KPMG Future Academy AI 활용 데이터 분석가 3기 35일차 수업을 2025년 1월 7일에 참석했다.
- 시각화 라이브러리
1.1. matplotlib
1.2. seaborn
1.3. plotly
1.4. folium
1. 시각화 라이브러리
데이터의 시각화 : 비즈니스의 인사이트를 파악
그래프의 통계량에는 요약된 정보가 표현된다는 한계가 있음.
요약을 하는 관점에 따라 해석의 결과가 달라질 수 있음.
요약시 정보의 손실이 발생함.
1.1. matplotlib
https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.plot.html
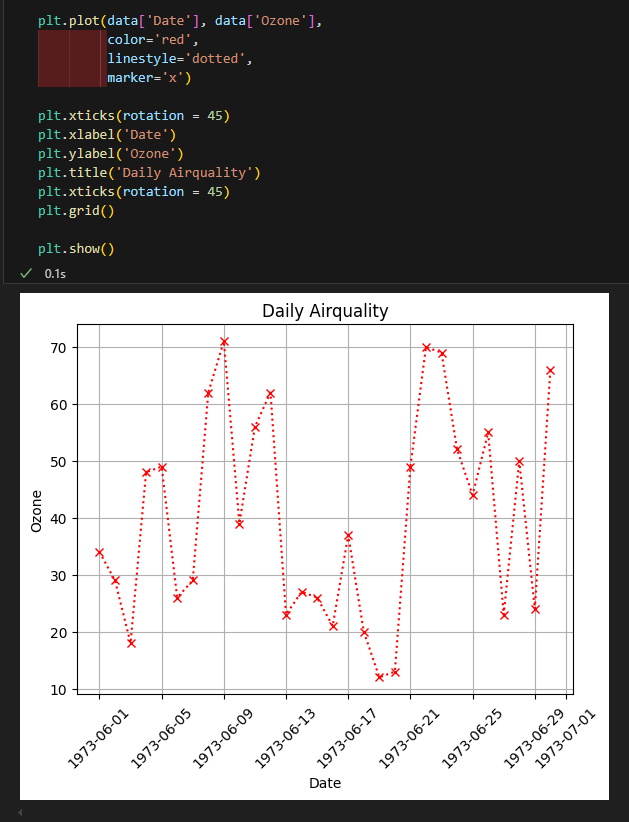
- xlabel() 함수를 사용하여 그래프의 x축에 대한 레이블 표시
- ylabel() 함수를 사용하여 그래프의 x축에 대한 레이블 표시
xticks(rotation=)으로 기울이기
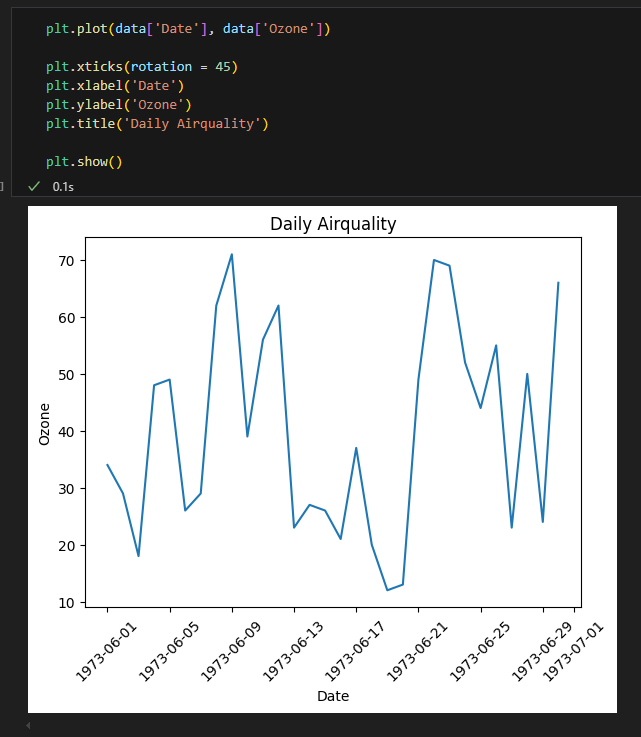
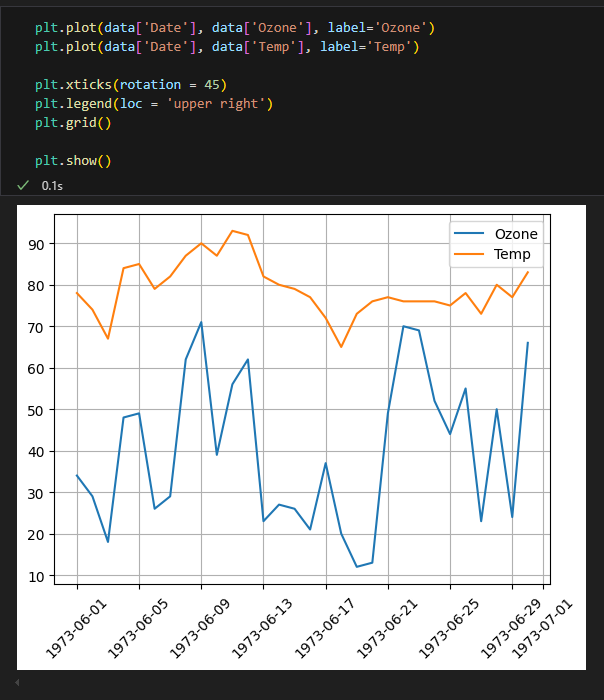
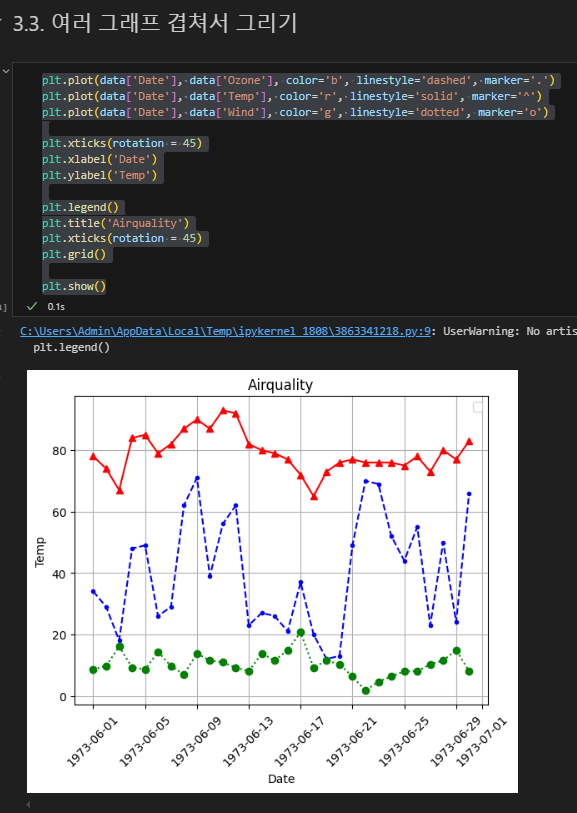
legend(), grid()
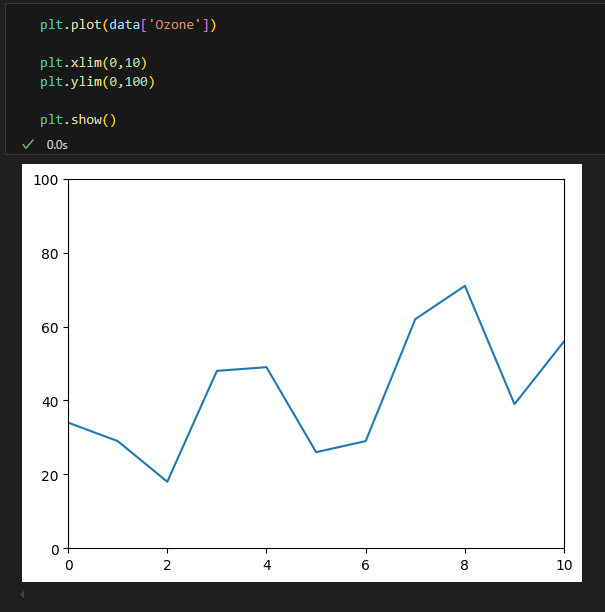
축 범위 조정
- xlim() : X축이 표시되는 범위 지정 [xmin, xmax]
- ylim() : Y축이 표시되는 범위 지정 [ymin, ymax]
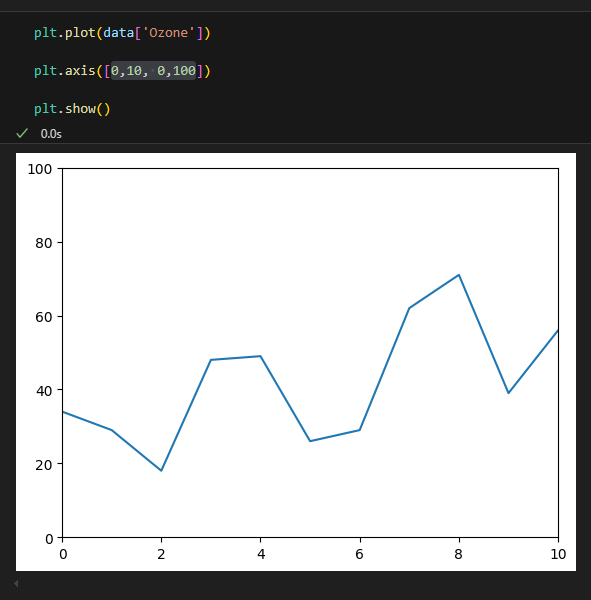
- axis() : X, Y축이 표시되는 범위 지정 [xmin, xmax, ymin, ymax]
- 입력 값이 없으면 데이터에 맞게 자동으로 범위 지정
xlim, ylim으로 최소 최대 범위 설정
axis로 최소 최대 범위 설정
라인 스타일 조정하기
- color=
- 'red','green','blue' ...
- 혹은 'r', 'g', 'b', ...
- https://matplotlib.org/stable/gallery/color/named_colors.html
- linestyle=
- 'solid', 'dashed', 'dashdot', 'dotted'
- 혹은 '-' , '--' , '-.' , ':'
- https://matplotlib.org/stable/gallery/lines_bars_and_markers/linestyles.html
- marker=
| marker | description |
|---|---|
| "." | point |
| "," | pixel |
| "o" | circle |
| "v" | triangle_down |
| "^" | triangle_up |
| "<" | triangle_left |
