
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 데이터셋 이해하기
딥러닝의 절차는
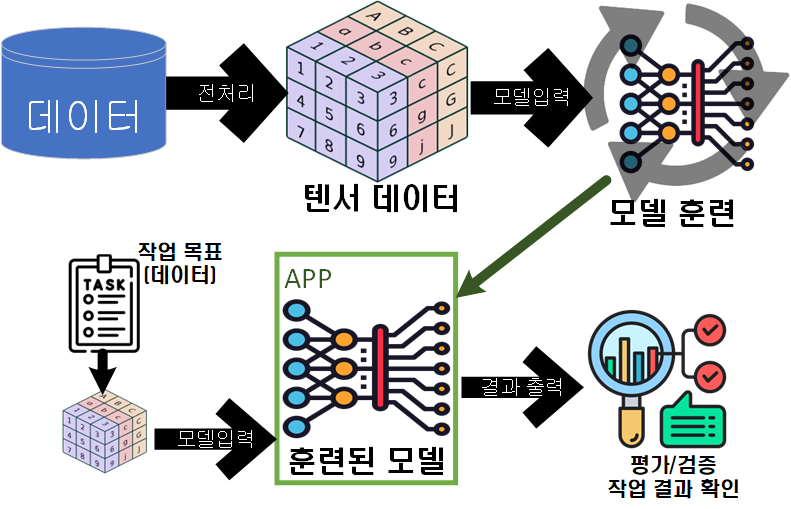 대략 이런 식으로 흘러가며, 데이터를 딥러닝 모델에 입력 가능한 형태로 전처리 하고, 그 뒤 훈련을 시킨 뒤, 훈련이 완료된 모델로 작업을 수행하는 과정이라 보면 된다.
대략 이런 식으로 흘러가며, 데이터를 딥러닝 모델에 입력 가능한 형태로 전처리 하고, 그 뒤 훈련을 시킨 뒤, 훈련이 완료된 모델로 작업을 수행하는 과정이라 보면 된다.
이 과정에서 이번에 복기할 내용은 '딥러닝에 입력 가능한 텐서 데이터'의 이해이다.
우선 강의에서 선택한 예제 데이터는 MNIST을 사용했다.
https://pytorch.org/vision/main/generated/torchvision.datasets.MNIST.html
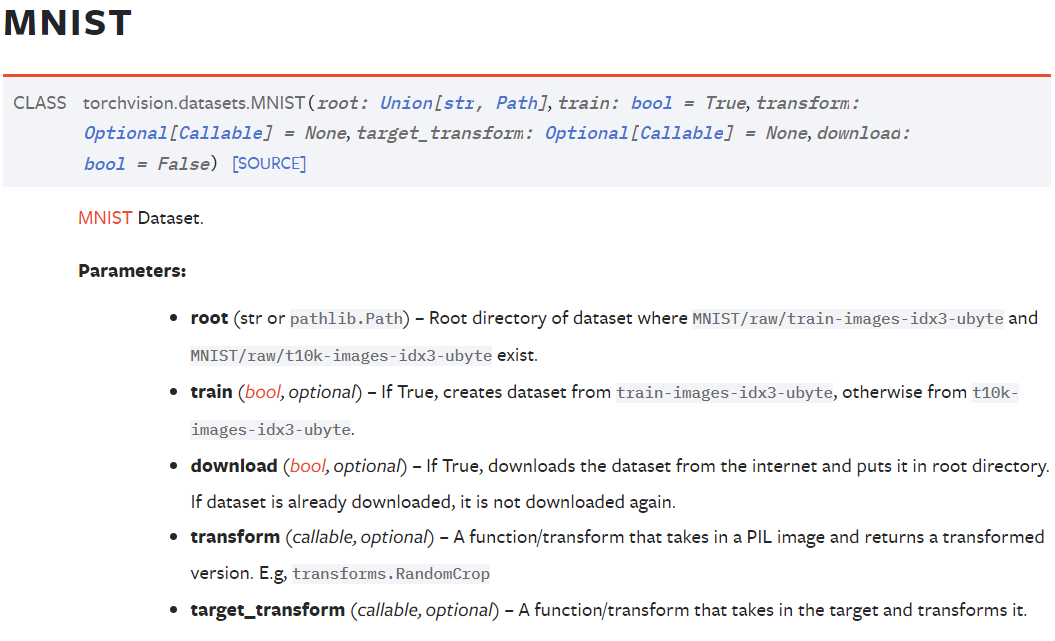 Pytorch에서는 해당 데이터셋을 torchvision라이브러리를 사용하며, 인자로는
Pytorch에서는 해당 데이터셋을 torchvision라이브러리를 사용하며, 인자로는
1) 데이터셋을 다운으면 이를 보관할 폴더 경로 root
2) 데이터셋이 훈련모드용 데이터셋인지? 아니면 평가(검증) 모드용 데이터셋인지? 설정하는 train
3) MNIST 데이터셋을 다운받았다면 추가적인 다운로드 과정을 방지하는 download
4) MNIST데이터셋은 PIL이미지 형태이니 이를 변환하는 과정(데이터 전처리)에 대한 방법인 transform
총 4가지 인자에 대한 설정을 받아야 한다.
