1. Ensemble Model
프로젝트 진행 초기, Model Soup에 관한 내용을 Ensemble Model으로 오인하여, 설계를 진행
만들어진 모델(VGGNet, ResNet, EfficientNet, DenseNet, MNASNet, VIT)에 대해 Ensemble을 적용함.
앙상블 기법은 하나의 모델로는 원하는 성능을 낼 수 없을 때, 주로 정확도 향상을 위해 사용하는 기법입니다. 각 모델을 종합하여 예측을 하기 때문에, 과적합이 발생할 우려가 작으며, 개별적으로 학습시킨 여러가지의 모델의 결과값을 평균 내거나, 투표하는 방식을 이용해, Target 값을 추론해 내는 방식으로 진행합니다.
Bagging 방식의 Ensemble Model
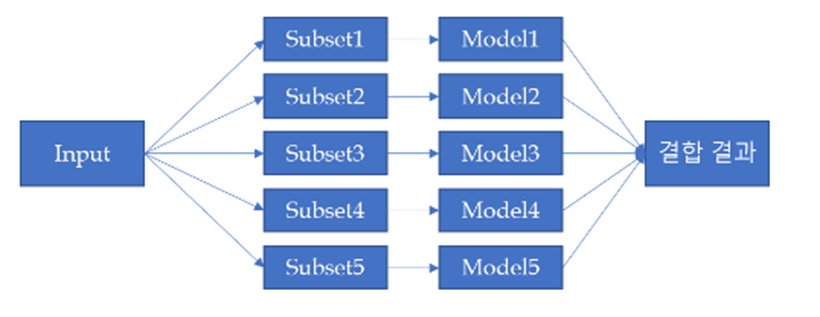
Bagging은 Bootstrap Aggregation의 약어로 전체 데이터 셋에 대해 복원 추출을 통해 모델을 학습시키고, 출력되어 나온 예측 값들을 Voting하여, 보다 더 높은 표를 받은 예측 값이 최종 예측 값이 되는 방식으로, 학습 데이터가 적더라도 높은 효율을 보인다는 장점을 가지고 있습니다.
제가 사용한 방법은 Soft Voting 방식으로 각각의 Softmax에서 나온 확률 예측값들을 모두 더한뒤 평균을 내고, 최종 예측값을 선택합니다.
### 라이브러리 생략 및 모델 선언 생략 ###
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
vit_outputs = torch.nn.functional.softmax(vit_model(inputs), dim=1)
resnet_outputs = torch.nn.functional.softmax(resnet_model(inputs), dim=1)
nasnet_outputs = torch.nn.functional.softmax(nasnet_model(inputs), dim=1)
vgg_outputs = torch.nn.functional.softmax(vgg_model(inputs), dim=1)
effnet_outputs = torch.nn.functional.softmax(effnet_model(inputs), dim=1)
densenet_outputs = torch.nn.functional.softmax(densenet_model(inputs), dim=1)
# 각 모델의 확률 예측값을 평균
soft_voting_probs = (vit_outputs+resnet_outputs+nasnet_outputs+vgg_outputs+effnet_outputs+densenet_outputs) / 6
# 최종 예측값 선택
ensemble_predictions = torch.argmax(soft_voting_probs,1)
total += labels.size(0)
correct += (ensemble_predictions == labels).sum().item()
accuracy = correct / total * 100
print(f"Test Accuracy: {accuracy:.4f}")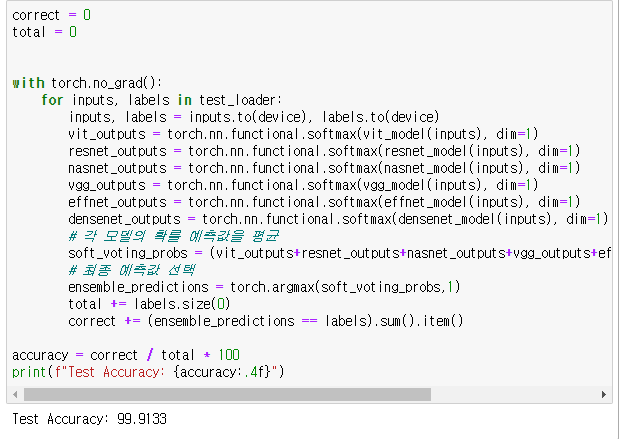
적용한 결과 99.9133%로 물론 높은 정확도를 보이지만, DenseNet이 단독으로 99.92%의 정확도를 보여준 것에 비해 다소 낮아진 정확도를 가지게 되었다.
하지만 여러가지 모델이 들어가기 때문에 인간으로 치면 집단지성에 가깝기 때문에, 상황에 따라선 매우 효과적인 모델일 것이라고 생각합니다.
2. Model Soup
기존에 Model Soup 과정을 Ensemble 모델의 Bagging 방식, Greedy Model Soup 과정을 Ensemble 모델의 Boosting 방식으로 생각하였지만, Greedy Model Soup 과정이 Boosting방식과 차이가 있다는 것을 발견, 이후 Model Soup 및 Greedy Model Soup 설계 진행을 하였습니다.
