KPMG Future Academy AI 활용 데이터 분석가 3기 34일차 수업을 2025년 1월 6일에 참석했다.
- 판다스
1.1. 데이터프레임 결측치 처리
1.2. 데이터프레임 합치기
1.3. 데이터프레임 날짜 다루기
1. 판다스
1.1. 데이터프레임 결측치 처리
info() 메소드로 non-null 값 확인.
isna(), isnull() 메소드로 확인.
dropna()로 결측치 제거.
subset= 옵션으로 특정 열에서 결측치가 있는 행 제거.
fillna()로 결측치 채우기.
method = 옵션에서 전후 값으로 채우기. ffill, bfill
interpolate 메소드로 선형보간법으로 채우기.
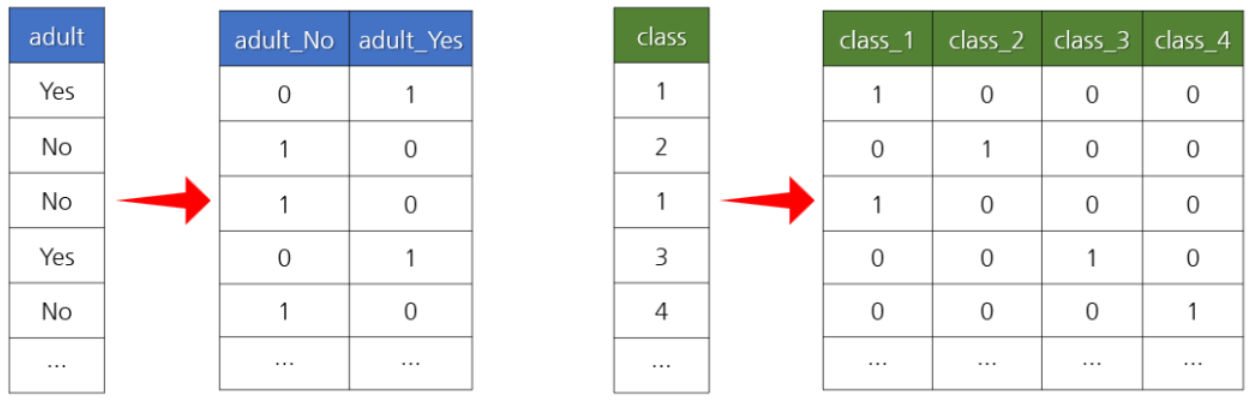
가변수(Dummy Variable) 만들기
- 가변수는 일정하게 정해진 범위의 값을 갖는 데이터(범주형 데이터)를 독립된 열로 변환한 것이다.
- 특히 범주형 문자열 데이터는 머신러닝 알고리즘에 사용하려면 숫자로 변환해야 한다.
- 가변수를 만드는 과정을 One-Hot-Encoding 이라고 부르기도 한다.
- get_dummies() 함수를 사용해서 가변수를 쉽게 만들 수 있다.
one-hot-encoding
get_dummies 함수로 가변수를 만들 수 있음.
[참고] 다중공선성 문제
- 통계학의 회귀분석에서 독립변수들 간에 강한 상관관계가 나타나는 문제이다.
- 독립변수들 간에 정확한 선형관계가 존재하는 완전공선성의 경우와 독립변수들 간에 높은 선형관계가 존재하는 다중공선성으로 구분하기도 한다.
- 이는 회귀분석의 전제 가정을 위배하는 것이므로 적절한 회구분석을 위해 해결해야 하는 문제가 된다.(위키백과)
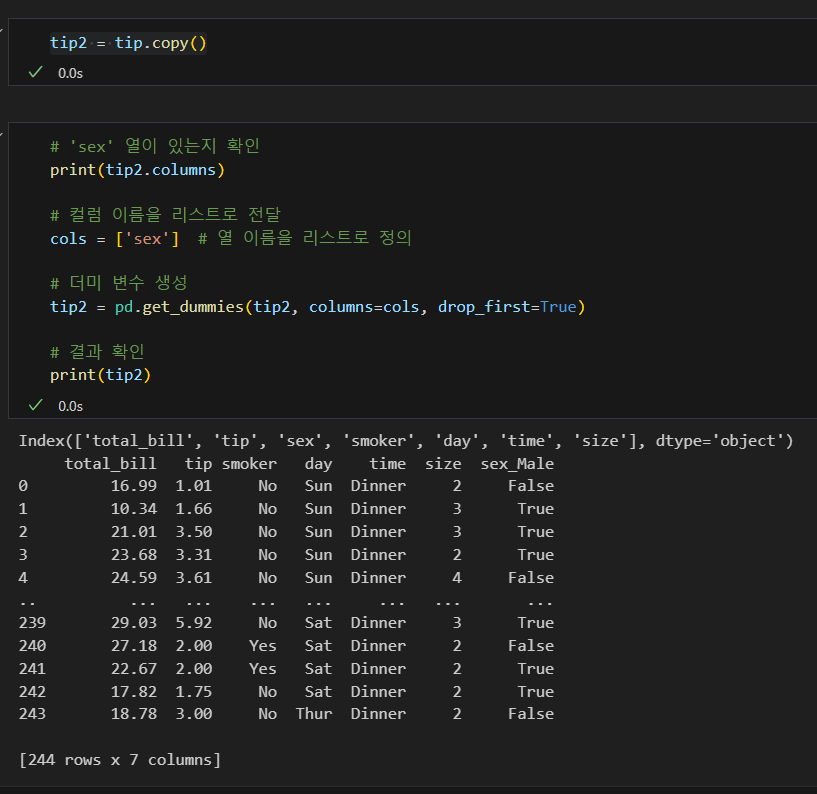
drop_first=True로 다중공선성 문제 해결.
