
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. 설계 개요
Yolo v3의 설계 이론을 이전포스트 인공지능 고급(시각) 강의 예습 - 22. (1) Yolo v3 과 v2, v1 비교분석에서 충분히 다뤘고, 이제 코드화 작업을 하려 했는데
이게 의외로 어려운 부분이 많았다. 이것에 대한 이유는
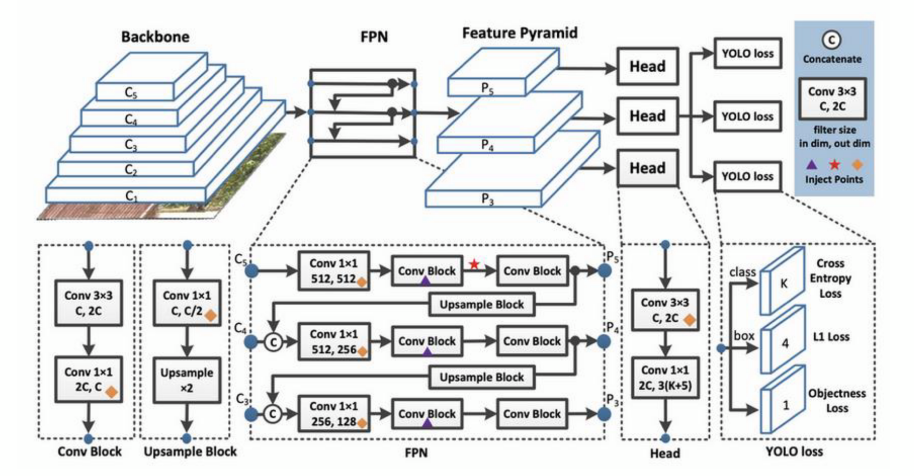
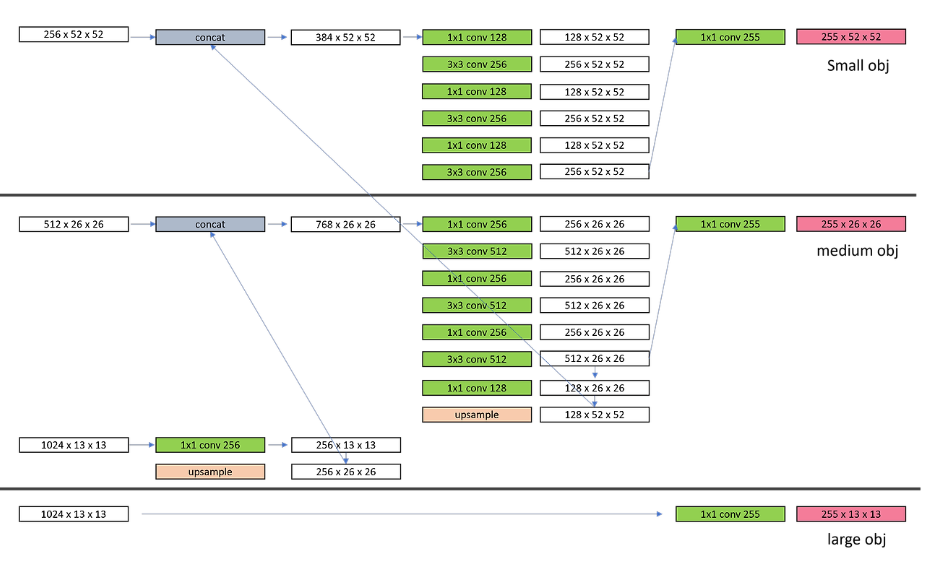
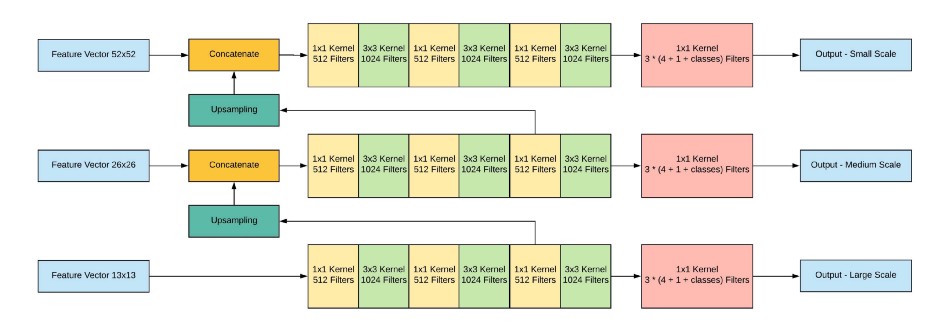
이런식으로 Yolo v3을 코드화 하는데 핵심이라 볼 수 있는 FPN(Feature Pyramid Network)의 구조를 잘 설명된 것을 찾기가 힘들었다.
솔직히 이거 구현하고 차원 오류난거 수정하는데 정말 많은 시간이 잡아먹혔다.
그리고 nn.ModuleList, nn.functional.interpolate, nn.Upsample, nn.ConvTranspose2d와 같이
여러 레이어를 병렬로 구성하는 방법론
Upsample을 수행하는 레이어
에 대한 사전지식 또한 필요하여 공부하는데 시간이 더 걸렸고
Pytornic하게 코드를 구성하다 보니
zip이랑 List Comprehension도 자주쓰게 되면서

코드가 참 사람 힘들게 만들었다
zip이랑 List Comprehension는 봐도봐도 이해가 안되니
반복시청으로 내재화를 하도록 하자.
아무튼 이번 포스트에서는 완성한 Yolo v3코드까지만 첨부하고
다음 포스트에서는 설계한 Yolo v3의 Pre-trained model 변환 및 2개 이상의 *.py 파일 작성으로 모듈화 작업을 수행하려 한다.