| ">" | triangle_right |
- https://matplotlib.org/stable/api/markers_api.html
- https://matplotlib.org/stable/gallery/lines_bars_and_markers/marker_reference.html#
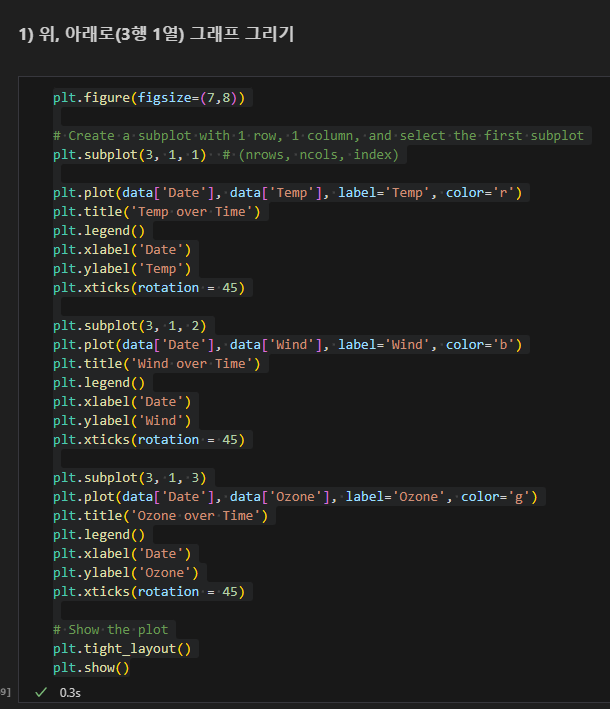
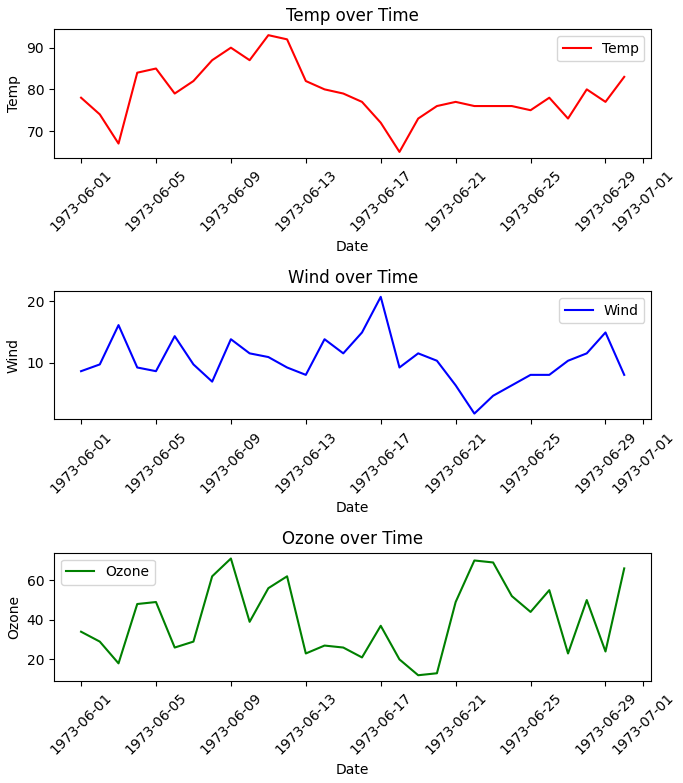
plt.subplot(low, column, index)
3행 1열
1행 3열
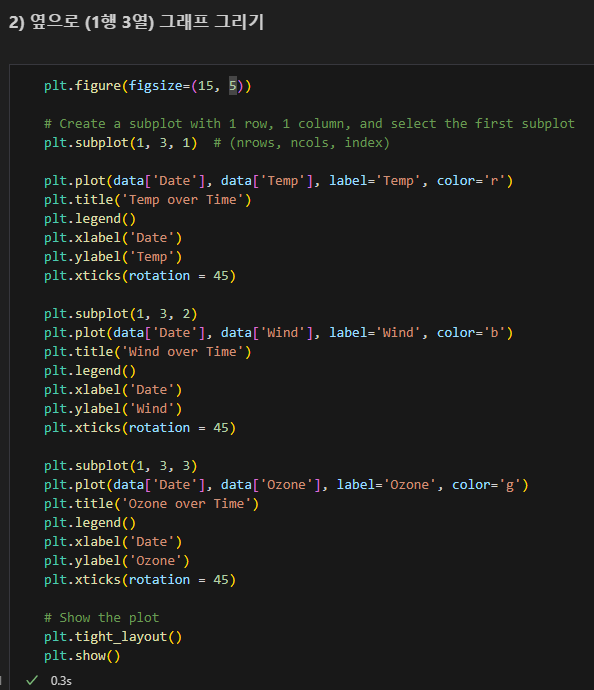
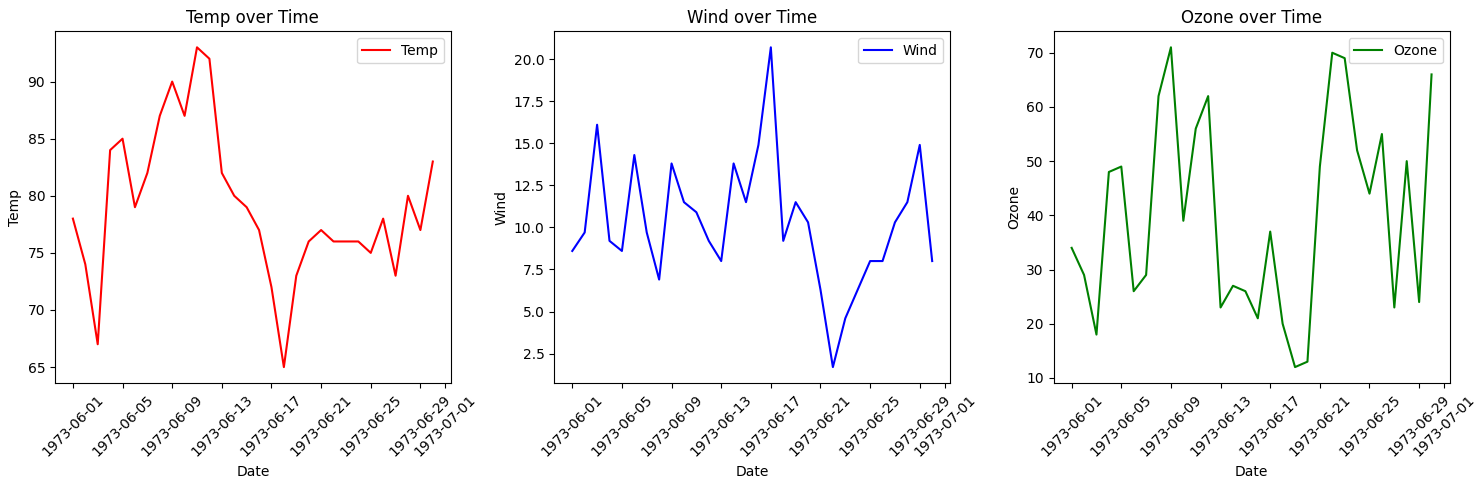
for문으로 여러 차트 그리기
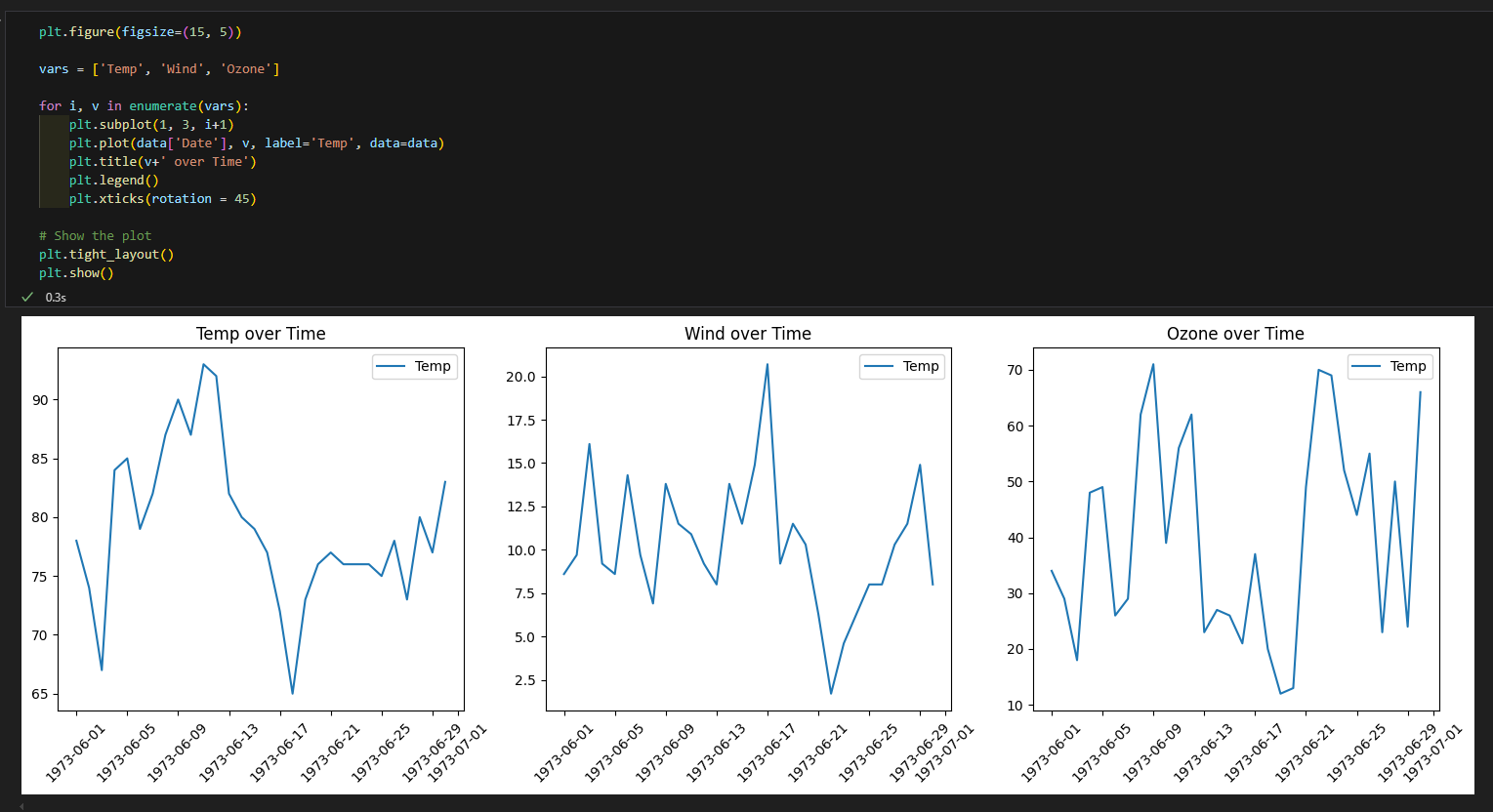
연습
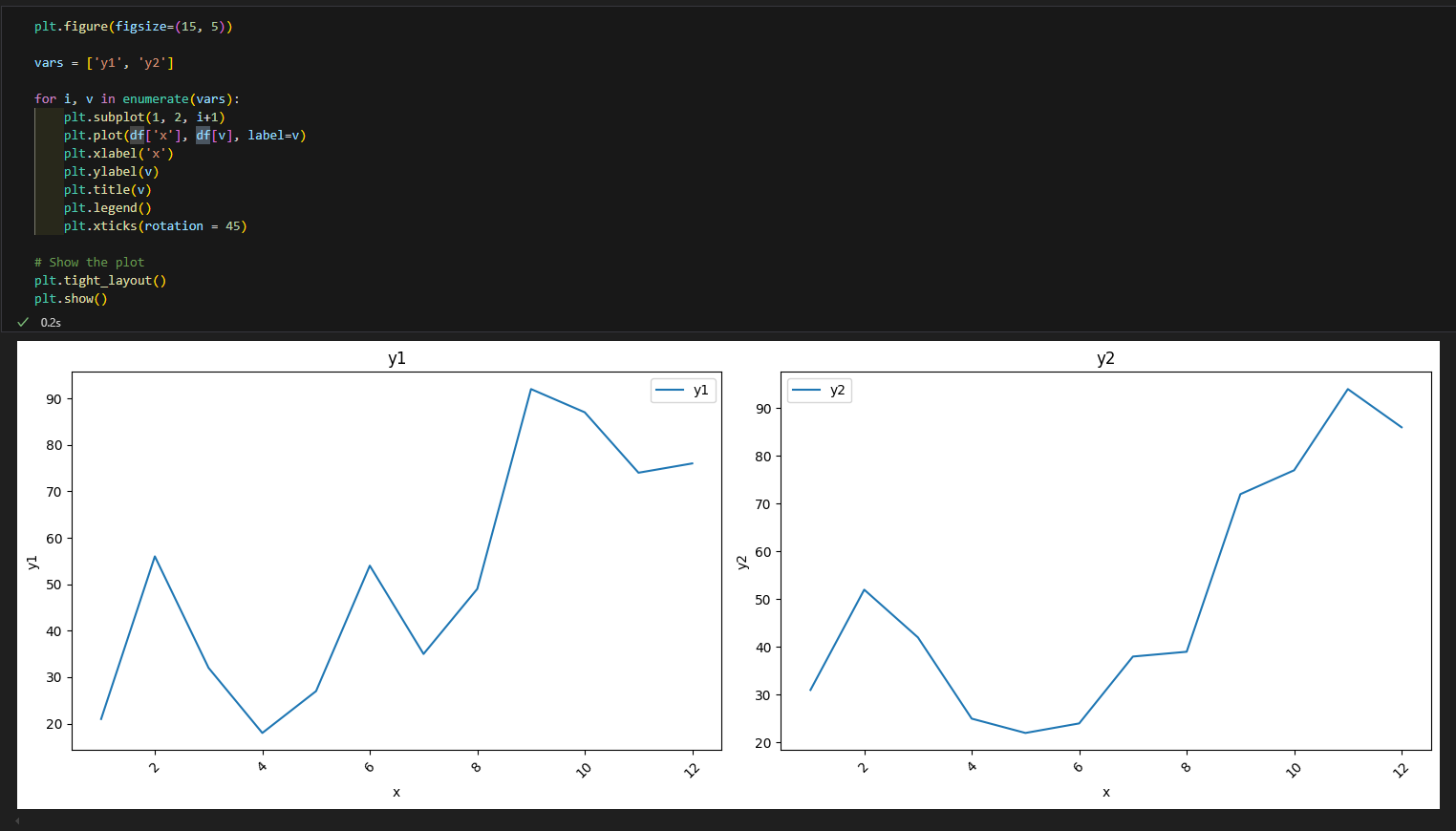
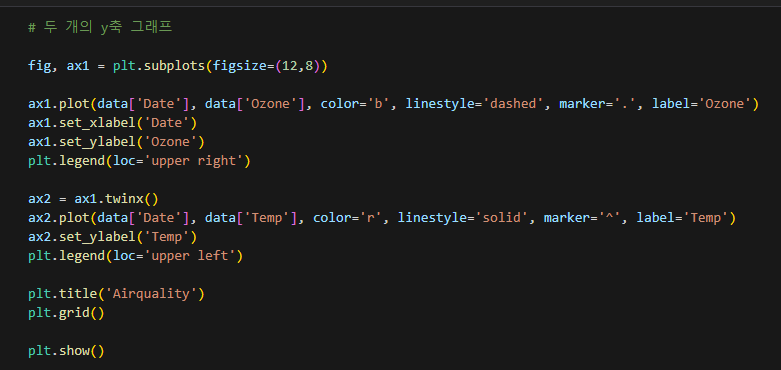
추가 기능
데이터프레임.plot()
- 데이터프레임을 쉽게 시각화하는 목적을 가지고 있다.
- 축, 제목, 범례 자동 설정
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.html
연습 문제
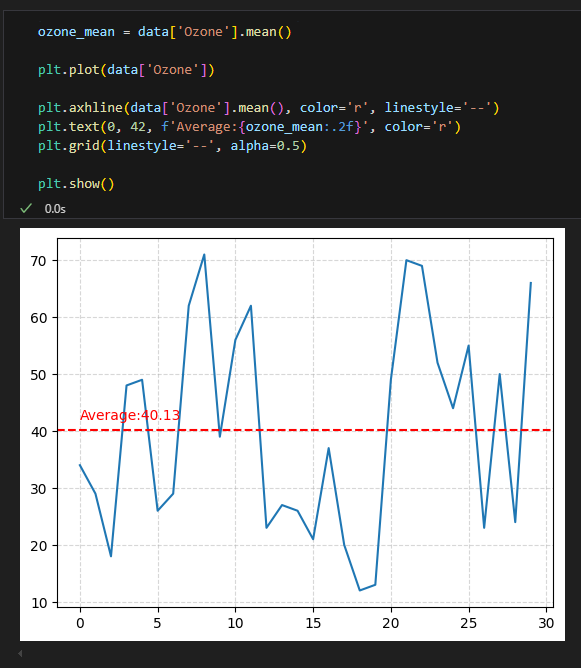
수평 수직선 추가, 텍스트 추가
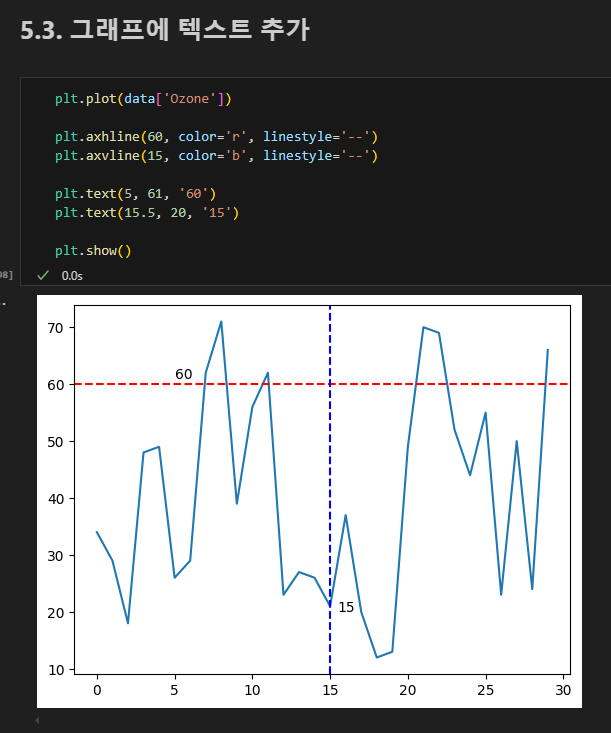
연습문제
그래프 저장하기
- savefig() 함수를 사용
- 주의할 점은 savefig() 함수를 호출한 이후에 plt.show( )를 호출하면 저장된 이미지가 비어 있을 수 있다.
- 그래서 figure를 저장할 때는 plt.show() 를 사용하지 않는 것이 좋다.
1.2.seaborn
기본 차트
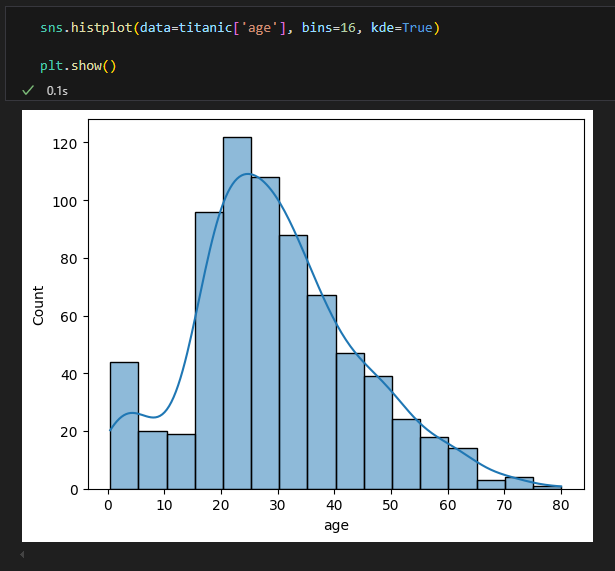
1) histogram : sns.histplot
-
histplot( ) 함수의 매개변수
- data : 히스토그램을 그릴 데이터셋을 지정
- bins : 히스토그램에서 막대의 개수를 지정
- kde : True로 설정하면 커널 밀도 추정(KDE) 곡선을 히스토그램 위에 추가
-
히스토그램
- 연속형 데이터를 일정한 간격으로 나누어 각 구간에 속하는 데이터 빈도를 막대로 표현한 그래프
- 각 막대는 데이터 분포를 나타내며 높이는 해당 구간의 데이터 개수를 나타낸다.
-
커널 밀도 추정 그래프
- 데이터 분포를 나타낸다는 점에서 히스토그램과 비슷하다.
- 그러나 막대 그래프 대신 부드러운 곡선을 사용하는데, 이는 커널 함수 덕분에 가능하다.
- 커널 함수는 각 데이터 포인트 주위에 작은 확률 분포를 만들고, 이를 모두 합하여 전체 데이터의 분포를 표현한다.