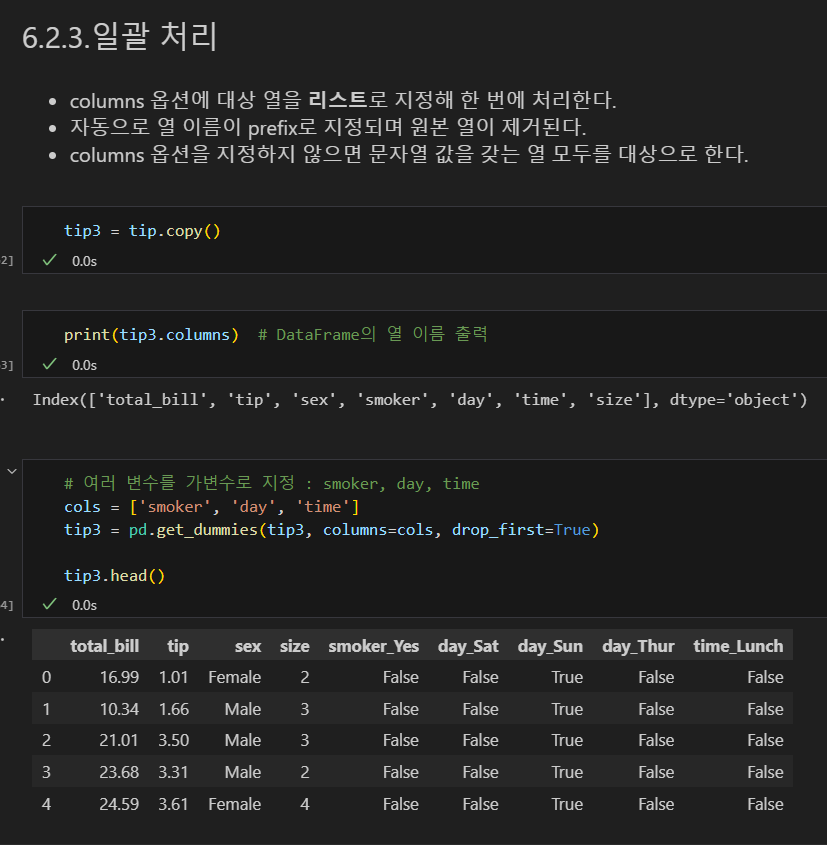
일괄 처리
- columns 옵션에 대상 열을 리스트로 지정해 한 번에 처리한다.
- 자동으로 열 이름이 prefix로 지정되며 원본 열이 제거된다.
- columns 옵션을 지정하지 않으면 문자열 값을 갖는 열 모두를 대상으로 한다.
실습
결측치 처리하기
1.2. 데이터프레임 합차기
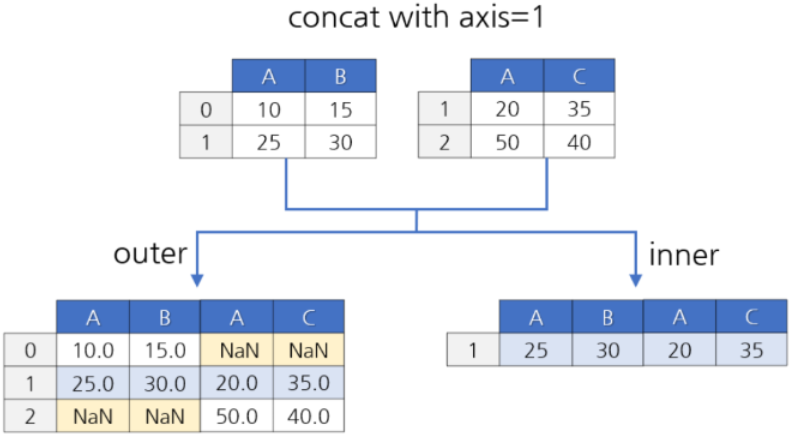
concat() 함수로 인덱스 값을 기준으로 두 데이터프레임을 가로 또는 세로로 합칠 수 있다.
-
pd.concat(objs, axis=0, join='outer', ignore_index=False)- objs : 합칠 데이터프레임이나 시리즈의 리스트 (예: [df1, df2])
- axis : 결합 방향: 0(세로, 행 추가), 1(가로, 열 추가)
- join : outer(기본값, 모든 데이터 포함), inner(공통 항목만 포함)
- ignore_index : 인덱스를 재설정할지 여부 (True면 새 인덱스 생성)
데이터프레임 합치기
데이터 불러오기
pop01
pop02
합치기
join='outer' 결과
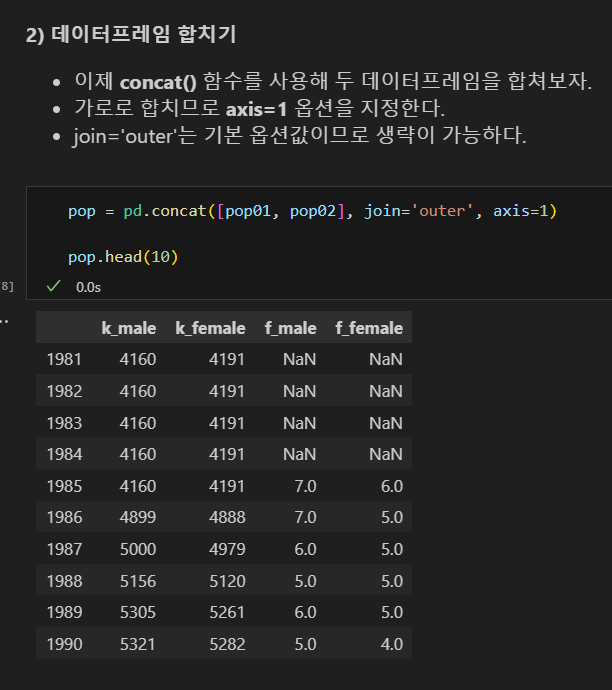
join='inner' 결과
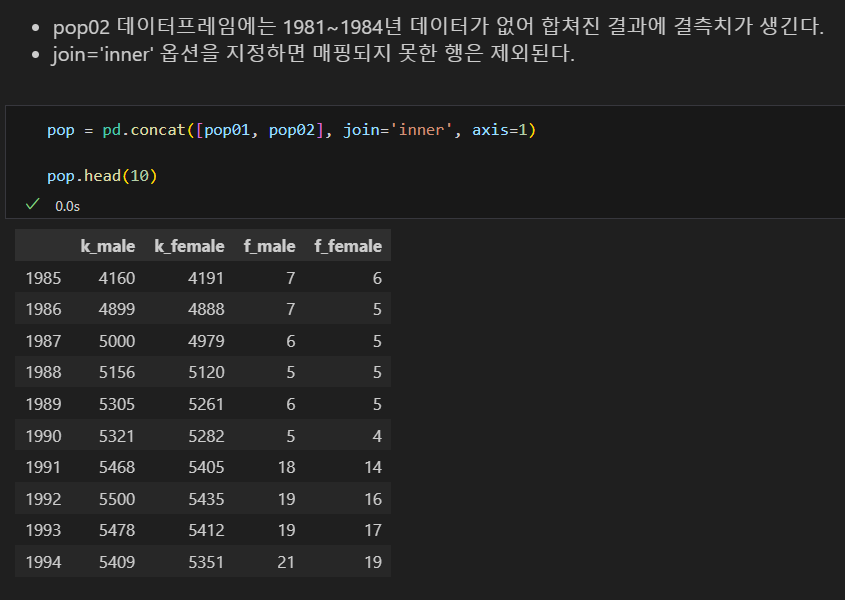
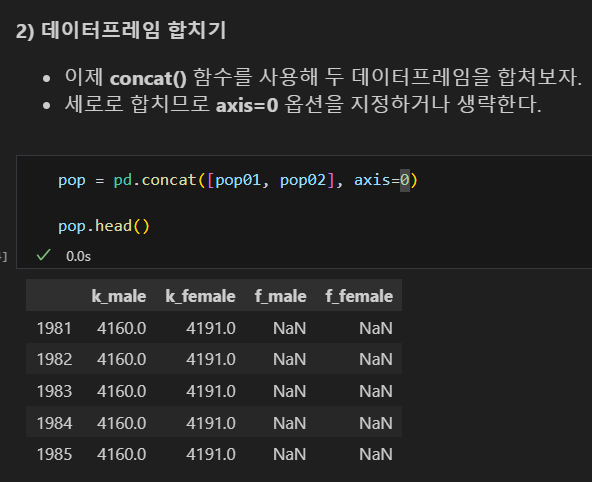
axis=0 으로 세로로 합치기
인덱스 초기화
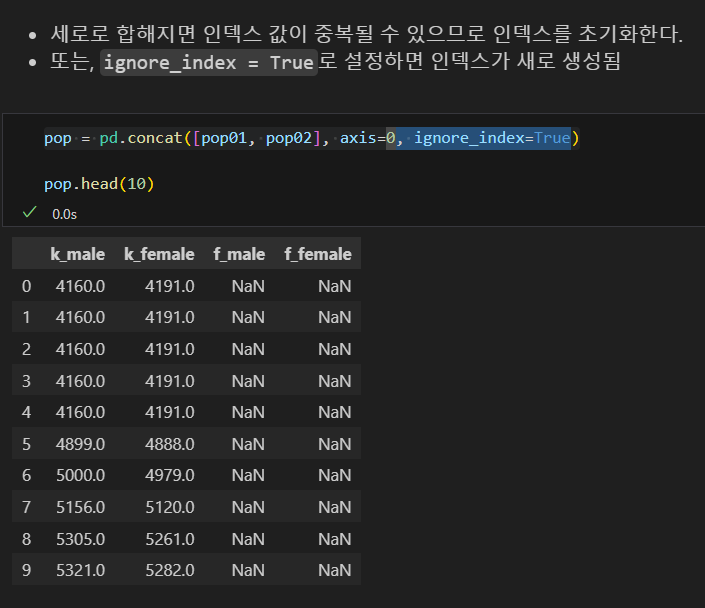
reset_index()로도 가능.
merge로 조인
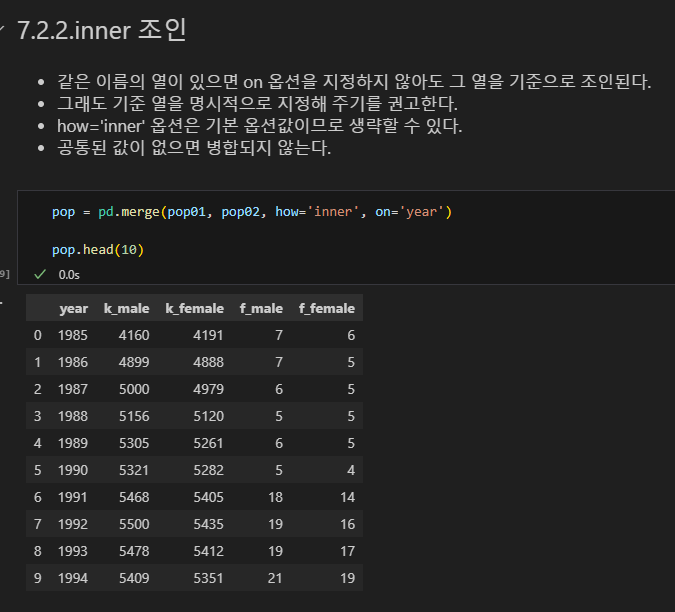
inner 조인
- 같은 이름의 열이 있으면 on 옵션을 지정하지 않아도 그 열을 기준으로 조인된다.
