
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. 업데이트 내역 + 작업목표
인공지능 고급(시각) 강의 예습 - 22. (8) Yolo v3 사전학습모델 + 추론검증에서
 위 사진처럼 코드 검증을 마쳤고 몇가지 자잘한 업데이트를 수행했다.
위 사진처럼 코드 검증을 마쳤고 몇가지 자잘한 업데이트를 수행했다.
 따라서 위 사진처럼 코드검증 / 신규 코드 작성을 수행했고
따라서 위 사진처럼 코드검증 / 신규 코드 작성을 수행했고
이제 두번째로
데이터셋을 생성하는 코드(yolo_dataset.py)를 다시 한번 검증해 보고, 이 검증과정에서
04_k-mean_cluster.ipynb
anchor_box_list.npy 파일 생성 및
연계된 coco_data.py, yolo_v3_metrics.py파일을 다시 사용하게 됫다.
이제 두번째 코드검증을 수행하려 한다.
2. yolo_dataset.py 코드검증 개요
인공지능 고급(시각) 강의 예습 - 22. (4) Yolo v3용 Coco 데이터셋 전처리 에서 포스트하긴 했지만
해당 커스텀 데이터셋의 작성 방식은 좌표변환 과정이 총 3번 발생하기에 어려움이 많았고
코드를 작성하면서도 오류가 있을 것이다
라고 생각되는 부분이 많아서 이번에 각잡고 코드검증을 다시 해보려고 한다.
우선 해당 데이터셋이 기능하는 workflow를 명확하게 이해해야 한다.
이를 먼저 도식화 하도록 하겠다.
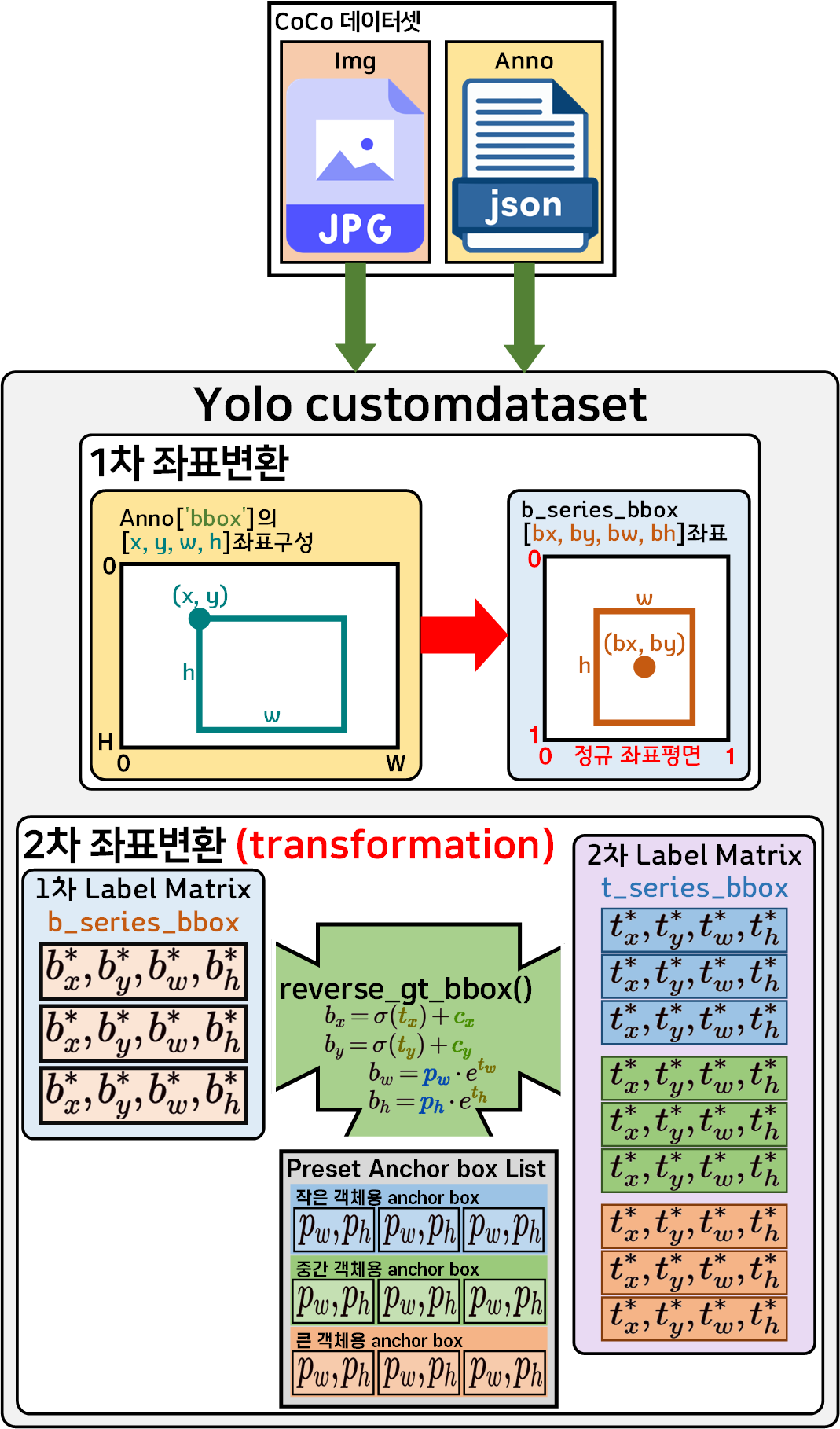 Yolo v3의 입력 요구조건을 맞추기 위한 CustomDataset의 구조는 위 사진처럼
Yolo v3의 입력 요구조건을 맞추기 위한 CustomDataset의 구조는 위 사진처럼
1차 좌표변환 :
Anno bbox 좌표 정규 좌표평면의 b_series_bbox
2차 좌표변환 : transform 메서드가 트리거
b_series_bbox t_serise_bbox로 좌표변환
두번의 좌표변환을 수행한다.
