KPMG Future Academy AI 활용 데이터 분석가 3기 36일차 수업을 2025년 1월 8일에 참석했다.
- 데이터 분석
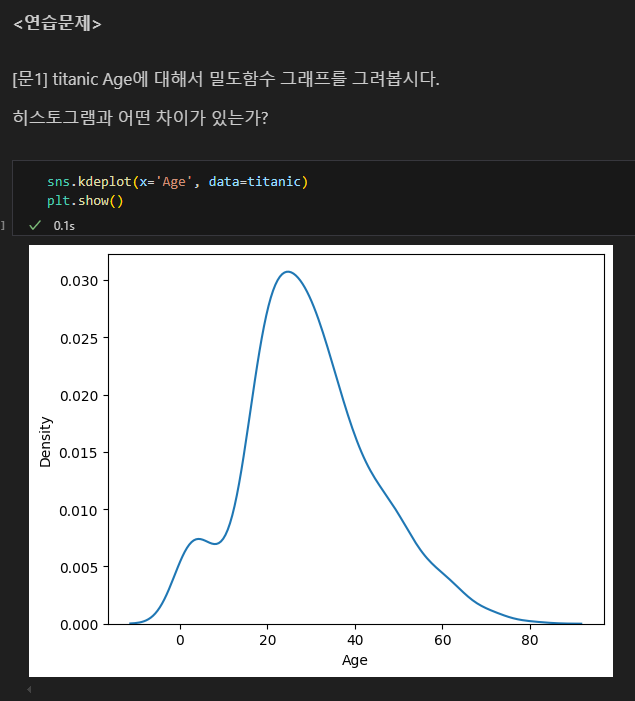
1.1. 단변량 분석 : 숫자형
1.2. 단변량 분석 : 범주형
1. 데이터 분석
1.1. 단변량 분석 : 숫자형
통계량에서 평균을 참조할 때 중앙값(median)과 최빈값(mode)을 함께 고려해야함.
평균의 함정에 대한 경각심을 위해 동영상을 시청했다. 통계를 참조할 때 이상치로 인해 평균값이 신뢰하기 어려워지는 수리적인 상식에 대한 내용이었다.
서도호, High School Uni-face: Boy, 1997
서도호, High School Uni-face: Girl, 1997

흑백 고등학생 사진을 합성한 작품.
위 작품의 합성 원리가 궁금하여 Claude 3.0에게 기술적인 부분을 물어보았다.

부족한 데이터에 대한 답변


dlib :
landmark points :
warp :
삼각형 메쉬 :
마스킹 및 블렌딩 :
알파 블렌딩 :
edge-aware 블렌딩 :
KNN 기반 imputation :
격자 기반 보간법 :
cubic interpolation :
가중 평균과 표준편차를 사용한 이상치 검출 :
z-score 기반 비정상적인 데이터 필터링 :
GAN :
다중 해상도 분석 :
텍스처 합성 알고리즘 적용 :
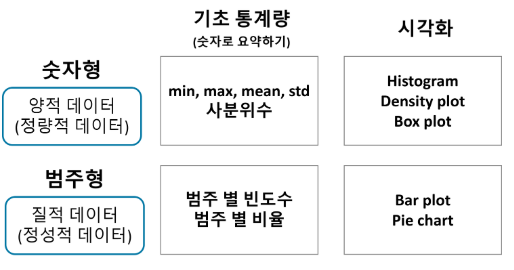
1) 평균(산술평균)
- 데이터를 모두 더한 뒤, 데이터의 개수로 나눈 값