- 그래도 기준 열을 명시적으로 지정해 주기를 권고한다.
- how='inner' 옵션은 기본 옵션값이므로 생략할 수 있다.
- 공통된 값이 없으면 병합되지 않는다.
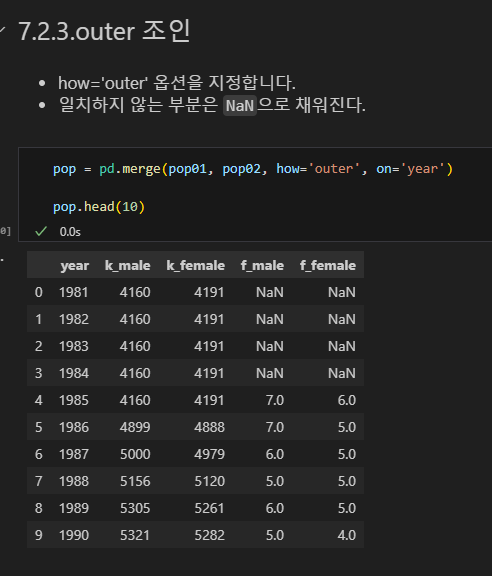
outer 조인
- how='outer' 옵션을 지정합니다.
- 일치하지 않는 부분은
NaN으로 채워진다.

merge로 데이터를 병합할 때는 양 데이터의 index를 해제하고 병합하는 것이 낫다.
주의해야 할 점들:
인덱스 레이블은 고유해야 함 (중복되면 경고가 발생)
reset_index()를 하면 기존 인덱스가 열로 변환됨
reindex() 시 없는 레이블의 경우 NaN 값이 채워짐
레이블 : 인덱스의 각 값
인덱스 이름 : 인덱스를 설명해주는 메타데이터

메타데이터 확인
df.index.name : 인덱스의 이름을 반환
df.columns.name: 열 이름의 이름을 반환
df.empty: 데이터프레임이 비어있는지 여부를 반환. 비어있으면 True, 아니면 False를 반환.
df.T: 데이터프레임을 전치(행과 열을 바꾸기)
통계적 정보 확인
df.corr(): 데이터프레임에서 숫자형 열들 간의 상관관계를 계산
df.values: 데이터프레임의 값들을 넘파이 배열 형태로 반환
df.axes: 데이터프레임의 인덱스(행)와 열을 포함하는 리스트를 반환
df.ndim: 데이터프레임의 차원 수를 반환. (2차원 데이터프레임은 2를 반환)
df.size: 데이터프레임의 전체 원소 수를 반환
df.columns.values: 열 이름들을 넘파이 배열 형태로 반환
데이터프레임 df의 모든 속성을 확인하고 싶을 때
dir(df)
1.3. 데이터프레임 날짜 다루기
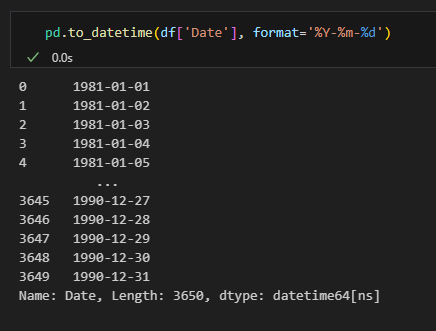
문자형을 날짜형으로 변경
- 날짜가 문자형으로 되어있다면 날짜형으로 변경해야 여러가지 날짜 계산을 할 수 있다.
