
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. Wandb(Weights & Biases)

Weights & Biases: The AI Developer Platform 줄여서 wandb 현재 작업중인 Machine Learning(ML) 워크플로우에 아래 10가지의 지원기능을 웹 기반으로 제공하여 효율적인 ML 개발 및 최적활르 도와주는 플랫폼이라 볼 수 있다.
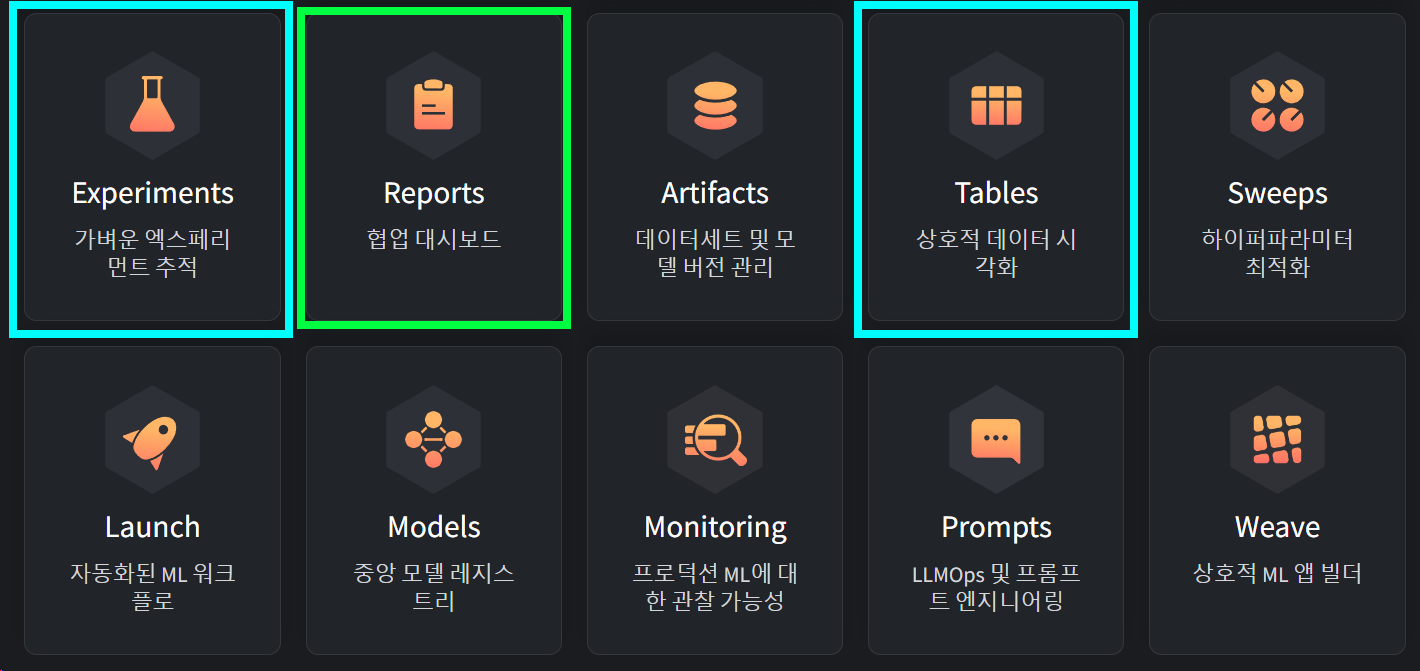 이 중 이번 포스트에서 필자가 수행한 내용은 이전 포스트
이 중 이번 포스트에서 필자가 수행한 내용은 이전 포스트
인공지능 고급(시각) 강의 복습 - 25. 주요 CNN알고리즘 구현 : (1) ResNeXt의 모델 훈련/검증 과정을 추적하고 시각화 하는 기능을 수행했다.
따지고 보면 필자의 지금 포스트는 wandb-intro에 속한다 보면 된다.
wandb에서 본인들의 플랫폼의 특 장점이라 소개하는건 아래의 이미지로 표현할 수 있다.

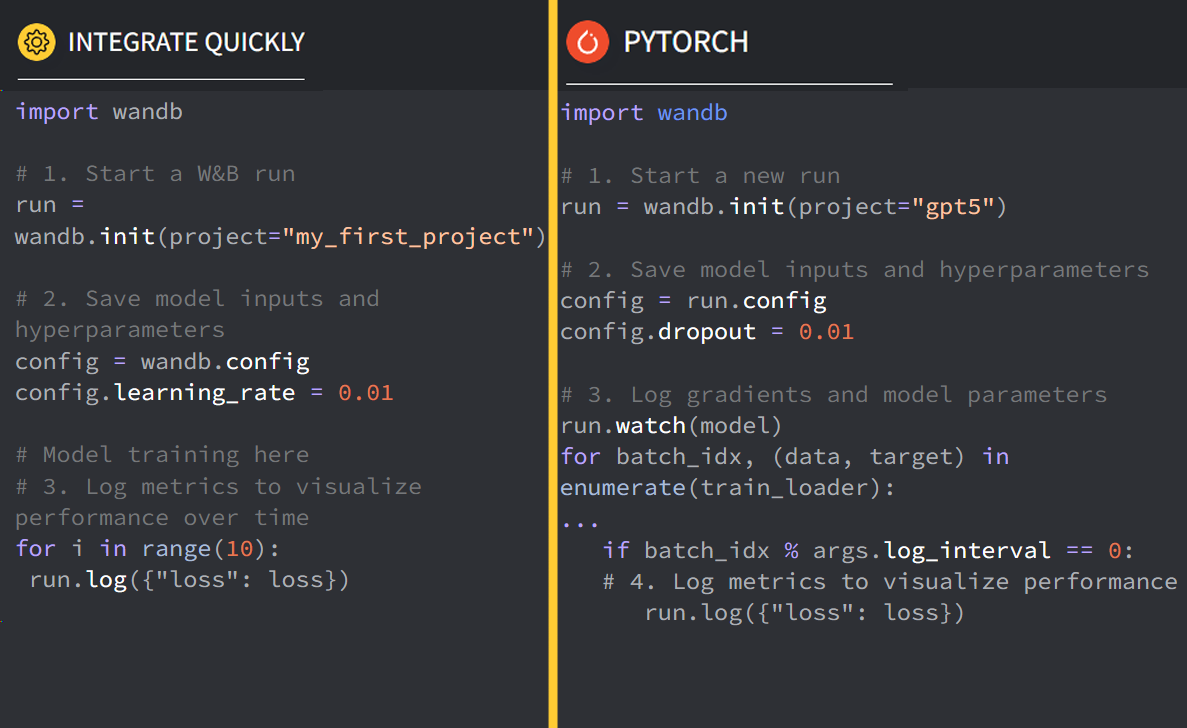 실제로도 저 홍보문구 옆에 각 ML 플랫폼 별로
실제로도 저 홍보문구 옆에 각 ML 플랫폼 별로 wandb를 어떻게 적용해야 하는지 코드를 요약하여 보여주고 있다.
