
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. 작업소개
사실 이 파트는 궂이 할 필요성은 존재하지 않으나,
그동안 필자를 괴롭혔던 사안에 관하여 그 의구심을 해결하기 위해
작성한 코드라 보면 된다.
인공지능 고급(시각) 강의 예습 - 22. (10) Yolo v3 : 3차 코드 검증 - 평가지표 이 포스트를 작성하면서
모든 코드에 대한 검증이 완료되었고 코드 디버깅을 완수했으며,
어떠한 위험인자가 내포되어 있는지도 다 해석했다.. 라고 볼 수 있다
P-R curve는 이해를 못했지만
이제 필자를 괴롭혀온 의구심은 아래 그림으로 표현할 수 있다.
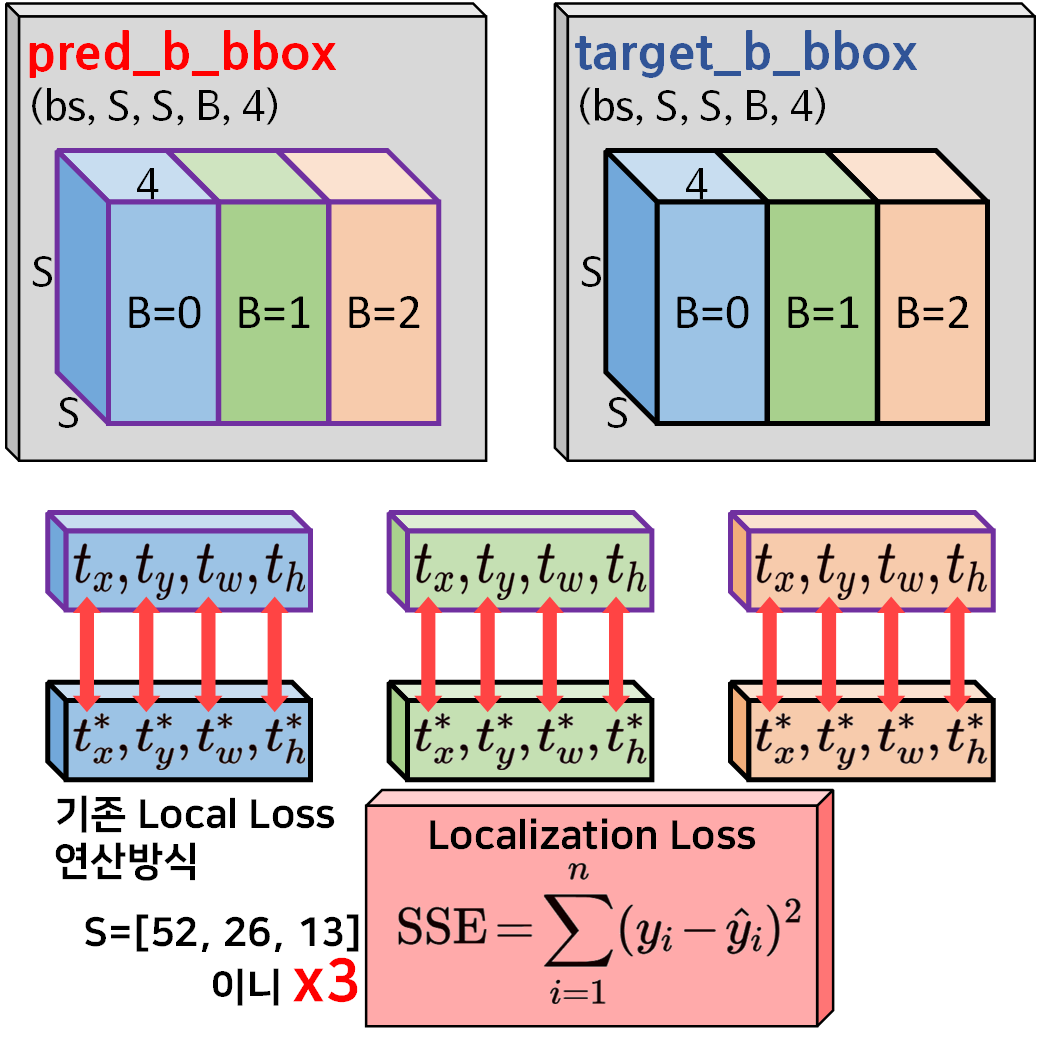
기존의 위치 손실 (Localization Loss)을 계산하는 방식은 위 사진처럼 도식화를 할 수 있다.
이 방식은 모든 예측값과 모든 정답값에 대하여 Local Loss를 연산하기에
신뢰도 손실(Confidence Loss), 분류 손실(Classification Loss) 이 나머지 손실지표와 합산할 때 아무래도 위치 손실 (Localization Loss)의 가중치가 쏠리고, 비효율적이라는 생각이 있었다.
그래서 다른 깃허브 Loss 연산과정의 코드를 찾아보니
아래의 방법론이 있어 소개하고자 한다.
