Contents
- Validation set
- Machine learning workflow
- Cross-validation (CV)
- Splitter
1. Validation set
A validation set is a set of data used for training with the goal of finding and optimizing the best model to solve a given problem.
그동안은 기본적인 ML 모델들을 배우며 구현을 위해 훈련과 테스트를 위한 두 개의 세트로 데이터들을 나누었다. 하지만 ML 과 DL 모두 훈련세트를 한번 더 쪼개어 검증세트를 생성해 다음과 같이 총 세 개의 세트로 모델을 훈련하는 것이 바람직하다.
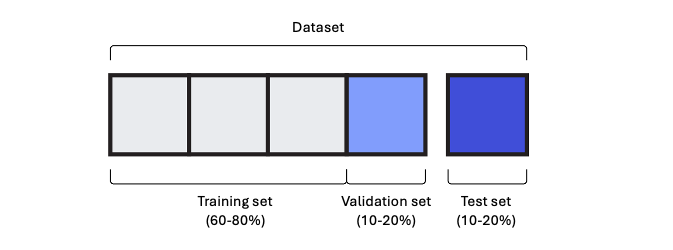
만약 훈련데이터의 양이 많아 validation set 을 충분히 확보할 수 있다면 그 비율을 줄일 수도 있다. 하지만 반대로 훈련데이터가 모자란다면 validation set 을 위해 10-20% 를 따로 두는 것이 좋지 않을 수 있다. 이때 우리는 교차검증을 통해 validation set 의 크기가 작더라도 신뢰할만한 점수를 얻을 수 있다.
2. Machine learning workflow
다음은 교차검증을 이용한 전체적인 machine learning workflow 이다. 먼저 모델 훈련은 training set 으로 수행하며, 최적의 매개변수들을 찾기 위해 validation set 을 이용해 반복적인 cross-validation 을 진행한다.
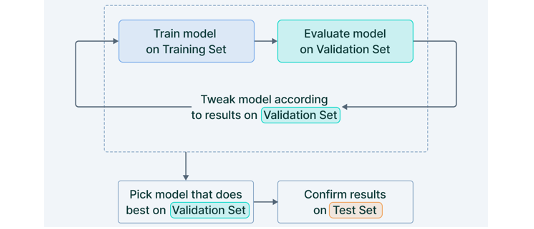
이를 바탕으로 훈련세트와 검증세트를 합쳐 최종적으로 모델을 학습시킨 다음 test set 를 제공한다면 unseen data 에 대한 모델의 성능을 보다 정확하게 판단할 수 있다. 하지만 test score 가 좋지 않아 이러한 일련의 과정을 다시 거치게 될수록 점수의 신뢰도가 떨어져 실제 성능과 멀어지게 될 수 있음에 유의해야 한다.
3. Cross-validation (CV)
Cross-validation is a statistical method of evaluating ML models by training on subsets of the available input data, "training set", and evaluating them on the complementary subset of the data, "validation set".
Cross-validation 은 주로 DL 에 비해 훈련데이터의 양이 막대하지 않은 ML tasks 에 사용된다.
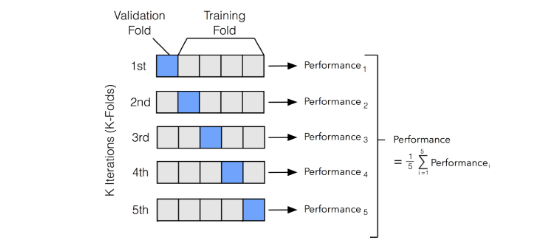
위의 cross-validation 과정은 실제로 sklearn 에서 제공하는 cross_validate() method 의 기본값인 5-fold 로 진행되었다. 따라서 각각의 fold 가 한번씩 validation set 이 되어 검증점수를 계산하면 이들의 평균을 신뢰할 수 있는 cross-validation score 로 간주하는 것이다. 다음 글에서 splitter 를 통해 직접 구간을 나누어보고 score 점수들을 확인해보자.
