Convolution
CNN은 Convolution layer, polling layer, fully connected layer로 이루어져 있다.
Convoluiton layer와 pooling layer는 feature extraction 즉 유용한 정보를 추출한다.
Fully connected layer는 decision making 즉 classification 혹은 regression .. 으로 원하는 출력값을 만든다.
*모델의 파라미터수가 클수록 학습이 어렵고 generalization performance가 떨어져 fully connected를 줄이는 추세이다.(fully connected layer의 파라미터가 많다) CNN의 목표는 deep하지만 parameter는 줄이는 것이다.
용어
- stride: convolution filter를 얼마나 자주 dense or sparse하게 찍을지를 말한다.
- padding: 가장자리 convolution operation하기 위한 것으로 양끝에 0을 추가해주는 것이다.
1x1convolution 사용이유: 파라미터의 수를 줄이면서 depth를 깊게함
Modern CNN
CNN의 목표: 파라미터는 적고 깊이는 깊어지고 성능은 좋아지는 방법
- AlextNet
ReLU activation을 사용하여 gradient vanishing x
multi gpu
Data augmentation
Dropout
- VGGNet
3x3 convolution filters 사용
→ 좋은이유? 5x5한번한것보다 3x3 두번계산한게 파라미터수가 더 적음. 즉 3x3여러번이 좋다.
- GoogLeNet
1x1 Conv 사용(Inception Block)
→ 좋은이유? 파라미터수를 줄일 수 있음. channel-wise dimension reduction을 하기 때문에 파라미터수가 줄어든다.
- ResNet
https://phil-baek.tistory.com/entry/ResNet-Deep-Residual-Learning-for-Image-Recognition-논문-리뷰 참고
당시 문제점: deep한 네트워크는 학습하기 어려움, 파라미터수가 증가함에 다라 overfitting 문제
해결법: Add an identity map(skip connection: f(x) → x + f(x) )
f(x)가 학습하는 것은 그 차이만 학습하길 원하는 것이다.

기존의 네트워크는 입력 x를 받아 layer를 거쳐 H(x)를 출력하는데 이는 입력값 x를 타겟값 y로 mapping하는 함수 H(x)를 얻는 것을 목적으로 한다. 하지만 residual learning은 입출력의 차인 H(x) - x를 얻도록 목표를 수정한다. 따라사 F(x) = H(x) - x를 최소화하고 출력과 입력의 차이를 줄인다는 의미가 된다.
f(x) = H(x) - x (구하고자 하는 함수: f(x))
H(x) = f(x) + x = x이므로 H(x)에 대해 x로 미분해도 f’(x) + 1이기 때문에 기울기가 1 이상으로 gradient vanishing 문제를 해결한다.
- DenseNet
ResNet의 +를 Concat으로 바꾼다.(+를 하면 두개값이 섞이기 때문)→ 문제: 파라미터가 기하급수적으로 증가
→ 해결: 문제를 1x1conv를 이용하여 해결한다
Computer Vision Applications
Sementic Segmentation(자율주행 활용)
- FCN(Fully Convolutional Network)
dense layer를 없애고 convolutionalization을 했다.
convolutionalization을 한 이유? convolution이 가지는 shared parameter 때문이다. shared parameterd의 동작이 히트맵같다.
output demension이 subsampling으로 작아지므로 다시 들려야한다. (Deconvolution,정확하게 복원되지는 않는다.)
Detection
- R-CNN
- 이미지를 받아들이고
- 구간을 자른다
- 각 구간에 대해 feature를 계산한다.
- svm로 분류한다.
단점: 이미지 안에서 구간을 뽑으면 그 이미지를 다 cnn통과시켜야한다.
- SPPNet
idea: 이미지 내에서 CNN한번만 돌리자
→ 방법: 입력 이미지의 크기에 관계없이 conv layer들을 통과하고 FC layer 통과 전에 피쳐맵들을 동일한 크기로 조절하자
이미지 내에서 bounding box를 뽑고, 이미지 전체에 대해 feature 맵을 만든 후 bounding box에 해당하는 부분에 대해서 텐서를 추출한다.