2. wandb 가입&설치
홈페이지 가입은 오른쪽 상단이랑 왼쪽 하단에 가입버튼이 있으니 가입을 하면 되고
가입을 하면서 wandb의 Overview 영상도 시청을 해두자
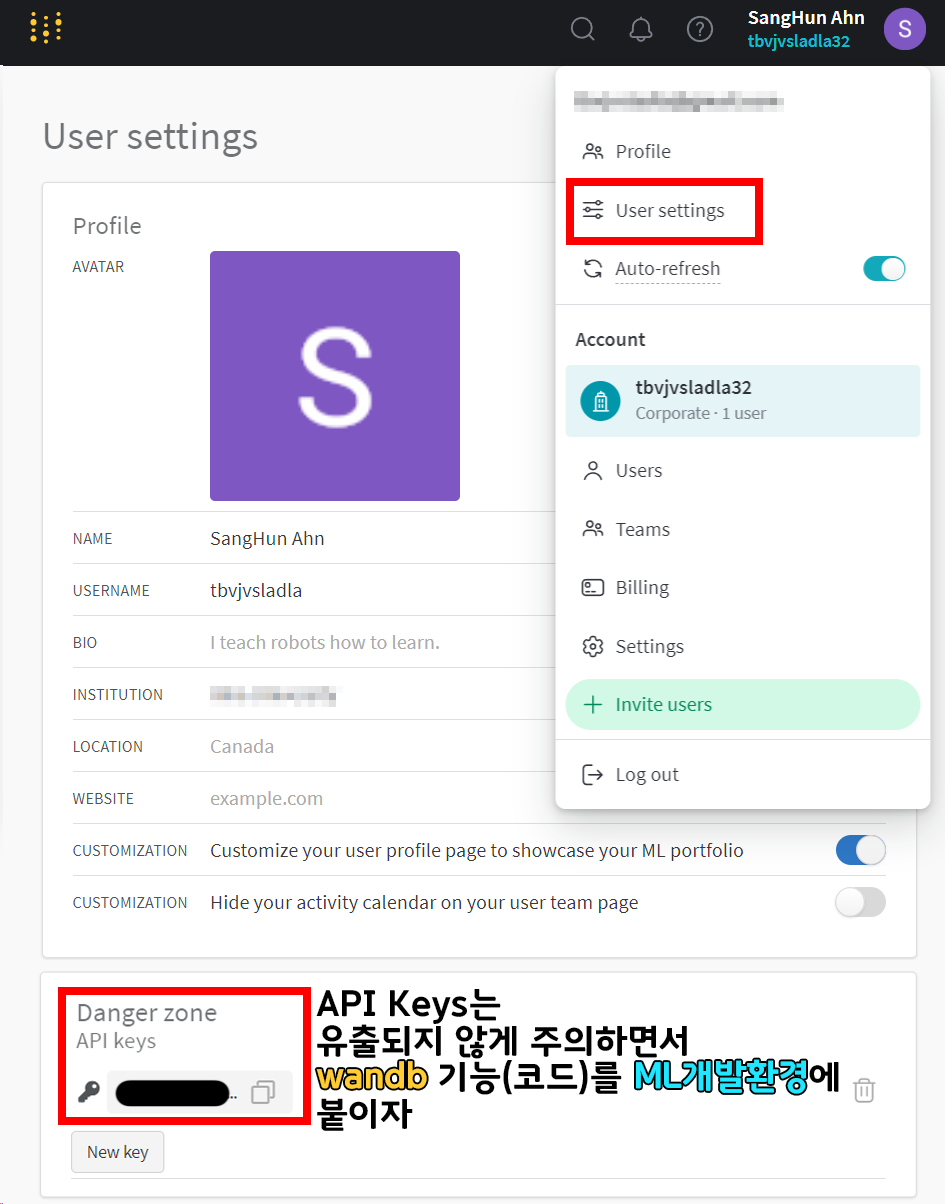
그리고 위 사진처럼 가입 후 User setting에 들어가서 이것저것 정보를 살피면
아래에 Danger zone API keys 항목이 존재한다.
이 API keys는 유출되지 않도록 잘 관리하도록 하자.
이제 PC에 wandb를 사용할 수 있도록 설치를 진행하자
그 전에 튜토리얼 2개가 있는데
두개의 파일을 보면서 wandb 사용방법을 참조하자
그런데...
홈페이지 Intro에서는 코드 짜기 쉽다고 하는데
해당 튜토리얼 보면 뭐 좀 알아먹기가 힘든 부분이 있다.
아무튼 설치는 아래와 같다
pip install wandb -Uq
wandb를 최신버전으로 설치 -U, 출력메세지는 적게 -q
옵션으로 설치한다.
2.1 wandb.login()
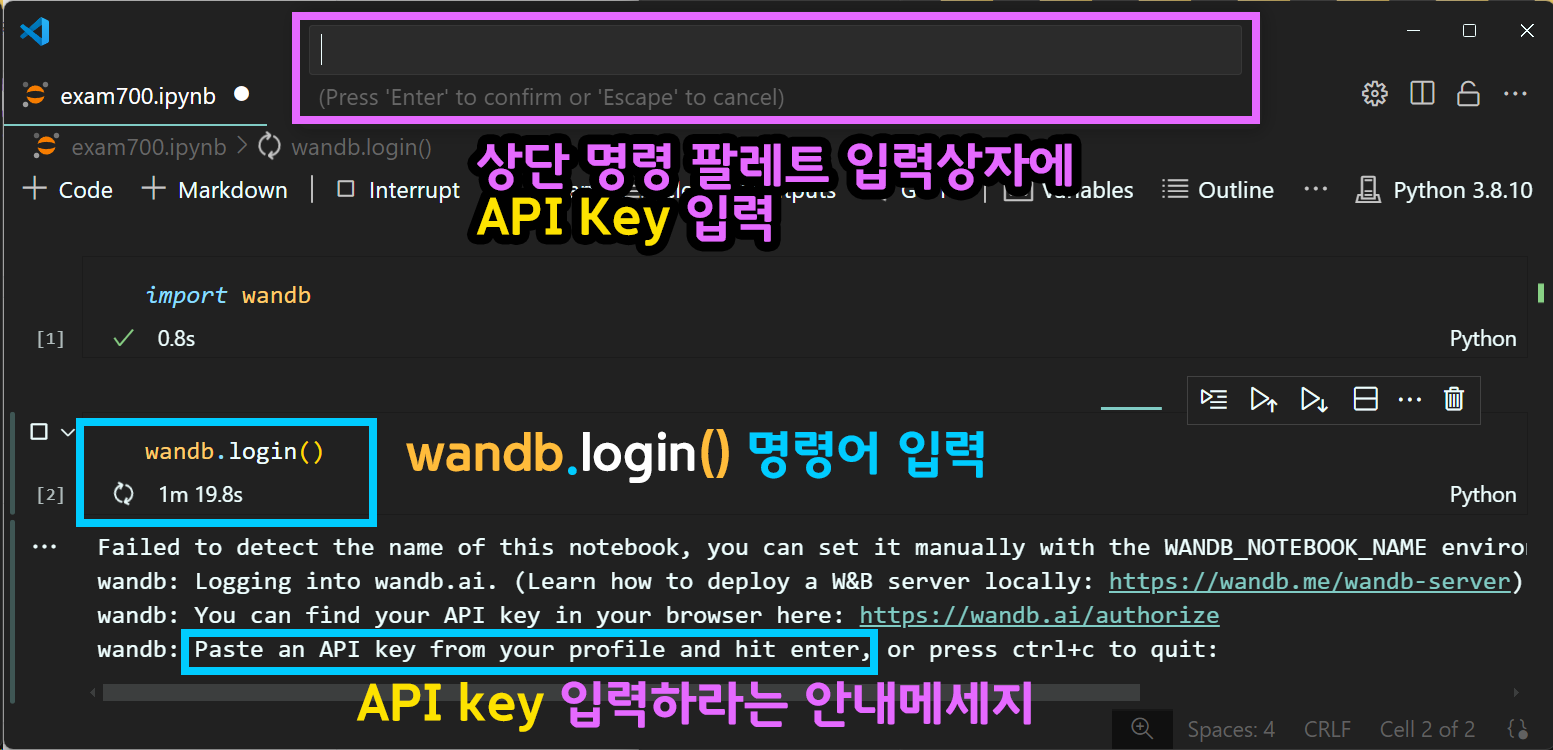
위 사진처럼
import wandb # Weights & Biases(W&B)라이브러리
wandb.login() #wandb 서비스 로그인을 수행하면 vscode의 상단 명령 팔레트 입력상자에 커서가 깜박거리게 된다.
여기에 API keys 키를 입력하면 로그인이 성공적으로 이뤄진다.
