
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 작업 개요
이전 포스트 인공지능 고급(시각) 강의 복습 - 24. Fast Neural Style Transfer - Image Trnasfom Net-1 (6)에서
억지로 MobileNet + SENet 후 Image Transform Net을 수행하니
작업 결과가 썩 만족스럽지 않았다.
하여 역으로
https://github.com/dxyang/StyleTransfer
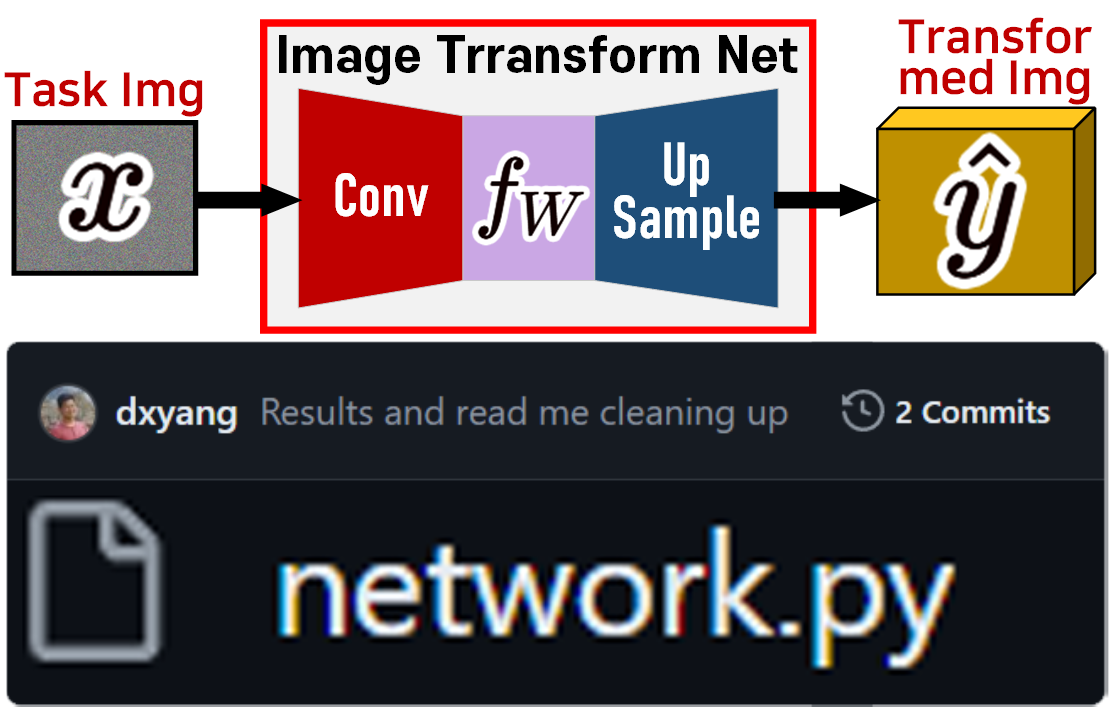
해당 깃허브 저장소에 업로드된 Image Transform Net의 코드를 최적화 한 뒤 Depthwise Separable Convolutions + Squeeze-and-Excitation block으로 문제를 해결하는 방식으로 선회를 하고자 한다.
2. network.py 코드최적화
Image Transform Net을 필자가 사용하기 쉬운 방식으로 코드를 최적화 하고
Upsample레이어는 nn.ConvTranspose2d으로 변경했을 때 전체 코드는 아래와 같이 정리할 수 있었다
import torch
import torch.nn as nnclass BasicConv(nn.Module):
def __init__(self, in_ch, out_ch, kernel_size, stride, relu=None):
super(BasicConv, self).__init__()
self.conv_block = nn.Sequential(
nn.ReflectionPad2d(kernel_size // 2),
nn.Conv2d(in_ch, out_ch, kernel_size, stride,
padding = 0, bias=False,),
nn.InstanceNorm2d(out_ch, affine=True),
)
self.relu = relu
if relu:
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv_block(x)
if self.relu:
x = self.relu(x)
return xclass ResidualBlock(nn.Module):
def __init__(self, in_ch):
super(ResidualBlock, self).__init__()
self.conv1 = BasicConv(in_ch, in_ch, kernel_size=3, stride=1, relu=True)
self.conv2 = BasicConv(in_ch, in_ch, kernel_size=3, stride=1, relu=False)
self.relu = nn.ReLU()
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.conv2(out)
out += identity
out = self.relu(out)
return outclass BasicTRConv(nn.Module):
def __init__(self, in_ch, out_ch, upsample=1, relu=None):
super(BasicTRConv, self).__init__()
self.tr_conv_block = nn.Sequential(
nn.ConvTranspose2d(in_ch, out_ch,
kernel_size=upsample, stride=upsample,
padding=0, output_padding=0,
bias=False),
nn.InstanceNorm2d(out_ch, affine=True),
)
self.relu = relu
if relu:
self.relu = nn.ReLU()
def forward(self, x):
x = self.tr_conv_block(x)
if self.relu:
x = self.relu(x)
return xclass ImageTransformNet(nn.Module):
def __init__(self):
super(ImageTransformNet, self).__init__()
#인코더
self.encoder = nn.Sequential(
BasicConv(3, 32, kernel_size=9, stride=1, relu=True),
BasicConv(32, 64, kernel_size=3, stride=2, relu=True),
BasicConv(64, 128, kernel_size=3, stride=2, relu=True)
)
#Residual Layer
residual_layer = []
for i in range(5):
residual_layer.append(ResidualBlock(128))
self.res_block = nn.Sequential(*residual_layer)
#디코더
self.decoder = nn.Sequential(
BasicTRConv(128, 64, upsample=2, relu=True),
BasicTRConv(64, 32, upsample=2, relu=True),
BasicTRConv(32, 3, upsample=1, relu=False),
)
def forward(self, x):
x = self.encoder(x)
x = self.res_block(x)
x = self.decoder(x)
return x코드를 최적화 했다고는 하나
역시 잘 동작하는지는 검증을 해봐야 한다.