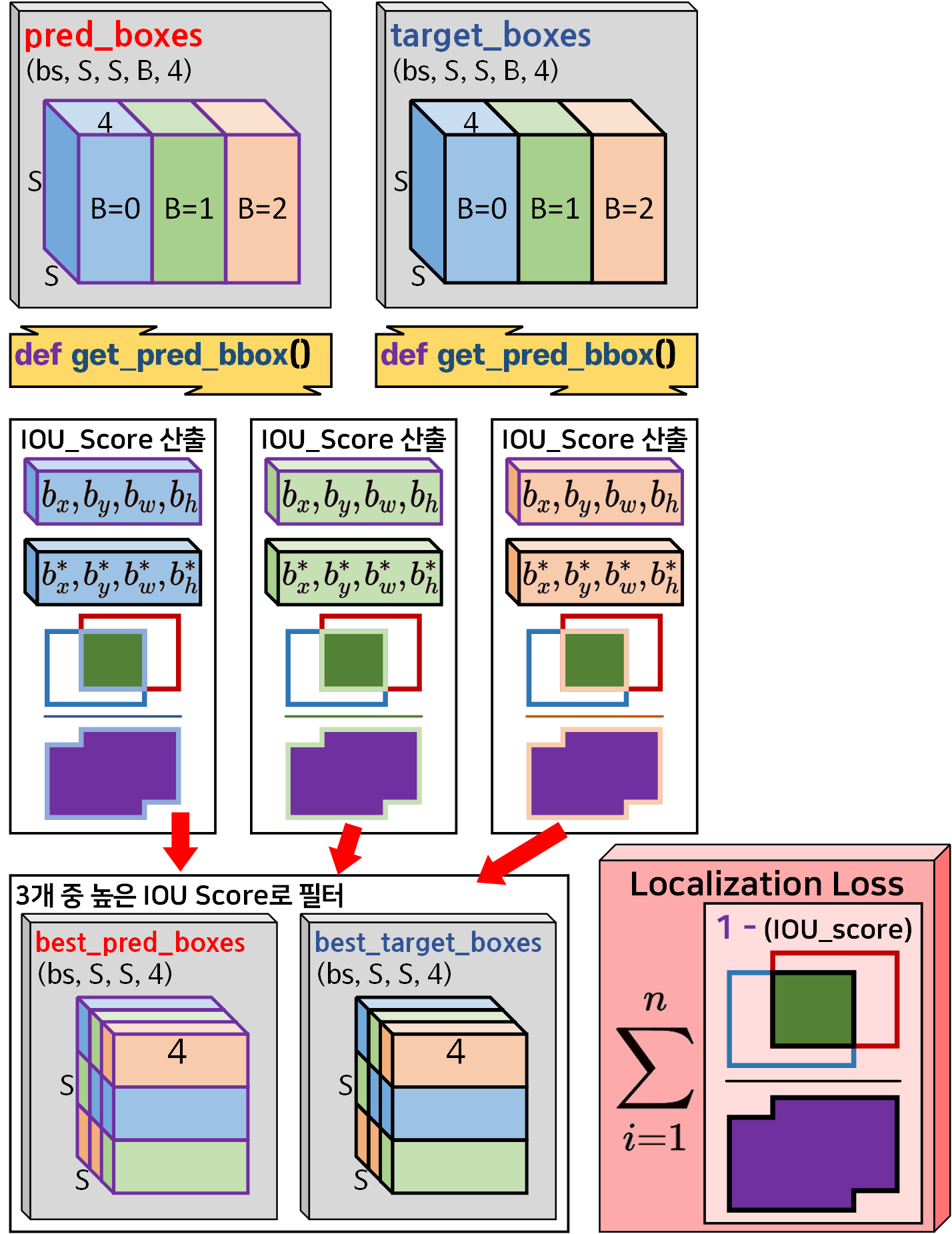 그림으로 표현하면 위와 같다.
그림으로 표현하면 위와 같다.
과정을 나열하자면
1) pred_boxes, target_boxes의 좌표변환(t_serise -> b_series)
2) 좌표변환 후 IOU_score를 계산 -> 3개 중 가장 높은 IOU_score를 갖는 항목을 인덱싱
3) 인덱싱한 결과치로 필터링된 best_pred_boxes, best_target_boxes 두개의 Tensor 추출
4) 추출된 Tensor의 좌표정보로 IOU산출 -> 1-IOU 값을 합산해 이를 위치 손실 (Localization Loss)로 사용
따라서 CFG 모델 - 전이학습으로 평가를 수행하던 코드를 그대로 사용해서
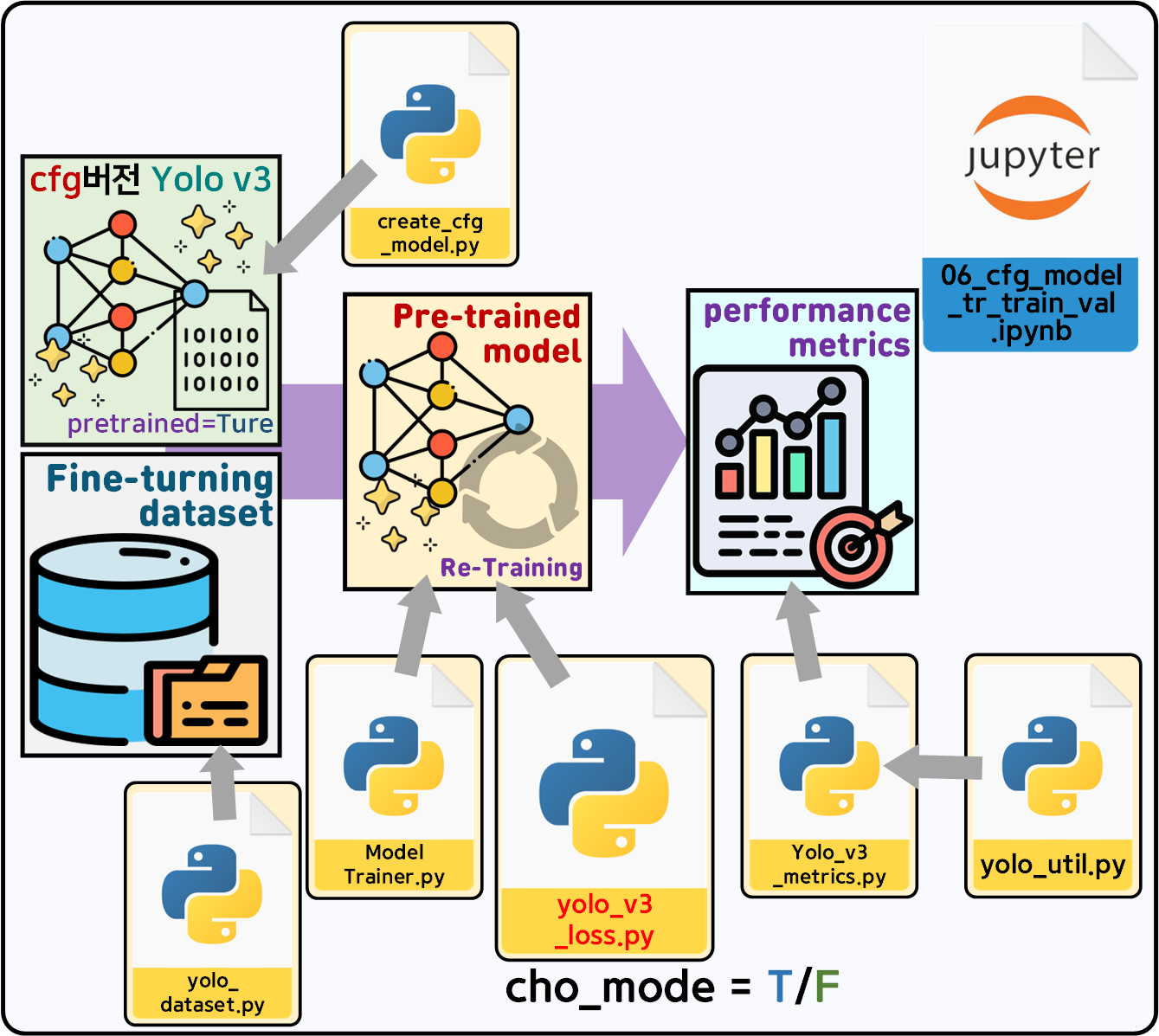 위 과정을 수행 ->
위 과정을 수행 -> yolo_v3_loss.py에 새로이 추가한 위치 손실 (Localization Loss) 계산방식
cho_mode = True : 새롭게 추가한 Local Loss계산
cho_mode = False : 기존 Local Loss 계산방식
2개로 나눠서 코드를 작성하고 그 결과를 비교하고자 한다.
