개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. ResNeXt 개요
ResNext는 ILSVRC 2016 대회에서 2등을 차지한 모델로, 기본 모델의 뼈대는 ResNet이며, Cardinality(기수성), Aggregated transformations(집합적 변환)을 도입해 기존 ResNet의 폭(width)이나 구조적 복잡성을 자연스럽게 확장시켜, 이를 통해 더 복잡하고 다양한 데이터 분포를 효과적으로 학습할 수 있는 아키텍쳐로 구성되어 있다.
이 구조를 통하여 모델의 Param이나 연산 비용을 크게 증가시키지 않으면서도 성능 향상을 시켰다.
1.1 Cardinality
Cardinality(기수성)은 ResNext의 표현력을 확장하기 위한 주요한 하이퍼 파라미터로써
Network의 주요 설계 파라미터인 깊이(Depth), 폭(Width)에 이은 또다른 주요 파라미터로 제안하고 있다.
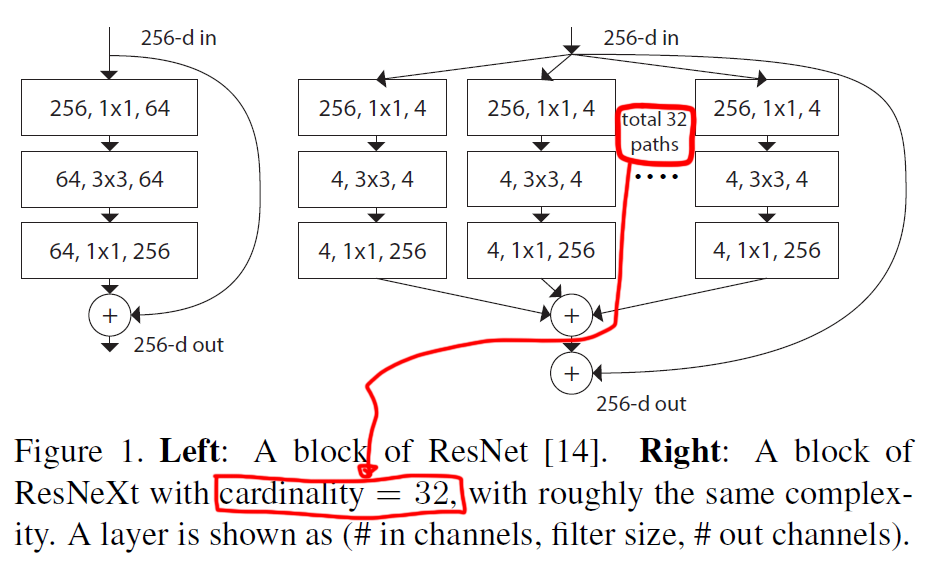
Cardinality(기수성)는 위 사진에서 알 수 있듯이 병렬로 처리되는 Convolution Layer Path의 개수를 의미한다.
이 병렬 Path는 독립적으로 여러개의 Group으로 나누어 각 그룹별로 독립적인 Convolution을 수행,
향후에는 이 출력을 합치는 방식(Sum혹은 Concat)으로 네트워크의 출력을 생성한다.
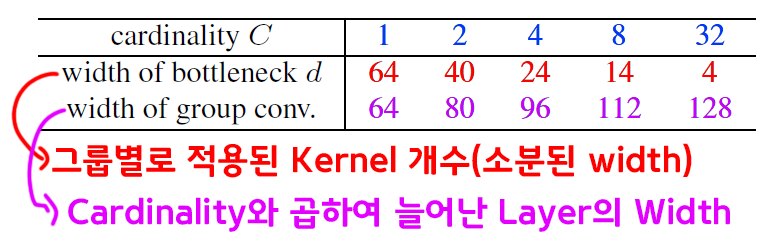
이때 이 병렬 처리의 단위가 Group Convolution이란 방식으로 구현되고, 각 Group별로 적용된 Kernel의 개수Width은 아래의 표로 전체 네트워크의 Width를 증가시키는 것과 같이 네트워크가 더 다양한 특징을 학습할 수 있는 효과를 낸다.
1.2 Aggregated Transformations
위 ResNext는 Cardinality 파라미터를 통해 입력된 이미지(Feature Map)를 여러개의 독립적인 Group로 나누어 병렬적으로 특징을 학습한다. 그 이후 결과Feature Map을 합치는데 이를 Aggregated Transformations이라 볼 수 있다.
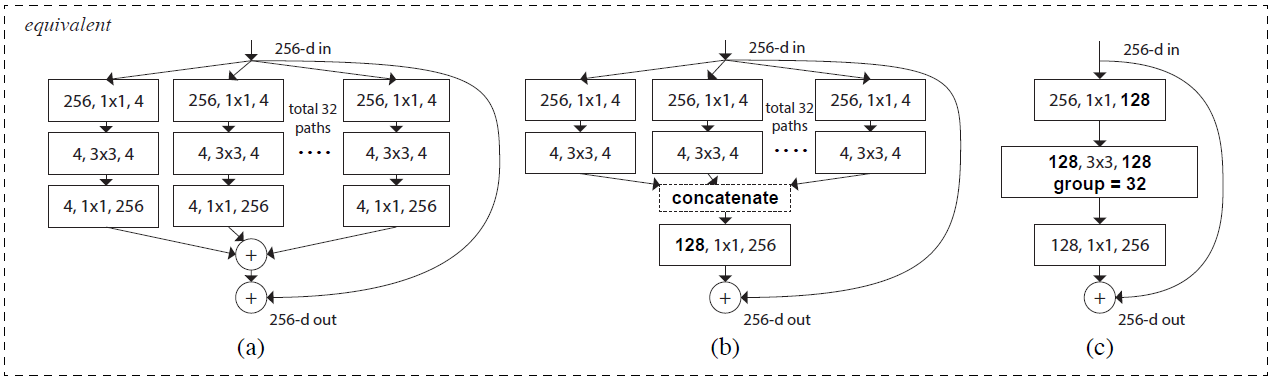
Aggregated Transformations을 Residual Block에 적용하는 방법은 총 3가지가 있으며, 모두 동일한 결과를 낸다.