따라서 해당 코드를 기반으로 Fast_NST_inference.ipynb
Image Transform Net 훈련을 수행했을 때 결과값을 확인해보자.

뭐 이정도면 원본 Network.py의 Image Transform Net을 잘 구현한 것 같다.
이제 몇가지 사전 실험을 수행하고자 한다
3.Tensor_size 변경실험
우선 실험 전 img_utils.py의 코드를 살짝 업데이트 했다.
https://github.com/tbvjvsladla/Neural_Style_Transfer/blob/main/img_utils.py
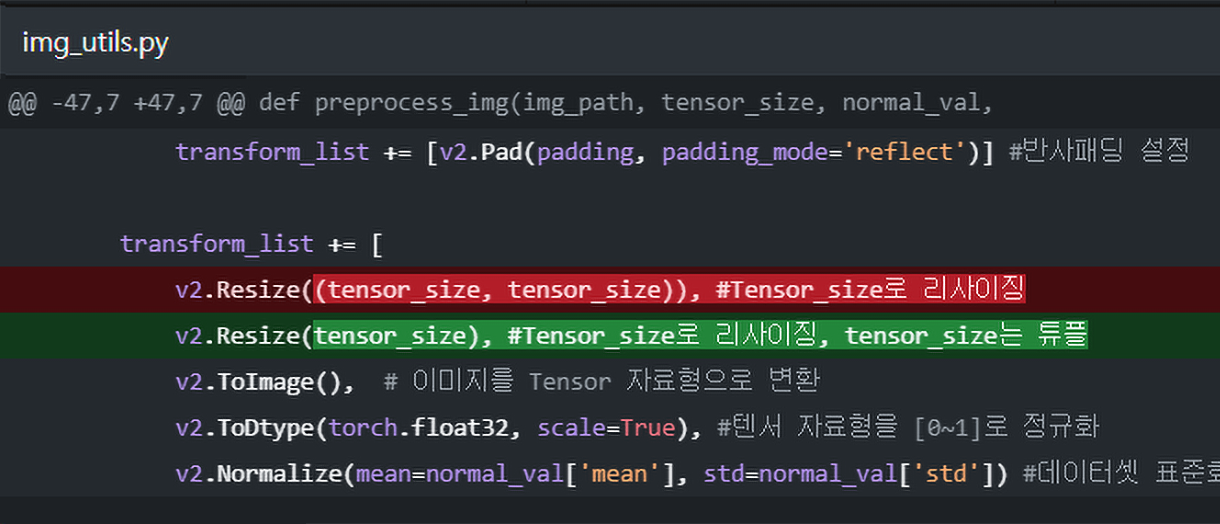
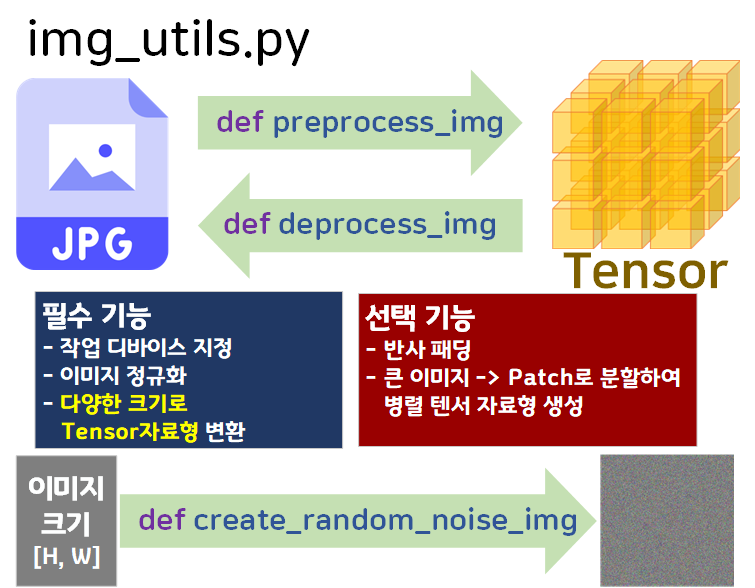
Img to Tensor을 수행할 때 무조건 정사각형으로만 변경되게 했었는데 이걸 좀 더 유연하게 직사각형으로도 변경 가능하게 코드를 살짝 수정했다.
