시작하며
오늘은 파이썬 및 데이터 파트의 마지막 내용인 데이터 시각화에 대해서 배웠다. 지금까지 그래프를 그려는 봤지만 시각화에 대해서 본질적으로 배워본 것은 처음이라 많은 것을 배운 하루였다.
탐색적 데이터 분석
- 모델 학습에 앞서 분석 대상 데이터셋의 구조와 특성을 이해하기 위해 수행
- 다양한 기술통계량을 계산하고, 그래프를 통해 데이터의 분포와 변수 간 관계를 확인
데이터 정렬 sort_values()
ascending: 정렬 방향 지정ignore_index: 인덱스 초기화 여부 지정
apt['층'].sort_values(ascending=False)apt.sort_values(by=['층', '거래금액'], ascending=[False, True])NumPy와 Pandas 집계 함수 비교
| 구분 | NumPy | Pandas |
|---|---|---|
| 개수 | np.size(a=sr) | sr.count() |
| 합계 | np.sum(a=sr) | sr.sum() |
| 평균 | np.mean(a=sr) | sr.mean() |
| 중위수 | np.median(a=sr) | sr.median() |
| 분산 | np.var(a=sr) | sr.var() |
| 표준편차 | np.std(a=sr) | sr.std() |
| 최솟값 | np.min(a=sr) | sr.min() |
| 최댓값 | np.max(a=sr) | sr.max() |
주로 Pandas 함수 사용
agg 메서드
- 여러 집계 함수 한번에 사용
시리즈
apt['거래금액'].agg(func=['count', 'sum', 'mean', 'std'])
# count 2.208900e+05
# sum 2.233578e+06
# mean 1.011172e+01
# std 7.461396e+00
# Name: 거래금액, dtype: float64- 인덱스 이름 지정
apt['거래금액'].agg(func={'개수': 'count','합계': 'sum','평균': 'mean','표준편차': 'std'})
# 개수 2.208900e+05
# 합계 2.233578e+06
# 평균 1.011172e+01
# 표준편차 7.461396e+00
# Name: 거래금액, dtype: float64데이터프레임
apt.select_dtypes(include='number').agg(func=['mean', 'std'])
# 거래금액 입주년도 계약년도 계약월 계약일 전용면적 층 경과년수 세대수 주차대수
# mean 10.111720 2002.322215 2021.735869 6.221241 15.823908 75.471219 9.534578 19.413654 1065.668079 1175.280823
# std 7.461396 10.396538 1.643023 3.134888 8.666083 30.573625 6.370747 10.336370 1253.131045 1614.546846범주별 집계 함수
groupby()
apt.groupby(by='시군구')['거래금액'].count().sort_values(ascending=False)cond = apt['시군구'].eq('강남구')
apt[cond].groupby(by='법정동')['거래금액'].mean().sort_values(ascending=False)groupby() + agg()
apt.groupby(by=['시군구', '계약년도'])['거래금액'].agg(func=['mean', 'std'])pivot_table()
data: 데이터프레임 지정index: 행이름에 적용할 범주형 변수명 지정columns: 열이름에 적용할 범주형 변수명 지정values: 집계 함수로 요약할 연속형 변수명 지정aggfunc: 집계 함수를 문자열 또는 numpy 함수로 지정margins: 행과 열 합계를 마지막 열, 행에 추가margins_name: 합계 이름 지정
변수 및 함수가 두 개 이상이면 리스트로 지정
pd.pivot_table(
data=apt,
index='시군구',
columns='계약년도',
values='거래금액',
aggfunc=['mean', 'std'],
margins=True,
margins_name='합계'
)도수 / 상대도수 확인
범주형 변수 확인 nunique() , unique()
nunique(): 중복을 제거한 고유값 개수 반환
apt['시군구'].nunique()
# 25unique(): 중복을 제거한 고유값 확인- 원본 데이터의 순서대로 고유값을 나열
apt['시군구'].unique()
# array(['강남구', '강동구', '강북구', '강서구', '관악구', '광진구', '구로구', '금천구', '노원구',
# '도봉구', '동대문구', '동작구', '마포구', '서대문구', '서초구', '성동구', '성북구', '송파구',
# '양천구', '영등포구', '용산구', '은평구', '종로구', '중구', '중랑구'], dtype=object)- 범주별 도수 확인
normalize: True 지정 시 상대도수 반환
apt['시군구'].value_counts().sort_index()
# 시군구
# 강남구 12291
# 강동구 11958
# 강북구 4875
# 강서구 13610
# 관악구 6911
# 광진구 4176
# 구로구 10966
# 금천구 3976
# 노원구 19204
# 도봉구 8323
# 동대문구 9181
# 동작구 8325
# 마포구 8888
# 서대문구 7958
# 서초구 9963
# 성동구 9228
# 성북구 11995
# 송파구 14186
# 양천구 9032
# 영등포구 10486
# 용산구 4023
# 은평구 9064
# 종로구 2058
# 중구 3119
# 중랑구 7094
# Name: count, dtype: int64두 범주형 변수 확인
cols = ['시군구', '계약년도']
apt[cols].value_counts()