따라서 이 좌표변환이 재대로 수행되는지를 확인하려면
아래의 과정으로 코드검증을 수행해야 한다.
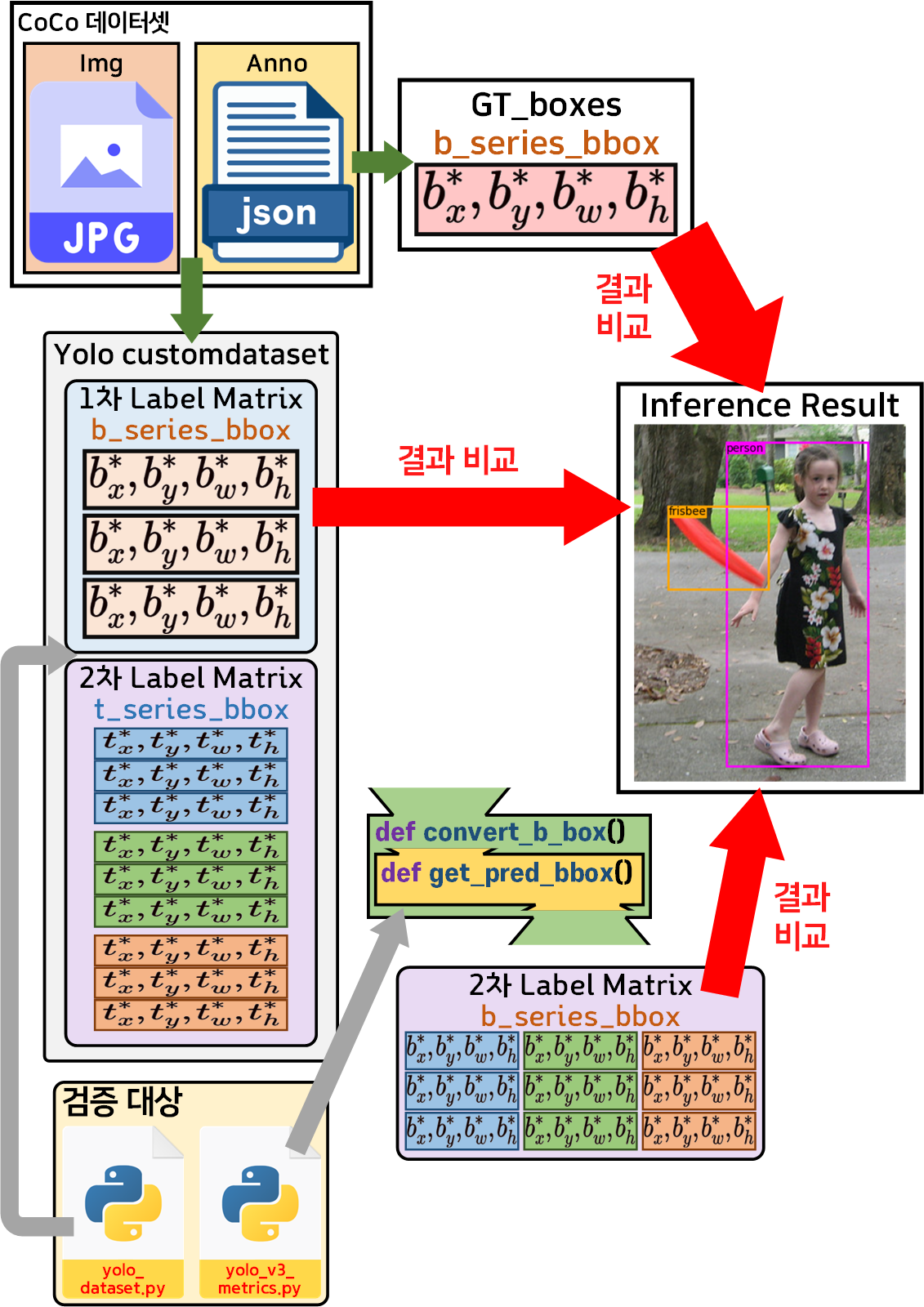
좌표변환이 2회 진행되니
GT_boxes
first_label_boxes
second_label_bbox
3개의 bbox좌표값들에 대하여 이미지 추론을 수행하고
이 3가지의 bbox가 모두 일치하는지 확인해야 한다.
