KPMG Future Academy AI 활용 데이터 분석가 3기 39일차 수업을 2025년 1월 13일에 참석했다.
- 데이터 수집
1.1. API
1. 데이터 수집
1.1. API
서울시 공공데이터 포털에서 회원가입 후 인증키를 요청하면 즉시 발급됨.
데이터 가져오기
response = urllib.request.urlopen(url)
json_str = response.read().decode('utf-8')
print(json_str)
이렇게 json으로 데이터를 가져와서 파이썬에서 딕셔너리나 리스트로 파싱하여 사용한다.
프로토콜을 추적하려면 urllib.request.urlopen(url)로 데이터 가져올 때 프로토콜 정보를 제공하지 않기 때문에 아래 방법으로 프로토콜 추적 가능.
- urllib의 로그 수준을 조정하면 HTTP 통신의 세부 정보를 확인할 수 있음.
- 요청이 HTTP인지 HTTPS인지 확인하려면 response 객체에서 확인할 수 있음.
- 더 자세히 프로토콜 수준의 데이터를 추적하려면, Wireshark나 tcpdump 같은 네트워크 패킷 분석기를 사용할 수 있음.
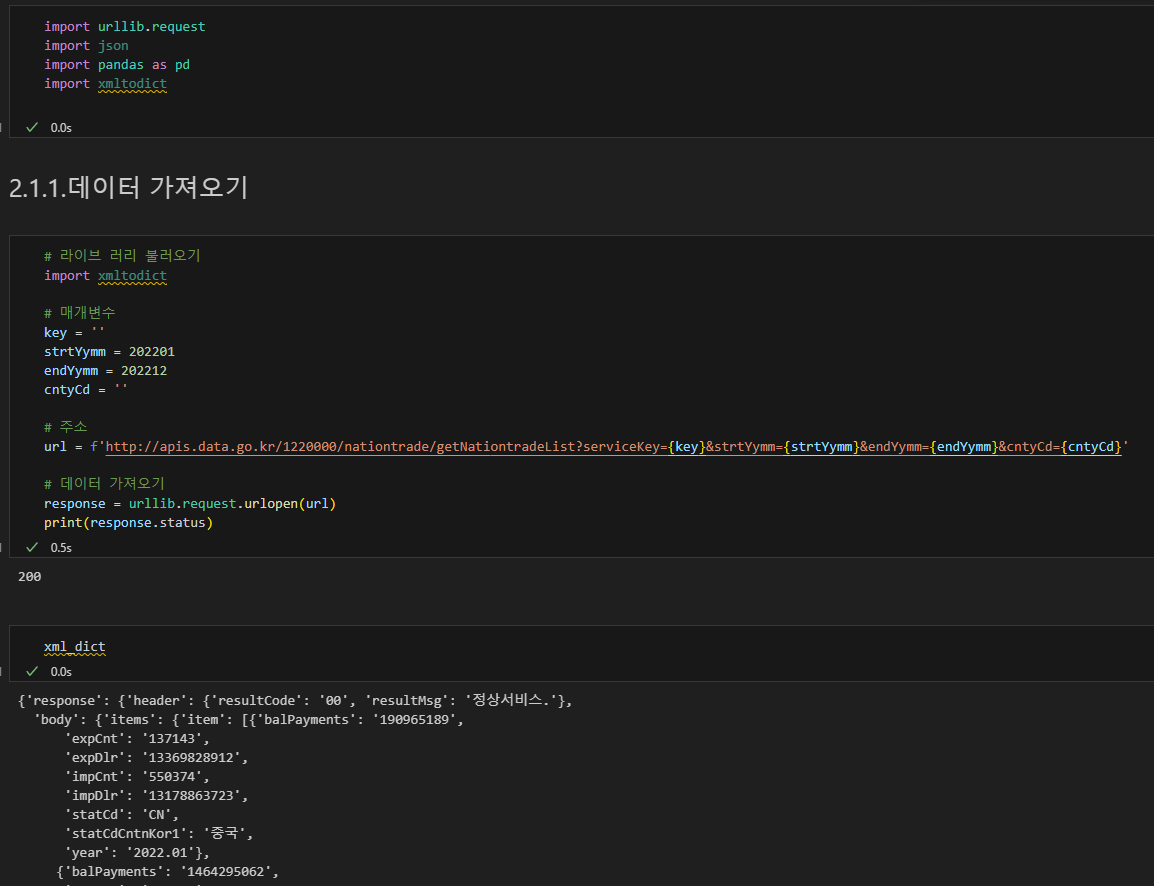
xml을 딕셔너리로 변환하는 라이브러리 설치

서울시 열린 데이터 광장 : 인증키 하나로 모든 데이터 활용 가능
공공데이터 포털 : 데이터마다 별도 인증 신청해야함.
