TSLANet: Rethinking Transformers for Time Series Representation Learning
- Paper : https://arxiv.org/pdf/2404.08472
- Github : https://github.com/emadeldeen24/TSLANet
- ICML 2024
요약
- 주제 : 시계열 데이터를 분석하기 위한 컨볼루션 기반의 경량 + 노이즈 적응형 네트워크 제안함
- 배경 : 트랜스포머 기반 모델은 장기 의존성 포착에는 뛰어나지만, 소규모 데이터셋에서는 노이즈 민감도, 계산 효율성, 과적합 문제 등의 한계가 존재함
- Adaptive Spectral Block (ASB) : 푸리에 분석을 활용하여 특성 표현을 향상시키고, 적응형 임계값 처리 (adaptive thresholding)을 통한 고주파 노이즈를 완화함
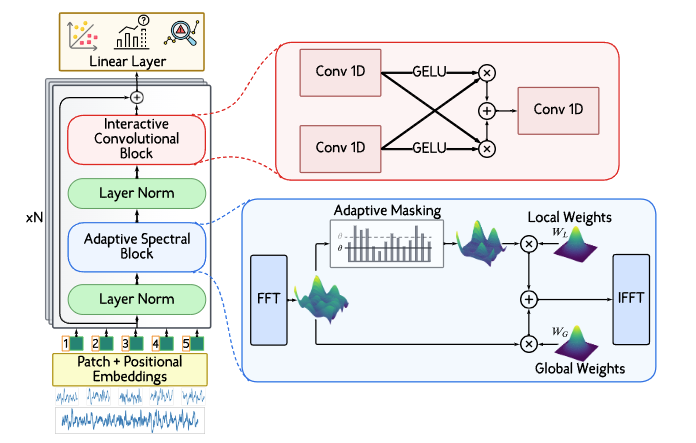
- Interactive Convolution Block (ICB) : 서로 다른 커널 크기를 가진 병렬 컨볼루션으로, 지역적 특징과 장기 의존성을 모두 포착할 수 있도록 구성함
- Self-Supervised Learning : 복잡한 시간 패턴의 해독 능력 및 다양한 데이터셋에서의 견고성을 향상함
배경
Transformer 계열 모델
- Attention 메커니즘은 시계열 데이터 내의 노이즈와 중복성에 취약함
- Self-Attention 메커니즘이 본질적으로 순서에 무관(permutation-invariant)하므로 시간 정보의 보존에 한계가 있음
- Position Encoding 으로 보완 가능하지만, 인코딩 방식에 따라 상대적/절대적 위치 정보가 다르게 반영될 수 있음
CNN 계열 모델
- CNN은 다양한 크기와 종류의 커널들로 인해 다양한 특징과 패턴을 효과적으로 감지하고, 분류 문제에서 우수한 성능을 보임
- 간단한 3-layer CNN 네트워크가 최신 Transformer 기반 아키텍처와 비교해 분류에서 더 뛰어난 성능을 보임 (Dataset : UEA)

