Machine Learning을 여러 다른 Domain에 적용하는 사례가 늘어나고 있지만 실환경에 적용하기 위해서는 빠르게 변하는 환경에 잘 적응을 해야된다. 변화된 환경에 빠르게 적응하지 못하는 AI는 실환경에 적용할 수 없을 것이다.

위의 2017년과 2019년 그림들을 보면 연구의 방향이나 시장의 수요에 따라 data/class가 세분화될 수 있으며, 증감된 data/class에 따라 새로운 task를 부여해야한다는 것을 알 수 있다. 즉, data는 시간의 흐름에 따라 끊임없이 성장한다는 것을 의미한다. 시간의 흐름에 따라 끊임없이 변하는 환경에 빠르게 적응하기 위해 continual learning이라는 기법이 등장했다.
Continual Learning은 이전 task에서 얻은 지식을 잊지 않고 multi task에 대한 model을 sequential하게 학습하는 개념이다. Catastrophic Forgetting 문제를 해결하기 위한 model으로 여러 task를 하나의 model에 sequential하게 학습하여 최종적으로 모든 task에 대한 수행이 가능한 model을 학습시킨다.
(이전 task의 data는 새로운 task를 훈련하는 동안 더 이상 사용할 수 없다.)
- Catastrophic Forgetting(= Semantic Draft)
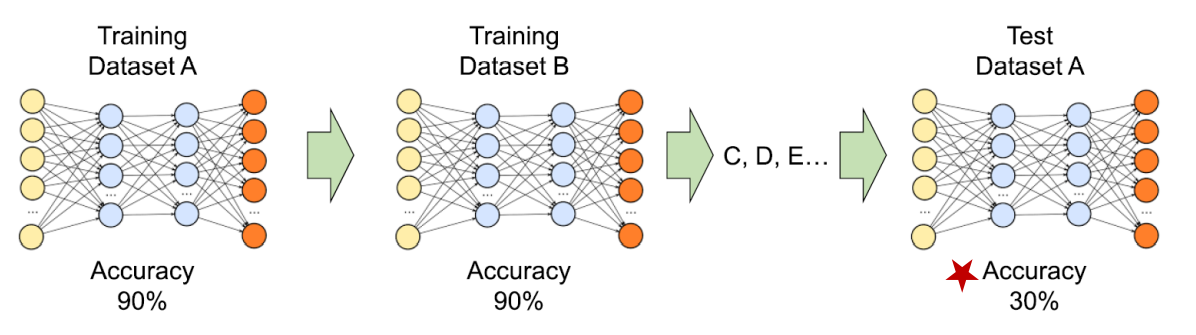
새로운 task에 대해 학습하게 되면 신경망 model이 이전에 배운 task에 대해서 까먹는 현상으로 이전 dataset으로 학습한 model에 새로운 dataset을 학습하면 두 dataset간에 관련이 있더라도 이전 dataset에 대한 정보를 대량으로 손실하게되는 것을 의미한다.
Approach(대표적인 4가지)
- Memory Replay
- Regularization approach
- Dynamic Architecture
- Mixture approach
1. Memory Replay
Regularization approach와 Structure approach는 Neural Network modeling 관점에서 바라보는 반면 Memory approach는 생물학적인 기억 메커니즘을 모방하자는 아이디어에서 출발했다. Memory Replay approach의 대표적인 algorithm은 SK T-brain이 발표한 Deep Generative Replay이다.
- DGR(Deep Generative Replay)
Continual Learning은 catastrophic forgetting 현상을 해결하는 것에 어려움이 있는데 단순하게 이전 data를 replay를 통해 어느 정도 해결할 수는 있지만 과도한 memory가 요구되고, 실환경에서 사용하기엔 과거 data에 접근하는 것이 어려울 수 있으므로 불가능에 가까웠다. DGR paper에서는 이를 해결하기 위해 생성하는 특성을 가진 해마(hippocampus)를 단기 기억 시스템으로 사용하는 인간의 뇌에서 영감을 받아 generator라는 generative model과 solver라는 task를 해결하는 model이 상호간에 협력하는 구조를 가진 Deep Generative Replay를 제안했다. Generator와 solver 구조로 이전 task의 training data를 쉽게 만들 수 있고, 새로운 task의 data와 함께 학습될 수 있게 되었다. 간단하게 Generative adversarial network(GAN)을 적용하여 이전 data로학습하여 다음 task에서 재현(replay)하는 방법을 통해 catastrophic forgetting 현상을 최소화하여 이전 task와 현재 task 모두 수행할 수 있도록하는 continual learning method이다. Generator는 GAN model 중 어떤 것을 사용해도 무방하다.
