[미니 프로젝트] DL 3. 네트워크를 이용하여 3epoch 학습 Loss Graph 확인 및 결과 확인하기 (4) 결과 및 Graph 확인
[미니 프로젝트] Deep Learning
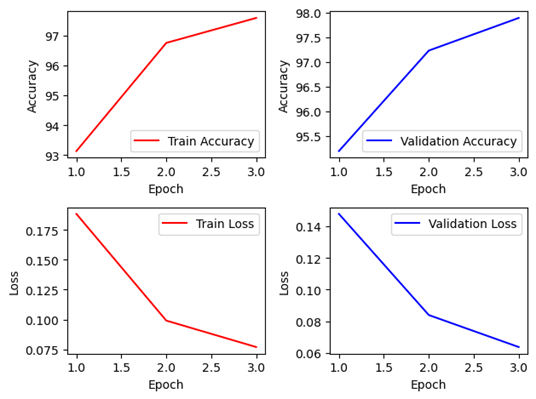
Graph는 Seed 고정 Pytorch만 첨부
1. VGG-16 (Lr=3e-4)
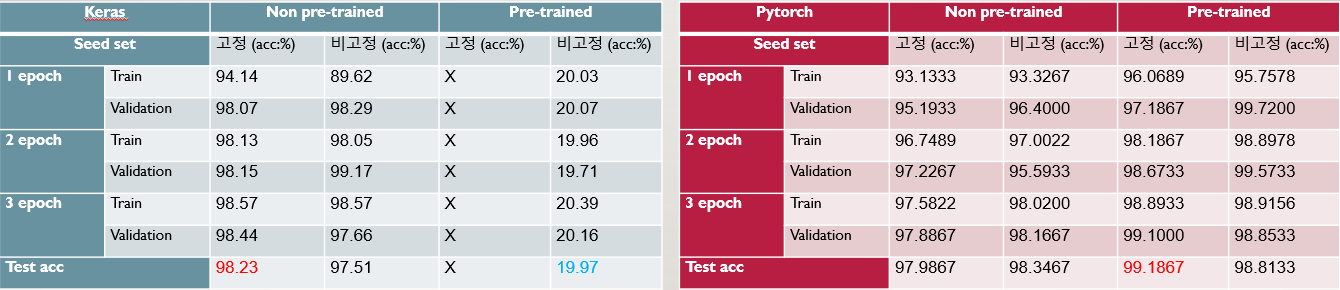
- Pytorch 에서 VGGNet의 Seed 고정의 결과를 가져온 것
 Non-Pretrained Non-Pretrained | 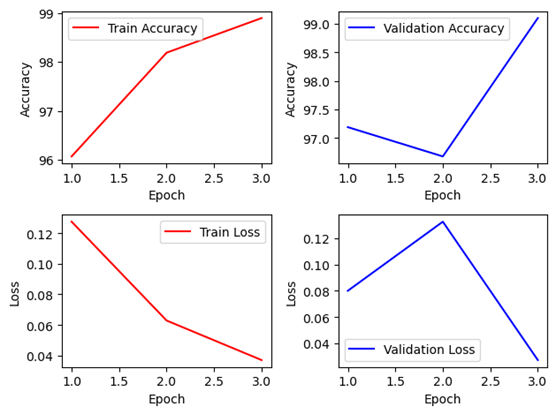 Pretrained Pretrained |
|---|
VGGNet은 다소 단순한 구조를 가지고 있기 때문에 Keras로 매우 단순하게 설계가 가능하다. 설계에는 그렇게 많은 시간이 들지 않았으며, 비록 Pretrained Keras 모델에서는 학습이 진행되지 않았지만, 이는 Learning rate를 바꿔가며 실험해보면 해결 가능할 것으로 보인다. Non-pretrained Keras 모델은 98%수준, Pretrained Pytorch 모델은 최대 99%이상의 정확도를 가지고 있다. 하지만 한 에폭당 841~893초 수준으로 조금 긴 정도에 속하고, 파라미터의 개수는 134,281,029개로 용량이 6개의 네트워크 중 가장 크다.
정리하자면, 모델의 크기, 용량적으로 매우 크고, 비용적으로 저렴하진 않지만, 설계가 간단하고, 학습 결과 역시 준수한 모습을 보이기 때문에 효과적인 모델 중 하나로 생각합니다.