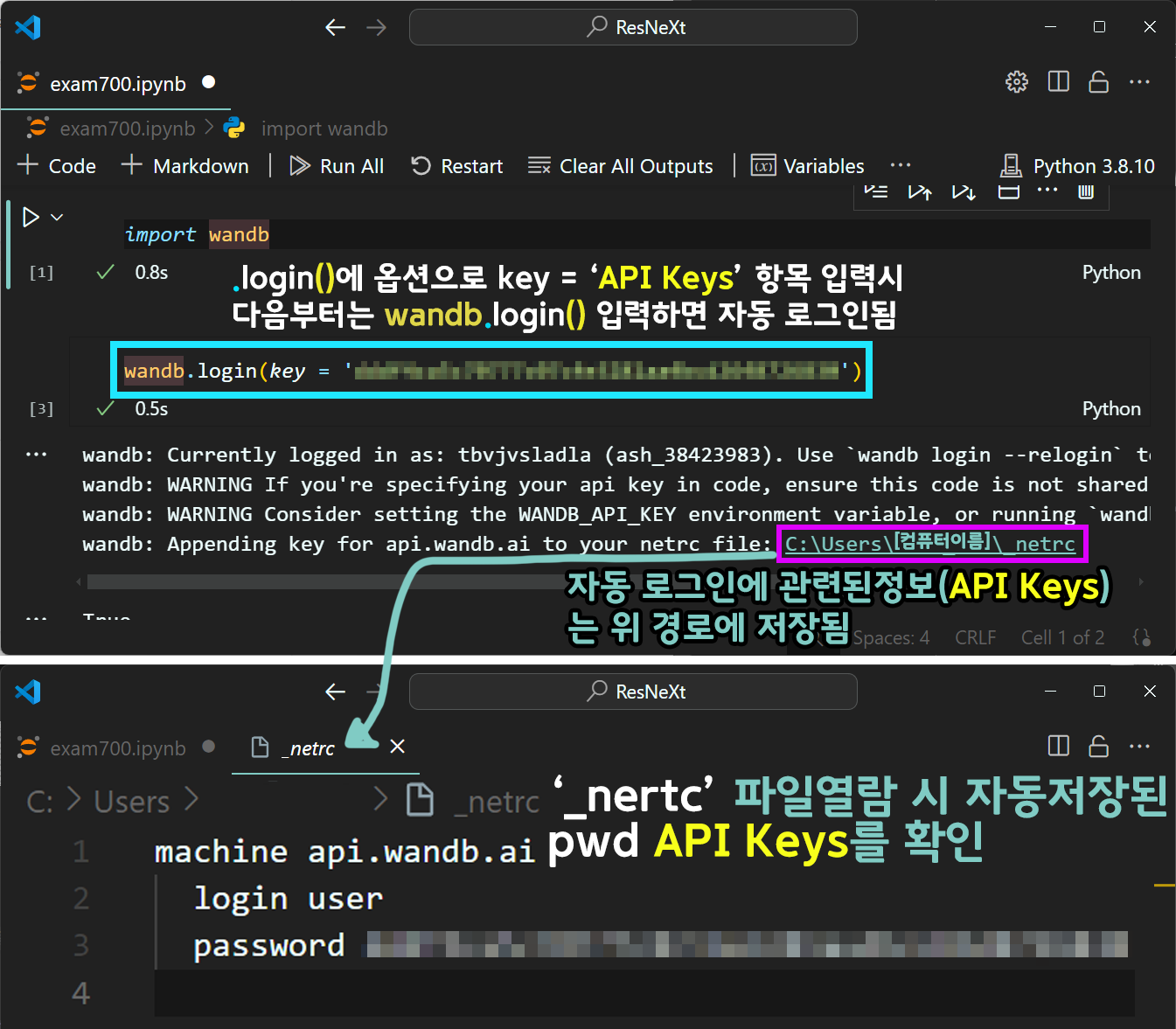
이때 위 사진처럼
wandb.login(key = '[API Keys]')로 인자값에 key = '[API Keys]를 입력하여 코드를 실행하면
해당 API keys가 _nertc라는 파일에 자동으로 정보가 넘어가서 윈도우 Users폴더에 저장되며,
이렇게 1회만 코드를 입력하면 다음부터는 API keys를 입력하지 않고
wandb.login() 함수를 구동하면 _nertc 정보를 참조하여 자동으로 로그인된다.
그러니까 딱 한번만 wandb.login(key = '[API Keys]')
수행하면 편해진다

key = '[API Keys] 인자 입력은 한 번만 넣으면 된다.
3. Wandb 적용하기
https://github.com/wandb/examples?tab=readme-ov-file
wandb에서 운영하는 github 저장소에 접속하면
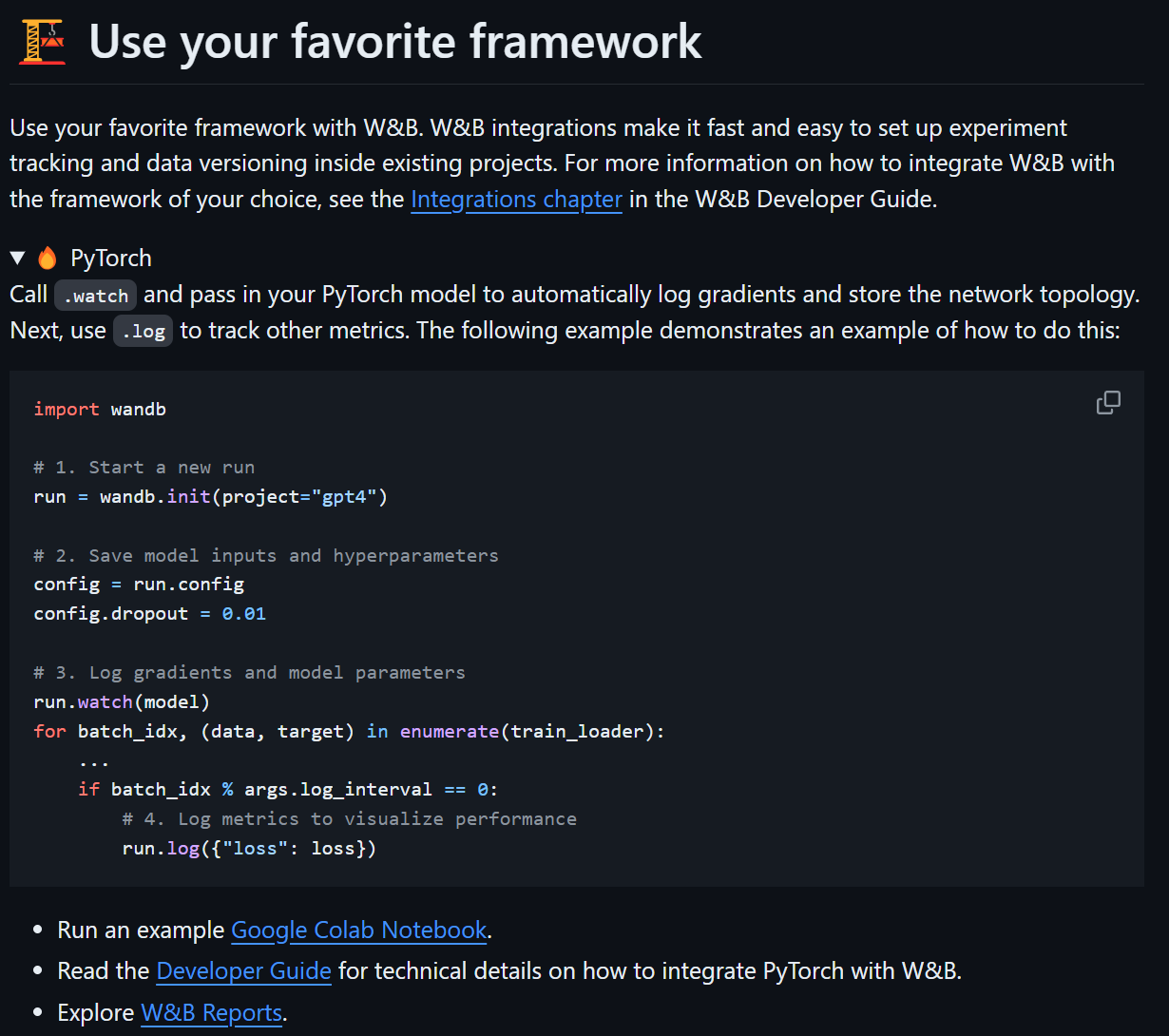 위 사진처럼 PyTorch 라이브러리에 어떻게
위 사진처럼 PyTorch 라이브러리에 어떻게 wandb를 적용하는지에 대한 설명 + 예제코드가 제공되고 있다.