커널 밀도 추정 그래프 포함 히스토그램
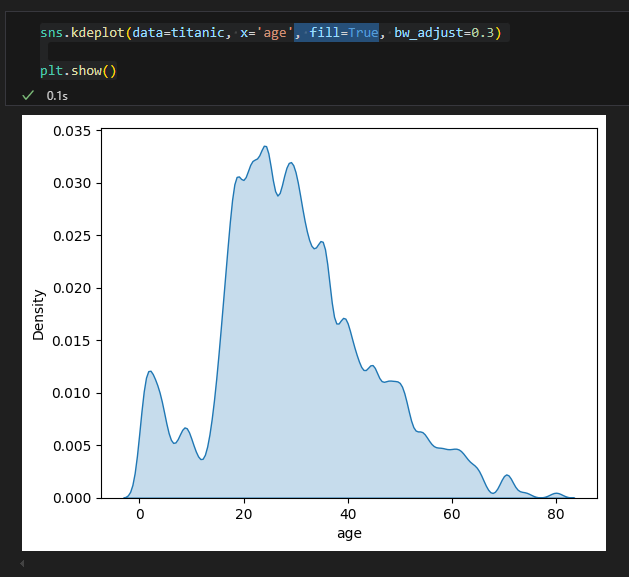
2) densityplot : sns.kdeplot
- https://seaborn.pydata.org/generated/seaborn.kdeplot.html
- kdeplot( ) 함수의 매개변수
- data : 사용한 데이터프레임
- hue : 그룹별로 색상을 나눔
- fill : 밀도 아래 영역을 채움
- bw_adjust : 커널의 너비 조정 (값이 작을수록 더 세밀함)
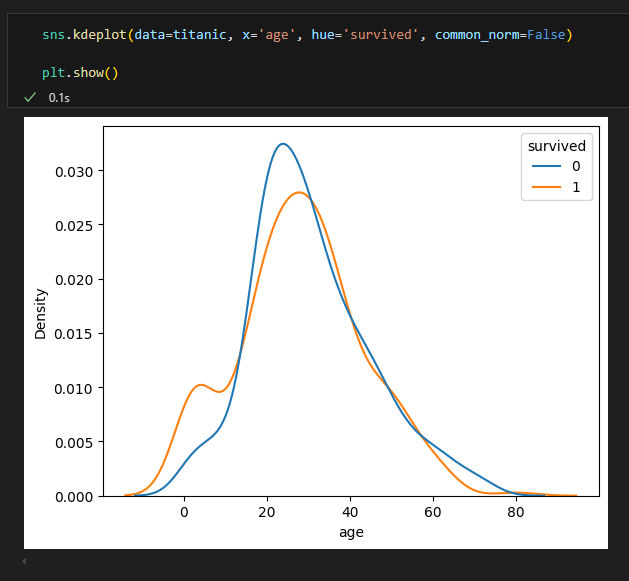
- common_norm : 그룹별 밀도 곡선의 정규화(Normalization) 방식을 설정
- 정규화(Normalization): 밀도 곡선을 그릴 때, 곡선 아래 면적의 총합이 1이 되도록 스케일을 맞추는 과정
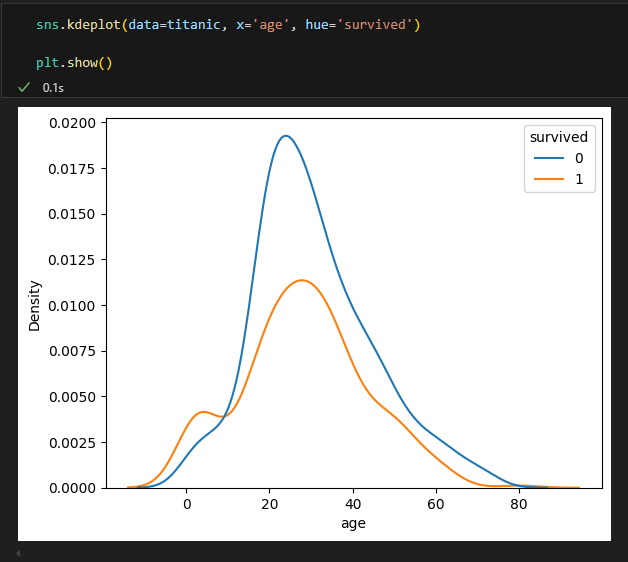
정규화 : 그룹별 밀도곡선의 정규화 적용 (False시 각 그룹별 밀도가 1)
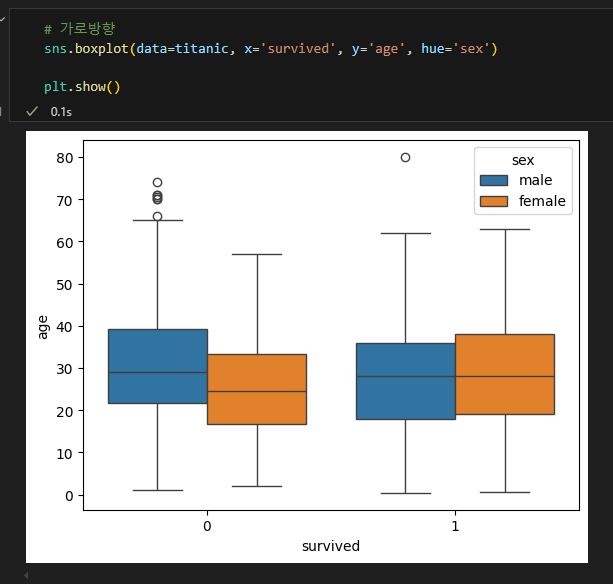
3) boxplot
- https://seaborn.pydata.org/generated/seaborn.boxplot.html
- 주로 범주형 데이터와 연속형 데이터 간의 관계를 나타낼 때 유용
- boxplot( ) 함수의 매개변수
- data : 사용한 데이터프레임
- hue : 그룹을 나눌 기준 변수
- order : x축 범주의 순서 지정
- width : 박스 너비 조정 (기본값: 0.8)
- showfliers : 이상치(outliers) 표시 여부 (기본값: True)
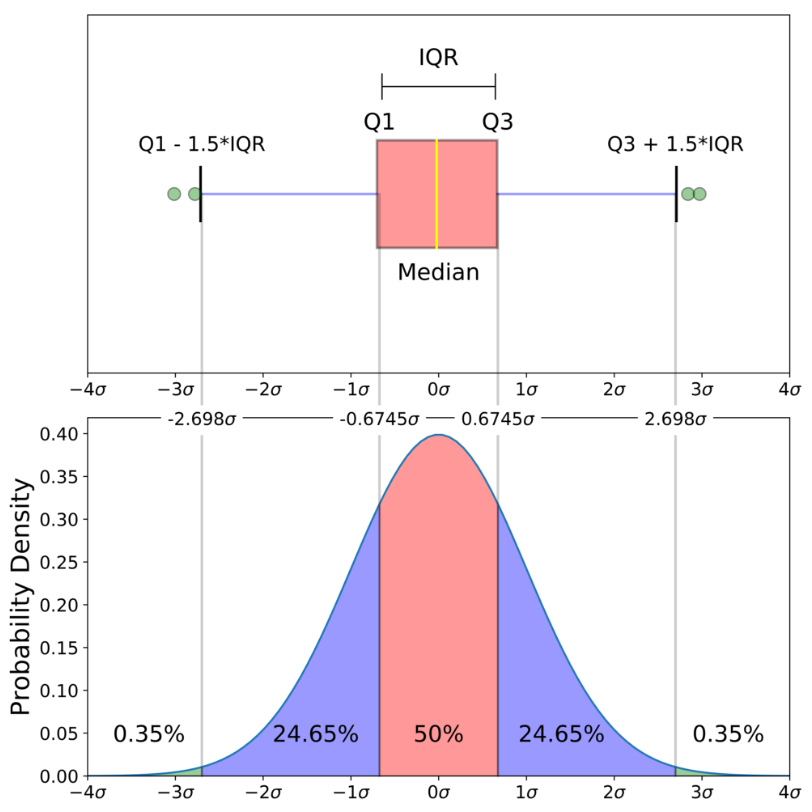
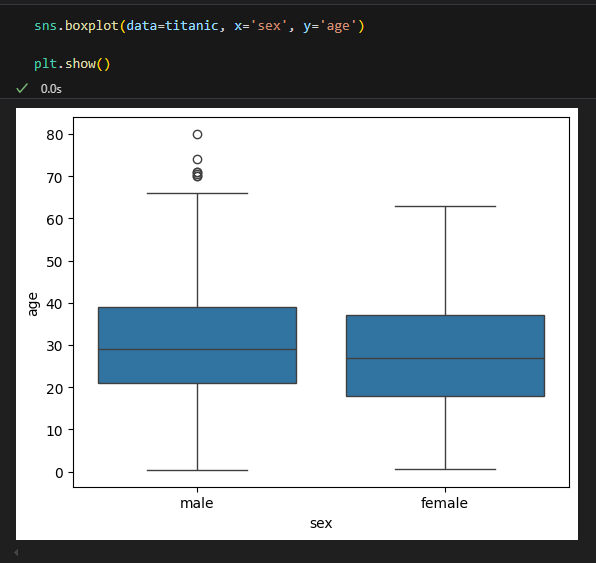
sns.boxplot(data=titanic, x='sex', y='age', showfliers=False) #이상치 감추기
가로
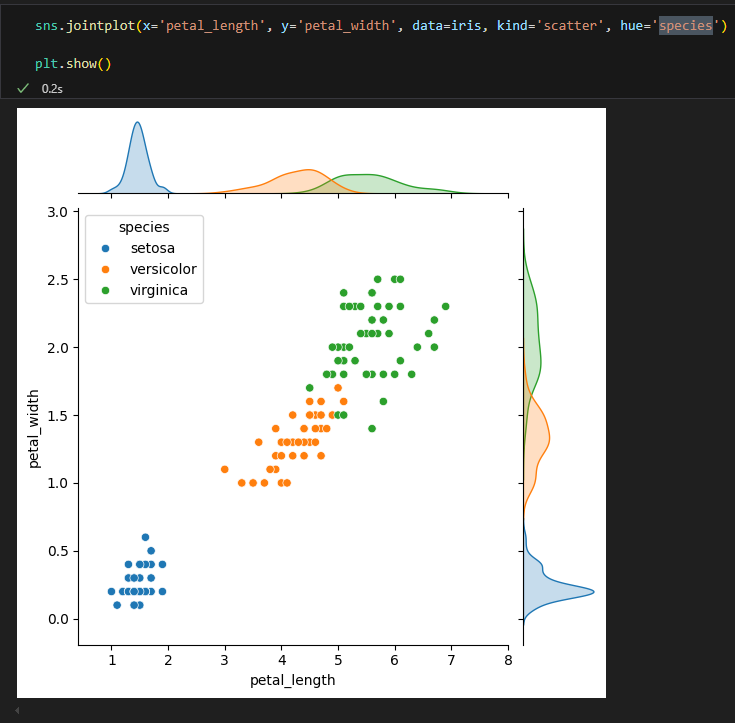
2.2.2. jointplot : scatter + histogram(혹은 density plot)
-
두 숫자형 변수의 분포를 산점도와 히스토그램으로 함께 시각화하여 데이터 간의 관계를 확인 할 수 있다.
-
Seaborn 그래프의 가장 큰 특징은 hue 옵션으로 범주 차원을 추가해서 볼 수 있다.
-
jointplot( ) 함수의 매개변수
- x, y : x축과 y축에 사용할 변수
- data : 히스토그램을 그릴 데이터셋을 지정
- kind : 결합 플롯의 유형을 지정
- scatter(산점도 플롯), kde(커널 밀도 추정 그래프), hex(육각형 바이닝 플롯), reg(회귀선을 포함한 산점도 플롯), resid(회귀 분석 잔차 플롯)
2.2.3. regplot : scatter + regression
-
두 숫자형 변수의 산점도와 회귀선을 한꺼번에 비교하여 보여준다.
-
두 변수 간의 선형 관계를 시각화하는데 사용
-
regplot() 함수의 매개변수
- x : x축에 사용할 변수
- y : y축에 사용할 변수
- data : 시각화할 데이터를 포함하는 데이터프레임을 지정
- fit_reg : False로 설정하면 회귀선을 그리지 않고 산점도만 시각화
- scatter_kws : 산점도의 점 스타일을 지정하는 데 사용
- line_kws : 회귀선의 스타일을 지정
- ax : 그래프가 그려질 맷플롯립 축 객체를 지정
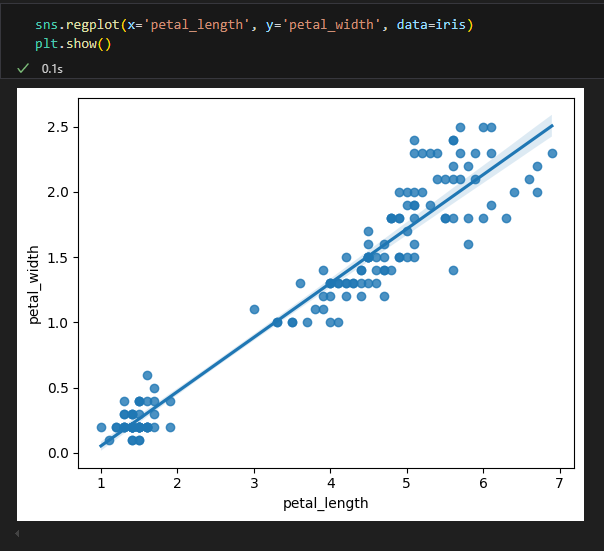
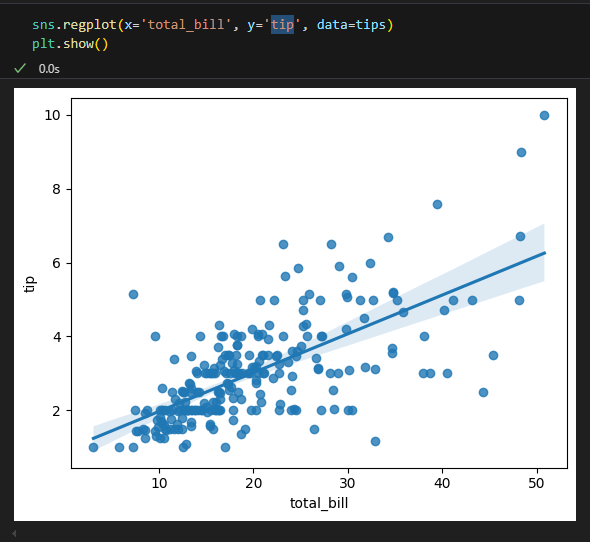
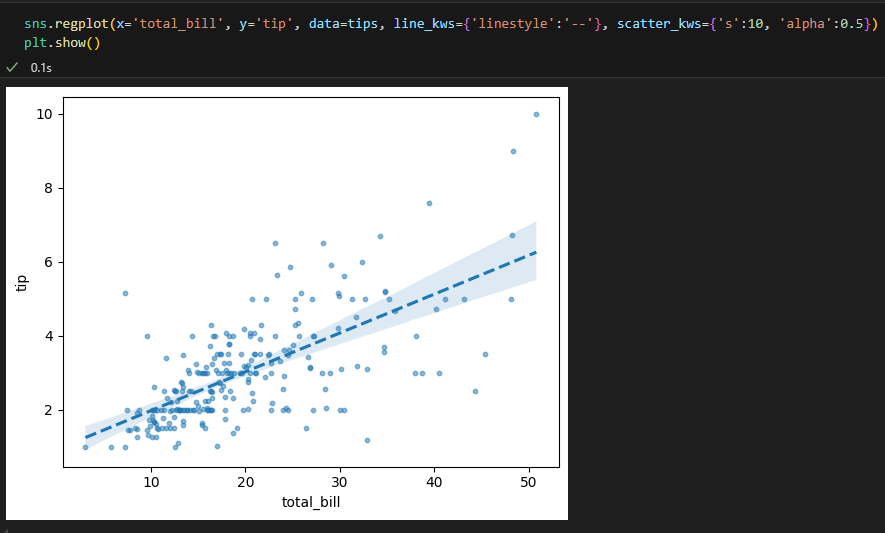
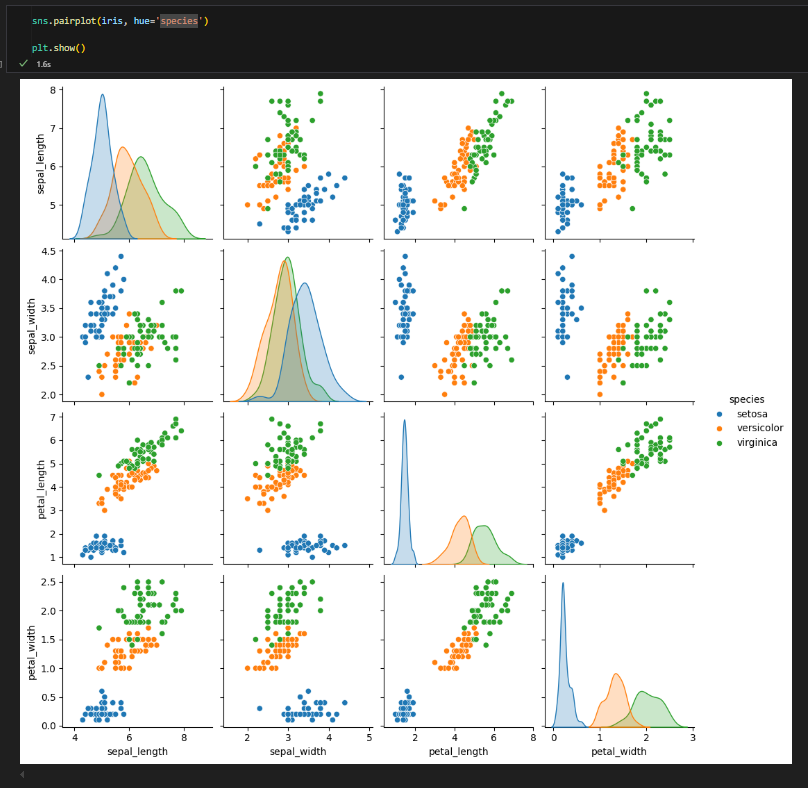
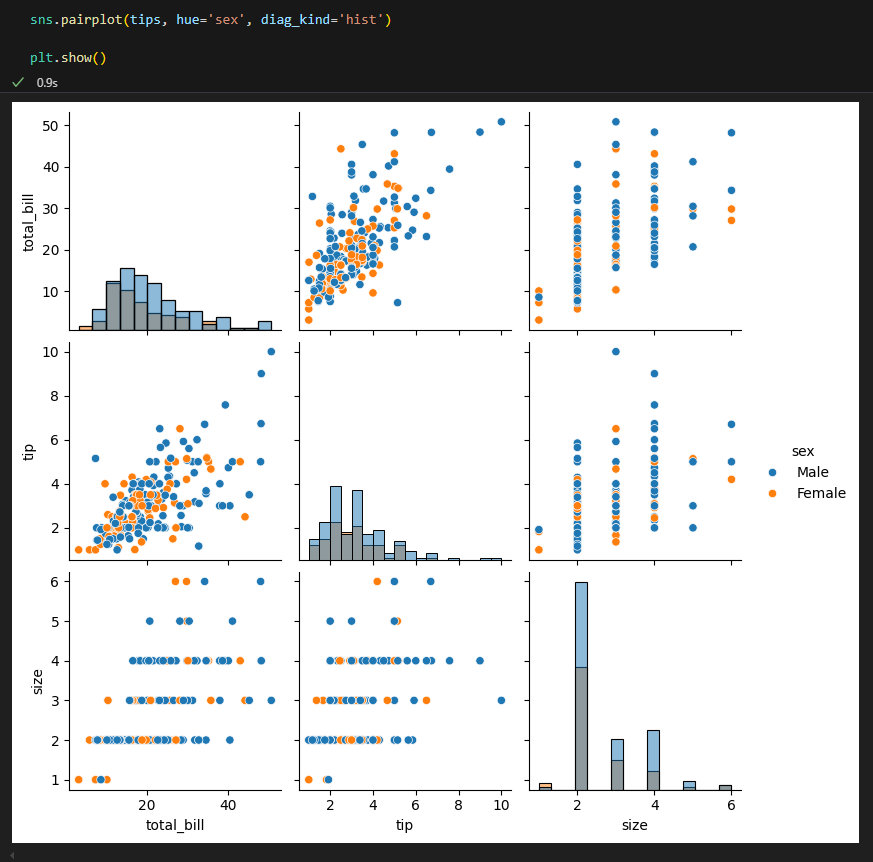
2.2.4. pairplot : scatter + histogram(혹은 density plot) 확장
-
모든 숫자형 변수들에 대해서 서로 비교하는 산점도 표시
-
각 변수에 대해서는 히스토그램(혹은 density plot) 표시
-
단점 : 시간이 오래 걸린다!