pd.to_datetime(컬럼, format='날짜 형식')
| 형식 | 설명 |
|---|---|
| %Y | 0을 채운 4자리 연도 |
| %y | 0을 채운 2자리 연도 |
| %m | 0을 채운 월 |
| %d | 0을 채운 일 |
| %H | 0을 채운 시간 |
| %M | 0을 채운 분 |
| %S | 0을 채운 초 |
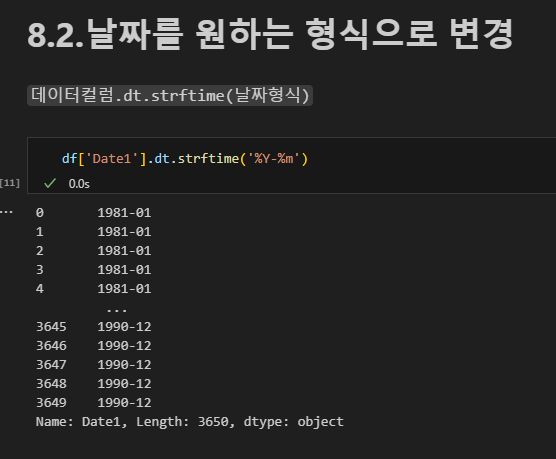
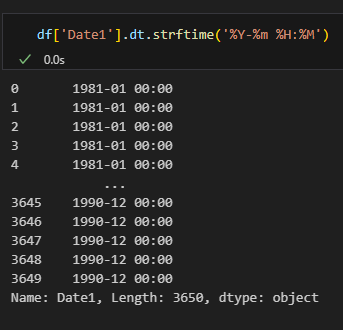
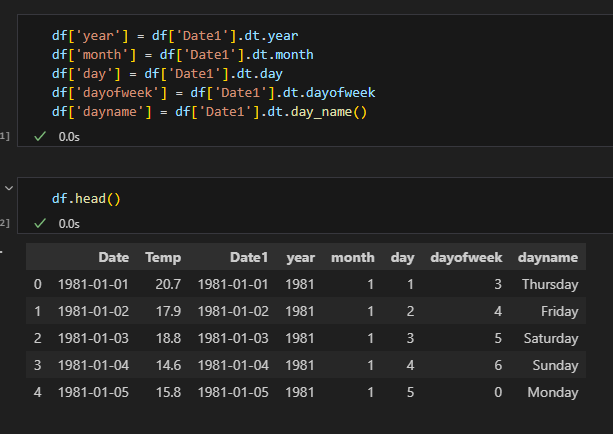
dt 연산자
| 연산자 | 설명 |
|---|---|
| year | 연도 |
| month | 월 |
| day | 일 |
| dayofweek | 요일(0-월요일, 6-일요일) |
| day_name() | 요일을 문자열로 |
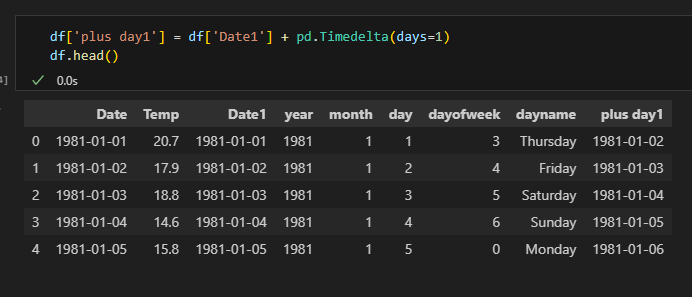
날짜 계산
- day 연산:
pd.Timedelta(day=숫자) - month 연산:
DateOffset(months=숫자) - year 연산:
DateOffset(years=숫자)