- 데이터를 대표하는 중심 경향성(central tendency)을 나타냄
- 이상치에 매우 민감함
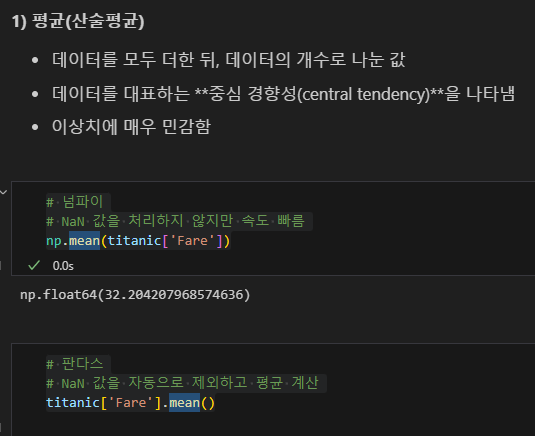
2) 중앙값(중위수, median)
- 데이터를 크기 순으로 정렬했을 때, 가운데에 위치한 값
- 데이터의 개수가 홀수이면 가운데 값이 중앙값
- 데이터의 개수가 짝수이면 가운데 두 값의 평균이 중앙값
- 이상치에 거의 영향을 받지 않음
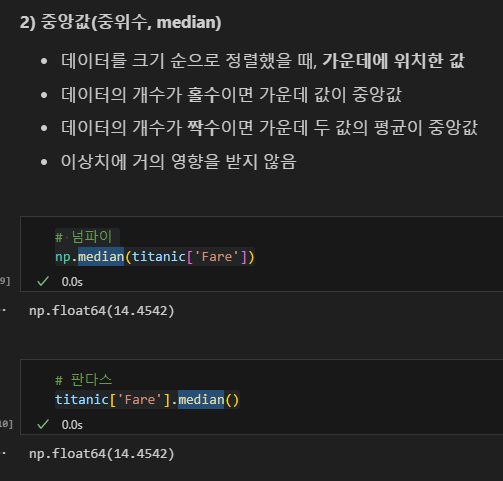
3) 최빈값
- 데이터셋에서 가장 자주 등장하는 값(빈도가 높은 값)
- 최빈값은 하나일 수도 있고, 여러 개일 수도 있음
- 이산형 데이터(셀 수 있는 데이터)
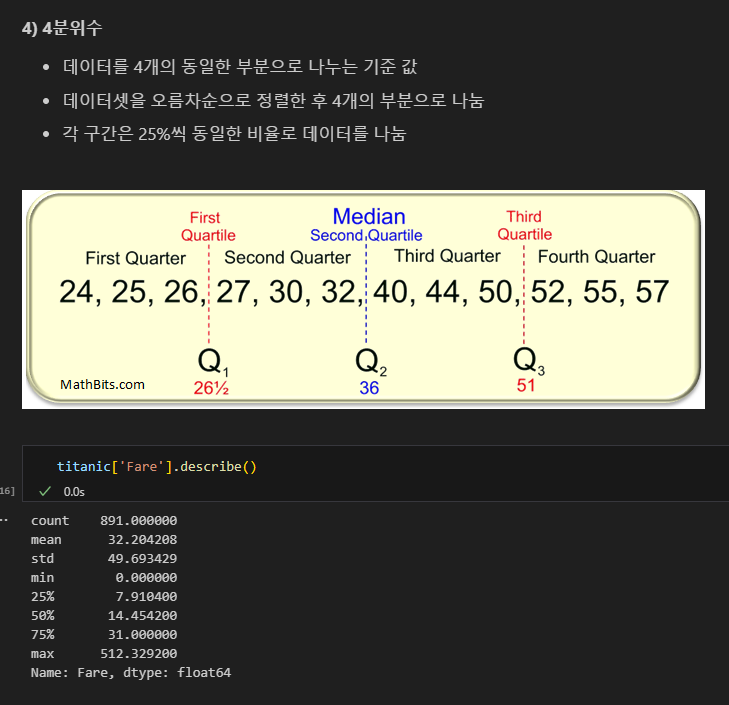
4) 4분위수
- 데이터를 4개의 동일한 부분으로 나누는 기준 값
- 데이터셋을 오름차순으로 정렬한 후 4개의 부분으로 나눔
- 각 구간은 25%씩 동일한 비율로 데이터를 나눔
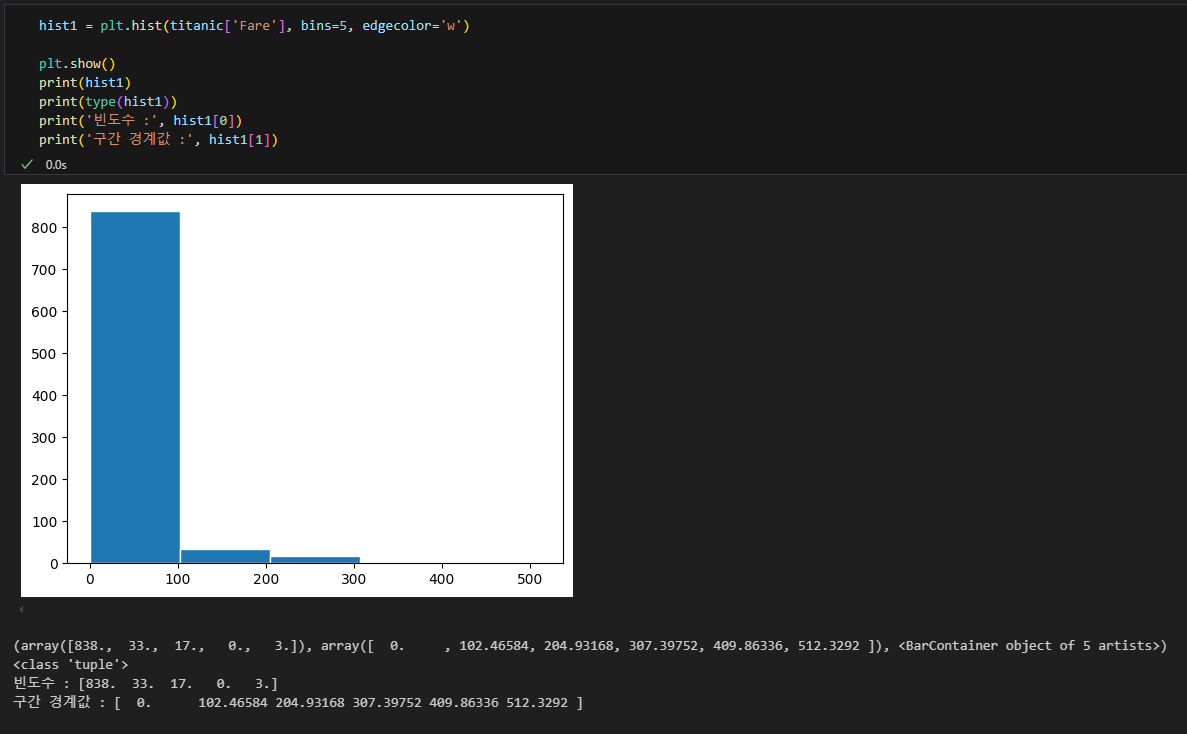
describe()
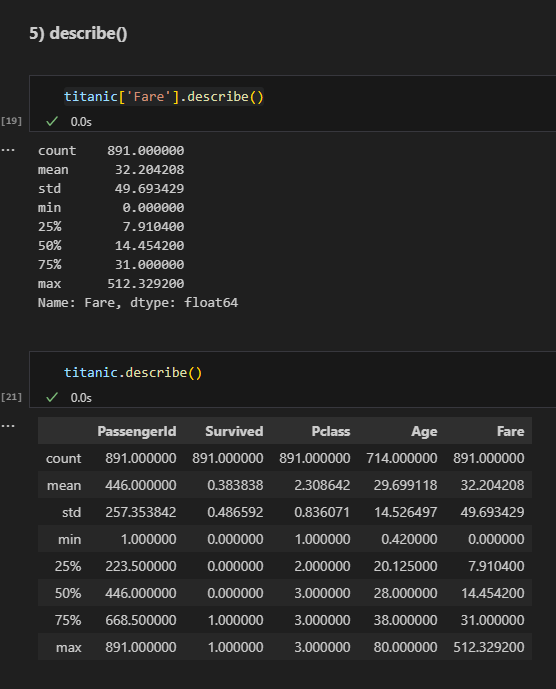
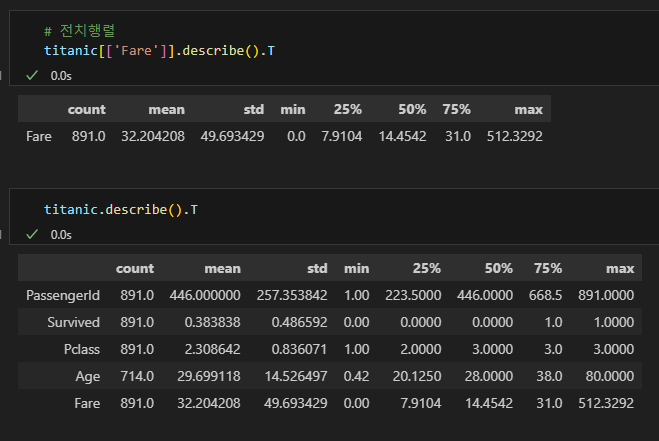
전치 행렬
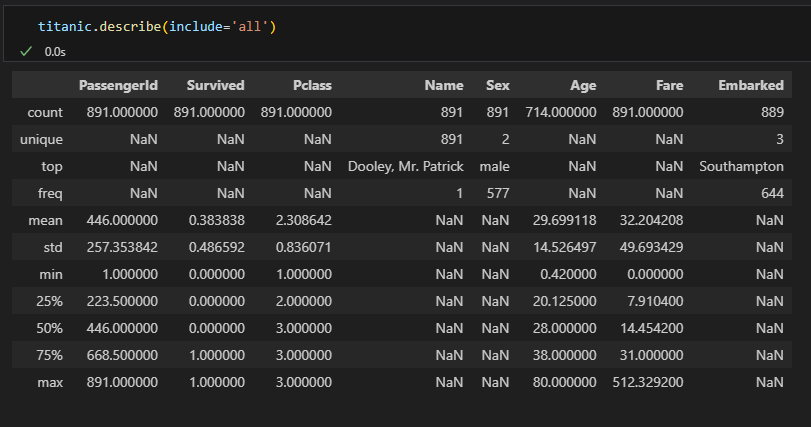
include= 속성
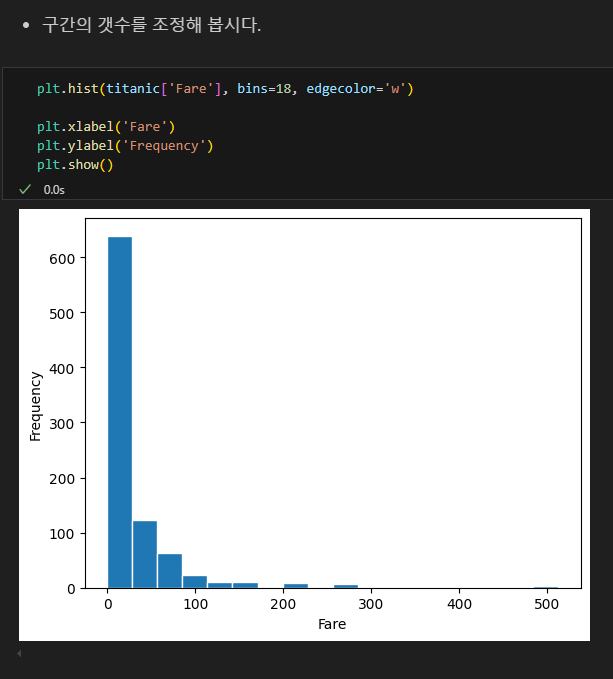