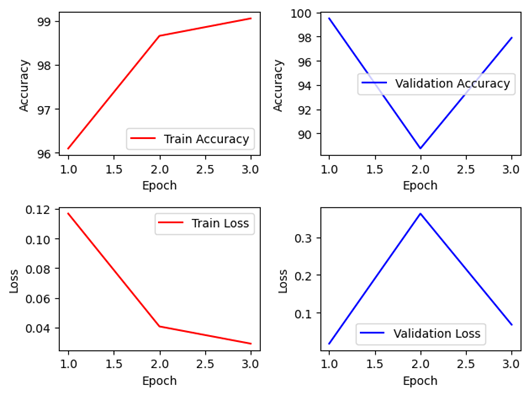
2. ResNet-50Layer (Lr=3e-4)
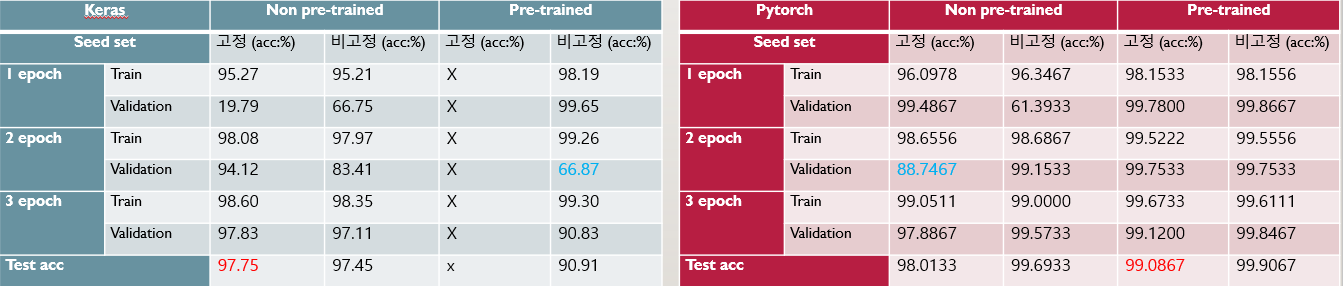
 Non-Pretrained Non-Pretrained | 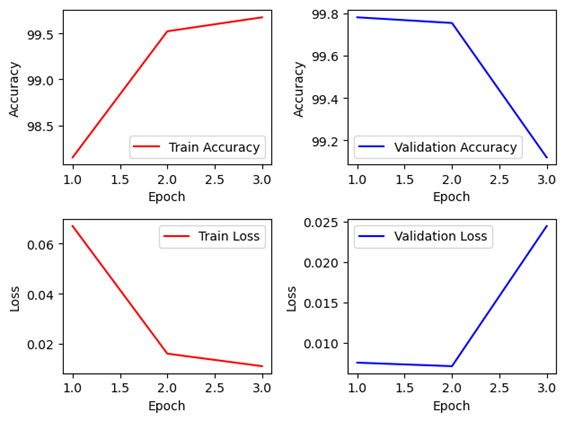 Pretrained Pretrained |
|---|
Keras 모델은 Non-Pretrained 모델의 경우에는 1epoch의 경우 Train에 비해 Validation이 매우 낮은 모습을 볼 수 있으나, 이후 에폭부터는 정상적으로 일반화를 하는 것을 볼 수 있다. Pretrained의 경우에는 1에폭에 이미 최고 정확도인 99.65%에 도달하였으나, 이후 에폭에서 급격한 하락이 있었다. 다소 다시 학습이 진행됨에 따라 정확도를 일부 회복하였으나, 1에폭에 비해 낮은 것을 보아 Overfitting이 났을 가능성이 높다.
Pytorch 모델은 Non-Pretrianed의 경우 99.7%까지 나오기도 하고, Pretrained의 경우 99.9%의 정확도를 가지고 있는 경우도 있었다. 매우 높은 정확도를 가지고 있으며, 설계는 비교적 단순한 편이고, Parameter수는 23,597,957개로 작지는 않지만 Global Average Pooling을 사용하기 때문에 VGGNet에 비해 상당히 파라미터의 수가 감소해 모델의 용량이 작으며, 에폭 당 588~593s 로 다소 짧은 학습 시간을 가지고 있다.