일 추가
일 빼기
DateOffset으로 월 더하고 빼기
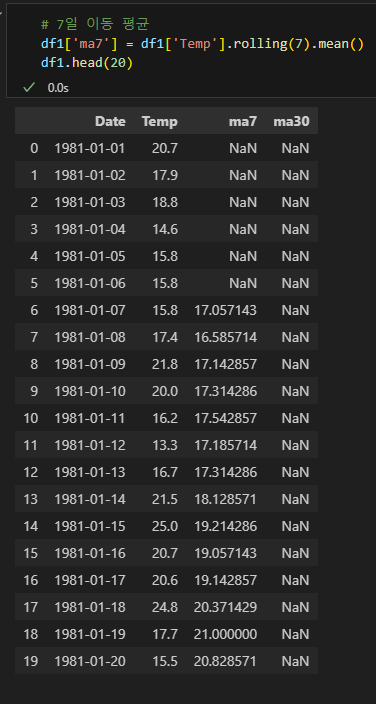
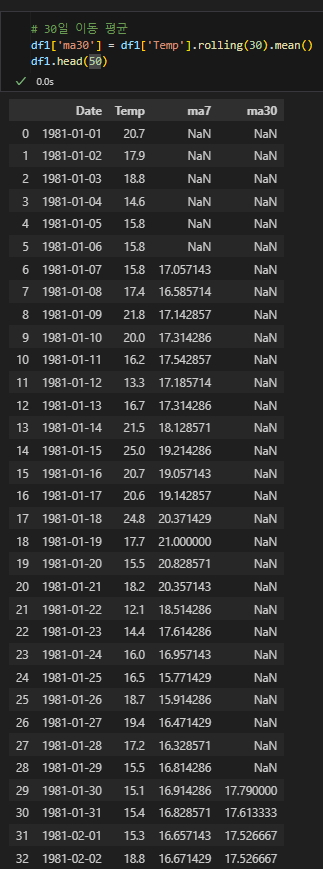
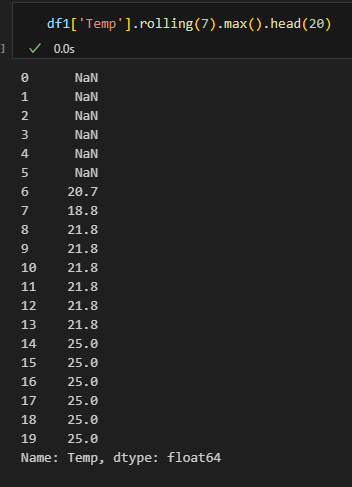
rolling 메소드로 이동간 평균 구하기
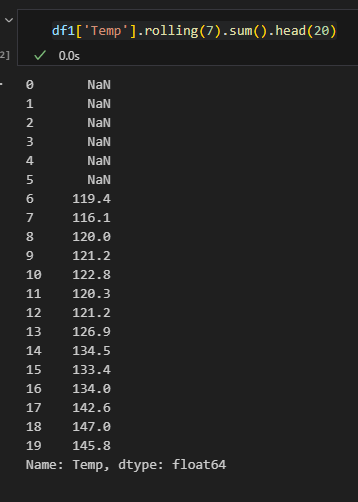
합계
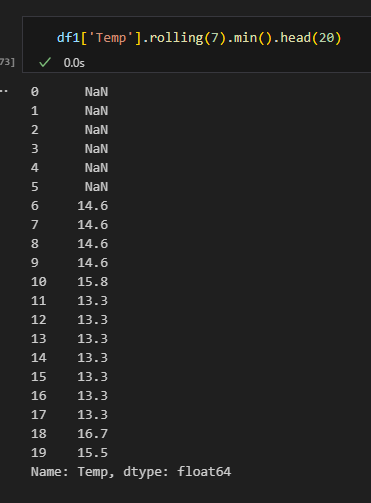
최소값
최대값
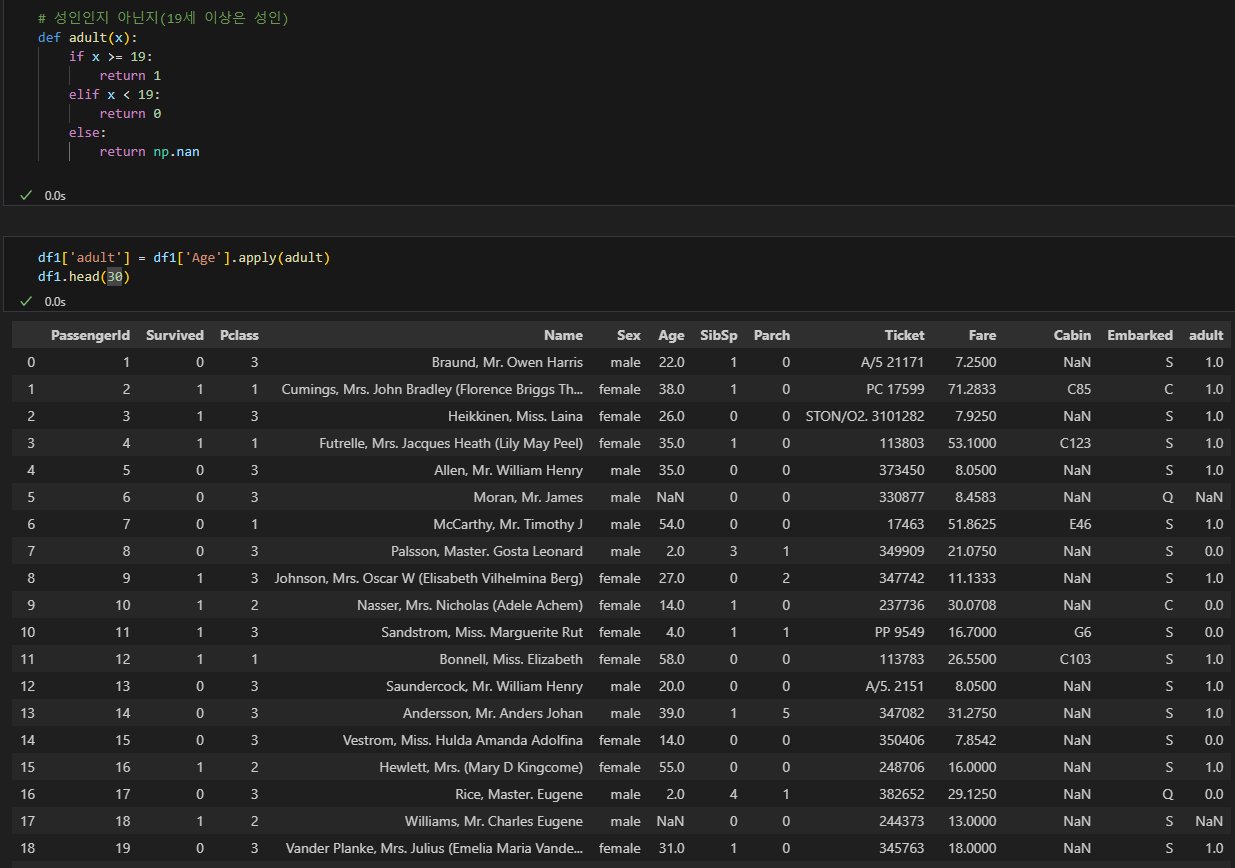
apply 함수
- 사용자 정의 함수를 데이터에 적용하고 싶을 때 사용한다.
데이터프레임.apply(함수, axis=0/1)
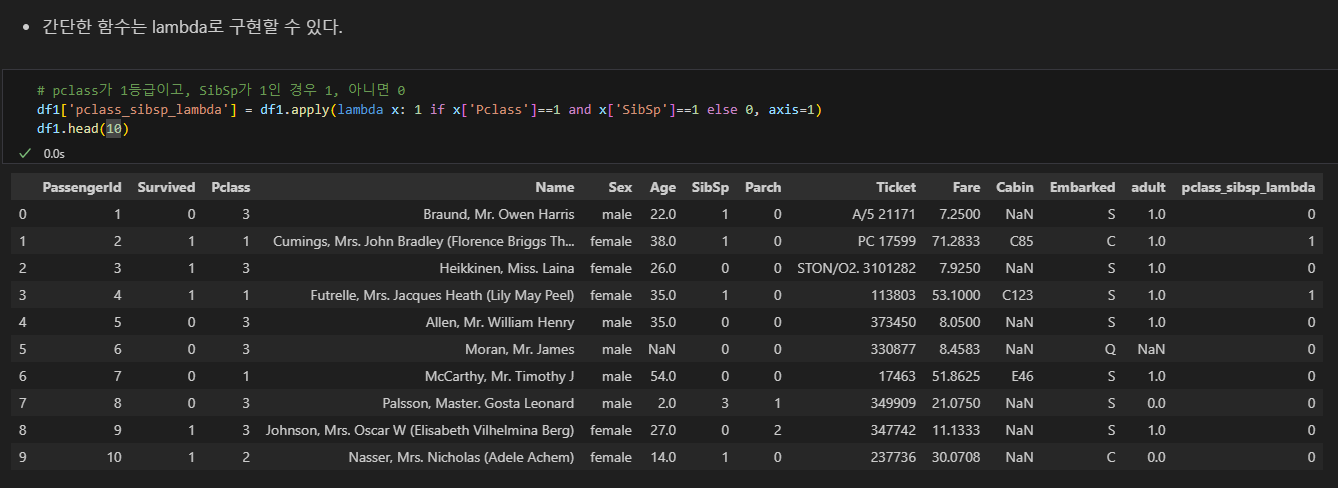
lambda 함수 사용
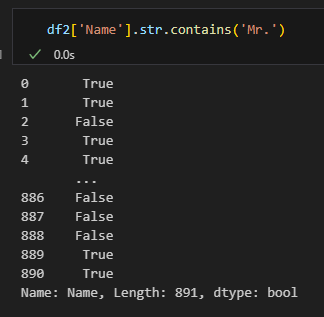
문자열 다루기
| 메소드 | 설명 |
|---|---|
.str.contains(문자열) | 문자열을 포함하고 있는지 유무 |
