
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. 작업목표

이전 포스트 인공지능 고급(시각) 강의 예습 - 22. (9) Yolo v3 : 2차 코드 검증 - 데이터셋에서 검증 결과가 조금은 못 미덥긴 하지만 이정도로 yolo_dataset.py코드의 검증을 완수했고
이번에는 yolo_v3_metrics.py의 나머지 기능인
 위 4개의 평가지표
위 4개의 평가지표 IOU, Precision, Recall, Top-1 Error을 재대로 측정하고 있는지 코드를 검증해 보려고 한다.
방식은 아래와 같다.
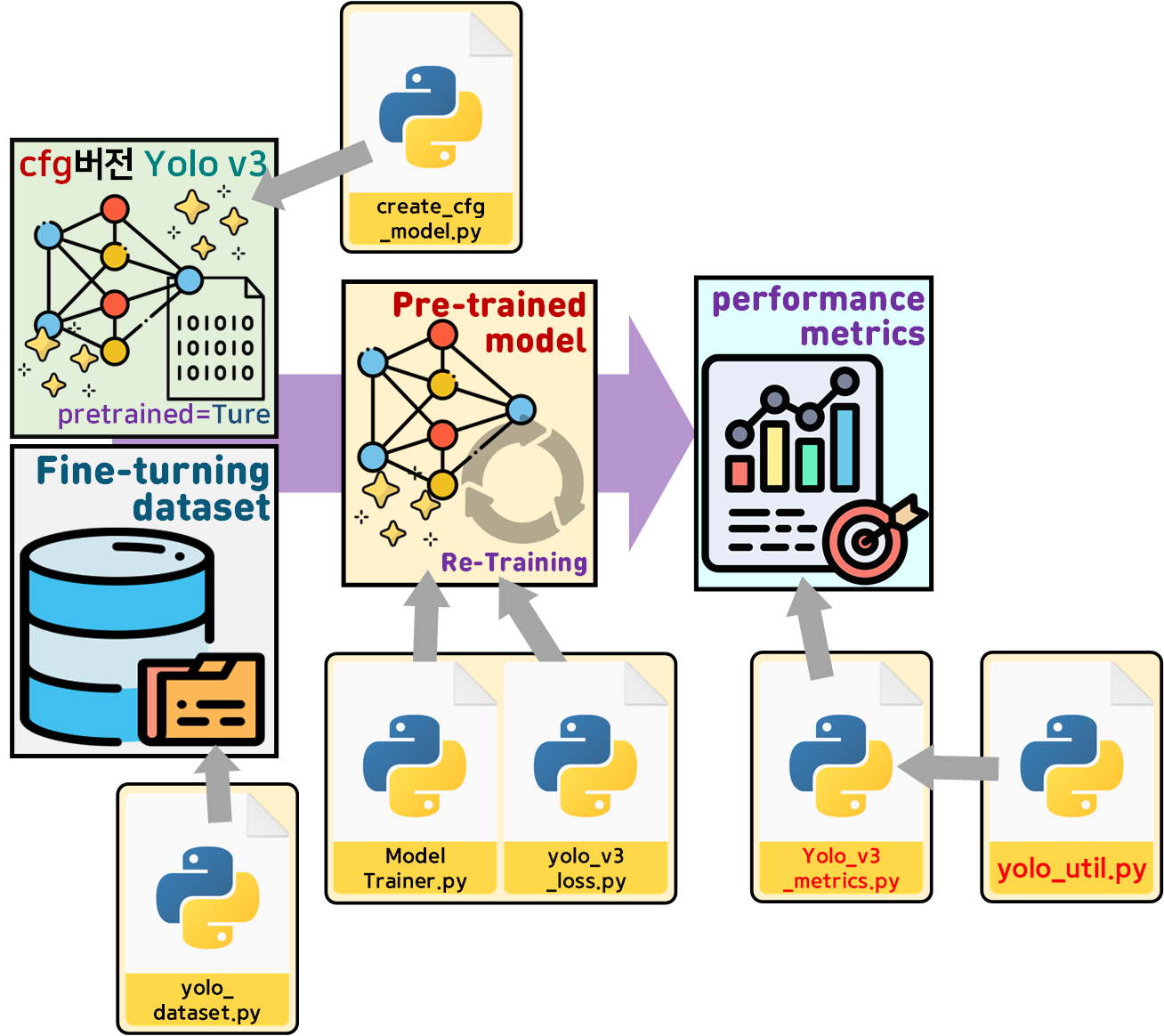
 학습이 완료된 Pre-trained model : CFG버전의 Yolo v3 모델을 핸들링하는 것이 가능하니
학습이 완료된 Pre-trained model : CFG버전의 Yolo v3 모델을 핸들링하는 것이 가능하니
위 사진처럼 COCO 데이터셋으로 재 학습을 시켜서 성능지표를 재 산출하는 것이 목표다.
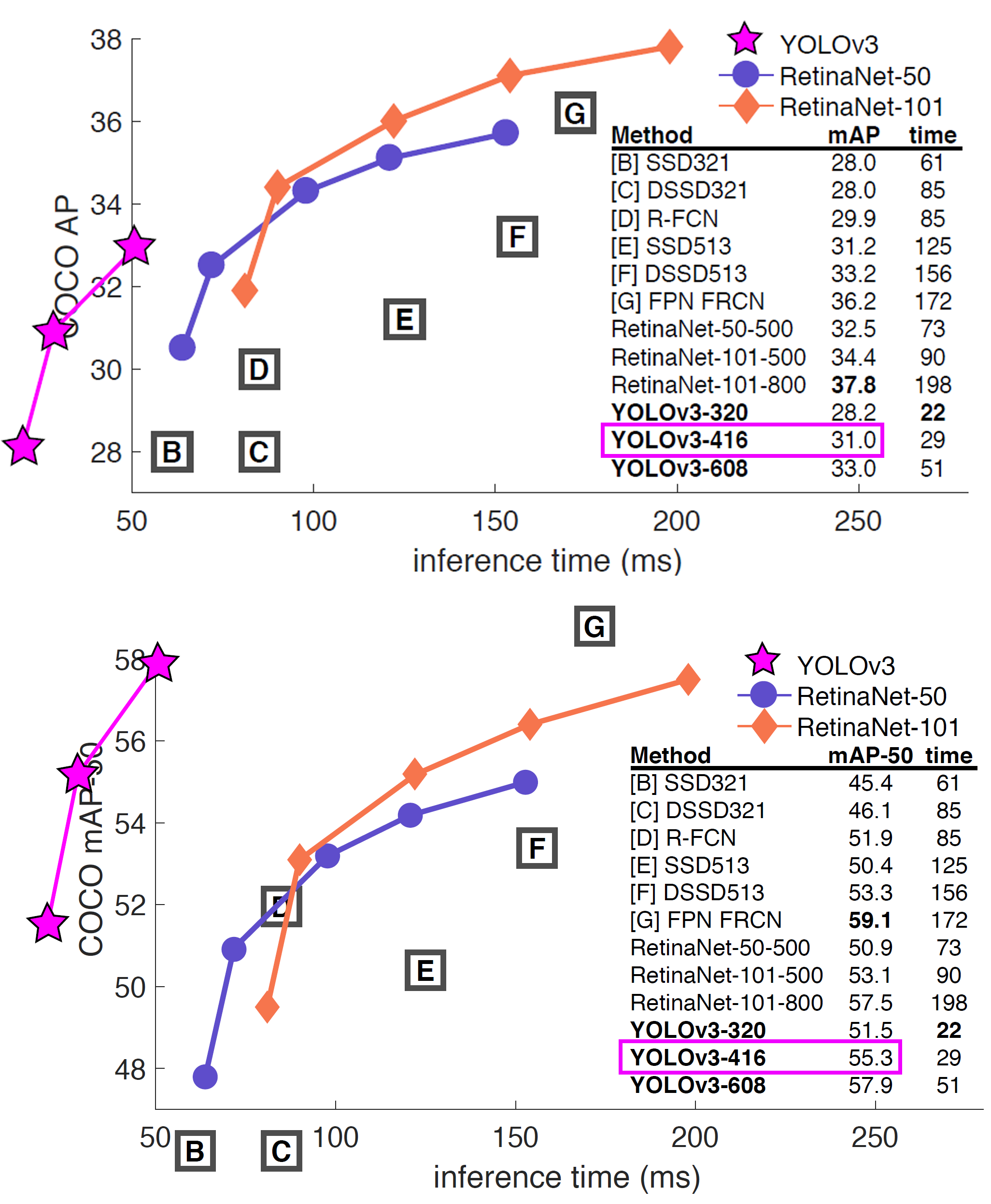 그래서 위 사진처럼 평가지표의 Precision / Recall 항목이 적어도 논문에 기재한 mAP에는 근접하게 나오는지?
