
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1.Torchvision 라이브러리로 추론하기
이번에는 쉬어가는 의미로 torchvision 라이브러리로 사전학습 모델로 이미지 추론을 수행하는 코드를 작성하면서 메서드별 설명을 진행하고자 한다.
라이브러리 import
import torch
from torchvision import models
from torchvision import io일단 사전학습 모델로 추론을 간편하게 하는 코드 작성을 위해 2개의 라이브러리 torcivision의 models, io를 import한다.
Pretrained model 인스턴스화
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#모델과 학습된 가중치 파일 로드
weight = models.ResNeXt101_32X8D_Weights.IMAGENET1K_V2
model = models.resnext101_32x8d(weights=weight).to(device)
#pretrained model을 평가모드로 전환
model.eval()
위 사진처럼 weight(사전학습 가중치 파일)을 불러오고
model의 인스턴스화 할 때 weight를 붙이는 방식으로 선언하여
pre-trained model을 인스턴스화 및 사용이 가능해진다.
마지막으로 이미지 추론작업만 수행할 예정이니
model.eval()로 평가모드로 전환한다.
이미지 전처리 - 이미지 텐서 자료형 변환
이미지 전처리는 PIL, Numpy라이브러리를 통해서
이미지 Matrix 자료형 Tensor 자료형으로 바꾸는 식으로도 진행해도 되지만
torchvision.io라이브러리를 통해서
바로 이미지 Tensor 자료형 변환
Tensor 자료형 이미지로 '저장'을 수행 가능하다.
https://pytorch.org/vision/stable/io.html
해당 페이지에서 설명하고 있는 메서드 중 주요 메서드는 아래와 같다.
1) read_image : JPEG나 PNG, GIF자료형을 Tensor 자료형으로 변환
입력인자는 크게 2개로, path, mode를 입력하며
path는 이미지 경로

mode는 5가지 옵션이 있는데
Default는 ImageReadMode.UNCHANGED
회색조 변환은 : ImageReadMode.GRAY
컬러조 변환 : ImageReadMode.RGB
그 외로 _ALPHA옵션은 PNG파일로 만들때 쓰는거라 몰라도 된다.
왠만하면 ImageReadMode.UNCHANGED로 쓰면 된다.
2) write_jpeg, write_png : Tensor자료형을 이미지로 변환하면서 동시에 '저장'을 진행한다.
아무튼 위 메서드를 사용하여 이미지를 텐서 자료형으로 변환하자
img_path = "./fig/classification/beagle.jpg"
img = io.read_image(img_path, mode=io.ImageReadMode.UNCHANGED)
img = img.to(device)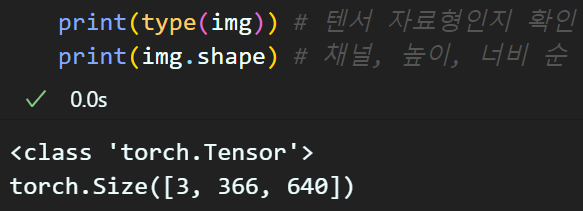
PIL, Numpy라이브러리 사용 없이
Torchvision.io라이브러리 만으로도 데이터 자료형 변환이 가능하니 알아둘 필요성은 있다.
이미지 전처리 - 모델에 입력가능한 형태로 변환
이미지 Tensor자료형 변환후
1차 Tensor자료 2차 자료형변환(데이터로더)로 바꿔줘야 한다.
이 과정이 모델에 입력 가능한 자료형 변환이라 보면 된다.
그러면 어케 입력하는지?
를 알아야 한다.
이는 weight = models.ResNeXt101_32X8D_Weights.IMAGENET1K_V2
여기에서 그 입력 과정을 찾아낼 수 있다.
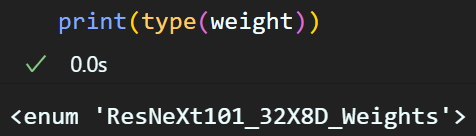 위 사진처럼
위 사진처럼 weight는 열거형 데이터타입 enum으로
하위 메서드로 url, meta, transfoms()를 제공한다.