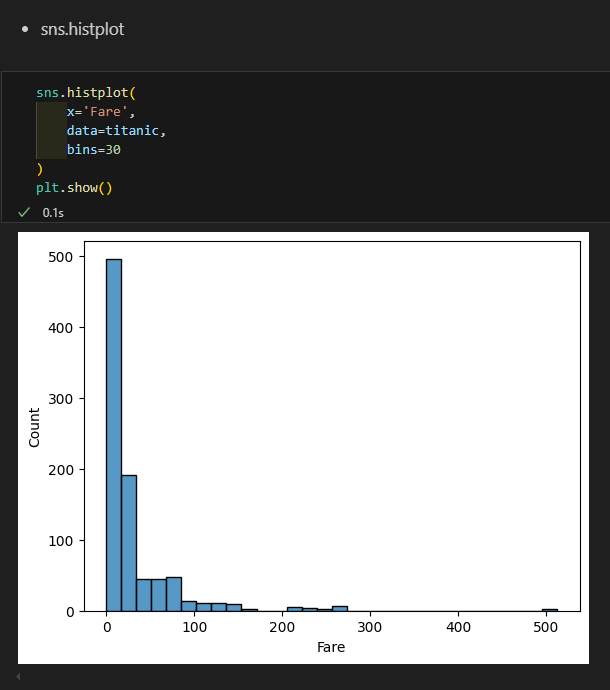
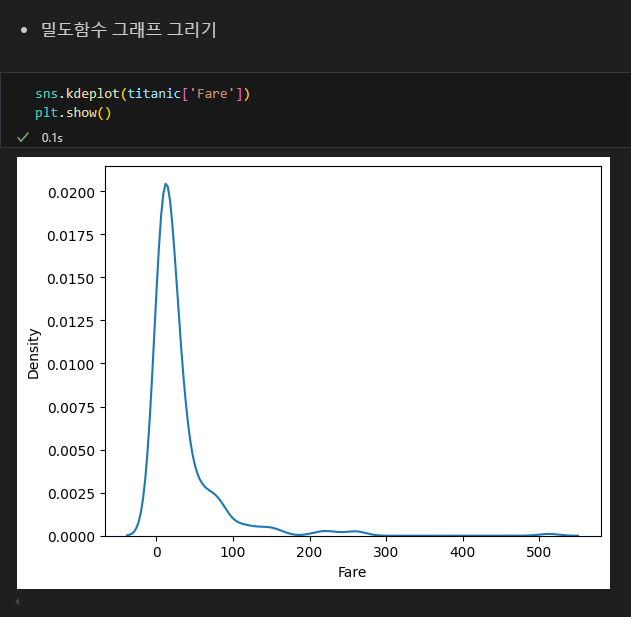
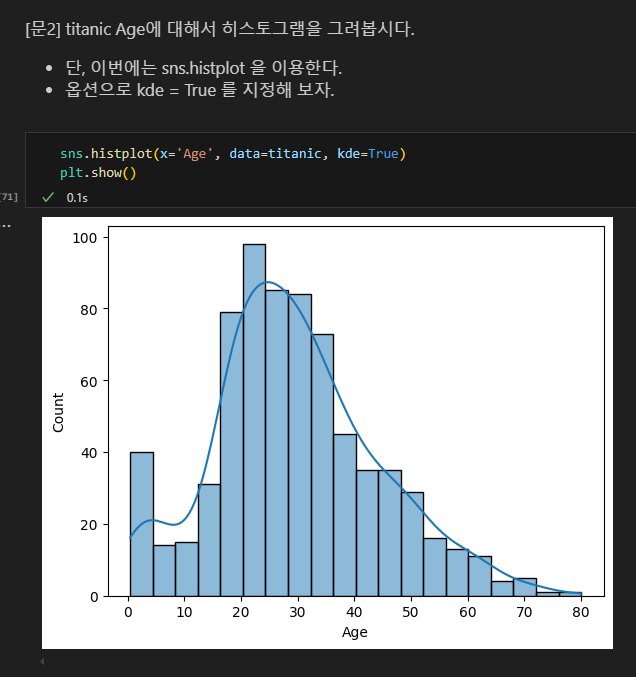
히스토그램
seaborn 히스토그램
밀도함수 그래프 kde
-
히스토그램의 단점
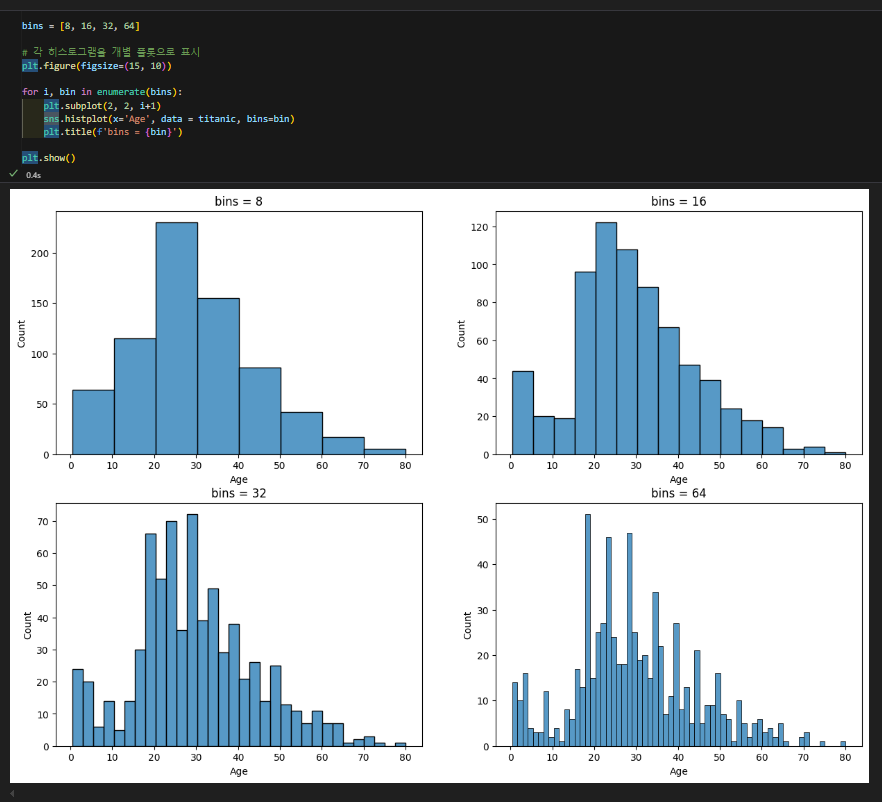
- 구간(bin)의 너비를 어떻게 잡는지에 따라 전혀 다른 모양이 될 수 있음
-
밀도함수 그래프
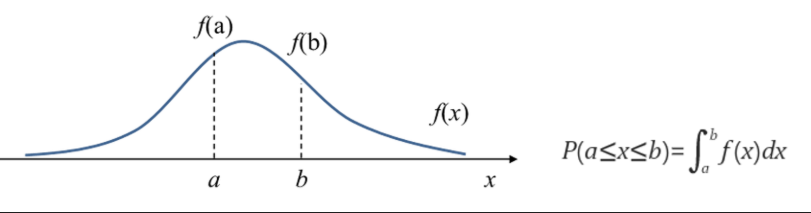
- 막대의 너비를 가정하지 않고 모든 점에서 데이터의 밀도를 추정하는 커널 밀도 추정(Kernel Density Estimation)방식을 사용하여 이러한 단점을 해결.
- 밀도함수 그래프 아래 면적은 1
밀도 추정
- 밀도 추정
- 측정된(관측된) 데이터로부터 전체 데이터 분포의 특성을 추정
- 예를 들어... 한 웹사이트의 일일 방문자수를 측정한다고 해 보자.
- 어제는 1200명이 방문했고, 오늘은 1620명, 내일은, 모레는...
- 이렇게 6개월간 매일 측정했다고 할 때,
- 우리는 약 180일치의 데이터를 가지고 일일 방문자 수 분포를 히스토그램으로 그려볼 수 있다.
- 그리고 나서 특정한 날의 방문자수가 얼마나 될지 확률로 나타냄
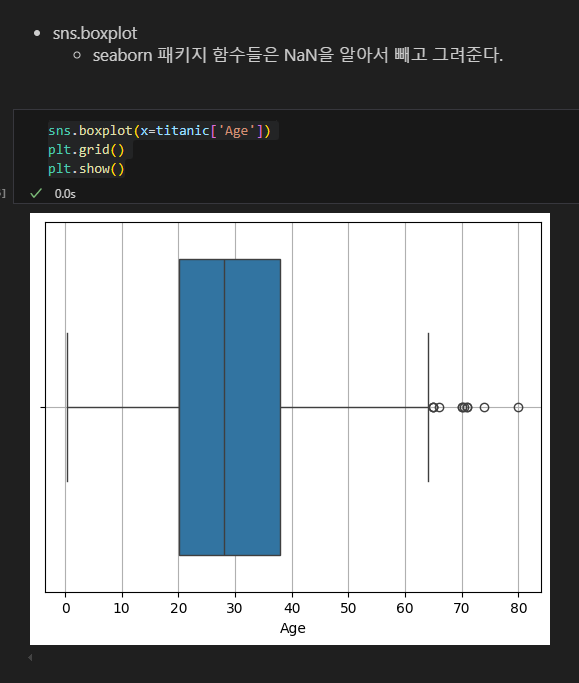
박스 플롯
NaN이 있으면 그려지지 않음
seaborn은 그려줌
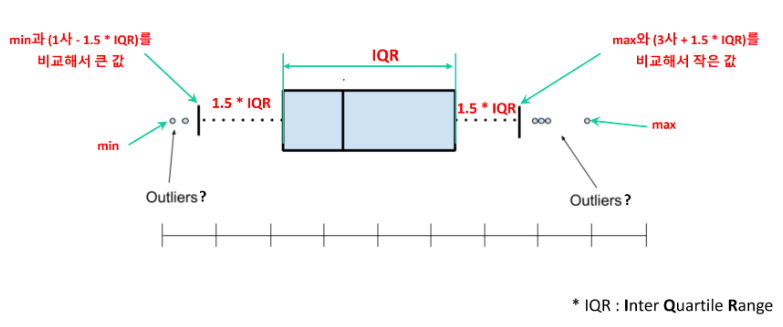