2. yolo_v3_loss.py
우선 전체 코드를 첨부한다
import torch
import torch.nn as nn
import coco_data
from yolo_util import YoloComFunc
class Yolov3Loss(nn.Module):
def __init__(self, B=3, C=80, device='cuda',
cho_mode=False, anchor=coco_data.anchor_box_list):
super(Yolov3Loss, self).__init__()
# self.S = S # 그리드셀의 단위(52, 26, 13)
self.B = B # 이 값은 Anchor box의 개수로 인자 변환
self.C = C # class종류(Coco 데이터 기준 80)
self.lambda_coord = 5 # 실험적으로 구한 계수값
self.lambda_noobj = 0.5 # 실험적으로 구한 계수값
# Objectness loss 및 Classification Loss는 SSE에서 BCE로 변경
self.bce_loss = nn.BCELoss(reduction='sum')
self.device = device # 연산에 필요한 변수를 다 GPU로 올려야 함
self.cho_mode = cho_mode
self.util_func = YoloComFunc(anchor=anchor)
def forward(self, outputs, labels):
# outputs, labels가 리스트 데이터
tot_loss = 0
# outputs와 labels를 GPU로 이전 + output data는 차원정렬 수행
self.outputs = [output.to(self.device).permute(0, 2, 3, 1) for output in outputs]
self.labels = [label.to(self.device) for label in labels]
for output, label in zip(self.outputs, self.labels):
element_loss = self.cal_loss(output, label)
tot_loss += element_loss
return tot_loss
def cal_iou_base_loss(self, pred_boxes, target_boxes, coord_mask, bs, S):
pred_b_bbox = self.util_func.get_pred_bbox(pred_boxes)
target_b_bbox = self.util_func.get_pred_bbox(target_boxes)
# (bs, S, S, B, 4), (bs, S, S, B, 4)
# pred_b_bbox[noobj_mask] = 0 # 유효하지 않은 타겟 제거
# target_b_bbox[noobj_mask] = 0 # 유효하지 않은 타겟 제거
#pred_b_bbox, target_b_bbox의 원소는 [bx, by, bw, bh] -> 모두 0보다 큰 값임을 확인
# 음수 값이 없는지 확인
if (pred_b_bbox < 0).any() or (target_b_bbox < 0).any():
print("bbox 텐서에 음수 값이 포함되어 있습니다")
return torch.tensor(0.0, device=self.device)
# IoU 계산 (형태: (bs, S, S, B))
ious = self.util_func.compute_iou(pred_b_bbox, target_b_bbox)
# B(anchorbox idx) 결과치로부터 가장 좋은 값 1개만 선택하기
best_iou_idx = ious.argmax(dim=-1, keepdim=True) # 형태: (bs, S, S, 1)
conf_mask = torch.gather(coord_mask, 3, best_iou_idx)
# gather를 위한 인덱스 준비 #(bs, S, S, 1) -> (bs, S, S, 1, 4)
best_iou_idx = best_iou_idx.unsqueeze(-1).expand(bs, S, S, 1, 4)
# 가장 좋은 예측 및 타겟 박스 추출 #형태: (bs, S, S, 1, 4)
best_p_bbox = torch.gather(pred_b_bbox, 3, best_iou_idx)
best_t_bbox = torch.gather(target_b_bbox, 3, best_iou_idx)
# 불필요한 차원 제거 #형태: (bs, S, S, 4)
best_p_bbox = best_p_bbox.squeeze(3)
best_t_bbox = best_t_bbox.squeeze(3)
conf_mask = conf_mask.expand(bs, S, S, 4)
# 선택된 박스들에 음수 값이 없는지 확인
if (best_p_bbox < 0).any() or (best_t_bbox < 0).any():
print("선택된 박스들에 음수 값이 포함되어 있습니다")
return torch.tensor(0.0, device=self.device)
# 선택된 박스들로 IoU 계산
C_ious = self.util_func.compute_iou(best_p_bbox[conf_mask], best_t_bbox[conf_mask])
coord_loss = (1.0 - C_ious).sum() # 필터링한 C_ious 값을 사용하여 손실 계산
return coord_loss
def cal_loss(self, predictions, target):
# Assert 구문을 활용하여 grid cell의 크기가 동일한지 확인
assert predictions.size(1) == predictions.size(2), "그리드셀 차원이 맞지 않음"
bs = predictions.size(0) # Batch_size의 사이즈 정보를 추출
S = predictions.size(2) # grid cell의 개수 정보를 추출
# [Batch_size, S, S, (5 + C) * B] -> [Batch_size, S, S, B, (5 + C)]로 변환
predictions = predictions.view(bs, S, S, self.B, 5 + self.C)