위 사진은 Cardinality = 32, 각 Group별 적용된 Kernel의 개수 : width of bottleneck(d) = 4 일 때의 Aggregated Transformations 적용 예시이다.
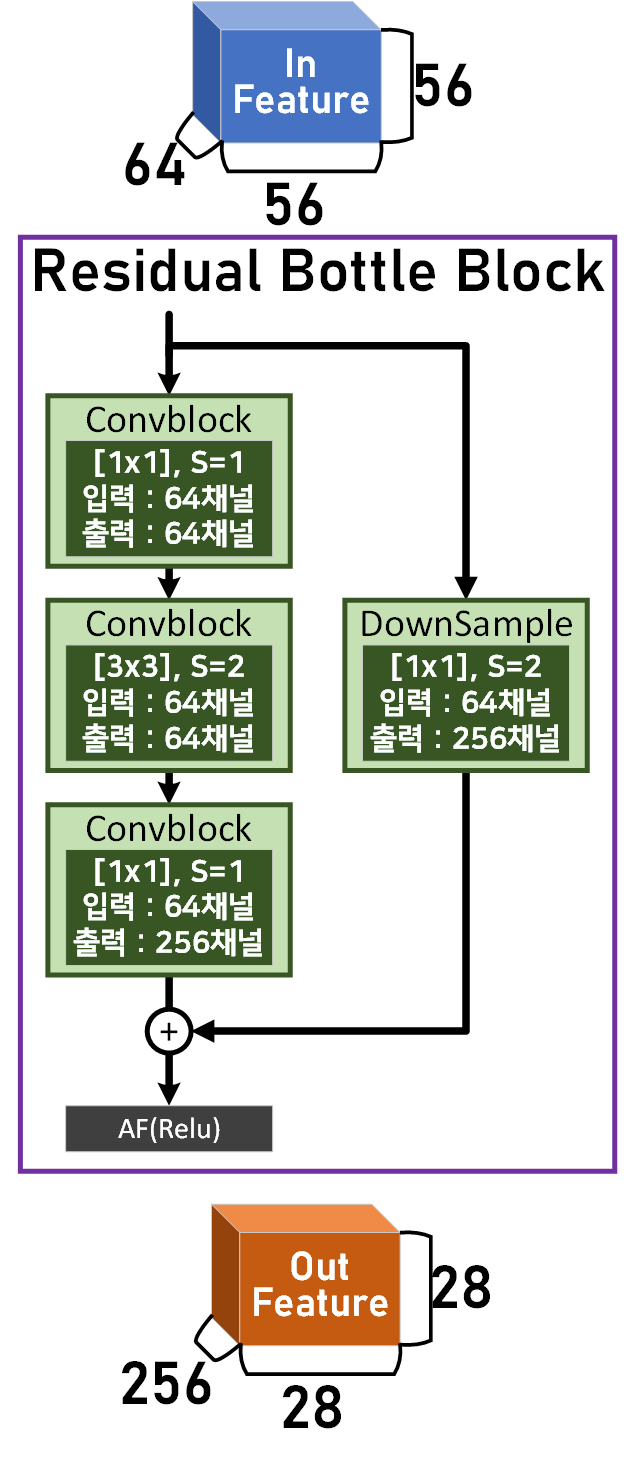
하이퍼 파라미터 Cardinality = 4, width of bottleneck(d) = 16으로 놓고 아래의 Residual BottleNeck Block를 다시 표현해보고자 한다.
1) Sum version Aggregated residual transformations
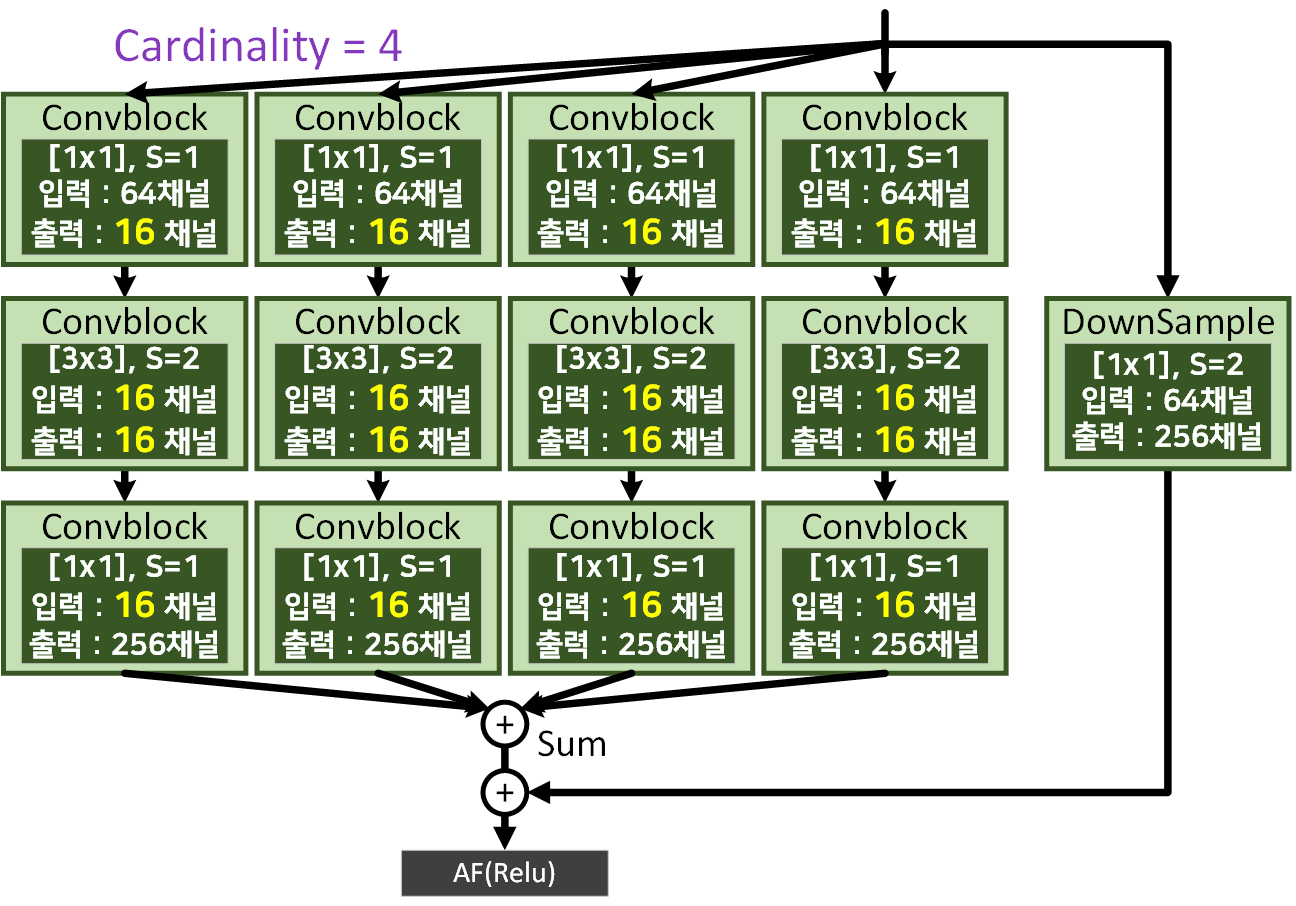
Cardinality = 4, width of bottleneck(d) = 16 옵션일 때는 위 사진처럼 가운데 Bottleneck block의 In, Out 채널이 모두 d 파라미터값인 16이 된다. 그리고 각 병렬 Path의 출력Feature는 Sum옵션을 통해 합산된 후 Residual connection이 적용된다.
이를 코드로 구현한다면 아래와 같다.
class BottleNeck_v1(nn.Module):
def __init__(self, in_ch, out_ch, config_F, stride=1):
super(BottleNeck_v1, self).__init__()
Cardinality, Contraction = config_F
#Cardinality는 그룹의 개수를 말한다
#Contraction는 축소계수를 의미한다.
mid_ch = round(out_ch / Contraction)
width_d = round(mid_ch / Cardinality) #한 병렬Path당 width
layers = []