2. Darknet 53
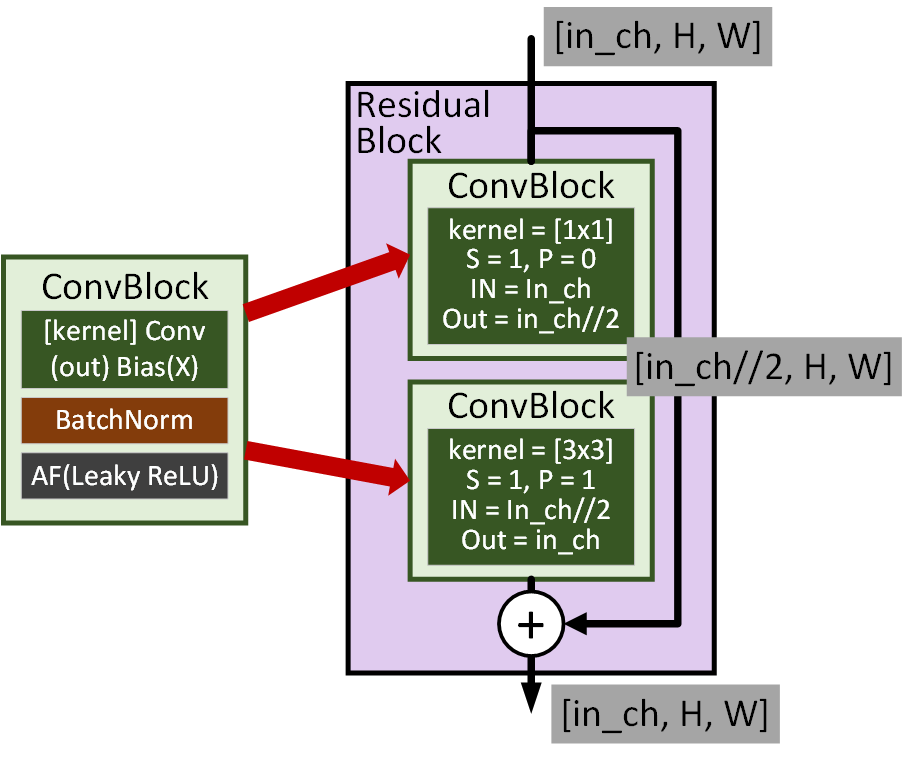
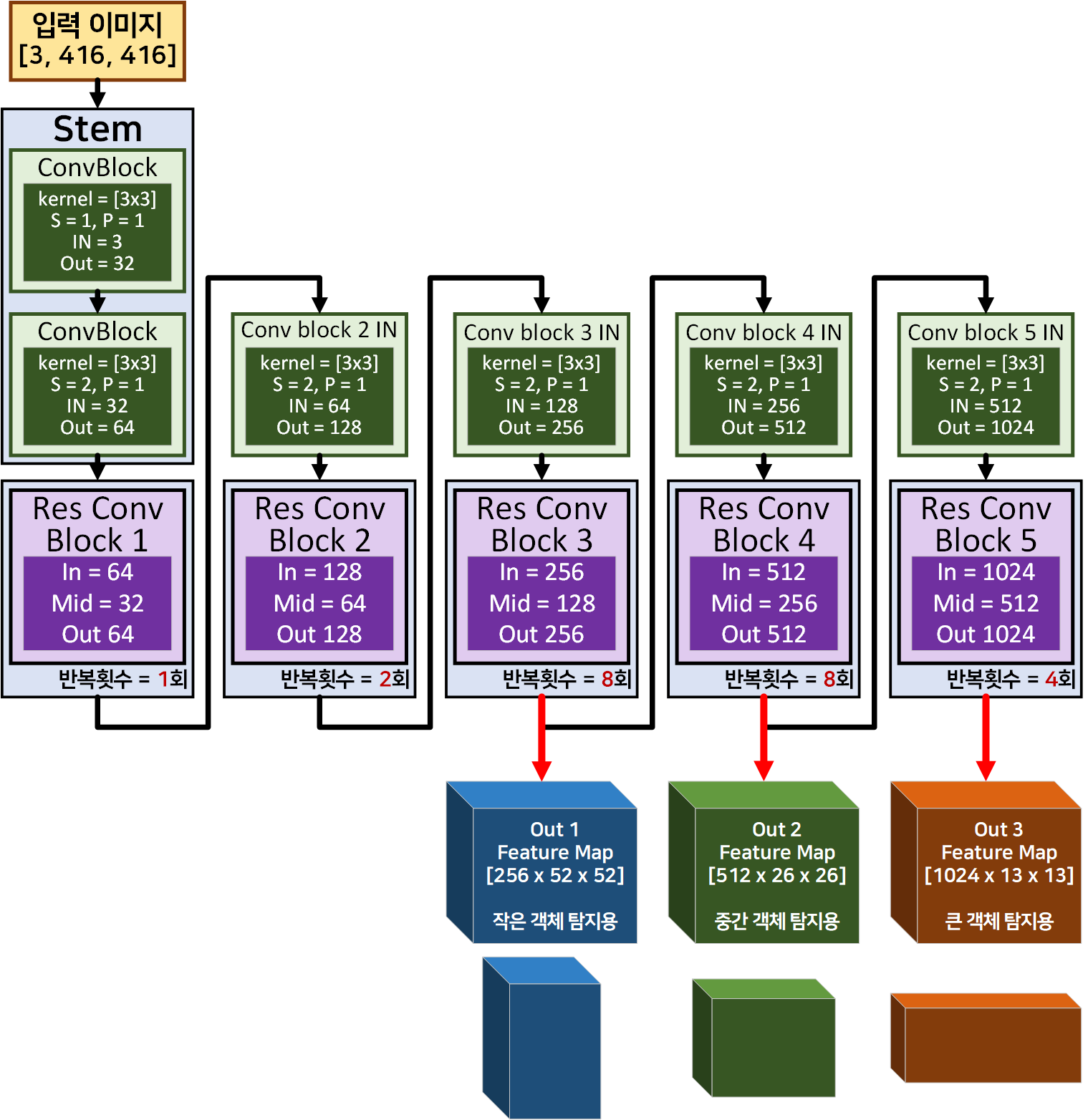
이 두 이미지에 해당하는 것을 코드로 구현하면 된다.