target = target.view(bs, S, S, self.B, 5 + self.C)
# 2) BBox좌표, OS, CS 정보 추출하여 재배치
pred_boxes = predictions[..., :4] # [batch_size, S, S, B, 4]
# target_boxex의 추출된 정보는 [sigtx, sig, ty, tw, th]이니
# 이것에 맞게 pred_boxe의 [tx, ty]도 [sigmoid(tx), sigmoid(ty)]처리
pred_boxes[..., :2] = torch.sigmoid(pred_boxes[..., :2])
# pred_boxes[..., :2] = torch.clamp(pred_boxes[..., :2], self.e, 1-self.e)
target_boxes = target[..., :4] # [batch_size, S, S, B, 4]
# Objectness Score에 sigmoid 적용 -> 이게 Yolo v3의 핵심임
pred_obj = torch.sigmoid(predictions[..., 4])
target_obj = target[..., 4] # [batch_size, S, S, B]
# Class scores에 sigmoid 적용 -> 이게 Yolo v3의 핵심임
pred_class = torch.sigmoid(predictions[..., 5:])
target_class = target[..., 5:] # [batch_size, S, S, B, C]
# 3) 마스크 필터 생성
coord_mask = target_obj > 0 # [batch_size, S, S, B]
noobj_mask = target_obj <= 0 # [batch_size, S, S, B]
# 예외처리 : 객체가 아에 없는 이미지에 대한
if coord_mask.sum() == 0 and noobj_mask.sum() == 0:
return torch.tensor(0.0, requires_grad=True)
# 4) 마스크 필터를 적용해 Bbox의 데이터 필터링
# unsqueeze를 이용해 [batch_size, S, S, B] -> [batch_size, S, S, B, 1]
# 이후 expand_as를 이용해 [batch_size, S, S, B, 4]
# expand_as는 expand랑 거의 기능이 같다
coord_mask_box = coord_mask.unsqueeze(-1).expand_as(target_boxes)
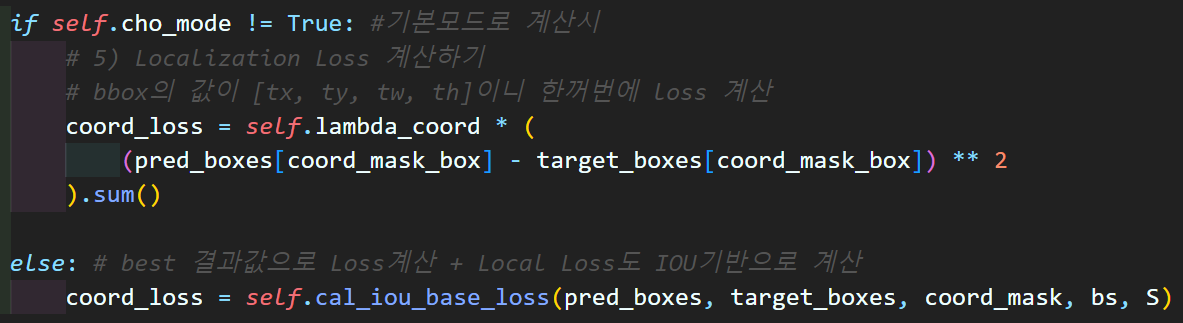
if self.cho_mode != True: #기본모드로 계산시
# 5) Localization Loss 계산하기
# bbox의 값이 [tx, ty, tw, th]이니 한꺼번에 loss 계산
coord_loss = self.lambda_coord * (
(pred_boxes[coord_mask_box] - target_boxes[coord_mask_box]) ** 2
).sum()
else: # best 결과값으로 Loss계산 + Local Loss도 IOU기반으로 계산
coord_loss = self.cal_iou_base_loss(pred_boxes, target_boxes, coord_mask, bs, S)
# 6) OS(objectness Score)의 마스크 필터를 활용한 필터링
# 7) Objectness Loss 계산하기
obj_loss = self.bce_loss(pred_obj[coord_mask], target_obj[coord_mask])
cal = self.bce_loss(pred_obj[noobj_mask], target_obj[noobj_mask])
noobj_loss = self.lambda_noobj * cal
# 8) CP(Class Probabilities)에 대한 필터링 작업
# 9) Classification Loss 계산하기
# coord_mask는 자동으로 broadcasting이 되어서 expand_as를 안써도 된다.
class_loss = self.bce_loss(pred_class[coord_mask], target_class[coord_mask])
element_loss = coord_loss + obj_loss + noobj_loss + class_loss
return element_loss
def loss_debug():
# 디버그용 데이터 생성하기
S_list = coco_data.S_list
outputs, targets = [], []
for S in S_list:
output = torch.rand(1, 255, S, S)
outputs.append(output)
target = torch.rand(1, S, S, 255)
for i in range(3):
target[..., (i*85)+4:(i*85)+85] = torch.randint(0, 2, (1, S, S, 81), dtype=torch.float32)
targets.append(target)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
yolov3_loss = Yolov3Loss(B=3, C=80, device=device.type, cal_mode=False)
loss = yolov3_loss(outputs, targets)
print(f"Loss: {loss.item()}")
if __name__ == '__main__':
loss_debug()여기서 추가된 부분은 아래의 이 코드 부분이라 보면 된다.
위치 손실 (Localization Loss)를 계산하는 방법이 2개가 되었으니 그 중 하나를 선택하는 코드와
새롭게 추가한 Local Loss 연산방식은 과정이 복잡하기에 별도의 함수로 해당 항목만 분리했다.
2.1 torch.gather
위 데이터를 선별하는 과정에서 제일 난해한 함수가 하나 있는데
그것은 torch.gather() 항목이다.
먼저 영상을 시청하고 필자의 설명도 확인해주길 바란다.

이 함수를 쓰려면 조건이
1) input의 차원과 index은 같아야 한다.
2) 그리고 input의 차원요소는 무조건 index의 차원요소보다 많아야 한다.
