
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. 작업목표
이전 포스트 인공지능 고급(시각) 강의 예습 - 22. (8) Yolo v3 사전학습모델 + 추론검증 부터
인공지능 고급(시각) 강의 예습 - 22. (11) Yolo v3 : 4차 코드 검증 - Loss까지
충분한 코드검증을 수행했다.
이제 마지막 코드검증인
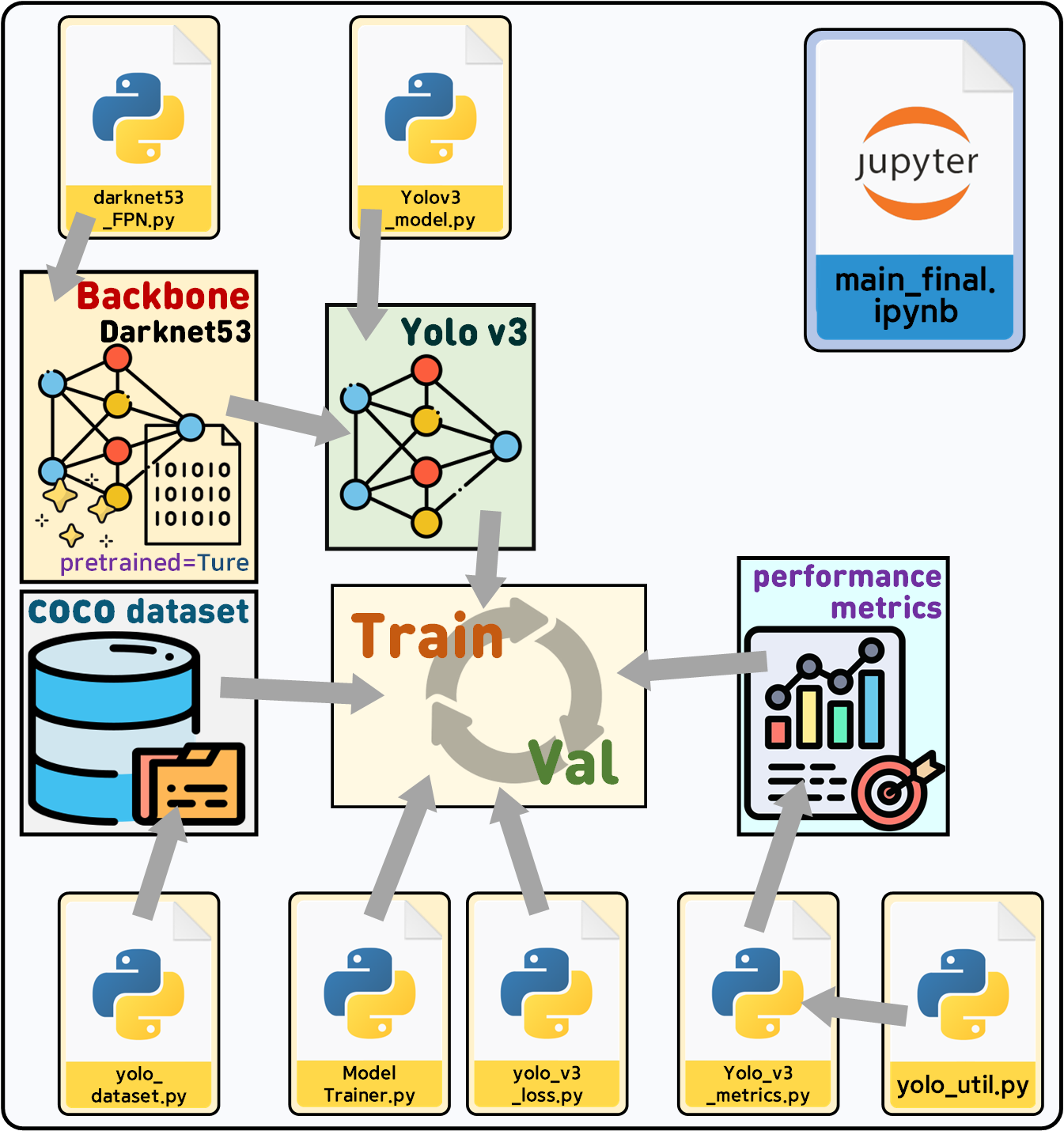 이 과정을 수행하고자 한다.
이 과정을 수행하고자 한다.