그래서 위 사진처럼 평가지표의 Precision / Recall 항목이 적어도 논문에 기재한 mAP에는 근접하게 나오는지?
나오지 않으면 어떤 문제가 있는지를 확인하는 것이 이번 포스트의 목표이다.
2. 사전학습 모델 재 학습
import torch
from yolo_dataset import CustomDataset #커스텀 데이터셋 코드
from ModelTrainer import ModelTrainer #train / val 코드
import create_cfg_model as cm # cfg 모델로 Re-training
from yolo_v3_loss import Yolov3Loss, loss_debug
from yolo_v3_metrics import YOLOv3Metrics, metrics_debug #평가지표 코드
from tqdm import tqdm# CFG모델을 불러와서 Pre-TrainModel 인스턴스화
cfg_file = "yolov3.cfg"
weight_file = "YOLOv3-416.weights"
# CFG 정보 파싱
blocks = cm.parse_cfg(cfg_file)
# CFG 모델 인스턴스화
cfg_model = cm.Yolo_v3_cfg(blocks)
# pre-trained weights로 CFG 모델 초기화
cm.load_weights(cfg_model, weight_file)
# cfg용 anchorbox리스트
cfg_anchor_box_list = cm.convert_anchor(cfg_file)# coco데이터셋의 메인 루트 디렉토리
root_dir = './COCO dataset'
# load_anno=val2014 -> 'instance_val2014.json'참조 + `val2014`img폴더 참조
train_dataset = CustomDataset(root=root_dir, load_anno='val2014',
anchor=cfg_anchor_box_list)
test_dataset = CustomDataset(root=root_dir, load_anno='val2017',
anchor=cfg_anchor_box_list)
print(f"훈련용 : {train_dataset}, \n 검증용 : {test_dataset}")from torchvision.transforms import v2
coco_val = [[0.4701, 0.4468, 0.4076], [0.2379, 0.2329, 0.2362]]
# 데이터셋 전처리 방법론 정의
transforamtion = v2.Compose([
v2.Resize((416, 416)), #이미지 크기를 416, 416로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=coco_val[0], std=coco_val[1]) #데이터셋 정규화
])# 데이터셋 전처리 방법론 적용
train_dataset.transform = transforamtion
test_dataset.transform = transforamtionfrom torch.utils.data import DataLoader
BATCH_SIZE = 32
# 전처리가 완료된 데이터셋의 데이터로더 전환
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# CFG 모델 GPU로 이전
cfg_model.to(device)
print()여기까지는 일반적인 모델 인스턴스화, 데이터셋 생성, GPU이전등의 내용이라 설명은 건너뛰겠다.
import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
# 손실 함수 설정 (YOLOv3 손실 함수)
criterion = Yolov3Loss(device=device.type)
# 옵티마이저는 Pretrain model의 전이학습이기에 매우 작은 learning rate로 설정
optimizer = optim.SGD(cfg_model.parameters(), lr=1e-6, momentum=0.9)
# 스케줄러 설정 (50 에폭 기준 Cosine Annealing)
scheduler = CosineAnnealingLR(optimizer, T_max=20)전이학습/미세조정에 속하기에 옵티마이저는 SGD를 사용했고 과적합이 나는 것을 경계해야 하기에
Learning Rate(lr)은 매우 작은 값으로 설정했다.
# Train / eval(Val)을 수행하는 클래스 인스턴스화
epoch_step = 1
trainer = ModelTrainer(epoch_step=epoch_step, device=device.type)
metrics = YOLOv3Metrics(anchor=cfg_anchor_box_list, device=device.type)다음으로 평가지표를 산출하는 YOLOv3Metrics와 Train / Val을 수행하는 ModelTrainer 클래스를 인스턴스화 한 뒤
# 학습과 검증 손실 및 정확도를 저장할 리스트
his_loss = []
his_KPI = []
num_epoch = 10
for epoch in range(num_epoch):
# 훈련 손실과 훈련 성과지표를 반환 받습니다.
train_loss, train_KPI = trainer.model_train(cfg_model, train_loader,
criterion, optimizer, scheduler,
metrics, epoch)
# 검증 손실과 검증 성과지표를 반환 받습니다.
test_loss, test_KPI = trainer.model_evaluate(cfg_model, test_loader,
criterion, metrics, epoch)
# 손실과 성능지표를 리스트에 저장
his_loss.append((train_loss, test_loss))
his_KPI.append((train_KPI, test_KPI))
# epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"Training loss: {train_loss:.4f}")
print(f"Train KPI[ IOU: {train_KPI[0]:.4f}, "+
f"Precision: {train_KPI[1]:.4f}, "+
f"Recall: {train_KPI[2]:.4f}, "+
f"Top1_err: {train_KPI[3]:.4f} ]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"Test loss: {test_loss:.4f}")
print(f"Test KPI[ IOU: {test_KPI[0]:.4f}, "+
f"Precision: {test_KPI[1]:.4f}, "+
f"Recall: {test_KPI[2]:.4f}, "+
f"Top1_err: {test_KPI[3]:.4f} ]")10 epoch로 매우 적게 재학습을 시켜보도록 하자.
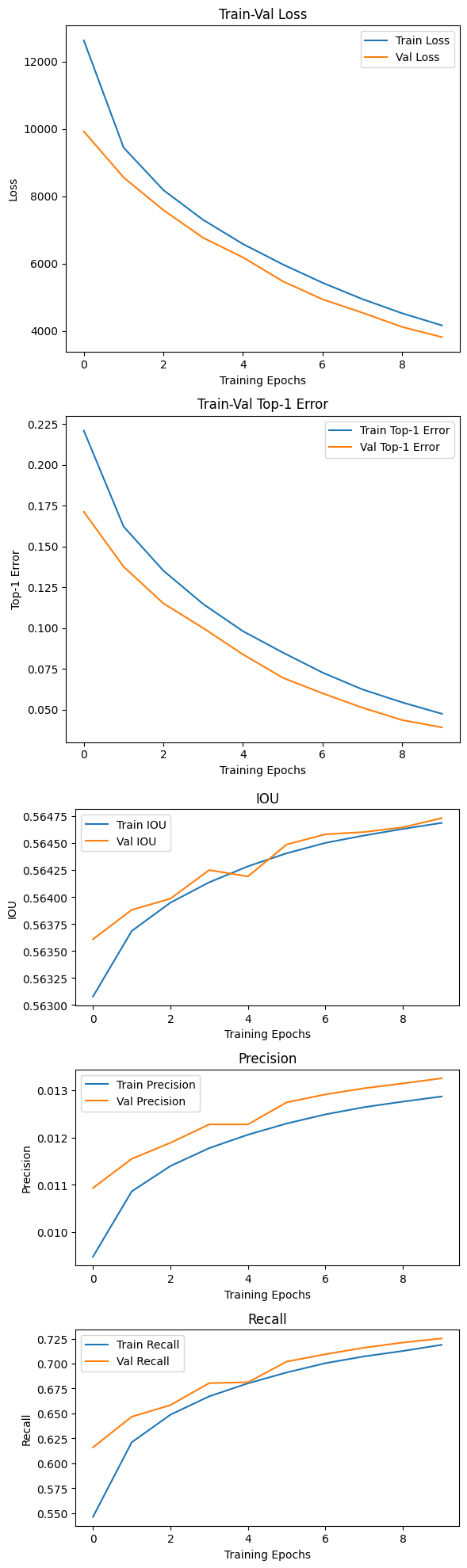
음.. 역시 IOU, Precision, Recall은 평가지표를 정의하는 방식을 찾아봐야 할거 같다.

2. P-R curve
평가지표를 다시 재정의를 수행하고, 이를 코드화를 해야 하다보니
공부를 다시해야 할 필요성이 발생했다.
우선 그간 개념정립이 미약했던 Precision, Recall부터 다시 공부를 시작해야 했다.