공공데이터 포털
인코딩 키 사용
https를 http로 수정.
plotly, seaborn, matpoltlib, folium 등 차트 한글 폰트 적용
plt.rcParams['font.family'] = 'Malgun Gothic'관세청_국가별 수출입실적(GW) (출처 : 공공데이터 포털)
소스 : https://www.data.go.kr/data/15101612/openapi.do
데이터셋 설명
- balPayments: 무역수지(달러)
- expCnt: 수출건수
- expDlr: 수출금액(달러)
- impCnt: 수입건수
- impDlr: 수입금액(달러)
- statCd: 국가코드
- statCdCntnKor1: 국가
- year: 기간
cols = ['balPayments', 'expCnt', 'expDlr', 'impCnt', 'impDlr']
im_export[cols] = im_export[cols].astype('int64')
im_export.info()im_export_mean = im_export.groupby(by='statCdCntnKor1', as_index=True).mean(numeric_only=True)
im_export_mean.sort_values(by='balPayments', ascending=False, inplace=True)
im_export_mean.head(10)이렇게 데이터 정렬한 뒤,
차트 확인
im_export_mean.plot()
plt.show()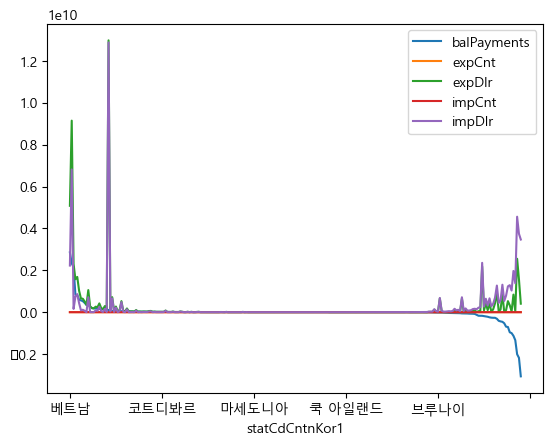
여기서 x축의 국가명이 자동으로 생략된 기준은 matplotlib의 공식문서에 따르면 아래와 같다.
AutoLocator :
https://matplotlib.org/stable/api/ticker_api.html#matplotlib.ticker.AutoLocator
Place evenly spaced ticks, with the step size and maximum number of ticks chosen automatically.
MaxNLocator :
https://matplotlib.org/stable/api/ticker_api.html#matplotlib.ticker.MaxNLocator
Place evenly spaced ticks, with a cap on the total number of ticks.
위 알고리즘과 FixedLocator를 사용.