1) 2)조건을 만족하는지 확인하려면 아래와 같이 코드로 표현하면 될거 같다
if input_tensor.dim() == index_tensor.dim(): #차원 개수가 같은지 확인
for i in range(input_tensor.dim()):
if input_tensor.size(i) >= index_tensor.size(i):
print("조건 만족")
else:
print("torch.gather실행불가")그럼 이제 이 조건을 만족하는 코드를 작성해서
어떻게 인덱싱을 수행하여 필터링을 하는지 확인해보자
일단 가볍게
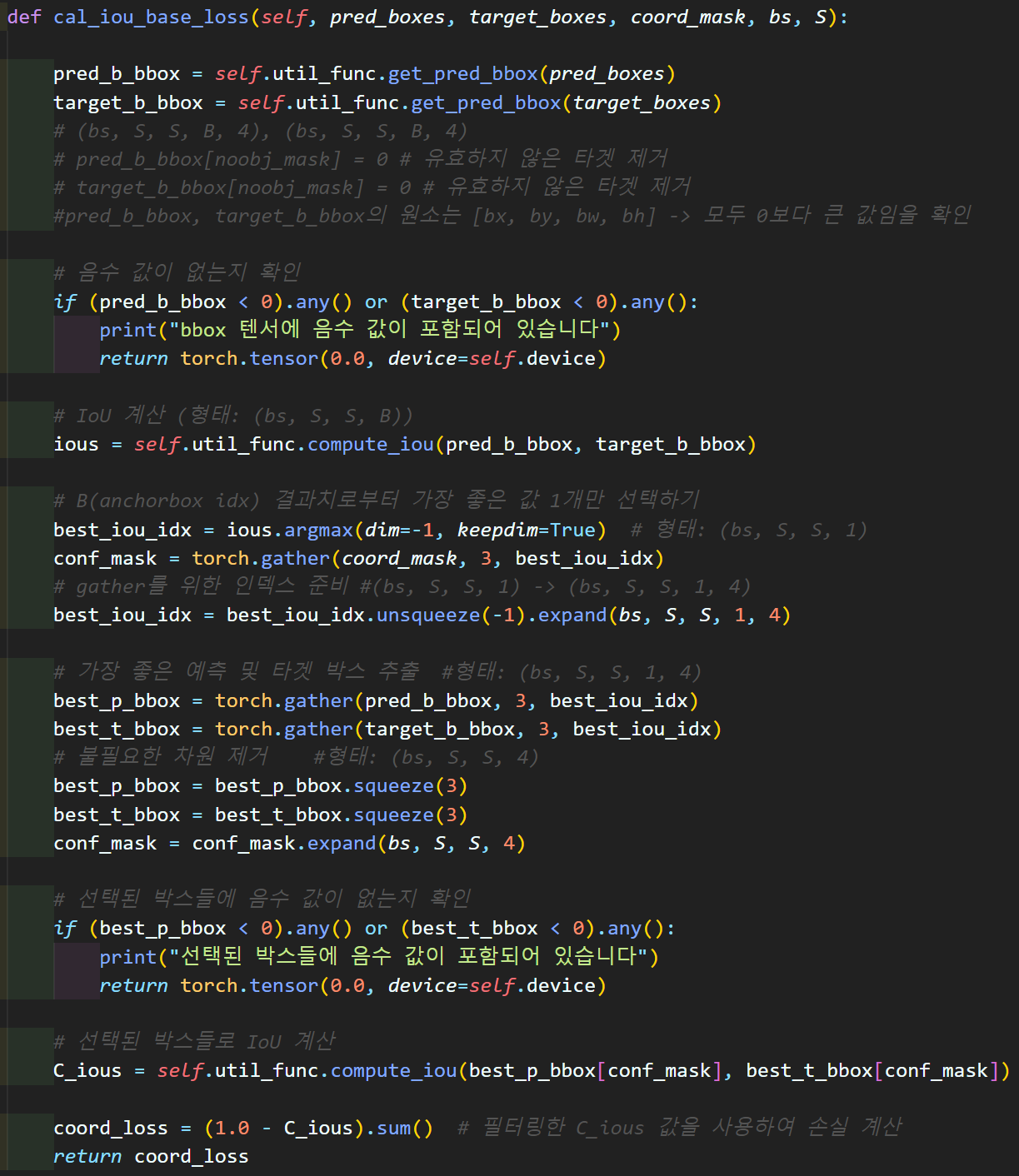
S=4, B=3, bs=1로 구성한
target_b_bbox = torch.rand((bs,S, S, B, 4)).round(decimals=2)
pred_b_bbox = torch.rand((bs,S, S, B, 4)).round(decimals=2)두게의 Tensor 자료형이 있다 생각해보자 (dim=5)
일단 이것 중 하나의 형상을 표현하면 아래의 그림과 같아진다.
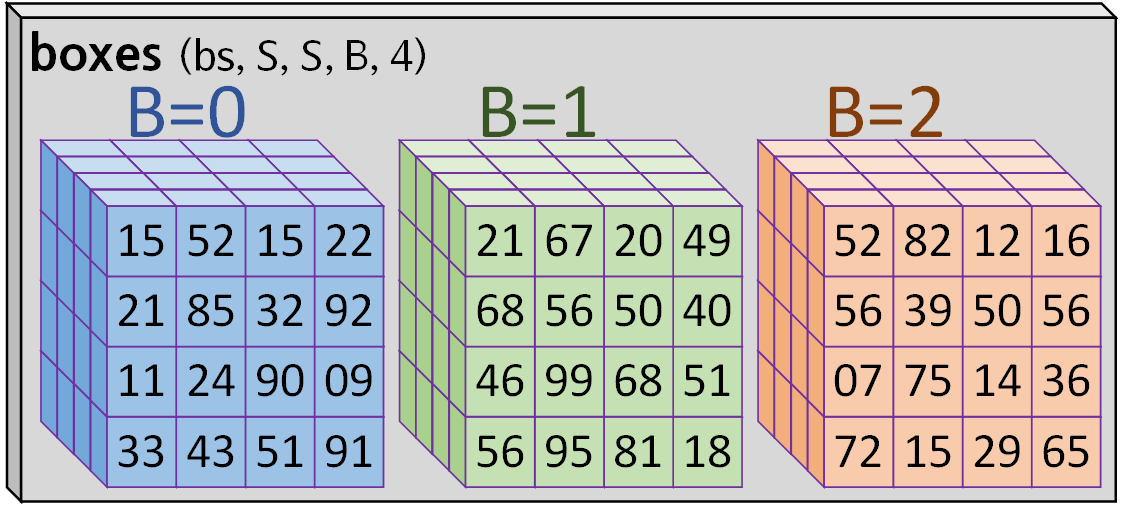
이제 아래의 IOU연산 -> 가장 높은 iou 선택(B에 대하여)
ious = util_func.compute_iou(pred_b_bbox, target_b_bbox)
best_iou_idx = ious.argmax(dim=-1, keepdim=True)여기까지 수행하면 best_iou_idx의 shape는
이 출력된다. (dim=4)
이 때의 차원은 4차원이나 1개 차원을 늘려주고 목표한 B에 대해서만 인덱싱을 수행할 것이니
이렇게 만들어줘야 한다.