for _ in range(Cardinality):
branch = nn.Sequential(
BasicConv(in_ch, width_d, kernel_size=1,
stride=1, padding=0, relu=True),
BasicConv(width_d, width_d, kernel_size=3,
stride=stride, padding=1, relu=True),
BasicConv(width_d, out_ch, kernel_size=1,
stride=1, padding=0, relu=False)
)
layers.append(branch)
self.conv1_2_3 = nn.ModuleList(layers)
self.relu = nn.ReLU(inplace=True)
self.downsample = None
if stride != 1 or in_ch != out_ch:
self.downsample = BasicConv(in_ch, out_ch, kernel_size=1,
stride=stride, relu=False)
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = sum(branch(x) for branch in self.conv1_2_3)
out += identity #Residual connection
out = self.relu(out)
return out2) Concat version Aggregated residual transformations
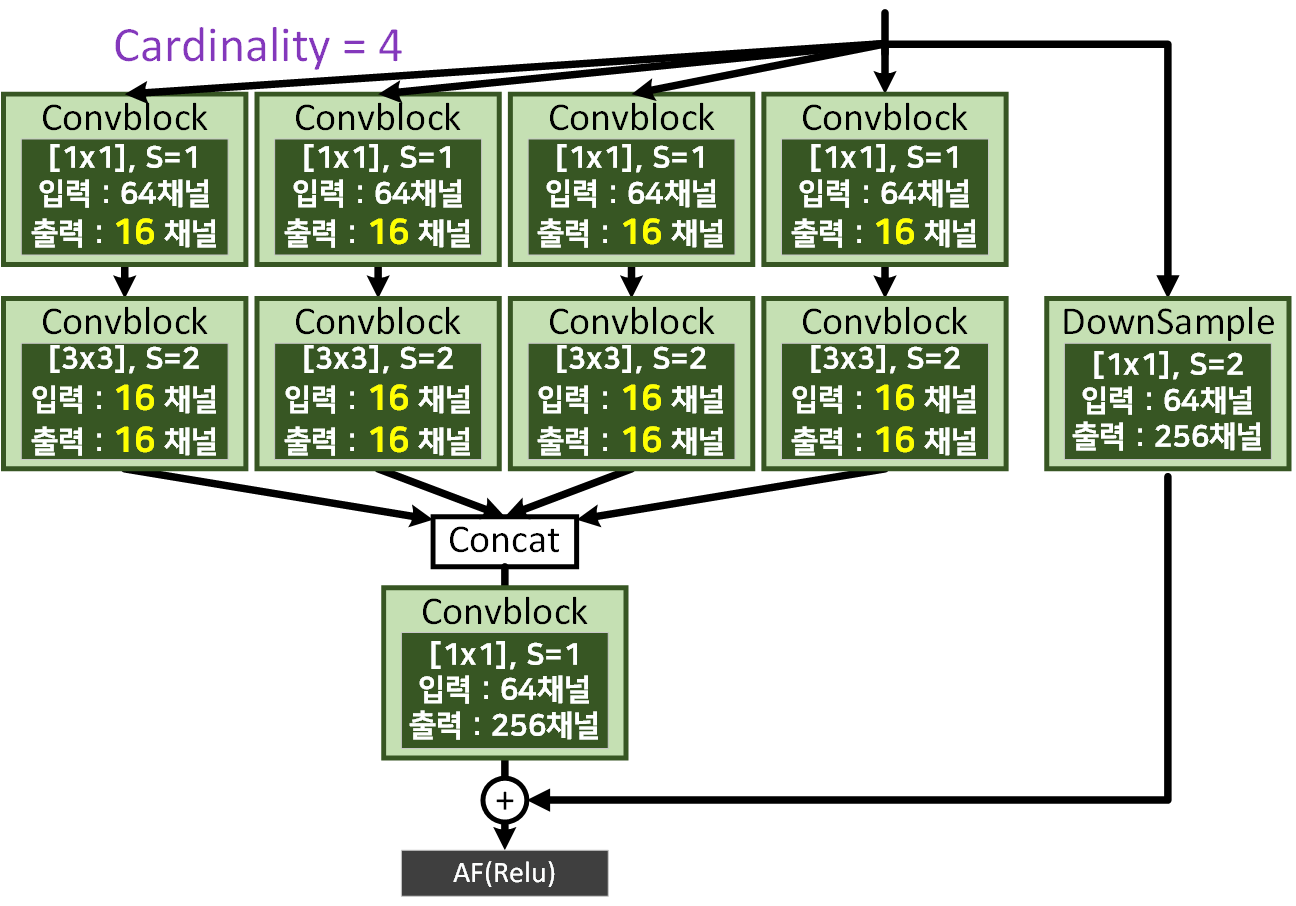
1) 버전과 다른점은 마지막 블럭을 병렬 Path로 나누는 것이 아니며, Bottleneck block의 출력을 Concat하는 차이점이 존재한다.