왜 이렇게 변경을 했냐면
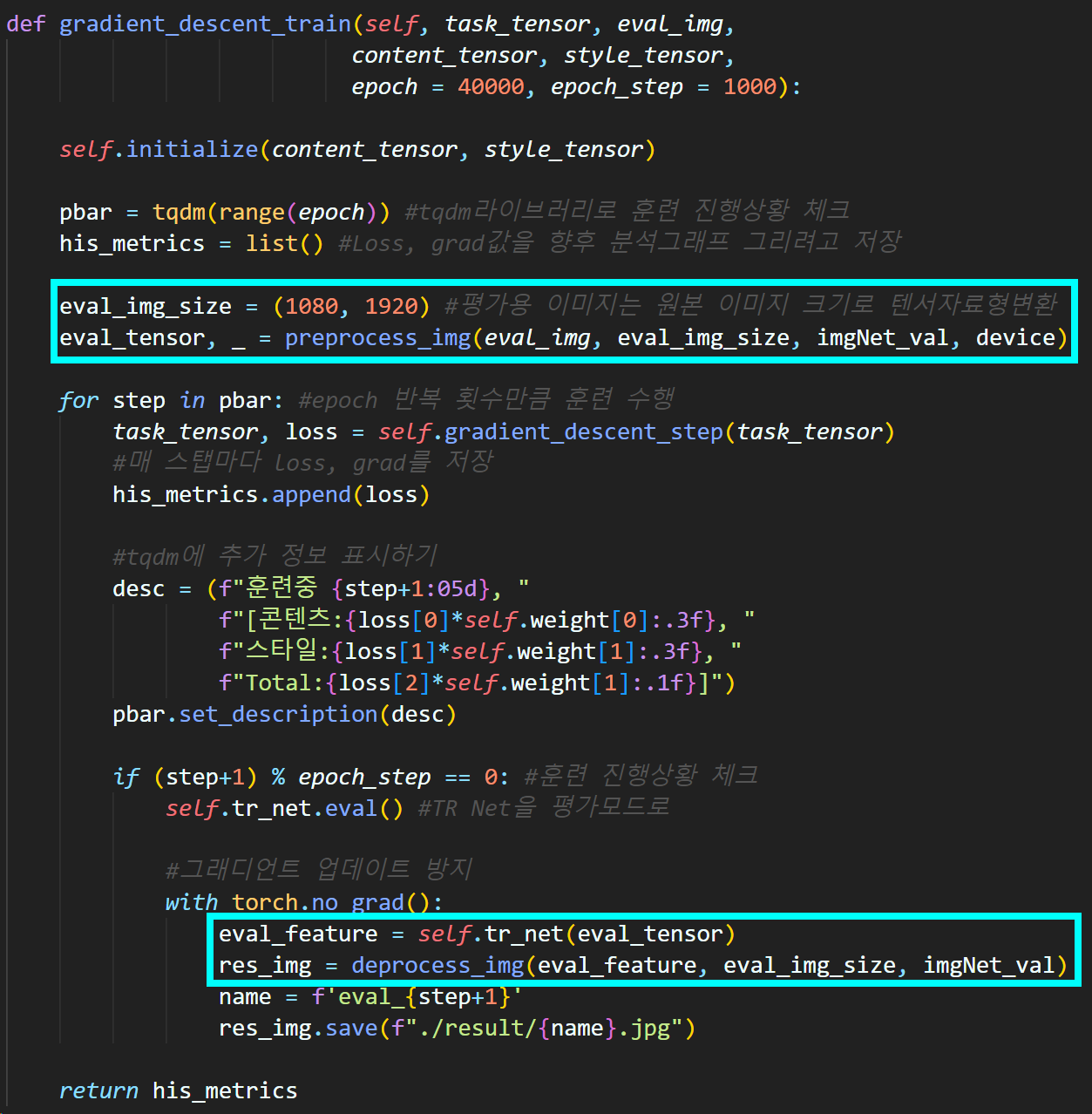
훈련 도중 훈련 과정을 샘플링 하기 위한 eval과정에서
평가용 이미지를 따로 생성한 뒤 해당 이미지로
Image Transform Net의 훈련성과를 테스트 하는게 더 고화질 성과 이미지를 취득할 수 있기 때문이다.
이제 실험 개요에 대해 설명하겠다.
