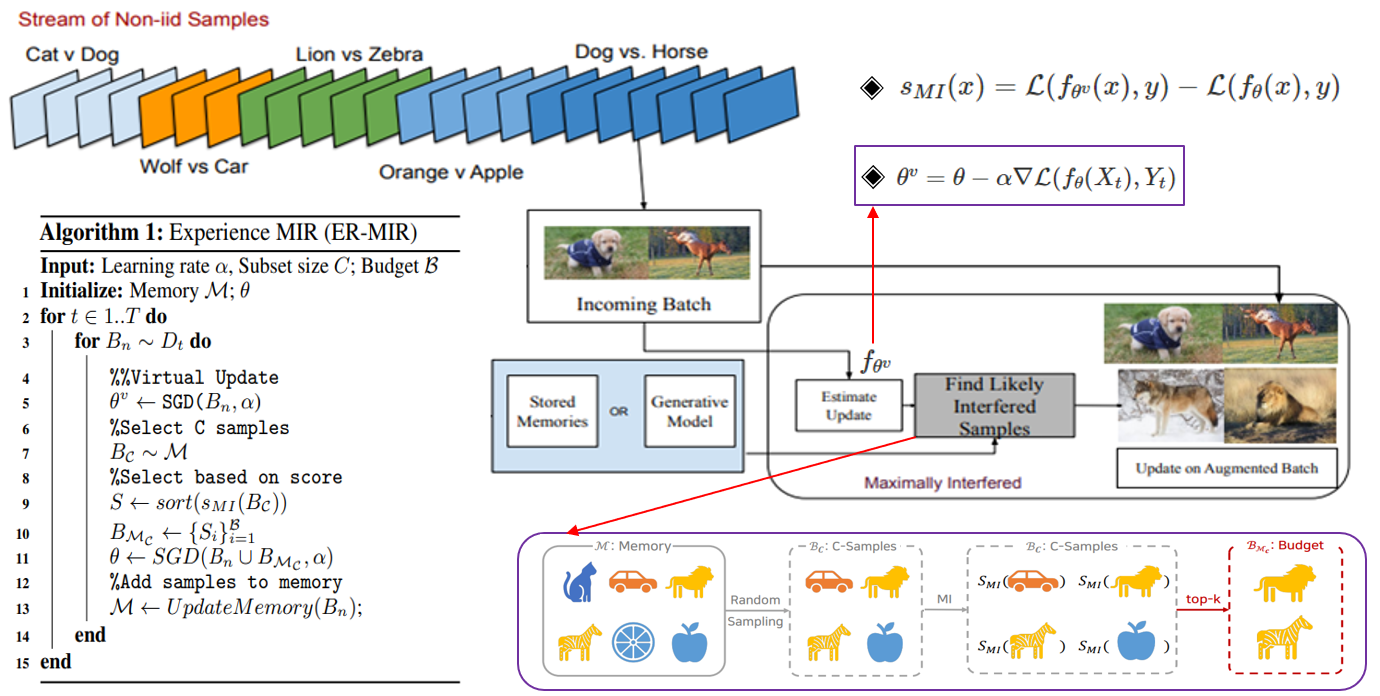
Non-iid(Non independent identically distribution)란 각 데이터가 독립 + 동일한 확률분포를 가지고 있지 않다는 의미를 지니고 있다.
MIR 업데이트는 random replay와 같지만 data 회수는 현재 새로운 데이터와 가장 간섭(interference)이 큰 date를 sampling하여 사용한다. 즉, random sampling을 사용하면 현재의 incoming batch와 유사성이 없는 sample을 뽑게되면 학습을 방해할 수 있으므로 해당 task와 최대한 관련있는 유의미한 sample을 뽑는다.
위의 그림을 자세하게 살펴보자.
Dog vs. Horse를 분류하는 task를 학습시킬 때 dog와 horse에 대한 data가 incoming batch로 들어온다. 이 때 를 계산하기 위해 가 필요하므로 incoming batch로 현재 모델을 stochastic gradient descent를 하여 가상으로 update한다. Incoming batch에 좀 더 specific한 model로 update하고, 가상의 update를 하기 전의 model의 loss 값의 차를 구하기 위함이다.
Find Likely Interfered Samples 부분을 세분화하여 살펴보면 가장 먼저 Memory M에서 C개의 samples를 random sampling으로 뽑는다. 이는 computational cost를 줄이기 위함이다. 그 다음 random sampling한 C개의 samples를 각각 L()와 L()에 대입하여 이 두 값의 차를 구한다. 여기서 는 현재 model을 incoming batch로 가상으로 SGD를 이용하여 update한 model이고, 는 incoming batch로 학습하기 전 model이다. L()와 L()의 의미는 해당 model이 incoming batch에 대해 학습을 한 후에 각각의 C개의 samples에 대해서 예측하지 못하는 정도 또는 해당 samples에 대해 잃은 정보의 정도를 나타내는 지표이다. 즉, 현재 incoming batch에 대해 가상으로 학습하여 현재의 task에 더 specific하게 된 model이 이전 task의 정보인 C개의 samples에 대해 잃은 정보의 정도를 계산하는 단계이다. 그 후 top-k개를 추출하여 Budget에 저장한다.