# 시군구 계약년도
# 노원구 2020 8386
# 강서구 2020 5703
# 구로구 2020 4532
# 송파구 2020 4532
# 성북구 2020 4316
# ...
# 금천구 2022 270
# 강북구 2022 267
# 용산구 2022 242
# 중구 2022 193
# 종로구 2022 166
# Name: count, Length: 125, dtype: int64apt[cols].value_counts(normalize=True) * 100
# 시군구 계약년도
# 노원구 2020 3.796460
# 강서구 2020 2.581828
# 구로구 2020 2.051700
# 송파구 2020 2.051700
# 성북구 2020 1.953914
# ...
# 금천구 2022 0.122233
# 강북구 2022 0.120875
# 용산구 2022 0.109557
# 중구 2022 0.087374
# 종로구 2022 0.075151
# Name: proportion, Length: 125, dtype: float64sort_index()적용
apt[cols].value_counts().sort_index()
# 시군구 계약년도
# 강남구 2020 3555
# 2021 2175
# 2022 861
# 2023 2264
# 2024 3436
# ...
# 중랑구 2020 2709
# 2021 1589
# 2022 413
# 2023 868
# 2024 1515
# Name: count, Length: 125, dtype: int64reset_index()적용
apt[cols].value_counts().sort_index().reset_index()
# 시군구 계약년도 count
# 0 강남구 2020 3555
# 1 강남구 2021 2175
# 2 강남구 2022 861
# 3 강남구 2023 2264
# 4 강남구 2024 3436
# ... ... ... ...
# 120 중랑구 2020 2709
# 121 중랑구 2021 1589
# 122 중랑구 2022 413
# 123 중랑구 2023 868
# 124 중랑구 2024 1515
# 125 rows × 3 columns교차 테이블 생성 crosstab()
pd.crosstab()index: 행이름에 적용할 시리즈 지정columns: 열이름에 적용할 시리즈 지정normalize: True를 지정하면 셀 값별, ‘index’를 지정하면 행별, ‘columns’를 지정하면 열별 상대도수 반환margins: 합계 추가margins_name: 합계의 이름 지정dropna: 결측값 삭제 여부(기본값 True)
pd.crosstab(
index=apt['시군구'],
columns=apt['계약년도'],
normalize='index',
margins=True
).tail()