- Fast R-CNN
2000개의 bounding boxes를 가진다. cnn feature맵을 구하고 각 부분에서 ROI(reasonable interest )pooling을 한다. output은 class 와 bounding box regresser이다.(bounding box를 어디로 움직이면 좋을지, bounding box에 대한 label)
- Faster R-CNN
Fast R-CNN과 다른것:
Region Proposal Network; 특정 영역이 bounding box로 의미가 있을지 찾아준다. 미리 정해놓은 bounding box의 크기→ template를 고정하는 역할
9개의 채널을 가진다
4개의 boundary box regression parameters를 가짐(x, y, w, h)
2개의 box classification(use or not)
- YOLO
bouning box와 class probability를 동시에 예측한다.
reason propose에 대한 step이 없다.(차이점)
이미지를 sxs grid로 나눈 후 (1번: Bounding 박스와 객체인지 confidence 예측, 2번:각 cell의 class 예측) 객체의 중심이 grid cell안에 위치하면 해당 grid cell이 중점에 있는 object가 어떤 클래스인지 예측한다.(즉 1번과 2번을 종합한다)
텐서의 크기는 SxS(B*5+C)이다. SxS:그리드의 수, B는 x, y, w, h, confidence, C는 클래스의 수
Recurrent Neural Network
Sequential Model
- Navie sequence model: 길이가 길어질수록 고려해야할 정보량이 많아짐
- Autoregressive model: 자기회기, 과거의 몇개만 봄
- Markov model(first-order autoregressive model) 바로 직전 정보에만 dependent하도록함, joint distribution으로 표현하기 쉬움
- Latent autoregressive model: 중간에 과거의 정보를 summary하는 hidden state를 넣는다.
RNN
xt에만 의존하는 것이 아닌 이전 t-1 cell state까지 dependent하게 한다.(recurrent한 구조) 하지만 short term dependencies의 문제가 있다.(먼 과거의 정보가 살아남기 힘들다. 왜냐면 중첩되는 구조로 gradient가 죽는다.)
LSTM(Long Short Term Memory)
idea: cell state는 컨베이어 벨트에서 어떤걸 올릴지, 어떤걸 뺄지에 대한 정보를 취합한다.

https://sooftware.io/lstm_gru/
(Cell) state: 내부에서만 흘러간다. 정보를 summary해주는 역할이다.
Hidden state: 이전 output
Forget gate: hidden state와 input으로부터 어떤 정보를 지울지 결정한다.
Input gate: 입력이 들어왔는데 이 정보 중 어떤 정보를 올릴지 결정한다.(현재 정보를 기억하기 위한 게이트)
Output gate: 어떤 값을 밖으로 내볼낼지에 해당하는 output gate를 만들고 output gate만큼 곱해서 ht로 흘러가게 된다.
GRU(Gated Recurrent Unit)
기존에 LSTM은 파라미터가 많다는 단점이 있었음
LSTM의 게이트를 사용하며 매개변수를 줄여 계산시간을 줄인다.
- 게이트를 reset gate와 update gate만 사용하여 구조를 단순화 한다.
- cell state를 사용하지 않고 hidden state 즉 과거 output을 넣는다.
결과적으로 적은 파라미터를 이용하여 동일한 output을 낸다. : 일반화 성능이 높아졌다.
RNN(문제: Long term dependency x)→게이트 사용한 LSTM(parameter너무많음)→게이트중 하나 없앤 GRU
Transformer
Sequential model을 학습하는데 어려운 것들
trimmed sequence(앞뒤로 잘린거)
omitted sequence(중간에 빠진거)
permuted sequence(순서가 이상한거)
Transformer
RNN(재귀적인 구조)과 달리Transformer는 attention이라는 구조를 활용한다.
가정
- 입력 sequence와 출력 sequence는 길이가 다를 수 있음
- 입력 sequence와 출력 sequence는 도메인이 다를 수 있음
- 모델은 하나의 모델을 사용한다.
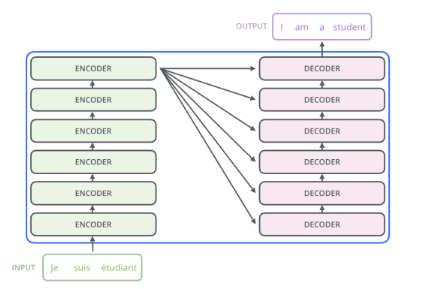
https://hyen4110.tistory.com/40
구조가 재귀적이지 않아 n개의 단어를 한번에 처리할 수 있는 구조이다.
중요한점!