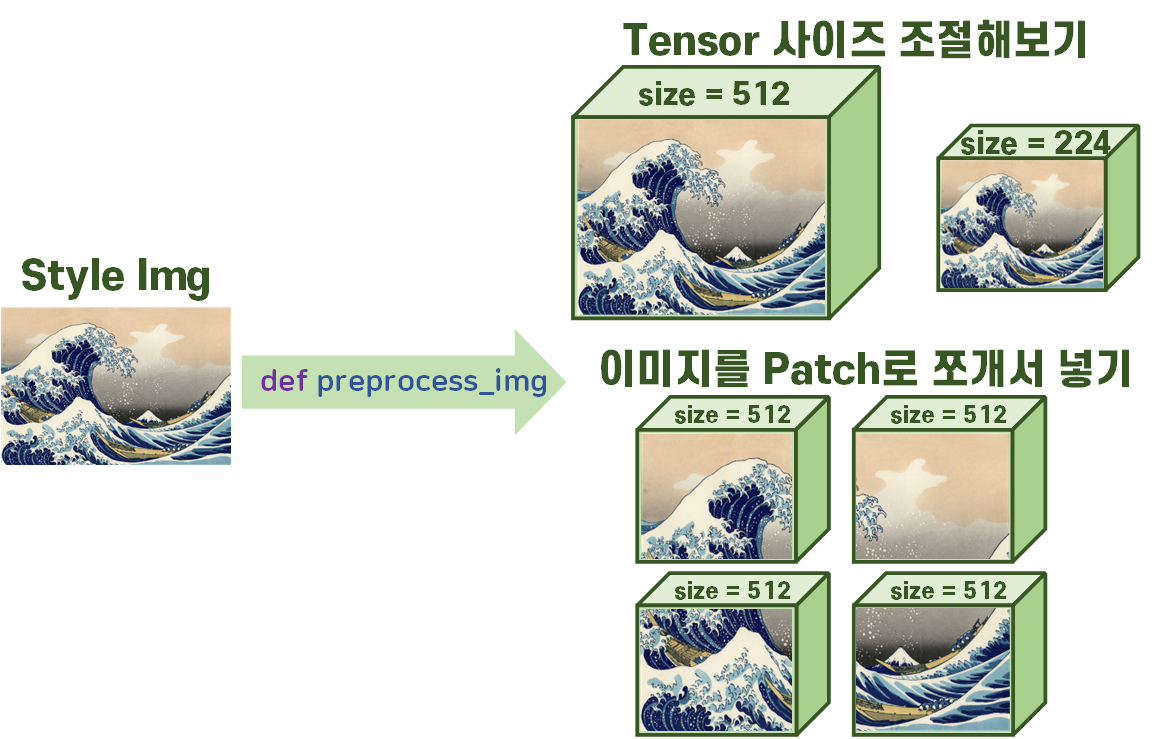
컨텐츠 이미지와 스타일 이미지의 Tensor자료형 변환 시
크기를 조절하는 것과
전체 크기는 변동이 없지만 큰 이미지를 여러개의 Patch로 쪼개서 쪼갠 Patch를 병렬로 Batch만든 뒤 훈련시키는 방법
두가지를 진행하고자 한다.
위 과정을 수행하는 이유는 스타일 이미지의 원본 크기에 거의 맞게 텐서 자료형을 만들어서 훈련시키는게 아무래도 훈련 소요시간도 크고 GPU부하도 많이 발생하기 때문이다.
따라서 각각의 경우로 최적화를 나름 해봤을 때 성능이 어떻게 나오는지 확인하고자 하는 것이다.
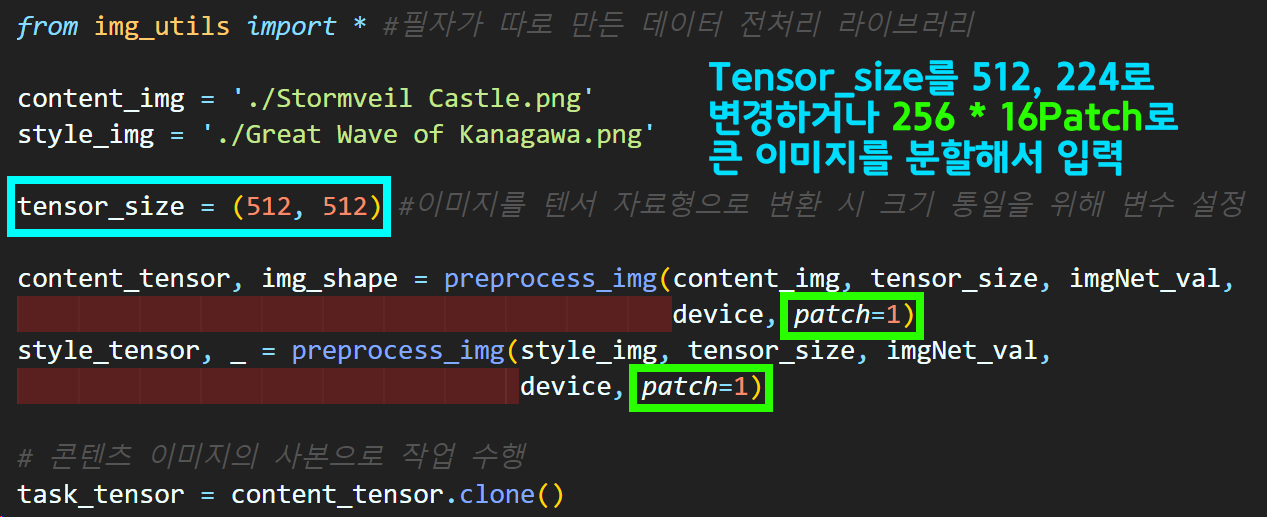
위와 같이 이미지 전처리 부에서 patch항목의 업데이트로
batch_size가 1이 아닌 n값으로 변경되니
이에 맞춰 코드 업데이트를 수행
주요 변경 부분은 Gram Matrix계산 부분이다.