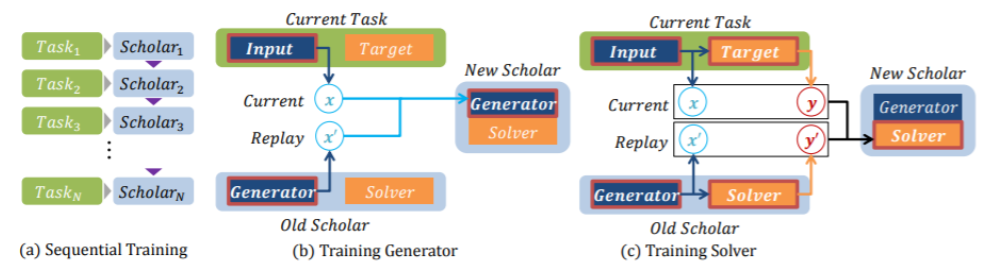
위의 그림에서 각 scholar는 generator와 solver로 구성되어있고, (a) Sequential Training은 Task에 대해 학습할 때 generator는 학습했던 이전 data를 재현(replay)하는 방향으로 학습되고, solver는 generator로부터 재현(replay)된 data와 현재의 진짜 data를 이용해서 정확히 분류하는 방향으로 학습된다. 이는 GAN의 generator와 discriminator와 유사하다. 이러한 scholar 구조를 sequential하게 학습한다.
- (b) Training Generator는 현재 task의 실제 data x와 generator로부터 이전 task에 대한 data를 재현(replay)한 x'를 가중치에 따라 섞은 data의 분포를 정확하게 재현(replay)하도록 현재 generator를 학습한다.
- (c) Training Solver는 현재 task의 실제 data x, 실제 data x의 label을 y, generator로부터 이전 data를 재현(replay)한 data를 x', x'을 이전 solver에 넣었을 때 나오는 prediction y'를 의미한다. 그리고 실제 (x, y)와 재현(replay)된 (x', y')를 이용하여 이전 task와 현재 task를 모두 수행하도록 현재 solver를 학습한다.
Generator model을 이용해서 이전 task들에 대해 학습된 data를 저장하며 학습하므로 방대한 모든 data를 한번에 저장해두지 않아도 되기 때문에 과도한 memory 사용 문제를 해결할 수 있게 되었다.
- Train loss function과 와 Test loss function

[reference]
https://realblack0.github.io/2020/03/22/lifelong-learning.html
https://noteforstudy.tistory.com/entry/Continual-Learning-2-Deep-Generative-Replay-%EB%85%BC%EB%AC%B8-%EB%B2%88%EC%97%AD
2. Regularization Approach
이전 task의 성능에 영향을 크게 미친 neural network의 weight는 중요도를 높게하고, 영향을 적게 미친 weight에 대해서는 중요도를 낮게한다. 즉, 중요도가 높을수록 성능에 크게 영향을 미친 weight라고 판단하여 weight들이 많이 변경되지 않도록 규제를 해주고, 중요도가 낮은 weight에 대해서는 많이 변경될 수 있도록 하여 catastrophic forgetting 현상이 발생하지 않도록 해서 continual learning이 가능하게 한 approach이다. 대표적인 기법으로는 Google Deepmind의 Elastic Weight Consolidation(EWC)가 있다.
- EWC(Elastic Weight Consolidation)

EWC(Elastic Weight Consolidation)은 Fisher information matrix를 이용하여 이전 stage에서 학습된 model의 weights를 성능에 영향을 미치는 정도에 따라 중요도를 정의하여 이전 task를 학습한 model의 weights를 중요도가 클수록 다음 task를 학습할 때 weights가 많이 변하지 못하도록 regularization하는 기법이다.
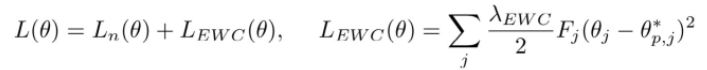
위의 식은 EWC(Elastic Weight Consolidation)에서 사용하는 loss function이고, 와 의 합으로 구성되어 있다. 에서 를 크게 할수록 weights의 변화를 줄이는 방향으로 학습하게 되고, 는 fisher information matrix로 이전 task에 대해 학습한 weights의 중요도 정보를 나타내는 matrix이고, 는 현재 weight, 는 이전 data를 학습한 후의 weight를 의미한다.
즉, 중요한 weights의 와 의 차가 커질수록 loss 값이 커지도록 설계되어 fisher information matrix로부터 weights의 중요도가 클수록 변화를 억제하여 loss가 작아지는 방향으로 학습한다.