-
pairplot( ) 함수 매개변수
- data : 사용할 데이터프레임
- hue : 데이터의 카테고리 변수를 기준으로 색상을 다르게 표시하여 그룹 간의 차이를 시각화
- diag_kind : 대각선에 나타낼 그래프의 종류를 선택
- auto : 기본값으로, 각 변수의 분포를 히스토그램으로 시각화
- hist : 각 변수의 분포를 히스토그램으로 시각화
- kde : 커널 밀도 추정 그래프를 사용하여 각 변수의 분포를 부드럽게 시각화
- None : 대각선에 아무런 그래프도 표시하지 않도록 설정할 수 있음
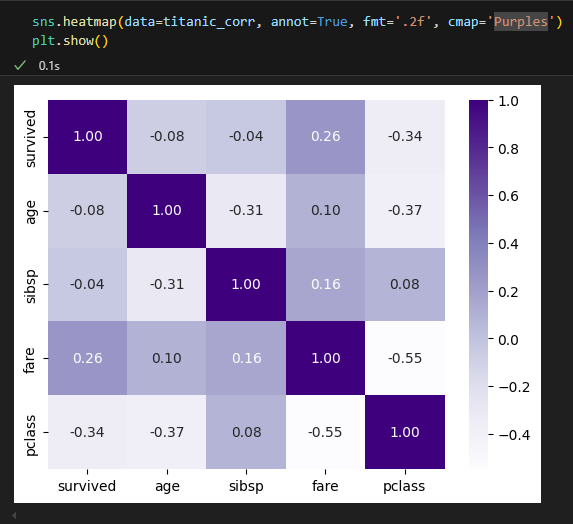
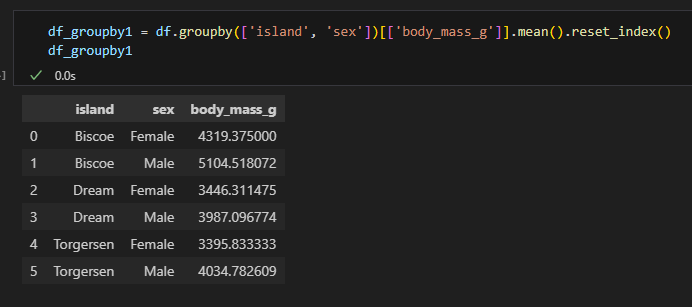
2.2.5. heatmap : 두 범주 집계 시각화
-
두 범주를 집계한 결과를 색의 농도로 표현해주는 그래프
-
집계(groupby)와 피봇(pivot)을 먼저 만들어 줘야 한다.
-
여러 범주를 갖는 변수 비교 시 유용하다.
-
heatmap( ) 함수 매개변수
- data : 히트맵에 사용할 2차원 데이터
- annot : 각 셀에 값을 표시할지 여부(기본값:False)
- fmt : annot=True일 때 숫자 포맷 설정
- cmap : 색상 팔레트 지정
- cbar : 컬러바 표시 여부