예제 코드인 Simple_PyTorch_Integration.ipynb를 그냥 맨 처음부터보면
필자의 느낌은.. 어렵다
코드가 어렵습니다
일단 필자가 그동안 CNN코드를 작성하는 방식이랑 순서가 많이 다른게 한몫 하기도 하고
함수 함수 함수 이런식으로 3회 이상 참조하는 코드가 꽤 많아서 코드를 왓다갓다 해야 하는 부분이 많아
알아먹기 힘들었다.

뭐.. 좀 어렵긴 하지만 과정만 알아보자
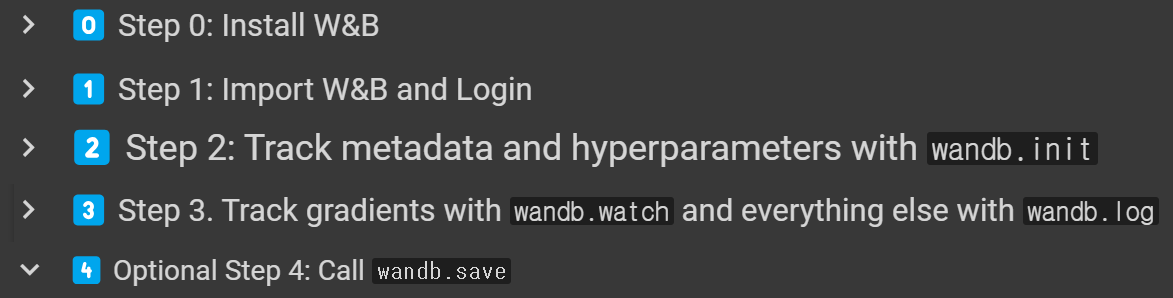
과정은
1) W&B 설치 (pip install wandb -Uq)
2) W&B 로그인 (wandb.login())
3) W&B 초기화 (wandb.init())
4) W&B 웹 서버로 추척할 정보 보내기(wandb.watch(), wandb.log())
5) 옵션 : 결과 저장 (wandb.save())
이렇게 5가지 과정으로 나누어 볼 수 있다.
위 1), 2)는 위에서 수행했으니 3), 4), 5)를 진행하면 되는데 필자는 5)는 귀찮아서 패스한다.
아무튼 위 과정을 필자가 그동안 수행한 CNN모델의
학습/검증에 적용하고자 한다.
3.1 필자의 CNN모델의 학습/검증 Workflow

위 workflow대로 인공지능 고급(시각) 강의 복습 - 25. 주요 CNN알고리즘 구현 : (1) ResNeXt에서 구현한 모델 ResNeXt을 훈련/검증시키는 코드를
https://github.com/tbvjvsladla/ResNext_wandb/blob/main/ResNext_Train_val.ipynb
에 업로드 하였다.
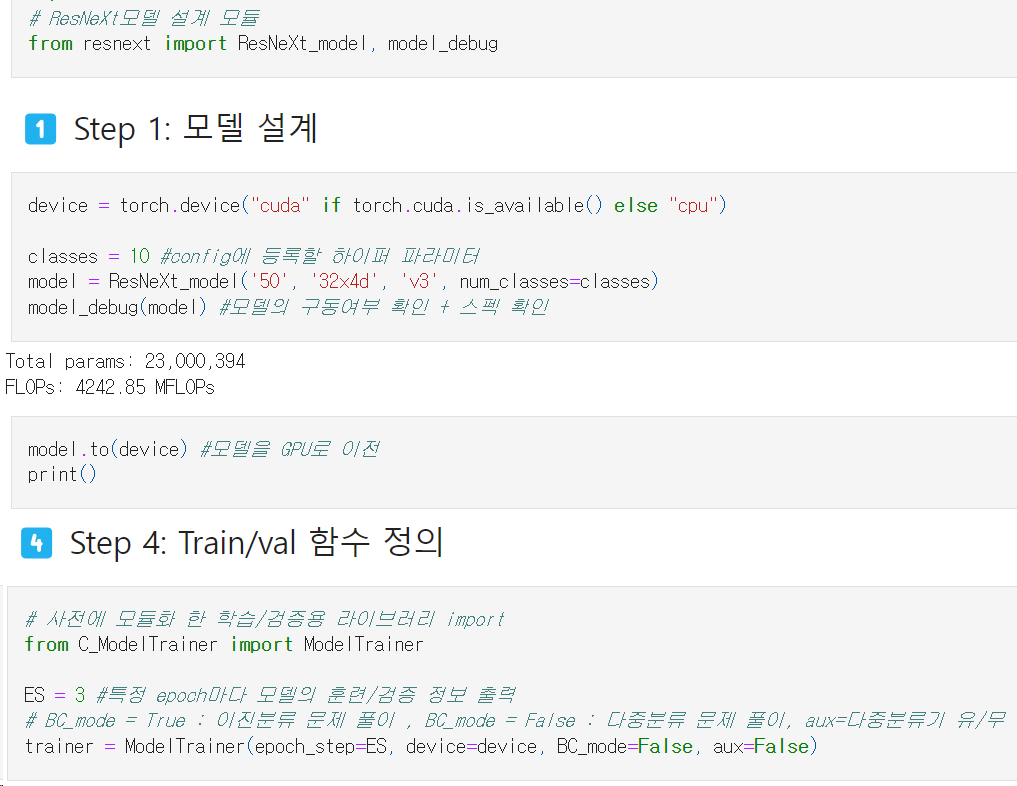
위 사진처럼 모델 설계, Train/val 함수 정의파트는 따로 resnext.py, C_ModelTrainer.py로 모듈화 한다.
이에 대한 코드도 https://github.com/tbvjvsladla/ResNext_wandb
저장소에서 확인 할 수 있다.
3.2 wandb 기능 추가하기
위 3.1 CNN 모델 학습/검증 workflow에 wandb기능을 추가하는데 각 step 사이에 함수를 집어넣으면 된다.
이는 아래의 그림처럼 표현할 수 있다.