1) url : 해당 weight파일이 웹 상에서 다운로드 받을 수 있는 위치를 알려준다.

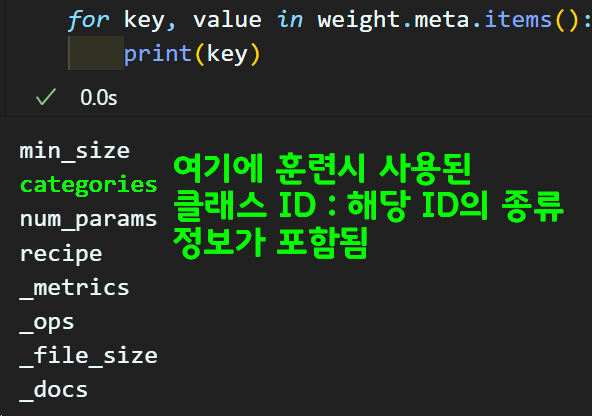
2) meta : 해당 가중치 파일이 만들어지기 위한 모델의 학습 실험정보에 관한 정보를 반환 모델 훈련 세팅값과 관련이 있을만한것은 다 출력한다 보면 된다.
3) transforms() : 해당 가중치 파일의 제일 중요한 이미지 전처리 방법론에 대한 정보가 기재되어 있다.
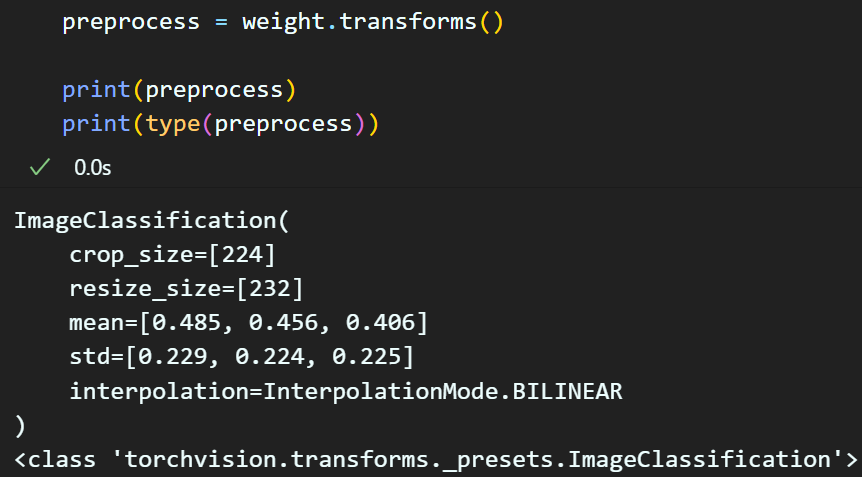
이때 여기서 중요한 점은 transforms()의 반환 타입은
Class이다.
즉, 해당 반환값을 '함수'처럼 쓸 수 있다
위 weight에 대한 이해를 숙지했으니 이제 코드로 2차 데이터 전처리를 수행해보자
preprocess = weight.transforms()
img = preprocess(img) #전처리 후 이미지 재귀업데이트
batch = img.unsqueeze(0) #배치 자료형으로 만들기 위해 맨 앞에 1차원 추가
여기까지 수행하면 img를 모델에 입력 가능한 형태(batch)로 완전히 전처리를 완료한 것이다.
추론 및 결과값 확인
predict = model(batch) #모델의 전사(추론)과정전처리가 완료된 자료 : batch를 모델에 입력하면
추론 결과 predict를 얻을 수 있을 것이다.