# 계약년도 2020 2021 2022 2023 2024
# 시군구
# 은평구 0.371690 0.183914 0.070609 0.151920 0.221867
# 종로구 0.344509 0.215258 0.080661 0.149174 0.210398
# 중구 0.319333 0.187881 0.061879 0.172812 0.258096
# 중랑구 0.381872 0.223992 0.058218 0.122357 0.213561
# All 0.361144 0.187138 0.052560 0.153022 0.246136기술통계량 및 이상치
기술통계량 확인 describe()
apt.describe(include=[int, float]).round(2)
# 거래금액 입주년도 계약년도 계약월 계약일 전용면적 층 경과년수 세대수 주차대수
# count 220890.00 220890.00 220890.00 220890.00 220890.00 220890.00 220890.00 220890.00 220890.00 220890.00
# mean 10.11 2002.32 2021.74 6.22 15.82 75.47 9.53 19.41 1065.67 1175.28
# std 7.46 10.40 1.64 3.13 8.67 30.57 6.37 10.34 1253.13 1614.55
# min 0.62 1961.00 2020.00 1.00 1.00 10.78 -3.00 -2.00 1.00 0.00
# 25% 5.70 1996.00 2020.00 4.00 8.00 59.64 5.00 12.00 259.00 241.00
# 50% 8.30 2002.00 2021.00 6.00 16.00 79.20 9.00 20.00 668.00 654.00
# 75% 12.40 2010.00 2023.00 8.00 23.00 84.96 13.00 26.00 1372.00 1401.00
# max 220.00 2024.00 2024.00 12.00 31.00 317.36 68.00 60.00 9510.00 12602.00apt.describe(include=object)
# 단지명 시도명 시군구 법정동 지번 재건축
# count 220890 220890 220890 220890 220890 220890
# unique 6191 1 25 332 5131 2
# top 현대 서울특별시 노원구 상계동 1013 부족
# freq 1928 220890 19204 7130 1111 183056이상치 처리 replace() , clip()
ages = pd.Series([-1, 0, 2, 3, 15])
ages.replace(15, 5)
# 0 -1
# 1 0
# 2 2
# 3 3
# 4 5
# dtype: int64
ages.replace([-1, 0], 1)
# 0 1
# 1 1
# 2 2
# 3 3
# 4 15
# dtype: int64ages.clip(1, 5)
# 0 1
# 1 1
# 2 2
# 3 3
# 4 5
# dtype: int64정적인 시각화
데이터 시각화 개요
- 데이터 시각화는 단순히 데이터를 차트로 표현하는 기술이 아니라, 데이터를 이해하고 정보를 다른 사람에게 명확하게 전달하는 커뮤니케이션 도구
- 데이터 시각화는 수치형 데이터를 시각적 언어로 번역하는 작업
- 데이터에 담긴 정보를 쉽고, 빠르고, 정확하게 전달하는 것
