
MNIST
MNIST: 고등학생과 미국 인구조사국 직원들이 손으로 쓴 70000개의 작은 숫자 이미지를 모은 데이터 셋
핸즈온 머신러닝 교재에 있는 코드로 진행을 해보았는데, 계속 X에 key값을 넣을 때마다 에러가 발생해서 해결이 안되고 구글링해도 해결이 안되어서.. 일단 개념적인 것만 정리하도록 했다.
근데 책 코드만 보면 되게 사람이 0부터 막 코드를 짜는게 아니라 이미 되게 편하게 잘 발달되어있는 것 같았다. 뭔가 나는 당연히 0의 상태에서 찬찬히 막 올라오는 그런 느낌인 줄 알았는데.. 뭔가 생각보다 간편하게 되어있다고 해야할까? 그치만 나중에는 더더더 어렵겠고 복잡할 것 같은데 갈 길이 멀다고 생각하게 되었다.
이진 분류기 훈련
두 개의 클래스를 구분할 수 있는 것. 즉 5인지, 5가 아닌지 구분 한다는 것이다.
SGDClassifier클래스를 사용하여 확률적 경사 하강법(SGD) 분류기를 사용해본다.
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
>>> sgd_clf.predict([digit])
array([ True])
성능 측정
1. 교차 검증을 사용한 정확도 측정
가끔 사이킷런이 제공하는 기능보다 교차 검증 과정을 더 많이 제어해ㅇ할 필요가 있는데 이때는 교차 검증 기능을 직접 구현한다.
아래 코드는 사이킷런의 cross_val_score()함수와 거의 같은 작업을 수행하고 동일한 결과를 출력한다.
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits=3, random_state=42, shuffle=True)
for train_index, test_index in skfolds.split(X_train, y_train_5):
clone_clf = clone(sgd_clf)
X_train_folds = X_train[train_index]
y_train_folds = y_train_5[train_index]
X_test_fold = X_train[test_index]
y_test_fold = y_train_5[test_index]
clone_clf.fit(X_train_folds, y_train_folds)
y_pred = clone_clf.predict(X_test_fold)
n_correct = sum(y_pred == y_test_fold)
print(n_correct / len(y_pred)) # 0.9669, 0.91625, 0.96785 출력2. 오차 행렬
클래스 A의 샘플이 클래스 B로 분류된 횟수를 세는 것에서 온다.
실제 타깃과 비교할 수 있도록 먼저 예측값들을 만들어야 한다. 이때, 테스트 세트로 예측을 만들 수 있지만 여기서 사용하면 안된다. 대신 cross_val_predict()함수를 사용한다.
여기서 저번 KEEPER스터디에서 배웠던 내용이 나왔다.
혼동 행렬에서 나왔던 개념인데, 구글에 물어보니깐 오차행렬이 곧 혼동행렬이더라.. 그래서 위 하이퍼링크로 기록을 대체하겠다.
아래 그림은 보면 좀 헷갈리는 구분을 쉽게 그림으로 확인할 수 있어서 넣어뒀다.
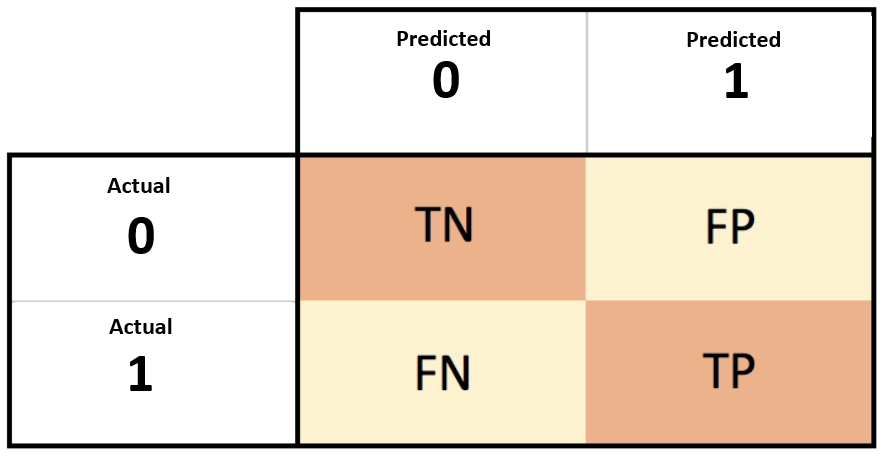
3. 정밀도와 재현율
핸즈온 머신러닝은 스터디에서 보지못한 개념으로, 조화 평균이라는 것을 소개한다. 곧, 점수화 하는 것을 이야기 하는 것 같아 보인다.
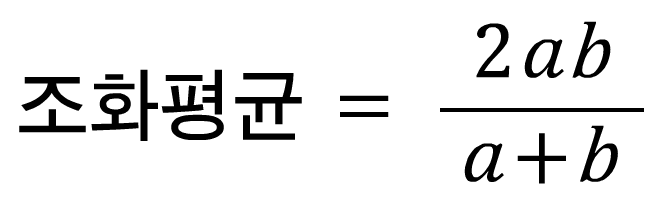
그냥 일반 수학.. 고딩때 했던 수학에서 나왔던 식이 저건데 a,b에 각각 정밀도와 재현율을 넣으면 된다. 그럼 결국에 점수가 된다.
당연한(?)것이지만 재현율과 정확도를 모두 얻는건 불가능에 가깝다. 재현율이 오르면 정밀도가 낮아지고 정밀도가 높아지면.. 재현율이 낮아지곤 한다. 이것을 정밀도/재현율 트레이드오프라고 한다.
4. ROC 곡선
수신기 조작 특성곡선은 이진 분류에서 널리 사용되는 도구라고 한다. 거짓 양성 비율에 대한 진짜 양성 비율의 곡선이다. 이때 양성으로 잘못 분류된 특성의 샘플의 비율이 FPR이라 한다. 이건 1에서 음성으로 정확하게 분류한 음성 샘플의 비율인 진짜 음성 비율을 뺀 값과 같다. 그리고 이 TNR(진짜 양성 비율)을 특이도라고 하며 결론적으로 ROC곡선은 민감도(재현율)에 대한 1-특이도그래프이다.
다중 분류
OvA전략: 이미지를 분류할 때 각 분류기의 결정 점수 중에서 가장 높은 것을 클래스로 선택하는 방법 (one vs all)
OvO전략: 각 숫자의 조합마다 이진 분류기를 훈련시키는 것 (one vs one)