※ Fisher Information Matrix
Detail
- LwF(Learning without Forgetting)
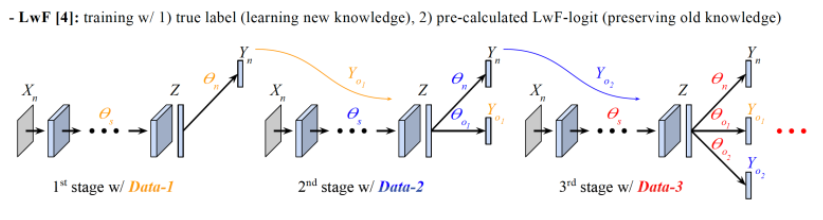
각 stage의 학습을 시작하기 전에 현재 stage의 모든 training examples에 대해 이전 stage에서 학습이 완료된 model의 feed-forward logit(LwF-logit)을 미리 계산하고, 각 example의 label과 LwF-logit을 모두 이번 stage 학습에 활용한다. 이때, label은 새로운 knowledge를 학습하는 목적으로 사용하고, LwF-logit은 과거의 knowledge를 보존하는데 사용한다.
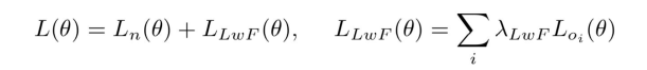
위의 식은 LwF(Learning without Forgetting)의 loss funtion이고, 와 의 합으로 구성되어 있다. 는 old branches 에 대한 LwF-logit을 label로 하는 loss이다.
이외에도 이를 보완한 LwF+, EWCLwF, EWCLwF+ 등의 기법들이 제안되었다.
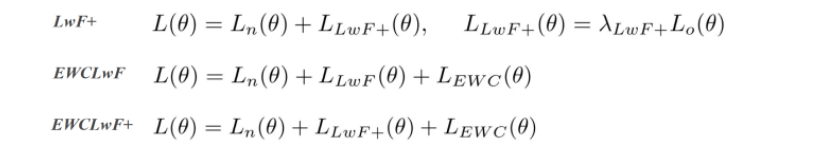
[reference]
https://blog.lunit.io/2018/08/31/keep-and-learn-continual-learning-by-constraining-the-latent-space-for-knowledge-preservation-in-neural-networks/
https://realblack0.github.io/2020/03/22/lifelong-learning.html
3. Dynamic Architecture
새로운 task를 학습하기 위해 network를 dynamic하게 변경함으로써 node or layer의 개수를 변경하여 parameter를 확보한다. Dynamic architecture approach의 대표적인 algorighm으로는 Google Deepmind의 Progressive Networks가 있다.
- Progressive Networks
-
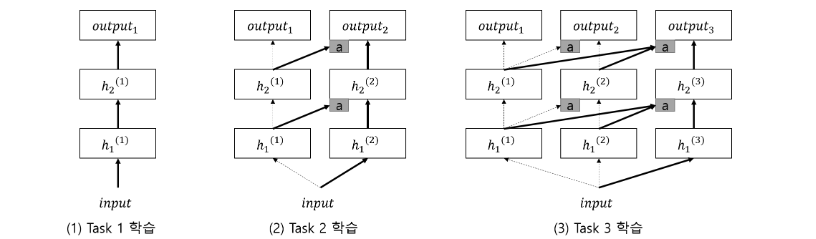
Task 1 학습은 일반적인 deep neural network 구조와 동일하게 학습된다.
-
Task 2 학습은 기존 deep neural network 구조와 다르게 2번째 column을 추가하여 sub network를 만든다. 이때, 1번째 column network의 weight를 고정함으로써 catastrophic forgetting 현상을 방지한다. 또한 lateral connection(측면 연결)이라는 기법이 적용되는데 이는 1번째 column network의 i번째 layer 의 output을 2번째 column의 sub network의 i + 1번째 layer인 에 input으로 추가적으로 넣는다.
-
Task 3 학습은 Task 2와 동일한 방법으로 3번째 column에 sub network를 하나 더 추가하고, 1 ~ 2번째 column network의 weight는 고정한다. 그리고 1번째 column network의 i번째 layer 의 output과 2번째 column network의 i번째 layer 의 output을 3번째 column의 sub network의 i + 1번째 layer인 에 input으로 추가적으로 넣는 lateral connection(측면 연결)을 적용한다.
※ 한계점 : catastrophic forgtetting 현상은 완화되지만 task가 증가할수록 network의 복잡도가 증가한다.
[reference]
https://realblack0.github.io/2020/03/22/lifelong-learning.html
4. Mixture Approach
DEN_Github
읽어보기
A Continual Learning Survey: Defying Forgetting in Classification Tasks

https://ieeexplore.ieee.org/abstract/document/9349197?ref=https:%2F%2Fgithubhelp.com&casa_token=sqqlAwZqIW8AAAAA:cL-KoJPEG2WiGiQutp3iD4DttRroFeLmixOOSMAb3UlO50ojRmQ7R40so-YMqTj4yj289raHGtQ