- square : 셀을 정사각형으로 표시
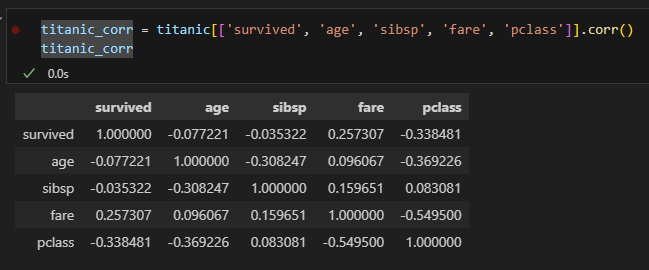
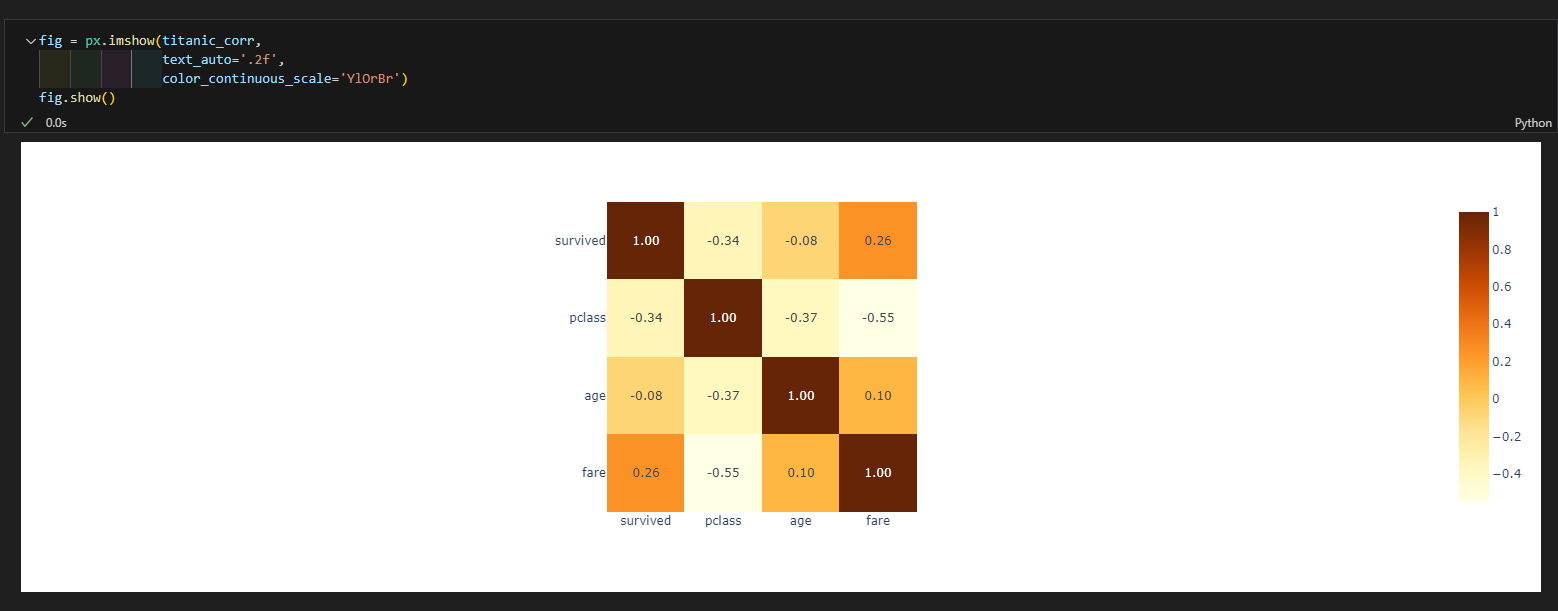
상관관계
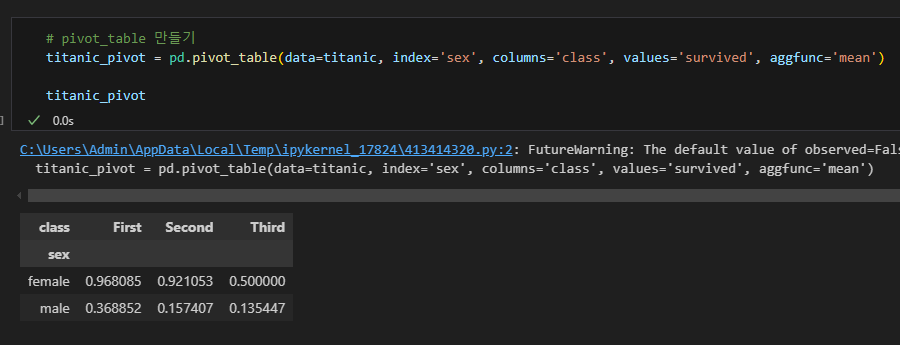
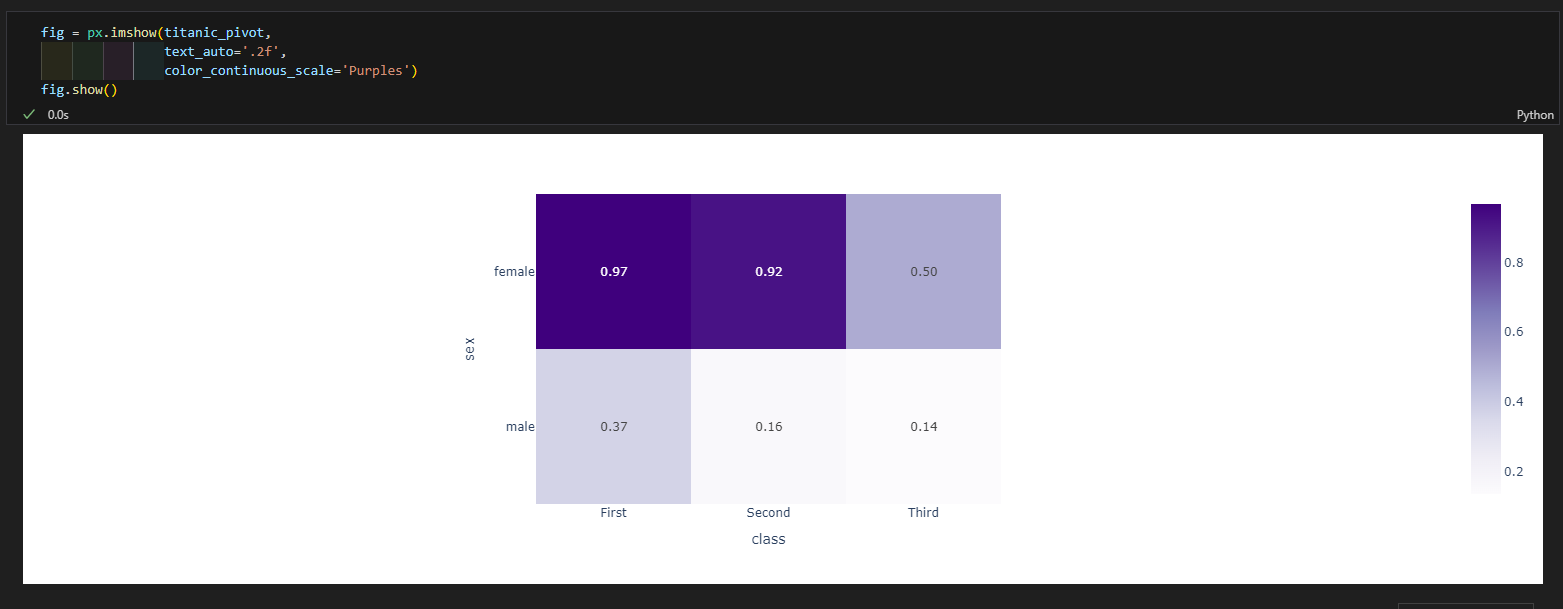
피벗테이블로 히트맵 그리기
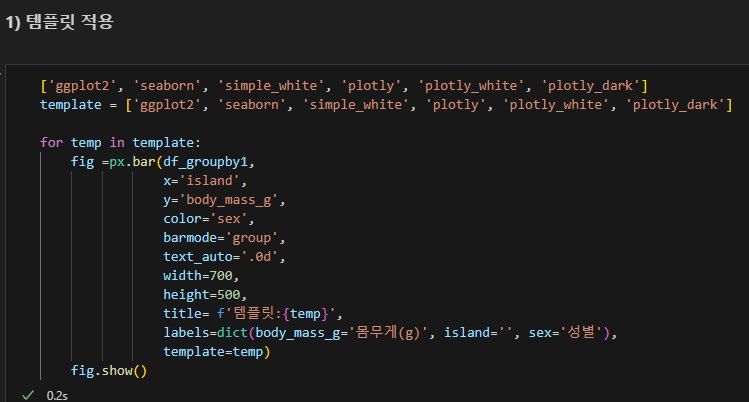
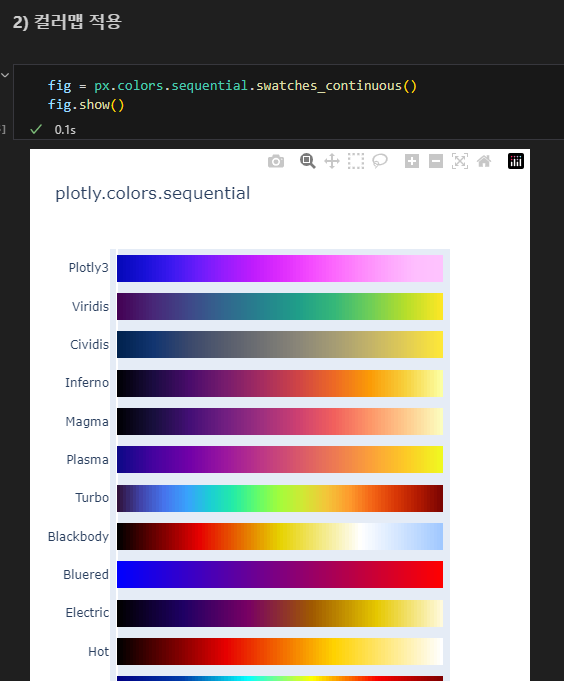
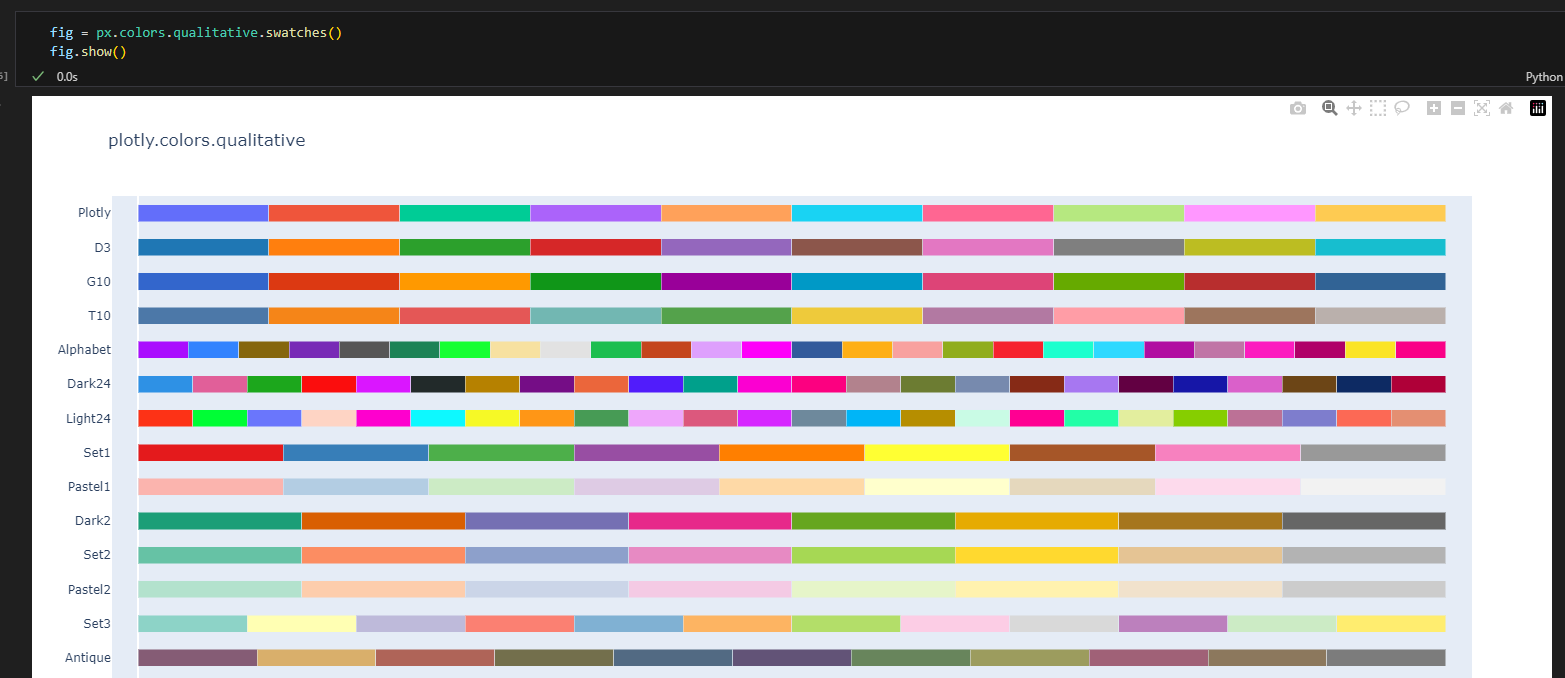
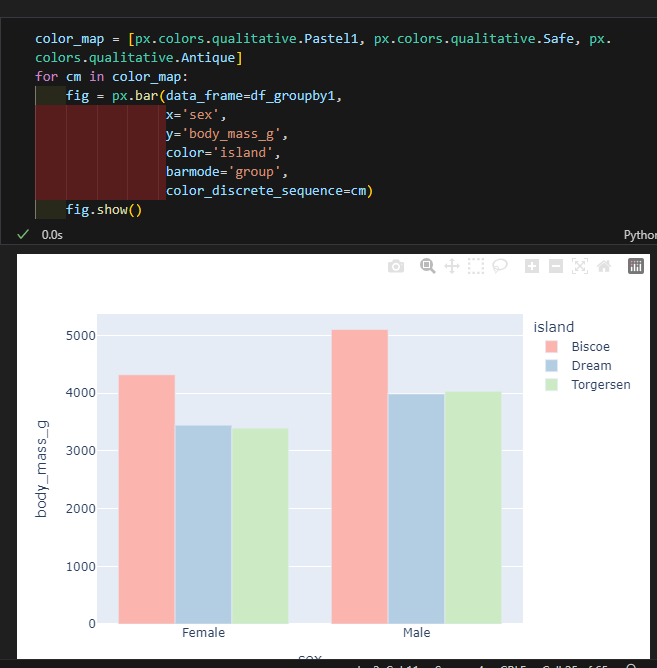
1.3. plotly
스타일 설정하기
- template : 템플릿명
- color_discrete_sequence : 컬러맵명 #범주형 데이터
- color_continuous_scale : 컬러맵명 #연속형 데이터
컬러맵 적용
html 저장
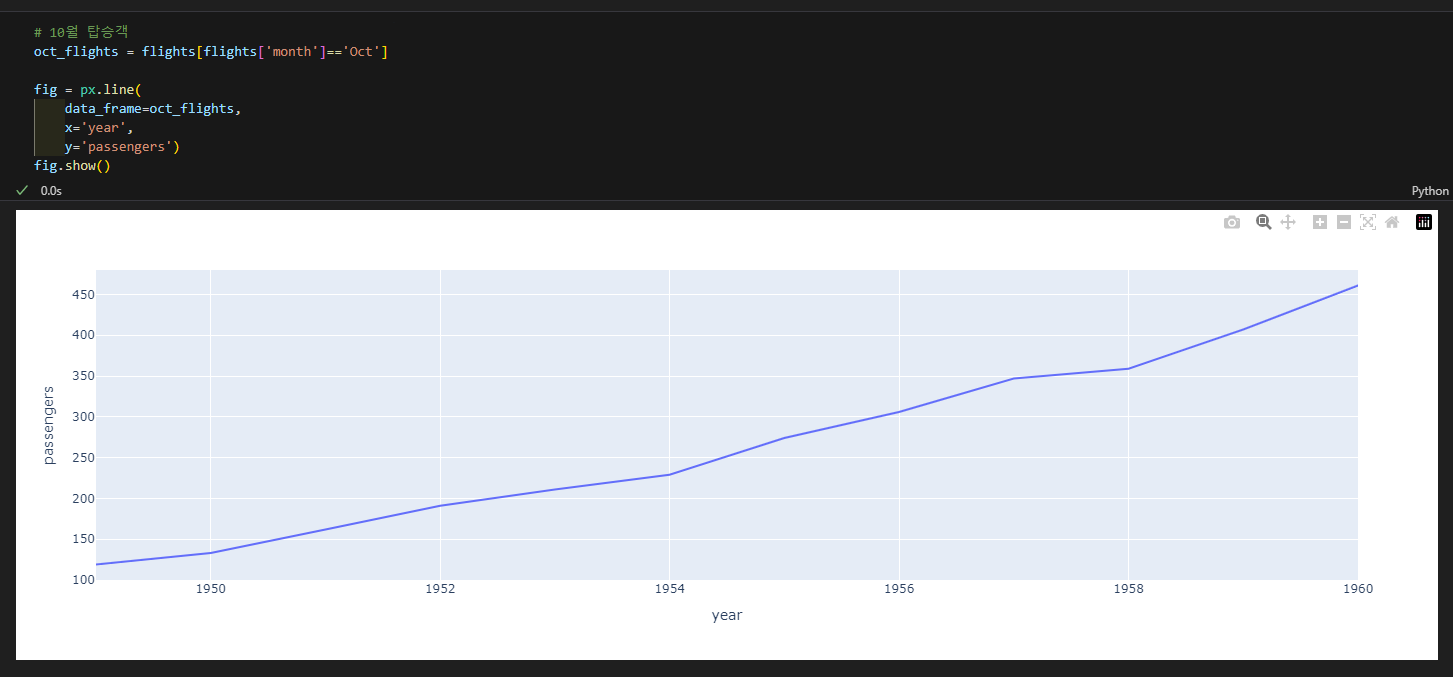
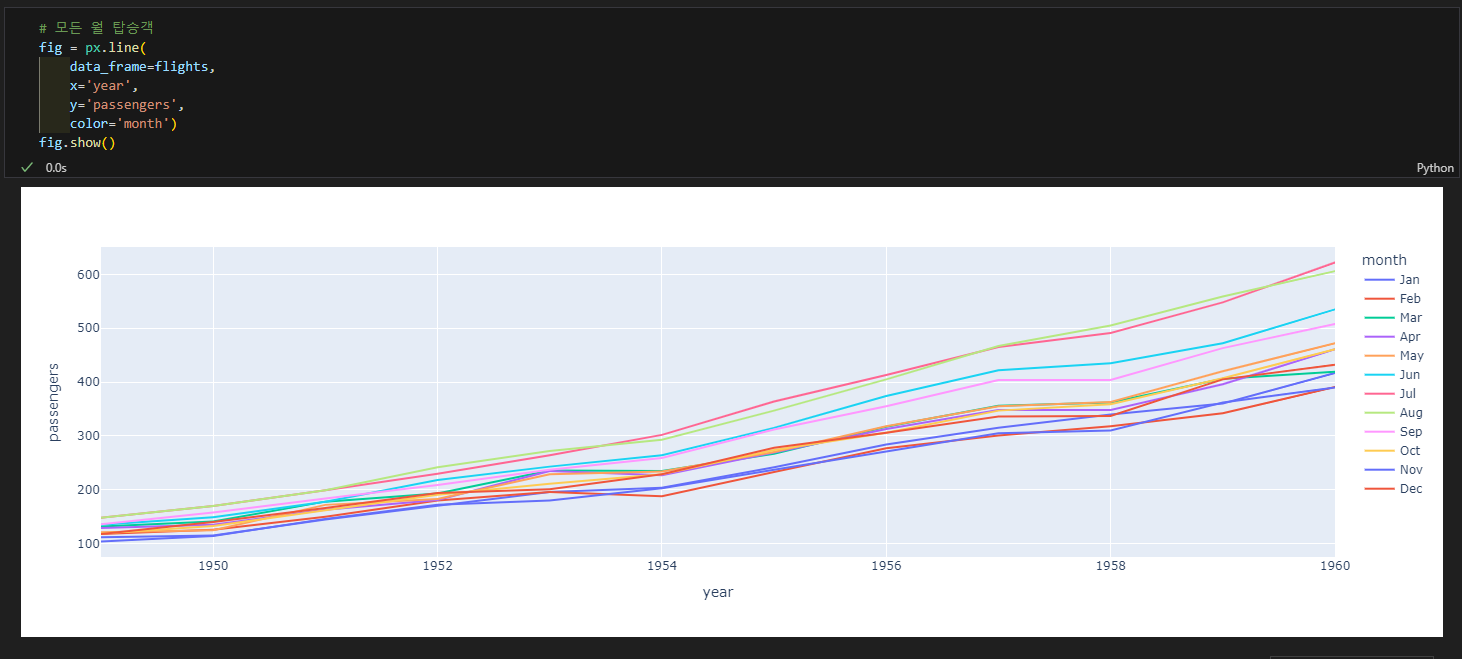
3.4.1. 선그래프
- px.line(data_frame=데이터, x=X축 컬럼, y=Y축 컬럼, color=색)