사실 이부분은 그렇게 크게 어려운 부분이 하나도 없다.
import torch
import torch.nn as nnclass BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
#conv2의 default stride=1, padding=0임을 잊지말자
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.LeakyReLU(0.1, inplace=False)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return xclass Residual_block(nn.Module):
def __init__(self, in_channels, **kwargs):
super(Residual_block, self).__init__()
self.conv1 = BasicConv2d(in_channels, in_channels // 2, kernel_size=1)
self.conv2 = BasicConv2d(in_channels // 2, in_channels, kernel_size=3, padding=1)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.conv2(out)
out += identity
return outclass Darknet53(nn.Module):
def __init__(self, in_channels=3, num_classes=1000):
super(Darknet53, self).__init__()
self.stem = nn.Sequential(
BasicConv2d(in_channels, 32, kernel_size=3, stride=1, padding=1),
BasicConv2d(32, 64, kernel_size=3, stride=2, padding=1)
)
self.res_conv_1 = self._make_layer(64, 1)
self.conv_2_in = BasicConv2d(64, 128, kernel_size=3, stride=2, padding=1)
self.res_conv_2 = self._make_layer(128, 2)
self.conv_3_in = BasicConv2d(128, 256, kernel_size=3, stride=2, padding=1)
self.res_conv_3 = self._make_layer(256, 8)
self.conv_4_in = BasicConv2d(256, 512, kernel_size=3, stride=2, padding=1)
self.res_conv_4 = self._make_layer(512, 8)
self.conv_5_in = BasicConv2d(512, 1024, kernel_size=3, stride=2, padding=1)
self.res_conv_5 = self._make_layer(1024, 4)
self.fc = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(1024, num_classes)
)
#Res_conv_block를 반복해서 붙여넣을 때 사용되는 메서드
def _make_layer(self, in_channels, num_blocks):
layers = []
for _ in range(num_blocks):
layers.append(Residual_block(in_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.stem(x)
f1 = self.res_conv_1(x) # 1st level features
x = self.conv_2_in(f1)
f2 = self.res_conv_2(x) # 2nd level features
x = self.conv_3_in(f2)
f3 = self.res_conv_3(x) # 3rd level features
x = self.conv_4_in(f3)
f4 = self.res_conv_4(x) # 4th level features
x = self.conv_5_in(f4)
f5 = self.res_conv_5(x) # 5th level features
features = [f3, f4, f5]
return features여기서 그나마 어려울만한 코드는.. _make_layer인데 이것도 이전포스트 인공지능 고급(시각) 강의 예습 - 19. Yolo v1 (1) 모델 설계에서 설명했으니 넘어가도록 하겠다.
3. FPN(Feature Pyramid Network)
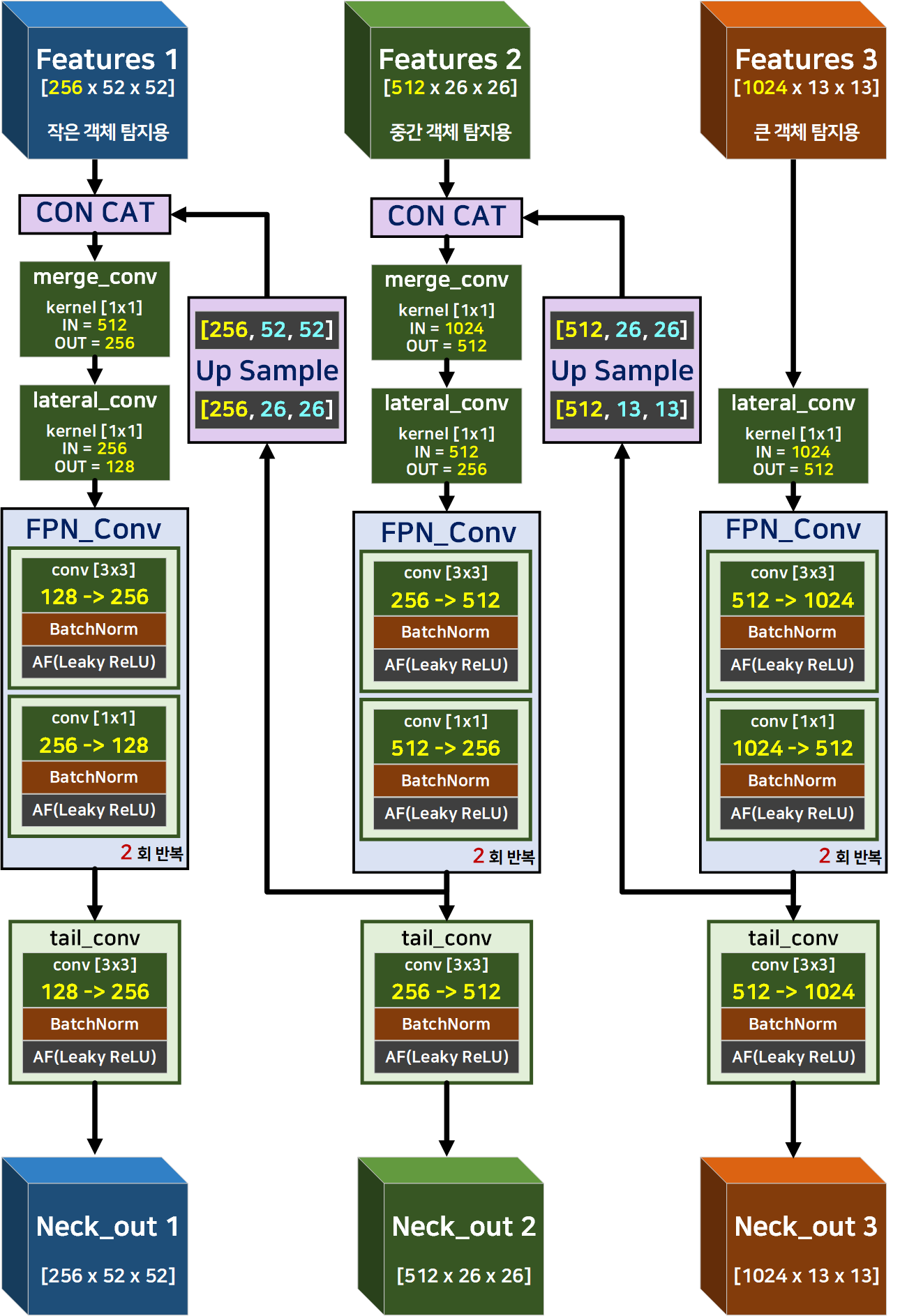 이게 이곳 저곳 다 참고해가면서 도식화를 성공한
이게 이곳 저곳 다 참고해가면서 도식화를 성공한
Yolo v3의 필자가 코드화 한 Feature Pyramid Network의 구조도 이다.