박스 플롯의 값 구하기
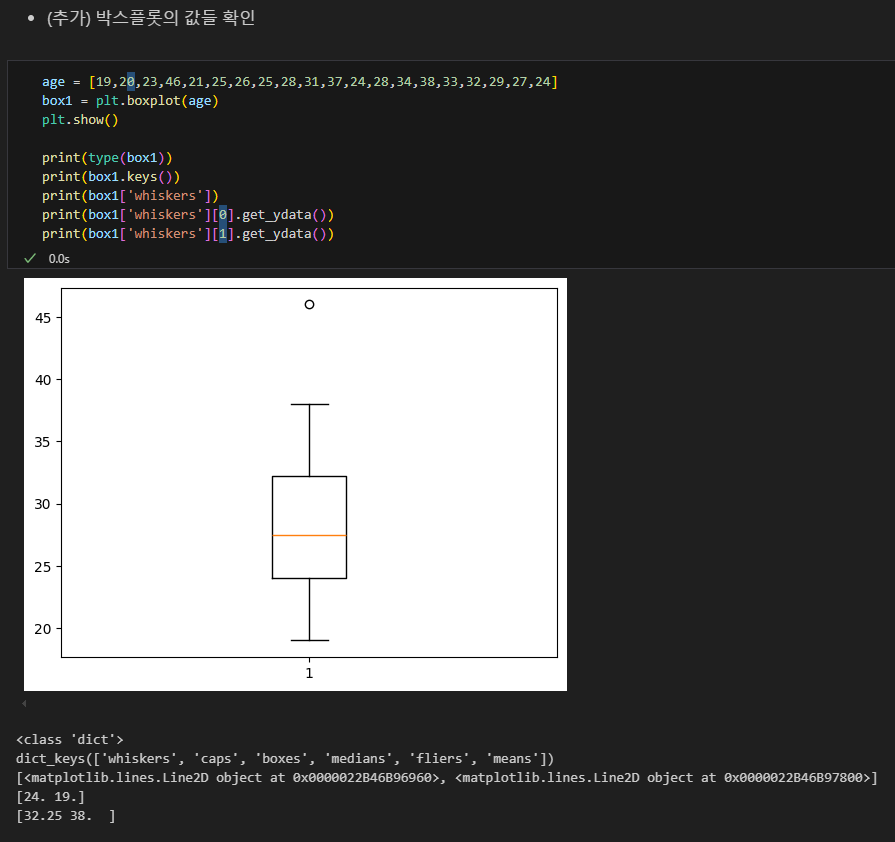
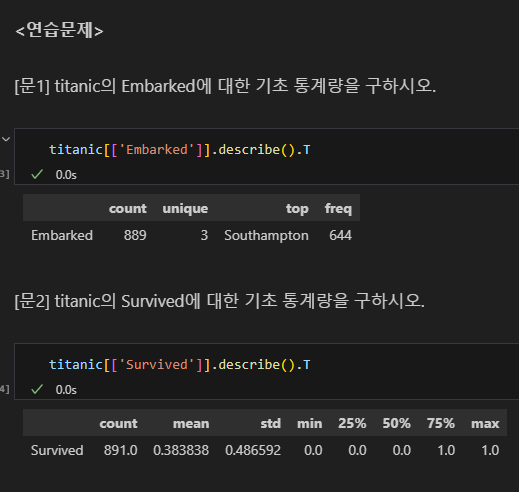
연습
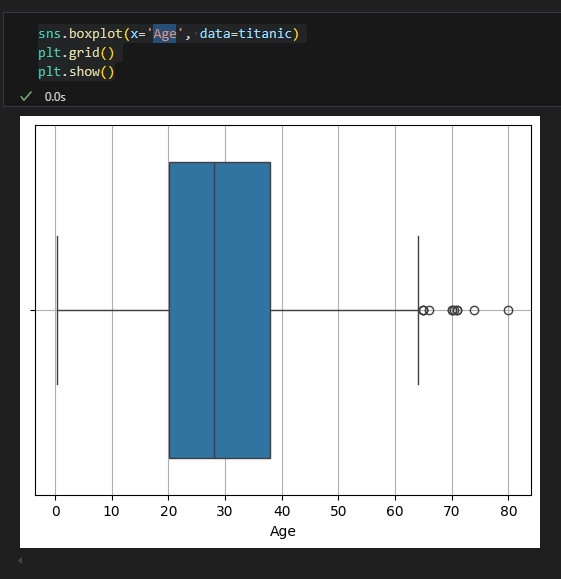
50%가 20-40대
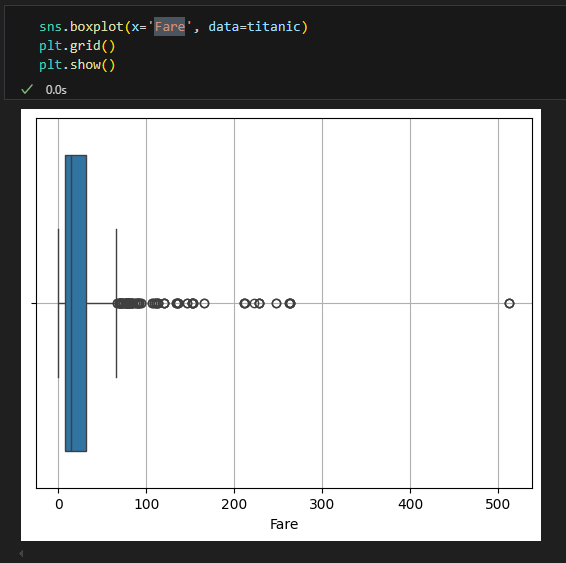
$500 극단적인 이상치
시계열 데이터 시각화
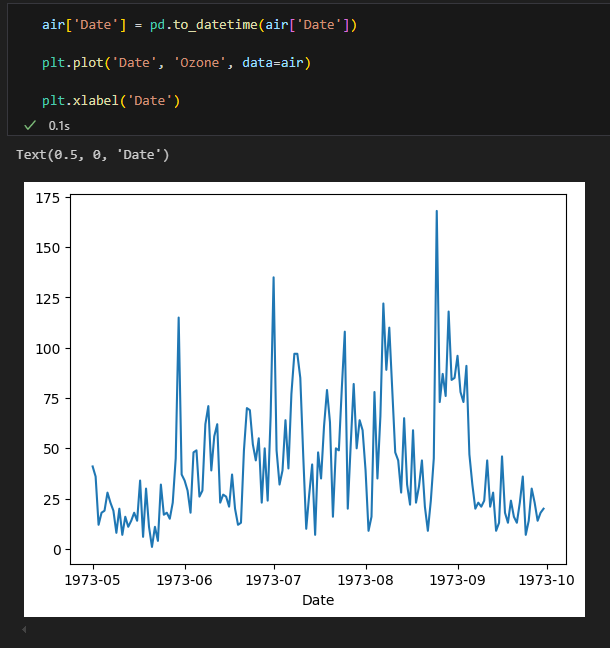
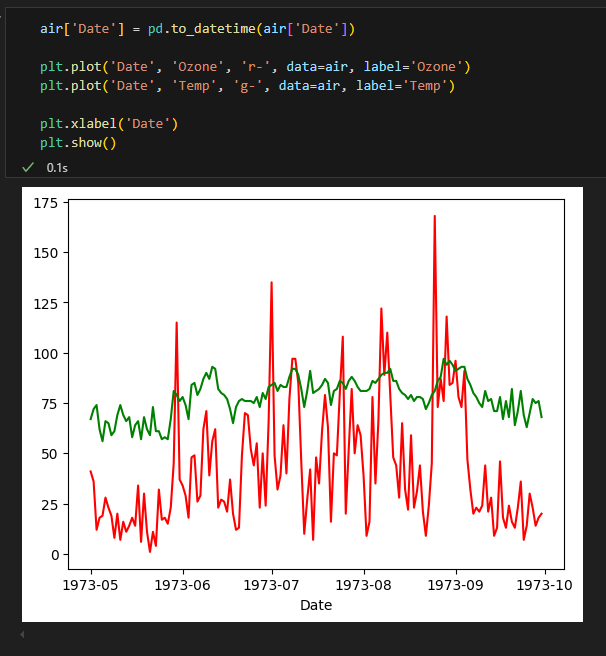
1.2. 단변량 분석 : 범주형
- 범주형 변수는 범주별 빈도수와 비율을 확인한다.
- 리스트.count(‘값’)
- 해당 값이 몇 개 있는지 count 한다.
- Count를 전체 개수(len(gender))로 나눠주면 비율이 된다.
- 그런데, 범주가 두 세 개 정도면, 이렇게 계산하는 게 가능하다.
- 하지만, 만약 범주가 20개라면?
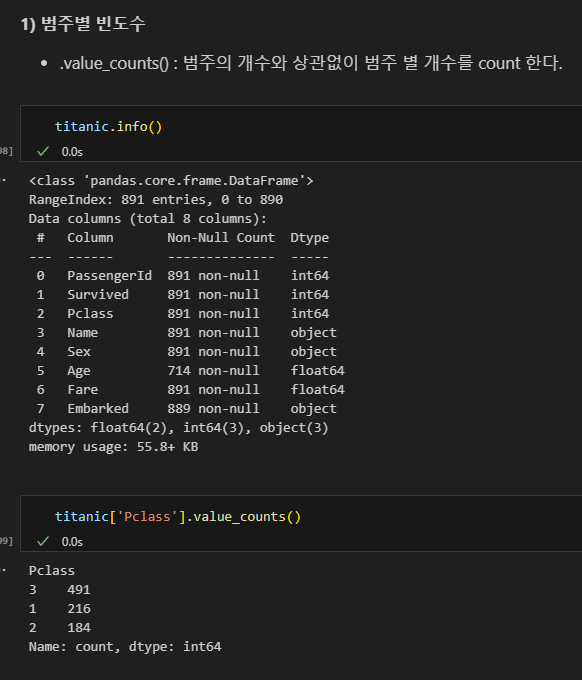
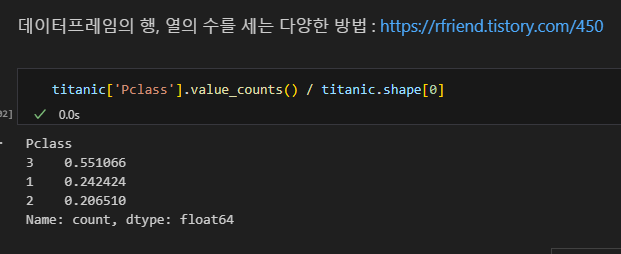
기초 통계량
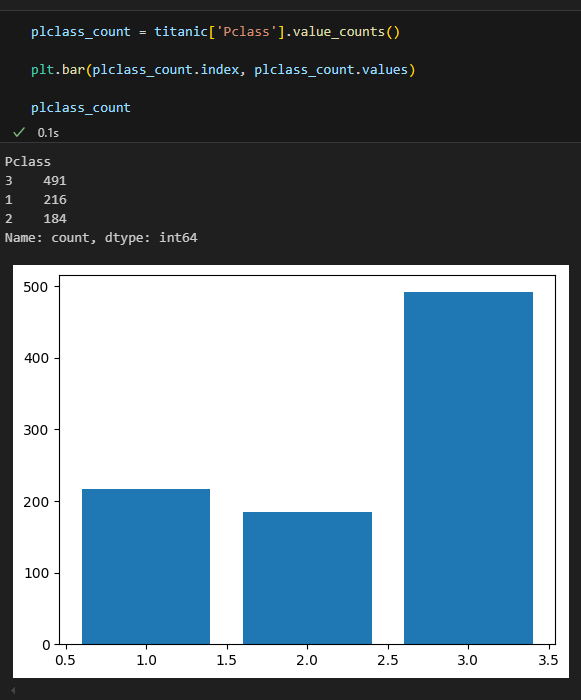
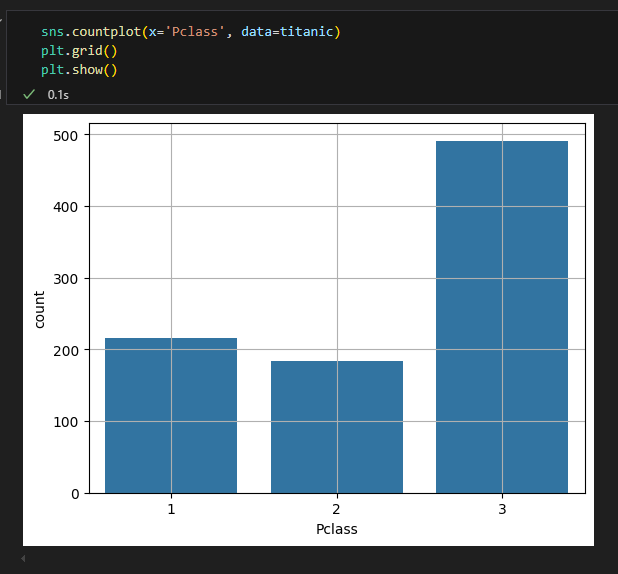
seaborn countplot
- seaborn의 countplot
- plt.bar() 를 이용하려면 먼저 집계한 후 결과를 가지고 그래프를 그려야 한다.