일단 위 torchvision 라이브러리로 데이터셋을 다운받는 코드를 작성하자
import torchvision
from torchvision import datasets, transforms
train_dataset = datasets.MNIST(root='./data',
train=True, download=True,
transform=transforms.ToTensor())
test_dataset = datasets.MNIST(root='./data',
train=False, download=True,
transform=transforms.ToTensor())이 중 마지막 인자값인 transform=transforms.ToTensor()는
 뭐라 뭐라 설명이 되어 있는데
뭐라 뭐라 설명이 되어 있는데
이것은 데이터셋 이미지를 Pytorch Tensor자료형으로 바꿔주는 가장 기본적인 데이터 전처리 메서드로
기존의 PIL이나 Numpy.array로 처리된 이미지 데이터가
[높이 x 너비 x 채널]로 되어 있는 것을
[채널 x 높이 x 너비]로 차원의 순서(축)을 변환하는 메서드라 보면 된다.
그 다음 [높이, 너비]에 속하는 이미지의 데이터 타입 및 범위가 0~255, uint8인 것을
0~1, float32으로 정규화를 수행한다.
코드로 본다면 np.transpose(2,0,1), (tensor_array/255.0).astype(np.float32) 이걸 수행한거라 보면 된다.
그럼 다운로드 받은 MNIST 데이터셋의 구조를 좀 더 확인해보자
train_images = train_dataset.data
test_image = test_dataset.data
print(train_images.shape)
print(test_image.shape)위 코드를 수행하면

이같이 데이터셋이 train인 경우 6만장에 각 이미지의 [높이, 너비]는 [28,28]인 것을 확인할 수 있고
test는 동일한 이미지의 크기에 데이터 개수만 1만개이다.
하지만 여기서 더 확인해야 할 항목이 있다.
바로 Label이다.
지금 수행하는 딥러닝 과정은 지도 학습(Supervised Learning)에 해당하기에 정답지인 종속변수:y(label)이 필요하다.
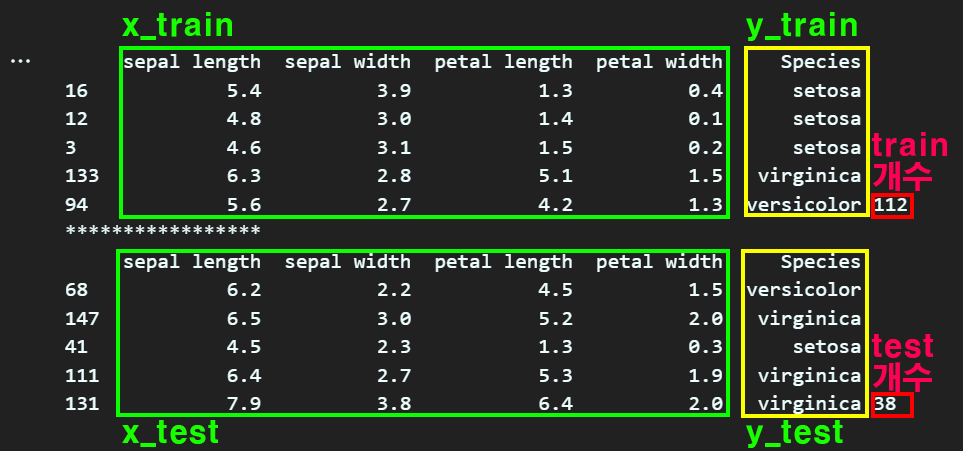
바로 위 사진처럼 x에 해당하는 값이 .data 인 것이다.