라벨 겹침 방지를 matplotlib 자동 생략 알고리즘이 아닌 수동으로 조정하는 방법
로그화해서 무역거래 상하위 국가 데이터만 추려서 보기
# 상위 10개, 하위 10개 국가 선택
top10 = data.head(10)
bottom10 = data.tail(10)
filtered_data = pd.concat([top10, bottom10])
# 시각화
fig, ax = plt.subplots(figsize=(15, 7))
# x축 위치 설정 (중간 생략 부분 제외)
x_positions_full = list(range(10)) + [10] + list(range(11, 21)) # 전체 x 위치
x_positions_data = list(range(10)) + list(range(11, 21)) # 데이터 표시용 x 위치
# 라인 차트 (로그화된 값)
ax.plot(x_positions_full, list(filtered_data['expDlr']) + [None], label='수출액(log)', color='green', linestyle='--', linewidth=2)
ax.plot(x_positions_full, list(filtered_data['impDlr']) + [None], label='수입액(log)', color='red', linestyle=':', linewidth=2)
# 막대 차트 (경상수지) - 중간 생략 부분 제외
ax.bar(x_positions_data, filtered_data['balPayments']/1e9, alpha=0.3, label='무역수지(10억)', color='blue')
# 0선 추가
ax.axhline(0, color='black', linewidth=0.5, linestyle='--')
# x축 레이블 설정
xticks_labels = list(filtered_data.index[:10]) + ['...'] + list(filtered_data.index[10:])
ax.set_xticks(x_positions_full)
ax.set_xticklabels(xticks_labels, rotation=45, ha='right')
# 그래프 꾸미기
ax.legend(loc='upper right', bbox_to_anchor=(1, 1))
ax.grid(True, alpha=0.3)
# 레이블 추가
plt.xlabel('국가명', fontsize=12)
plt.ylabel('무역 지표', fontsize=12)
# 제목 설정
plt.title('국가별 무역 지표 분석 (상위/하위 10개국)\n수출입액: 로그스케일, 무역수지: 10억원 단위',
fontsize=14,
pad=20)
plt.tight_layout()
plt.show()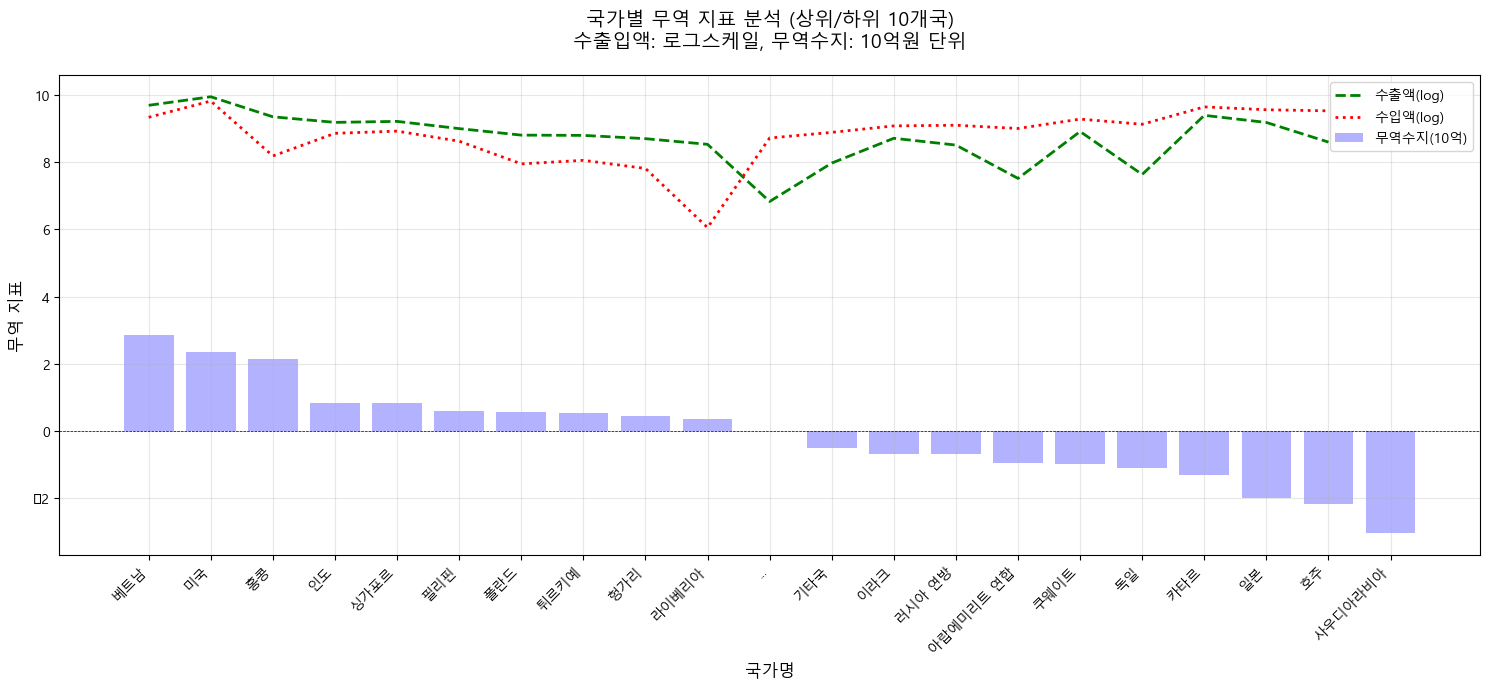
이 중에서 무역수지 계산식에 따르지 않은 값이 도출된 국가는 아래와 같다.