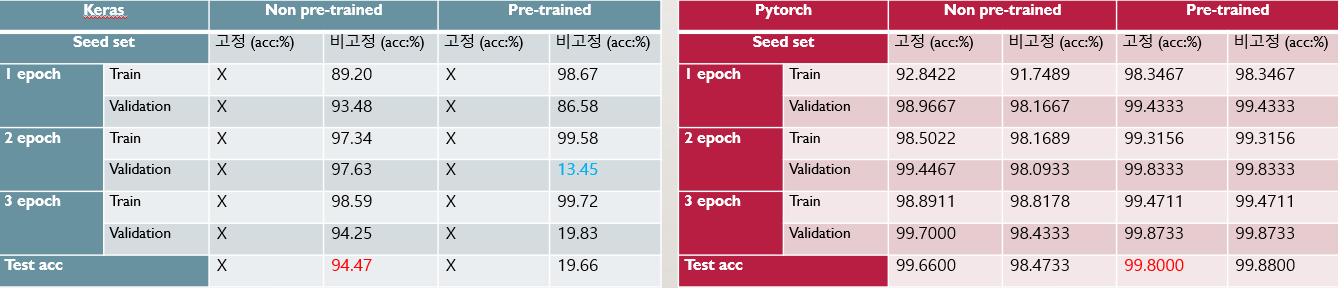
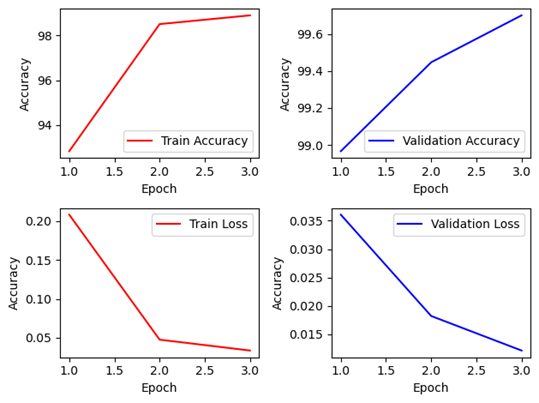
3. EfficientNet B0 (Lr=3e-4)
 Non-Pretrained Non-Pretrained | 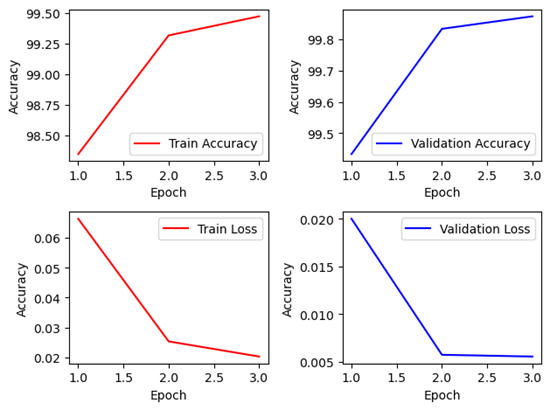 Pretrained Pretrained |
|---|
Keras 모델은 Non-Pretrained 모델의 경우에는 상당히 순조로운 학습이 진행되고 있는 것을 볼 수 있다. 하지만 학습에 수렴이 조금 늦어지는 것이 발견되어 다소 에폭이 조금 더 필요해 보이나, 에폭 당 학습 시간이 597~650초 수준으로 다른 네트워크에 비해 빠른 속도로 학습이 진행되었다. Pretrained 모델의 경우는 2에폭부터 Overfitting이 일어난 것으로 보이고, 학습이 전혀 진행되지 않은 모습 처럼 보이고 있다.
Pytorch 모델은 Non-Pretrained 모델의 경우 99.6% Pretrained 모델은 99.8%로 매우 높은 결과를 나타냈다.
에폭 당 597~650s, 파라미터는 4,055,976개로 모델의 용량이 매우 작고, 학습에 소요되는 시간도 적으며, Pytorch에서는 매우 높은 정확도를 기록하였다.
Compound Scaling을 통해서 효과적으로 파라미터 수를 줄이고 모바일의 환경에 맞추어, 용량을 줄이는 방법은 매우 효과적으로 작용한 것으로 보인다.
Keras모델에서, EfficientNet에서 Seed고정을 하기 위해os.environ['PYTHONHASHSEED']='1' os.environ['TF_DETERMINISTIC_OPS']='1' np.random.seed(5148) random.seed(5148) tf.random.set_seed(5148)해당 코드를 통해 시드를 고정하려 하였으나,
A deterministic GPU implementation of DepthwiseConvBackpropFilter is not currently available.라는 오류가 발생하여, 수행하지 못한 부분이 있다.
해당 문제는 Tensorflow에서 발생하는 GPU변수 제어에서 DepthwiseConvolution에서 발생하는 역전파(최적화)문제로 보이는 데, 해결하지 못하여 도중에 Pytorch를 주류로 사용하게 된 가장 큰 계기가 되었다.