이제 라벨 정보를 출력해보자.
import numpy as np
train_labels = np.array(train_dataset.targets)
test_labels = np.array(test_dataset.targets)
print(len(np.unique(train_labels))) #10
print(len(np.unique(test_labels))) #10라벨 정보의 경우 독립변수인 X에 해당하는 train_images, test_image와 똑같은 값인 60000, 10000이 출력될 것이니
이 중 앞서 이미지에 첨부한 'setosa, virginica, versicolor'와 같이 라벨이 총 몇개로 분류되냐가 더 중요한 정보에 속하기에
이 중복항을 제거한 Unique한 정보를 출력하면 10라는 값을 얻을 수 있다.
즉 MNIST 데이터셋은 총 7만장의 데이터셋이고, 그중 6만장은 훈련용, 1만장은 테스트용으로 분류되어 있으며,
라벨은 10총의 라벨이 매겨쳐 있음을 확인할 수 있다.
1-1. DataLoader
그러면 위 불러온MNIST을 바로 딥러닝 모델에 적용가능한 데이터 전처리가 완료된 자료일까?
Pytorch에서는 여기서 한가지 작업을 더 해줘야 한다
그것이 바로 DataLoader으로
Tensor자료형으로 처리된 데이터셋을 다시
딥러닝 모델, 특히 GPU연산에 적합하도록 한번 더 처리를 해주는 작업을 해주는 메서드라 보면 된다.
import torch
#---------여기는 무시해도 됨-----------#
transformation = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset.transform = transformation
test_dataset.transform = transformation
#---------여기는 무시해도 됨-----------#
#------------여기가 중요함------------#
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
#------------여기가 중요함------------#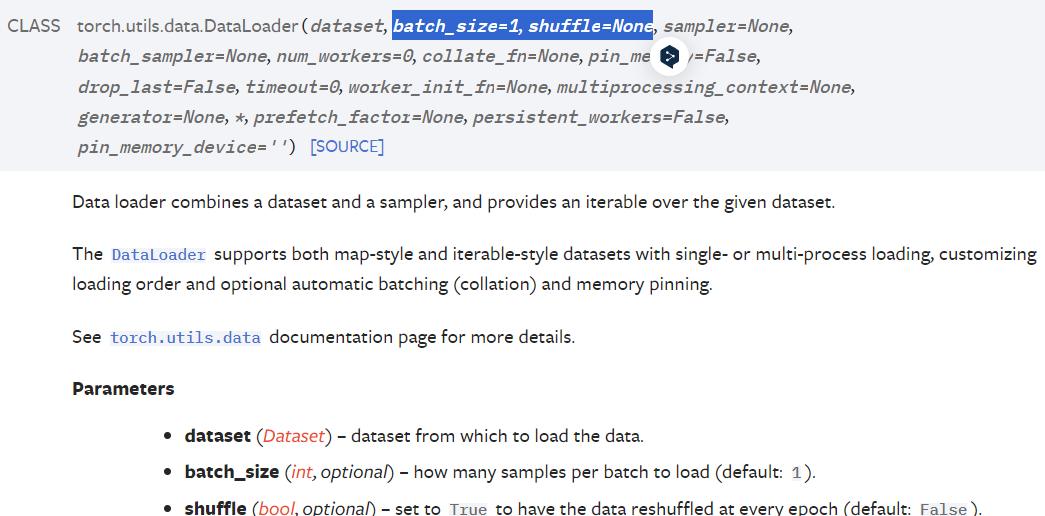 도큐먼트의 설명을 본다면
도큐먼트의 설명을 본다면
torch.utils.data.DataLoader는 데이터셋을 샘플러랑 결합하여 이터러블을 제공한다는데...