베트남
미국
라이베리아
싱가포르
튀르키예
(브루나이)
무역수지 (Trade Balance)=수출 금액 (expDlr)−수입 금액 (impDlr)
무역 순이익 (Net Trade Profit)=수출 금액 (expDlr)−수입 금액 (impDlr)−추가 비용 (Additional Costs)
이 중에서 약 2452 행은 비정식 지역: 자치구, 영토, 특수 상태 지역 등으로 정식국가에 해당하지 않음.
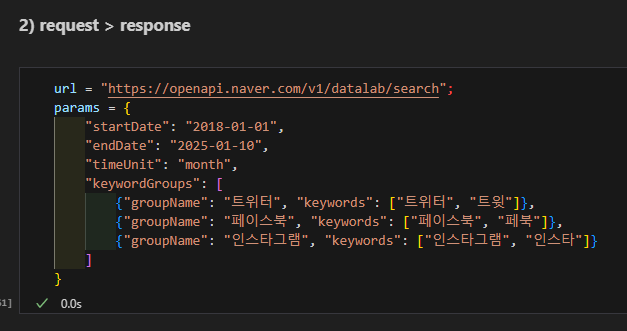
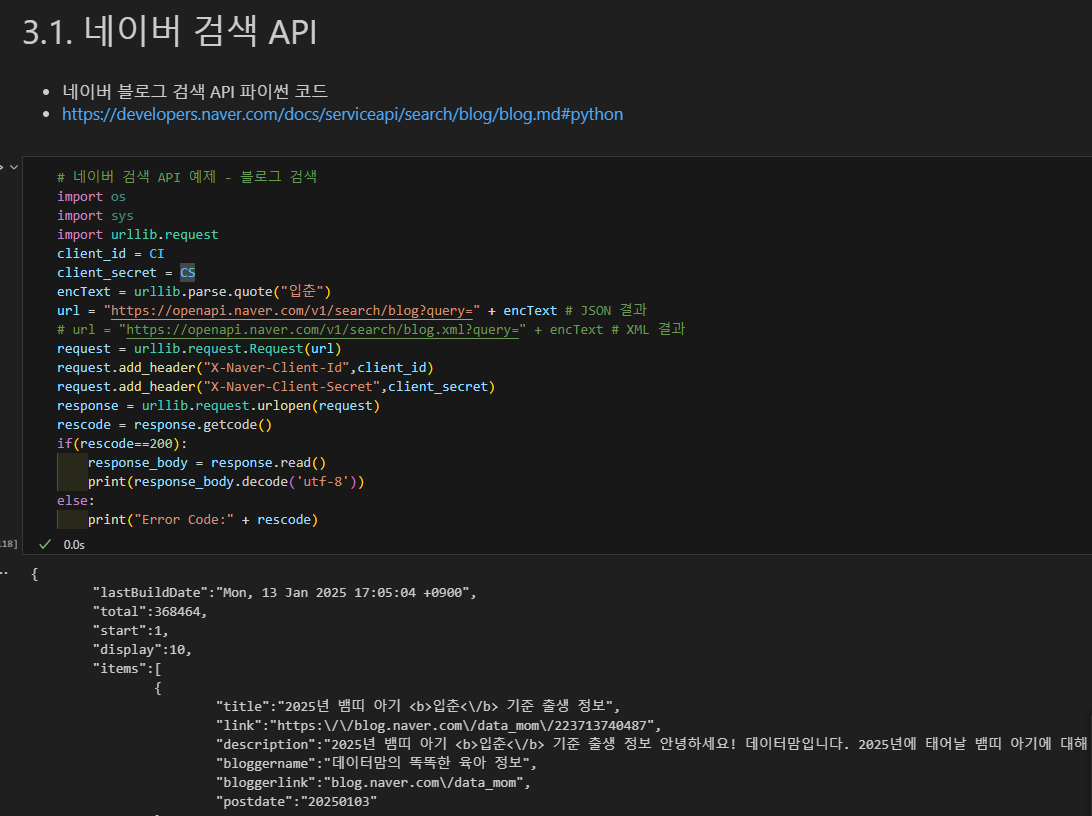
네이버 검색어 트렌드 API : 애플리케이션 등록하고
클라이언트 ID
클라이언트 secret 확보
매개변수 지정해서 불러옴.