중요한 차원정보는 노란색으로 표기했고
Upsample을 하면서 변화되는 H, W는 하늘색으로 표기했다.
그만큼 코드를 구성하면서 중요한 항목이니 참고 바란다.
import torch.nn.functional as F
class FPN(nn.Module):
def __init__(self, channels_list, num_repeats=2):
super(FPN, self).__init__()
self.lateral_convs = nn.ModuleList([
nn.Conv2d(channels, channels//2, kernel_size=1)
for channels in channels_list
])
self.fpn_convs = nn.ModuleList([
self._make_fpn_layers(channels, num_repeats)
for channels in channels_list
])
self.tail_convs = nn.ModuleList([
BasicConv2d(channels // 2, channels, kernel_size=3, padding=1)
for channels in channels_list
])
self.merge_convs = nn.ModuleList([
nn.Conv2d(channels_list[i] + channels_list[i+1]//2, channels_list[i]//2, kernel_size=1)
for i in range(len(channels_list) - 1)
]) # channels_list[i+1]//2 연산 수행 후 channels_list[i]랑 덧셈되는 것
def _make_fpn_layers(self, channels, num_repeats):
layers = []
for _ in range(num_repeats):
layers.append(BasicConv2d(channels // 2, channels, kernel_size=3, padding=1))
layers.append(BasicConv2d(channels, channels // 2, kernel_size=1))
return nn.Sequential(*layers)
def forward(self, *features):
# 가변 위치인자 '*args'는 튜플로 처리되기에 리스트로 변환시킨다.
features = list(features)
# 첫번재 병렬 레이어 lateral_convs를 적용해 리스트 Feature Map : lateral_features 생성
lateral_features = [lateral_conv(f) for lateral_conv, f in zip(self.lateral_convs, features)]
# 두번째 병렬 레이어 fpn_convs를 적용해 리스트 fpn_features 피처맵 생성
fpn_features = [fpn_conv(f) for fpn_conv, f in zip(self.fpn_convs, lateral_features)]
# FPN의 Top-down pathway(상향경로) and aggregation(통합) 코드
for i in range(len(fpn_features)-1, 0, -1):
# 높은 레벨의 Featue를 낮은 레벨의 Featuer와 합성하기 위해 H, W를 Upsample
upsampled = F.interpolate(fpn_features[i], scale_factor=2, mode='nearest')
# 업 샘플된 높은 레벨의 Feature을 낮은 레벨의 Featuer와 Concat
features[i-1] = torch.cat((features[i-1], upsampled), 1)
# Concat한 신규 Feature을 차원축소(merge_convs) 하여 첫번째 병렬 레이어 업데이트
lateral_features[i-1] = self.merge_convs[i-1](features[i-1])
# 업데이트 된 첫번째 병렬 레이어 정보를 기반으로 두번째 병렬 레이어 업데이트
fpn_features[i-1] = self.fpn_convs[i-1](lateral_features[i-1])
# 가장 마지막 3번째 병렬 레이어에 Top-down pathway and aggregation이 적용된 Feature를 적용
neck_out = [tail_conv(fpn_feature) for tail_conv, fpn_feature in zip(self.tail_convs, fpn_features)]
return neck_out그럼 주요 항목별 코드리뷰를 진행하도록 하겠다.
1) nn.ModuleList : nn.Sequential와 동일하게 모듈을 리스트 형태로 저장하나, 연산 순서를 지정하지 않고 단순하게 리스트로 저장만 할 뿐이다.
따라서
def forward(self, x):위 forward메서드가 호출되면 nn.Sequential는 선언한 순서에 맞춰 레이어가 쌓여나가지만 nn.ModuleList는 순서가 지정되지 않았기에 순서를 따로 정의해줘야 한다.
이를 표로 정리하면 아래와 같다.
| 특성 | nn.ModuleList | nn.Sequential |
|---|---|---|
| 역할 | 모듈들을 리스트 형태로 저장 | 모듈들을 순차적으로 저장하고 하나의 모듈처럼 처리 |
| 연산 순서 | 순서가 있으나 자동으로 연산 순서 지정하지 않음 | 저장된 순서대로 자동으로 호출 |
| 사용자의 작업 | 사용자가 직접 순회하면서 모듈을 적용해야 함 | 한 번의 호출로 모든 모듈 적용 |
| 주 용도 | 동적으로 모듈을 추가하거나 제거할 때 사용 | 고정된 순서의 모듈을 적용할 때 사용 |
| 예시 | ModuleList([layer1, layer2]) | Sequential(layer1, layer2) |
| 동적 모델 구성 | 가능 | 불가능 |
| 고정된 순서의 모델 구성 | 불편 | 편리 |
2) merge_convs : lateral_convs, fpn_convs, tail_convs는 모두 리스트 형태로 저장된 모듈로 레이어를 선언한 코드고 merge_convs도 다를바가 없으나
in_ch와 out_ch는 좀 도식화 할 필요성이 있다.