best_iou_idx = best_iou_idx.unsqueeze(-1).expand(bs, S, S, 1, 4)이제 torch.gather를 수행해보자
# 가장 좋은 예측 및 타겟 박스 추출 #형태: (bs, S, S, 1, 4)
best_pred_boxes = torch.gather(pred_b_bbox, 3, best_iou_idx)
best_target_boxes = torch.gather(target_b_bbox, 3, best_iou_idx)여기서 dim=3 인자는 0, 1, 2, 3, 4 이렇게 축의 번호를 매기니
dim = B 라 보면 된다.
수행 결과를 그림으로 보면 아래와 같다.
이게 다차원 Tensor 자료형에서 특정 idx 항목만 찾아내서 추출하는 기능을 지원하는 torch.gather 함수의 사용법이다.
마지막에는 깔끔하게 B 축이 1 되었으니
best_pred_boxes = best_pred_boxes.squeeze(3)
best_target_boxes = best_target_boxes.squeeze(3)이렇게 B 축의 차원축소를 수행으로 마무리를 하는 것이다.
3. 06_cfg_model_tr_train_val
https://github.com/tbvjvsladla/yolo_v3_pytorch
코드는 업로드 하였지만 예의바르게 첨부하도록 하겠다.
import torch
from yolo_dataset import CustomDataset #커스텀 데이터셋 코드
from ModelTrainer import ModelTrainer #train / val 코드
import create_cfg_model as cm # cfg 모델로 Re-training
from yolo_v3_loss import Yolov3Loss, loss_debug
from yolo_v3_metrics import YOLOv3Metrics, metrics_debug #평가지표 코드
from tqdm import tqdm# CFG모델을 불러와서 Pre-TrainModel 인스턴스화
cfg_file = "yolov3.cfg"
weight_file = "YOLOv3-416.weights"
# CFG 정보 파싱
blocks = cm.parse_cfg(cfg_file)
# CFG 모델 인스턴스화
cfg_model = cm.Yolo_v3_cfg(blocks)
# pre-trained weights로 CFG 모델 초기화
cm.load_weights(cfg_model, weight_file)
# cfg용 anchorbox리스트
cfg_anchor_box_list = cm.convert_anchor(cfg_file)# coco데이터셋의 메인 루트 디렉토리
root_dir = './COCO dataset'
# load_anno=val2014 -> 'instance_val2014.json'참조 + `val2014`img폴더 참조
train_dataset = CustomDataset(root=root_dir, load_anno='val2017',
anchor=cfg_anchor_box_list)
test_dataset = CustomDataset(root=root_dir, load_anno='val2017',
anchor=cfg_anchor_box_list)
print(f"훈련용 : {train_dataset}, \n 검증용 : {test_dataset}")from torchvision.transforms import v2
coco_val = [[0.4701, 0.4468, 0.4076], [0.2379, 0.2329, 0.2362]]
# 데이터셋 전처리 방법론 정의
transforamtion = v2.Compose([
v2.Resize((416, 416)), #이미지 크기를 416, 416로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=coco_val[0], std=coco_val[1]) #데이터셋 정규화
])# 데이터셋 전처리 방법론 적용
train_dataset.transform = transforamtion
test_dataset.transform = transforamtionfrom torch.utils.data import DataLoader
BATCH_SIZE = 32
# 전처리가 완료된 데이터셋의 데이터로더 전환
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# CFG 모델 GPU로 이전
cfg_model.to(device)
print()import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
# 손실 함수 설정 (YOLOv3 손실 함수)
# 여기서 cho_mode=True 이면 예측 값을 필터링해서 IOU값으로 Localization Loss연산 수행
# cho_mode=False 이면 기존 방식으로 모든 예측값에 대하여 Localization Loss연산 수행
criterion = Yolov3Loss(device=device.type, cho_mode=True, anchor=cfg_anchor_box_list)
# 옵티마이저는 Pretrain model의 전이학습이기에 매우 작은 learning rate로 설정
optimizer = optim.SGD(cfg_model.parameters(), lr=1e-6, momentum=0.9)
# 스케줄러 설정 (50 에폭 기준 Cosine Annealing)
scheduler = CosineAnnealingLR(optimizer, T_max=20)# Train / eval(Val)을 수행하는 클래스 인스턴스화
epoch_step = 1
trainer = ModelTrainer(epoch_step=epoch_step, device=device.type)
metrics = YOLOv3Metrics(anchor=cfg_anchor_box_list, device=device.type)# 학습과 검증 손실 및 정확도를 저장할 리스트
his_loss = []
his_KPI = []
num_epoch = 10
for epoch in range(num_epoch):
# 훈련 손실과 훈련 성과지표를 반환 받습니다.
train_loss, train_KPI = trainer.model_train(cfg_model, train_loader,
criterion, optimizer, scheduler,
metrics, epoch)