- n개의 단어가 encoder에서 어떻게 처리되는지
- decoder와 encoder 사이에 어떤 정보를 주고받는지
- decover가 어떻게 generation할 수 있는지
Self Attention은 encoder와 decoder에서 아주 중요하다!!
동작원리
- 입력값 임베딩(RNN을 사용하지 않으려면 위치 정보를 포함하고 있는 임베딩을 사용해야 한다. 이를 위해 트랜스포머에서 positional encoding을 사용한다.)
- encoder: 임베딩이 끝난 이후에 어텐션을 진행, 어텐션은 각각의 단어가 어떤 연관성을 가지고 있는지 구하기 위해서 사용한다. 즉 문맥에 대한 정보를 잘 학습하도록 만드는 것임, 성능 향상을 위해 residual learning을 사용한다. 여기서 어텐션과 정규화(normalization)과정을 반복하는데 각 레이어는 서로 다른 파라미터를 가진다. 입력값과 출력값의 demension은 동일하다!!!
- 인코더와 디코더: 한층의 디코더 레이어에서 두개의 어텐션을 사용한다. 트랜스포머에서의 마지막 인코더 레이어의 출력이 모든 디코더 레이어에 입력된다., 디코더 파트의 두번째 어텐션에서 각각의 출력단어가 입력단어중에서 어떤 단어와 높은 관련성을 가지는지 계산하도록 만들어줌
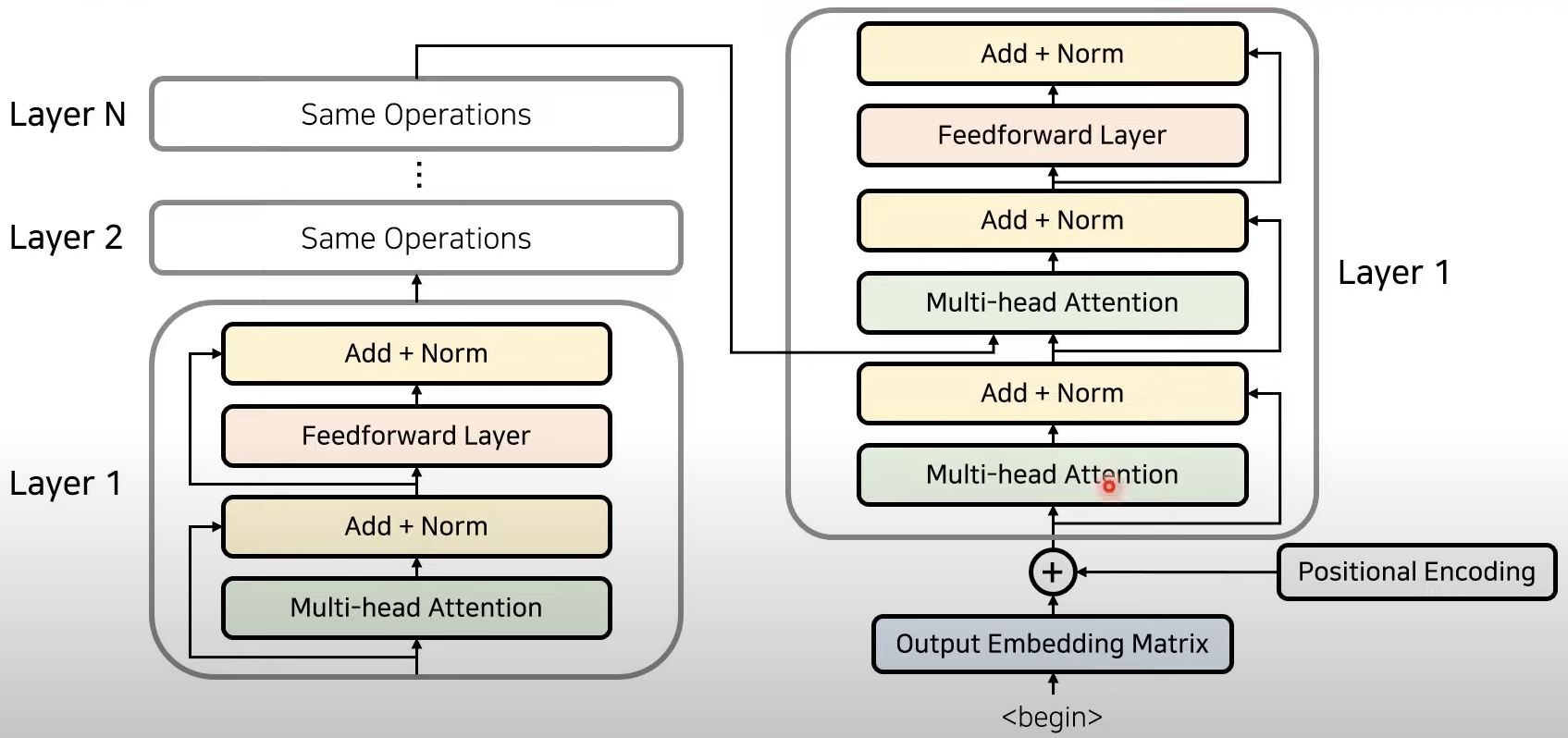
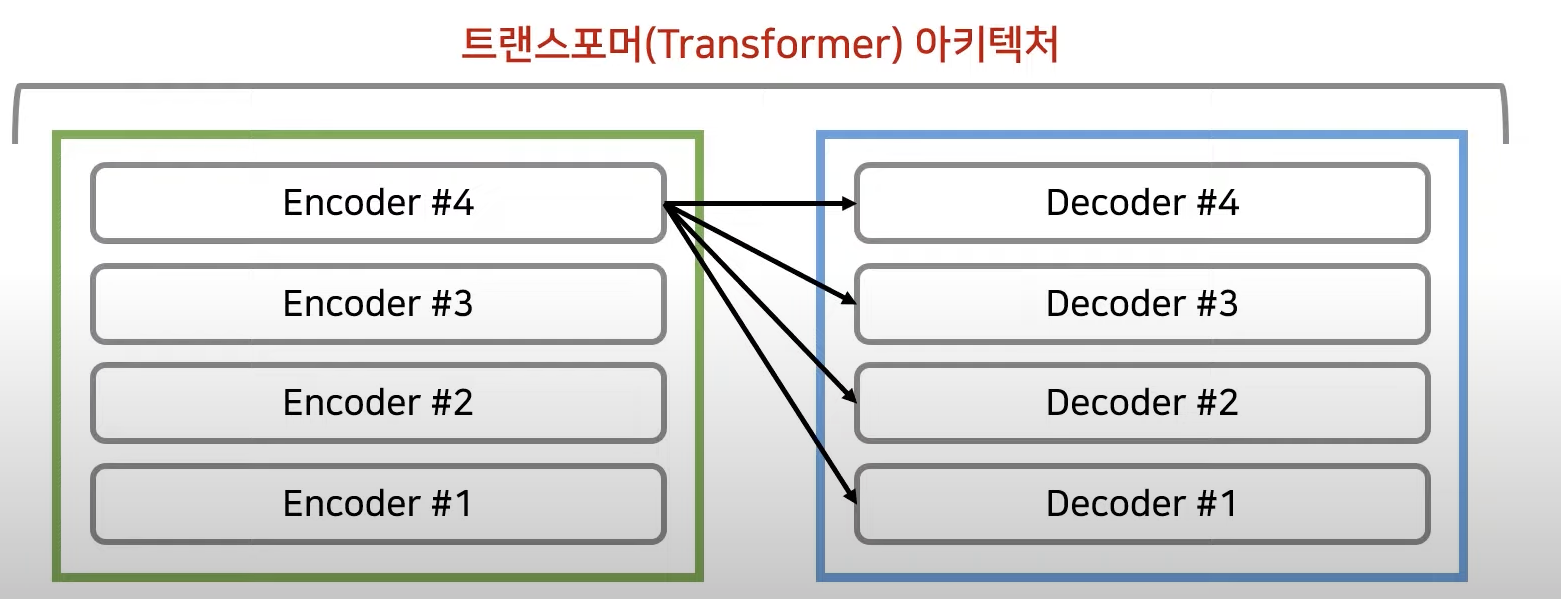
https://www.youtube.com/watch?v=AA621UofTUA
Generative Models
Generative model을 학습하는 것이란?
강아지들 사진이 주어져있다고 가정해보자
우리가 probability distribution p(x)를 학습하기를 원했을 때
Generation: 우리가 p(x)로 부터 sample_x를 뽑았을 때 그것은 개와 닮아야 한다.
Density estimation: sample_x가 강아지와 와 닮았다면 p(x)는는 커야하고 반대의 경우 작아야 한다.