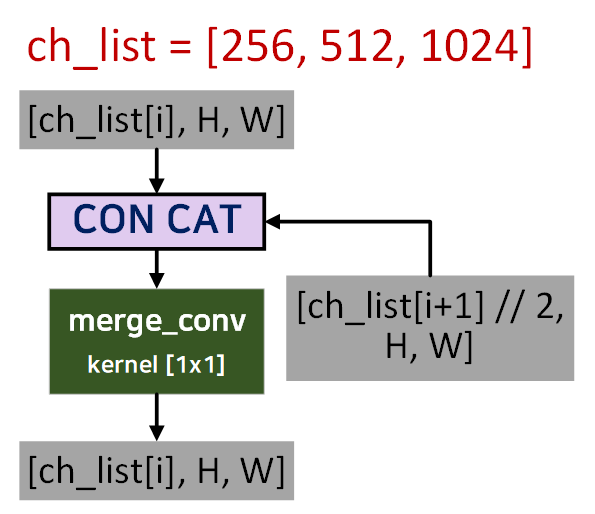 이렇게 떼어내서 보면
이렇게 떼어내서 보면 merge_conv가 입력받는 채널을 절반으로 줄이는 것을 알 수 있을 것이다.
3) *features : FPN클래스는 입력받는 feature이
features = [f3, f4, f5]위 사진처럼 리스트형태의 출력을 받기에 동적으로 구성되는 리스트를 받으려면 Positional arguments(가변 위치인자)인 *args 형태로 입력을 받는 것이 편하다.
단, Positional arguments(가변 위치인자)로 데이터를 받으면 해당 데이터는 자료형이 튜플(tuple)이 되기에 이를 다시 쓰기 쉬운 리스트(list)형태로 자료형을 변환한다.
4) nn.functional.interpolate : PyTorch 라이브러리에서 제공하는 nn.Upsample와 거의 동일한 기능을 수행하는
Feature Map을 업 샘플링하는데 사용되는 API로써
nn.functional.interpolate는 함수형 API
nn.Upsample는 레이어처럼 선언하는 모듈형 클래스
이렇게 나눠 보면 된다.

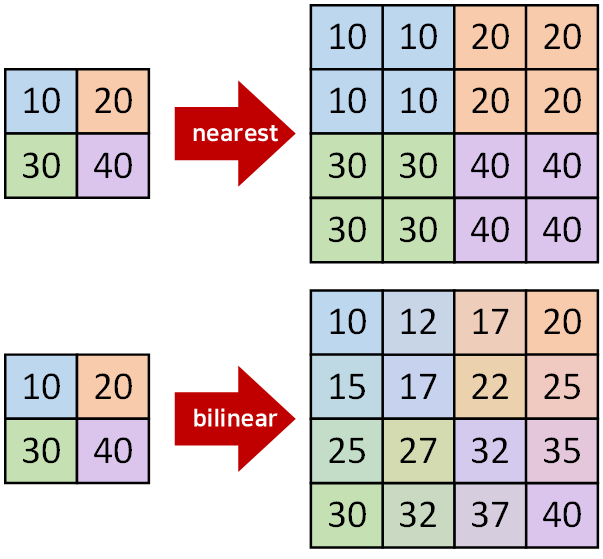
size, scale_factor
입력된 tensor의 몇 배? 이렇게 업스케일링 할거면 scale_factor
목표하는 크기(H, W)가 있다면 size를 쓰면 된다.
mode
nearest,bilinear만 알아두면 된다.
위 업스케일링과 동일하게 기능을 수행할 수 있는 메서드로 nn.ConvTranspose2d가 존재하지만, 이거는 학습 가능한 파라미터가 포함된 nn.Conv2d와 같은 메서드인 convolution 레이어의 역산을 하는 레이어라 보면 된다.
이게 맞는 설명은 아니긴 하지만 nn.ConvTranspose2d는 향후 U-Net 모델을 설명할 때 자세하게 풀어나가도록 하겠다.
이정도면 설명할 내용은 다 설명한 듯 하고
작성한 코드를 검증하면 아래와 같다.
in_1 = torch.rand(1, 256, 52, 52)
in_2 = torch.rand(1, 512, 26, 26)
in_3 = torch.rand(1, 1024, 13, 13)
features = [in_1, in_2, in_3]
# 예시 데이터를 기반으로 FPN의 인스턴스화
model = FPN(channels_list=[256, 512, 1024])from torchinfo import summary
summary(model, input_data=features, col_names=("input_size", "output_size", "num_params"))===================================================================================================================
Layer (type:depth-idx) Input Shape Output Shape Param #
===================================================================================================================
FPN [1, 256, 52, 52] [1, 256, 52, 52] --
├─ModuleList: 1-1 -- -- --
│ └─Conv2d: 2-1 [1, 256, 52, 52] [1, 128, 52, 52] 32,896
│ └─Conv2d: 2-2 [1, 512, 26, 26] [1, 256, 26, 26] 131,328
│ └─Conv2d: 2-3 [1, 1024, 13, 13] [1, 512, 13, 13] 524,800
├─ModuleList: 1-6 -- -- (recursive)
│ └─Sequential: 2-4 [1, 128, 52, 52] [1, 128, 52, 52] --
│ │ └─BasicConv2d: 3-1 [1, 128, 52, 52] [1, 256, 52, 52] 295,424
│ │ └─BasicConv2d: 3-2 [1, 256, 52, 52] [1, 128, 52, 52] 33,024
│ │ └─BasicConv2d: 3-3 [1, 128, 52, 52] [1, 256, 52, 52] 295,424
│ │ └─BasicConv2d: 3-4 [1, 256, 52, 52] [1, 128, 52, 52] 33,024
│ └─Sequential: 2-5 [1, 256, 26, 26] [1, 256, 26, 26] --
│ │ └─BasicConv2d: 3-5 [1, 256, 26, 26] [1, 512, 26, 26] 1,180,672
│ │ └─BasicConv2d: 3-6 [1, 512, 26, 26] [1, 256, 26, 26] 131,584
│ │ └─BasicConv2d: 3-7 [1, 256, 26, 26] [1, 512, 26, 26] 1,180,672
│ │ └─BasicConv2d: 3-8 [1, 512, 26, 26] [1, 256, 26, 26] 131,584
│ └─Sequential: 2-6 [1, 512, 13, 13] [1, 512, 13, 13] --
│ │ └─BasicConv2d: 3-9 [1, 512, 13, 13] [1, 1024, 13, 13] 4,720,640
│ │ └─BasicConv2d: 3-10 [1, 1024, 13, 13] [1, 512, 13, 13] 525,312
│ │ └─BasicConv2d: 3-11 [1, 512, 13, 13] [1, 1024, 13, 13] 4,720,640
│ │ └─BasicConv2d: 3-12 [1, 1024, 13, 13] [1, 512, 13, 13] 525,312
├─ModuleList: 1-5 -- -- (recursive)
│ └─Conv2d: 2-7 [1, 1024, 26, 26] [1, 256, 26, 26] 262,400
├─ModuleList: 1-6 -- -- (recursive)