필자가 직접 설계한 Yolo v3을 Train / Val을 수행해서 그 결과가 제대로 나오는지를 확인하는 것이 이번 포스트의 목적이다.
2. main_final.ipynb
해당 코드에 대한 설명은 이전 포스트를 참조하면
충분히 이해가 될 것이라 생각한다...
import torch
import darknet53_FPN as darknet53 #백본 모델 구성정보
from Yolov3_model import YOLOv3, FPN, debug # 나머지 모델레이어 구성정보
from yolo_dataset import CustomDataset #커스텀 데이터셋 코드
from yolo_v3_loss import Yolov3Loss, loss_debug #Loss 함수 코드
from yolo_v3_metrics import YOLOv3Metrics, metrics_debug #평가지표 코드
from ModelTrainer import ModelTrainer #train / val 코드
import coco_data # 전역변수 모음집# 모델 초기화(backbone는 사전학습모델 로드)
backbone = darknet53.Darknet53(pretrained=True)
fpn = FPN(channels_list=coco_data.fpn_in_ch)
yolov3 = YOLOv3(backbone, fpn, num_classes=80)# 백본 파라미터 Freeze
for param in backbone.parameters():
param.requires_grad = False# coco데이터셋의 메인 루트 디렉토리
root_dir = '[./COCO dataset]'
# load_anno=val2014 -> 'instance_val2014.json'참조 + `val2014`img폴더 참조
train_dataset = CustomDataset(root=root_dir, load_anno='train2017',
anchor=coco_data.anchor_box_list)
test_dataset = CustomDataset(root=root_dir, load_anno='val2017',
anchor=coco_data.anchor_box_list)
print(f"훈련용 : {train_dataset}, \n 검증용 : {test_dataset}")from torchvision.transforms import v2
coco_val = [[0.4701, 0.4468, 0.4076], [0.2379, 0.2329, 0.2362]]
# 데이터셋 전처리 방법론 정의
transforamtion = v2.Compose([
v2.Resize((416, 416)), #이미지 크기를 416, 416로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=coco_val[0], std=coco_val[1]) #데이터셋 정규화
])# 데이터셋 전처리 방법론 적용
train_dataset.transform = transforamtion
test_dataset.transform = transforamtionfrom torch.utils.data import DataLoader
BATCH_SIZE = 128
# 전처리가 완료된 데이터셋의 데이터로더 전환
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 앞서 선언한 모델의 GPU이전
backbone.to(device)
fpn.to(device)
yolov3.to(device)
print()학습 하이퍼 파라미터 설정
from torch.optim import AdamW
from torch.optim.lr_scheduler import CosineAnnealingLR
# 손실 함수 설정 (YOLOv3 손실 함수)
# 여기서 cho_mode=True 이면 예측 값을 필터링해서 IOU값으로 Localization Loss연산 수행
# cho_mode=False 이면 기존 방식으로 모든 예측값에 대하여 Localization Loss연산 수행
criterion = Yolov3Loss(device=device.type, cho_mode=False,
anchor=coco_data.anchor_box_list)
# 옵티마이저 설정 (프리즈되지 않은 파라미터만)
optimizer = AdamW(filter(lambda p: p.requires_grad, yolov3.parameters()), lr=1e-4, weight_decay=1e-4)
# 스케줄러 설정 (50 에폭 기준 Cosine Annealing)
scheduler = CosineAnnealingLR(optimizer, T_max=40)하이퍼 파라미터 설정은 이것저것 해보니까 이게 제일 적당했다.
그리고 epoch = 30이다.
조금만 epoch가 늘어도 과적합이 발생하는데
음.. 원인을 잘 모르겟다.
# Train / eval(Val) 및 평가지표 코드 인스턴스화
epoch_step = 3
trainer = ModelTrainer(epoch_step=epoch_step, device=device.type)
metrics = YOLOv3Metrics(anchor=coco_data.anchor_box_list, device=device.type)# 학습과 검증 손실 및 정확도를 저장할 리스트
his_loss = []
his_KPI = []
num_epoch = 30
for epoch in range(num_epoch):
# 훈련 손실과 훈련 성과지표를 반환 받습니다.
train_loss, train_KPI = trainer.model_train(yolov3, train_loader,
criterion, optimizer, scheduler,
metrics, epoch)