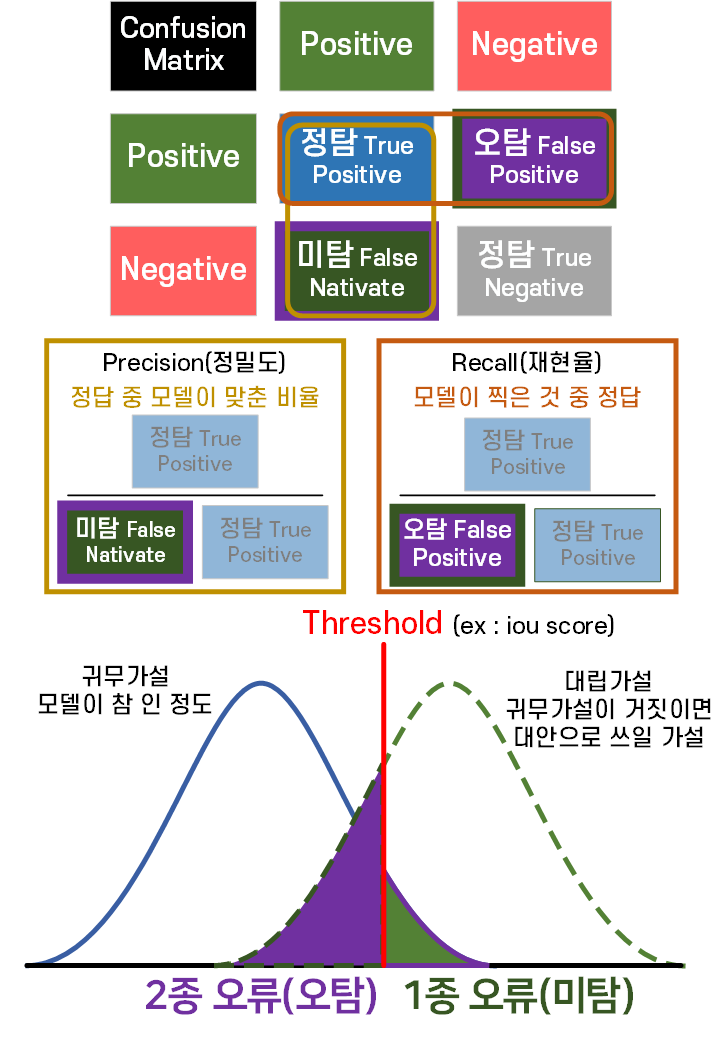
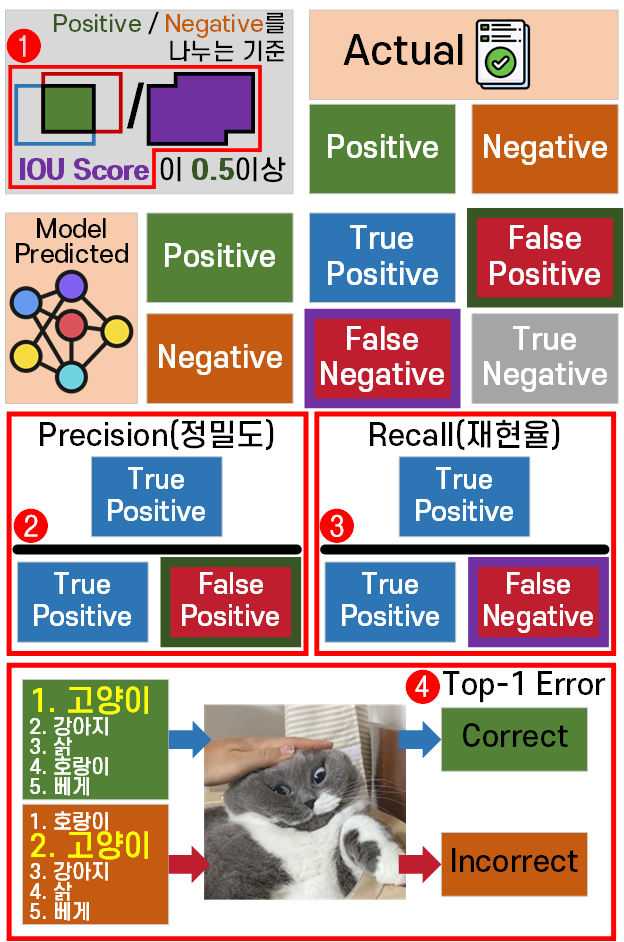
위 그림처럼 모델이 어떤 문제를 풀이할 때는
Confuision Matrix(혼동행렬)로 모델이 풀이한 결과를 정답과 비교하여 4가지 케이스로 나누어 볼 수 있다.
이 케이스 별로 미 탐지(False Native)가 분모로 들어가서
전체 정답 중 모델이 정답으로 맞춘 비율 : Precision(정밀도)
가 되는 것이고 이 미탐 1종 오류
그리고 또다른 케이스로 오 탐지(False Positive)가 분모로 들어가서
모델이 정답이라 한 것 중 진짜 정답 비율 : Recall(재현율)가
되고 여기서 오탐 2종 오류
가 되는 것이다.

뭐 참 여러가지 어려운단어가 많이 발생하는데
모델이 학습이 진행될 때에는 Recall(재현율)의 성능이 먼저 좋아 경향이 있고
최종적으로 모델이 쓸만한가? 를 논할 때는 Precision(정밀도)를 더 중점으로 놓고 평가한다.
그리고 Precision(정밀도) / Recall(재현율)의 관계는 Trade-off 관계여서
여기서 골아파지기 시작하는 P-R Curve라는 개념이 발생한다.
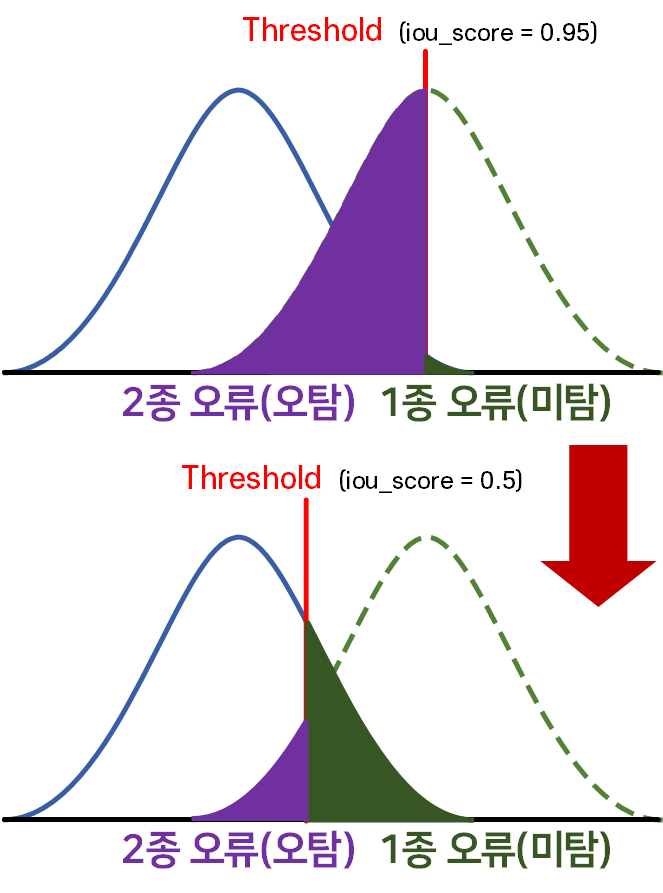
P-R Curve는 위 사진처럼 IOU Score를 임계값으로 설정하여 iou_th값을 다양하게 조정하면서 Precision(정밀도) / Recall(재현율)이 어떻게 변화하는지를 관찰한 그래프라 보면 된다.
이때 Yolo v3에서 사용한 COCO데이터셋 기준으로는 iou_th를 [0.95 ~ 0.5] 사이로 사용하는 경우가 일반적인 것 같고
이 때의 P-R Curve 그래프를 도식화 하면 대략 아래와 같은 그림이 그려진다 보면 된다.
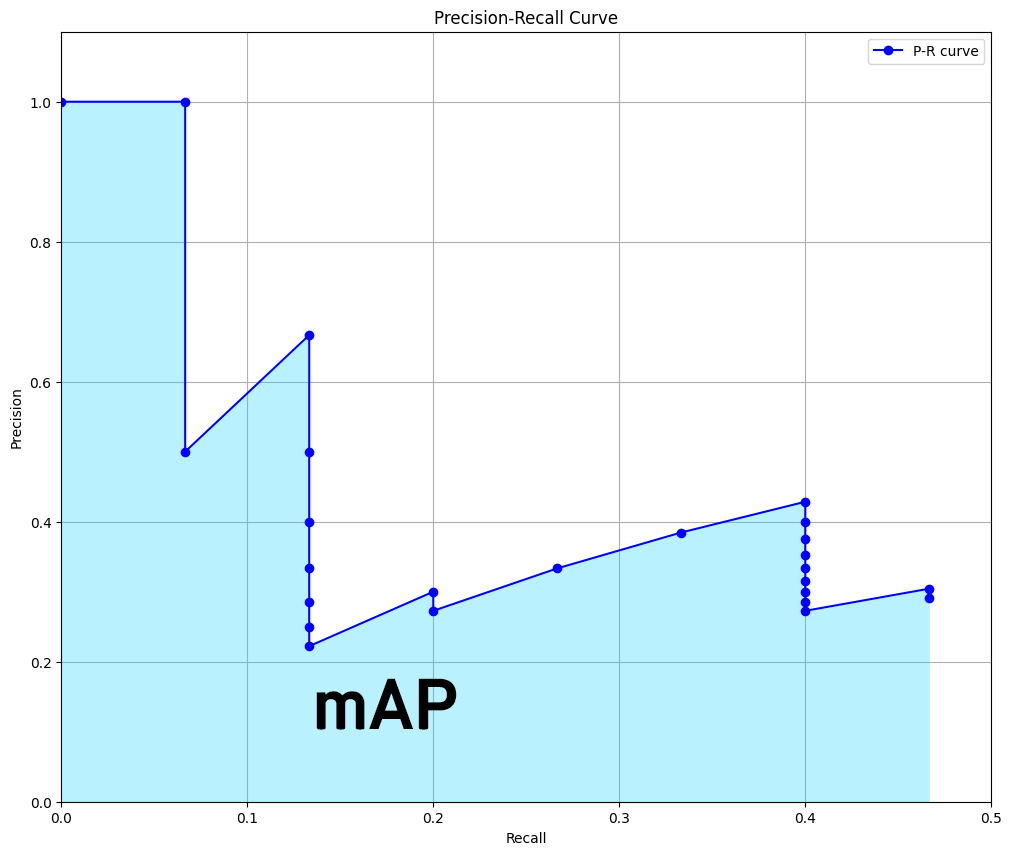
이때 이 P-R Curve의 아래 영역을 mAP라는 지표로 정의하는 것이
일반적이다.. 라고 한다.