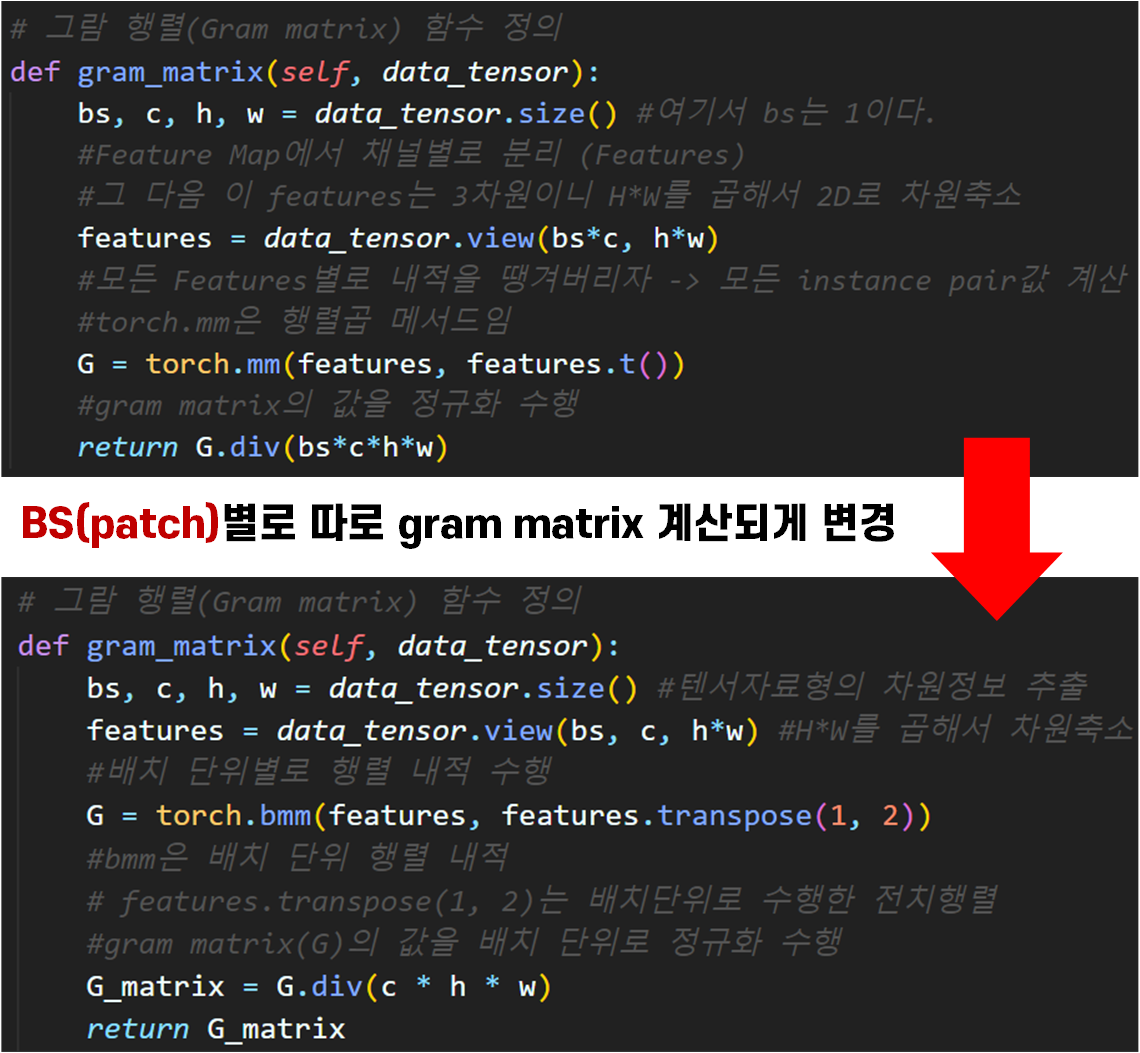
큰 차이는 없어보이지만
features계산 부분에서 1개의 bs만 있는 것으로 코드가 제한적이었다면
bs(patch개수)가 여러개여도 gram matrix가 patch의 개수에 적응형으로 patch 별 gram matrix가 계산되게끔 살짝 코드가 업데이트 된다.
물론 행렬 내적도 배치 별 행렬 내적이 가능한 함수인 torch.bmm으로 업데이트 되었고, 전치행렬도 텐서 자료형 전체에 대한 것이 아닌 일부 항목의 전치이니 .T()가 아닌 .transpose()메서드로 변경된다.
수정된 코드는 https://github.com/tbvjvsladla/Neural_Style_Transfer/blob/main/Fast_NST_train_v2.ipynb
Fast_NST_train_v2.ipynb라는 파일명으로 깃허브에 업데이트 하였다.




어떻게든 최적화를 시켜보려고 Tensor size를 줄여서 작업을 하면
스타일 이미지의 스타일 정보가 유실되서 style transfer이 잘 수행되지 않으며,
병렬처리 꼼수로 스타일 이미지를 Patch 단위로 쪼개서 style transfer를 수행하는건
음.. 뭐랄까 살짝 만족스럽지가 못하다...
정론은 Style Img를 최대한 원본 크기에 가깝게 사용하는게 style transfer가 가장 잘된다..
여기서 Content Img는 쪼개던, Patch로 자르던 별 영향을 받지 않는다.