│ └─Sequential: 2-8 [1, 256, 26, 26] [1, 256, 26, 26] (recursive)
│ │ └─BasicConv2d: 3-13 [1, 256, 26, 26] [1, 512, 26, 26] (recursive)
│ │ └─BasicConv2d: 3-14 [1, 512, 26, 26] [1, 256, 26, 26] (recursive)
│ │ └─BasicConv2d: 3-15 [1, 256, 26, 26] [1, 512, 26, 26] (recursive)
│ │ └─BasicConv2d: 3-16 [1, 512, 26, 26] [1, 256, 26, 26] (recursive)
├─ModuleList: 1-5 -- -- (recursive)
│ └─Conv2d: 2-9 [1, 512, 52, 52] [1, 128, 52, 52] 65,664
├─ModuleList: 1-6 -- -- (recursive)
│ └─Sequential: 2-10 [1, 128, 52, 52] [1, 128, 52, 52] (recursive)
│ │ └─BasicConv2d: 3-17 [1, 128, 52, 52] [1, 256, 52, 52] (recursive)
│ │ └─BasicConv2d: 3-18 [1, 256, 52, 52] [1, 128, 52, 52] (recursive)
│ │ └─BasicConv2d: 3-19 [1, 128, 52, 52] [1, 256, 52, 52] (recursive)
│ │ └─BasicConv2d: 3-20 [1, 256, 52, 52] [1, 128, 52, 52] (recursive)
├─ModuleList: 1-7 -- -- --
│ └─BasicConv2d: 2-11 [1, 128, 52, 52] [1, 256, 52, 52] --
│ │ └─Conv2d: 3-21 [1, 128, 52, 52] [1, 256, 52, 52] 294,912
│ │ └─BatchNorm2d: 3-22 [1, 256, 52, 52] [1, 256, 52, 52] 512
│ │ └─LeakyReLU: 3-23 [1, 256, 52, 52] [1, 256, 52, 52] --
│ └─BasicConv2d: 2-12 [1, 256, 26, 26] [1, 512, 26, 26] --
│ │ └─Conv2d: 3-24 [1, 256, 26, 26] [1, 512, 26, 26] 1,179,648
│ │ └─BatchNorm2d: 3-25 [1, 512, 26, 26] [1, 512, 26, 26] 1,024
│ │ └─LeakyReLU: 3-26 [1, 512, 26, 26] [1, 512, 26, 26] --
│ └─BasicConv2d: 2-13 [1, 512, 13, 13] [1, 1024, 13, 13] --
│ │ └─Conv2d: 3-27 [1, 512, 13, 13] [1, 1024, 13, 13] 4,718,592
│ │ └─BatchNorm2d: 3-28 [1, 1024, 13, 13] [1, 1024, 13, 13] 2,048
│ │ └─LeakyReLU: 3-29 [1, 1024, 13, 13] [1, 1024, 13, 13] --
===================================================================================================================
Total params: 20,987,136
Trainable params: 20,987,136
Non-trainable params: 0
Total mult-adds (G): 11.87
===================================================================================================================
Input size (MB): 4.85
Forward/backward pass size (MB): 136.37
Params size (MB): 83.95
Estimated Total Size (MB): 225.16
===================================================================================================================이 FPN 레이어도 학습 가능한 파라미터의 개수가 2천만개쯤 되니
흠.. darknet53에 대한 Weight File만 구할게 아닌거 같긴하다...
아무튼 FPN 모델의 출력 결과물도 확인해보자
fpn_features = model(*features)
# upsampled의 shape 출력
for i in range(len(fpn_features)):
print("Upsampled shape:", fpn_features[i].shape)Upsampled shape: torch.Size([1, 256, 52, 52])
Upsampled shape: torch.Size([1, 512, 26, 26])
Upsampled shape: torch.Size([1, 512, 13, 13])FPN 모델의 출력 결과물을 확인해보니 해당 모델이 재대로 설계된 것을 확인할 수 있다.
3. 기타 모듈 코드
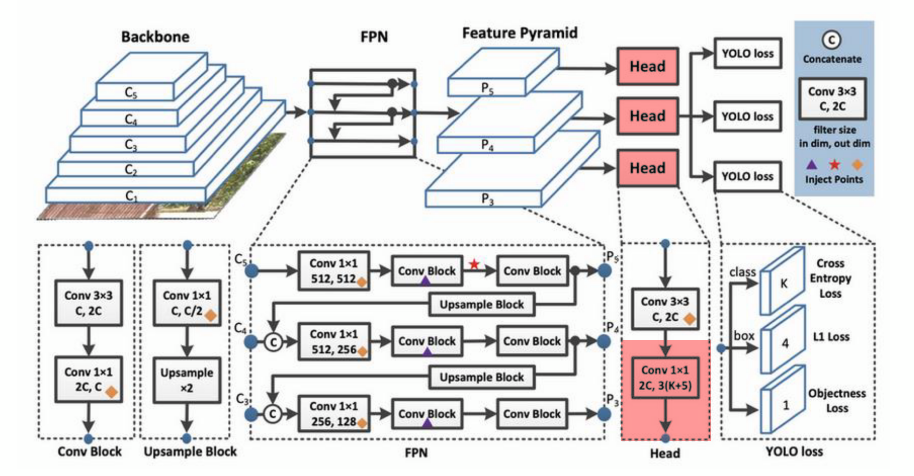 위 사진의
위 사진의 head에 속하는 레이어를 코드화 해주자
class YOLOHead(nn.Module):
def __init__(self, in_channels, num_classes):
super(YOLOHead, self).__init__()
self.conv = nn.Conv2d(in_channels, 3 * (5 + num_classes), kernel_size=1)
def forward(self, x):
return self.conv(x)위 코드를 수행한 뒤에
Backbone모델을 미리 인스턴스화 해서 해당 모델의 출력 정보를 따로 저장하는것이 편하다.