- 하지만 CNN의 예측 성능은 주기가 긴 데이터의 경우
- 10분 단위의 짧은 주기를 갖는 Weather 데이터셋에서 Transformer 계열과 비슷한 성능을 보임
- 시간 단위의 긴 주기를 갖는 ETTh1 데이터셋에서는 낮은 성능을 보임
⇒ "어떻게 하면 CNN의 강인한 성능을 더 다양한 시계열 작업으로 확장할 수 있을까?"
모델 아키텍처
Adaptive Spectral Block (ASB)
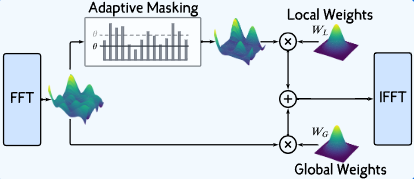
- FFT (푸리에 변환)
- 1D FFT를 적용하여 주파수 도메인으로 변환함
- 각 채널은 독립적으로 변환되어, 원래 시계열의 스펙트럼 특성을 담는 데이터 를 생성함
- 고주파 노이즈의 학습 가능한 Threshold
- 고주파 성분은 근본적인 변동 추세나 관심 신호에서 벗어난 빠른 변화로, 성능에 악영향을 미침
- 데이터셋 특성에 따라 필터링 강도를 동적으로 조절할 수 있는 적응형 로컬 필터를 제안함
- 파워 스펙트럼 는 각 주파수 성분의 크기의 제곱()으로 계산함
- 학습 가능한 임계값 를 이용해 파워 스펙트럼 의 고주파 성분을 적응형으로 필터링함
- 파워()가 임계값 이상인 주파수에서 1(유지), 아니면 0(제거)인 바이너리 마스크를 적용함
- 학습 가능한 필터
- 적응적으로 필터링된 주파수 도메인 데이터에 대해, 두 종류의 학습 가능한 필터를 적용함
- 원본 주파수 데이터 에서 학습하는 전역 필터
필터링된 데이터 에서 학습하는 로컬 필터
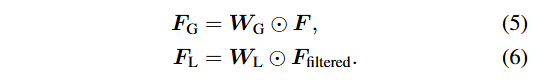
- 필터링된 특징을 결합하여, 종합적인 스펙트럼 정보를 얻음
- IFFT (역 푸리에 변환)
- 최종적으로 필터링 및 결합된 주파수 도메인 데이터를 다시 시간 도메인으로 변환하기 위해, IFFT를 적용함
- IFFT는 특성 추출 후의 특성이 원래 시계열 입력의 데이터 구조와 일치하도록 보장함
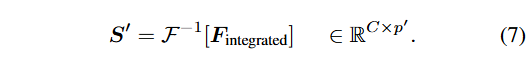
Interactive Convolution Block (ICB)
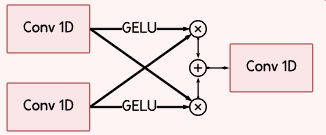
- 서로 다른 커널 크기를 가진 병렬 컨볼루션으로, 지역적(local) 특징과 장기 의존성(long-range dependency)를 모두 포착할 수 있도록 구성함
- 첫 번째 컨볼루션 레이어는 작은 커널을 사용해 미세하고 국소적인 패턴을 포착하고,
두 번째 레이어는 더 큰 커널을 활용해 넓은 영역의 장기적 의존성을 식별함
Self-Supervised Pretraining
- Masked Auto Encoder 방식으로 pretrain 함
- 단일 시간 스텝 단위의 마스킹 방법을 적용하지 않고, 패치 단위로 마스킹 함
- 입력 시퀀스 패치의 일부를 마스킹한 뒤, TSLANet을 학습시켜 마스킹된 패치를 복원하도록 함
실험 결과
Classification

- Transformer 모델은 장기 시계열 데이터 CNN 모델보다 낮은 성능을 보임
Forecasting
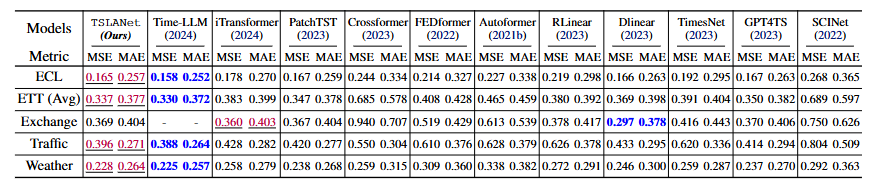
- 비교 모델 :
- Transformer 기반 모델 : iTransformer, PatchTST, Crossformer, FEDformer, Autoformer
- MLP 기반 모델 : RLinear, DLinear
- 범용 시계열 모델 : TimesNet과 GPT4TS
- 합성곱 기반 예측 모델 : SCINet
- LLM 기반 모델 : Time-LLM (Llama-7B)
- Time-LLM이 더 높은 성능을 보이지만, 계산 비용은 TSLANet에 비해 훨씬 높음
Anomaly Detection

- Transformer 기반 모델들이 이상 탐지에서는 상대적으로 효율성이 떨어짐
- TimesNet이나 FEDformer처럼 주기성을 고려하는 모델은 비정상 패턴 탐지에서 뛰어난 성능을 보임
5. 모델 분석
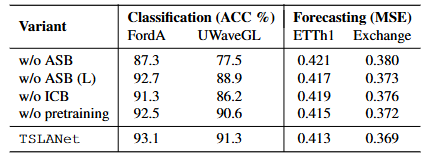
- Adaptive Spectral Block(ASB)을 제거하면 성능이 크게 저하됨
- 특히 ASB-L(적응형 로컬 부분)을 제외하면, 잡음이 많은 데이터셋에서 성능 저하가 더욱 두드러짐
- pretraining은 하는게 더 좋음

MedicalAI Researcher