위의 방법대로 MIR sampling을 한 후에는 현재 task의 incoming batch와 MIR sampling을 통해 추출한 sample들을 모두 이용하여 현재 task를 학습하게 된다. 중요한 점은 현재 task의 incoming batch로 model을 가상으로 update 했을 때 update 전후로 loss 값이 크게 증가하는 sample들 위주로 MIR sampling하여 incoming batch와 sampling한 sample들을 합하여 model을 학습한다. 이로 인해 이전 task에 대한 정보를 잃는 chatastrophic forgetting 현상을 완화할 수 있다.
Reference
[Paper] Online Continual Learning with Maximal Interfered Retrieval
[Naver Post] 최우수 AI학회 AAAI-21에서 인정받은 LG의 연속학습
DSBA LAB Seminar
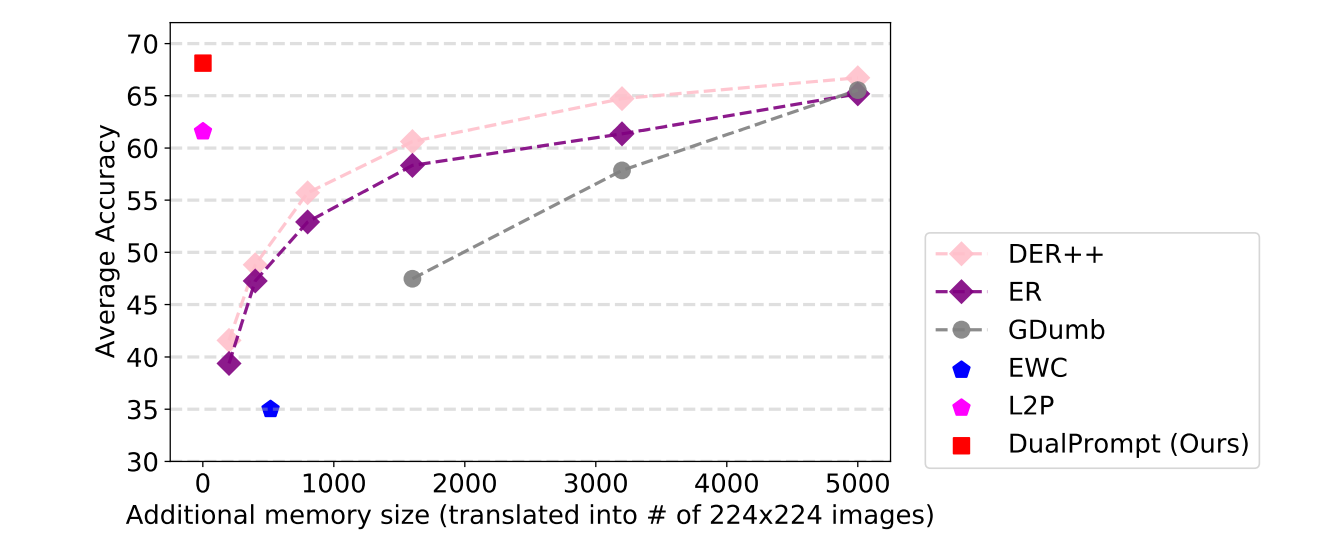
DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning
Continual learning은 단일 모델로 catastrophic forgetting 현상 없이 여러 task들을 순차적으로 학습할 수 있도록 하는 것에 목표를 두고 있다. 현재 높은 성능을 내고 있는 CL 모델들은 일반적으로 이전 task들의 data를 저장하는 Rehearsal Buffer가 요구된다. 하지만 Rehearsal Buffer는 data의 privacy와 memory 문제로 제약이 많다. 그래서 이 논문에서는 Rehearsal Buffer를 사용하지 않고, CL 문제를 푸는 방법으로 DualPrompt를 제안한다. DualPrompt는 prompts라는 작은 parameter set을 학습해서 pretrained 모델이 replay buffer를 사용하지 않고, 순차적인 tasks를 학습하도록 적절하게 지시한다. 이는 pretrained backbone에 상호보완적인 prompts를 붙이고, task-invariant와 task-specific에 대한 지시사항을 학습함으로써 목적을 공식화한다. DualPrompt는 여러 실험을 통해 어려운 class-incremental 상황에서 최고의 성능을 보인다는 것을 검증했다.