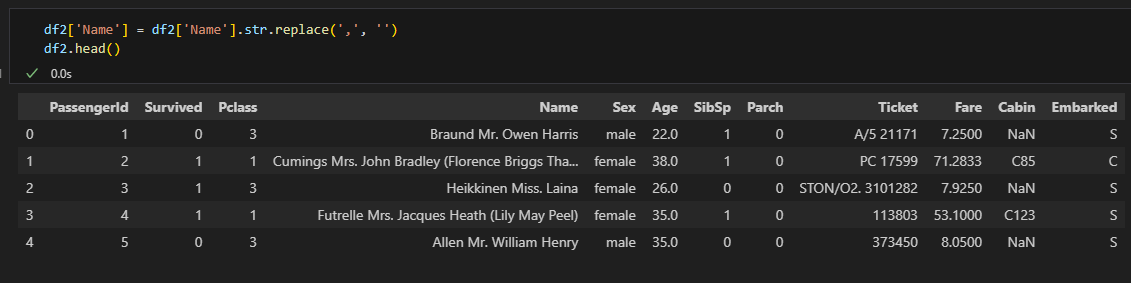
.str.replace(기존문자열, 대치문자열) | 문자열 대치 |
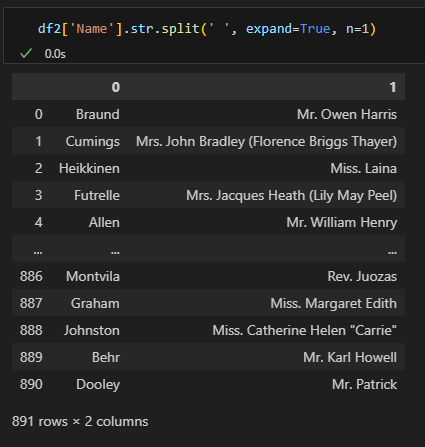
.str.split(문자열, expand=True/False, n=개수) | 특정 문자열을 기준으로 쪼개기 |
.str.lower() | 소문자로 바꾸기 |
.str.upper() | 대문자로 바꾸기 |
contain
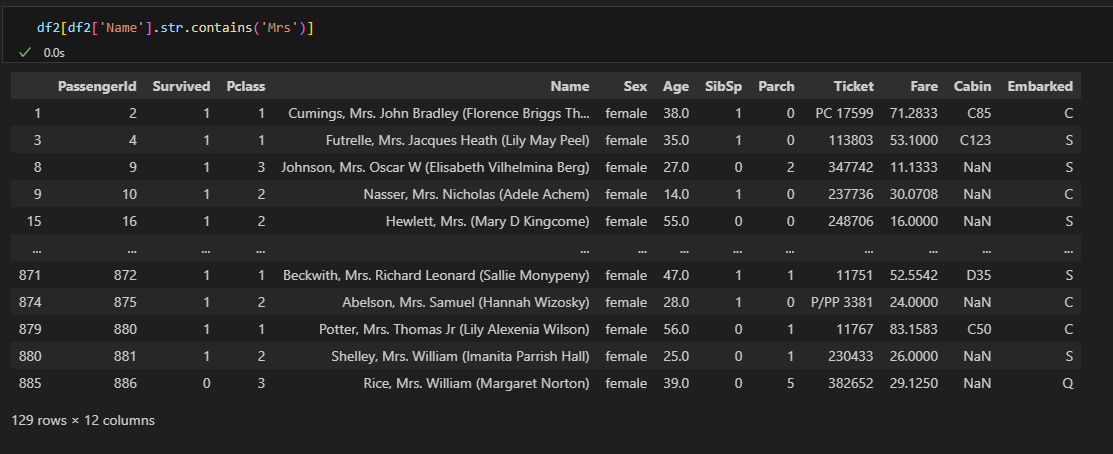
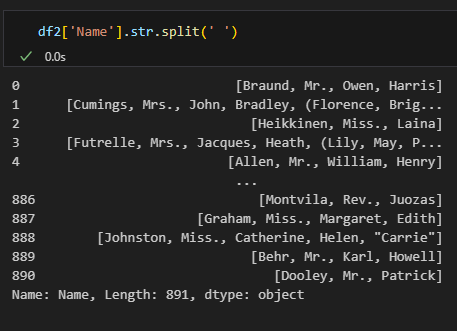
expand=False가 기본값이므로 리스트 형태로 반환됨- True: 데이터프레임으로 반환(나눈 문자열을 개별 컬럼으로 나누기), False: 리스트로 반환
대소문자 변경
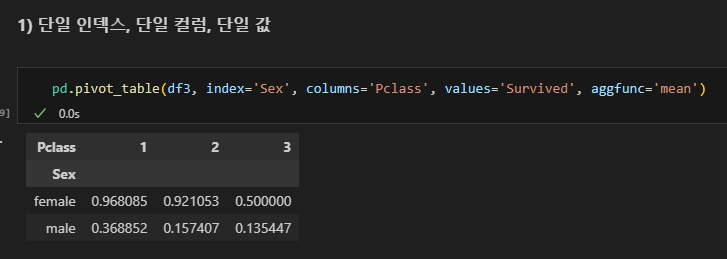
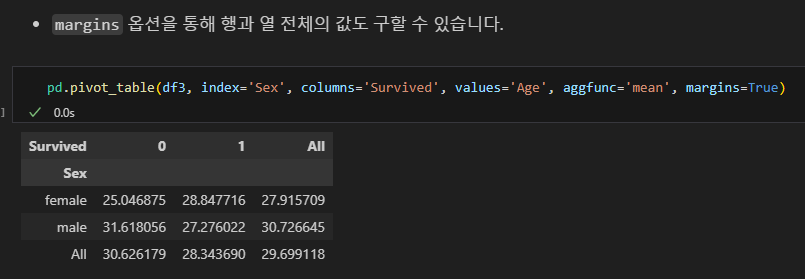
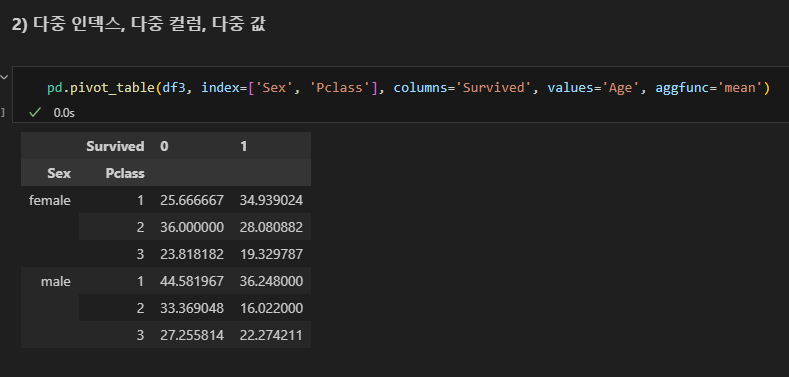
피벗테이블
- 엑셀의 피벗테이블처럼 인덱스별 컬럼별 값의 연산을 할 수 있다.