- countplot은 집계 + bar plot을 한꺼번에 해결해준다.
비교
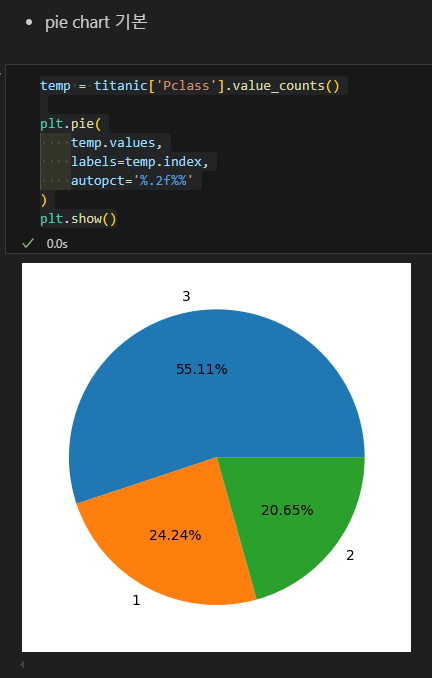
파이 차트
- 범주별 비율 비교할 때 파이차트 사용
- 역시 먼저 집계를 해야 한다.
- plt.pie( 값, labels=범주이름, autopct = ‘%.2f%%’)
- autopct = ‘%.2f%%’ : 그래프에 표시할 값 비율 값에 대한 설정이다.
- .2f% : 소수점 두 자리 퍼센트로 표기 한다는 의미
- autopct = ‘%.2f%%’ : 그래프에 표시할 값 비율 값에 대한 설정이다.
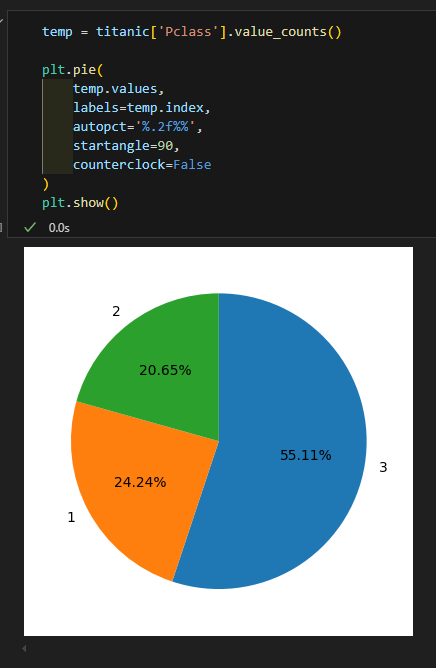
- pie chart 꾸미기 1
- 각도와 방향 조정
- startangle = 90 : 90도 부터 시작
- counterclock = False : 시계 방향으로
- 각도와 방향 조정
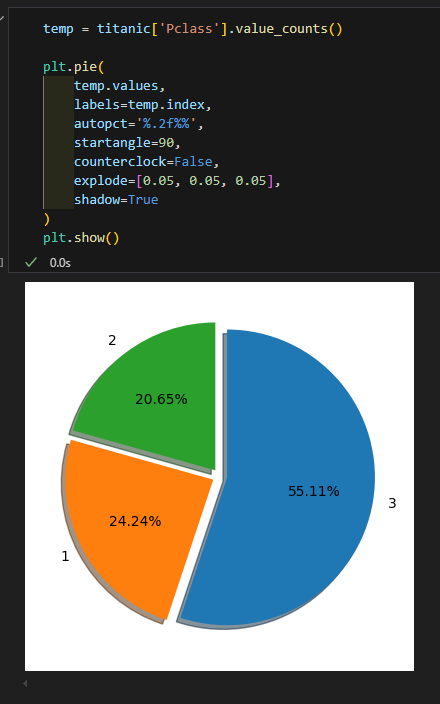
- pie chart 꾸미기 2
- 간격 띄우고, 그림자 넣기
- explode = [0.05, 0.05,0.05] : 중심으로 부터 1,2,3 을 얼마만큼 띄울지
- shadow = True : 그림자 추가
- 간격 띄우고, 그림자 넣기
종합 연습
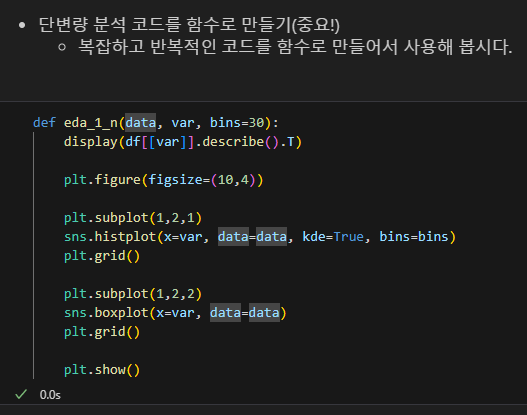
함수로 통계량 확인 및 시각화 만들기
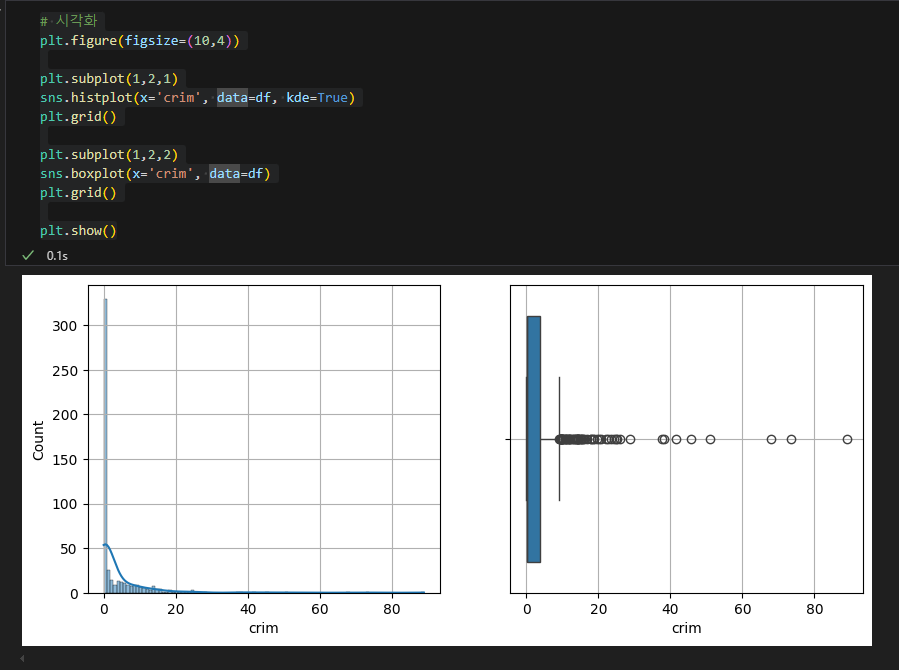
극단적으로 높은 범죄율 등 분포상 이상치를 확인
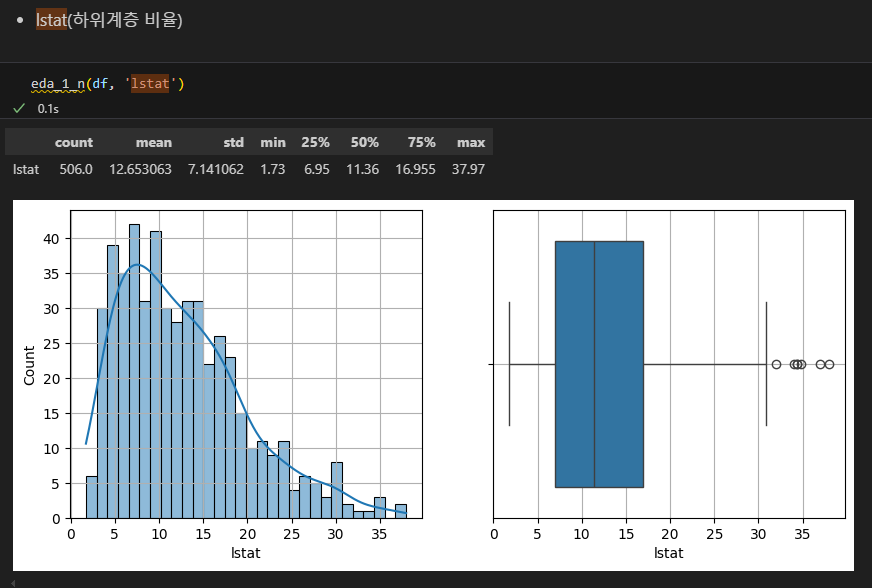
많은 지역에서 저소득층의 비율이 높음. 일부 지역에서 저소득층 비율이 높은 이상치.
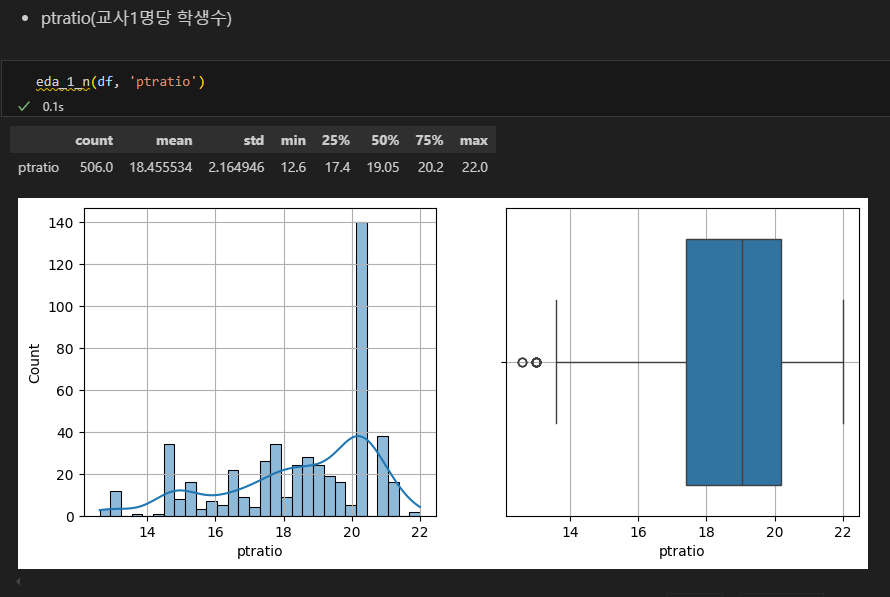
특정 값에 몰려있고, 분포가 넓고 중위값이 낮음.
