
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. iris 품종 구분하기

이번에는 iris의 데이터를 활용하여 세부 품종을 구분하는 방법에 딥러닝을 적용해 보도록 하겠다.
과정은
데이터 분석 -> 데이터 전처리 -> 딥러닝 모델 설계 -> 모델 훈련 -> 모델 성능평가 -> 모델 저장 및 검증으로 진행된다.
2. 데이터 분석
우선 예제 데이터를 불러와서 컬럼명 조정, 종속변수에 해당하는 값의 범주형 데이터 전환 등을 수행한다.
import pandas as pd
from sklearn.datasets import load_iris
# scikit-learn의 샘플 데이터 로드를 위해 importiris = load_iris()
# 데이터프레임 생성
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df.columns = df.columns.str.replace(' \(cm\)', '', regex=True)
df['Species'] = pd.Series(iris.target).map({0: 'setosa', 1: 'versicolor', 2: 'virginica'})
df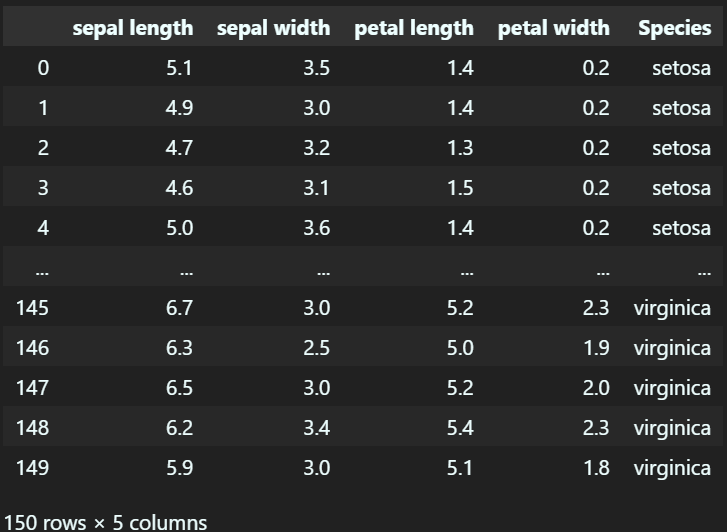
sklearn 라이브러리에서 제공하는 iris 예제 데이터셋을 불러온 뒤, 데이터를 가독성 좋게 조정을 하면 위와 같이 데이터가 정리된 것을 확인 할 수 있다.
다음으로 데이터를 섞어 준 뒤, 데이터를 알아보기 쉽게 요약정보를 출력하는 코드를 작성한다.
df = df.sample(frac=1) #데이터 뒤섞기
df.info() #데이터의 간단 정보 출력
df.describe() #데이터의 요약정보 출력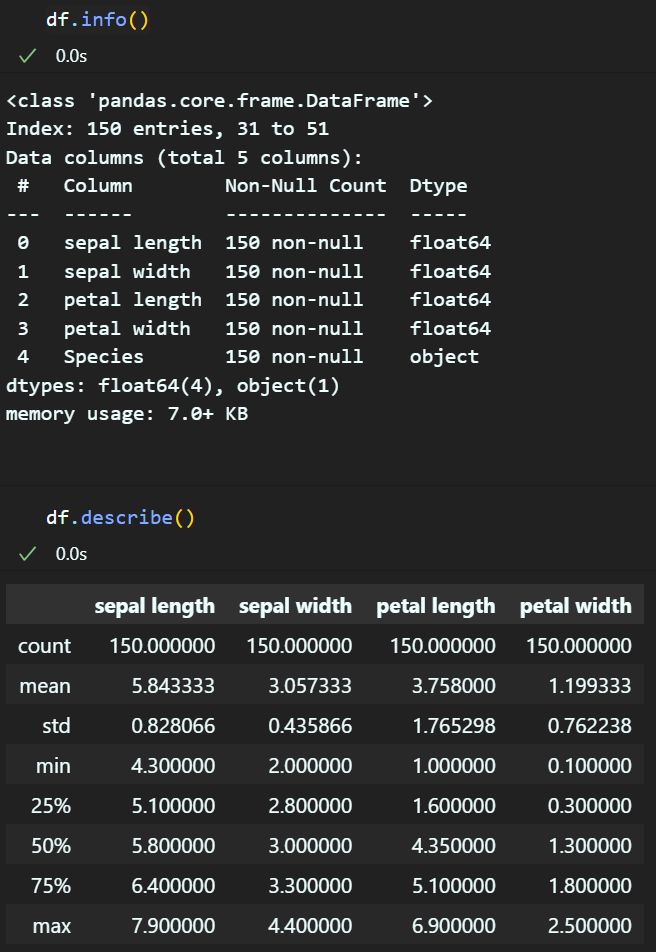
그리고 해당 데이터에 대한 캔들 그래프도 그려본다.