# 검증 손실과 검증 성과지표를 반환 받습니다.
test_loss, test_KPI = trainer.model_evaluate(cfg_model, test_loader,
criterion, metrics, epoch)
# 손실과 성능지표를 리스트에 저장
his_loss.append((train_loss, test_loss))
his_KPI.append((train_KPI, test_KPI))
# epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"Training loss: {train_loss:.4f}")
print(f"Train KPI[ IOU: {train_KPI[0]:.4f}, "+
f"Precision: {train_KPI[1]:.4f}, "+
f"Recall: {train_KPI[2]:.4f}, "+
f"Top1_err: {train_KPI[3]:.4f} ]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"Test loss: {test_loss:.4f}")
print(f"Test KPI[ IOU: {test_KPI[0]:.4f}, "+
f"Precision: {test_KPI[1]:.4f}, "+
f"Recall: {test_KPI[2]:.4f}, "+
f"Top1_err: {test_KPI[3]:.4f} ]")import numpy as np
import matplotlib.pyplot as plt
#histroy는 [train, test] 순임
#KPI는 [iou, precision, recall, top1_error] 순임
np_his_loss = np.array(his_loss)
np_his_KPI = np.array(his_KPI)
# his_loss에서 손실 데이터 추출
train_loss, val_loss = np_his_loss[..., 0], np_his_loss[..., 1]
# his_KPI에서 각 성능 지표 추출
train_iou, val_iou = np_his_KPI[..., 0, 0], np_his_KPI[..., 1, 0]
train_precision, val_precision = np_his_KPI[..., 0, 1], np_his_KPI[..., 1, 1]
train_recall, val_recall = np_his_KPI[..., 0, 2], np_his_KPI[..., 1, 2]
train_top1_errors, val_top1_errors = np_his_KPI[..., 0, 3], np_his_KPI[..., 1, 3]
# 1x2 로 그래프 그리기
plt.figure(figsize=(6, 10))
# Train-Val Loss
plt.subplot(2, 1, 1)
plt.plot(train_loss, label='Train Loss')
plt.plot(val_loss, label='Val Loss')
plt.xlabel('Training Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Train-Val Loss')
# Train-Val Top-1 Error
plt.subplot(2, 1, 2)
plt.plot(train_top1_errors, label='Train Top-1 Error')
plt.plot(val_top1_errors, label='Val Top-1 Error')
plt.xlabel('Training Epochs')
plt.ylabel('Top-1 Error')
plt.legend()
plt.title('Train-Val Top-1 Error')
plt.tight_layout()
plt.show()
# 1x3로 그래프 그리기
plt.figure(figsize=(6, 10))
# IOU
plt.subplot(3, 1, 1)
plt.plot(train_iou, label='Train IOU')
plt.plot(val_iou, label='Val IOU')
plt.xlabel('Training Epochs')
plt.ylabel('IOU')
plt.legend()
plt.title('IOU')
# Precision
plt.subplot(3, 1, 2)
plt.plot(train_precision, label='Train Precision')
plt.plot(val_precision, label='Val Precision')
plt.xlabel('Training Epochs')
plt.ylabel('Precision')
plt.legend()
plt.title('Precision')
# Recall
plt.subplot(3, 1, 3)
plt.plot(train_recall, label='Train Recall')
plt.plot(val_recall, label='Val Recall')
plt.xlabel('Training Epochs')
plt.ylabel('Recall')
plt.legend()
plt.title('Recall')
plt.tight_layout()
plt.show()4. 결과 비교
결과를 비교하면 아래와 같다.
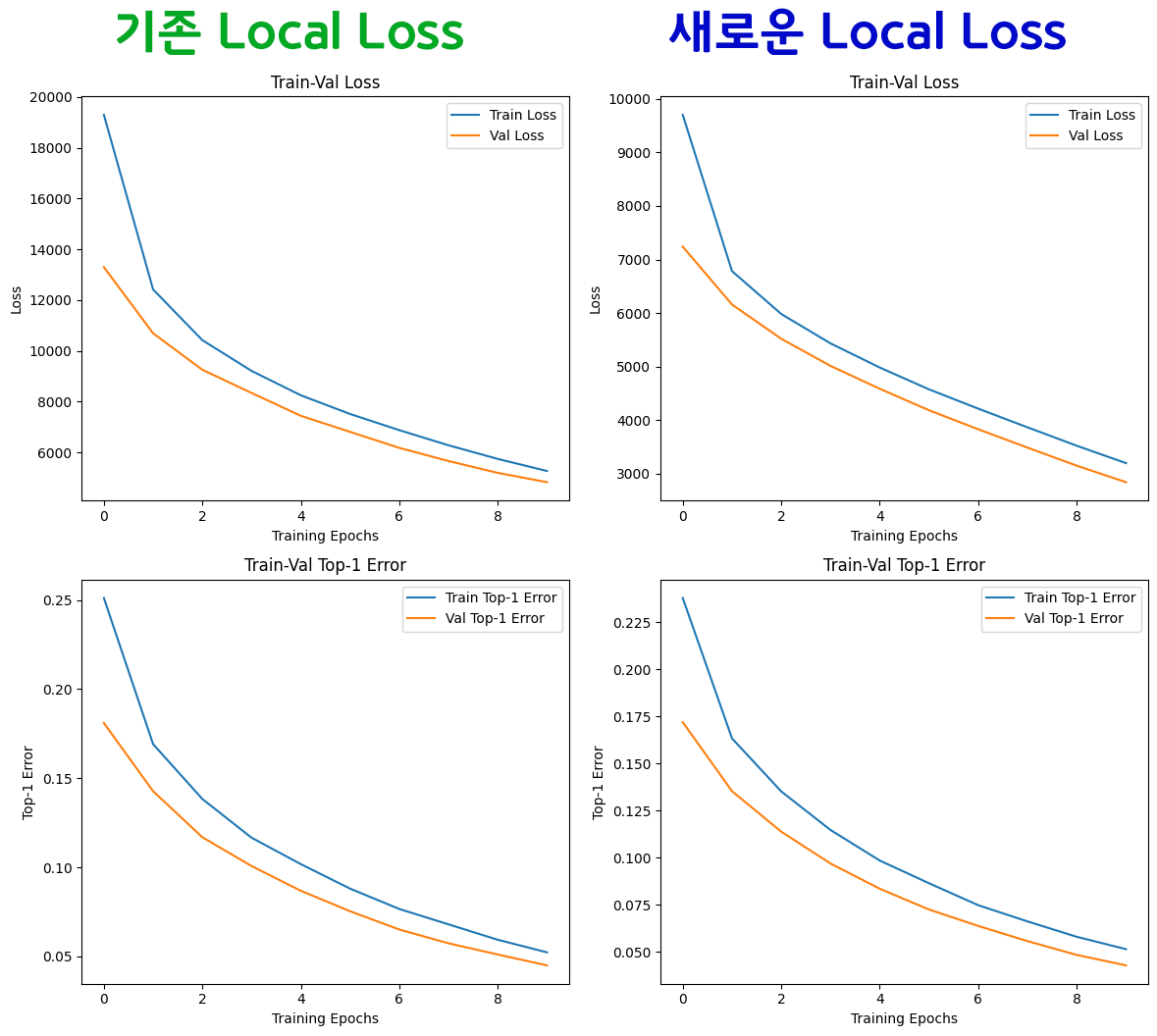
두 그래프를 비교하면 그 양상은 거의 동일하나 차이점이 하나 있다
전체 Loss의 시작이 기존Local Loss는 값이 20,000 부터 시작하지만
새로운Local Loss는 값이 10,000 부터 시작해서
전체 Loss가 절반 정도 줄어든 것을 확인할 수 있다.