이를 코드로 구현하면 아래와 같다.
class BottleNeck_v2(nn.Module):
def __init__(self, in_ch, out_ch, config_F, stride=1):
super(BottleNeck_v2, self).__init__()
Cardinality, Contraction = config_F
#Cardinality는 그룹의 개수를 말한다
#Contraction는 축소계수를 의미한다.
mid_ch = round(out_ch / Contraction)
width_d = round(mid_ch / Cardinality) #한 병렬Path당 width
layers = []
for _ in range(Cardinality):
branch = nn.Sequential(
BasicConv(in_ch, width_d, kernel_size=1,
stride=1, padding=0, relu=True),
BasicConv(width_d, width_d, kernel_size=3,
stride=stride, padding=1, relu=True)
)
layers.append(branch)
self.conv1_2 = nn.ModuleList(layers)
self.conv3 = BasicConv(mid_ch, out_ch, kernel_size=1,
stride=1, padding=0, relu=False)
self.relu = nn.ReLU(inplace=True)
self.downsample = None
if stride != 1 or in_ch != out_ch:
self.downsample = BasicConv(in_ch, out_ch, kernel_size=1,
stride=stride, relu=False)
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = [branch(x) for branch in self.conv1_2]
out = torch.cat(out, dim=1)
out = self.conv3(out)
out += identity #Residual connection
out = self.relu(out)
return out3) Gropups optiion Aggregated residual transformations
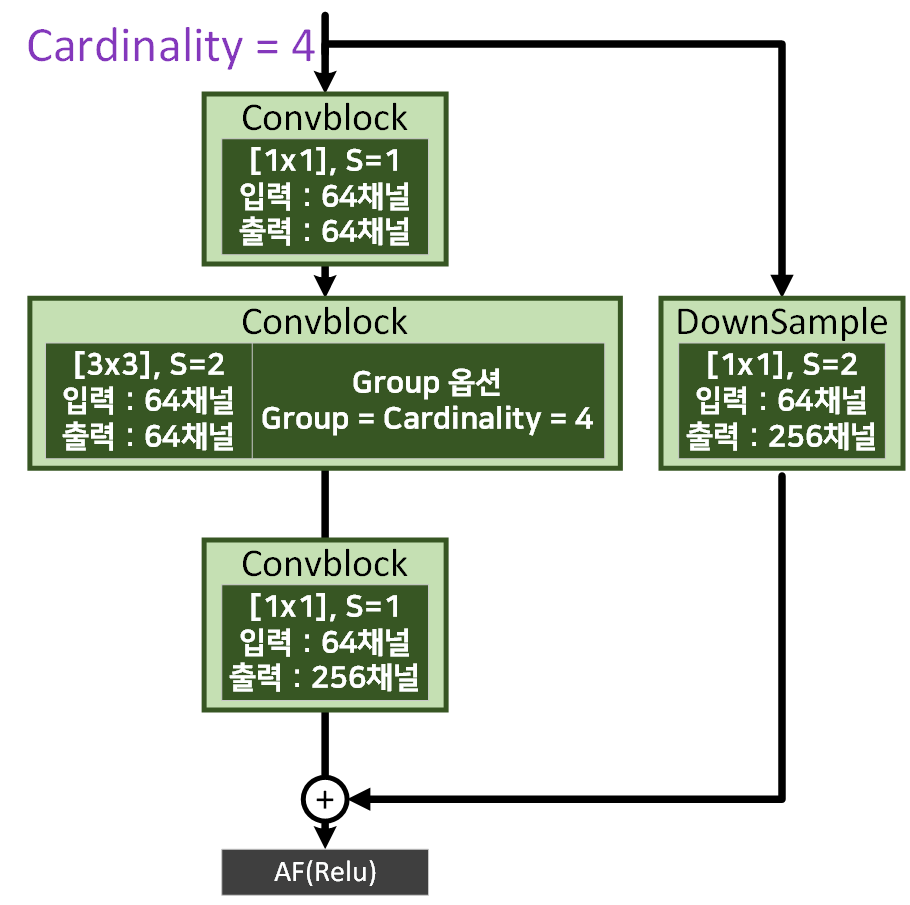
마지막 Aggregated Transformations 방법론은
 위 사진에서 표현한
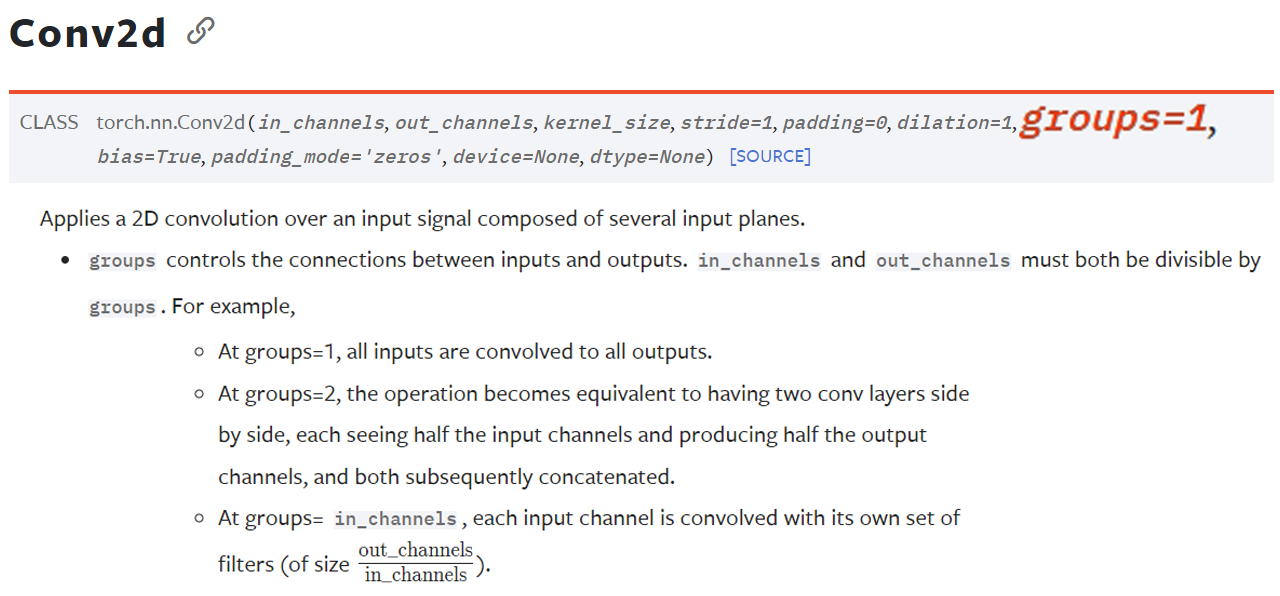
위 사진에서 표현한 nn.Conv2d의 gropus옵션을 사용하는 방법이다.
해당 옵션에 Cardinality = 4 값을 입력하는 방식으로 1), 2)과정이 전반적으로