import matplotlib.pyplot as plt
# Boxplot 그리기
plt.figure(figsize=(14, 6))
df.boxplot()
plt.title('title')
plt.xlabel('Attributes') #속성은, 꽃받침, 꽃입의 길이 및 너비가 주요 항목이다.
plt.ylabel('Values')
plt.grid(True)
plt.show()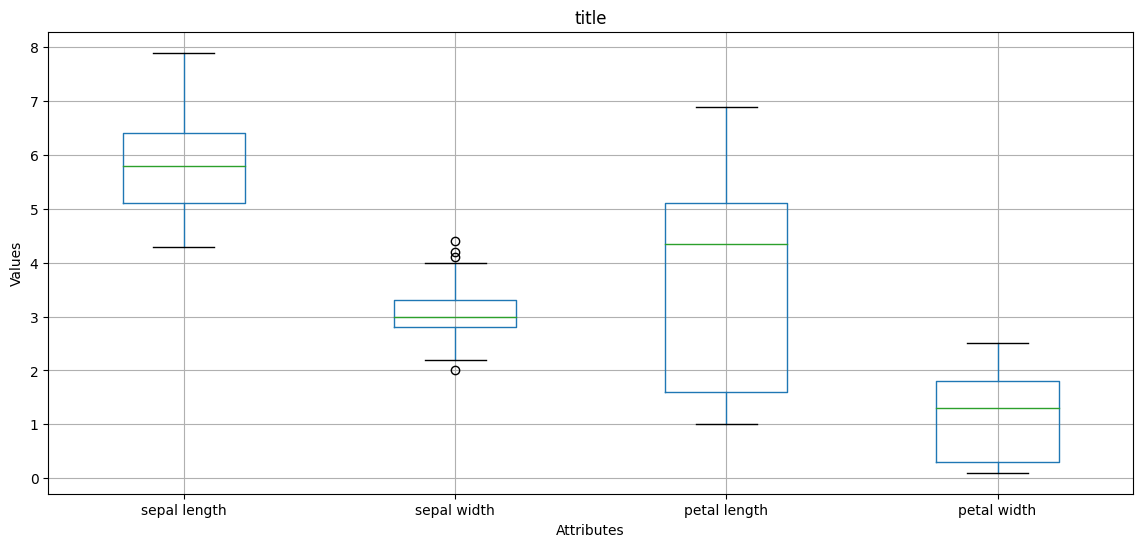
이렇게 불러온 데이터에 대한 다양한 방식의 분석을 먼저 수행해서 현재 데이터가 어떻게 구성되어 있는지 알아둘 필요가 있다.
3. 데이터 전처리
딥러닝 모델에 학습시키기 전 항시 수행해야 하는 데이터 전처리 과정에서는
데이터를 훈련데이터 / 평가 데이터로 나누는 과정을 수행한다.