4. DenseNet-121Layer (Lr=3e-4)
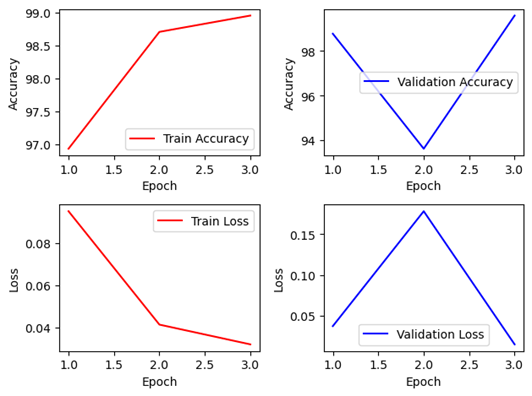 Non-Pretrained Non-Pretrained | 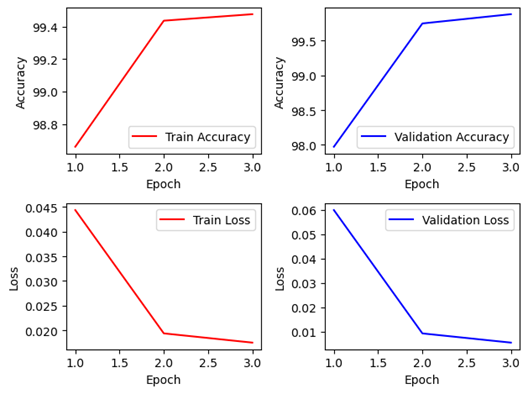 Pretrained Pretrained |
|---|
Keras 모델 Non-Pretrained의 경우엔 정확도 94%까지 나타났지만 2epoch에서 약 40%까지 감소한 모습을 보였다. 98%의 정확도를 유지하지 못하고 일부 데이터에서 일반화를 하는 과정에서 훈련 데이터에 최적화 하려 하다가 overfitting을 한 모습을 보이나, 이후 다시 정확도를 대부분 회복하였다. Pretrained의 경우는 초기에 일반화가 잘 되지 않는 모습을 보이다가, 이후 다시 어느정도 준수하게 올라온 모습을 보이지만, 전체적으로 Keras에서 Pretrained의 경우 Overfitting의 문제가 빈번히 발생하는 데, Learning rate를 전체적으로 조절하여 학습 속도를 조절할 필요가 있어 보인다.
Pytorch 모델에서는 Non-Pretrained와 Pretrained 모두 99% 정확도 이상으로 매우 높은 학습성과를 거두었습니다. 이후 해당 모델을 Best Model로 선정하여 설계를 추가적으로 진행하였습니다.
DenseNet은 파라미터수 7,042,629개로 앞서 나온 EfficientNet이나, NASNet에 비해서는 많지만, ResNet이나 VGGNet에 비해서 깊이는 매우 깊지만 파라미터 수는 많이 적어 모델의 용량 역시 작다. 뿐만 아니라 에폭당 시간도 617~632초 수준으로 학습에 걸리는 시간 역시 길지 않은 편에 속하고, 정확도도 매우 준수하게 나오는 것을 확인할 수 있다.