위 그래프는 독립변인에 속하는 iou_th에 대한 정보가 없어
이를 추가한 3차원 그래프를 그리면 아래와 같아진다.
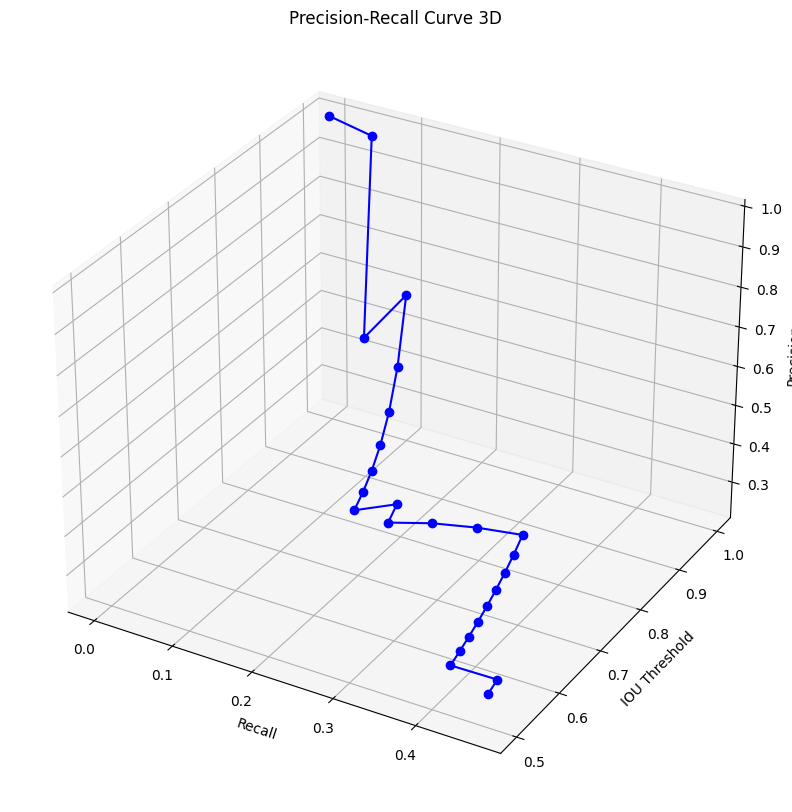
독립변인인 iou_th가 변화함에 따라 Precision / Recall의 비율이 어떻게 변화하는지 알 필요성이 있다.
이때 아래 면적에 해당하는 mAP를 정확하게 산출하기 어려운 부분이 있어
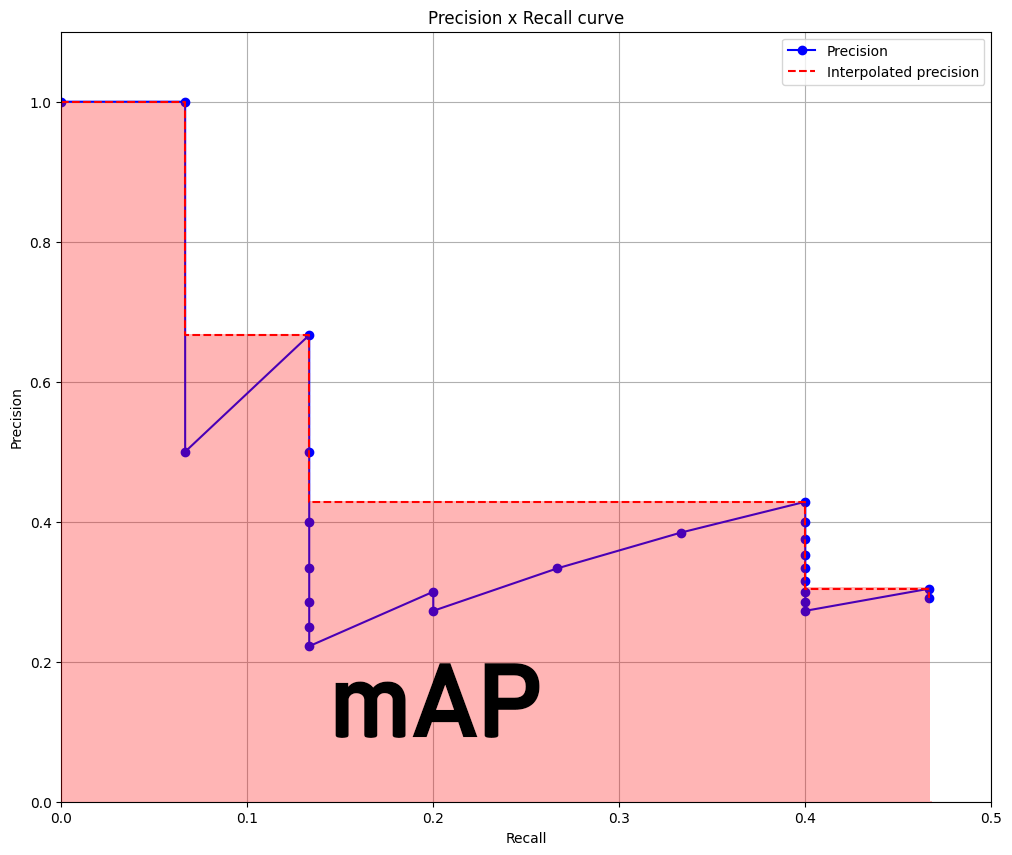 위 사진처럼 면적을 보간한 뒤 보간된 면적에 대하여
위 사진처럼 면적을 보간한 뒤 보간된 면적에 대하여 mAP를 산출한다.
라고 한다.

왜 이렇게 복잡하게 mAP를 계산하는지 필자는 잘 와닿지가 않는다.
확실한건 iou_th = 0.5 이렇게 단순하게 정의하고
Precision / Recall을 계산하던 좋은 시절은 지났다는 것이다.
3. yolo_v3_metrics.py 모듈화
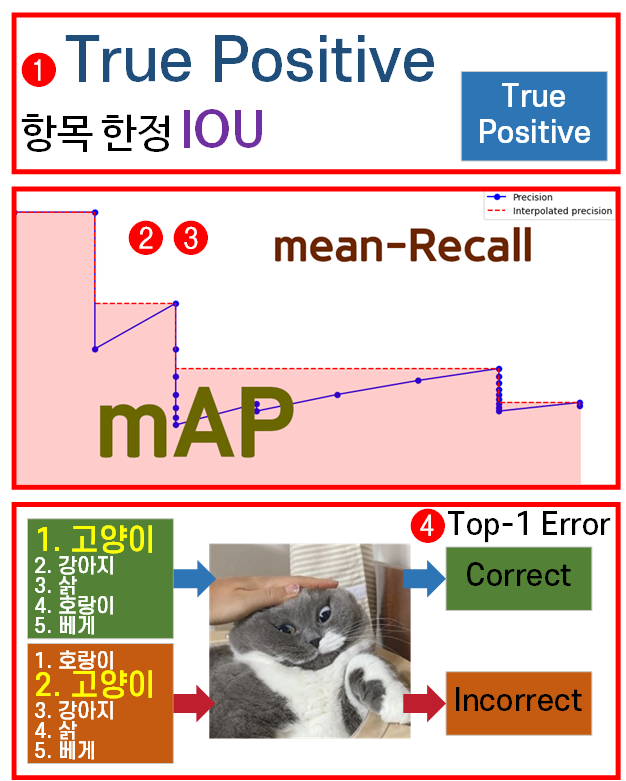
yolo_v3_metrics.py파일 내에서 평가지표의 산정 방식이
위 사진처럼 변경되었고
2, 3에 해당하는 mAP, mean-Recall 항목은 연산과정이 복잡해졌기에 이 기능이 추가되면서 코드가 상당히 무거워졌다.