이를 위해 먼저 앞서 확인한 데이터를 독립변수(), 종속변수()로 나눠준다
x = df.iloc[:, 0:4]
y = df.iloc[:, 4]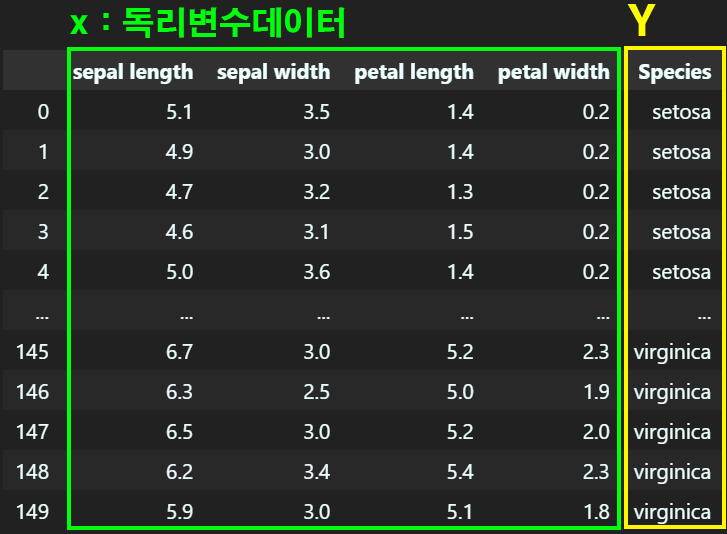 첫번째로 위 그림처럼 데이터를 X, Y로 나눠준 뒤
첫번째로 위 그림처럼 데이터를 X, Y로 나눠준 뒤
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y)train_concat = pd.concat([x_train, y_train], axis=1)
test_concat = pd.concat([x_test, y_test], axis=1)
print(train_concat.head(), len(train_concat))
print("*****************")
print(test_concat.head(), len(test_concat))위 train_test_split 메서드를 통하여
훈련 데이터, 평가 데이터를 다시 한번 나눠준다.
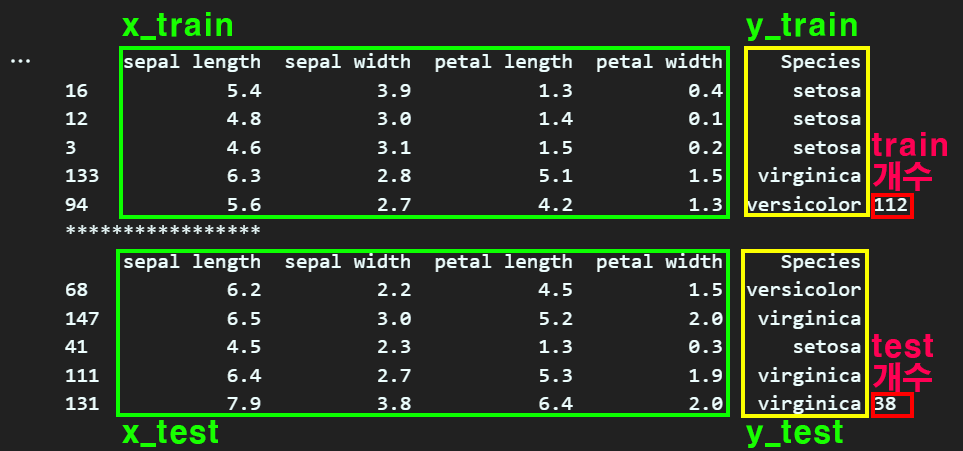
이렇게 train_test_split 메서드를 사용하면 x_train, x_test, y_train, y_test 이 생성되며, train데이터셋과 test데이터셋의 비율도 결정된다.
다음으로 y데이터셋은 범주형 데이터에 속하기에 이를 One Hot encdoing과정을 통하여 숫자형 데이터로 치환해줘야 한다.
from sklearn.preprocessing import LabelEncoder
#-----범주형 데이터 확인 과정---------#
unique_species = y_train.unique()
unique_species = sorted(unique_species.tolist())
print(unique_species, type(unique_species))
#-----범주형 데이터 확인 과정---------#
e = LabelEncoder() # LabelEncoder 객체를 생성한다.
e.fit(y_train)
y_train = e.transform(y_train)
print(f"y_train: {y_train}, y_type : {type(y_train)}")뭔가 복잡해 보이지만 핵심은
LabelEncoder에서 제공하는 라이브러리에서
OneHotEncoding을 수행하게 해주는 클래스인
LabelEncoder()을 하나 인스턴스화 한 뒤
e = LabelEncoder()
범주형 데이터의 Unique한 데이터만 추출하는 .fit 과정을 수행하여
y_train = e.transform(y_train)
라는 코드로 현재 범주형 데이터인 y_train을
숫자형 데이터로 변환해준다.
그림으로 이해하자면 아래와 같다.