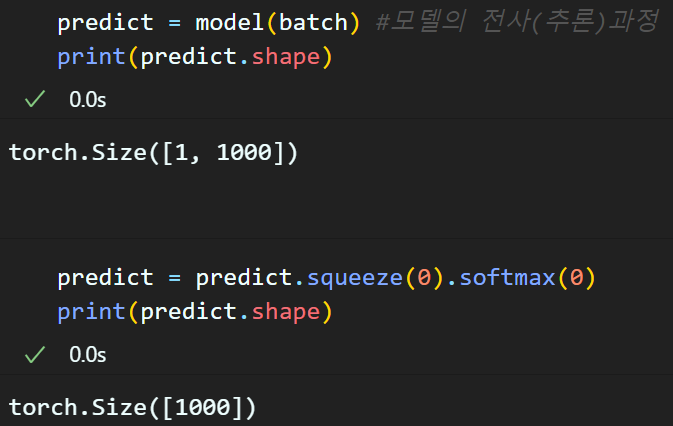
이제 이 추론 결과값을 사람이 확인할 수 있게 후처리를 해야 한다
그 첫번째 과정이 squeeze(0) : 앞단에 붙은 차원 없애기
softmax(0) : 추론 결과값을 확률정보로 재처리
이 softmax메서드는 torch.nn.functional.softamax에서 유래한거고
 뭐.. softmax 알 거라 생각한다..
뭐.. softmax 알 거라 생각한다..
이미지 classification 할때 필수로 알아야 할 함수가 sigmoid, softmax이니...

sigmoid, softmax.. 아시죠?
뭐.. 여기까지 수행하여 모델의 추론 결과값을 softmax로 후처리를 진행했으면
아래의 코드를 통해 확률정보를 확인하자
score, class_id = predict.max(dim=0)
inference_res = score.item() * 100
print(f"예측한 클래스 ID: {class_id.item()}")
print(f"예측 퍼센트: {inference_res:.2f}%")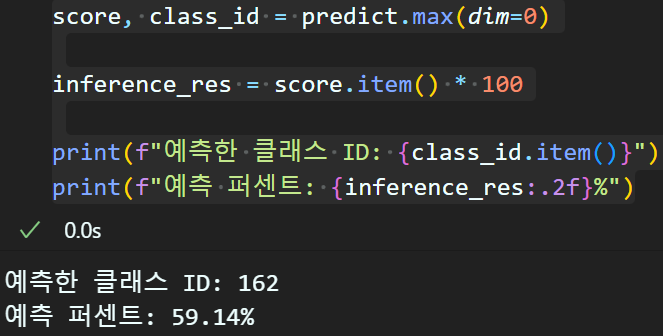
클래스 ID의 범주형 데이터 확인
예측한 클래스 ID가 정수형 데이터으로 나왓지만
이게 개? 고양이? 같이
사람이 이해가능한 범주형 데이터로 후처리 해야한다.
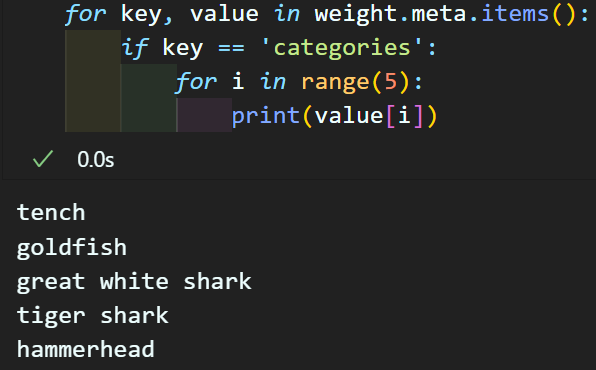
이것을 알려면 class_id의 훈련시 사용된 카테고리를 찾아내야 한다.
이는 weight.meta정보를 더 탐색하면 알아낼 수 있다.
category_name = weight.meta["categories"][class_id.item()]
print(f"클래스ID : {class_id.item()}, 클래스명 : {category_name}")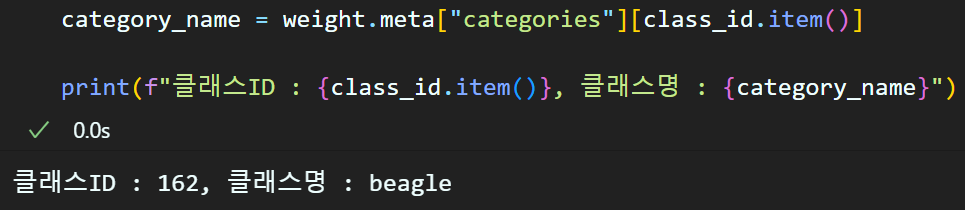
이렇게 PyTorch torchvision라이브러리만을 사용하여 사전학습 모델의 추론을 진행할 수 있다.