4.Depthwise Separable 적용
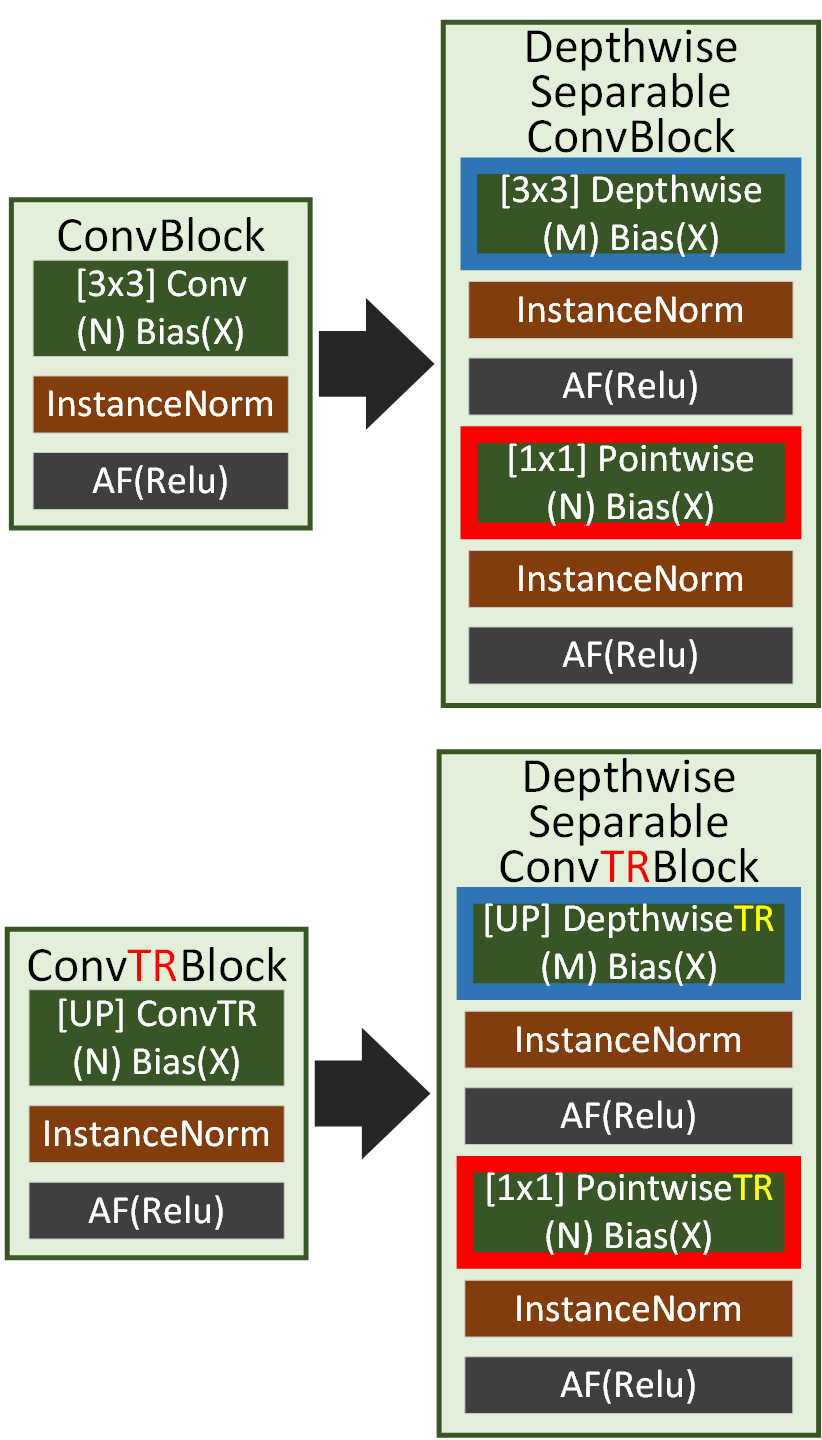
위 사진처럼 기존의 Conv, TRConv모두
Depthwise Separable Convolution 방식이 적용 가능하며
코드는
https://github.com/tbvjvsladla/Neural_Style_Transfer/blob/main/tr_net_dep.py
여기에 업로드를 하였다.