인공지능 고급(시각) 강의 복습 - 24. 주요 CNN알고리즘 구현 : (1) MobileNet에서 설명에서 설명한 Depthwise Separable Convolutions기법와 유사하기에 해당 옵션을 사용했다 보면 된다.

이 gropus옵션에 대한 설명은 위 gif파일을 보면 이해가 빠를 것이다.
class BottleNeck_v3(nn.Module):
def __init__(self, in_ch, out_ch, config_F, stride=1):
super(BottleNeck_v3, self).__init__()
Cardinality, Contraction = config_F
#Cardinality는 그룹의 개수를 말한다
#Contraction는 축소계수를 의미한다.
mid_ch = round(out_ch / Contraction)
width_d = round(mid_ch / Cardinality) #한 병렬Path당 width
self.conv1 = BasicConv(in_ch, mid_ch, kernel_size=1,
stride=1, padding=0, relu=True)
self.conv2 = BasicConv(mid_ch, mid_ch, kernel_size=3,
stride=stride, padding=1,
groups=Cardinality, relu=True)
self.conv3 = BasicConv(mid_ch, out_ch, kernel_size=1,
stride=1, padding=0, relu=False)
self.relu = nn.ReLU(inplace=True)
self.downsample = None
if stride != 1 or in_ch != out_ch:
self.downsample = BasicConv(in_ch, out_ch, kernel_size=1,
stride=stride, relu=False)
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out += identity #Residual connection
out = self.relu(out)
return out2. ResNeXt 아키텍쳐
ResNext에 대해 소개하고 있는 논문 Aggregated Residual Transformations for Deep Neural Networks만 봐서는 정확하게 구현하는데 여러 에로사항이 꼽힌다.
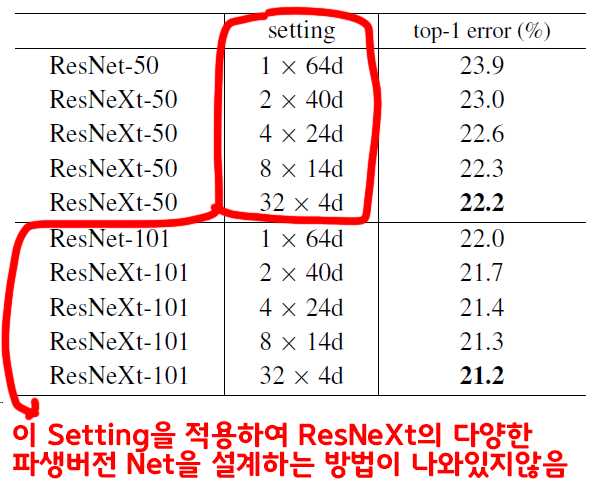
정확하게는 Cardinality 파라미터와 width of bottleneck(d) 파라미터를 어떻게 조합해서 파생된 ResNext를 만들어 내는지가 나와있지 않다.
그래서 다른 블로그를 찾아봐도 Cardinality=32, width of bottleneck(d)=4 항목 하나만 코드로 구현하고
그 외 버전은 코드로 구현한 것을 찾기 어려운 부분이 있다.