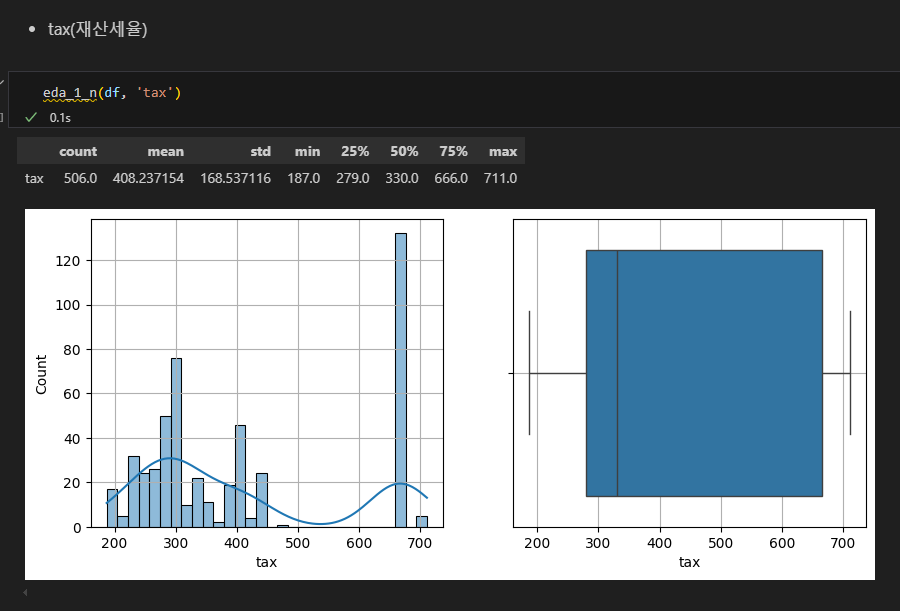
- 단변량 분석 코드를 함수로 만들기(중요!)
- 복잡하고 반복적인 코드를 함수로 만들어서 사용해 봅시다.
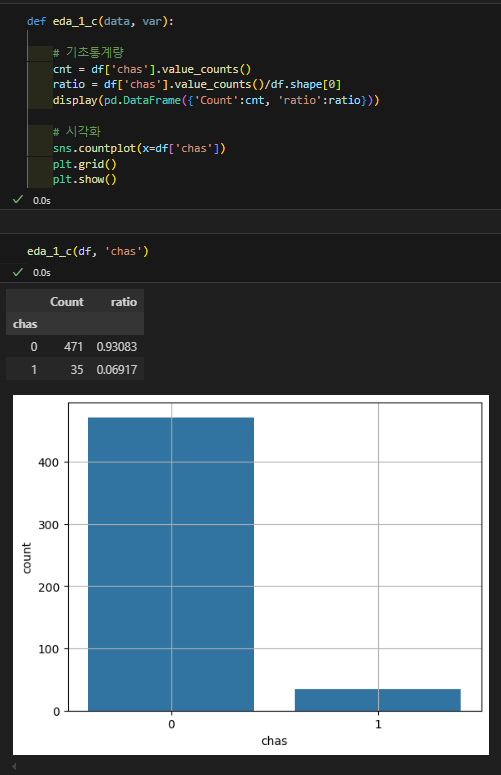
실습
-
고객사는 카시트 전문 판매 회사입니다.
-
최근, 매출 그래프가 조금씩 아래로 향하기 시작했습니다. 회사의 여러 부서에서는 다양한 원인을 제시했지만, 그 원인들이 정말 데이터에 기반한 것인지는 여전히 의문입니다.
-
부서별 문제 진단:
- 가격 경쟁력 약화: 경쟁사와의 가격 경쟁에서 밀리고 있음
- 광고비 집행 비효율: 광고비는 쓰고 있지만, 정말 적절하게 집행되지 않음
- 국내 시장 편중: 해외 시장 개척은 뒷전이고, 국내 시장에만 집중됨
- 지역 구매력 미파악: 지역별 구매력과 특성을 제대로 분석하지 못하고 있음
-
-
이 문제를 해결하기 위해 DX 프로젝트 팀이 빌딩되었습니다.
- 여러분은 이 팀에서 데이터 분석을 책임지는 DX 컨설턴트로 합류했습니다.
- 드디어 갈고 닦은 실력을 발휘할 기회가 주어졌습니다.
- 자, 이제 단변량 분석을 통해 비즈니스 인사이트를 도출해 봅시다!
- 반복되는 코드는 함수로 만듭시다!
- 함수를 만드는 순서
- 먼저 절차대로 코드를 작성해서 실행한다.
- 실행된 코드(오류가 없는 코드)를 가져다 함수로 구성한다.
- 입력과 출력 결정
- 함수를 만드는 순서
카시트 판매 데이터 분석
1. 매장이 미국에 있는지 여부와 판매량의 유관도
1-1. 미국/비미국 매장의 평균 판매량 비교
2. 매장이 도심 지역에 있는지 여부와 판매량의 유관도
2-1. ShelveLoc(진열 위치)와 함께 크로스 분석
3. 가격에 따른 판매량 유관도
3-1.CompPrice(경쟁사 가격)와 함께 분석하여 가격 경쟁력 파악
3-2.Price/CompPrice 비율을 만들어 분석
4. 인구수별 판매지수
6. 소득수준과 판매지수 유관도
소득수준 대비 판매량
7. 여러 변수의 상관관계를 한번에 보는 상관계수 행렬 분석
8. ROI와 가격의 상관관계
9. Advertising(광고)과 판매량의 관계
10. ROI와 연령의 유관도
10-1. 판매량과 연령 유관도
-
매장이 미국에 있는지 여부와 판매량의 유관도
1-1. 미국/비미국 매장의 평균 판매량 비교
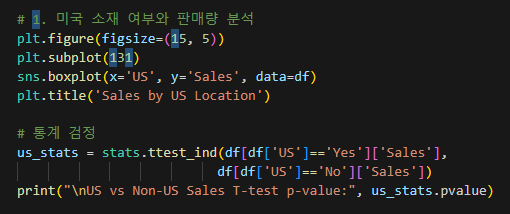
-
매장이 도심 지역에 있는지 여부와 판매량의 유관도
2-1. ShelveLoc(진열 위치)와 함께 크로스 분석
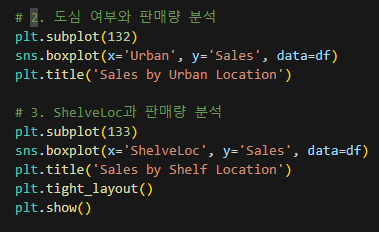
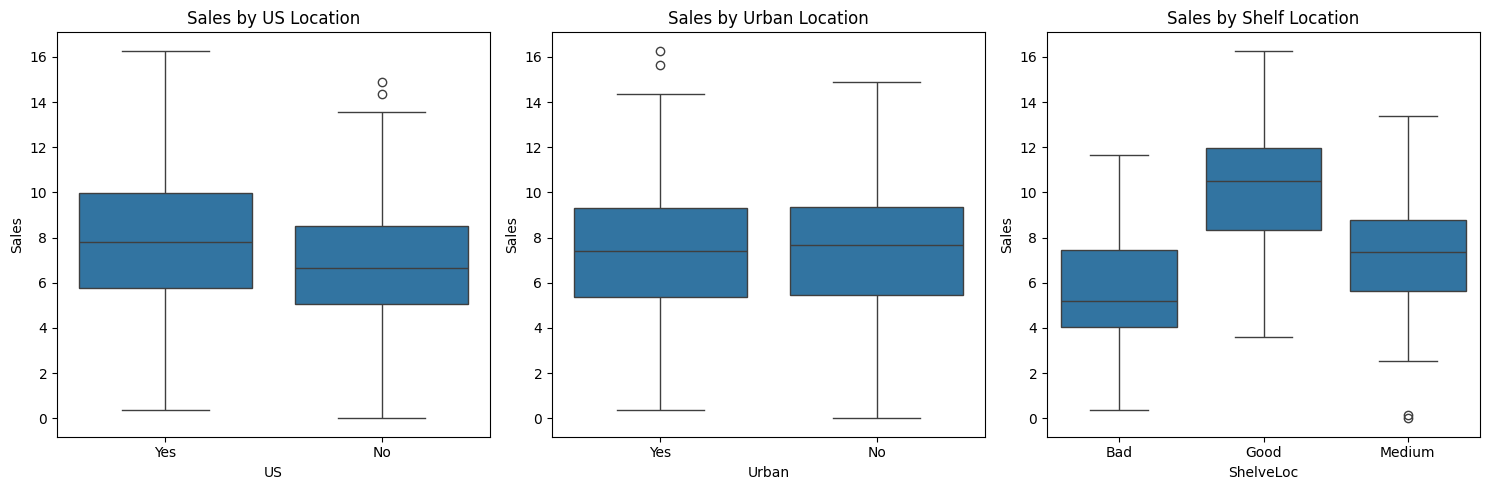
- 미국 내 매장이 평균적으로 더 높은 판매량을 보임.