pd.pivot_table(데이터명, index=, columns=, values=, aggfunc=)
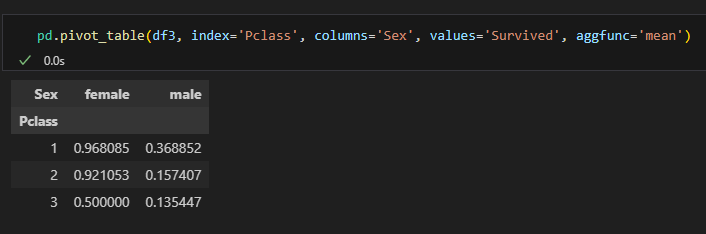
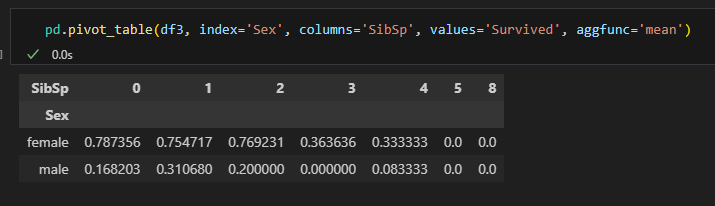
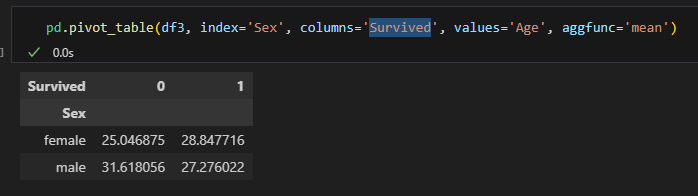
margins옵션을 통해 행과 열 전체의 값도 구할 수 있음.
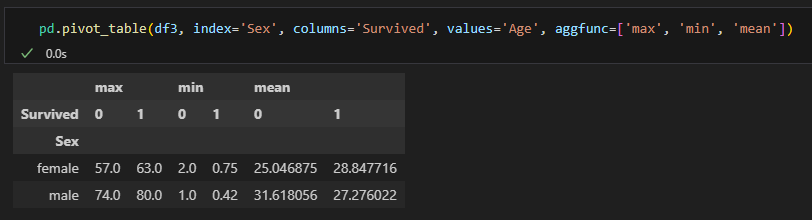
다중 인덱스, 다중 컬럼, 다중 값
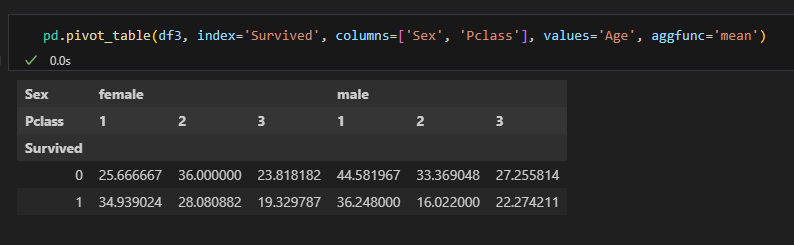
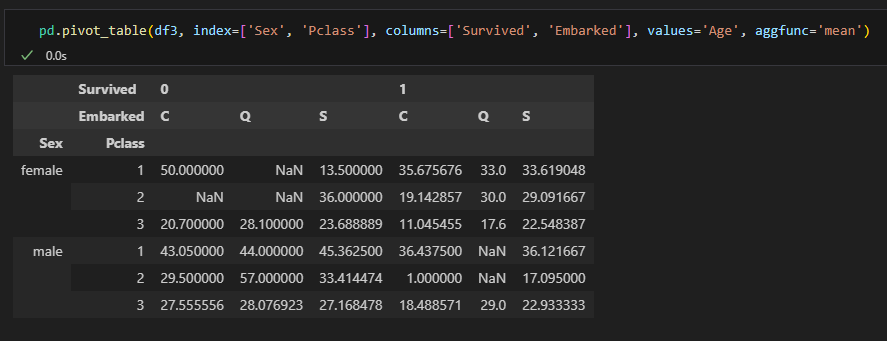
pivot_table VS groupby
| 기능 | pd.pivot_table | groupby |
|---|---|---|
| 목적 | 행, 열, 값으로 다차원 분석 | 주로 그룹화 및 집계 |
| 출력 형태 | 피벗 테이블 형태의 DataFrame | 그룹화된 DataFrame 또는 Series |
| 다중 집계 함수 | 지원 (aggfunc로 여러 함수 가능) | agg()로 여러 함수 가능 |
| margins 옵션 | 전체 합/평균 등 추가 가능 | 지원하지 않음 |
| 다중 인덱스 | 행과 열에 다중 인덱스 생성 | 행에만 다중 인덱스 생성 |
| 사용성 | 행과 열을 동시에 요약 가능 | 주로 행 기준으로 요약 |
이후 시간에는 데이터 분석 연습을 진행했다.
HR 데이터를 간단히 분석해보았다.
직원만족도와 각각 급여, 휴가의 유관도는 1에 가깝지 않으므로 귀무가설(불채택)이다.
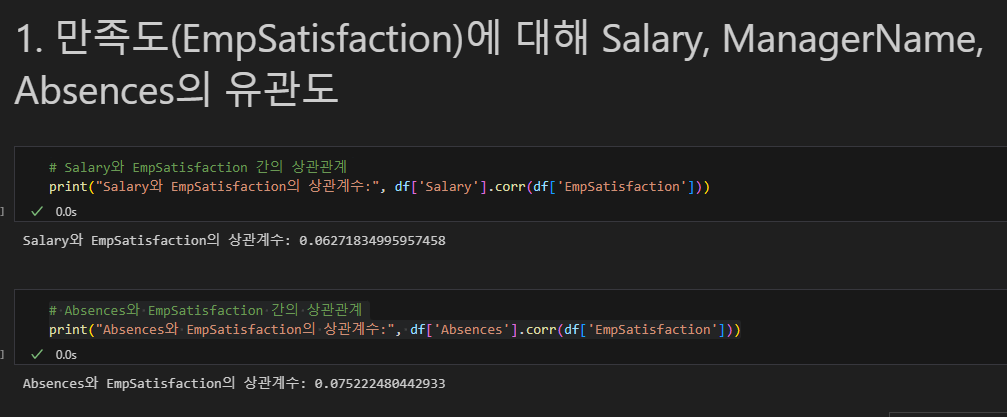
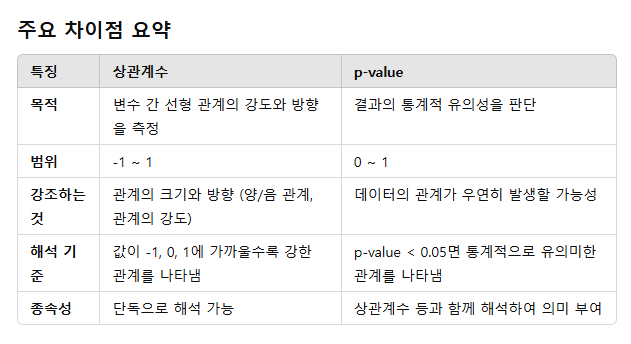
상관계수로는 음의 상관관계인지, 양의 상관관계인지를 판별하고, p-value로는 통계적으로 유의미한지를 판별한다.
p-value를 구해본 결과 마찬가지로 유의미하지 않음.