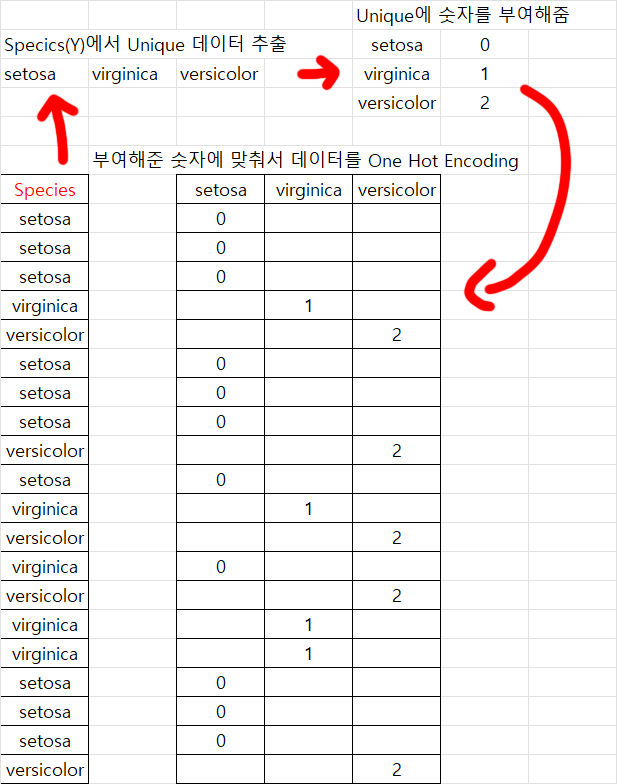
여기까지 수행했으면
이제 두번째 전처리인 '딥러닝 모델에 입력 가능한 Tensor 자료형으로 데이터 변환'을 수행한다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim# numpy 배열을 PyTorch 텐서로 변환
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
# 고유한 클래스의 수를 계산 (3이 나온다)
num_classes = torch.unique(y_train_tensor).size(0)
# one-hot 인코딩
y_train_one_hot = F.one_hot(y_train_tensor, num_classes=num_classes)
#y_test데이터도 One-hot 인코딩
y_test = e.transform(y_test)
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
y_test_one_hot = F.one_hot(y_test_tensor, num_classes=num_classes)여기까지 수행한다면
'볌주형 데이터'에 해당하는 y_train, y_test데이터가 모두
텐서 자료형에 입력 가능한
One-Hot encoding이 완료됨을 알 수 있다.
그리고 추가로 train데이터 군 들도 Tensor 자료형으로 변환해준다
# 훈련 데이터 Tensor 자료형으로 전처리
x_train_tensor = torch.tensor(x_train.values, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.long)4. 모델 설계
이제 딥러닝 다중분류를 위한 모델을 설계한다.
# PyTorch 모델 정의
class SimpleNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.softmax(self.fc2(x), dim=1)
return x
#모델 인스턴스 생성
input_dim = x_train.shape[1] # 입력 차원: 특성의 수
output_dim = num_classes # 출력 차원: 클래스의 수
hidden_dim = 16 #이거는 작업자 마음대로임
print(input_dim, output_dim, hidden_dim)모델에 대한 설명을 하자면
독립 변수에 속하는 X의 데이터 종류(컬럼 종류)가
4개 였으니 input_dim = 4가 되고
딥러닝 모델의 Hidden layer은 노드가 16개
출력 노드는 종속변수 Y의 OneHotEncoding 결과가
[0, 1, 2] 3개만 나오니 output_dim = 3이 되게 하는 모델을 설계했다.
그 사이에 Activation Function으로는 ReLu와
최종 출력 데이터에 대한 활성화 함수는 softmax를 적용했다.
이제 모델을 GPU로 옮기고
Loss Function, Optimizer
GPU에 넣을 Batch_size
학습 횟수(epoch)를 각각 설정한다.
# GPU 장치 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 모델 인스턴스 생성
model = SimpleNN(input_dim, hidden_dim, output_dim).to(device)
# 손실 함수 및 옵티마이저 정의 (TensorFlow와 동일하게 설정)
criterion = nn.CrossEntropyLoss()
optimizer = optim.RMSprop(model.parameters(), lr=0.001)
# 배치 학습 설정
batch_size = 1
num_epochs = 50손실함수(Loss Function)은 CrossEntropyLoss를 사용했고
최적화 방법론(Optimizer)은 RMSprop를 사용했다.