따라서 아래의 사진처럼 get_pred_bbox(), compute_iou() 함수 2개는 따로 분리하여 yolo_util.py로 모듈화를 진행했다.
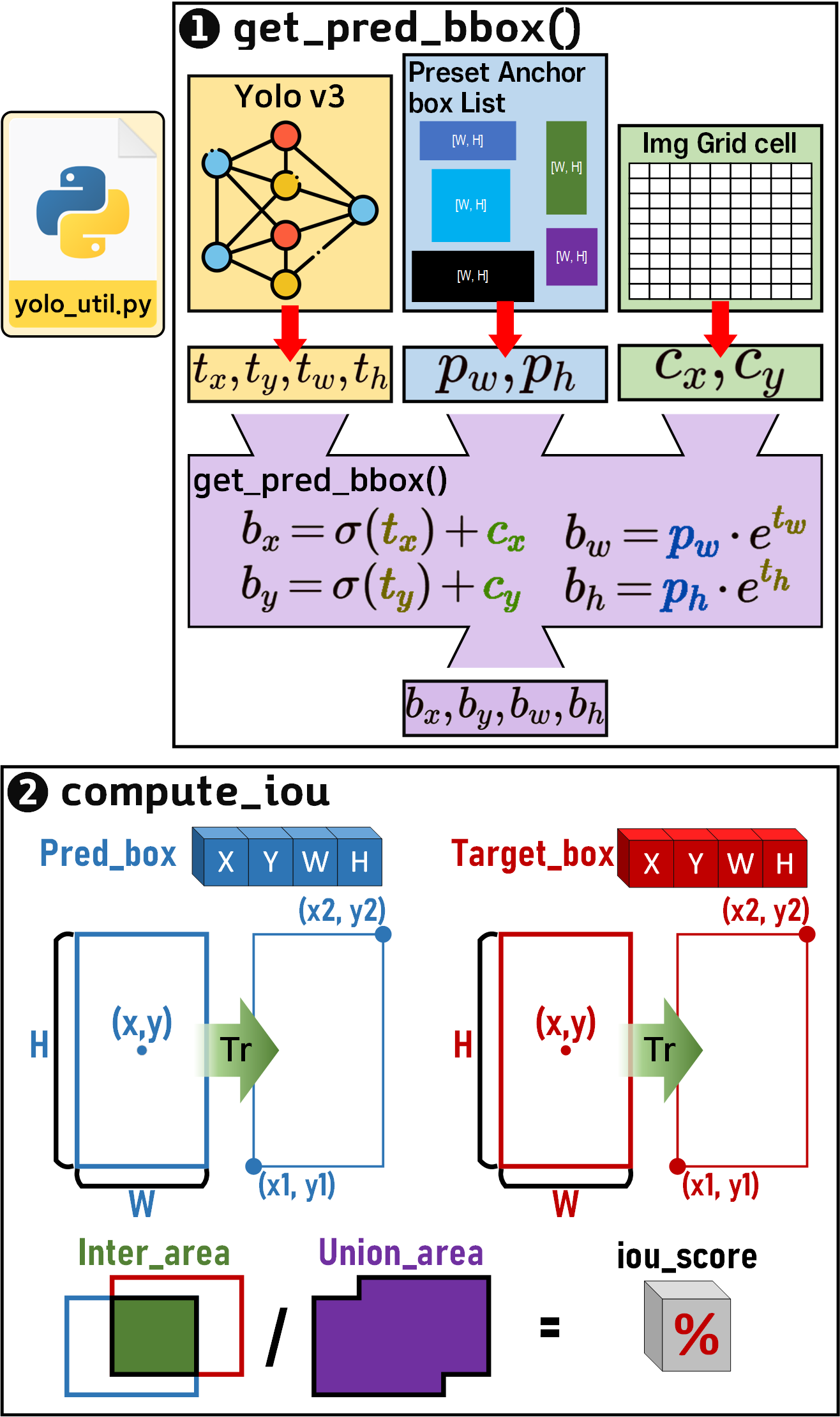
이렇게 좌표변환, IOU 연산함수는 다른 py모듈에서도 빈번하게 가져와서 사용되기에
모듈을 또 분리할 필요성이 있었다.
이제는 코드가 너무 복잡해져서 나도 잘 모르겠다...
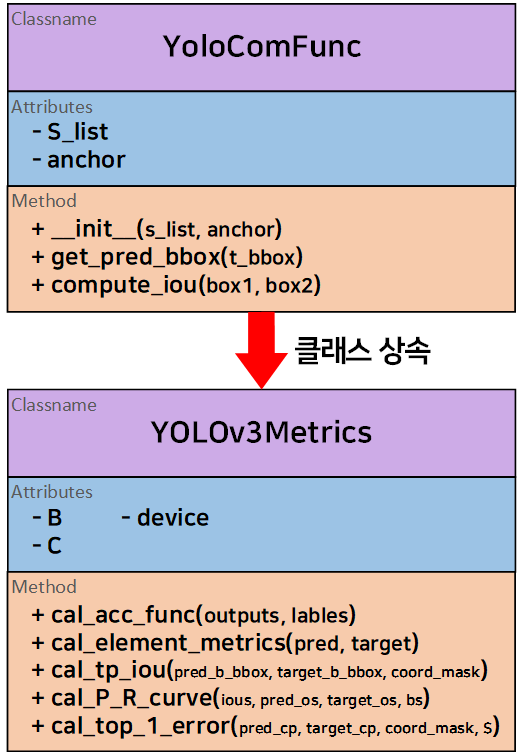
아무튼 기저 함수가 분기가 됬으니 클래스 상속 관계가 형성되고 이를 클래스 다이어그램으로 표현하면 아래와 같다.
4. Yolov3Metrics 코드
전체 코드를 첨부한 뒤 주요 함수별로 설명을 진행하도록 하겠다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import coco_data #데이터 관리용 py파일
from yolo_util import YoloComFunc #좌표변환, IOU연산 클래스
class YOLOv3Metrics(YoloComFunc):
def __init__(self, B=3, C=80, device='cuda',
anchor=coco_data.anchor_box_list):
super().__init__(anchor=anchor) # 이 anchor 값을 부모 클래스에 전달
self.B = B
self.C = C
self.device = device # 연산에 필요한 변수를 다 GPU로 올려야 함
# 2, 3번 평가지표 계산(mAP, Recall에 mean처리한 값)
def cal_P_R_curve(self, ious, pred_os, target_os, bs):
# pred_os의 shape = #[batch_size, S, S, B]
ious = ious.reshape(bs, -1) #[batch_size, S*S*B]
pred_os = pred_os.reshape(bs, -1) #[batch_size, S*S*B]
target_os = target_os.reshape(bs, -1) #[batch_size, S*S*B]
iou_ths = torch.linspace(0.5, 0.95, 10).to(self.device)
# (10) -> (batch_size, S*S*B, 10)으로 iou확장
ious = ious.unsqueeze(-1).expand(-1, -1, 10)
#iou의 차원을 ious와 같게 만들기
iou_ths = iou_ths.view(1, 1, -1).expand_as(ious)
# true_positives 계산 (batch_size, S*S*B, 10)
TP = (ious >= iou_ths).float()
# 각 IoU 임계값에 대해 정렬 수행
s_indices = torch.argsort(-pred_os, dim=-1) #(batch_size, S*S*B)
s_indices = s_indices.unsqueeze(-1).expand_as(TP) #(batch_size, S*S*B, 10)
# 정렬된 신뢰도값으로 True Positive를 정렬 후 차원 축소
s_TP = torch.gather(TP, 1, s_indices)
# 누적합 계산 및 Precision / Recall 계산
tp_cumsum = torch.cumsum(s_TP, dim=1) # S*S*B 차원에서 누적합 계산 -> (batch_size, S*S*B, 10)
precision = tp_cumsum / (torch.arange(tp_cumsum.size(1)).to(self.device).float() + 1).view(1, -1, 1)
recall = tp_cumsum / (target_os.view(bs, -1).sum(dim=-1, keepdim=True).unsqueeze(-1) + 1e-16)
# mAP 계산
mAP = torch.trapz(precision, recall, dim=1).mean()
m_recall = recall.mean()
# recall은 그냥 평균값을 내서 보냄
return mAP, m_recall
# 1번 평가지표 : True Positive에 대한 IOU
def cal_tp_iou(self, pred_b_bbox, target_b_bbox, coord_mask):
ious = self.compute_iou(pred_b_bbox, target_b_bbox)
# 전체 IOU 항목 중 True Positive 항목만 필터링
TP_ious = ious[coord_mask]
return ious, TP_ious.mean()
# 4번 평가지표 : top-1 error
def cal_top_1_error(self, pred_cp, target_cp, coord_mask, S):
# 객체 존재지역을 [batch_size, S*S*B] 차원으로 재정렬
coord_mask = coord_mask.reshape(-1, S*S*self.B)
#[batch_size, S, S, B, C] -> [batch_size, S*S*B, C]
pred_cp = pred_cp.reshape(-1, S*S*self.B, self.C)
target_cp = target_cp.reshape(-1, S*S*self.B, self.C)
# Softmax 적용 -> class 차원인 C항목에 적용함
pred_cp = F.softmax(pred_cp, dim=-1)
# Class 확률 정보에서 가장 높은 값을 갖는 idx 정보 추출
pred_cls = torch.argmax(pred_cp, dim=-1)
target_cls = torch.argmax(target_cp, dim=-1)
# 객체가 존재하는 지역으로 필터링 수행
f_pred_cls = pred_cls[coord_mask]
f_target_cls = target_cls[coord_mask]
# top-1_error 연산
top1_error = (~f_pred_cls.eq(f_target_cls))
return top1_error.float().mean()
# 원소값 기준으로 평가지표를 연산하는 함수
def cal_element_metrics(self, pred, target):
# Assert 구문을 활용하여 grid cell의 크기가 동일한지 확인
assert pred.size(1) == target.size(1), "데이터 정렬 오류"
# batch_size, S의 크기 확인
bs, S = pred.size(0), pred.size(1)