2. opencv.dnn 라이브러리로 추론하기
https://github.com/opencv/opencv/wiki/Deep-Learning-in-OpenCV
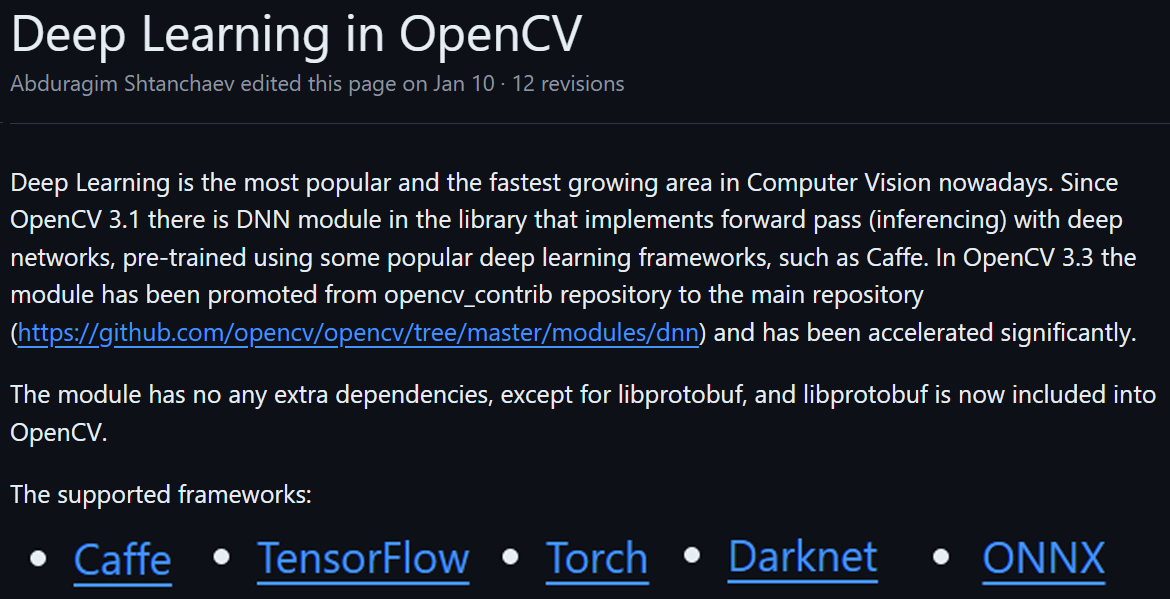
OpenCV는 버전 3.1부터 외부 딥러닝 프레임워크로 개발된 모델을 불러와서 네트워크 추론을 수행할 수 있는 기능
dnn(Deep Neural Network) 모듈을 지원한다.
dnn모듈은 Caffe, Tensorflow, Torch, Darknet, ONNX 프레임워크로 개발된 모델의 설계정보(config)와 학습된 가중치 파일(model) 두가지 인자값을 받아서
외부 프레임워크로 개발된 모델을 Opencv라이브러리를 통해서 인스턴스화가 가능하다.
라이브러리 import 및 이미지 불러오기
import sys
import numpy as np
import cv2img_path = "./fig/classification/beagle.jpg"
img = cv2.imread(img_path)
if img is None:
print("이미지 불러오기 실패")
sys.exit()Opencv + numpy 라이브러리만 사용하는 것이며
이는 Tensor 자료형을 사용하지 않겠다는 의미로 해석하면 된다.