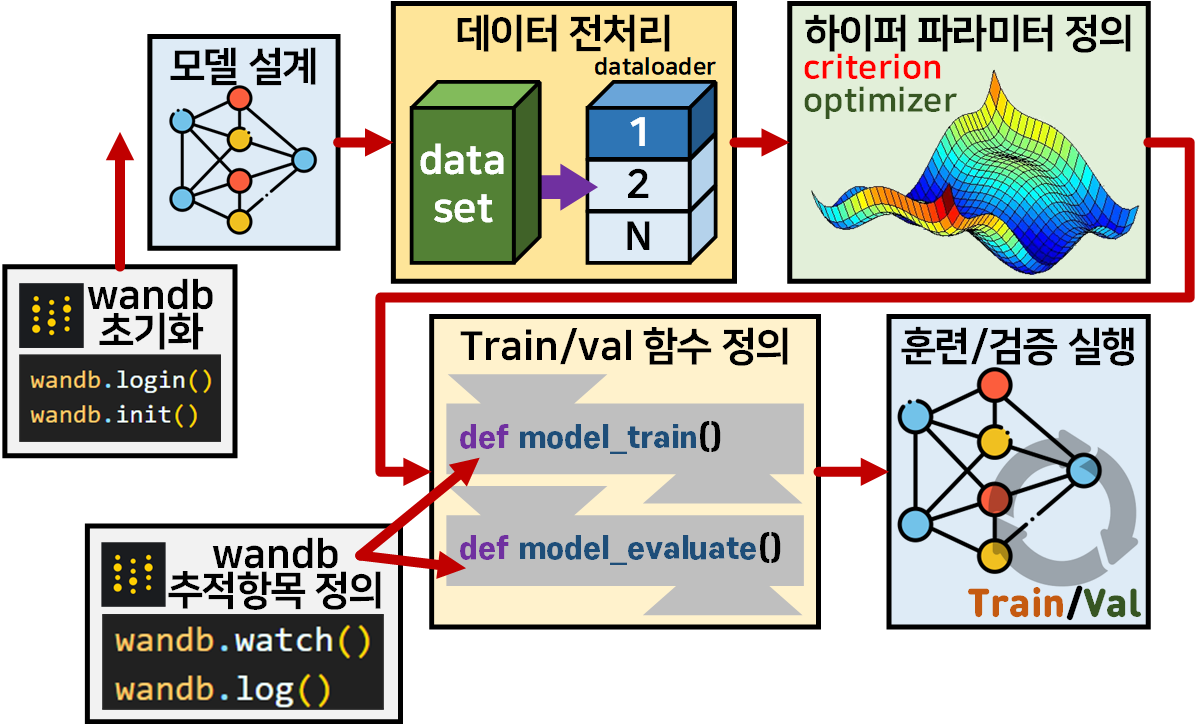
총 4개의 메서드
wandb.login(), wandb.init()
wandb.watch(), wandb.log()를
wandb 초기화, wandb 추적항목 정의 파트로 묶어서 각각
모델 설계 전, Train/val 함수 정의
파트에 각각 코드를 삽입하면 된다.
4. ResNeXt_wandb.ipynb
이제 wandb기능을 추가하여 ResNext_Train_val.ipynb를 다시 수행해보자
import torch
import torch.nn as nn
# ResNeXt모델 설계 모듈
from resnext import ResNeXt_model, model_debug1) wandb 초기화
import wandb #wandb 라이브러리wandb.login()wandb.init(
project="ResNext프로젝트", name="관측자",
config = { #config 항목 정의
"num_class" : 10,
"data_path" : './data',
"batch_size": 128,
"learning_rate" : 1e-4,
"epochs" : 15,
"dataset" : "CIFAR10",
"architecture" : "ResNeXt",
"epoch_step" : 3 }
)wandb.login() 함수는 충분히 설명한 듯 하니
wandb.init()의 코드에 대해 설명하겠다.
https://docs.wandb.ai/ref/python/init
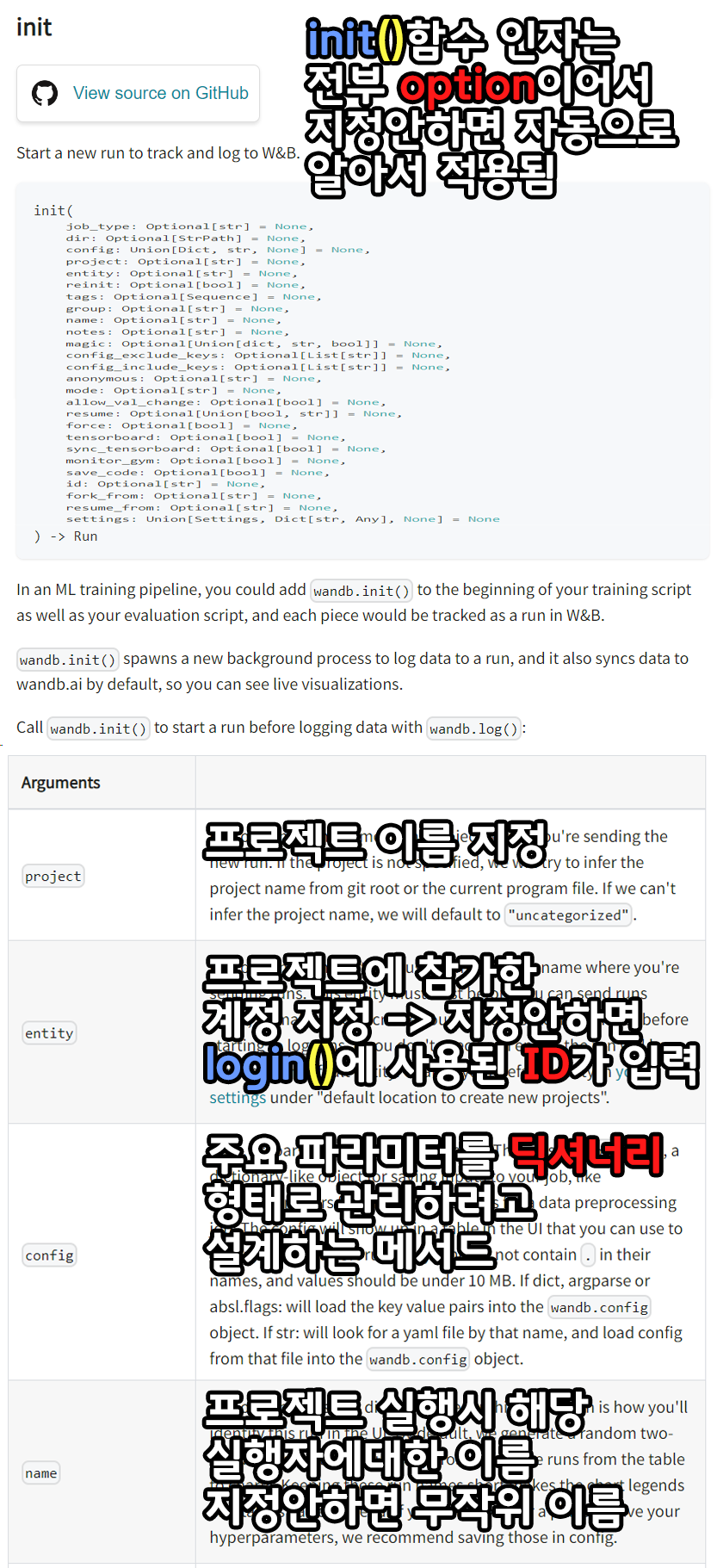
.init()에는 정말 다양한 인자값을 넣어서 초기화 방법에 대해 지정할 수 있지만
현재 필자가 수행한 주요 메서드(알아두어야 할)는
위 4가지 project, entity, config, name 이다
이미지에 설명구문을 첨부했으니 첨부한 설명대로 초기화를 수행하면 아래와 같은 코드가 출력된다.
 음.. 그러니까
음.. 그러니까
초기화를 하면 wandb 웹 서버에 해당 프로젝트가 개설되고, 지정한 초기화 방법에 따라 해당 프로젝트 내 다양한 항목들이 조정된다.
이를 홈페이지에서 확인해보면 아래와 같다.