헤더 설정
받아옴
JSON으로 파싱
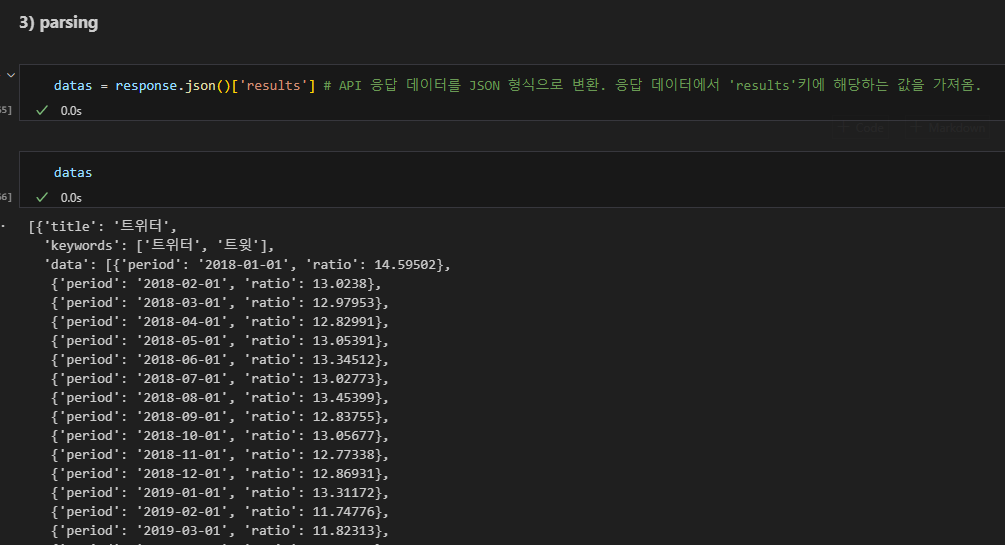
데이터프레임으로 변환
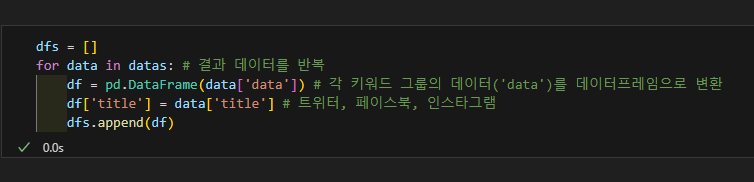
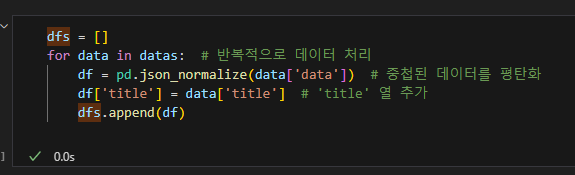
만약 데이터가 중첩됐다면 평탄화 작업 수행:
평탄화 : JSON, XML 등 계층구조의 데이터를 데이터프레임 등으로 단순화.
json_normalize() 메소드로 평탄화.
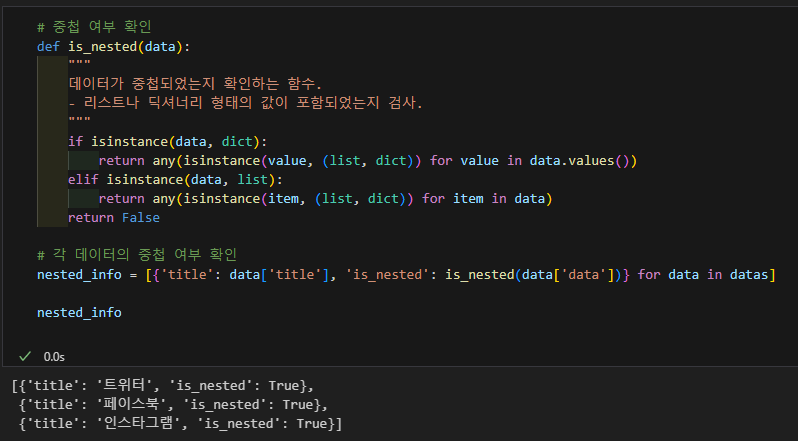
데이터가 중첩됐는지 확인하는 코드
데이터 평탄화
데이터 중첩이란?
