A cross-dataset deep learning-based classifier for people fall detection and identification

학부연구생으로 소속된 연구실에서 진행중인 Fall Detection을 위한 모델을 구현하기 위해 관련 논문을 읽고 이해한 부분에 대해 간단하게 정리하였다.
<논문 정보>
제목: A cross-dataset deep learning-based classifier for people fall detection and identification
게재일자: 2020
발행기관: Computer Methods and Programs in Biomedicine
위 논문에서는 딥러닝 아키텍처를 기존의 머신 러닝 분류기와 결합하는 것을 제안하였다. CNN과 LSTM을 사용하여 분류기가 Fall/Non Fall에 대한 결정을 출력하기 위해 사용할 일련의 특징들을 생성해낸다.
Introduction
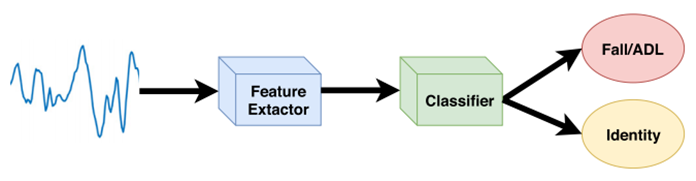
Fall Down을 감지하기 위해 구현하는 모델은 활동 인식 시스템(activity recognition systems)의 범주에 속한다. 이 시스템에서 일반적으로 고려되는 기법 두 가지는 임계값과 머신 러닝이다. 임계값 기반 기법의 경우 가속의 크기가 임계치를 초과할 경우 Fall Down을 의심하는데, 이는 성능이 그다지 좋지 않다. 따라서 본 논문에서는 머신 러닝 기법을 사용해 모델을 구현하였다. 지금까지 읽은 논문들과 다르게 입력값으로 비디오가 아닌 센서 값을 사용한다. 샘플링 속도, 센서 범위, 이동 유형 등 서로 다른 특성을 가진 네 개의 데이터셋을 사용해 모델의 일반성을 확보하고자 하였다. 사용한 데이터셋은 DFNAPAS, SisFall, UniMiB-ShAR, ASLH 데이터셋이다.
Methods
Problem definition
여러 다양한 조건들에 관계 없이 Fall Detection을 실행하기 위해 본 논문에서는 cross-dataset 분류기를 제안하였다. 이 분류기는 CNN과 LSTM의 조합으로 구축된 특징 추출기를 기반으로 한다. 설명을 덧붙이자면, 구별되는 특징을 추출하는 컨볼루션과 연속적인 subsequence들의 시간적 상관 관계를 보여주는 LSTM 레이어를 결합했다. 그리고 전처리 단계 없이 가속도계 센서에서 획득한 원시 데이터를 직접 사용하였다.
컨볼루션 레이어는 센서의 위치 혹은 범위에 관계 없이 짧은 signal windows에서 특징을 추출해내고, LSTM은 전체 신호의 특징을 클러스터링 한다. 부가적으로, 모든 데이터셋에는 피사체의 ID에 대한 정보가 포함되어 있어서 이에 대한 멀티태스크 접근 방식을 구축해 주체 ID를 분류함과 동시에 Fall Down도 감지하는 멀티태스크 모델을 구현하였다. 이때 분류 프로세스에는 k-NN 분류기를 사용하였고, 특징 추출에 있어서는 SVM, RandomForest 같은 기존 분류기를 사용하였다.
Neural network architecture
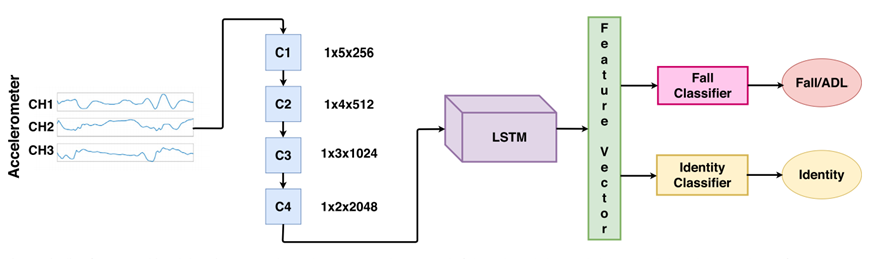
3개의 채널로 구성된 가속도계 신호는 4개의 컨볼루션 레이어로 구성된 cross-dataset 특징 추출기와 LSTM 레이어로 전달된다. 출력에는 ID와 Fall 발생 가능성에 대한 정보가 포함된다. 데이터 시퀀스는 NN에 하나씩 공급되는 50개 샘플의 subsequence로 분할된다. 모든 subsequence가 처리되면 모델은 시퀀스 수준에서 출력을 생성해낸다. 이러한 방식으로 길이가 다른 시퀀스를 사용할 수 있게 된다.
CNN의 컨볼루션 레이어는 4개로 구성되어 있는데, 단차원 신호를 다루기 때문에 첫 번째 항은 모두 1로 동일하다. 두 번째 항은 신호에서 가져온 하위 시퀀스 수를, 마지막 항은 레이어의 필터(커널) 수를 의미한다. 각 컨볼루션 작업 후에 ReLU, Batch Normalization, Max Pooling 레이어를 추가하고 마지막 컨볼루션 레이어 후에는 Max Pooling 대신 Average Pooling 레이어를 추가한다. 이후 시간 정보를 저장하기 위해 LSTM과 Dropout 레이어를 추가하고 loss function, Fully-Connected 레이어, Softmax 레이어를 추가해 최종적으로 모델을 훈련한다.