이미지로 설명하는게 편할 듯 하다.
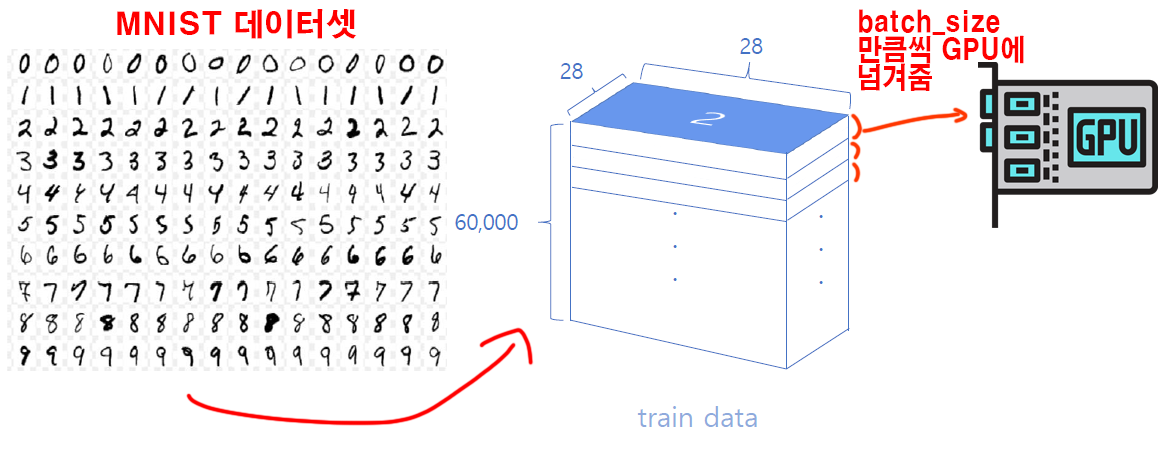
그림처럼 train_dataset이 [60000 x 28 x 28]의 차원으로 된 데이터 임은 확인을 했다.
이것을 딥러닝을 돌릴 때 데이터셋을 한번에 GPU에 넘겨주면 GPU의 메모리 한계로 인해 프로그램이 터질것이다.
그래서 GPU의 메모리 용량을 고려해서
6만장의 데이터중 일부 데이터를 떼어 내서 차례차레 GPU에 넘겨주면서 학습을 시키는데
이 떼어내는 정도가 batch_size가 된다.
고 성능의 GPU라면 메모리 용량도 넉넉할 것이고 그러면 한번에 떼어서 넘겨주는 데이터의 용량도 크게 설정할 수 있을 것이니 batch_size값을 큰 값으로 설정해도 무리가 없을 것이다.
그럼 마지막으로 GPU에 넘겨주기 직전의 데이터
즉, 전처리가 완료된 데이터셋의 구조는 어떻게 될까?
ex_images, ex_labels = next(iter(train_loader))
print(ex_images.shape)
print(ex_labels.shape)GPU에 입력 가능한 형태의 데이터 자료형인 DataLoader은 python의 이터레이터 형태의 자료형이 되기에
값을 추출하기 위하여 next(iter(이터레이터 객체))함수로 값을 추출했고, 각각의 차원을 살펴보면 아래와 같은 값이 나온다
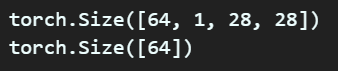
이렇게 4차원 데이터로 변환을 해줘야 GPU를 통해서 딥러닝 학습, 평가, 검증이 가능해진
데이터셋의 형태가 된다...
라고 이해하면 될 듯 하다.
이걸 모델링 하면 꼭 이렇게 4개의 파라미터를 붙여서 표현한다.
2. 딥러닝 모델과 텐서 차원변환
데이터셋을 딥러닝 모델에 입력 가능한 형태로 전처리를 하면서, 그 과정에서 발생하는 텐서 자료형의 차원에 대한 이해를 수행했으니
이제 딥러닝 모델에 입력되면서 텐서 자료형이 어떻게 변화되는지 알아보도록 하자
우선 가장 간단한 FCL(Fully Connected Layer)기반의 모델을 먼저 설계한다.
