Contents
- Splitter (StratifiedKFold)
- Grid search (GridSearchCV)
1. Splitter (StratifiedKFold)
기본적으로 cross_validate() 을 사용하면 5-fold 로 나뉘는 것으로 저번 글을 마무리했었다. 만약 5-fold 말고 10-fold 로, 즉 오직 10% 의 데이터만을 이용해 검증을 하고 싶다면 어떻게 해야할까?
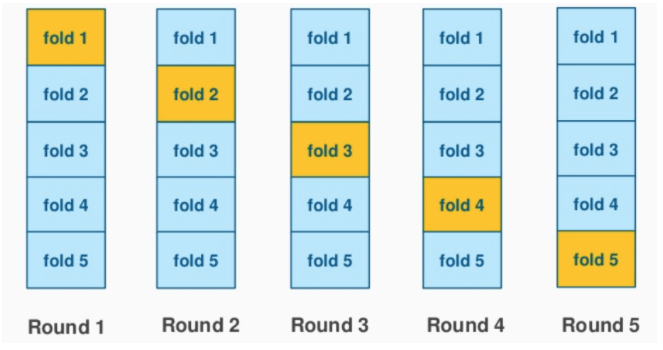
우선 cross-validate() 는 'cv' 라는 parameter 를 통해 splitting strategy 를 지정할 수 있도록 한다. 따라서 우리는 cv=10 과 같이 fold 의 개수를 지정해 줄 수도 있지만 이와 같은 hard-coding 방법은 권장되지 않는다. 대신 'StratifiedKFold' 의 object 로 'splitter' 를 만들어 n_split 에 int 를 지정해보자.
splitter = StratifiedKFold(n_splits=10, shuffle=True)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score'])) # 0.84240217874610962. Grid search
검증세트는 최적의 매개변수를 찾기 위한 목적으로 이용된다. 단, 일반적으로 어떠한 모델의 매개변수는 여러 개가 존재하기 때문에 그 조합이 중요하다. 이후 계속 교차검증으로 성능을 확인해야 하는데 반복문을 이용한다면 매우 번거로운 작업이 될 것이다. 대신 sklearn 에서 grid search 를 위해 제공하는 class 를 사용하도록 하자.
Grid search is a tuning technique that searches exhaustively through a manually specified subset of the hyperparameter space to find the best combination of hyperparameters for a given model.
Grid search 는 일정하게 매개변수 값을 바꿔가며 매번 교차검증을 수행해준다. 반면에 다음 글에서 다룰 random search 는 말 그대로 probability distribution 에 따라 독립적으로 고른 hyperparameter 를 바탕으로 tuning 한다.
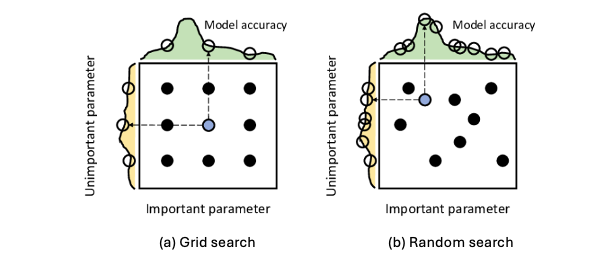
따라서 우리는 다음과 같이 parameters 를 dict 으로 만들어 GridSearchCV() class 에 넣어준 후 학습을 시킬 수 있다.
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs = GridSearchCV(DecisionTreeClassifier(), params, n_jobs=-1)
gs.fit(train_input, train_target)
print(gs.best_params_) # {'min_impurity_decrease': 0.0002}
print(gs.cv_results_['mean_test_score']) # [0.86703728 0.86953765 0.86761476 0.86357444 0.8624206 ]이때 bestparams 와 cvresults 는 검증세트에 대해서만 학습한 결과이고, cross-validation 은 최종적으로 훈련세트와 검증세트를 combine 하여 모델을 훈련해 얻은 값을 bestestimator 에 저장한다. 그렇기 때문에 우리는 bestestimator 를 통해 우리의 결정트리 estimator 를 재설정한 후 테스트해야 한다.
dt = gs.best_estimator_
print(dt.score(train_input, train_target)) # 0.9259187993072927이전에는 약 85% 의 score 를 보였다면, bestestimator 로 다시 학습한 모델은 약 92.6% 의 score 를 가지며 훨씬 개선되었음을 알 수 있다.