# 검증 손실과 검증 성과지표를 반환 받습니다.
test_loss, test_KPI = trainer.model_evaluate(yolov3, test_loader,
criterion, metrics, epoch)
# 손실과 성능지표를 리스트에 저장
his_loss.append((train_loss, test_loss))
his_KPI.append((train_KPI, test_KPI))
# epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 loss: {train_loss:.4f}")
print(f"훈련 KPI[ IOU: {train_KPI[0]:.4f}, "+
f"mAP: {train_KPI[1]:.4f}, "+
f"Recall: {train_KPI[2]:.4f}, "+
f"Top1_err: {train_KPI[3]:.4f} ]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"검증 loss: {test_loss:.4f}")
print(f"검증 KPI[ IOU: {test_KPI[0]:.4f}, "+
f"mAP: {test_KPI[1]:.4f}, "+
f"Recall: {test_KPI[2]:.4f}, "+
f"Top1_err: {test_KPI[3]:.4f} ]")2.1 학습 결과
MODEL_NAME="Yolo_v3_final"
torch.save(yolov3.state_dict(), f'{MODEL_NAME}.pth')학습이 완료된 Yolo_v3_final.pth파일은
https://drive.google.com/file/d/1-7kMFBkEMtch01l2JajgIaTFnc1qHwzr/view?usp=drive_link
에 업로드를 완료했다.
import numpy as np
import matplotlib.pyplot as plt
#histroy는 [train, test] 순임
#KPI는 [iou, precision, recall, top1_error] 순임
np_his_loss = np.array(his_loss)
np_his_KPI = np.array(his_KPI)
# his_loss에서 손실 데이터 추출
train_loss, val_loss = np_his_loss[..., 0], np_his_loss[..., 1]
# his_KPI에서 각 성능 지표 추출
train_iou, val_iou = np_his_KPI[..., 0, 0], np_his_KPI[..., 1, 0]
train_precision, val_precision = np_his_KPI[..., 0, 1], np_his_KPI[..., 1, 1]
train_recall, val_recall = np_his_KPI[..., 0, 2], np_his_KPI[..., 1, 2]
train_top1_errors, val_top1_errors = np_his_KPI[..., 0, 3], np_his_KPI[..., 1, 3]