- 상대방의 판단과 행동을 변화시키는 것이 데이터 시각화의 궁극적인 목적
데이터 리터러시와 시각화의 관계
- 데이터 리터러시는 데이터를 읽고, 이해하고, 해석하는 능력
- 비교를 통해 의미를 해석해야만 좋다, 나쁘다를 판단할 수 있음
- 대표적인 비교는 개인 / 집단, 현재 / 과거
- 기술통계량은 비교를 위한 도구
- 데이터 시각화는 데이터 리터러시를 완성하는 커뮤니케이션의 기술
인지적 특성과 시각 요소
- 그래프를 해석할 때 시각 요소별로 위치, 길이, 각도, 면적, 부피, 채도 순서로 인지
- 위치와 길이 기반의 그래프가 데이터 비교에 적합
Data Ink Ratio
- 불필요한 장식을 최소화하고, 데이터의 본질에 집중하는 것
데이터 시각화 종류
- 히스토그램 : 일변량 연속형 변수의 도수분포표에 사용
- 막대가 서로 붙어 있으며 막대의 총면적은 확률 1을 의미
- 상자 그림 : 일변량 연속형 변수의 분포에 사분위수와 이상치를 추가
- 집단 간 연속형 변수의 분포를 비교할 수 있음
- 막대 그래프(크기 비교)
- 일변량 막대 그래프 : 범주형 변수의 도수를 그린 그래프(x, y 중 하나만 사용)
- 이변량 막대 그래프 : 범주형 변수에 따라 연속형 변수의 크기 비교(x, y 전부 사용)
- 선 그래프 : 시간에 따라 연속형 변수의 변화를 표현
- 산점도 : 이변량 연속형 변수의 선형관계를 점으로 표현
- 선형 회귀분석의 입력변수와 목표변수에 직선의 관계가 존재하는지 확인
- 히트맵 : 여러 변수 간 관계의 크기를 색의 분포로 표현
- 다중공선성 문제를 확인 가능
데이터 시각화(정적 데이터)
matplotlib & seaborn
- matplotlib
- Python의 가장 기본적인 시각화 라이브러리
- 개별 그래프 요소를 세밀하게 조정가능
- 코드가 길고 복잡할 수 있음
- seaborn
- matplotlib 기반으로 동작하는 고수준 시각화 라이브러리
- 보기 좋은 기본 테마를 제공
- 짧은 코드로 통계 그래프를 쉽게 그릴 수 있음
matplotlib.pyplot.rc Property
| 속성 | 별칭 | 상세 내용 |
|---|---|---|
linewidth | lw | 선의 두께를 지정 |
linestyle | ls | 선의 형태를 지정 |
color | c | 데이터 요소(점, 선, 막대 등)의 색을 지정 |
facecolor | fc | 데이터 요소의 채우기 색을 지정 |
edgecolor | ec | 데이터 요소의 테두리 색을 지정 |
markeredgewidth | mew | 점의 테두리 두께를 지정 |
antialiased | aa | 픽셀 단위로 표현된 선이나 면의 가장자리를 부드럽게 보정 |
한글 폰트
- 원하는 폰트 리스트 확인
font_list = fm.findSystemFonts(fontext='ttf')
font_path = [font for font in font_list if 'Gowun' in font]
font_path