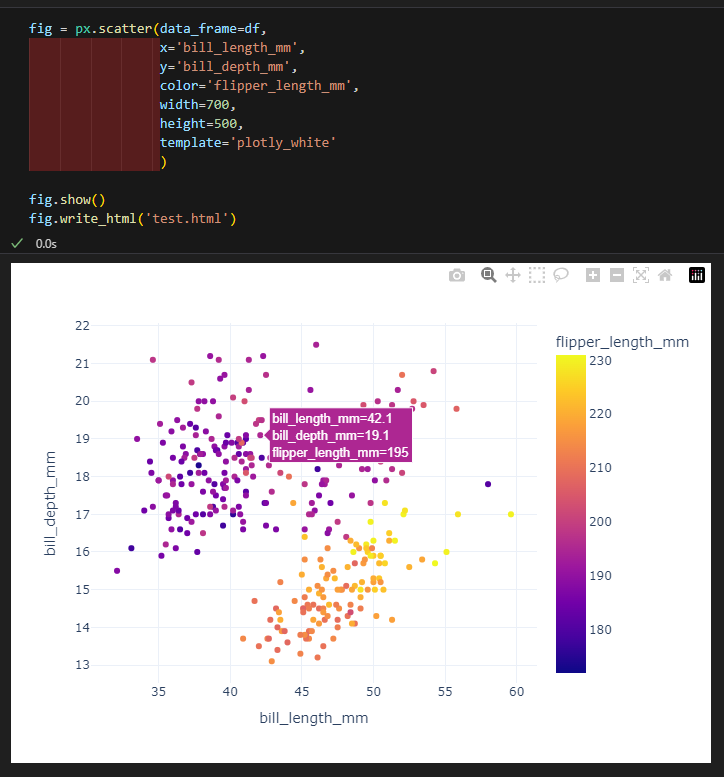
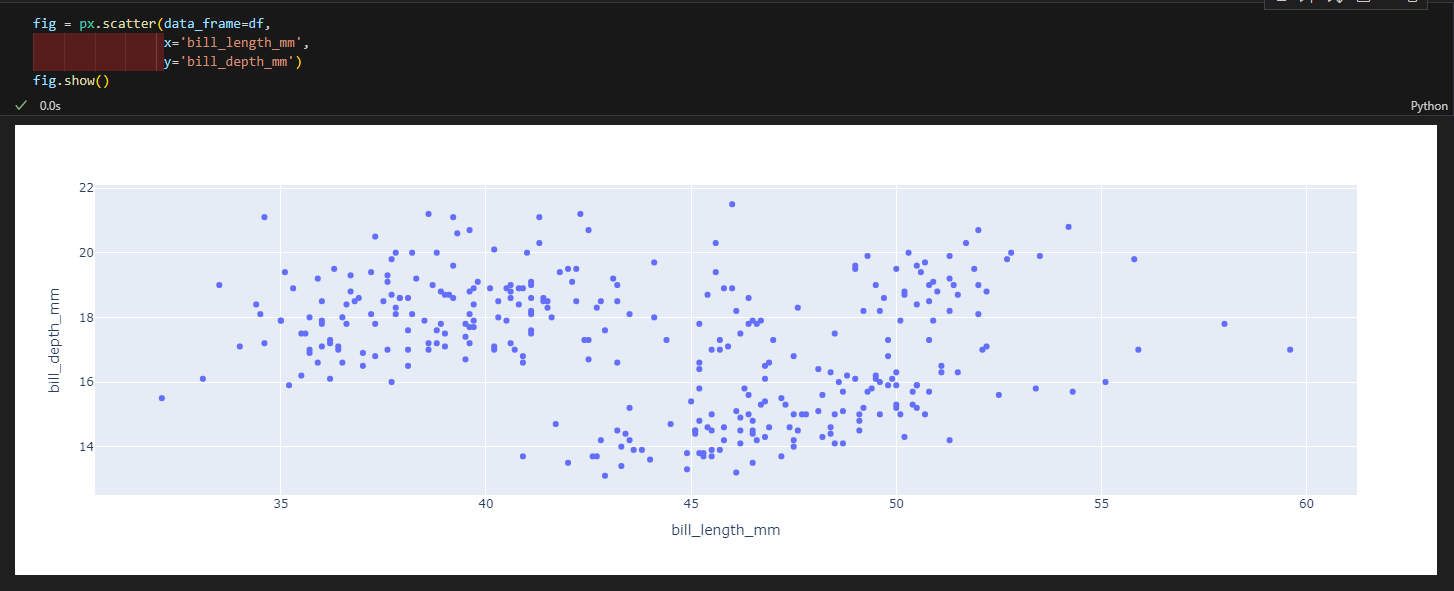
산점도
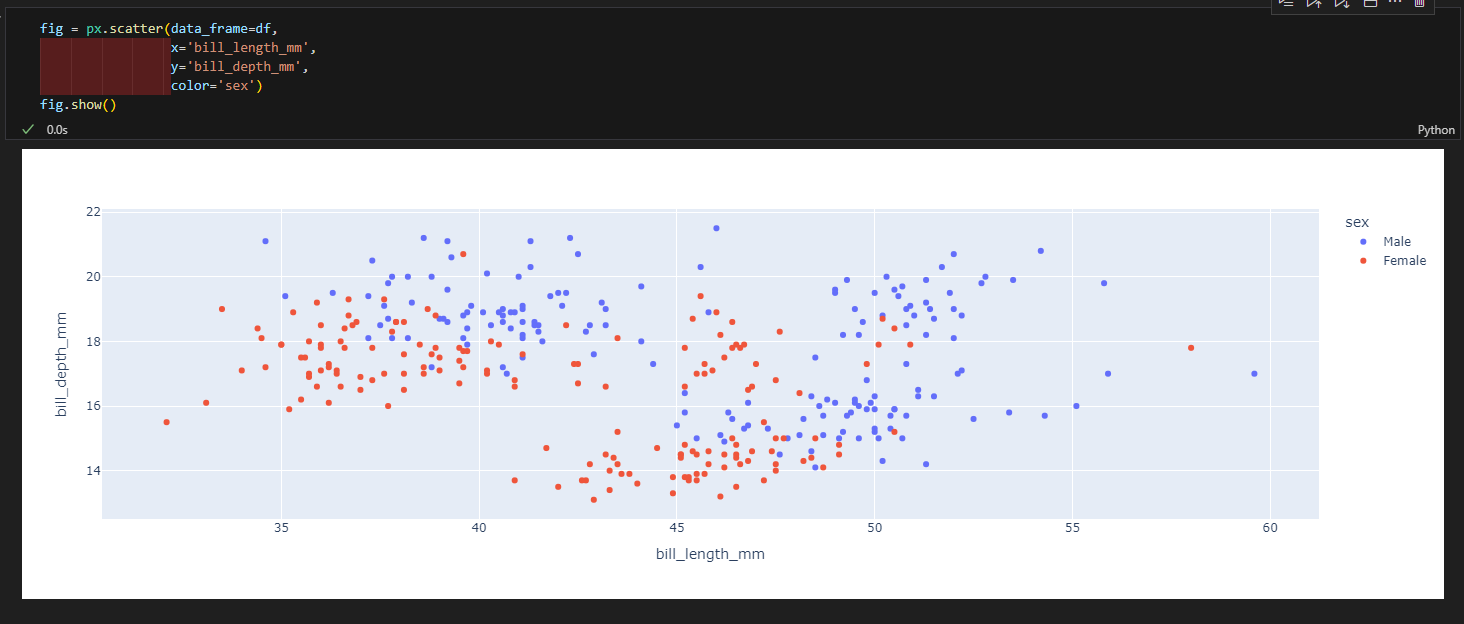
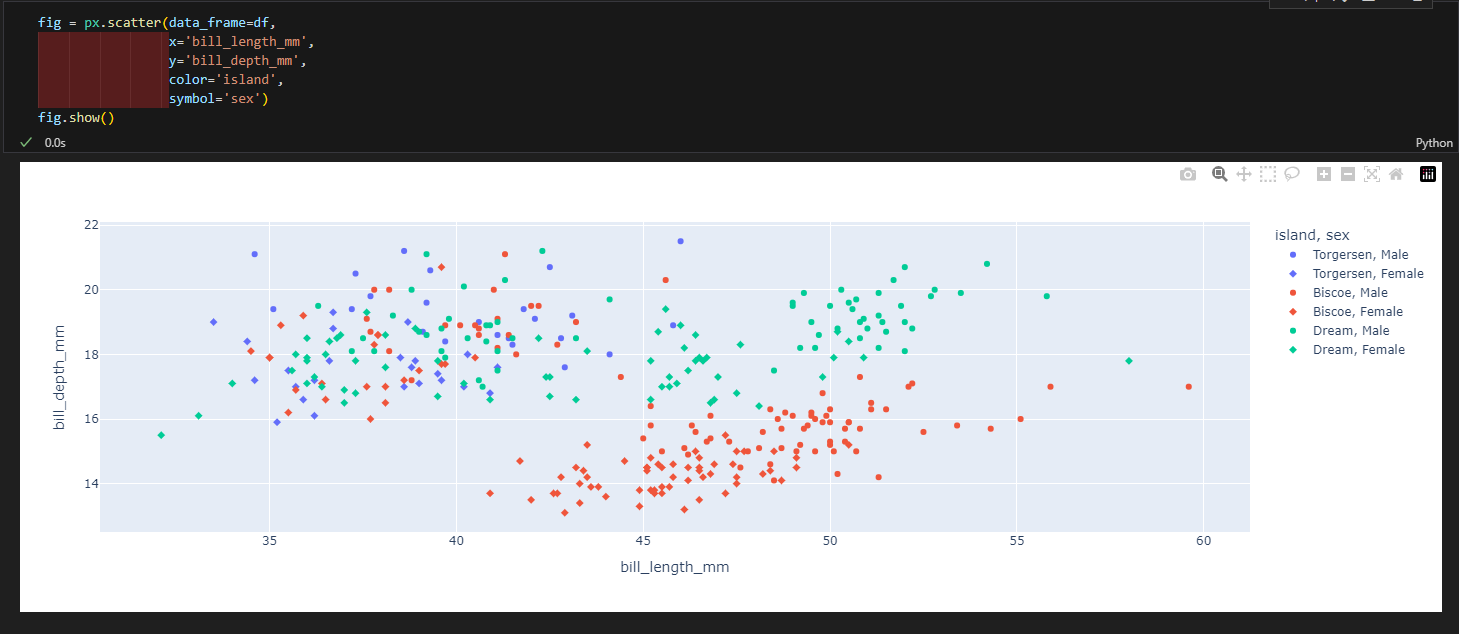
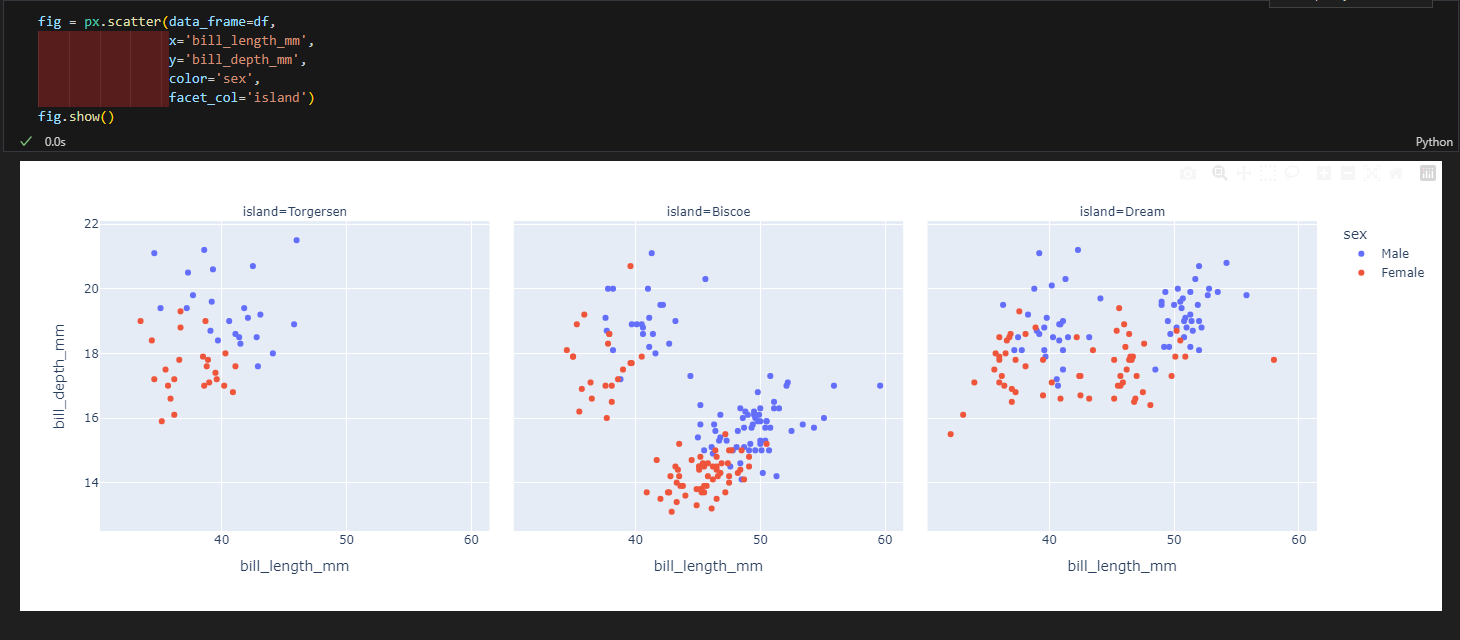
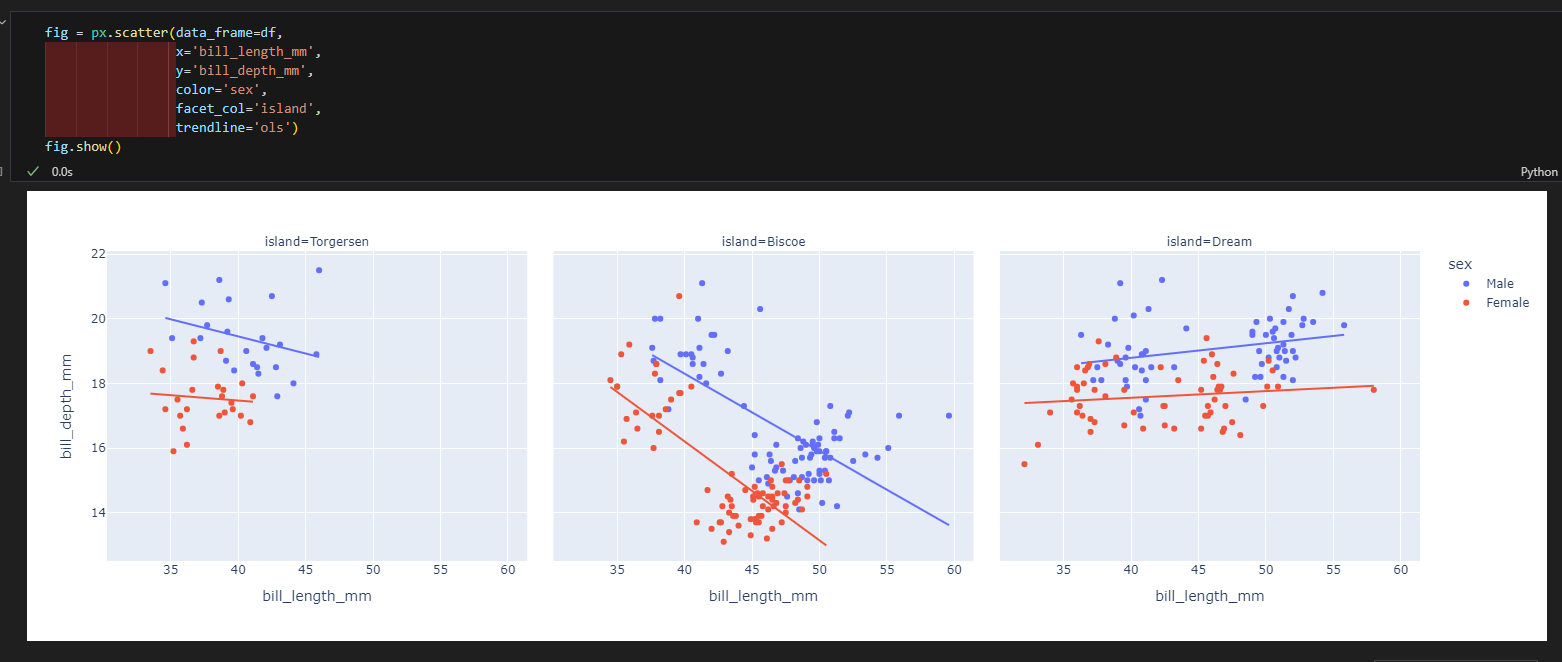
3.4.2. 산점도
- px.scatter(data_frame=데이터, x=X축 컬럼, y=Y축 컬럼, color=색, trendline='ols') #trendline은 추세선 추가
히스토그램
3.4.3.히스토그램
- px.histogram(data_frame=데이터, x=X축 컬럼, color=색)
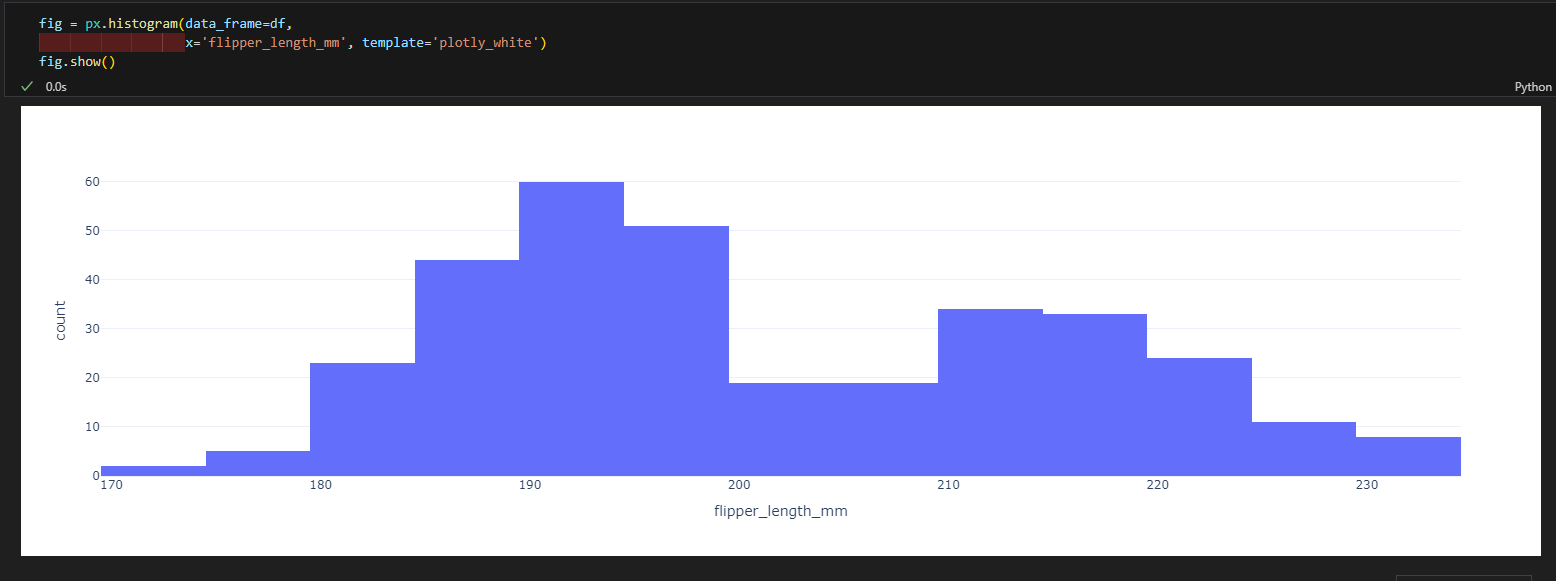
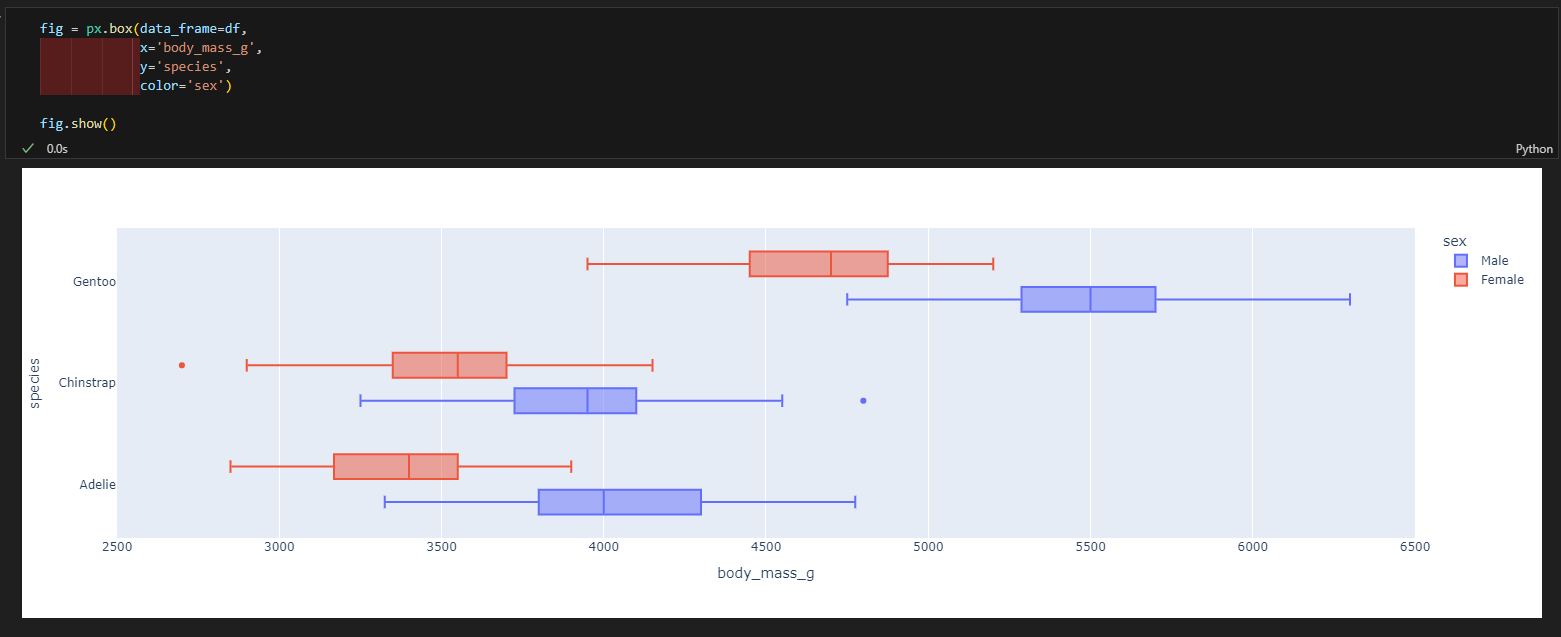
3.4.4.상자그림
- px.box(data_frame=데이터, x=X축 컬럼, y=Y축 컬럼, color=색)
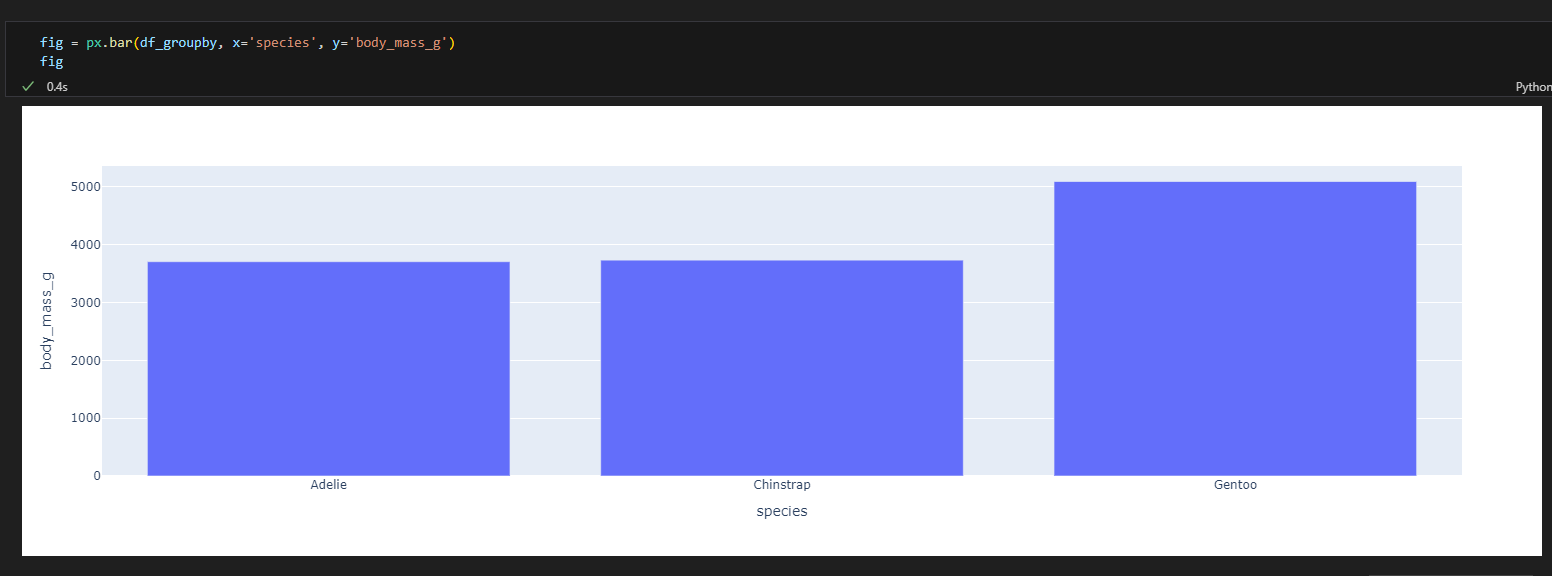
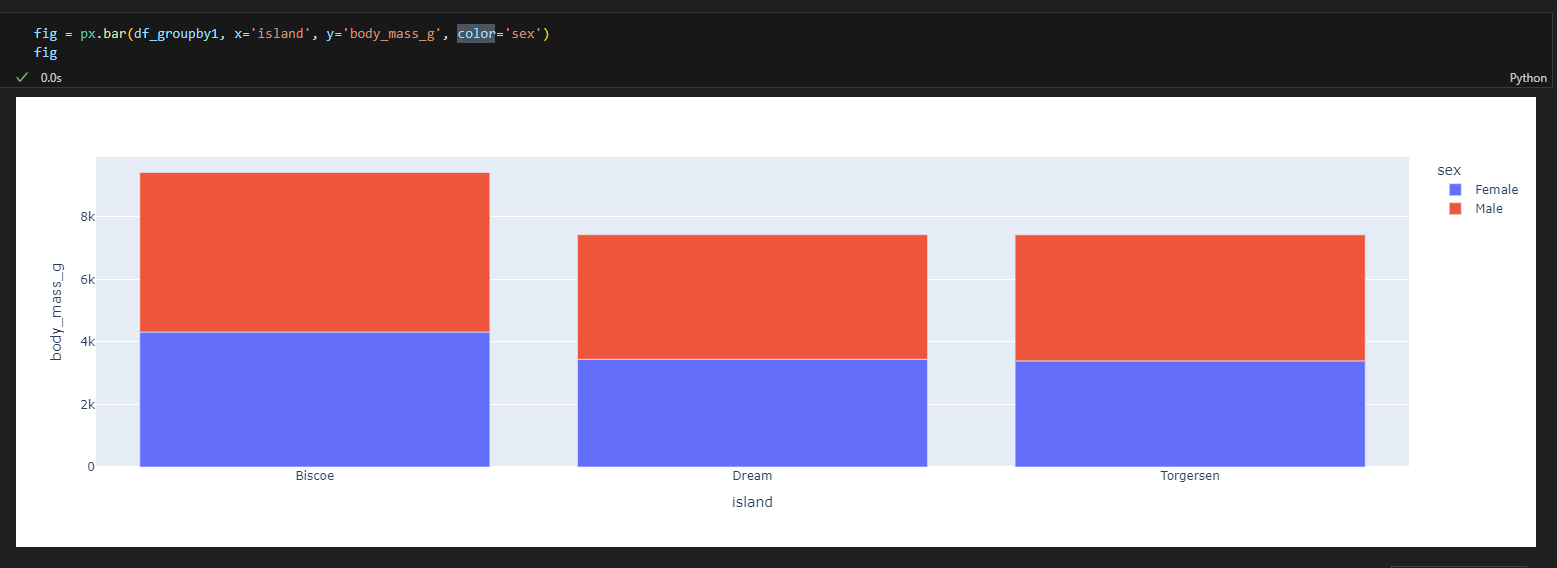