# [batch_size, S, S, B*(C+5)]-> [batch_size, S, S, B, (C+5)]
pred = pred.view(bs, S, S, self.B, 5 + self.C)
target = target.view(bs, S, S, self.B, 5 + self.C)
# tx, ty, OS(objectness score), 항목에 sigmoid 적용
pred[..., :2] = torch.sigmoid(pred[..., :2]) # t_x, t_y
pred[..., 4] = torch.sigmoid(pred[..., 4]) # OS
# bbox, os, cp로 데이터 분해
pred_t_bbox = pred[..., :4] #[batch_size, S, S, B, 4]
target_t_bbox = target[..., :4] #[batch_size, S, S, B, 4]
pred_os = pred[..., 4] #[batch_size, S, S, B]
target_os = target[..., 4] #[batch_size, S, S, B]
pred_cp = pred[..., 5:] #[batch_size, S, S, B, C]
target_cp = target[..., 5:] #[batch_size, S, S, B, C]
# obj 정보로 마스크 필터 생성하기
coord_mask = target_os > 0 #객체가 있는 지역 -> coord_mask
if coord_mask.sum() == 0: #객체가 아에 없는 예외처리
return torch.tensor([0.0, 0.0, 0.0, 1.0], device=self.device)
noobj_mask = target_os <= 0
# [tx, ty, tw, th] -> [bx, by, bw, bh] 변환 실행
pred_b_bbox = self.get_pred_bbox(pred_t_bbox)
target_b_bbox = self.get_pred_bbox(target_t_bbox)
# 마스크 필터로 target의 bbox 데이터 필터링
# os가 0이면 t_series_bbox가 0인데, 해당 함수를 통과하면
# b_series_bbox가 [grid/s, gird/s, pw, ph]값이 차버리게 됨
target_b_bbox[noobj_mask] = 0
# 1번 평가지표 Ture Positive만의 IOU값 계산
ious, TP_iou = self.cal_tp_iou(pred_b_bbox, target_b_bbox, coord_mask)
# 4번 평가지표 원소 Top-1 Error 계산
top1_err = self.cal_top_1_error(pred_cp, target_cp, coord_mask, S)
# 2, 3번 평가지표 mAP, Recall의 평균값 계산
mAP, m_recall = self.cal_P_R_curve(ious, pred_os, target_os, bs)
#원소 평가지표 4가지를 리턴
element = torch.stack([TP_iou, mAP, m_recall, top1_err], dim= -1)
return element
# mini_batch에 대한 평가지표 산출함수
def cal_acc_func(self, outputs, labels):
# outputs와 labels를 GPU로 이전 + output의 데이터 정렬 수행
self.outputs = [output.to(self.device).permute(0, 2, 3, 1) for output in outputs]
self.labels = [label.to(self.device) for label in labels]
res_metrics = []
# 리스트 내 원소들을 추출한 후 연산 수행
for output, label in zip(self.outputs, self.labels):
# 실제 원소별 평가지표 연산은 `compute_metrics`함수에서 수행
element_metrics = self.cal_element_metrics(output, label)
res_metrics.append(element_metrics)
# 리스트를 텐서로 변환하여 평균 계산
res_metrics = torch.stack(res_metrics)
mean_metrics = res_metrics.mean(dim=0)
cal_res = [mean_metrics[i].item() for i in range(mean_metrics.size(0))]
return cal_res
def metrics_debug():
S_list = coco_data.S_list
outputs, labels = [], []
for S in S_list:
output = torch.rand(1, 255, S, S)
outputs.append(output)
label = torch.rand(1, S, S, 255)
for i in range(3):
label[..., (i*85)+4:(i*85)+85] = torch.randint(0, 2, (1, S, S, 81), dtype=torch.float32)
labels.append(label)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
metrics = YOLOv3Metrics(anchor=coco_data.anchor_box_list, device=device.type)
metric_res = metrics.cal_acc_func(outputs, labels)
iou_score, precision, recall, top1_error = metric_res
print(f"iou_score: {iou_score}")
print(f"precision: {precision}")
print(f"recall: {recall}")
print(f"top1_error: {top1_error}")
if __name__ == '__main__':
metrics_debug()
1) cal_acc_func 함수
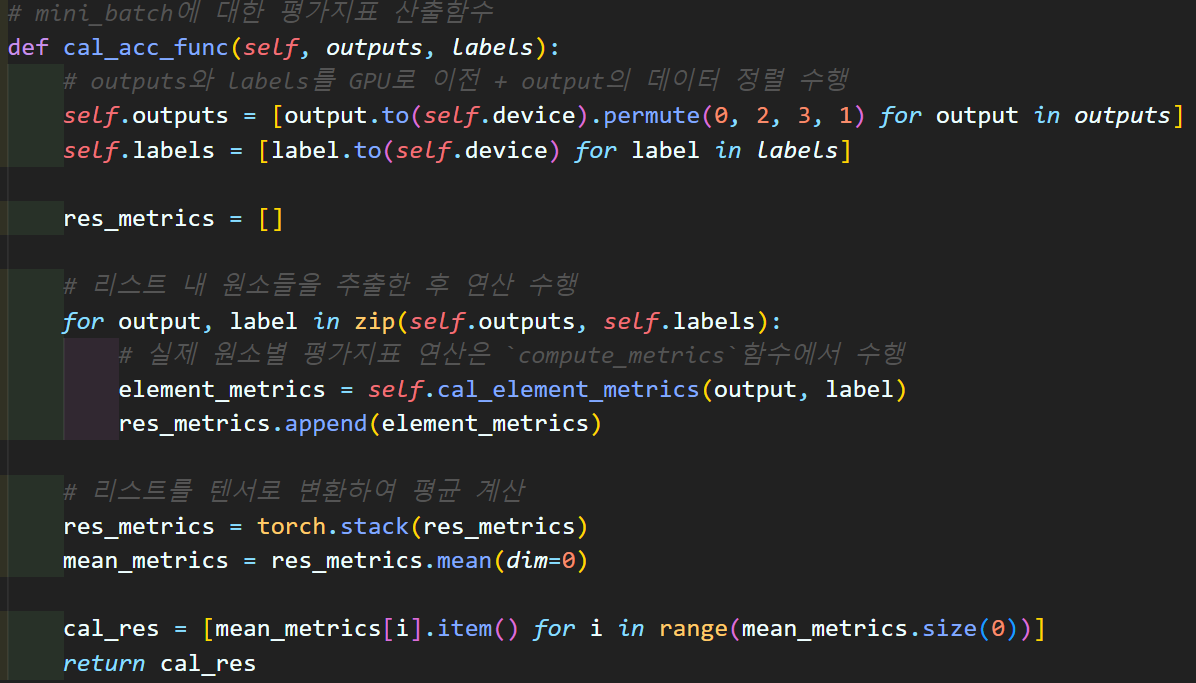
사실상 YOLOv3Metrics 클래스의 __init__메서드를 제외하면 가장 머리에 해당하는 함수라 보면 된다.
모델의 입력 : outputs -> purmute로 매트릭스 순서 재배치
라벨 매트릭스 : Lables
두개의 리스트 데이터를 받아서 원소별로 cal_element_metrics를 수행하고
이 결과값을 반환하는 코드라 보면 된다.