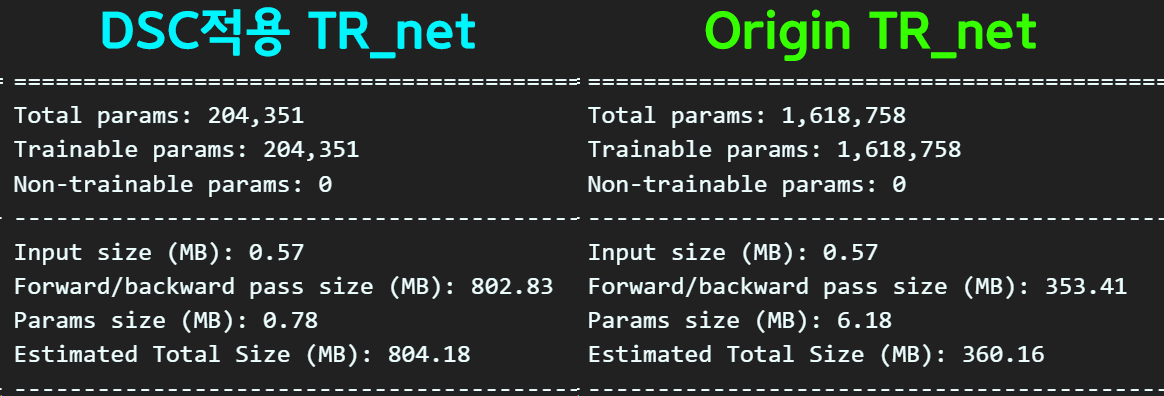
Param개수는 많이 감소했는데

성능은 많이 하락한것을 보니 적용을 안하는게 옳은 듯 하다
5.Squeeze-and-Excitation 적용
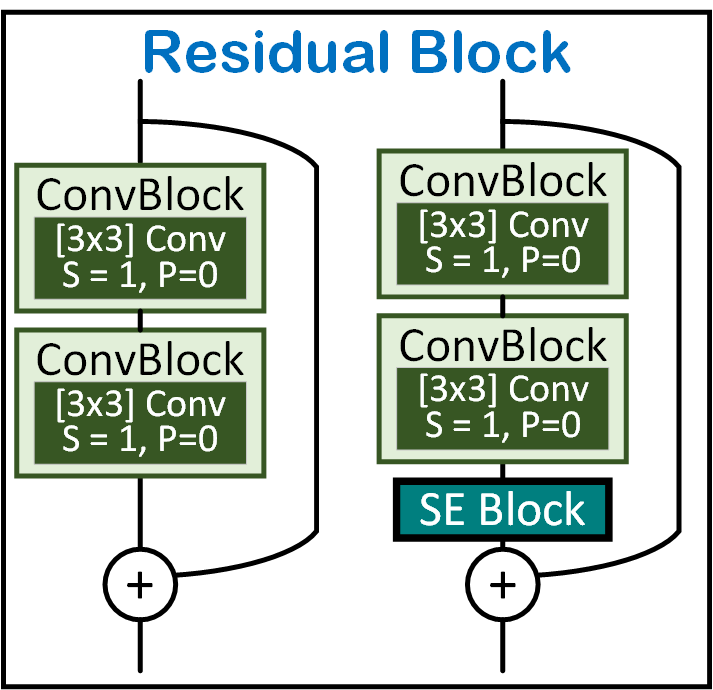
Image Transform Net의 몸통부분에 해당하는 Residual block에만
SE block를 적용하여 실험을 진행하였다.
이에 대한 코드는 https://github.com/tbvjvsladla/Neural_Style_Transfer/blob/main/tr_net_se.py
에서 확인할 수 있다.
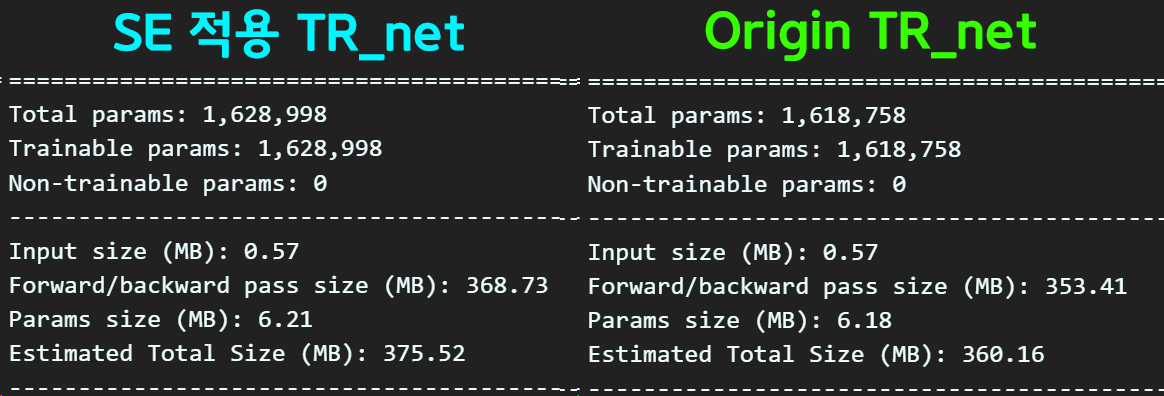
SE block적용으로 약간 Param이 증가했으나, 그만큼 Image Classification 분야에서 성능개선이 있었던 항목이니 결과를 확인해 볼 필요성이 있다.

이거는 Origin TR_net랑 거의 비슷한 성능을 내고 있으니
SE block은 적용을 해도 무방할 듯 싶다
6.Multiple Style Image Train
마지막으로 수행해보고자 하는 작업내용은
동일한 작가의 여러 작품을 Style Img로 묶어서 Image Transform Net을 학습시키는 것이다.

Tensor Size의 [H, W]를 900으로 하는 이유는 필자의 GPU 최대성이라 보면 된다.