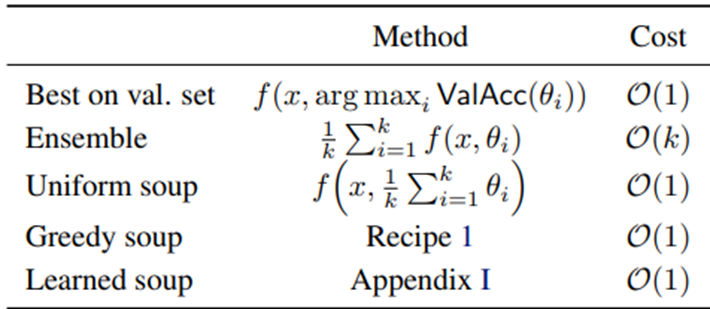
Ensemble 기법은 여러모델을 병렬로 사용하고, 각 모델의 출력을 평균화하면 훨씬 더 나은 성능을 얻을 수 있는 경우가 많기는 했지만, Model soup는 여러 모델이 아닌 하나의 모델에 여러 미세 조정 모델(주로 하이퍼 파라미터)의 가중치를 평균내면 추론 시간을 늘리지 않더라도 정확도가 향상 될 수 있다는 것을 나타내고 있습니다.
방식
하나의 모델에, 각각의 레이어에 대해서, 모든 레이어 가중치를 평균내어 사용하는 방식
이 때 중요한 것은 Greedy Model Soup를 적용할 때는 가장 정확도가 높은 네트워크를 가장 먼저 두는 것 (정확도 기준 내림차순)으로 정렬하는 것입니다.
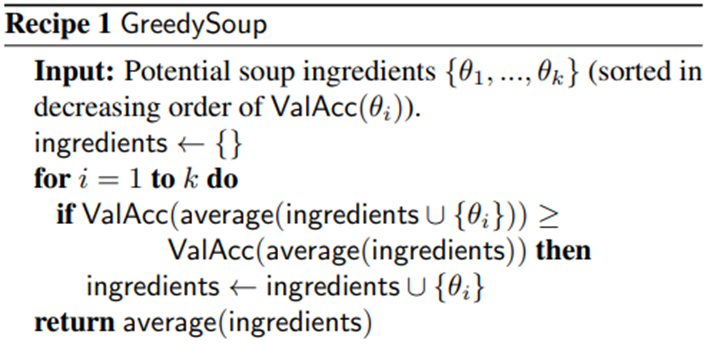
설계
설계의 시간적인 여유가 없어 Best Model이었던 DenseNet 4가지를 선정
Test 정확도 순서로 내림차순으로 정렬
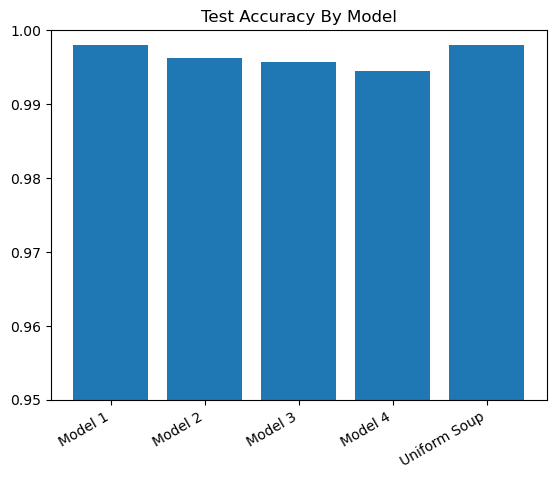
Model 1 = Densenet(Lr=0.0005) => accuracy 99.80%
Model 2 = Densenet(Lr=0.0003) => accuracy 99.62%
Model 3 = Densenet(Lr=0.0003 + rotate data) => accuracy 99.56%
Model 4 = Densenet(Lr=0.0001) => accuracy 99.44%
Model soup
4가지 모델을 한번에 가중치를 평균을 내는 작업을 시작
def get_model(state_dicts, alphal):
feature_dim=1024
num_classes = 5
model=define_model(file_name[0])
sd = {k : state_dicts[0][k].clone() * alphal[0] for k in state_dicts[0].keys()}
for i in range(1, len(state_dicts)):
for k in state_dicts[i].keys():
sd[k] = sd[k] + state_dicts[i][k].clone() * alphal[i]
model.load_state_dict(sd)
model = model.to(device)
return model해당 코드를 통해서 모델에 저장되어있는 가중치를 평균내는 작업을 거침
- featuredim = SoftMax바로 이전의 Layer의 output 차원 개수
- alphal = 1/입력 모델의 개수
Model Soup 결과
정확도 약 99.80% 이후 자세히 참조
Greedy Model soup
0~1 = (Model 1 + Model 2) / 2
0~2 = (Model 1 + Model 2 + Model 3) / 3
0~3 = (Model 1 + Model 2 + Model 3 + Model 4) / 4 = Model Soup
ranked_candidates = [i for i in range(len(state_dicts))]
ranked_candidates.sort(key=lambda x: -val_results[x])
current_best = val_results[ranked_candidates[0]]
best_ingredients = ranked_candidates[:1]
for i in range(1, len(state_dicts)):
# add current index to the ingredients
ingredient_indices = best_ingredients \
+ [ranked_candidates[i]]
alphal = [0 for i in range(len(state_dicts))]
for j in ingredient_indices:
alphal[j] = 1 / len(ingredient_indices)
# benchmark and conditionally append
model = get_model(state_dicts, alphal)
current = validate(model)
print(f'Models {ingredient_indices} got {current*100}% on validation.')