사전학습 모델 불러오기
import urllib.request# 다운로드할 config파일의 URL
config_url = "https://raw.githubusercontent.com/BVLC/caffe/master/models/bvlc_googlenet/deploy.prototxt"
config_path = "deploy.prototxt"
# config 파일 다운로드
urllib.request.urlretrieve(config_url, config_path)
# caffemodel 파일의 URL
model_url = "http://dl.caffe.berkeleyvision.org/bvlc_googlenet.caffemodel"
model_path = "bvlc_googlenet.caffemodel"
# 파일 다운로드
urllib.request.urlretrieve(model_url, model_path)# 모델과 설정 파일을 사용하여 네트워크 로드
net = cv2.dnn.readNet(model_path, config_path)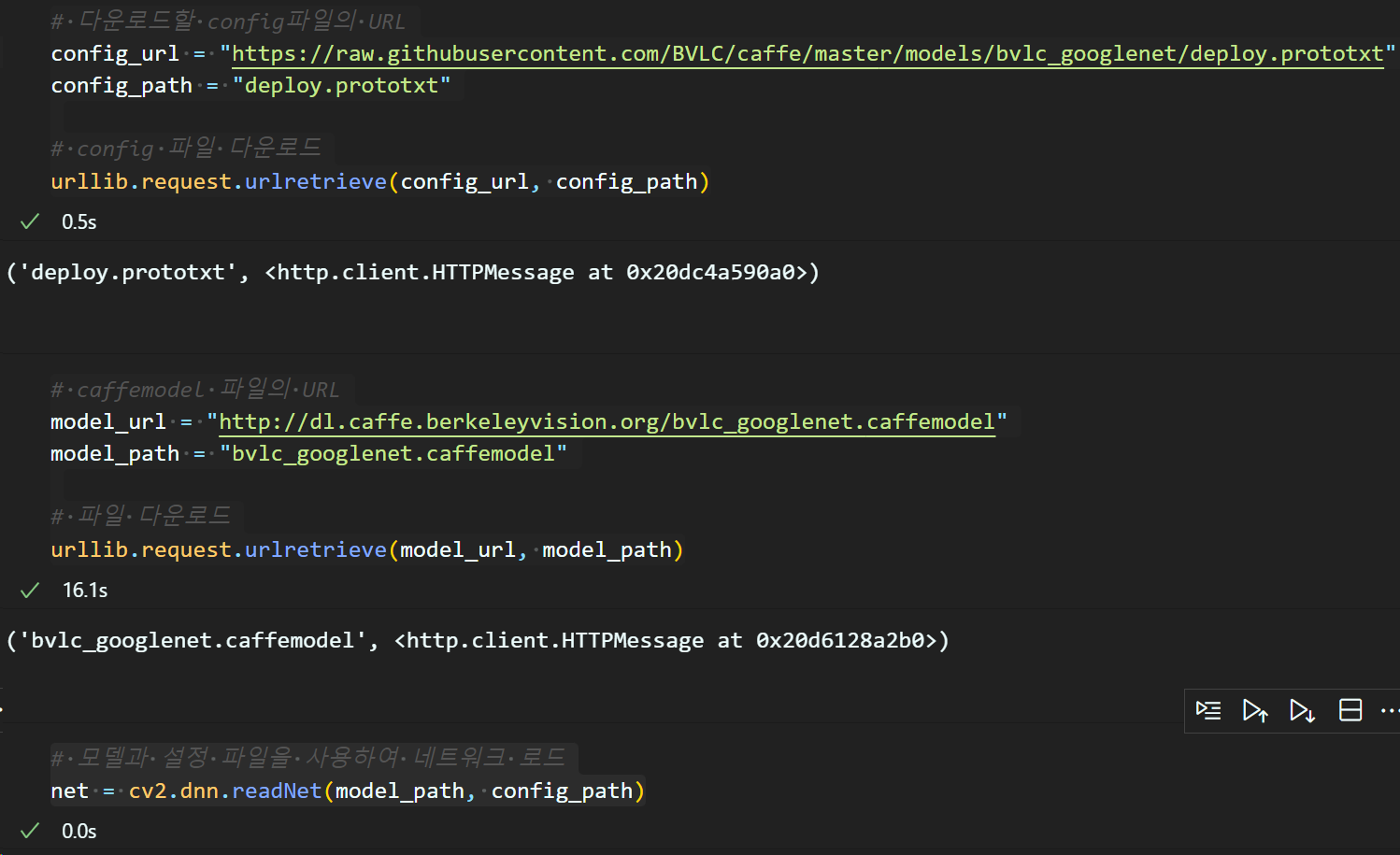
이렇게 타 딥러닝 프레임워크에서 config와 model에 해당하는 정보가 업로드 되어 있는 URL을 찾아서
다운로드를 수행하면 된다.