Multi-task approach
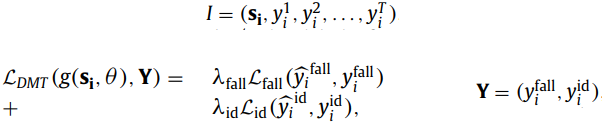
본 논문에서 사용한 데이터셋은 Fall 감지와 피실험자 ID를 모두 제공하기 때문에 Deep Multi-Task(DMT) 모델을 문제에 적용할 수 있는 방법이 필요하다. DMT 모델을 학습시키려면 첫 번째 식 I와 같은 튜플 셋을 사용해야 한다. 이때 s는 입력 시퀀스를, y는 각 작업의 라벨을 나타낸다. 두 번째 식은 DMT에 대한 로스 함수를 의미한다. Y와 g는 s에 대한 네트워크 출력을 의미한다. 손실함수로는 교차 엔트로피 loss 함수를 사용하였다.
k-Nearest neighbors classifier
k-NN 분류기에서 시퀀스는 인접 항목의 과반수 투표 전략에 따라 분류된다. 새 시퀀스의 근접한 이웃을 찾기 위해, 새 시퀀스와 이전에 라벨이 지정된 모든 시퀀스 간 유사성이나 거리 메트릭을 계산한 다음 가장 인접한 이웃을 선택한다. 학습할 매개 변수가 없기 때문에 이 분류기는 훈련 절차가 필요하지 않다. k값과 라벨이 지정된 시퀀스의 train set을 미리 선택하기만 하면 된다.
Experiments and results
Input data
먼저, 4개의 데이터셋의 밸런스를 맞춰줌으로 인해 Fall class에서 훈련에 사용할 수 있는 데이터 양이 줄어들기 때문에 Data augmentation 프로세스를 수행한다. 이렇게 하면 모든 원본 시퀀스에서 세 가지 새로운 시퀀스를 얻을 수 있다고 한다. 이후 표준 편차 0.01인 Gaussian noise를 입력 스퀀스에 추가한 후, 0.7~1.1 범위에서 임의의 값으로 시퀀스 크기를 조정한다. 각각의 기존 값 쌍 사이에 10개의 새로운 값을 삽입하여 보간을 수행한 다음, 새 시퀀스를 랜덤하게 샘플링한다. 마지막으로, N-fold cross validation을 수행하기 위해 각 데이터셋을 N개로 나눈다.
Implementation details
Fall에 해당하는 시퀀스 부족으로 인한 불균형 train set의 영향을 줄이기 위해 train set을 클래스 당 동일한 수의 시퀀스를 포함하는 서브셋으로 나누는 curriculum learning strategy를 도입했다. 또한 시퀀스를 클래스 구성원에 따라 다른 가중치를 부여하여 불균형 문제를 대처하였다. 이 외에도 과적합을 최소화하기 위해 그라디언트에 랜덤 노이즈를 추가하고, L2 정규화를 컨볼루션 레이어에 적용하였다.
Experimental results
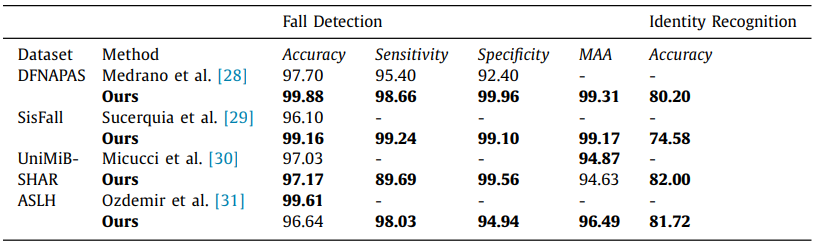
필자는 제안한 모델이 최상의 성능을 낼 수 있도록 여러 실험을 진행하였다. 먼저, k-NN 분류기에서의 적절한 k값 선정을 위한 실험에서는 1부터 4까지의 값 중 k=3 일때 평균적으로 최상의 결과를 얻어낼 수 있었다. 두 번째로는, cross dataset 특징 추출기를 사용할 때 사용하는 분류 알고리즘에 따른 성능을 비교했을 때, SoftMax 함수와 FC 레이어를 사용하는 것보다 k-NN 구조에서 일반화가 원활히 진행되어 더 좋은 성능을 얻어낼 수 있었다고 한다. 마지막으로, 위의 표에서 확인할 수 있듯 멀티태스크 학습 접근 방식을 적용시켜 다른 실험 결과 값들과 비교했는데, 결과적으로 7개 중 2개의 케이스를 제외하고는 기존의 실험값들보다 우수한 결과를 도출해낼 수 있었다고 한다.
Conclusions
본 논문에서는 원시 가속도계 데이터를 입력으로 사용하는 Fall Detection 및 피사체 식별을 위한 아키텍처를 제시했다. 멀티태스크 학습 접근 방식을 사용함으로써 단일 모델을 가지고 Fall 감지와 동시에 피사체를 식별할 수 있었다. 또한, 4개의 다양한 조건의 데이셋으로 시스템을 테스트하여 일반화시킬 수 있었다. 따라서 추가 훈련이나 fine-tuning 프로세스를 거치지 않고 모든 데이터셋에 적용할 수 있는 모델을 개발한 것이 가장 큰 의의라고 볼 수 있다.