5. mobile NASNet (Lr=5e-4(Keras),3e-4(Pytorch))
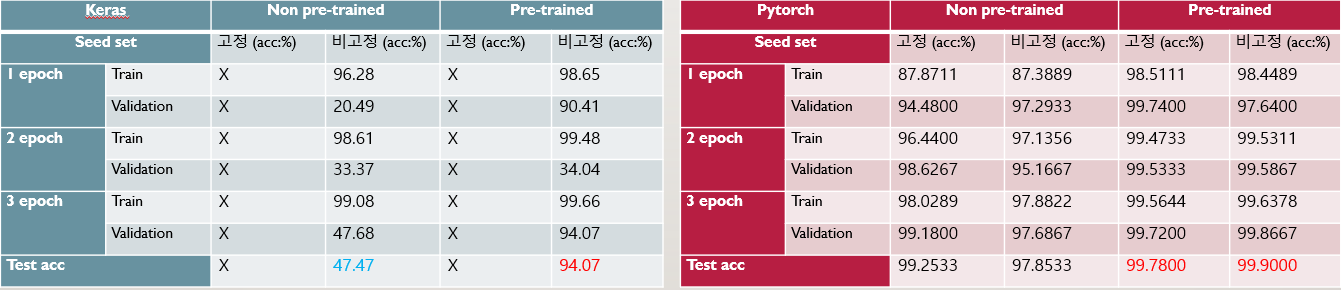
 Non-Pretrained Non-Pretrained | 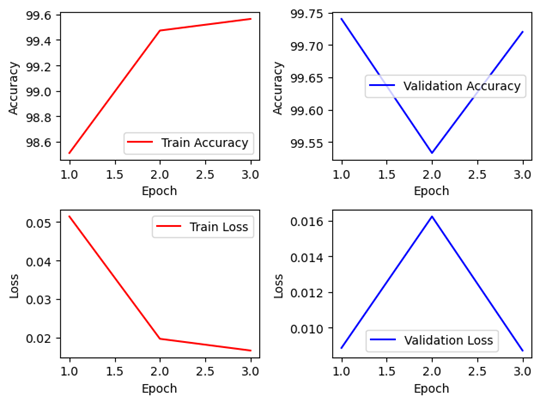 Pretrained Pretrained |
|---|
먼저 Keras 모델은 학습이 전혀 진행되지 않는 모습을 보여서 Learning rate를 조금 바꿔가며 실험해보았다. 먼저 MNASNet에서는 작은 데이터셋에 한계가 있는 부분이 있기 때문에, Non-Pretrained에서는 조금 낮은 정확도를 보이는 것을 부정하긴 어렵지만 반대로 학습자체는 원활하게 진행되고, Validation의 경우에서도 정확도가 낮은 속도로 오르고는 있다. 이후 epoch을 늘려서 실험한다면 성능이 좋을 수 있지만, Overfitting으로 이어질 가능성 또한 높다. Pretrianed의 경우에는 Keras 모델 중에서 다소 학습이 잘 진행되었으나, 2epoch에서 34%라는 많이 낮은 Validation정확도를 보이고 있기 때문에 일반화에 잠시 오류가 있었음을 생각해 볼 수 있다.
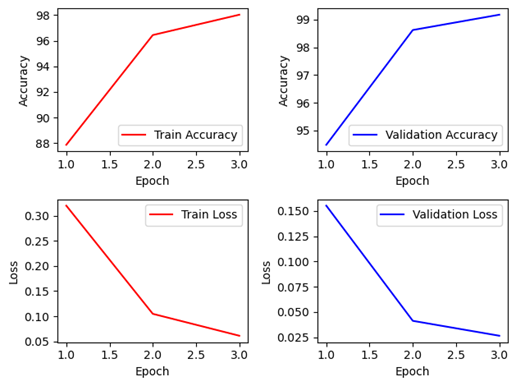
Pytorch에서는 Non-Pretraiend, Pretrained 모두 잘 학습이 진행된 것을 볼 수 있으나, 1epoch의 Train 정확도를 볼 때 확실히 앞서 설명한 CNN모델들에 비해서는 다소 정확도가 낮은 것을 확인 할 수 있다. 이를 통해 소규모 데이터 셋이었으면 해당 상황처럼 학습이 원활하게 진행되지 않을 수 있음을 확인할 수 있다.
파라미터 개수는 4,275,001개로 EfficientNet의 4,055,976개보다 조금 더 많은 수준이므로 용량적인 부분에서는 매우 큰 메리트가 있다. 에폭 당 646~659s수준으로 계산에 필요한 비용 자체는 EfficientNet보다 더 크다. 물론 해당 문제는 Seed, GPU사용 상황, RAM 등 여러가지 문제로 인해 바뀔 수 있지만, 현재 분석한 결과로서는 Parameter수, 계산 비용, 학습 시간이나 데이터 크기, 정확도적인 측면에서 EfficientNet이 MNASNet보다 좀 더 효율적인 네트워크로 보인다.