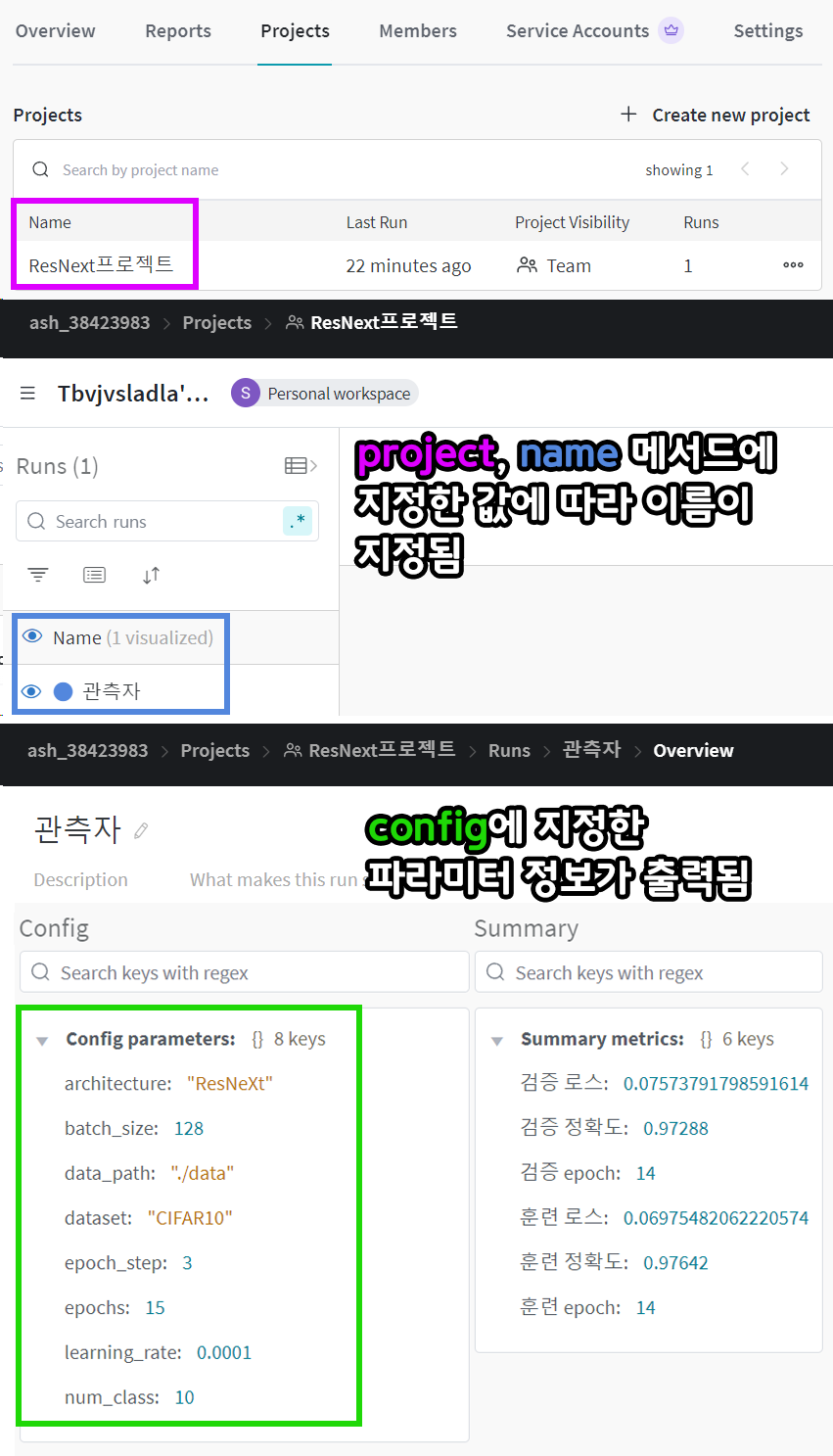
config는 모델의 설계정보, 학습/검증에 사용되는 하이퍼 파라미터, 데이터셋 경로 등 지정하고 싶은 어떤 파라미터든지 딕셔너리 형태로 집어넣으면 된다.
이 부분에 대한 설명은 https://docs.wandb.ai/guides/track/config
를 참조하기 바란다.
만약 config 항목을 코드를 수행하면서 변경이 진행된다면.update() 메서드를 통해 업데이트가 가능하다고 하는데...
이건 필자가 어떻게 쓰는지 잘 모르겟다...
(어케쓰는지 모르겟음...)
아무튼 코드 수행에 사용되는 주요 파라미터를 config에 등록했다면
이를 아래와 같이 참조를 변경하면 된다.
classes = wandb.config.num_class
root = wandb.config.data_path
BS = wandb.config.batch_size
Learning_Rate = wandb.config.learning_rate
ES = wandb.config.epoch_step
num_epoch = wandb.config.epochs이렇게 위 코드로 따로따로 관리되던 하이퍼 파라미터를 한번에 config메서드로 묶어서 관리하라는게
wandb이 제안하는 바 라고 보면 된다.
(이렇게 쓰라고..)
2) wandb 추적 항목 정의
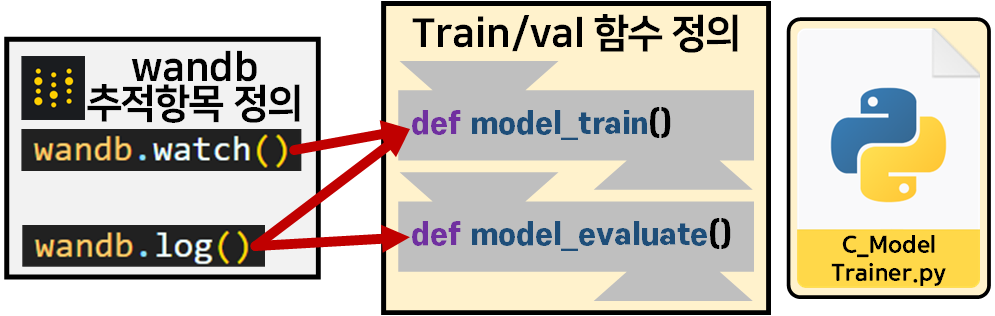 위 사진처럼
위 사진처럼
C_ModelTrainer.py로 모듈화한 Train/val 함수에
wandb.watch(), wandb.log()함수를 적절한 위치에 삽입하면 된다.
wandb.watch()는 모델의 훈련 과정에 첨부해야 하고
wandb.log()는 두 함수에 원하는 위치에 첨부하면 된다.
이때, wandb.watch(), wandb.log()는 wandb의 초기화된 정보가 필요하기에
# 사전에 모듈화 한 학습/검증용 라이브러리 import
from C_ModelTrainer import ModelTrainer
ES = wandb.config.epoch_step
# BC_mode = True : 이진분류 문제 풀이 , BC_mode = False : 다중분류 문제 풀이, aux=다중분류기 유/무
trainer = ModelTrainer(epoch_step=ES, device=device, BC_mode=False, aux=False, wandb=wandb)위 코드처럼 C_ModelTrainer.py를 업데이트하여
wandb초기화된 객체를 인자로 받을 수 있게 조정한다.
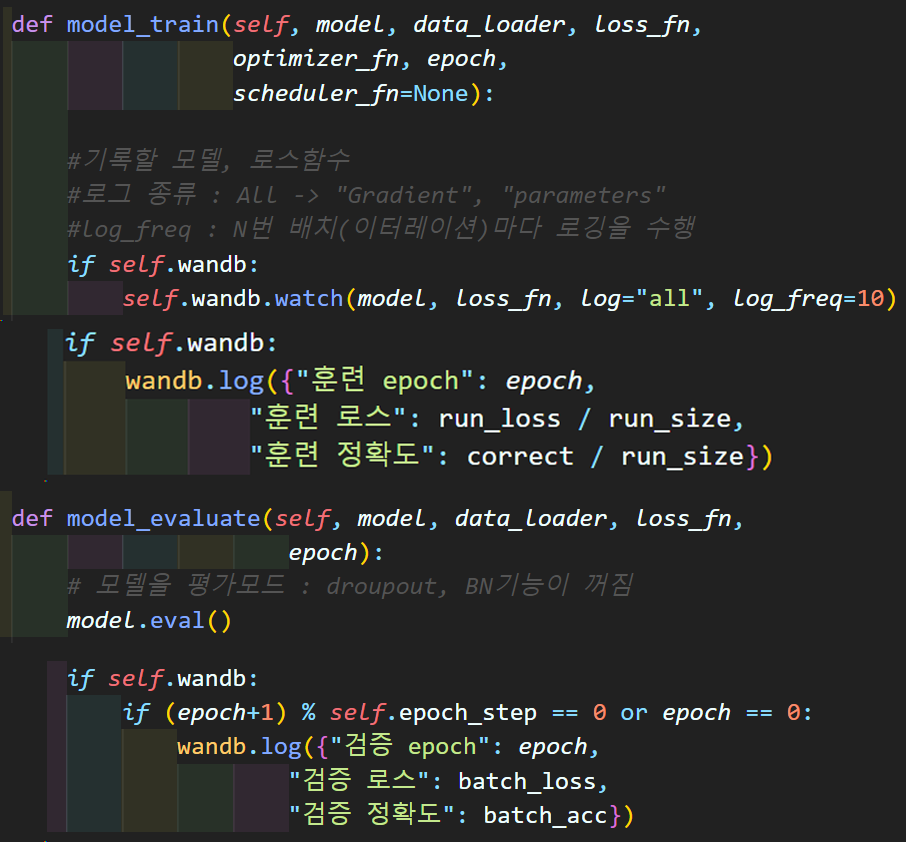 그리고 위 사진처럼
그리고 위 사진처럼
model_train(), model_evaluate() 함수에
wandb.watch(), wandb.log() 메서드를 삽입해 훈련/검증되면서 각각의 항목을 추적한다.