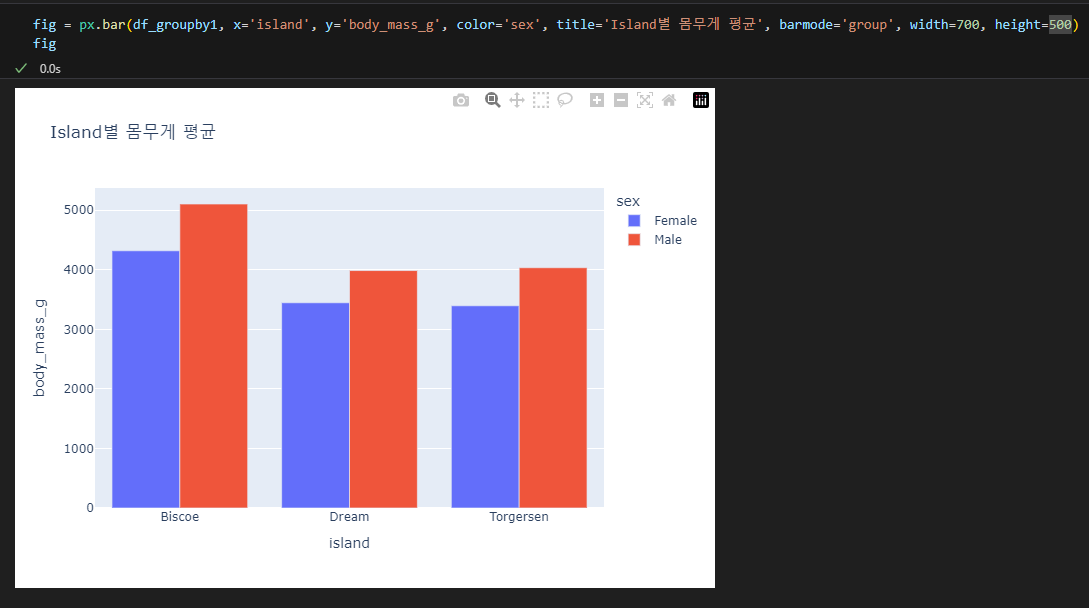
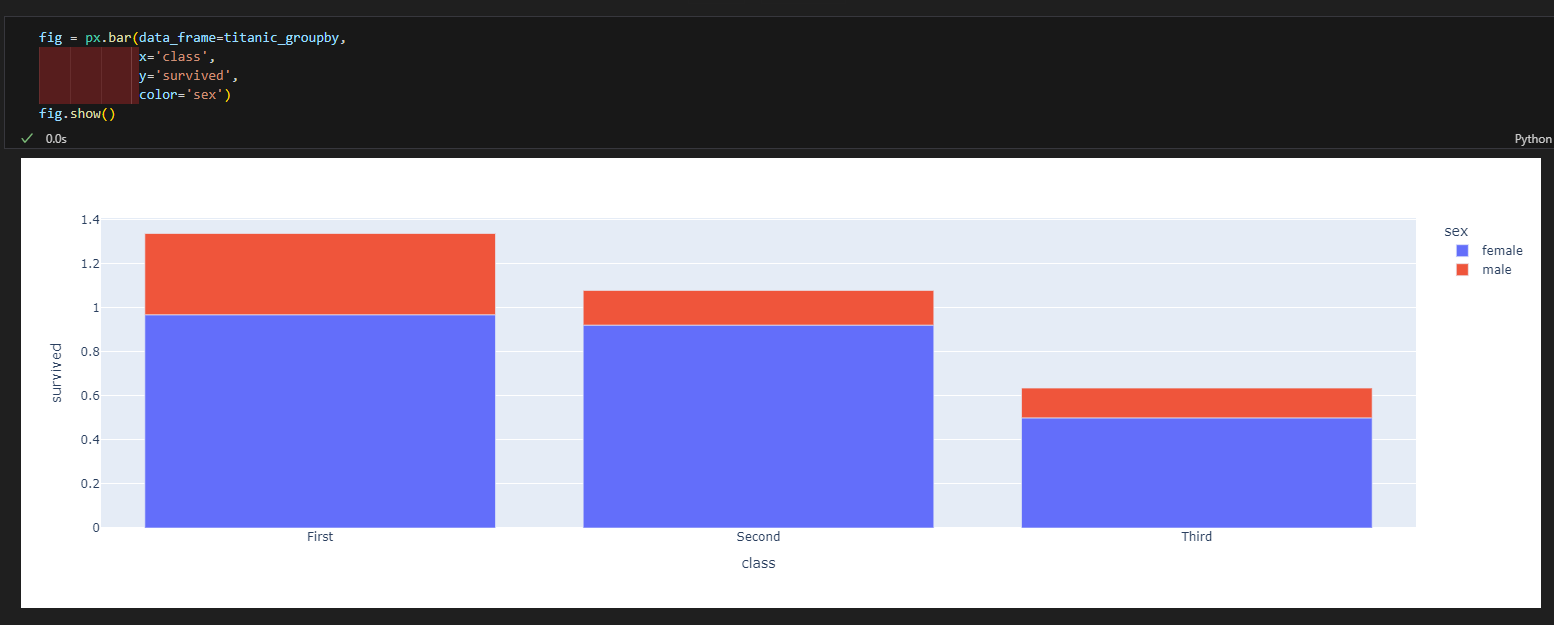
3.4.5. 막대 그래프
- px.bar(data_frame=데이터, x=X축 컬럼, y=Y축 컬럼, color=색, barmode='group') #쌓아서 올리지 않으면 barmode = 'group'을 추가한다
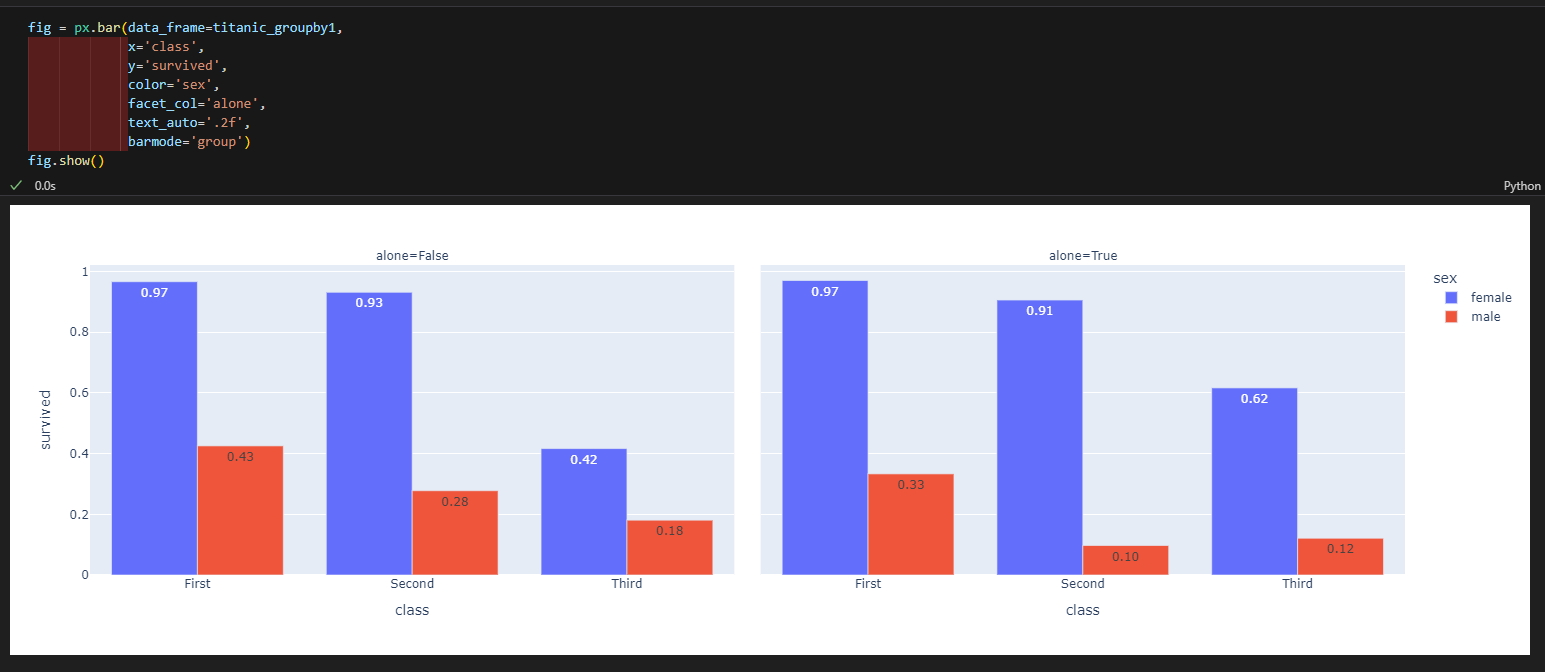
3.4.6. 히트맵
- px.imshow(데이터, text_auto=텍스트포맷, color_continuous_scale=컬러맵)
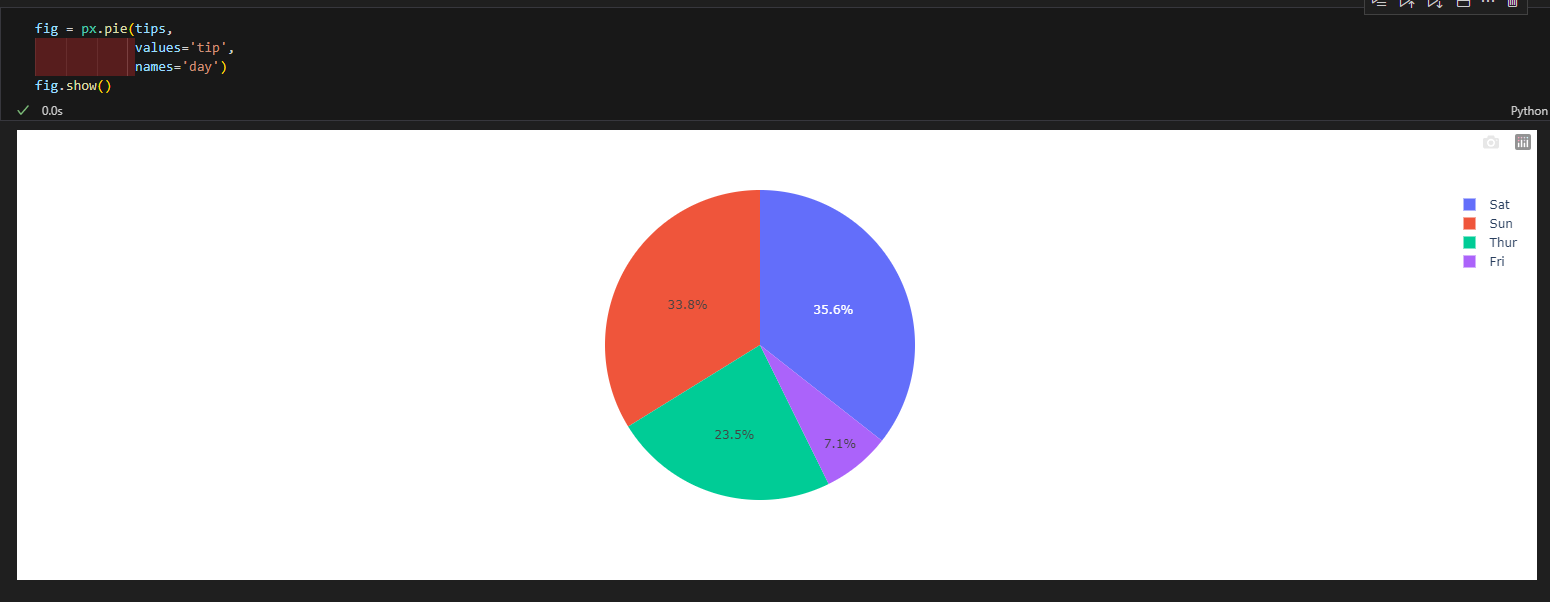
3.4.7. 파이차트
- px.pie(data_frame=데이터, values=값, names=라벨)
1.4. folium
4.2. 마커 추가하기
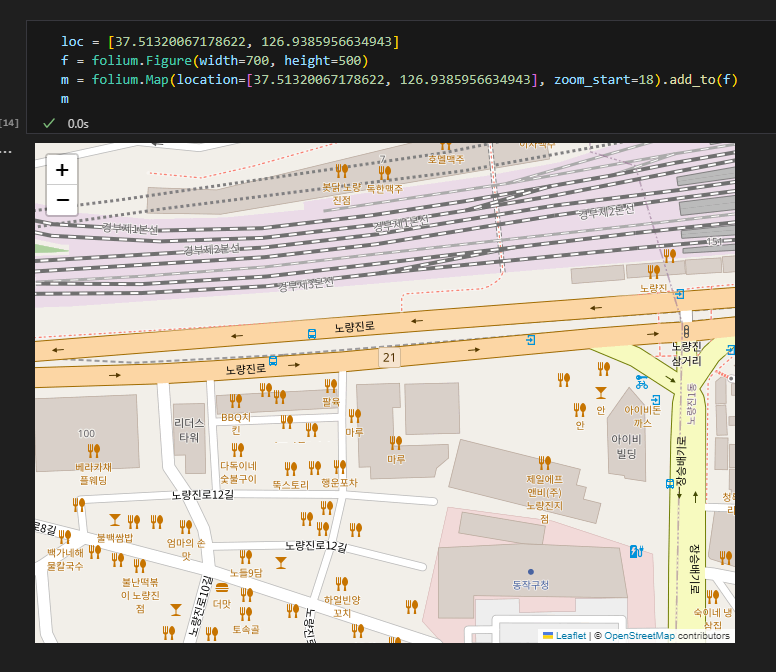
- 장소 표시 마커
folium.Marker([위도, 경도]
, tooltip=마우스 오버시 나타남
, popup=클릭시 나타남
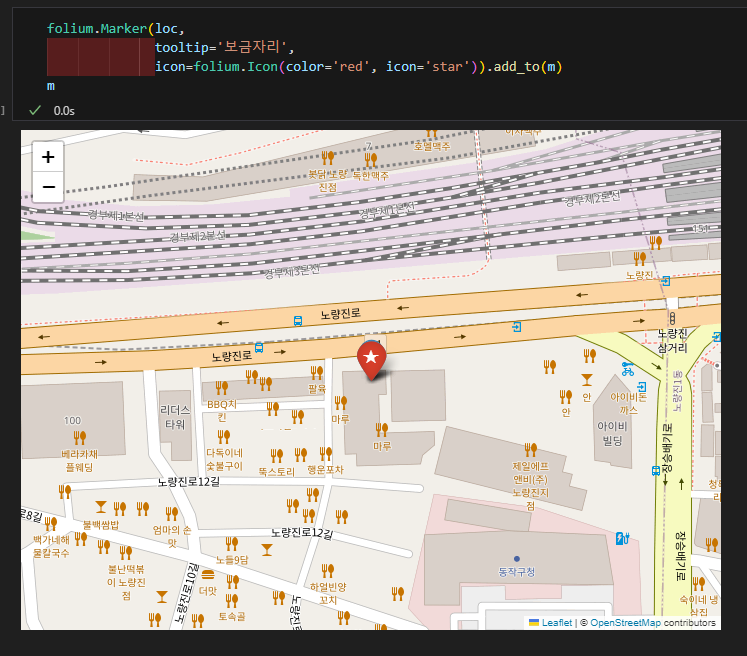
, icon=folium.Icon(color=색, icon=모양)).add_to(지도)- 원 형태 마커