그래서 논문을 보면
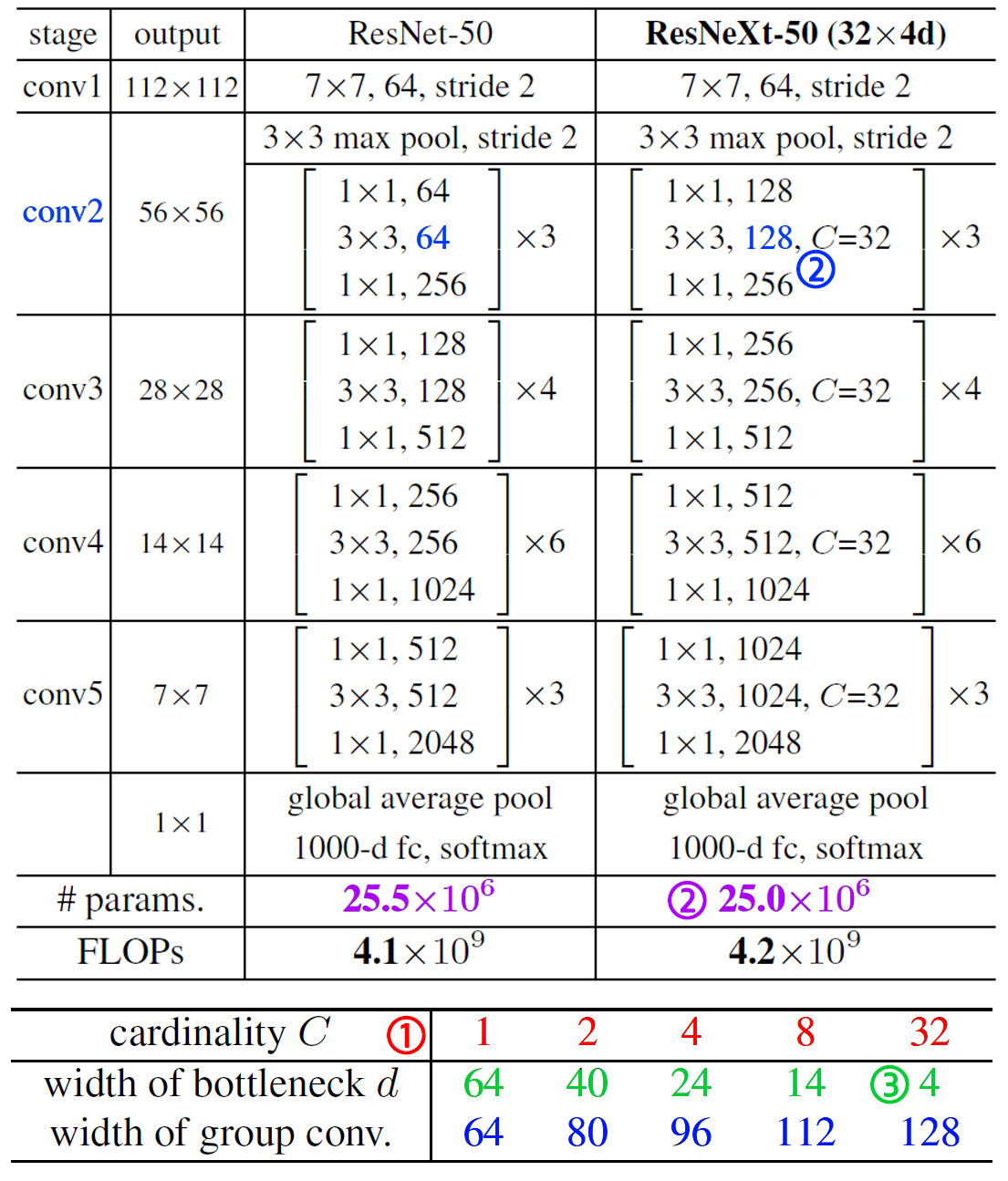
위 2개의 표와 연계를 해서 봐야하는데 각 파생 모델을 만드는 방식은 아래와 같다.
1) 적당한 Cardinality 값을 선정한다.
2) Conv2 블럭의 구성블럭인 Bottleneck 블럭의 가운데블럭 채널값을 적당하게 조절한다 조절하다보면 어느 순간 ResNet의 Params랑 비슷한 파라미터를 갖는 모델이 되는 순간이 온다
3) 이 때의 conv2 - bottleblock - mid conv layer의 채널값을 Cardinality로 나눈다 이게 width of bottleneck(d) 인자값이다.

진짜 이딴식으로 모델을 설계할 줄은 몰랏는데...

그래서 이 적당하게 조절하는 값을 찾아야 하는데 ResNet에 사용되는 확장계수(expansion)와 나름 관련이 있는 값이 쓰인다.
이 값을 찾아내는데 3번째 conv 블럭 Out channel로부터 얼마나 줄어든 channel값이 적용되는지를 찾는게 더 편리해서 필자는 이를 Contraction 계수값이라 임의로 명시했다.
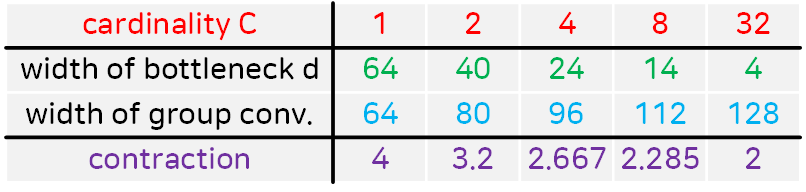
따라서 여러 파생 모델을 설계할 때는 위 Cardinality와 Contraction두개의 인자값을 적용하면 된다.