# 1x2 로 그래프 그리기
plt.figure(figsize=(6, 10))
# Train-Val Loss
plt.subplot(2, 1, 1)
plt.plot(train_loss, label='Train Loss')
plt.plot(val_loss, label='Val Loss')
plt.xlabel('Training Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Train-Val Loss')
# Train-Val Top-1 Error
plt.subplot(2, 1, 2)
plt.plot(train_top1_errors, label='Train Top-1 Error')
plt.plot(val_top1_errors, label='Val Top-1 Error')
plt.xlabel('Training Epochs')
plt.ylabel('Top-1 Error')
plt.legend()
plt.title('Train-Val Top-1 Error')
plt.tight_layout()
plt.show()
# 1x3로 그래프 그리기
plt.figure(figsize=(6, 10))
# IOU
plt.subplot(3, 1, 1)
plt.plot(train_iou, label='Train IOU')
plt.plot(val_iou, label='Val IOU')
plt.xlabel('Training Epochs')
plt.ylabel('IOU')
plt.legend()
plt.title('IOU')
# Precision
plt.subplot(3, 1, 2)
plt.plot(train_precision, label='Train Precision')
plt.plot(val_precision, label='Val Precision')
plt.xlabel('Training Epochs')
plt.ylabel('Precision')
plt.legend()
plt.title('Precision')
# Recall
plt.subplot(3, 1, 3)
plt.plot(train_recall, label='Train Recall')
plt.plot(val_recall, label='Val Recall')
plt.xlabel('Training Epochs')
plt.ylabel('Recall')
plt.legend()
plt.title('Recall')
plt.tight_layout()
plt.show()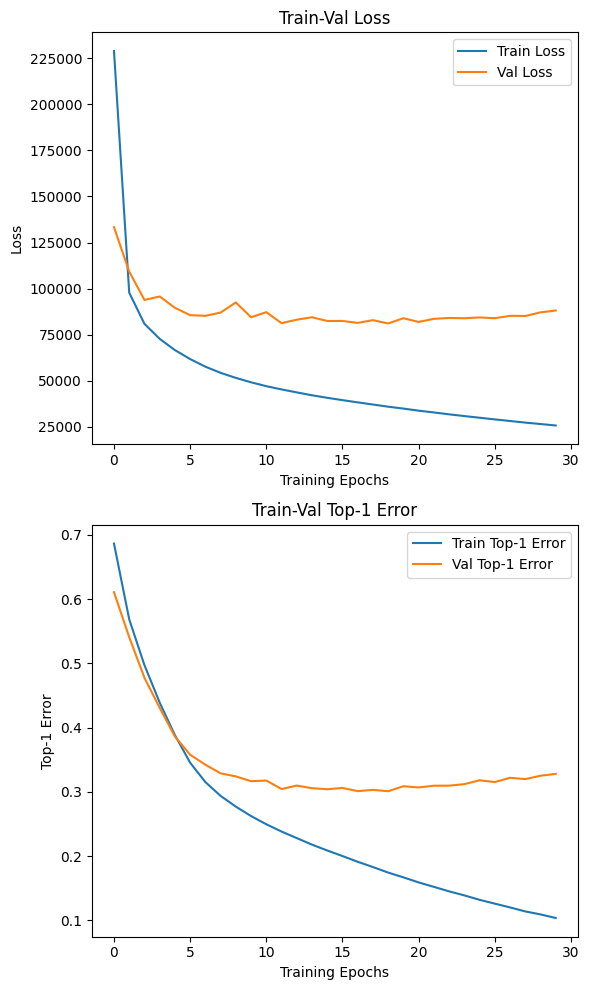
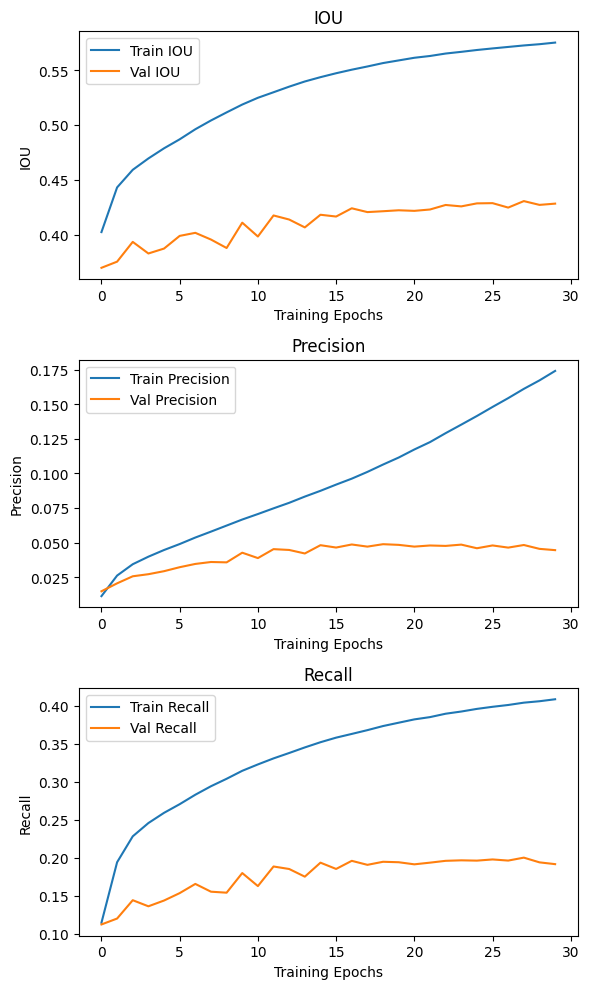
성능평가 지수를 출력해보니..
음..이게 epoch를 더 늘리면 과적합이 나서
더이상 돌리기가 어려운데
아무튼 Validation의 Loss는 8만 이하로 떨어트리기가 매우 어려웠다.