5. 모델 훈련
위 과정까지 수행했으면
모델을 Train, 훈련을 시킨다.
# 훈련 루프
for epoch in range(num_epochs):
model.train()
#데이터 인덱스를 랜덤하게 섞음
permutation = torch.randperm(x_train_tensor.size()[0])
#x_train_tensor.size()[0] -> 이거는 차원의 크기(샘플 수)반환
#torch.randperm(n) -> 이거는 0~n-1까지 무작위로 섞은 순열 발생시키는거
for i in range(0, x_train_tensor.size()[0], batch_size):
optimizer.zero_grad()
indices = permutation[i:i + batch_size]
batch_x = x_train_tensor[indices].to(device)
batch_y = y_train_tensor[indices].to(device)
# 순전파
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
# 역전파 및 최적화
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')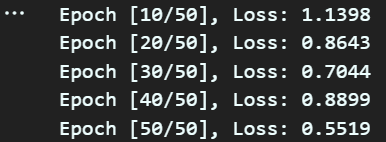
훈련이 정상적으로 되고 있다면
epoch가 증가할수록(훈련이 진행될 수록)
Loss값이 0에 수렴하는 식으로 내려갈 것이다.
6. 모델 평가
모델을 평가하는 구문이다. 다시말해서
모델에 종속변수인 Y데이터를 입력했을 때
출력되는 최종 정확도(딥러닝 모델이 얼마나 잘 맞추는지)를 평가한다.
# 테스트 데이터 준비 및 GPU로 이동
x_test_tensor = torch.tensor(x_test.values, dtype=torch.float32).to(device)
y_test_tensor = torch.tensor(y_test, dtype=torch.long).to(device)
model.eval()
with torch.no_grad():
test_outputs = model(x_test_tensor)
_, predicted = torch.max(test_outputs.data, 1)
accuracy = (predicted == y_test_tensor).sum().item() / y_test_tensor.size(0)
print(f'Test Accuracy: {accuracy * 100:.2f}%')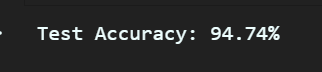
평가 결과 모델의 정확도는 94%가 나옴을 확인할 수 있다.
7. 모델 저장 및 사후 모델 사용
훈련된 모델을 '저장'하고
저장한 모델을 불러와서
새 데이터를 입력하는 어플을 만들었다
보면 된다.
import os
#모델의 저장 경로 확인하기
print("현재 작업 디렉토리:", os.getcwd())
torch.save(model.state_dict(), "iris.pth")# 모델 인스턴스 생성 및 GPU로 이동
loaded_model = SimpleNN(input_dim, hidden_dim, output_dim).to(device)
# 저장된 모델 상태를 불러오기
loaded_model.load_state_dict(torch.load("iris.pth"))
# 모델을 평가 모드로 설정
loaded_model.eval()#새 데이터 만들기
new_data = {
"Sepal.Length": [5.3],
"Sepal.Width": [3.4],
"Petal.Length": [1.4],
"Petal.Width": [0.2]
}
new_data = pd.DataFrame(new_data)#새로 만든 데이터를 GPU로 보내기
new_data_tensor = torch.tensor(new_data.values, dtype=torch.float32).to(device)
#모델을 평가모드로 바꾸고 새로 만든 데이터를 입력시켜 결과 예측
model.eval()
with torch.no_grad():
new_prediction = model(new_data_tensor)
_, new_predicted_class = torch.max(new_prediction, 1)
#출력
print("새로운 데이터 예측 확률:", new_prediction.cpu().numpy())
print("새로운 데이터 예측 결과:", new_predicted_class.item())
#출력값을 알아볼 수 있게 바꾸기
new_predict_idx = np.argmax(new_prediction.cpu().numpy())
predicted_label = e.inverse_transform([new_predict_idx])[0]
print(predicted_label)
훈련이 완료된 모델을 불러와서
임의의 새 데이터를 입력해서
이 데이터가 어떤 꽃의 아종에 속하는지 확인 후
이 아종 꽃이 'setosa'라고 알려주는
어플을 완료하였다.