2) cal_element_metrics 함수
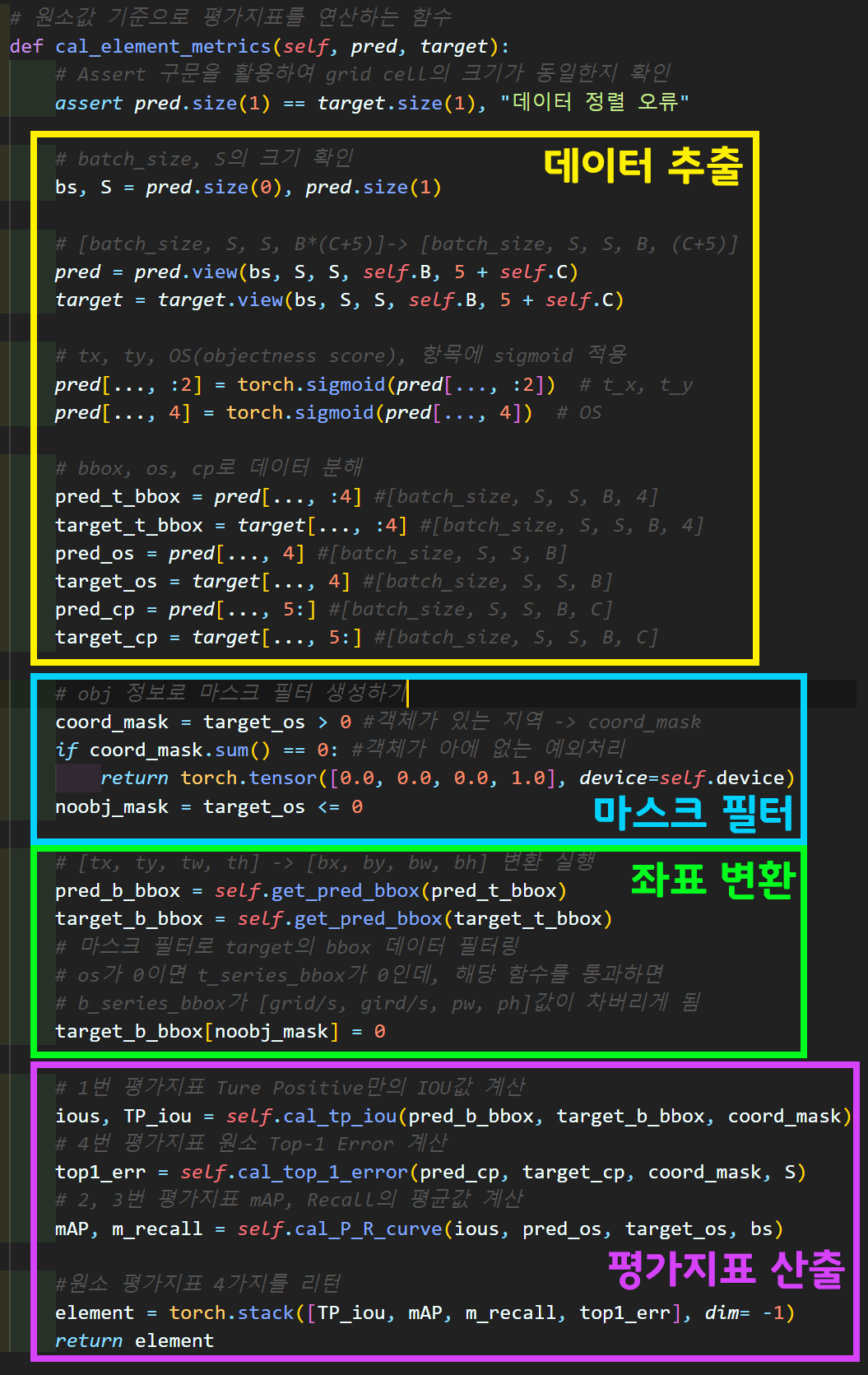
음.. 데이터 추출, 마스크필터, 좌표변환 에 관한 내용들은
인공지능 고급(시각) 강의 예습 - 22. (5) Yolo v3 평가지표 + Train/Val 코드검증 여기를 참조해주길 바란다...
너무 많이 설명해서 이 부분은 넘어가도록 하겠다.
3)
cal_tp_iou,cal_top_1_error함수
평가지표 1번, 평가지표 4번 항목을 산출하는 코드이다.
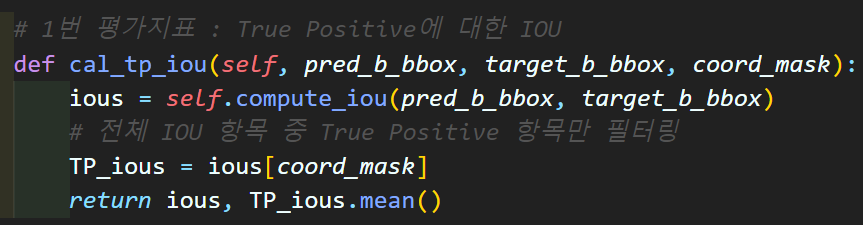
평가지표 1번의 경우 정답지(Labels matrix = Target)에서
객체가 확실히 존재하는 구역의 OS 정보인
target_os로 생성한 mask : coored_mask
이 마스크 필터를 통과한 항목만 추려서
IOU연산을 수행한다.
이렇게 좁은 범위에 해당하는 값 끼리 IOU 계산을 해야
그나마 좀 학습 변화율의 측정이 가능해진다...
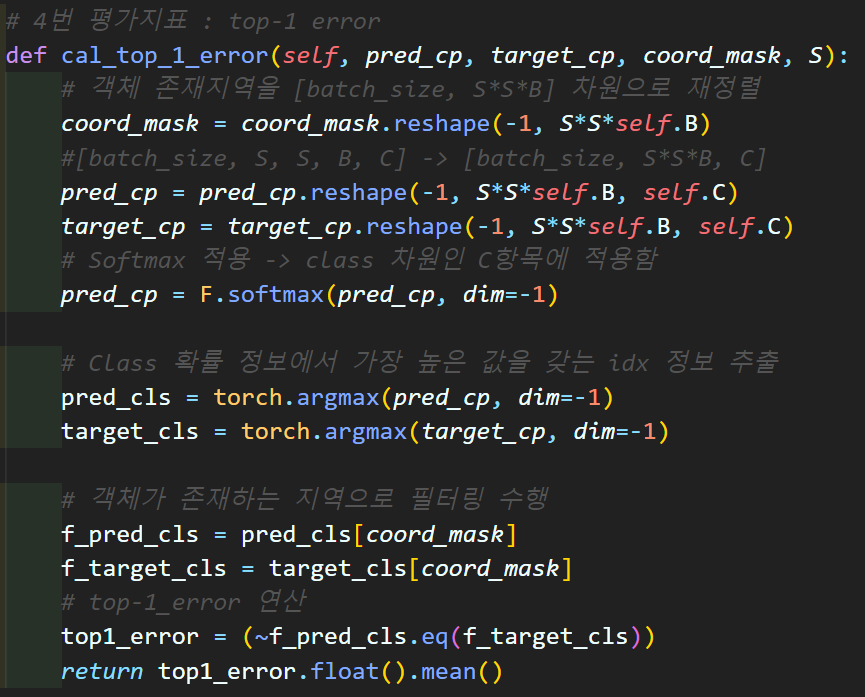
평가지표 4번의 Top-1 error은
mini-batch 내 이미지 별로 class 정보를 산출한 뒤
모델이 예측한 해당 이미지의 class == 정답지 class 비교
이 연산을 수행한다 보면된다.
흔히 Image classification의 Accuracy 산출 과정과 거의 동일하다 보면 된다.
4)
cal_P_R_curve함수
드디어 YOLOv3Metrics 클래스의 가장 중요한 항목이라 볼 수 있는 mAP, 그리고 mAP 연산과정에서 발생하는 Recall의 mean값인 mean-Recall을 산출하는 코드이다.