데이터 중첩(Nested Data)이란, 데이터가 딕셔너리(Dictionary) 또는 리스트(List) 형태로 계층 구조를 이루고 있는 상태를 말함. 즉, 데이터가 단순한 1차원 배열이 아니라, 내부에 또 다른 리스트나 딕셔너리를 포함하고 있는 경우를 의미함.
데이터 구조
평탄화 전: 중첩된 딕셔너리나 리스트를 포함한 계층적 데이터.
평탄화 후: 중첩된 데이터가 열(column)로 분리된 테이블 형태.
전처리
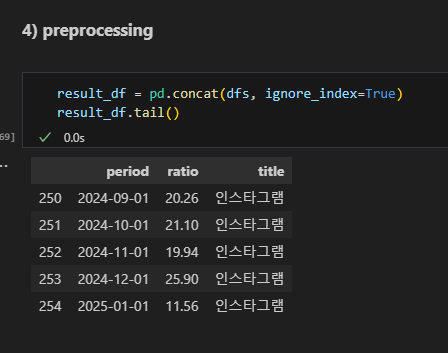
피봇테이블
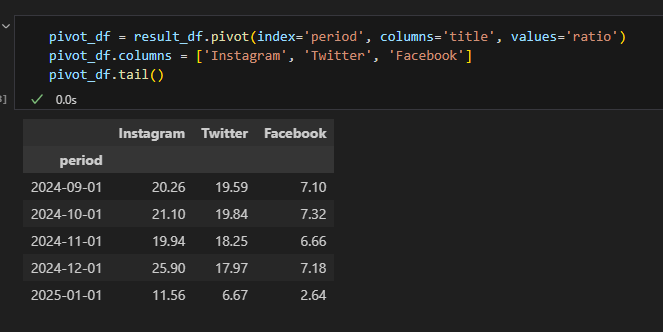
시각화
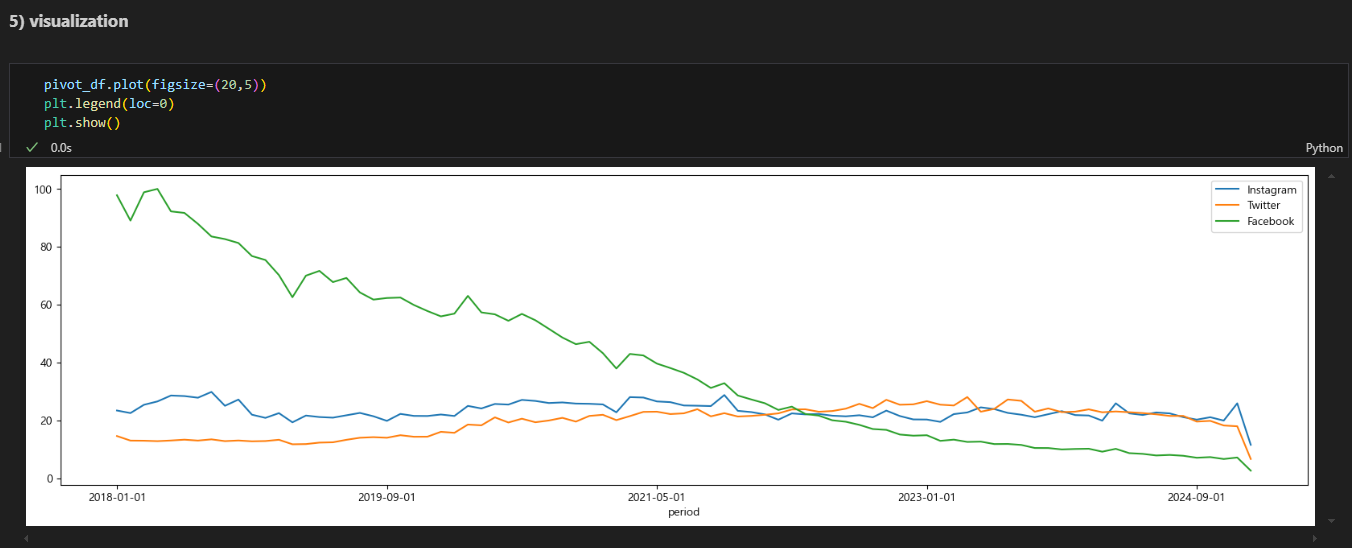
네이버 블로그 검색 결과 분석
JSON 데이터 파싱

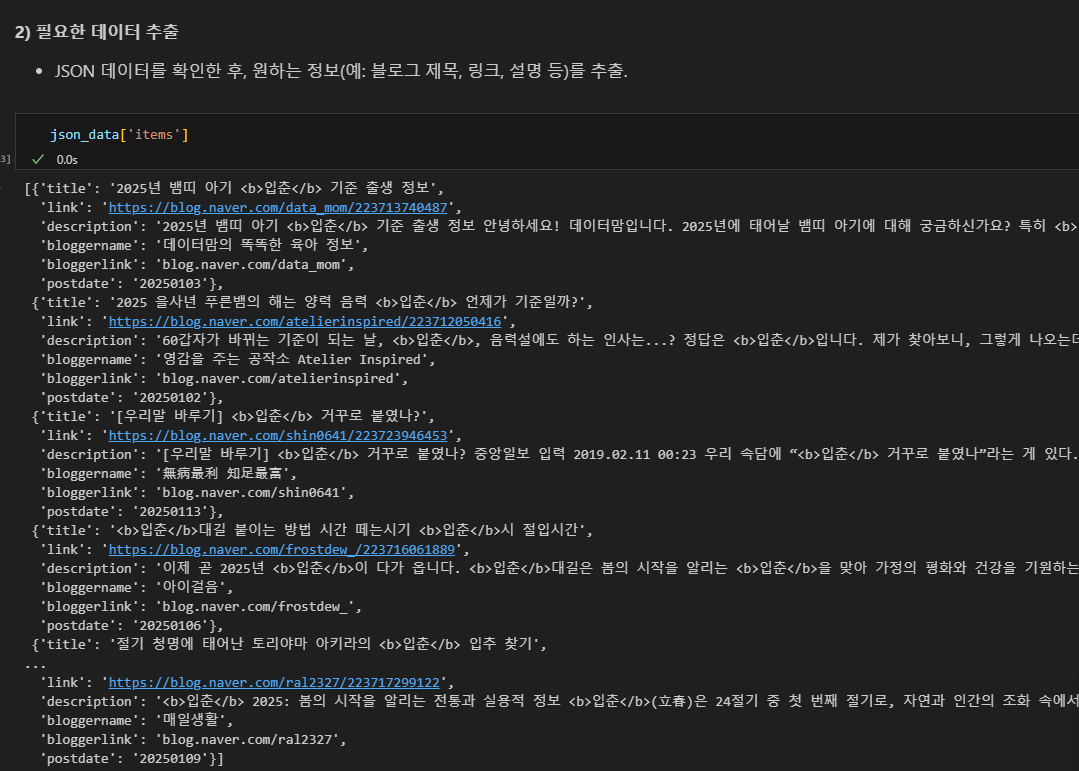
필요한 데이터 추출
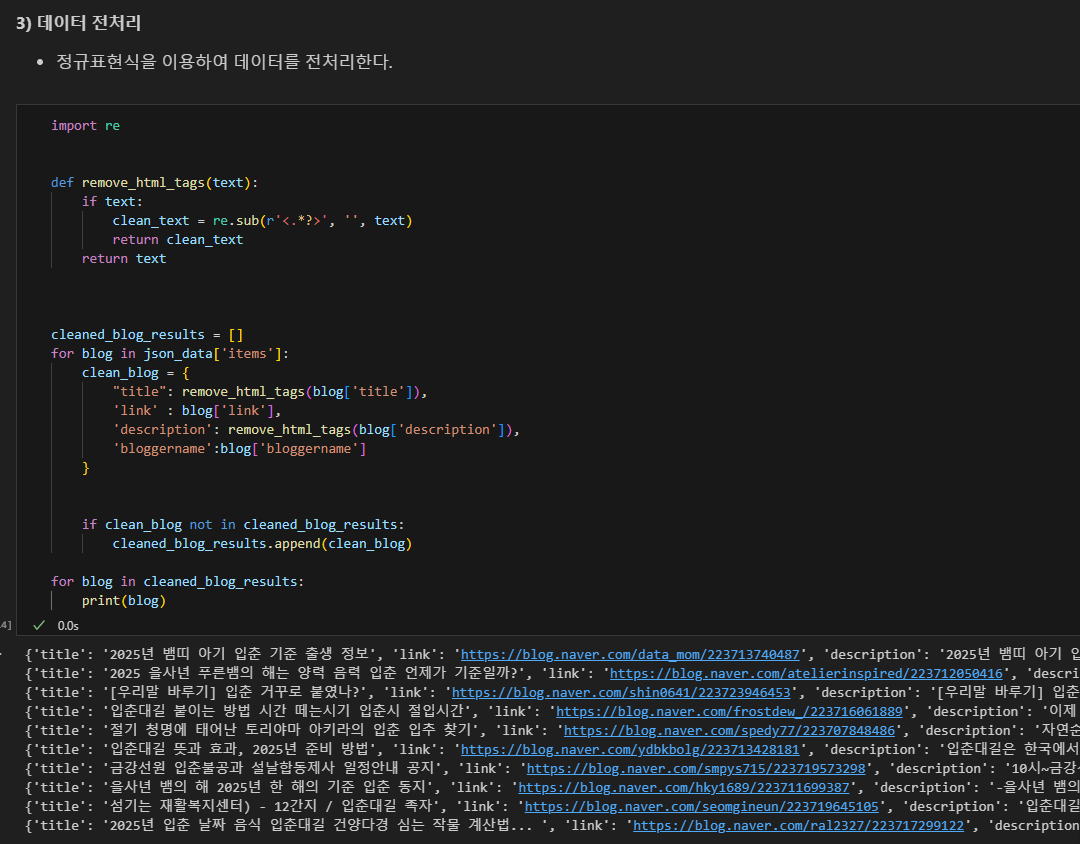