if current > current_best:
current_best = current
best_ingredients = ingredient_indices
alphal = [0 for i in range(len(state_dicts))]
for j in best_ingredients:
alphal[j] = 1 / len(best_ingredients)
model = get_model(state_dicts, alphal)
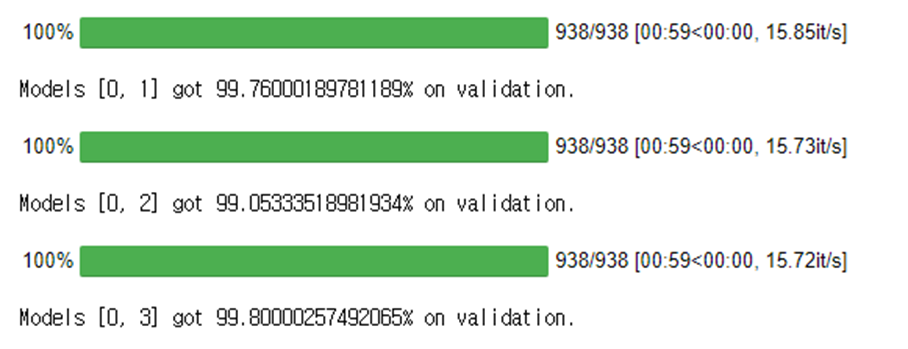
test_results.append(test(model))Greedy Model Soup 결과
Greedy Model Soup 1 => accuracy 99.76%
Greedy Model Soup 2 => accuracy 99.05%
Greedy Model Soup 3 => accuracy 99.80%
로 결과값이 나온 것을 확인할 수 있다.
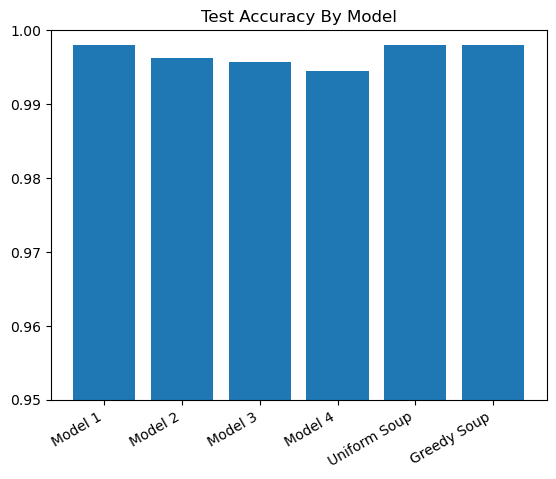
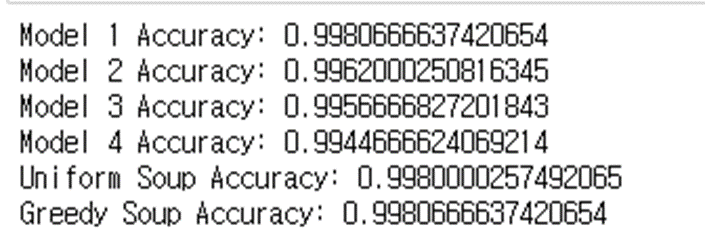
결과 검증
결과값이 매우 근소한 차이이므로 소숫점 두자리로 판별되지 않아 모든 소숫점을 출력하였습니다.
다음과 같이 모델들의 정확도를 출력해 보았을 때,
- 모델 1과 Greedy Model Soup의 정확도가 같다. => Greedy Model Soup 과정에서 Model 1의 정확도를 넘는 모델이 없었기 때문에, 정확도 면에서 가장 높은 Model 1 단독 모델이 Greedy Model Soup 출력으로 나옴
- Uniform Soup = Greedy Model Soup (0~3: Model 1 ~ Model 4) 모든 모델이 종합된 Uniform Soup 모델과 Greedy Soup모델의 결과가 일치한 것으로 보아 Model Soup 과정이 잘 진행된 것으로 간주
고찰
분명 해당 시도에서는 정확도의 상승을 이루지는 못하였지만, 추가적으로 모델의 Learning rate 뿐만 아니라, augmentation, epoch, 레이블 스무딩 등 많은 모델을 양산하여 Greedy Model Soup를 적용한다면 비약적인 성능향상을 기대해 볼 수 있을 것으로 예상함.

안녕하세요 재밌게 읽었습니다!! 논문과 서핑을 해보니 model soup은 다른 모델, 다양한 하이퍼파라미터를 다르게 사용 했을 때 더 큰 효과가 있다고 하는데 한번 적용해보시면 더 아름다운 결과가 있지 않을까 싶습니다! 이미 1개의 모델로도 충분히 좋은 성능이긴 하지만요..ㅎ