Basic Discrete Distribution
우리가 rgb single sample을 모델링한다하면 경우의 수는 256256256이다. 이 경우에 우리는 256^3-1개의 파라미터를 필요로한다.(Categorical distribution (주사위)생각..)→ 파라미터가 셀수없이 많다.
Structure Through Independence
binary image(mnist)에서 우리가 필요한 파라미터의 수는 2^n-1이다. 근데 만약 서로의 픽셀이 독립적이라면 우리가 필요한 파라미터는 n개로 줄어든다.
→ 독립을 가정했을 경우 파라미터를 줄이지만 유의미한 분포를 모델링할 수 없고, 그렇지 않을 경우에는 고려해야할 파라미터수가 너무 많아 근사할 수 없다.
Conditional Independence
세가지 중요한 공식 활용
- Chain rule
P(X1, ..., Xn) = P(X1)P(X2 | X1)P(X3 | X1, X2)⋯P(Xn | X1, ⋯, Xn−1)
→ 독립 여부와 상관없이 항상 만족한다.
- Bayes’rule
p(x|y) = p(x,y)/p(y) = p(y|x)p(x)/p(y)
- Conditional independence
If x ⊥ y|z, then p(x|y,z) = p(x|z) → z가 주어졌을 때만 x와 y가 independent
→ Markov assumtion(바로앞만 dependent)을 가정했을 때 필요한 파라미터의 수는 2n-1이다
p(x1) 한개 p(x2|x1)은 두개, 왜냐면 x1이 0 or 1 그 다음도 마찬가지..
Autoregressive models는 conditional independency를 적용한다
Autoregressive Model
28x28픽셀의 흑백 이미지를 가지고 있다 했을 때 우리의 목표는 를 근사하는 것이다. 이를 Parametrize하기 위한 방법은?
chain rule을 사용할 수 있다.
여기서 어떤 식으로 condition을 주는지에 따라서 구조는 달라질 수 있다.
Maximum Likelihood Learning
likelihood: 파라미터가 주어졌을 때 그 데이터와 얼마나 likely한지 나타낸 것
training set이 주어졌을 때 학습할 수 있는 분포의 경우로부터 그 분포와 내가 학습할 수 있는 거리를 최소화 하는 방향으로 최적화하는 모델을 찾음으로써 generative model을 학습하는 것
데이터가 적으면 정확하지 않음, 데이터가 많을수록 분산이 작아진다.
Latent Variable Models(VAE)
AutoEncoder이 생성모델인가? No, Autoencoder는 입력이 들어오면 압축시키고 압축된 데이터를 복원시키는 것이다.
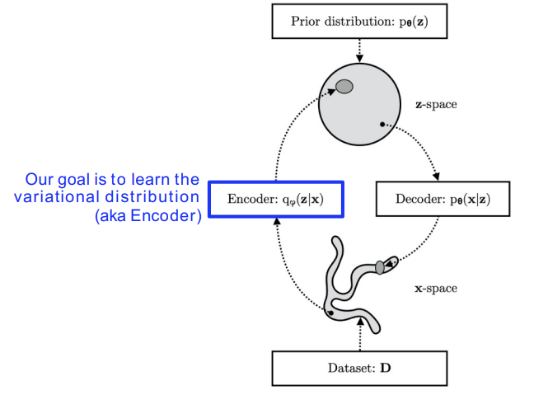
- Variational inference
VI의 목표는 찾고자 하는 분포가 너무 복잡해서 모델링 할 수 없을 때 분포를 찾을 수 있는 간단한 분포로 근사하는 것이다. 즉 우리는 true posterior(실제분포)과의 KL divergence를 줄이는 variational distribution(우리가 만드는 간단한 분포)을 찾길 원한다.
Generative Adversarial Networks
- GAN은 generator와 discriminator 사이의 minmax game을 하는 것이다.
화폐위조자는 그럴듯한 위조화폐를 만들고 경찰은 위조화폐를 더 잘 구분한다.
Diffusion Models
노이즈로 부터 이미지를 만드는 모델이다.
- Forward(diffusion) process: 이미지에 노이즈를 점차 추가한다.
- reverse process: 노이즈가 있는 데이터로부터 깨끗한 이미지로 가도록 denoise
참고: Boostcamp AI Tech 4기 DL Basic 최성준 교수님 강의