아무튼 ResNext를 코드로 구현하면 아래와 같다.
import torch
import torch.nn as nnclass BasicConv(nn.Module):
def __init__(self, in_ch, out_ch, relu=False, **kwargs):
super(BasicConv, self).__init__()
self.conv = nn.Conv2d(in_ch, out_ch, **kwargs, bias=False,)
self.bn = nn.BatchNorm2d(out_ch)
self.relu = relu
if relu: #여기서 Relu가 있고/없고를 결정하는게 코드짜기 더 편함
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
if self.relu:
x = self.relu(x)
return x
이거는 셋 다 동일한 기능을 하고, 코드는 1.2 Aggregated Transformations에서 설명했으니 사진으로 넘어간다.
class ResNeXt(nn.Module):
def __init__(self, blocks, config_F, version, num_classes=1000):
super(ResNeXt, self).__init__()
self.in_ch = 64
#cardinality(groups)와 축소계수값
self.config_F = config_F
self.conv1 = nn.Sequential(
BasicConv(3, self.in_ch, kernel_size=7,
stride=2, padding=3, relu=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.conv2_x = self._make_layer(256, blocks[0], version)
self.conv3_x = self._make_layer(512, blocks[1], version, stride=2)
self.conv4_x = self._make_layer(1024, blocks[2], version, stride=2)
self.conv5_x = self._make_layer(2048, blocks[3], version, stride=2)
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(2048, num_classes)
)
def _make_layer(self, out_ch, num_block, version, stride=1):
layers = []
# BottleNeck 클래스 선택
if version == 'v1':
block = BottleNeck_v1
elif version == 'v2':
block = BottleNeck_v2
elif version == 'v3':
block = BottleNeck_v3
else:
raise ValueError(f"Unknown version: {version}")
layers.append(block(self.in_ch, out_ch, self.config_F, stride))
self.in_ch = out_ch #in_ch의 업데이트
for _ in range(1, num_block):
layers.append(block(self.in_ch, out_ch, self.config_F))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.conv2_x(x)
x = self.conv3_x(x)
x = self.conv4_x(x)
x = self.conv5_x(x)
x = self.classifier(x)
return x설계한 모델을 인스턴스화 할 때 인자값 넣는 방식은 아래와 같다.

2.1 Aggregated Transformations 버전별 차이
앞서 1.2 Aggregate Transformations에서
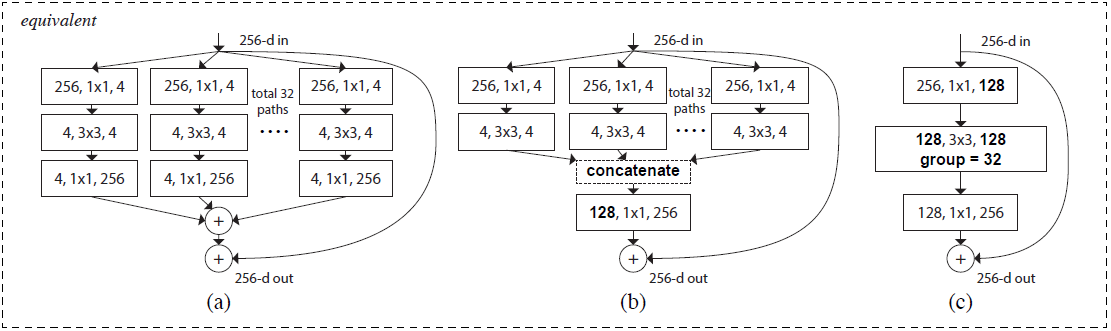 위 3가지 구현 방식에 따른 차이는 없다고 논문에서 언급하고 있다.
위 3가지 구현 방식에 따른 차이는 없다고 논문에서 언급하고 있다.
물론 코드 구현의 과정은 다르니, 이를 검증해 볼 필요성이 있다.
방법은 각 버전별로 ResNext 모델을 설계한 뒤
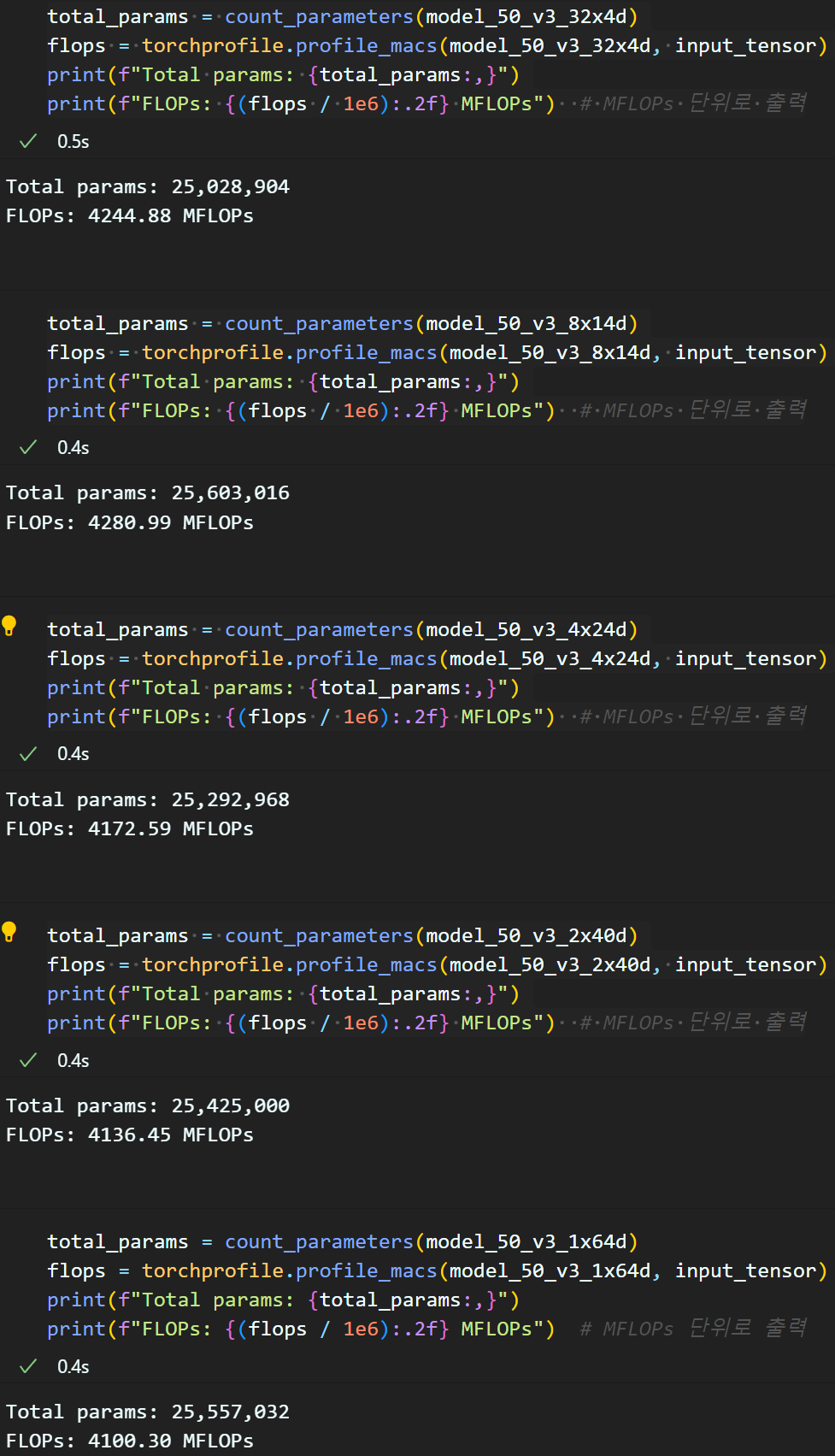
모델의Total Parm과 연산 cost인 FLOPs를 측정으로 해당 내용을 검증하고자 한다.