여기서 좀.. 설명할게 있는데

cv2.dnn.readNet 메서드의 설명을 보면
위 dnn 모듈의 설명대로
Caffe, TensorFlow, Torch, Darknet, ONNX와 같은 외부 딥러닝 프레임워크를 가져와서 모델을 인스턴스 할 수 있다 설명하고 있다.
그러나 실제로는 Caffe, Yolo-Darknet 딥러닝 프레임워크만 dnn모듈에서 주로 가져오는 식이다.

음.. 그러니까 OpenCV는 C++언어 기반으로 동작하는 프레임 워크이고 요즘은 OpenCV는 임베디드 기기에서 동작하는 환경에서 사용하는 프레임워크로 많이 사용이 되고 있는데
또 임베디드 기기에서 사용할 법한 딥러닝 모델이
Object Detection 분야에서는 가볍고, 빠른 모델로
Yolo, SSD가 주로 쓰이고 Caffe는 초기에 나온 딥러닝 프레임워크다 보니
OpenCV와 죽이 잘 맞는 편이다.
그러니까 cv2.dnn.readNet로 주로 불러오는 모델이
Caffe에서 지원하는 모델, Yolo, SSD 이 3가지라 보면 된다.
http://dl.caffe.berkeleyvision.org/

그리고 Caffe에서 제공하는 모델들도 리스트를 보면 초기 CNN모델이거나, 가벼운 모델이 주 를 이룬다
뭐 아무튼 cv2.dnn.readNet 으로 인스턴스화 한 모델은
googlenet(inception v1)이다.
인스턴스화 한 사전학습 모델의 훈련 클래스 카테고리
앞선 torchvision라이브러리는 학습된 가중치 파일weight파일의 meta메서드를 살펴보면
해당 모델을 학습시킨 데이터셋에 대한 정보(클래스 카테고리)를 추출할 수 있었는데
cv.dnn은 다른 URL에서 이 클래스 카테고리 정보를 찾아내야 한다.
https://github.com/opencv/opencv/tree/4.x/samples/data/dnn
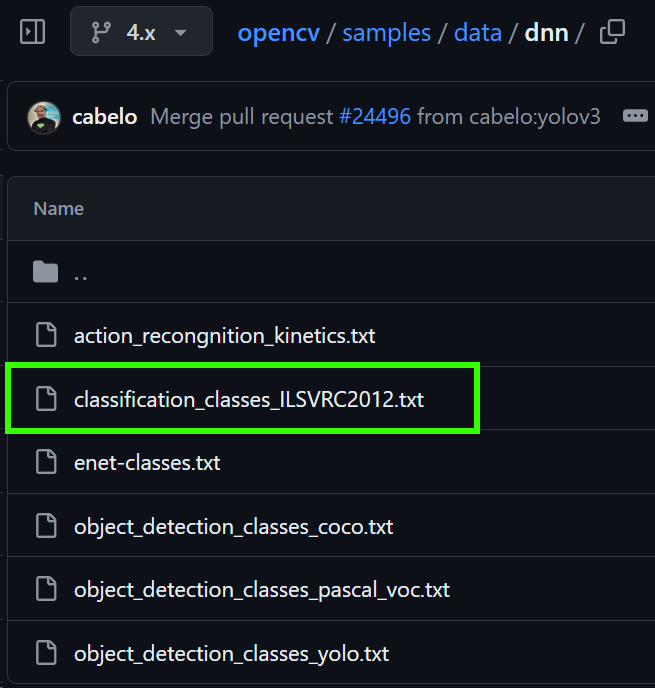
위 초록색 박스 파일을 다운로드 하고
해당 파일이 *.txt 이기에 문자열 전처리 작업을 진행해야 한다.