# ['/Users/taehyunan/Library/Fonts/GowunBatang-Bold.ttf',
# '/Users/taehyunan/Library/Fonts/GowunBatang-Regular.ttf',
# '/Users/taehyunan/Library/Fonts/GowunDodum-Regular.ttf']- 폰트 이름 확인
for font in font_path:
print(fm.FontProperties(fname=font).get_name())
# Gowun Dodum
# Gowun Batang
# Gowun Batang- rc로 폰트 설정
- rc : runtime configuration, matplotlib이 동작하는 중에 환경 설정하는 코드
plt.rc(group='font', family='Gowun Batang', size=10)
plt.rc(group='figure', figsize=(8, 4), dpi=120)
plt.rc(group='axes', unicode_minus=False)
plt.rc(group='legend', frameon=True, fc='0.9', ec='0.9')폰트 설정 오류 시 matplotlib 캐시 파일 삭제 및 폰트 설정 json 삭제 필요
fm._load_fontmanager(try_read_cache=False)
좋은 시각화를 위한 색 사용
- 색은 메시지를 전달하는 주요 대상에만 제한적으로 사용
- 하나의 색에는 하나의 의미만 부여
- 색상 수는 5개 미만으로 최소화
- 기본 요소에는 낮은 채도의 색을, 강조할 요소에는 높은 채도의 색을 사용
- 의미 없는 배경색은 사용 X
그래프 png 파일로 저장
plt.savefig('test.png', bbox_inches='tight', pad_inches=0.1)png 파일 렌더링 및 삭제
from IPython.display import Image
Image('test.png')
os.remove('test.png')Color Palette
- 기본 팔래트 확인
sns.color_palette()- 기본값 변경
sns.set_palette('Set1')- 컬러맵 목록 조회
dir(plt.cm)사용자 팔레트
- 리스트로 생성
mypal = ['lightgray', 'royalblue', 'orangered']
sns.color_palette(mypal)- 딕셔너리로 생성
sns.histplot(
data=apt,
x='거래금액',
binwidth=2,
binrange=(0, 60),
hue='재건축',
ec='0',
palette={
'부족': 'lightgray',
'충족': 'royalblue'
}
);선의 형태
| 구분 | 이름 | 기호 | 대시 튜플 |
|---|---|---|---|
| 실선 | solid | ‘-’ | ‘’ |
| 파선 | dashed | ‘--’ | (4, 1.5) |
| 1점 쇄선 | dashdot | ‘-.’ | (3, 1, 1,5, 1) |
| 점선 | dotted | ‘:’ | (1, 1) |
marker 종류
| un-filled markers | 채우기와 테두리 색 일체형, color만 가능 | filled markers | 채우기와 테두리 색 별도, face, edge 다 가능 |