- 도심과 비도심 간의 판매량 차이가 크지 않음.
- 'Good' 진열 위치가 확연히 높은 판매량을 보임.
- 가격에 따른 판매량 유관도
3-1.CompPrice(경쟁사 가격)와 함께 분석하여 가격 경쟁력 파악
3-2.Price/CompPrice 비율을 만들어 분석
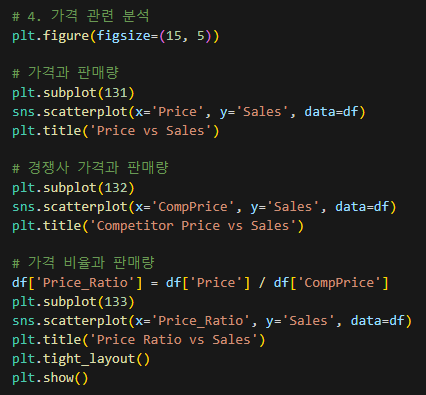
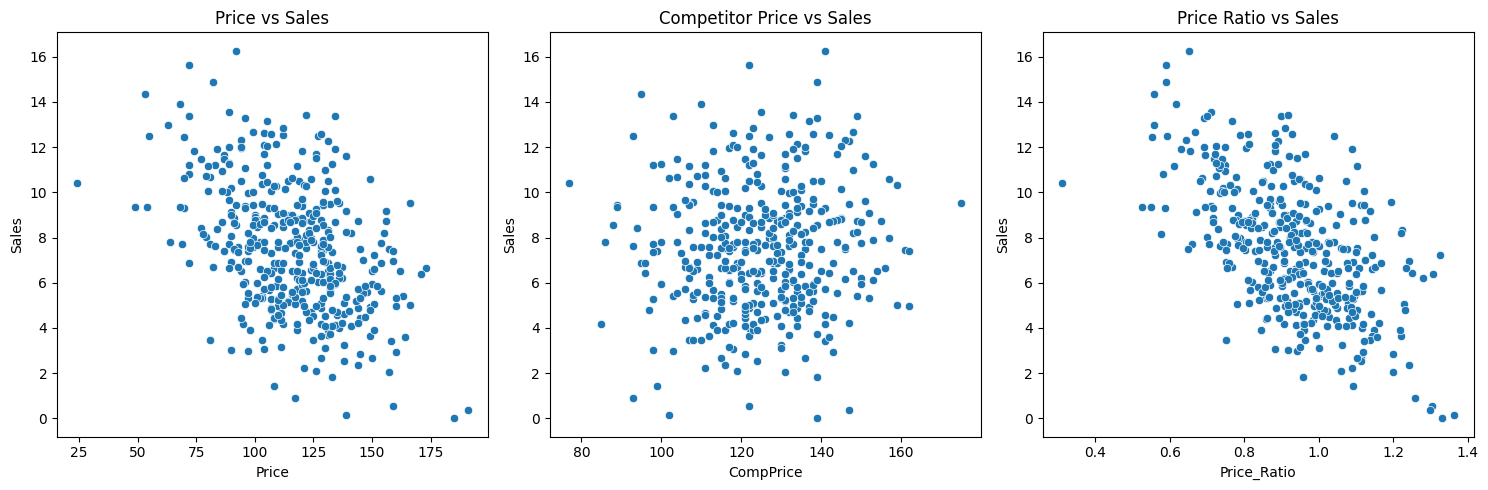
- 가격과 판매량은 음의 상관관계를 보임.
- 경쟁사 대비 가격 비율이 낮을수록 판매량이 증가하는 경향이 있음.
- 인구수별 판매지수
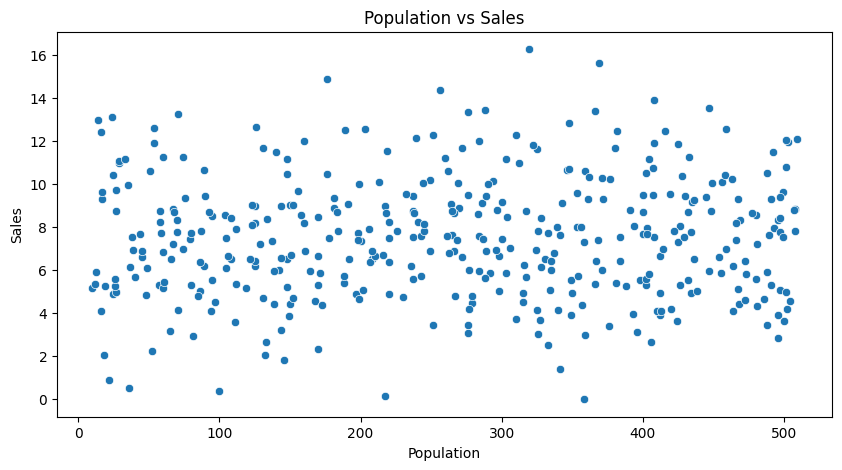
- 약한 양의 상관관계가 있음.
- 하지만 인구수가 많다고 반드시 판매량이 높지는 않음.
- 소득수준과 판매지수 유관도
소득수준 대비 ROI
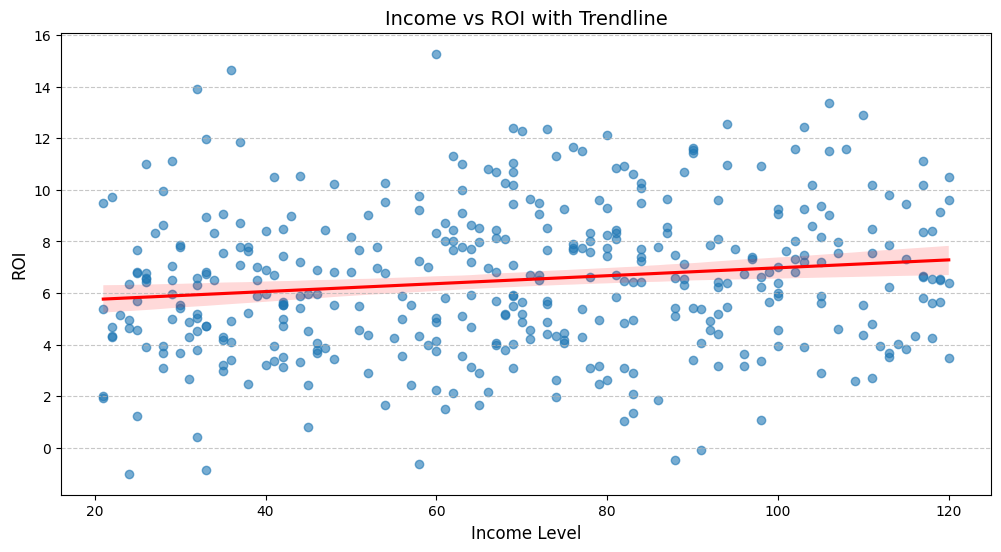
- 양의 상관관계
- 여러 변수의 상관관계를 한번에 보는 상관계수 행렬 분석
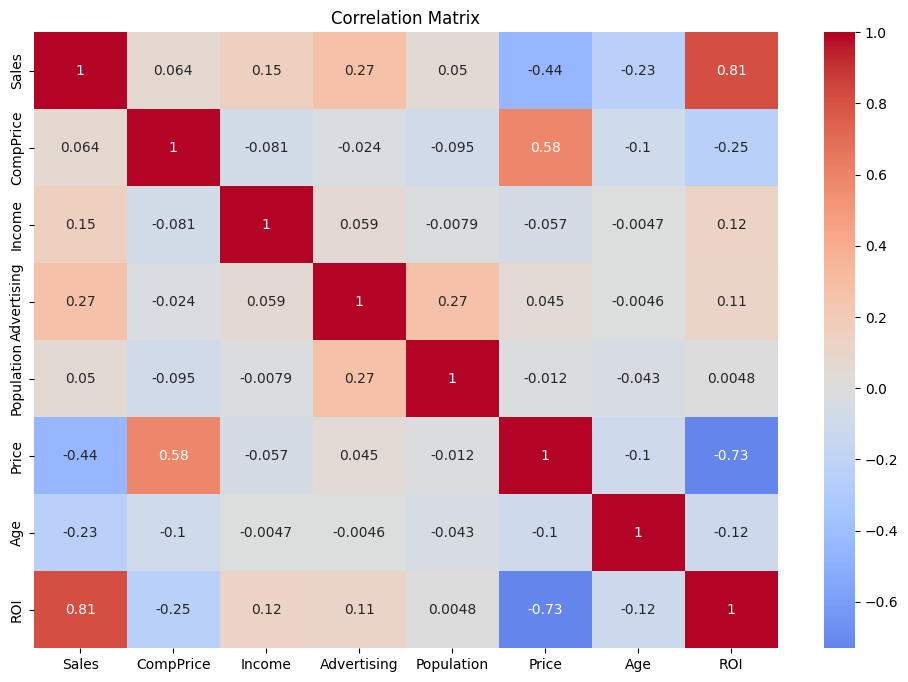
- ROI는 가격과 강한 음의 상관관계
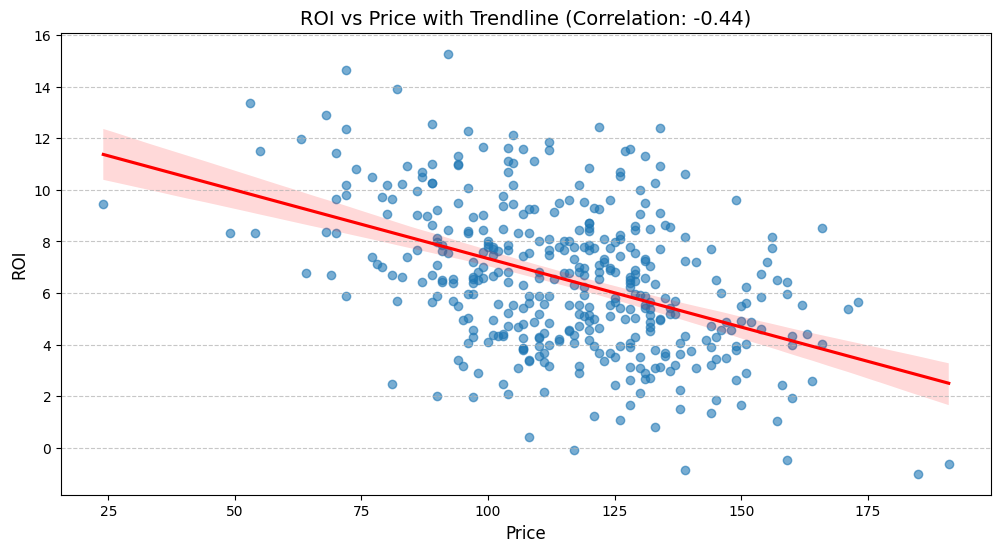
- ROI와 가격의 상관관계
- 강한 양의 상관관계
- Advertising(광고)과 판매량의 관계
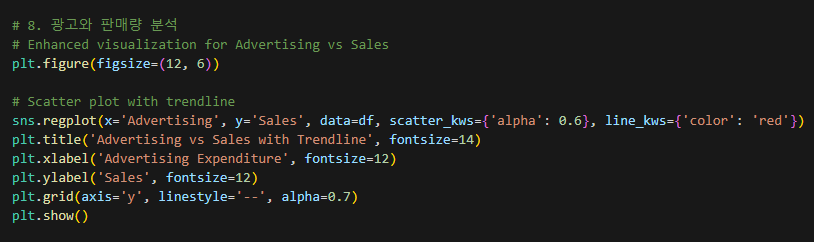
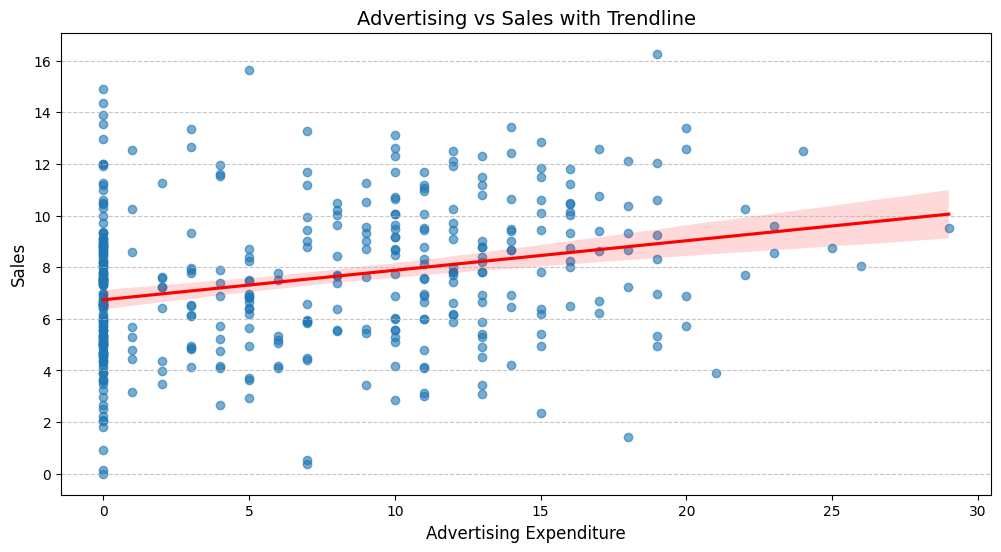
- 강한 양의 상관관계
- ROI와 연령의 유관도
9-1. 판매량과 연령 유관도
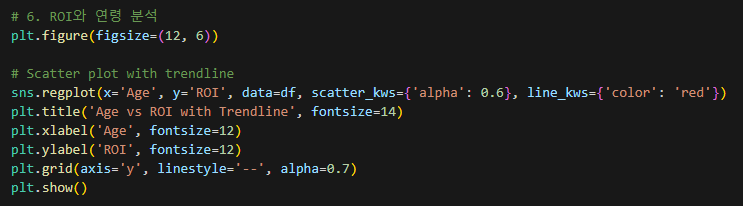
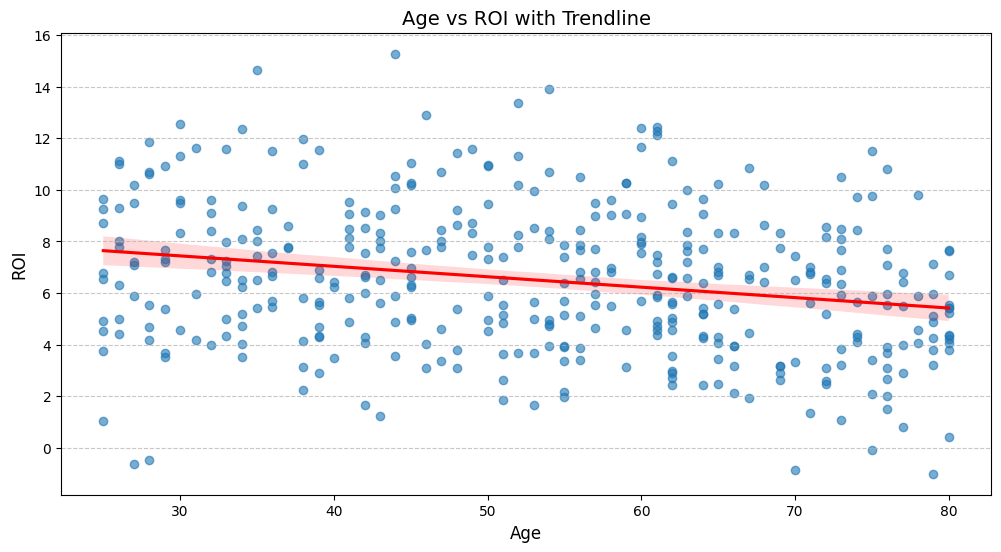
- 연령과 ROI는 약한 음의 상관관계
상관관계 높은 순
Price > Advertising > Age
단변량 분석
1. Sales