wandb.watch()는 추적항목에 대한 정의 인자는 아래와 같다.
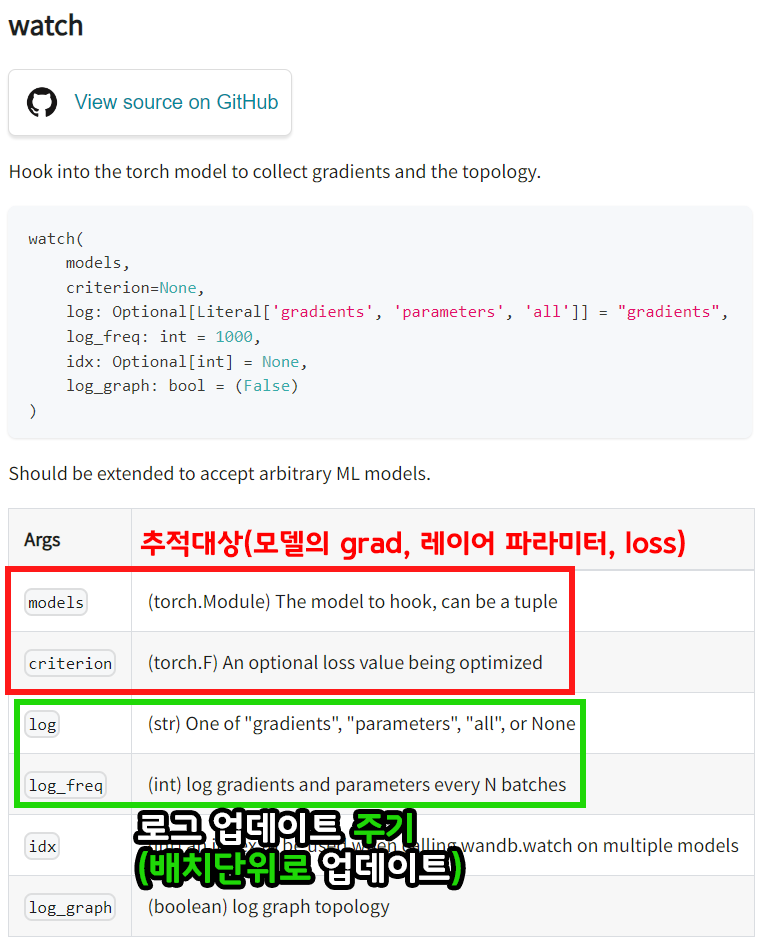
위 사진처럼 wandb.watch()의 각 인자값을 정의하면 모델이 훈련되면서 얻을 수 있는 정보를 모두 그래프화 한다.
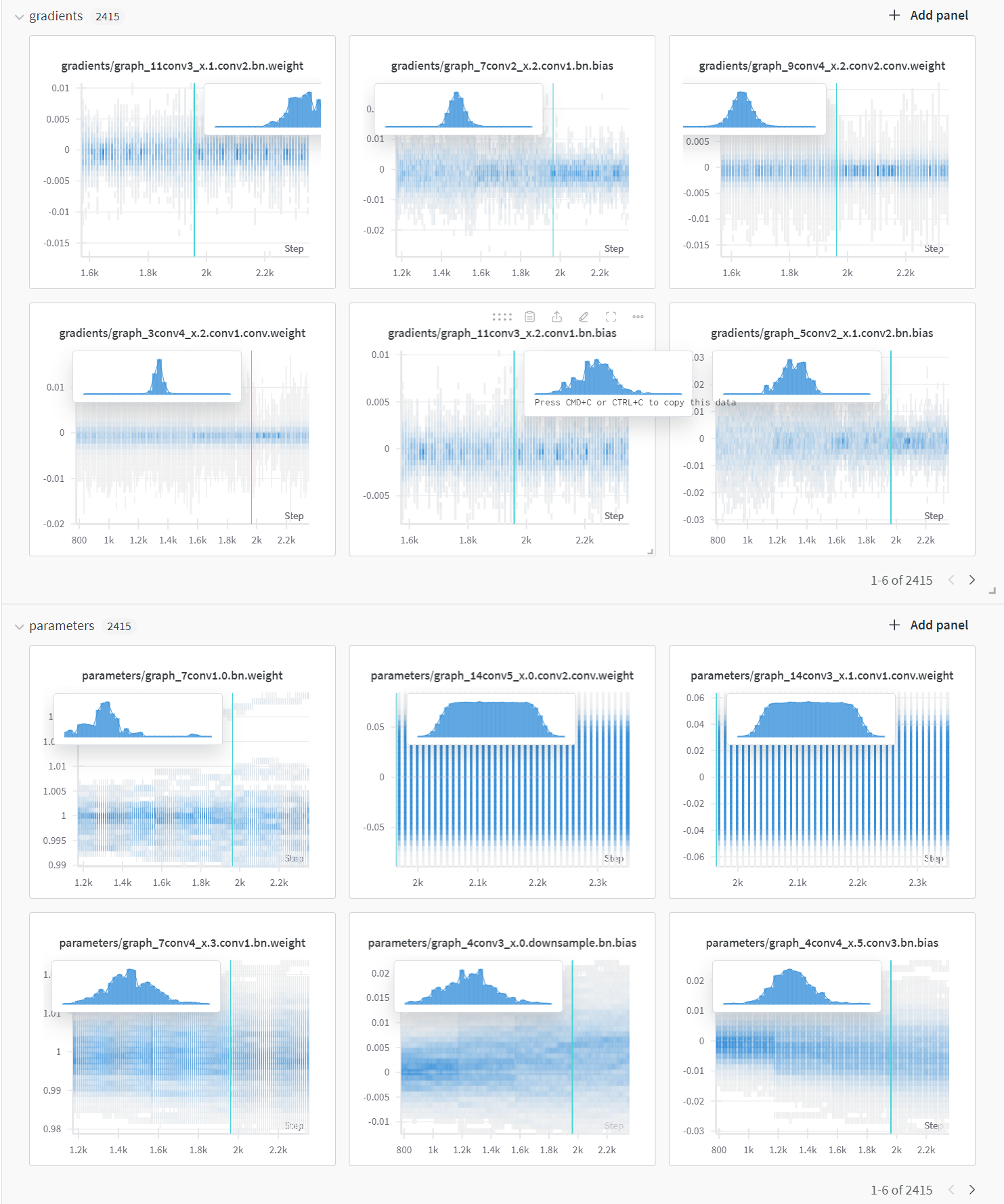 이런식으로 모델의 각 레이어
이런식으로 모델의 각 레이어 grad, parm이 어떻게 변화하는지를 로그 업데이트 주기(log_freq)에 맞춰서 기록한다.
다음으로 wandb.log()의 사용방법은 아래와 같다.