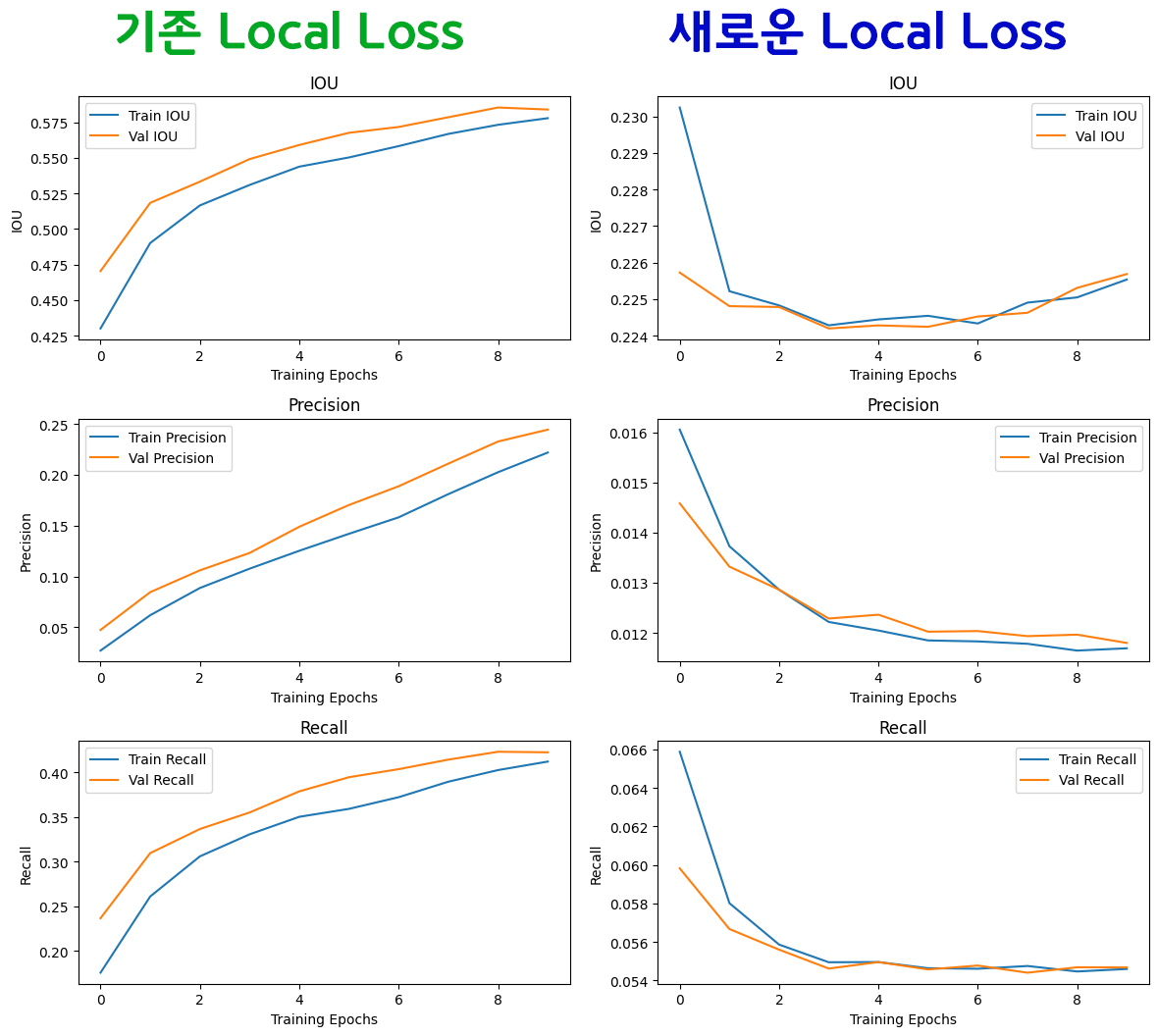 그러나 나머지 성능 결과치까지 뽑아본다면
그러나 나머지 성능 결과치까지 뽑아본다면
음.. 새로운Local Loss연산 방식이 그렇게 썩 좋은 학습결과를 도출하는 것은 아님을 알 수 있다.

드디어 그동안 Yolo v3 코드를 작성하면서 나를 짓누르던 고민이 해소됬다.

기존 방식인 모든 Pred와 Target 에 대한 Local Loss를 연산하는 방식이 더 학습효율이 좋다.
4회에 걸친 모든 코드 검증, 해보고 싶은 내용은
다 해본거 같다.
이제 정말로 마지막이다.