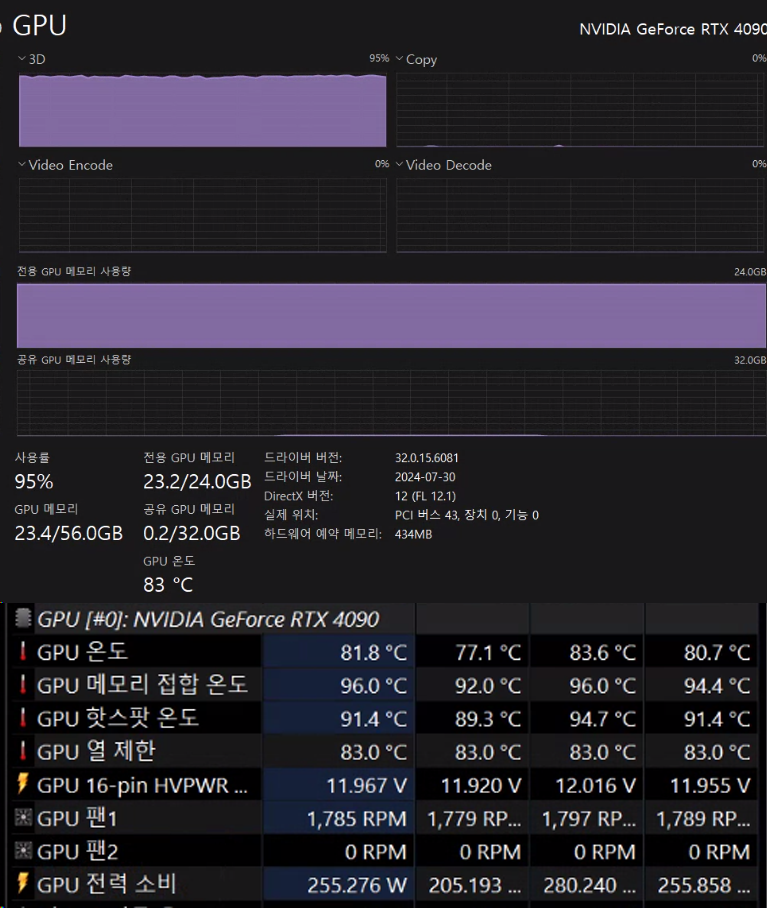
이게 VRAM의 용량이 GPU에 탑재된 VRAM을 넘어가서 공유 GPU 메모리까지 사용하게 되면 학습속도가 급격하게 하락하기에
아슬아슬하게 맞춰서 학습시키려면 사이즈가 900x900이 필자의 PC로는 최고성능이라 보면 된다.
이에 대한 코드는 데이터 전처리부에서 아래와 같이 구현한다.
from img_utils import * #필자가 따로 만든 데이터 전처리 라이브러리
import glob
style_img_path = './style_img/' #한 작가의 스타일 이미지가 저장된 경로
content_img = './Stormveil Castle.png'
style_imges = glob.glob(style_img_path + '*.jpg')
print(style_imges)
tensor_size = (900, 900) #이미지를 텐서 자료형으로 변환 시 크기 통일을 위해 변수 설정
content_tensor, img_shape = preprocess_img(content_img, tensor_size, imgNet_val,
device, patch=1)
style_tensors = list()
for style_img in style_imges:
style_tensor, _ = preprocess_img(style_img, tensor_size, imgNet_val,
device, patch=1)
style_tensors.append(style_tensor)
#리스트 내 이미지 텐서를 배치 탠서로 결합
style_tensor = torch.cat(style_tensors, dim=0)
#콘텐츠 이미지를 스타일 이미지 개수와 맞추기 위해 복제
content_tensor = content_tensor.repeat(4, 1, 1, 1)
# 콘텐츠 이미지의 사본으로 작업 수행
task_tensor = content_tensor.clone()
print(task_tensor.size())그 외의 코드는 모두 동일하게 진행된다.
훈련결과

훈련 epoch별로 Loss의 변화 양상 추이를 살펴본다면 이게 잘 진행되고 있는건지? 아닌지?를 수치로 확인하기는 힘들고
중간중간 결과물을 뽑아보면서 변화양상을 확인하는게 더 직관적이긴 하다.
아무튼 이전처럼 훈련이 완료되었으니 훈련 완료 후 생성한
weight file : SE4style_TR_net.pth를 사용하여
이전과 동일하게 스타일 전이 추론작업을 수행하면 아래와 같다.
SE4style_TR_net.pth : https://drive.google.com/file/d/1Hg9mMnH_Y9BHEtTLu7x8EupNC_VdcZt9/view?usp=drive_link
추론 결과






스타일 이미지를 몇개 더 묶어서 학습시킨 거라서 더 잘된건가?
이것도 사실 잘 모르겠다
전반적으로 style transfer가 수행되면 스타일이미즈의 화풍 중 색상 정보가 많이 반영되는것 같고 패턴같은건.. 음 다른것도 찾아보니 스타일 이미지가 모자이크처럼 단순 패턴이 반복되는 구조의 이미지여만 반영이 잘 되는듯 하다.
뭐 Image Transform Net도 분석을 다 해봤고 분석 후 MobileNet의 Depthwise Separable Convolutions, SENet의 Squeeze-and-Excitation block의 적용, 입력 이미지의 크기 조정 등
이것저것 해보고싶은것은 다 해본것 같다.
이정도로 마치면 될 듯 하다.
추론에 사용한 Fast_NST_inference : https://github.com/tbvjvsladla/Neural_Style_Transfer/blob/main/Fast_NST_inference.ipynb
에 업로드했으니 참조 바랍니다.