|---|---|---|---|
‘.’ | 1 | ‘o’ | ‘p’ |
‘,’ | 2 | ‘v’ | ‘*’ |
‘1’ | 3 | ‘^’ | ‘h’ |
‘2’ | 4 | ‘<’ | ‘H’ |
‘3’ | 5 | ‘>’ | ‘D’ |
‘4’ | 6 | ‘8’ | ‘d’ |
‘+’ | 7 | ‘s’ | ‘P’ |
‘x’ | 8 | ‘X’ | |
‘\|’ | 9 | ||
‘-’ | 10 | ||
0 | 11 |
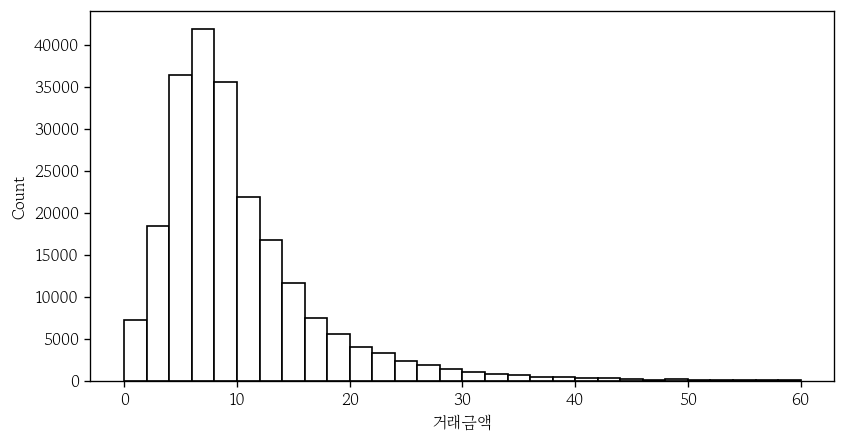
히스토그램 그래프
히스토그램은 일변량 연속형 변수의 도수분포표를 시각화한 것
data: 데이터프레임 지정x: 연속형 변수명 지정binwidth: 막대 너비 지정binrange: 히스토그램 범위를 튜플로 지정(구간 제한 가능)facecolor(fc): 채우기 색 지정edgecolor(ec): 테두리 색 지정
apt['거래금액'].agg(func=['min', 'max'])
# min 0.62
# max 220.00
# Name: 거래금액, dtype: float64sns.histplot(
data=apt,
x='거래금액',
binwidth=2,
binrange=(0, 60),
facecolor='1',
edgecolor='0'
);
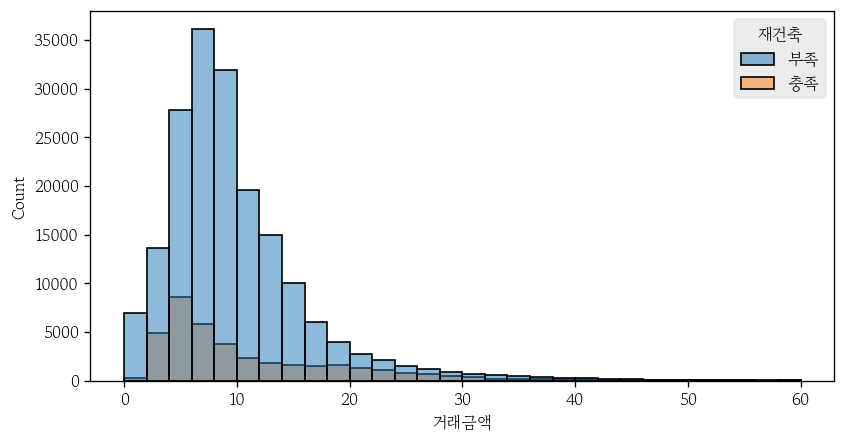
히스토그램 막대 채우기 색 변경
hue: 지정한 범주형 변수의 범주별 색을 다르게 지정- fc 대신 사용
- 범례 자동 생성
sns.histplot(
data=apt,
x='거래금액',
binwidth=2,
binrange=(0, 60),
hue='재건축',
ec='0'
);
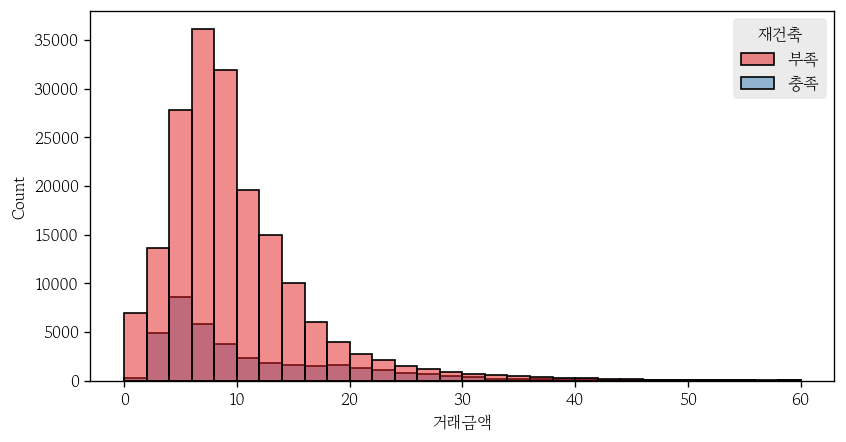
- 다른 팔레트로 변경
sns.histplot(
data=apt,
x='거래금액',
binwidth=2,
binrange=(0, 60),
hue='재건축',
ec='0',
palette='Set1'
);
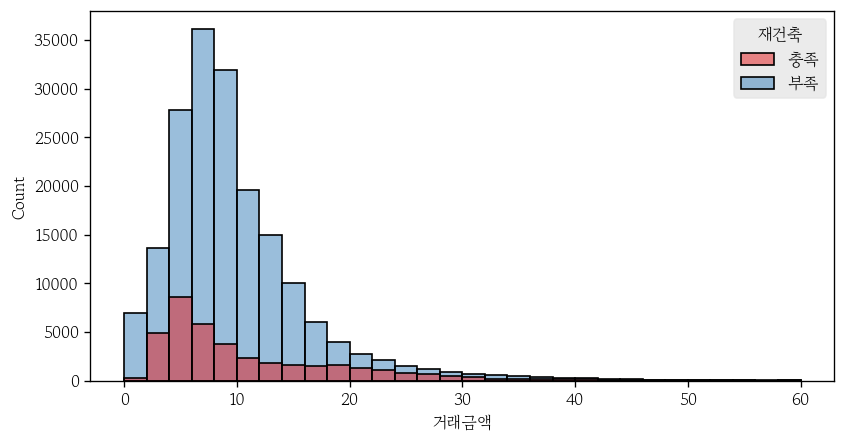
범주형 변수의 레벨 순서 변경
apt['재건축'].head()
# 0 부족
# 1 부족
# 2 충족
# 3 부족
# 4 충족
# Name: 재건축, dtype: objectsort_values()사용해서 내림차순 정렬
apt1 = apt.sort_values('재건축', ascending=False)
apt1['재건축'].head()
# 140335 충족
# 98022 충족
# 98020 충족
# 174035 충족
# 98018 충족
# Name: 재건축, dtype: object- 또는
hue_order사용- 범례 순서 변경
sns.histplot(
data=apt,
x='거래금액',
binwidth=2,
binrange=(0, 60),
hue='재건축',
ec='0',
hue_order=['충족', '부족']
);
제목 및 축이름 추가
plt.title(): 제목 추가y매개변수로 제목의 높이를 실수로 지정 가능
plt.xlabel(): x 축 이름 추가plt.ylabel(): y 축 이름 추가