#모델 설계하기
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class SimpleNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = x.view(x.size(0), -1) # Flatten the input tensor
#레이어에 입력하려면 Linear은 선형 함수이니 2차원 어레이로 만들어줘야함
#그리고 2차원 어레이의 첫번째 axis는 batch_size랑 같은 값을 가져야함
x = F.relu(self.fc1(x))
x = F.softmax(self.fc2(x), dim=1) #이진분류는 sigmoid를 쓴다.
return x2개의 FCL이 엮인 가장 간단한 모델이고
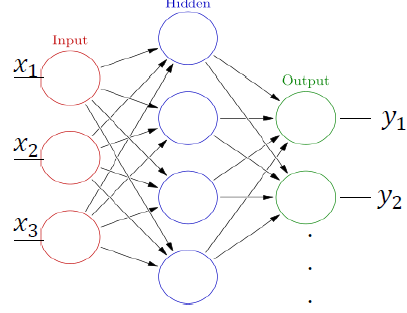 그림으로 표현하면 위 사진과 같다.
그림으로 표현하면 위 사진과 같다.
여기서 input_dim과 output_dim을 잘 정의를 해줘야 한다.
일단 output_dim은 입력하는 데이터셋의 종속변수(y, labels)과 같은 값을 가져야 한다.
이건.. 뭐 당연하다 보면 된다.
내가 판별하고자 하는 목적이 곧 종속변수이고,
MNIST데이터셋은 입력 데이터인 손글씨가 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 총 10개에 해당하는 숫자 중 어느 것을 의미하는지?
를 확인하는 딥러닝 문제풀이를 하는 것이니 말이다.
그러면 input_dim은 얼마를 넣어야 할까?
이는 FCL의 구조가 1차원 Node의 연속이니
아까의 수식 에서 $
채널, 높이, 너비의 곱한 값을 넣어주면 된다.