# 백본 모델 인스턴스 생성
backbone = Darknet53()
# 임의의 입력 텐서 생성 및 모델에 통과시킴
input_tensor = torch.rand(1, 3, 416, 416)
features = backbone(input_tensor)
# 각 레이어의 출력 shape 정보에서 채널 수만 추출하여 리스트에 저장
features_shape = [feature.shape[1] for feature in features]이제 최종으로 Yolo v3을
위 설계한 모든 클래스를 합친 모델로 재 정의하면 된다.
class YOLOv3(nn.Module):
def __init__(self, backbone, fpn, num_classes):
super(YOLOv3, self).__init__()
self.backbone = backbone
self.fpn = fpn
self.num_classes = num_classes
self.heads = nn.ModuleList([
YOLOHead(in_channels, num_classes) for in_channels in features_shape
])
def forward(self, x):
features = self.backbone(x)
fpn_features = self.fpn(*features)
outputs = [head(fpn_feature) for head, fpn_feature in zip(self.heads, fpn_features)]
return outputsbackbone = Darknet53()
fpn = FPN(channels_list=features_shape)
#coco 데이터셋 기준 클래스 종류 = 80
yolov3 = YOLOv3(backbone, fpn, num_classes=80)설계한 Yolo v3이 재대로 모델링이 되었는지 마지막으로 검증을 더 수행해보자
from torchinfo import summary
# Use torchinfo to summarize the model
summary(yolov3, input_size=(1, 3, 416, 416))===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
YOLOv3 [1, 255, 52, 52] --
├─Darknet53: 1-1 [1, 256, 52, 52] 1,025,000
│ └─Sequential: 2-1 [1, 64, 208, 208] --
│ │ └─BasicConv2d: 3-1 [1, 32, 416, 416] 928
│ │ └─BasicConv2d: 3-2 [1, 64, 208, 208] 18,560
│ └─Sequential: 2-2 [1, 64, 208, 208] --
│ │ └─Residual_block: 3-3 [1, 64, 208, 208] 20,672
│ └─BasicConv2d: 2-3 [1, 128, 104, 104] --
│ │ └─Conv2d: 3-4 [1, 128, 104, 104] 73,728
│ │ └─BatchNorm2d: 3-5 [1, 128, 104, 104] 256
│ │ └─LeakyReLU: 3-6 [1, 128, 104, 104] --
│ └─Sequential: 2-4 [1, 128, 104, 104] --
│ │ └─Residual_block: 3-7 [1, 128, 104, 104] 82,304
│ │ └─Residual_block: 3-8 [1, 128, 104, 104] 82,304
│ └─BasicConv2d: 2-5 [1, 256, 52, 52] --
│ │ └─Conv2d: 3-9 [1, 256, 52, 52] 294,912
│ │ └─BatchNorm2d: 3-10 [1, 256, 52, 52] 512
│ │ └─LeakyReLU: 3-11 [1, 256, 52, 52] --
│ └─Sequential: 2-6 [1, 256, 52, 52] --
│ │ └─Residual_block: 3-12 [1, 256, 52, 52] 328,448
│ │ └─Residual_block: 3-13 [1, 256, 52, 52] 328,448
│ │ └─Residual_block: 3-14 [1, 256, 52, 52] 328,448
│ │ └─Residual_block: 3-15 [1, 256, 52, 52] 328,448
│ │ └─Residual_block: 3-16 [1, 256, 52, 52] 328,448
│ │ └─Residual_block: 3-17 [1, 256, 52, 52] 328,448
│ │ └─Residual_block: 3-18 [1, 256, 52, 52] 328,448
│ │ └─Residual_block: 3-19 [1, 256, 52, 52] 328,448
│ └─BasicConv2d: 2-7 [1, 512, 26, 26] --
│ │ └─Conv2d: 3-20 [1, 512, 26, 26] 1,179,648
│ │ └─BatchNorm2d: 3-21 [1, 512, 26, 26] 1,024
│ │ └─LeakyReLU: 3-22 [1, 512, 26, 26] --
│ └─Sequential: 2-8 [1, 512, 26, 26] --
│ │ └─Residual_block: 3-23 [1, 512, 26, 26] 1,312,256
│ │ └─Residual_block: 3-24 [1, 512, 26, 26] 1,312,256
│ │ └─Residual_block: 3-25 [1, 512, 26, 26] 1,312,256
│ │ └─Residual_block: 3-26 [1, 512, 26, 26] 1,312,256
│ │ └─Residual_block: 3-27 [1, 512, 26, 26] 1,312,256
│ │ └─Residual_block: 3-28 [1, 512, 26, 26] 1,312,256
│ │ └─Residual_block: 3-29 [1, 512, 26, 26] 1,312,256