sns.histplot(
data=apt,
x='거래금액',
binwidth=2,
binrange=(0, 60),
hue='재건축',
ec='0',
palette=mypal
)
plt.title('아파트 거래금액 분포', size=16, fontweight='bold', color='red')
plt.xlabel('거래금액(억)')
plt.ylabel('거래건수(건)');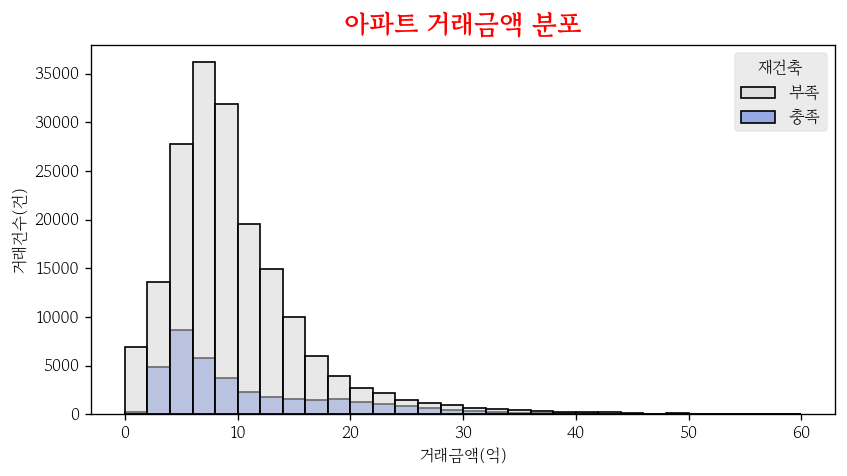
커널 밀도 추정 곡선 추가
kde: 커널 밀도 추정 곡선 추가- 커널 밀도 추정 : 비모수적인 방법으로 밀도를 추정하며 개별 관측값을 중심으로 하는 커널 함수의 평균
color: kde 곡선의 색 지정plt.xlim(): x 축을 제한- 전체 범위의 5%씩 추가하면 좋음
sns.histplot(
data=apt,
x='거래금액',
binwidth=2,
binrange=(0, 60),
fc='1',
ec='0.8',
kde=True,
color='red'
)
plt.xlim(-3, 63);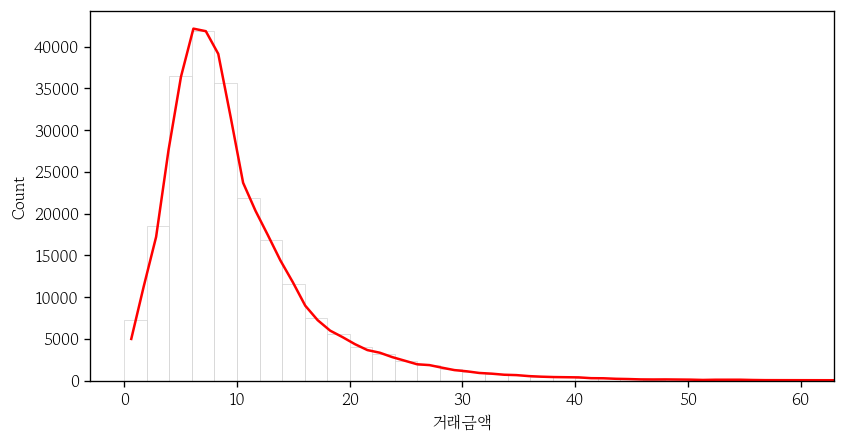
- 2개의 그래프로 나타내기
stat='density': y축을 도수에서 밀도로 변경(기본값 : count)linewidth(lw): 곡선의 두께 지정linestyle(ls): 곡선의 형태 지정
sns.histplot(
data=apt,
x='거래금액',
binwidth=2,
binrange=(0, 60),
fc='1',
ec='0.8',
stat='density'
)
sns.kdeplot(
data=apt,
x='거래금액',
color='red',
linewidth=1,
linestyle='--'
)
plt.xlim(-3, 63);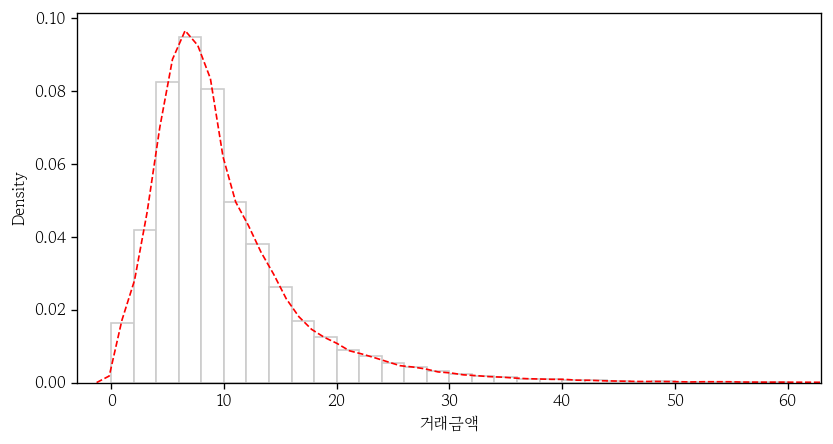
관심 지역 선택
cond = apt['시군구'].str.contains(pat='강[남동북]구')
sub = apt.loc[cond, :]
sub.groupby('시군구')['거래금액'].agg(func=['count', 'mean', 'std'])
# count mean std
# 시군구
# 강남구 12291 20.857690 12.250572
# 강동구 11958 9.412720 4.219959
# 강북구 4875 5.881168 2.092242dd연속형 범주 겹쳐서 그리기
- 연속형 범주를 겹쳐서 그릴때는 히스토그램 X
kdeplot사용
fill: 내부 채우기
sns.kdeplot(
data=sub,
x='거래금액',
hue='시군구',
palette=mypal,
fill=True
)
plt.xlim(-3, 63);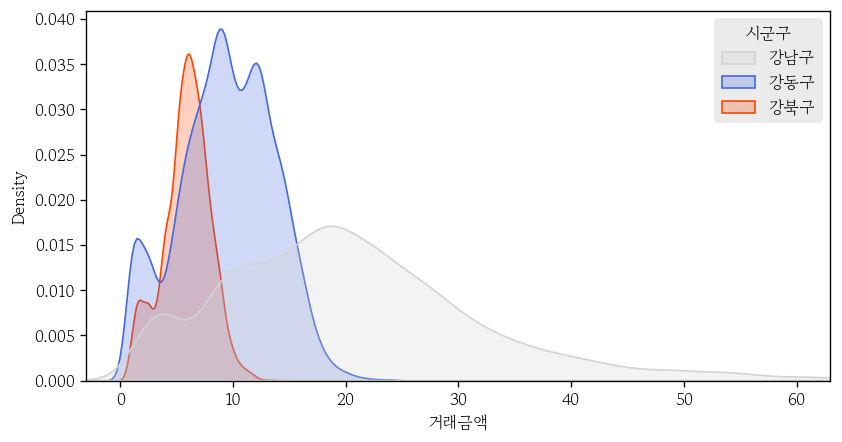
상자 그림
상자 그림은 연속형 변수의 분포를 한눈에 요약해서 보여주는 통계적 시각화 방법
- 상자는 데이터의 중심(중위수)와 퍼짐(사분범위)를 나타냄
- 1사분위수 ~ 3사분위수
- 수염은 이상치를 제외한 최솟값과 최댓값까지의 범위
일변량 상자 그림 그리기