class_categories_list = []
class_categories_url = 'https://raw.githubusercontent.com/opencv/opencv/4.x/samples/data/dnn/classification_classes_ILSVRC2012.txt'
class_categories_path = "classification_classes_ILSVRC2012.txt"#클래스 카테고리 리스트 파일 다운로드
urllib.request.urlretrieve(class_categories_url, class_categories_path)#카테고리 리스트(텍스트 파일)에서 필요정보만 추출(문자열 전처리)
with open('classification_classes_ILSVRC2012.txt', 'rt') as f:
class_categories_list = f.read().rstrip('\n').split('\n')위 코드를 순차로 수행하면
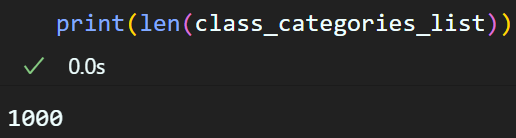
이렇게 1000개의 클래스 카테고리 정보를 리스트화 할 수 있을 것이다.
이래서 cv.dnn은 임베디드 기기에서 Obj Detect할때나..
이미지 전처리 + 모델 추론 수행
인스턴스화 한 cv.dnn라이브러리를 활용한 사전 학습 모델에 이미지를 입력하려면
모델에 입력가능한 자료형으로 변환해야 한다.
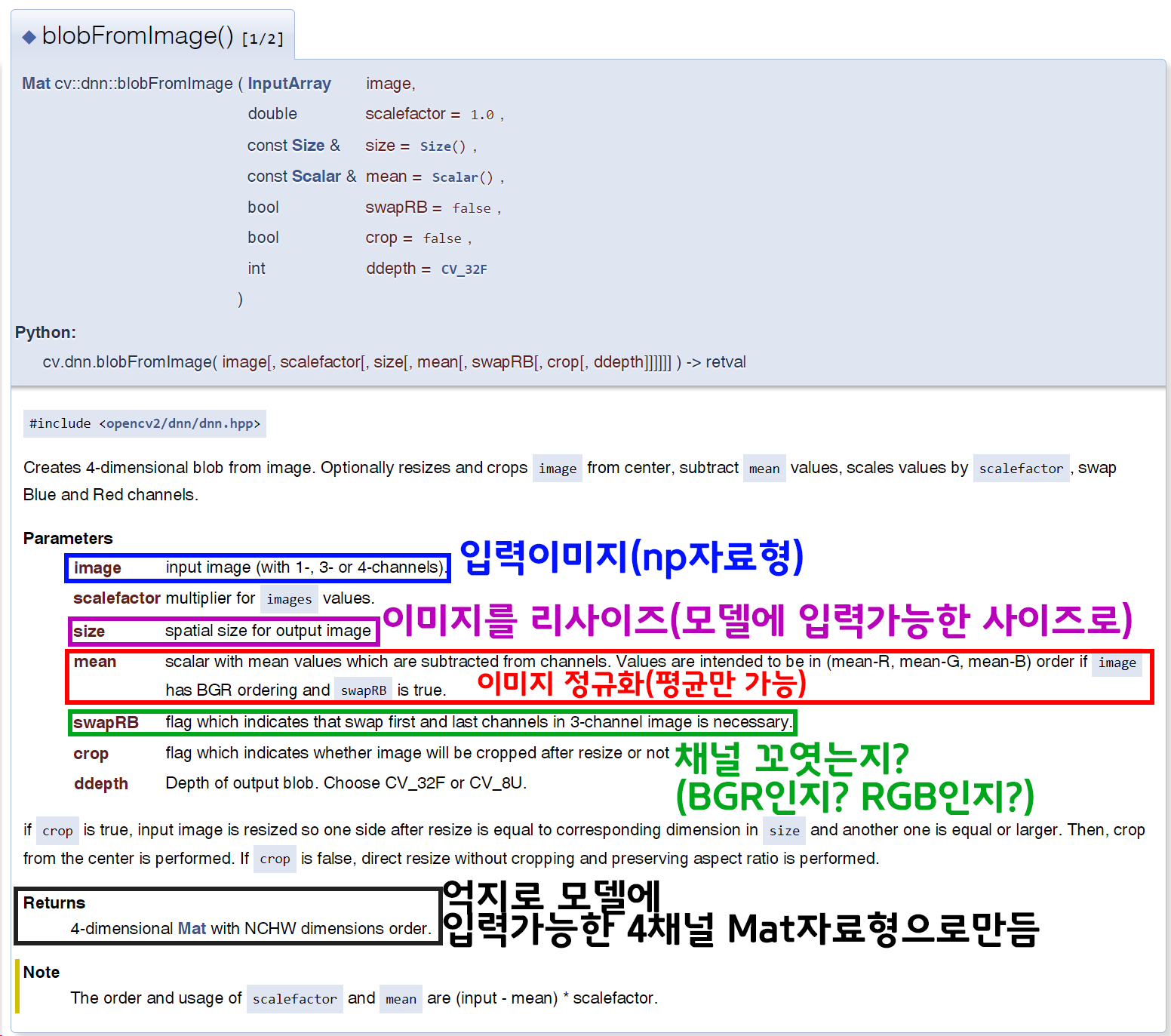
이 기능을 수행하는건 cv.dnn.blobFromImage인데
torchvision.transform의 이미지 전처리 방법론을 모사한 메서드라 보면 된다.
여기서 이미지 정규화에 필요한 인자값 입력이 mean만 가능하고 std불가능한 것을 확인할 수 있다.
그리고 이 mean값도 인공지능 고급(시각) 강의 복습 - 24. 이미지 정규화 (2)이 포스트에서 설명한