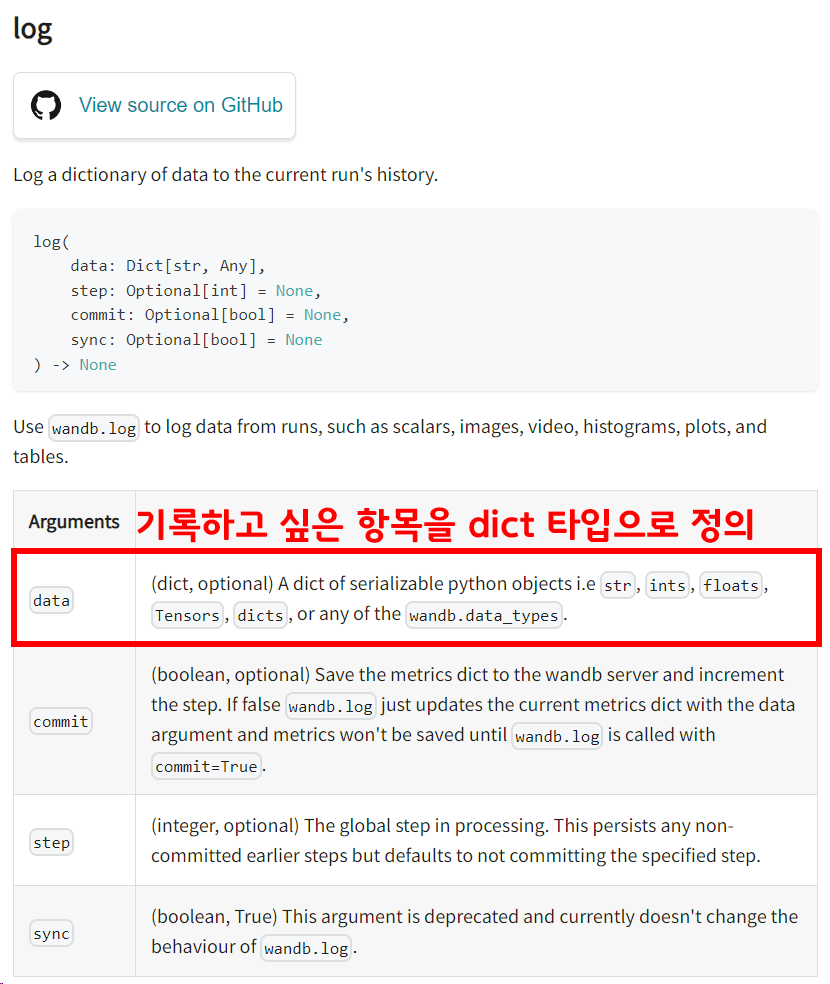 필자는 총 6가지 항목을 기록하기로 정의 했으며, 아래새진처럼
필자는 총 6가지 항목을 기록하기로 정의 했으며, 아래새진처럼 log항목에 대한 그래프를 확인할 수 있다.
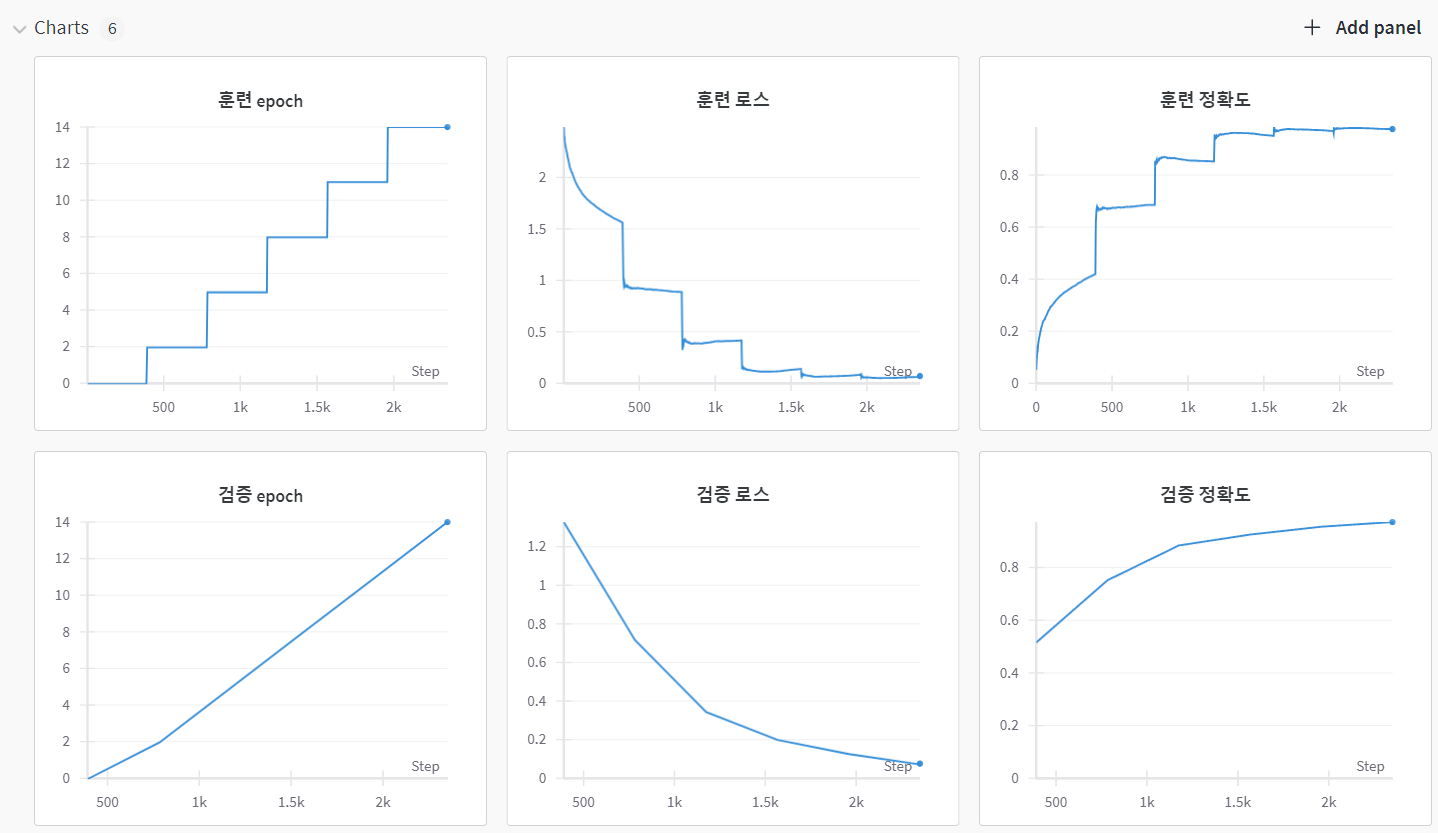
이렇게 ResNeXt_wandb.ipynb코드 실습을 통하여 wandb기능을 추가할 수 있었다.
wandb기능이 추가되면서 코드 실행속도가 많이 느려졌는데
wandb.watch()에서 모델의 grad, parm 정보를 모두 업데이트 하고 업데이트 주기도 굉장히 빠르게 업데이트 하기에 데이터 전송에 소요되는 시간으로 인한 것이라 생각한다.
따라서 업데이트 주기를 조정하거나 아니면 필수 레이어만 특정하는 식으로 필터링할 필요성이 있다.
두번째로 wandb.log()가 코드를 작성하면서 오류가 있음을 확인할 수 있을 것이다.
wandb.log()는 wandb.watch()대비 정말 중요한 항목만 지정해서 로그하도록 설계하는 것이 일반적이기에 로그 주기는 문제가 생기지 않는 위치에서 로그하는것이 권장된다.
아무튼 wandb와 같이 모델이 학습되면서 기록하고 싶은 내용을 관리해주는 웹 서비스 플랫폼이 여러개 존재하며, 그 중 하나에 대해 실습해 보았다.

츄라이 츄라이