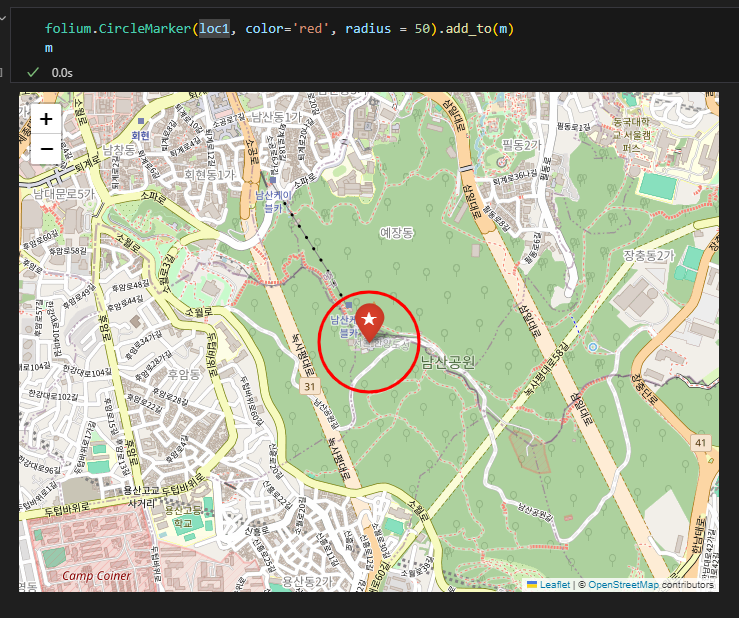
folium.CircleMarker([위도, 경도]
, radius=범위
, color=색).add_to(지도)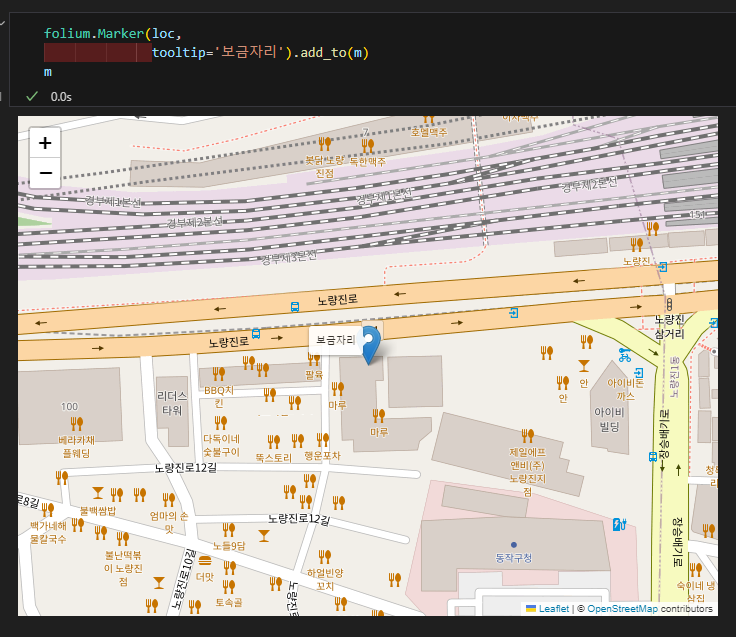
아이콘 변경
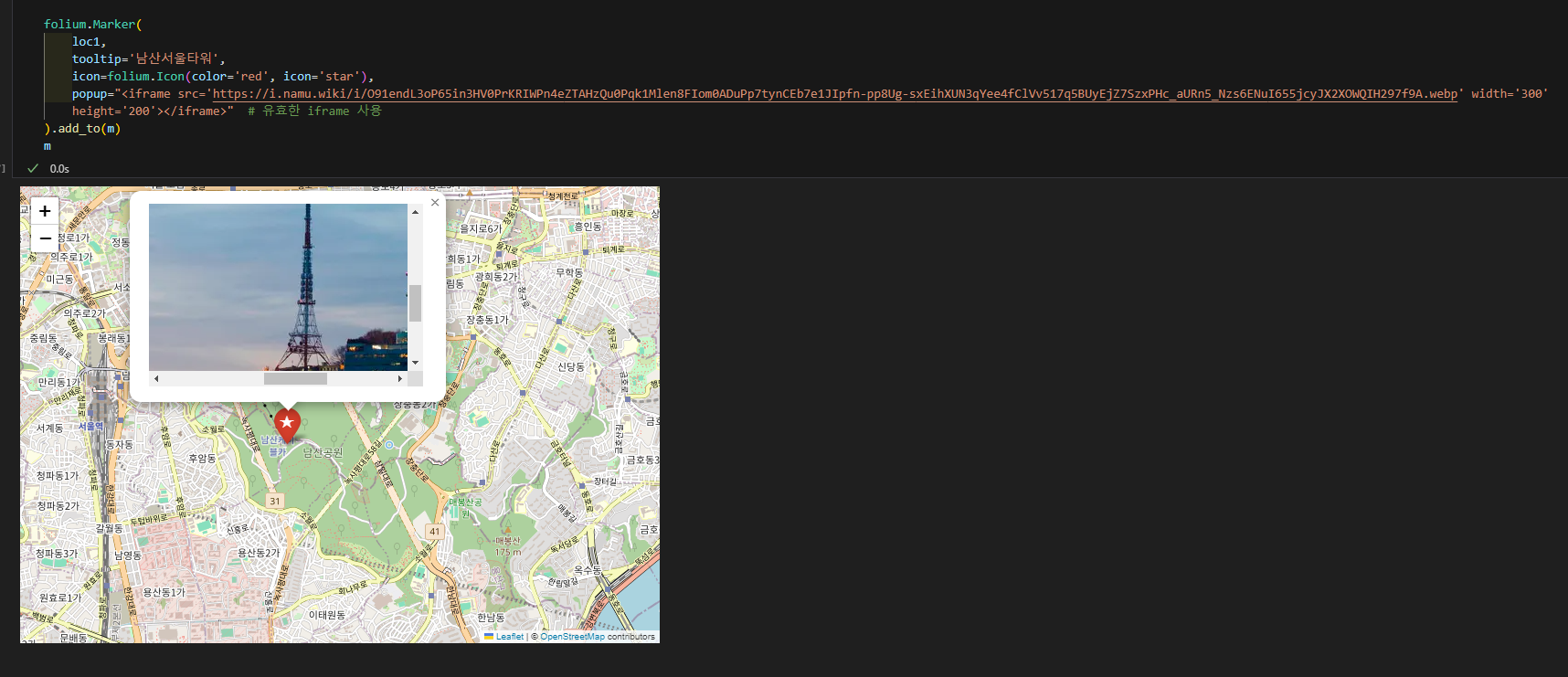
popup 속성으로 이미지 띄우기
원그리기
실습
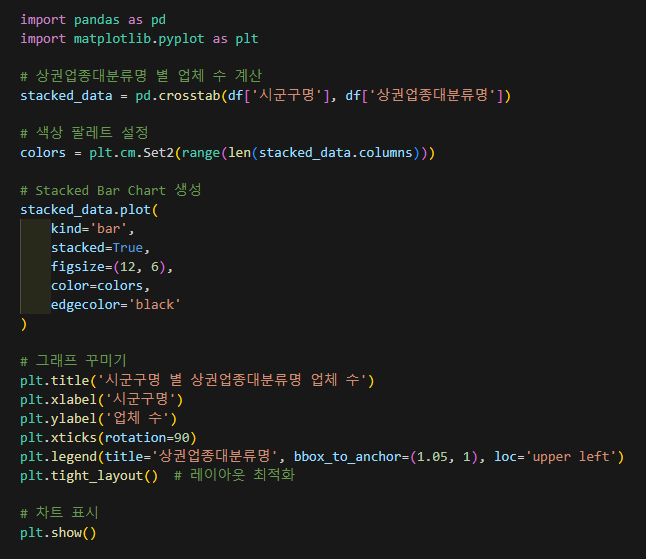
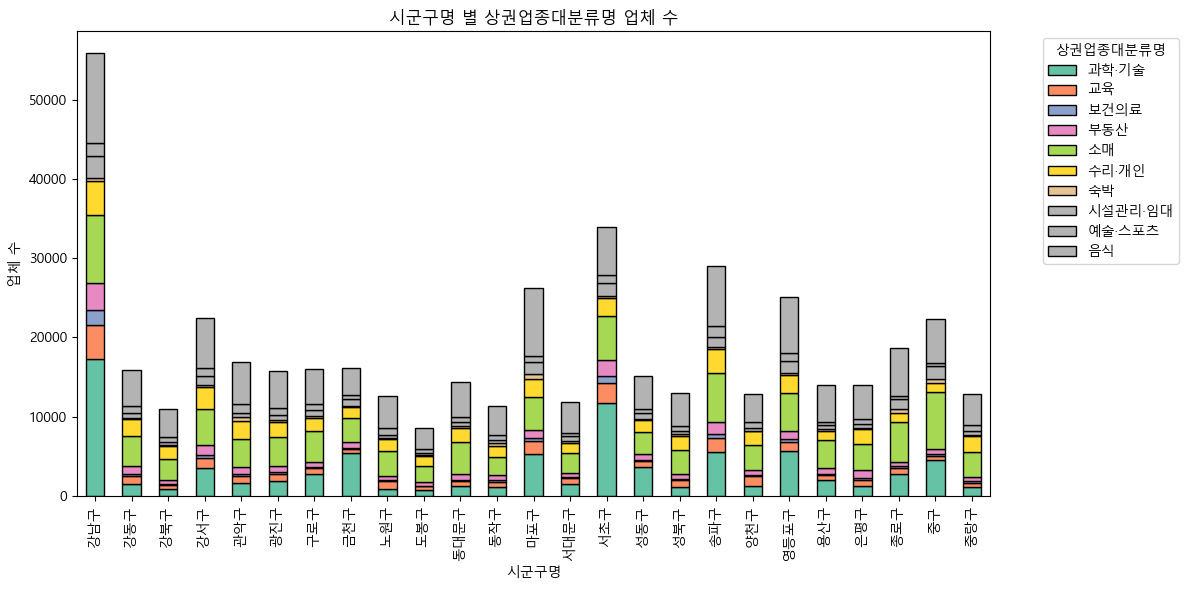
소상공인시장진흥공단_상가(상권)정보 : 서울시 분석해보기
전처리로 불필요한 열 제거한 데이터프레임
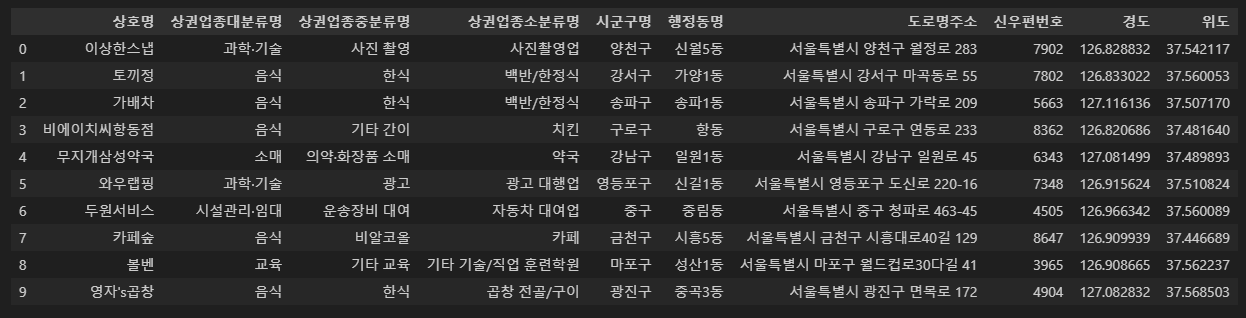
시각화에 한글폰트 적용

- 전체 상권업종대분류명 중에서 각 항목이 차지하는 비율 (pie)
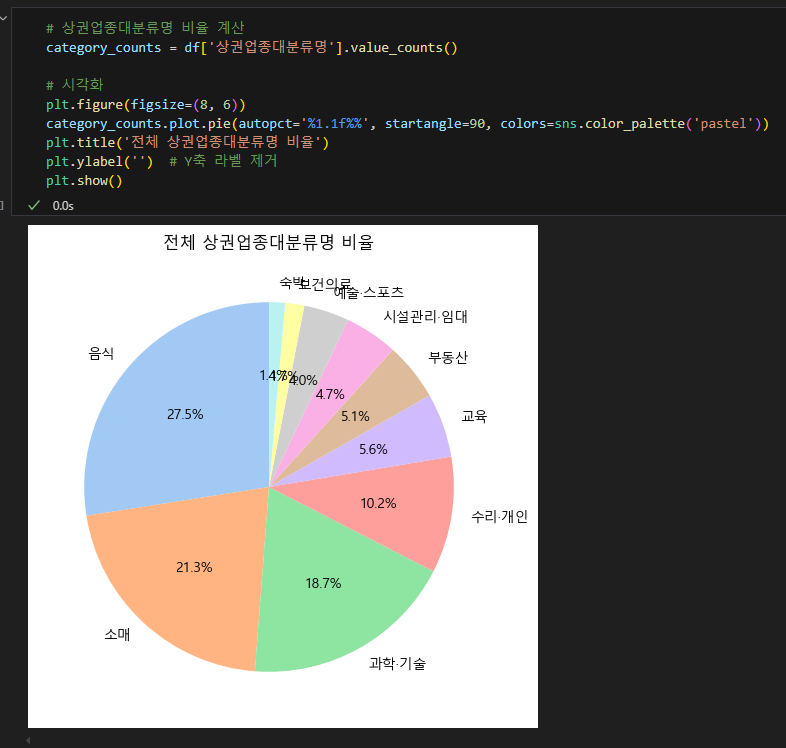
음식, 소매, 과학기술 업체가 많음.
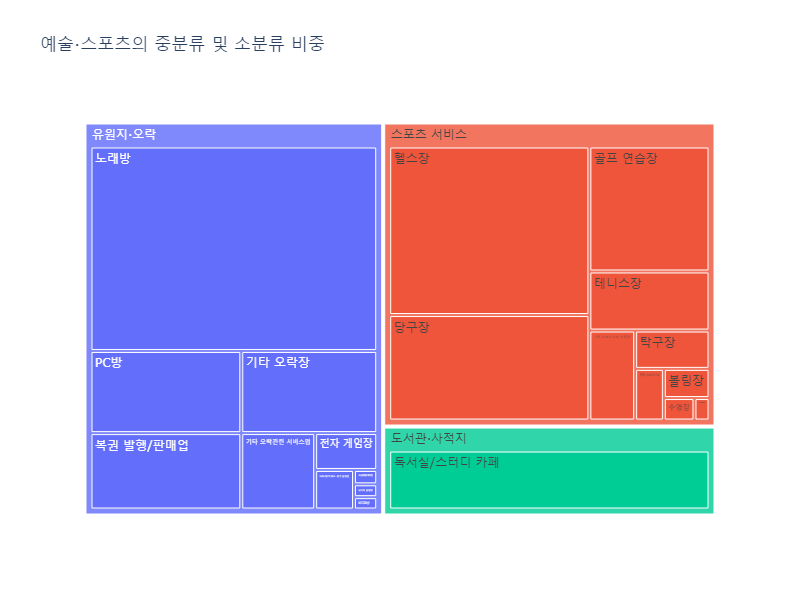
2. 상권업종대분류명 중에서 상권업종중분류명과 상권업종소분류명가 차지하는 하위 비중 (피벗테이블 사용)(Treemap)









- 시군구명 별 상권업종대분류명의 비율