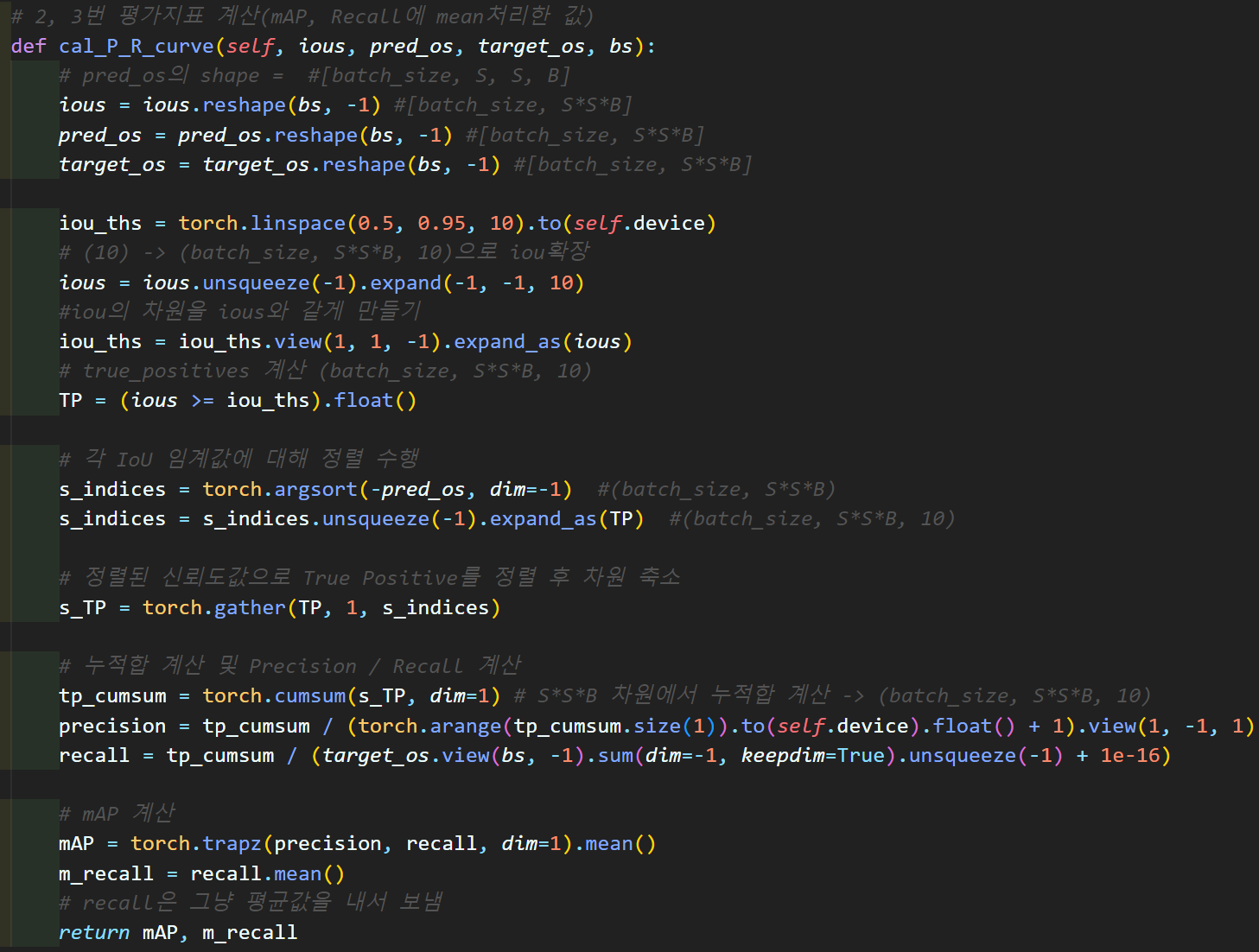
음.. 그런데.. 이건 내가 코드를 아무리 봐도 잘 이해가 안간다.
iou_th를 0.5부터 0.95까지 10개의 step를 만들고
이 스텝별로 마스크필터 10개를 생성한 뒤
스탭별 마스크 필터를 통과한 것들을 각 케이스별
True Positive(정탐)으로 설정한다.
이제 여기서부터 이해되지 않는 부분이
1) 왜 True Positive(정탐) 항목을 Pred OS 지표를 바탕으로 정렬을 수행하는지?
2) 정렬된 True Positive(정탐)항목을 누적합으로 케이스 별 분자값으로 설정한 뒤 분모값(정탐 + 미탐)은 총 예측 개수라는데 저 분모가 어떻게 예측개수가 되는지?
따라서 왜 2)항목 연산이 Precision(정밀도)가 되는지 잘 모르겠으며
3) Recall(재현율)의 분모값 (정탐 + 오탐)은 Target OS정보로 만드는지?
이다.
그래도 마지막코드

이거는 Precision(정밀도)를 Y로
Recall(재현율)를 X로 놓았을 때 그려지는 P-R Curve의 적분이다.
그러니까 사람열받게
 이 상태에서 그냥
이 상태에서 그냥 interpolation을 수행안하고 바로 적분을 때려버린다.
이 mAP값은 mini-Batch에 포함된 한장의 이미지에 대한 결과치이니 이걸 mean한 값은
해당 mini-Batch의 mAP라 보면 된다.
나도 다른사람이 작성한 코드를 mini-Batch별로 연산을 한번에 수행하게끔 코드를 수정한거라
Precision(정밀도), Recall(재현율)를 저렇게 정의하는 이유는 잘 모르겟다...
그리고 mean-Recall은 mAP를 연산하는 과정에서 Recall(재현율)값을 연산하니 이 연산된 값들을 다 평균때린 항목이라 보면 된다.
사실 이렇게 정의해서 사용하는 코드는 없다..
그래도 이 값을 평가지표로 선정한 이유는
대충 내가 예상하는 Recall(재현율)값이 Precision(정밀도)보다는 크게, 그리고 먼저 성능값이 올라가고
Precision(정밀도)도 최종값을 출력했을 때 어느정도 납득 가능할 수준치까지 결과값이 올라가서
이 값을 썻다.. 라고 보면 될 듯하다.
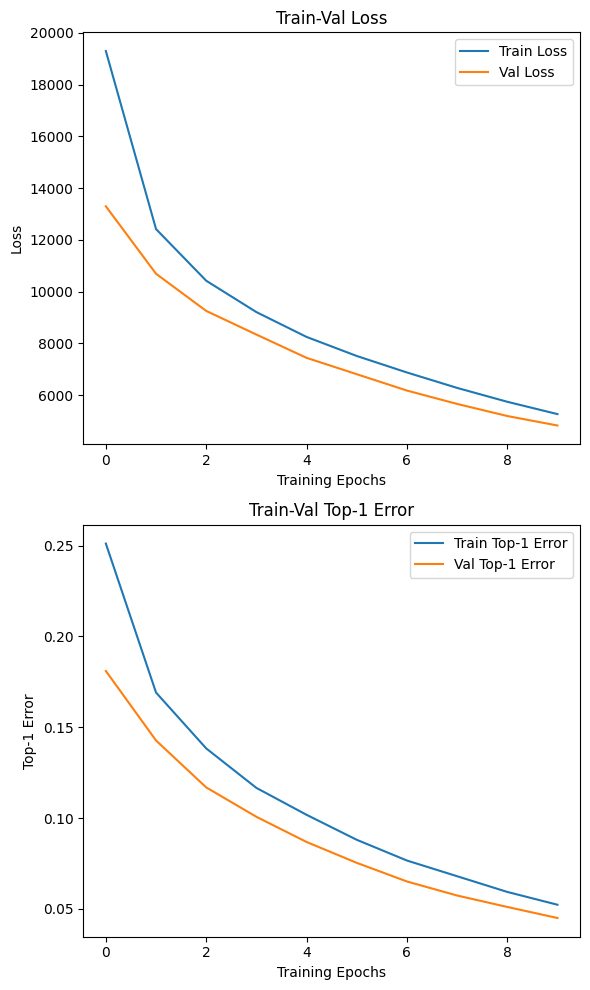
5. 아무튼 결과
이 과정을 다시 수행한 결과값을 첨부하도록 하겠다.
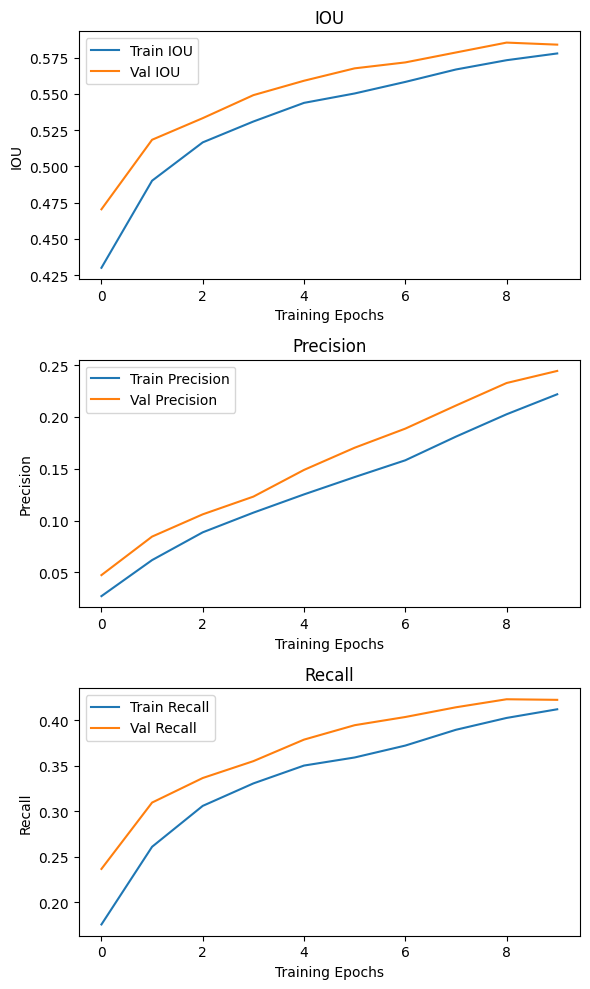

이제 평가지표 코드가 완성된 듯 하다...