│ │ └─Residual_block: 3-30 [1, 512, 26, 26] 1,312,256
│ └─BasicConv2d: 2-9 [1, 1024, 13, 13] --
│ │ └─Conv2d: 3-31 [1, 1024, 13, 13] 4,718,592
│ │ └─BatchNorm2d: 3-32 [1, 1024, 13, 13] 2,048
│ │ └─LeakyReLU: 3-33 [1, 1024, 13, 13] --
│ └─Sequential: 2-10 [1, 1024, 13, 13] --
│ │ └─Residual_block: 3-34 [1, 1024, 13, 13] 5,245,952
│ │ └─Residual_block: 3-35 [1, 1024, 13, 13] 5,245,952
│ │ └─Residual_block: 3-36 [1, 1024, 13, 13] 5,245,952
│ │ └─Residual_block: 3-37 [1, 1024, 13, 13] 5,245,952
├─FPN: 1-2 [1, 256, 52, 52] --
│ └─ModuleList: 2-11 -- --
│ │ └─Conv2d: 3-38 [1, 128, 52, 52] 32,896
│ │ └─Conv2d: 3-39 [1, 256, 26, 26] 131,328
│ │ └─Conv2d: 3-40 [1, 512, 13, 13] 524,800
│ └─ModuleList: 2-16 -- (recursive)
│ │ └─Sequential: 3-41 [1, 128, 52, 52] 656,896
│ │ └─Sequential: 3-42 [1, 256, 26, 26] 2,624,512
│ │ └─Sequential: 3-43 [1, 512, 13, 13] 10,491,904
│ └─ModuleList: 2-15 -- (recursive)
│ │ └─Conv2d: 3-44 [1, 256, 26, 26] 262,400
│ └─ModuleList: 2-16 -- (recursive)
│ │ └─Sequential: 3-45 [1, 256, 26, 26] (recursive)
│ └─ModuleList: 2-15 -- (recursive)
│ │ └─Conv2d: 3-46 [1, 128, 52, 52] 65,664
│ └─ModuleList: 2-16 -- (recursive)
│ │ └─Sequential: 3-47 [1, 128, 52, 52] (recursive)
│ └─ModuleList: 2-17 -- --
│ │ └─BasicConv2d: 3-48 [1, 256, 52, 52] 295,424
│ │ └─BasicConv2d: 3-49 [1, 512, 26, 26] 1,180,672
│ │ └─BasicConv2d: 3-50 [1, 1024, 13, 13] 4,720,640
├─ModuleList: 1-3 -- --
│ └─YOLOHead: 2-18 [1, 255, 52, 52] --
│ │ └─Conv2d: 3-51 [1, 255, 52, 52] 65,535
│ └─YOLOHead: 2-19 [1, 255, 26, 26] --
│ │ └─Conv2d: 3-52 [1, 255, 26, 26] 130,815
│ └─YOLOHead: 2-20 [1, 255, 13, 13] --
│ │ └─Conv2d: 3-53 [1, 255, 13, 13] 261,375
===============================================================================================
Total params: 63,054,789
Trainable params: 63,054,789
Non-trainable params: 0
Total mult-adds (G): 36.70
===============================================================================================
Input size (MB): 2.08
Forward/backward pass size (MB): 666.93
Params size (MB): 248.12
Estimated Total Size (MB): 917.13
===============================================================================================input = torch.rand(1, 3, 416, 416).to('cuda')
# 출력물 검증해보기
output = yolov3(input)for i in range(len(output)):
print(output[i].shape)torch.Size([1, 255, 52, 52])
torch.Size([1, 255, 26, 26])
torch.Size([1, 255, 13, 13])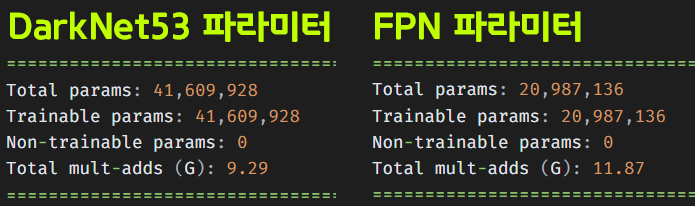
Yolo v3 head 모듈까지 합치면 대충 파라미터 개수도 맞게 나온 듯 하다.
3.1 모든 Feature 레벨에서 출력
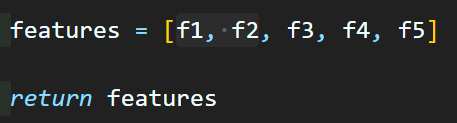
위 사진처럼 Darknet53의 마지막 Feature Map을 f1, f2 두개만 더 추가해주면 된다
이러면 Yolo v3의 출력 tensor 종류가 3개에서 5개로 늘어난다.
이것 말고 다른 코드는 변경할 필요가 없으니
다시 재 인스턴스화 하면 아래와 같은 출력물을 얻을 수 있다.
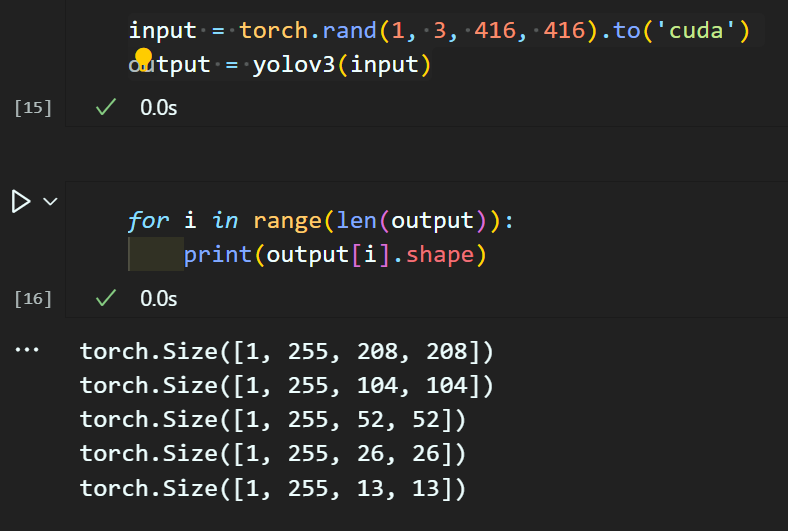

출력물을 3개에서 5개로 늘린다고 해도
뭐 딱히 학습시켜야 할 파라미터가 드라마틱하게 늘어나는 편은 아니다.
이걸 하는 이유는... 궂이 Yolo v3의 Feature Pyramid Network가 3개만 출력해야 한다
라는 고정된 사고를 버릴 필요가 있다..
음...

아무튼 동적인 코드를 잘 짯다는 것에 만족하자