6. VIT_B16 (Lr=1e-3(Keras),3e-4(Pytorch))
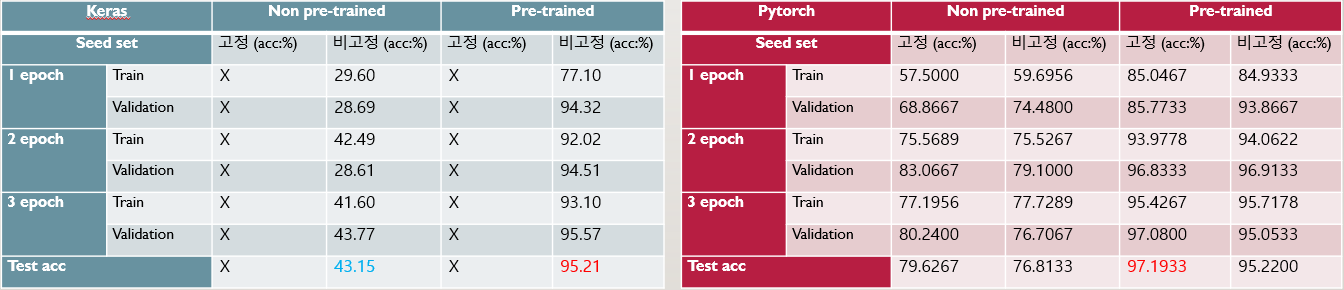
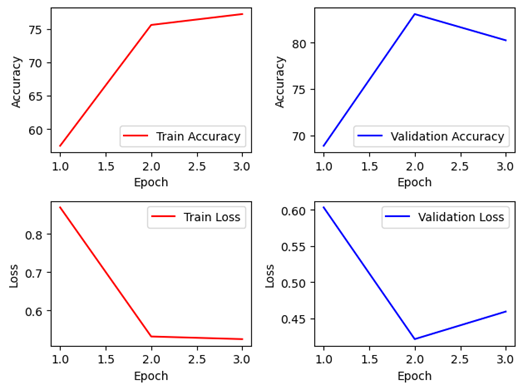 Non-Pretrained Non-Pretrained | 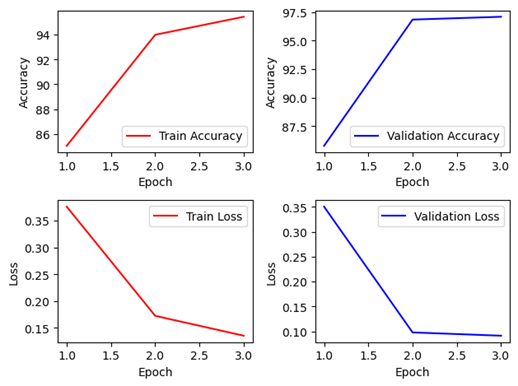 Pretrained Pretrained |
|---|
Keras.applications에는 VIT 네트워크가 없기 때문에,vit_keras라이브러리를 사용하여 진행
최초에는 VIT가 해당 네트워크들 중 가장 최근에 출시한 네트워크이기 때문에 가장 기대했으나, 전체적으로 기존의 CNN모델들이 좀 더 높은 성능을 가지고 있었다.
먼저 Keras에서는 Non-Pretrained의 경우에는 서서히 정확도가 상승하는 모습을 보였는데, 약 29%~ 43%까지 3에폭동안 지속적으로 증가하였다. 학습 속도 자체는 조금 느릴 뿐 학습은 원활하게 진행하는 것으로 보아 epoch을 늘린다면 좋은 성능을 가질 가능성이 높아 보인다. Pretrained의 경우에는 처음부터 Validation 94%수준의 정확도를 가지고 있어, 확실히 전이학습이 되지 않은 경우와 비교했을 때 월등한 차이를 보이고 있습니다.
Pytorch에서도 경향성은 비슷하게 나타났는데, 전이학습을 하지 않은 경우 15000장씩 5클래스 총 75000장이 적은 데이터셋은 아니지만, 80%수준으로 정확도가 상당히 낮다. 전이 학습을 한 경우에도 97% 수준으로 다른 CNN네트워크보다 낮은 수준의 정확도를 보여주고 있다.
앞서 네트워크 분석에서 나왔듯이 전역적인 이미지 학습에는 유리할 수 있으나, 반대로 지역적인 부분에선 다소 불리한 모습이 보이는 것으로 보이지만, 학슴이 정확도는 우상향을 보이는 것으로 보아 에폭을 더 늘리는 것으로 정확도를 더욱 상승시킬 수 있을 것이라 생각합니다.
하지만 효율적인 부분에서는 오히려 상당히 불리한 모습을 보였는데, Keras 기준 4GB로 메모리를 제한한 경우에는 시행되지 않아서, 6GB로 불가피하게 늘리게 되었으며, 파라미터 수는 85,802,501개로 VGGNet 다음으로 가장 무거운 모델이며, 에폭당 3014~3161s로 기존의 CNN에 비해 4~5배 시간이 걸린다. 즉, 모델의 용량, 낮은 정확도, 계산비용 등 모든 부분에서 해당 데이터를 학습하기에는 부적절한 네트워크에 가까운 것으로 보입니다.