데이터 전처리
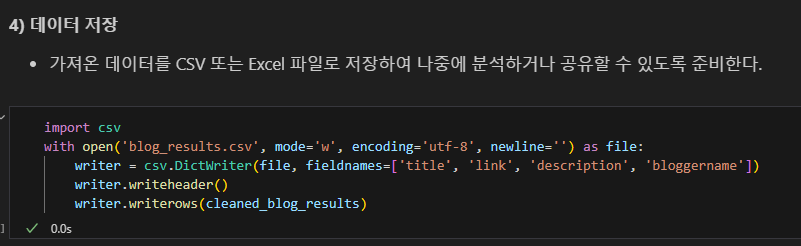
데이터 저장
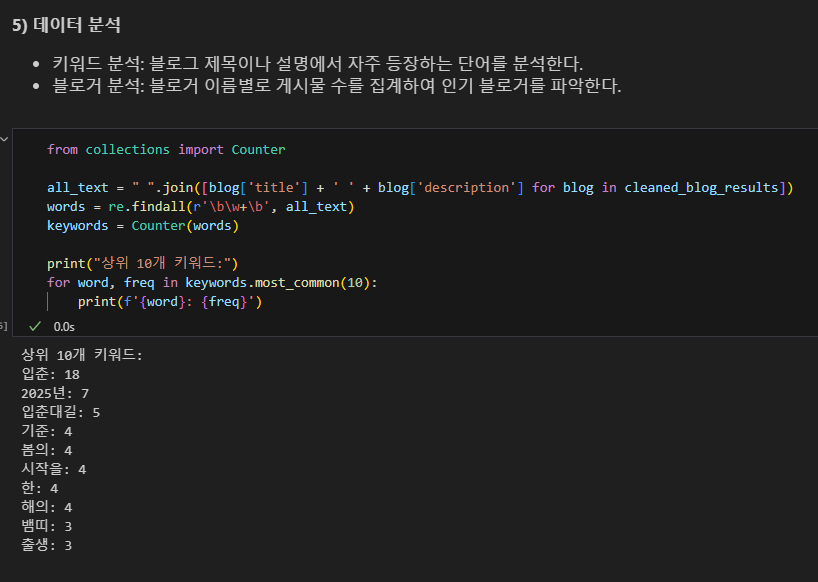
데이터 분석
이후 과정에서 머신러닝을 활용한 분석을 배울 것이다.
- 알고리즘 직접 짜보기
- 로지스틱 회귀(regression), KNN, 랜덤 포레스트, XG부스트(앙상블 기법) 등 알아보기
- 예측 분석