y: 연속형 변수 지정x매개변수에 지정하면 가로로 그려짐
color: 상자의 채우기 색 지정- c로 줄일 수 없음
linewidth: 모든 선의 두께 지정- lw로 줄일 수 없음
boxprops: 상자 관련 속성을 딕셔너리로 지정medianprops: 중위수 관련 속성을 딕셔너리로 지정
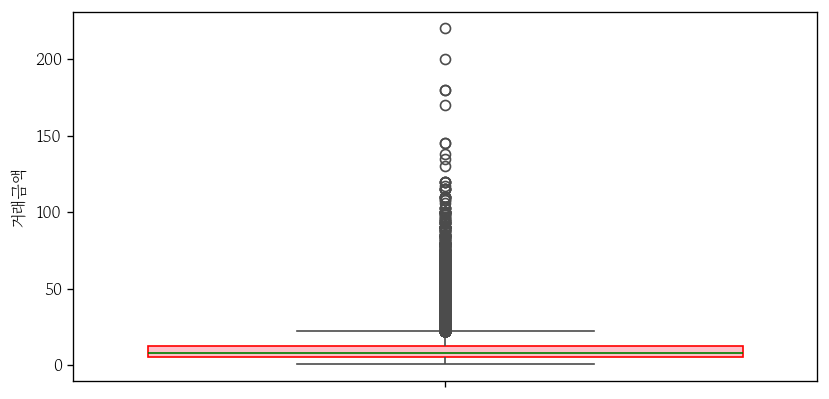
sns.boxplot(
data=apt,
y='거래금액',
# color='0.8',
# linewidth=0.5
boxprops={
'facecolor': 'pink',
'edgecolor': 'red'
},
medianprops={
'color': 'green'
}
);
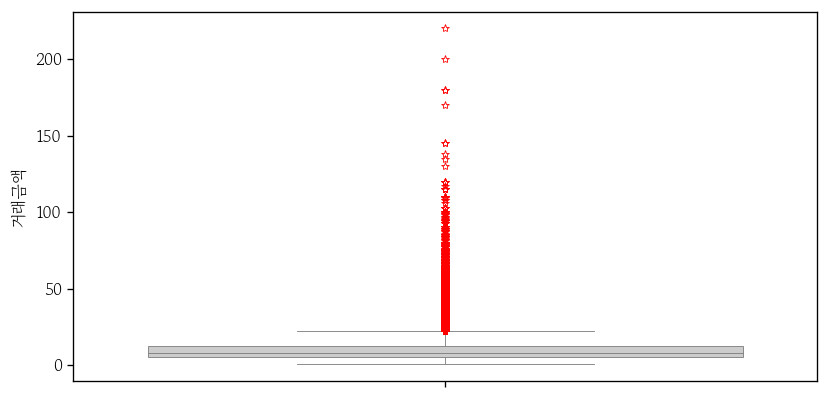
이상치 관련 속성 설정
marker: 이상치 모양 지정markersize: 이상치 크기 지정(기본값 6)markeredgecolor: 이상치 테두리 색 지정markerfacecolor: 이상치 채우기 색 지정
markeredgewidth: 이상체 테두리 선의 두께 지정(기본값 1)flierprops: 이상치 관련 속성 지정
out_prop = {
'marker': '*',
'markersize': 5,
'markeredgecolor': 'red',
'markeredgewidth': 0.5
}
sns.boxplot(
data=apt,
y='거래금액',
color='0.8',
linewidth=0.5,
flierprops=out_prop
);
이변량 상자 그림 그리기
grp = apt.groupby('시군구')['거래금액'].median().sort_values()
grp.head()
# 시군구
# 도봉구 4.9
# 금천구 5.4
# 노원구 5.5
# 중랑구 5.7
# 강북구 6.0
# Name: 거래금액, dtype: float64order: x축의 눈금명 순서를 지정(오름차순 정렬)plt.axhline: 가로 직선 추가plt.xticks: x축 눈금명 제어rotation: 지정 각도만큼 회전
sns.boxplot(
data=apt,
x='시군구',
y='거래금액',
color='0.8',
linewidth=0.5,
flierprops=out_prop,
order=grp.index
)
plt.axhline(y=apt['거래금액'].median(), color='red', linewidth=1, linestyle='--')
plt.xticks(size=8, rotation=90)
plt.xlim(-1, 25);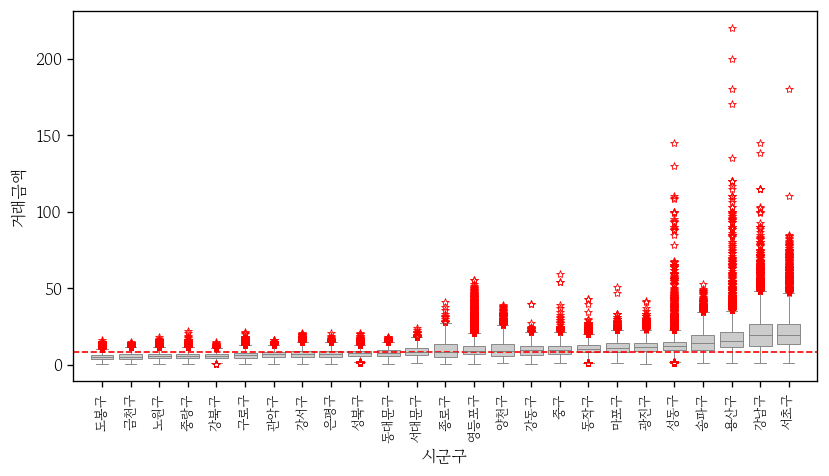
마치며
오늘이 파이썬 & 데이터 분석의 마지막 수업이라 강의 자료에 있는 다른 시각화 그래프들도 따로 공부를 해서 정리를 해둬야겠다. 정말 빠르게 달려왔다. 짧은 시간 너무 많은 내용을 배워 복습을 안 하면 금방 까먹을 수도 있을 것 같으니 복습을 열심히 해서 데이터 분석부터 시각화 기술을 만족스러울 정도로 키우고 싶다.

Hello I'm TaeHyunAn, Currently Studying Data Analysis