3. 이미지 추론
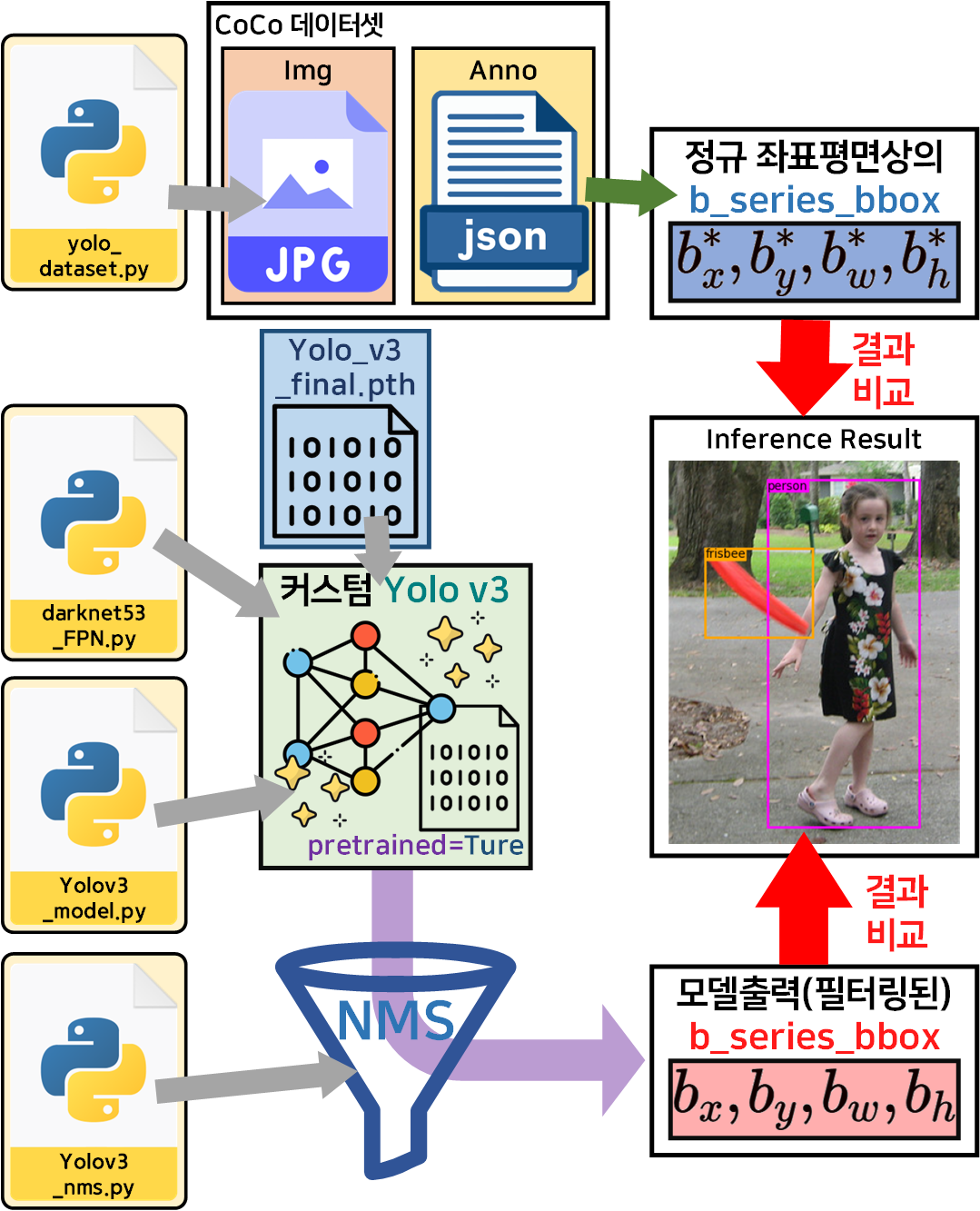
이 과정수행을 통해 얼마나 필자가 그간의 12개 포스트를 남겨가면서
수행한 결과물이 잘 나왔는지 최종 테스트 하는 과정이라 보면 된다.

이 과정에 대한 코드는 08_inference.ipynb이다.