이걸.. 그림으로 표현하자면...
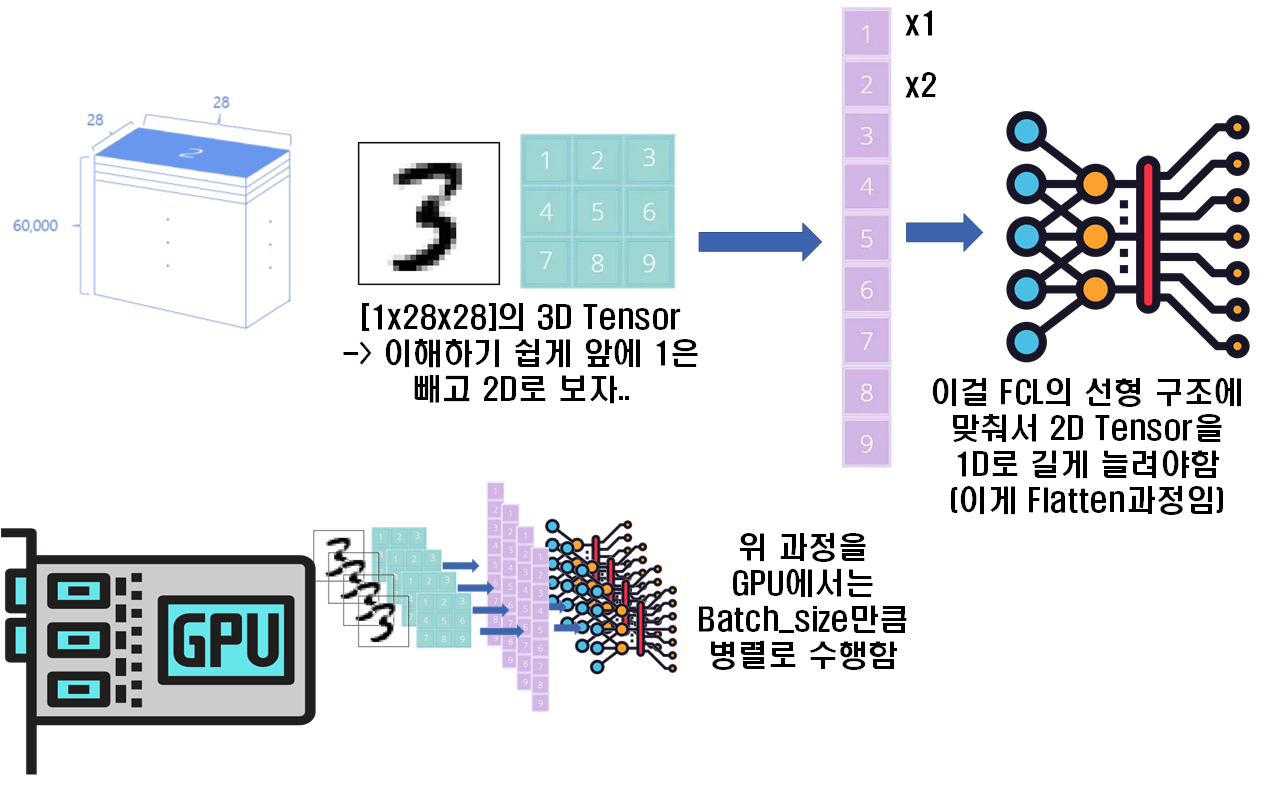 위 사진처럼
위 사진처럼
전체 데이터셋에서 batch_size만큼 떼어내서 딥러닝 모델에 입력가능한 DataLoader이 있다면 여기서 한장의 이미지는 FCL에 입력 가능하게 끔 3D Tensor를 1D Tensor로 차원변환(Flatten) 해주고 모델에 입력하는데, 이걸 Batch_size만큼 병렬로 수행한다... 라고 보면 된다.
따라서 input_dim은 인 784로 정의하면 된다.
# GPU 장치 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
from torchsummary import summary
# 모델 인스턴스 생성
model = SimpleNN(784, 256, 10).to(device)
summary(model, input_size=(1, 28, 28), device='cuda')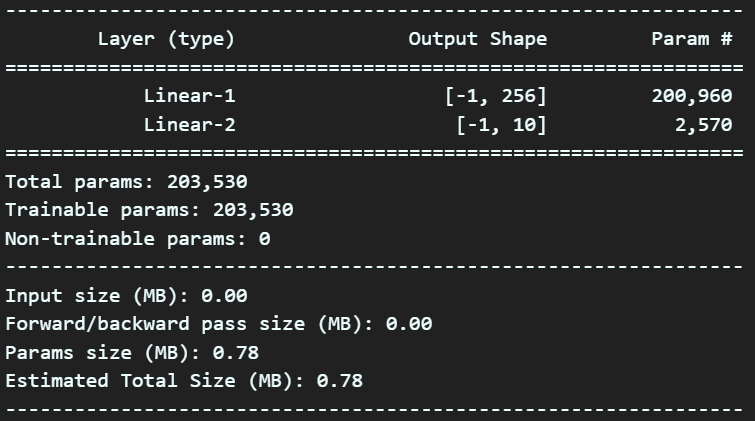 따라서 모델에 대한 FCL의 노드 개수를 설정해주고 이 모델에 대한 검토를 위 코드처럼 수행하면 된다.
따라서 모델에 대한 FCL의 노드 개수를 설정해주고 이 모델에 대한 검토를 위 코드처럼 수행하면 된다.
criterion = nn.CrossEntropyLoss()
optimizer = optim.RMSprop(model.parameters(), lr=0.001)다음으로 모델의 손실함수, 손실에 대한 최적화 방법론(옵티마이저)를 설계하고
(손실함수 계산이나, 옵티마이저의 최적화 방법에 대한 설명은 넘어가도록 한다..)