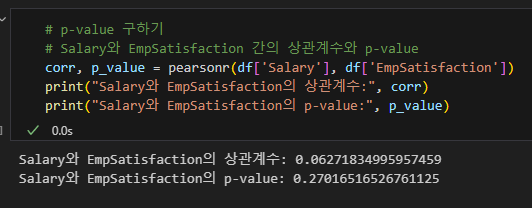
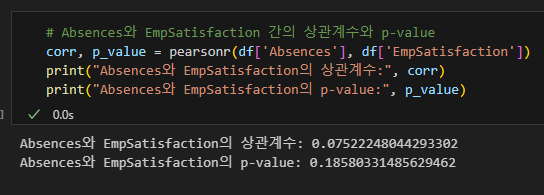
연습문제 1
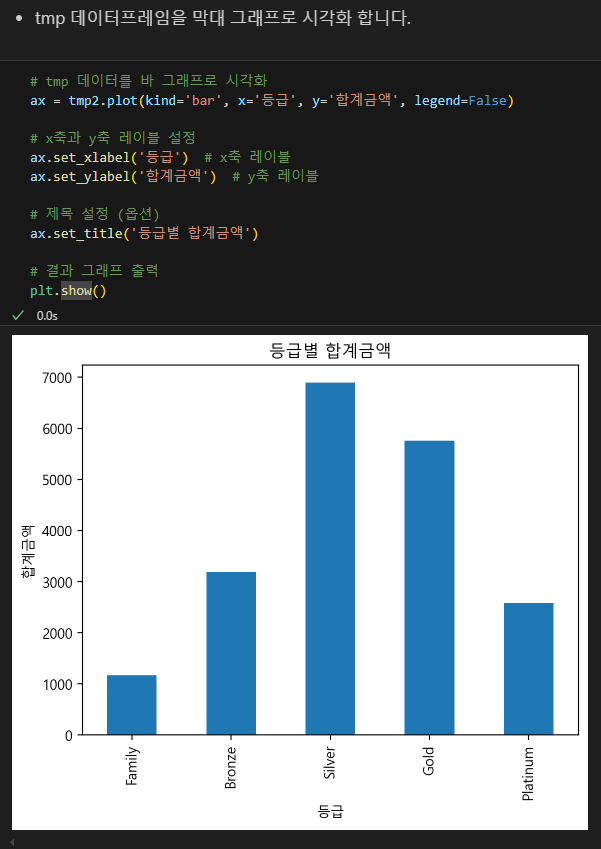
서울인구변화 시각화해보기
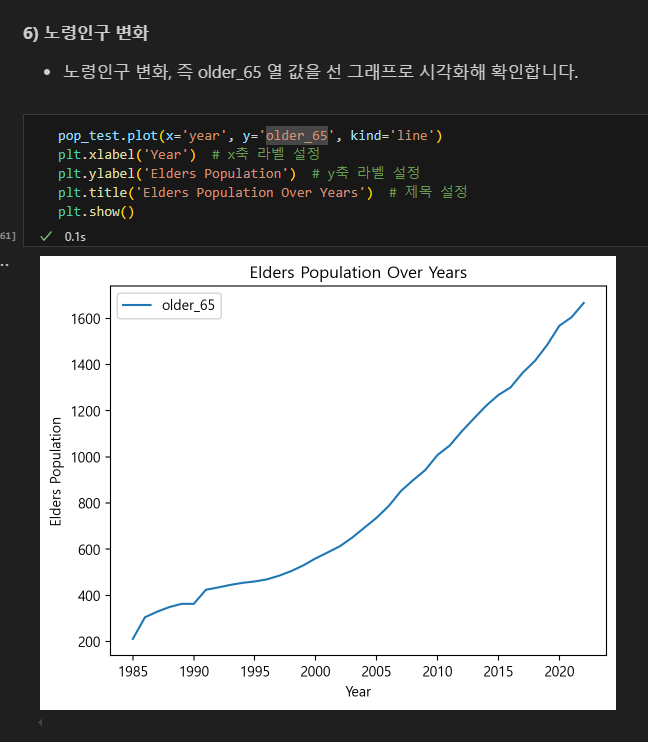
서울 인구의 고령화를 한 눈에 볼 수 있는 차트였다.
외국인 인구수도 2000년대부터 급격히 늘어났다.
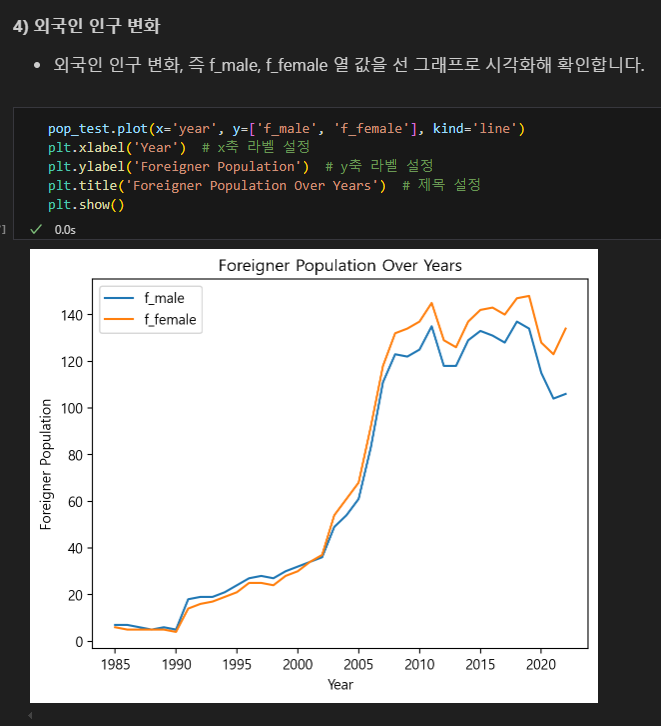
연습문제 2