ImageNet의 표준화 mean 값 : 0.485, 0.456, 0.406 이 값에 255를 곱한값을
R, G, B채널 순이 아닌
B, G, R 순으로 저장해야 한다.
음.. 그러니까 이건 코드를 보면 이해가 빠를것 같다.
imageNet_val = {'mean': [0.485, 0.456, 0.406],
'std' : [0.229, 0.224, 0.225]}
# mean 값에 255를 곱하고 int로 변환하여 리스트에 저장(이때 역순으로 저장)
blob_mean = [int(value * 255) for value in reversed(imageNet_val['mean'])]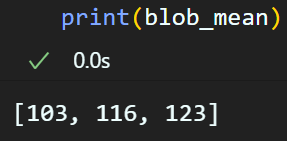
이렇게 변환한 값을
# cv2.dnn버전으로 이미지를 모델에 입력가능한 형태로 전처리 방법론 정의
blob = cv2.dnn.blobFromImage(img, 1, (224, 224), blob_mean, swapRB=False)
# 전처리 방법론에 의거하여 전처리 수행 후 모델에 입력하기 바로 직전상황
net.setInput(blob)이렇게 전처리 하면 된다.
# 모델에 전처리된 이미지 입력(Forward)
prob = net.forward()그리고 모델에 입력하여 추론 결과를 얻어낼 수 있다.
추론 결과 후처리
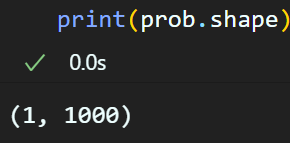
모델의 추론 결과가 위 형태를 띄니 후처리를 해줘야 한다.
out = prob.flatten() # 차원 축소
classId = np.argmax(out)
confidence = out[classId]
이렇게 입력된 이미지에 대한 추론을
cv.dnn라이브러리를 통해서도 할 수 있다.
그러나 코드를 실습하면서 느낀점은
cv.dnn라이브러리는 C++언어로 임베디드 기기에서
Obj Detection(Yolo, SSD)를 사용할 때에
좀 더 적합한 기능이지않나..
라는 생각이 든다..