그냥 간단하게
입력이미지 -> 모델입력 -> 출력결과(예측물)
입력이미지의 정답 과 출력 결과 비교 => 손실함수
손실함수를 0에 가깝게 만드는 방법(0에 가까워진다 == 출력결과와 입력이미지의 정답이 같은 값이 된다) -> 이게 최적화 방법론(옵티마이저)
이케 이해하고 넘어가자
3. 훈련, 평가, 실행
여기까지 수행했으면 한번 모델을 훈련하고 평가하는 함수를 작성하고 딥러닝을 돌려보자
def train(model, device, train_loader, optimizer, criterion, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}'
f' ({100. * batch_idx / len(train_loader):.0f}%)]\n'
f'Loss: {loss.item():.6f}')def test(model, device, test_loader, criterion):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item() # Sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # Get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)}'
f' ({100. * correct / len(test_loader.dataset):.0f}%)\n')# 훈련 및 검증 루프 실행
num_epochs = 10
for epoch in range(1, num_epochs + 1):
train(model, device, train_loader, optimizer, criterion, epoch)
test(model, device, test_loader, criterion)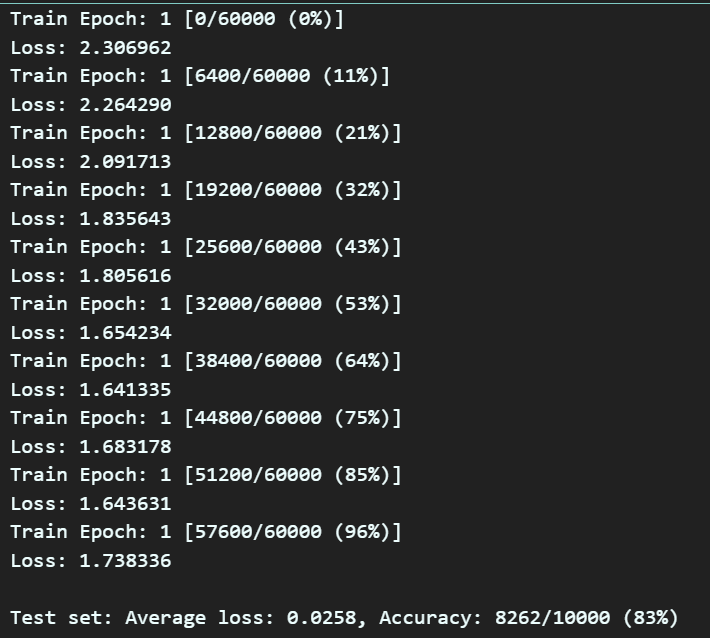
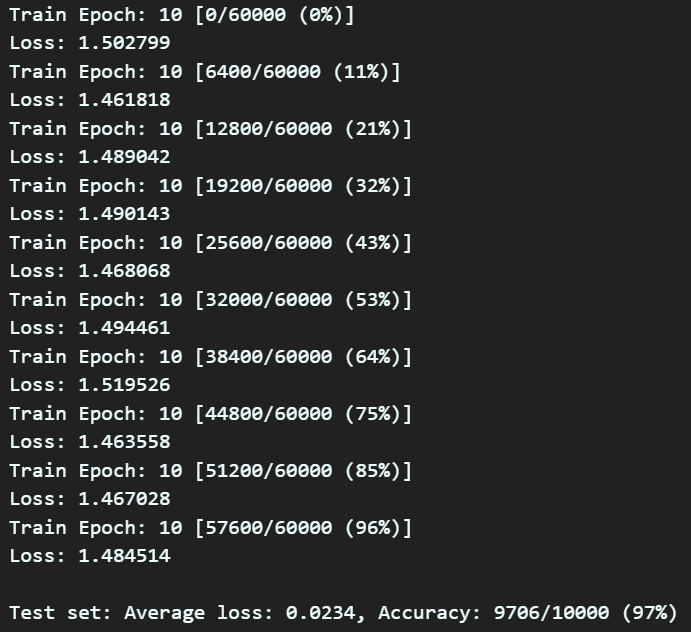
훈련의 epoch가 진행될 수록 Accuracy는 증가하고 Loss는 0에 수렴하는 것을 확인했으면
모델이 잘 훈련되고 있다.. 이렇게 알아두면 된다.
이번 강의의 목적은 Tensor자료형이 딥러닝 모델에 입력되기 전 전처리, 그리고 모델에 입력되고 움직이는 양상에 대한 정리이니 여기까지만 포스팅을 진행하겠다.