Sales의 중앙값은 7,490건으로 평균 판매량인 7,496건과 유사하다. 50% 판매량은 5,000 ~ 10,000건 사이에 분포한다. 판매량의 분포가 넓은지(변동적), 좁은지(덜 변동적)에 대해 타 경쟁사의 사례를 분석해서 비교해보면 어떨까?

2. Price
단변량 분석에서 평균값 115.795는 중앙값 117.0보다 낮다. 이는 가격을 추가적으로 높일 수 있는 가능성을 시사한다.
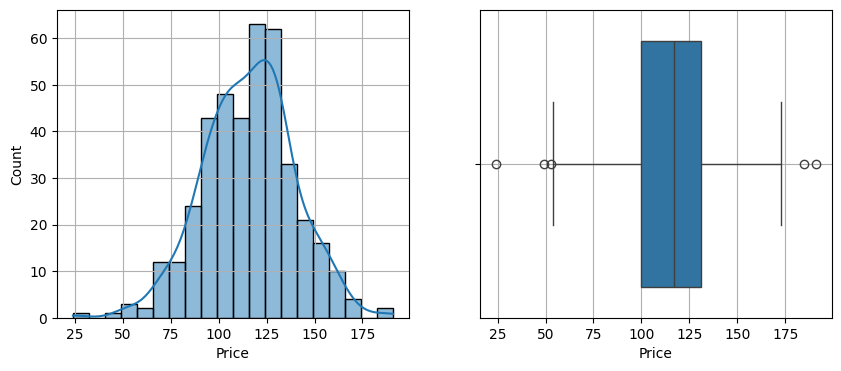
다만 앞서 살핀대로 다변량 분석에서 ROI와 Price의 상관관계는 다른 변수 대비 -0.44로 강하게 나타나며, 따라서 가격을 낮추는 것이 판매수익을 높일 가능성이 있다.
추가 분석할 내용
1. 경쟁사들의 판매량 분포 범위를 조사
2. 경쟁사 가격 분포와 비교
3. 특별히 판매량이 높은 지점에 대한 변인 분석
*가격의 과대평가, 과소평가 알아보기
1. 벤치마크 또는 비교 :
이 가격을 경쟁사 가격, 과거 평균 또는 특정 기준과 비교
- 분포 분석 :
- 대부분의 가격이 평균($115.80)에 가까우면, 평균+표준편차($115.80 + $23.68 ≈ $139.48)보다 상당히 높은 가격은 과대평가된 것으로 간주될 수 있다.
- 마찬가지로, 평균−std\text{평균} - \text{std}($115.80 - $23.68 ≈ $92.12)보다 상당히 낮은 가격은 저평가되었을 수 있다.
- 통계에서 얻은 주요 관찰 사항:
- 평균 가격 : $115.80
- 표준편차(Std) : $23.68 (이는 가격의 적당한 변동성을 나타냅니다.)
- 범위 : $24에서 $191까지
- 사분위수 :
- 가격의 25%는 100달러 미만이다.
- 가격의 50%(중간값)은 117달러이다.
- 가격의 75%가 131달러 미만이다.
- 통찰력:
- 중간값($117)에 가까운 가격이 일반적이다.
- 과대평가 : 가격이 139.48달러(평균+표준)보다 상당히 높습니다.
- 저평가 : 가격이 $92.12(평균 - 표준)보다 상당히 낮음.
벤치마크(예: 경쟁사 가격 또는 고객의 지불 의향)가 있는 경우, 이러한 가격이 기대치에 비해 높은지 낮은지 추가로 분석할 수 있다.