import cv2, random, os
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
# 모델의 출력 outputs의 bbox를 필터링하는 nms 클래스
from yolo_v3_nms import Yolov3NMS
from pycocotools.coco import COCOimport torch
import darknet53_FPN as darknet53 #백본 모델 구성정보
from Yolov3_model import YOLOv3, FPN, debug # 나머지 모델레이어 구성정보
import coco_data # 전역변수 모음집Yolo_v3_final.pth 다운로드 부분
import gdown #학습시킨 가중치 파일은 구글드라이브에 있음
import os# 파일 ID 추출
file_id = "1-7kMFBkEMtch01l2JajgIaTFnc1qHwzr"
# 다운로드 링크 생성
download_url = f"https://drive.google.com/uc?id={file_id}"
# 파일 다운로드
output_file = "Yolo_v3_final.pth"
# 파일 다운로드
if not os.path.exists(output_file):
gdown.download(download_url, output_file, quiet=False)
print("다운로드 완료")
else:
print("파일이 이미 존재함")# 다운로드받은 가중치 파일을 붙여서 Pretrined-model로 만들기
yolov3.load_weights('Yolo_v3_final.pth')이미지추론 준비 부분
# coco데이터셋의 메인 루트 디렉토리
root_dir = '[./COCO dataset]'
anno_path = os.path.join(root_dir, 'annotations')
load_anno = 'val2014'
json_file = 'instances_' + load_anno + '.json'
coco = COCO(os.path.join(anno_path, json_file))# 임의의 이미지 하나 선택하기
img_ids = coco.getImgIds()
chosen_img = random.choice(img_ids)
img_info = coco.loadImgs(chosen_img)[0]
ann_ids = coco.getAnnIds(imgIds=img_info['id'])
img_file_name = img_info['file_name']
print(f"선택Img: {img_file_name}")
print(f"객체개수: {len(ann_ids)}")
print(f"이미지 크기 [W: {img_info['width']}, H:{img_info['height']}]")# 이미지 불러오기 및 전처리
image_path = os.path.join(root_dir, load_anno, img_file_name)
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_resized = cv2.resize(image_rgb, (416, 416))
image_tensor = torch.from_numpy(image_resized).permute(2, 0, 1).unsqueeze(0).float() / 255.0성능 검증 부분
# gt_box 정보 추출하기
ann_ids = coco.getAnnIds(imgIds=chosen_img)
anns = coco.loadAnns(ann_ids)
gt_boxes = []
for ann in anns:
bbox = ann['bbox']
# CP는 Class Probability이니 = Class ID
CP_idx = coco_data.real_class_idx[ann['category_id']]
x, y, w, h = bbox
# bbox 좌표 정규화
bx = (x + w / 2) / img_info['width']
by = (y + h / 2) / img_info['height']
bw = w / img_info['width']
bh = h / img_info['height']
gt_box = torch.tensor([bx, by, bw, bh, 1, CP_idx])
gt_boxes.append(gt_box)
gt_boxes = sorted(gt_boxes, key=lambda box: (box[5], box[2] * box[3]))
# 정규 좌표평면상으로 변환한 GT_b_series_bbox 좌표 리스트 출력
for gt_box in gt_boxes:
print(gt_box)# 모델 추론
with torch.no_grad():
outputs = yolov3(image_tensor)
# NMS 적용을 위한 nms 클래스 인스턴스화
# 이때 `anchor` 변수는 앞서 정규 좌표평면의 anthor_box_list를 인자로
nms = Yolov3NMS(conf_th=0.4, anchor=coco_data.anchor_box_list)
# 아래의 메서드가 수행되면 [tx, ty, tw, th] -> [bx, by, bw, bh] 좌표변환
# 그 이후 NMS 필터가 한번에 다 돌아감
boxes = nms.non_max_suppression(outputs)
boxes = sorted(boxes, key=lambda box: (box[5], box[2] * box[3]))
# 최종 모델이 추론한 정보인 B_series_bbox 좌표 리스트 출력
for box in boxes:
print(box)# 결과 시각화 함수
def plot_boxes(image, boxes, labels):
plt.figure(figsize=(10, 10))
plt.imshow(image)
ax = plt.gca()
# 정규 좌표값 boxes를 원래 값으로 복원
scale_y = image.shape[0] # height
scale_x = image.shape[1] # width
boxes = [[box[0] * scale_x, # x_center * width
box[1] * scale_y, # y_center * height
box[2] * scale_x, # w * width
box[3] * scale_y, # h * height
box[4], box[5]] for box in boxes]
for box in boxes:
x_center, y_center, w, h, conf, label = box
# bbox를 그리는데 좌 상단 좌표, width, hight 필요
x1 = x_center - w / 2
y1 = y_center - h / 2
# 라벨의 텍스트 좌표 및 bbox의 색깔 정하기
label = int(label)
superclass = coco_data.cls_map[label]
color = coco_data.cls_color[superclass]
rect = Rectangle((x1, y1), w, h, linewidth=2, edgecolor=color, facecolor='none')
ax.add_patch(rect)
plt.text(x1, y1, s=labels[label], color='black', verticalalignment='top',
bbox={'color': color, 'pad': 0})
plt.axis('off')
plt.show()


잘 되나?


이런 결과가 나올줄은 몰랐는데 말이지...
아무튼 3주에 긴 여정으로

Yolo v3에 대한
로우-레벨 프로그래밍을 완료했다.
두서없이 정리된 부분이 있어 조금 아쉬운 부분이 있지만
앞으로 해야 할 것들도 많아서 이정도로 줄이고자 한다.

모든 코드는
https://github.com/tbvjvsladla/yolo_v3_pytorch
에 업로드했습니다.