from torchsummary import summary
import torchprofile #flops 측정 라이브러리
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
input_tensor = torch.rand(1, 3, 224, 224).to(device)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)위와 같이 Total Parm, FLOPs을 측정한다.
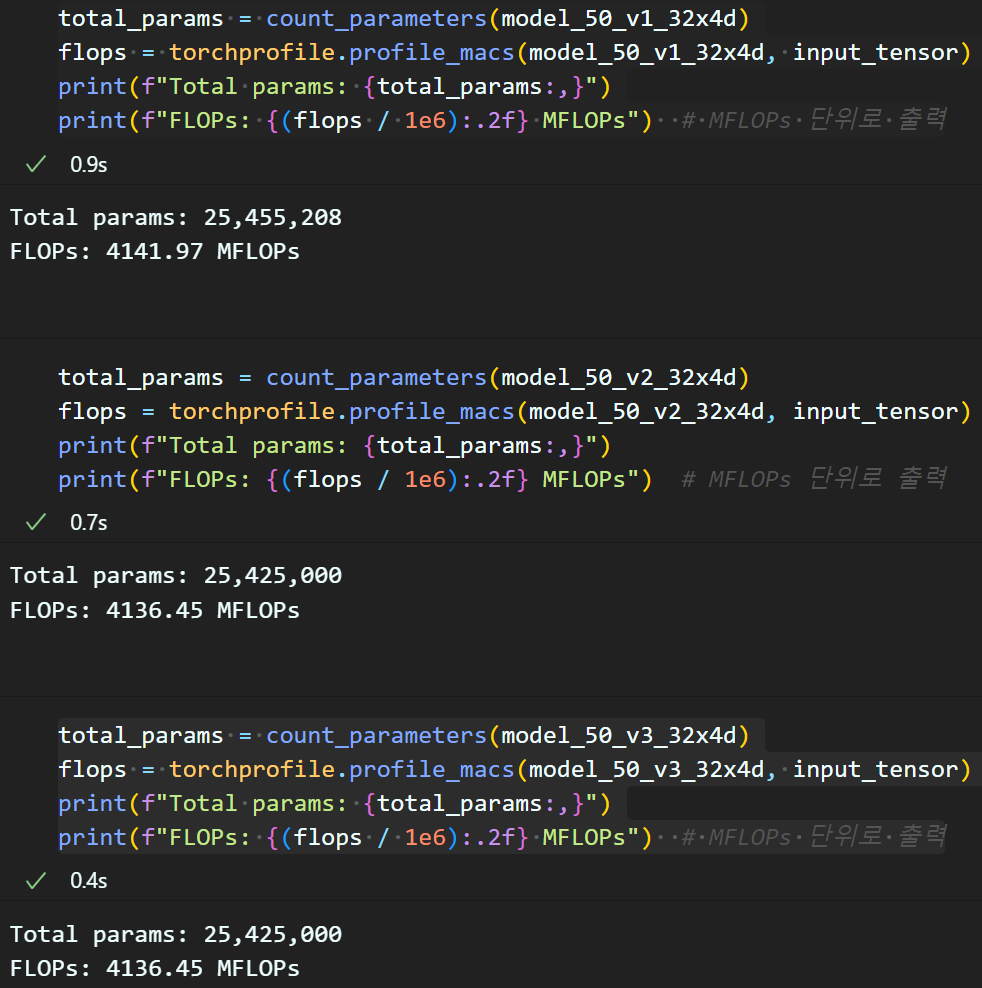
뭐.. 이정도면 같다고 봐야 할 수준의 다름이 측정됨을 확인할 수 있다.
1) Sum version Aggregated residual transformations 버전의 Total Parm, FLOPs이 좀 더 높게 측정되고
2), 3)은 Total Parm, FLOPs 두 값 동일한 것을 확인할 수 있다.
그리고 실험의 수행속도도 확인해보면
1) 2) 3)순으로 실험 측정속도도 더 빠른것을 확인할 수 있다.
논문에서는 1), 2), 3)버전 같다고는 하지만
실제 구현된 코드의 실행 속도나 Total Parm, FLOPs 를 고려한다면
3) Gropups optiion Aggregated residual transformations 버전으로 구현한 ResNext이 가장 실용성이 높은것을 확인할 수 있다.
참고로 위 파생 모델별 Total Parm, FLOPs은 아래와 같다.