이때 검증 대상 코드는
커스텀 데이터셋을 생성하는 코드 : yolo_dataset.py
좌표변환 코드 : yolo_v3_metrics.py
여기서 yolo_v3_metrics.py는
이전 포스트 인공지능 고급(시각) 강의 예습 - 22. (8) Yolo v3 사전학습모델 + 추론검증 에서 1차 검증을 하긴 했지만
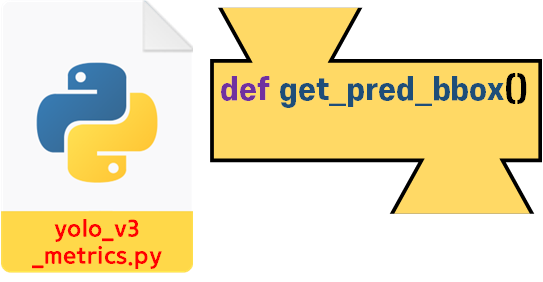 1차 검증에서는
1차 검증에서는 get_pred_bbox 함수만 검증했고
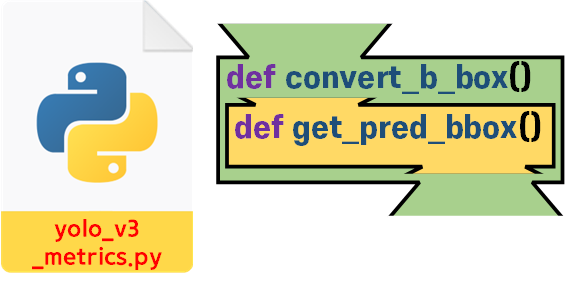 2차 검증에서는 해당 함수를 감싸고 있는
2차 검증에서는 해당 함수를 감싸고 있는 conver_b_box 함수까지 검증을 수행한다.
yolo_v3_metrics.py는 다양한 기능을 포함하고, 또 범용성 있게 활용되기에 아마 한번 더 코드 검증을 수행하지 않을까 싶다.
3. yolo_dataset.py 코드검증
먼저 yolo_dataset.py코드를 검증 하기 전
추가로 데이터 추출이 가능한 코드를 하나 더 추가해준다.
# 디버그용 img 정보 취득 함수
def get_img_info(self, idx):
img_id = self.img_ids[idx]
img_info = self.coco.loadImgs(img_id)[0]
ann_ids = self.coco.getAnnIds(imgIds=img_id)
img_info['obj_num'] = len(ann_ids)
return img_info이 코드를 yolo_dataset.py의
CustomDataset클래스에 추가해준다.
따라서 클래스 다이어그램을 보면 아래와 같이 업데이트가 된다.
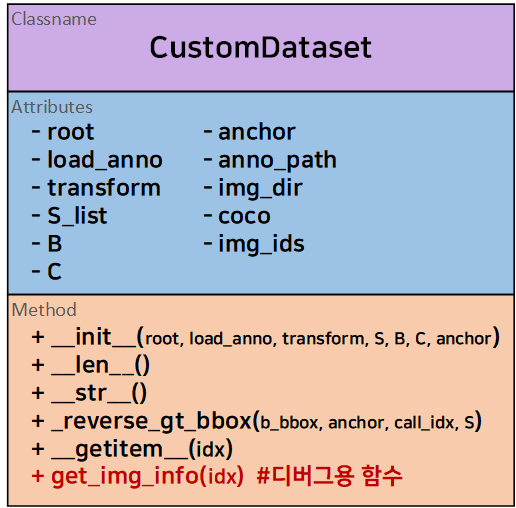
이 get_img_info 함수는 커스텀 데이터셋에서 임의의 idx에 대한 img, labels를 출력할 때
img의 정보를 추가로 열람하기 위한 디버그용 함수라 보면 된다.
다음으로 코드 검증을 위해 작성한 코드는 아래와 같다.
import torch
import coco_data
from yolo_dataset import CustomDataset
import cv2, random, os
from pycocotools.coco import COCO# coco데이터셋의 메인 루트 디렉토리
root_dir = './COCO dataset'
load_anno = 'train2017'
# 데이터셋 생성
exam_dataset = CustomDataset(root=root_dir, load_anno=load_anno)
# 커스텀 데이터셋과 동일한 coco 데이터셋 새로 생성하기
anno_path = os.path.join(root_dir, 'annotations')
json_file = 'instances_' + load_anno + '.json'
coco = COCO(os.path.join(anno_path, json_file))참고로 데이터셋은 exam_dataset과
coco 두개를 생성하며,
이때 생성한 두 데이터셋이 참조하는 Img, Anno는 동일한 데이터를 참조한다.
coco 데이터셋은 GT_boxes 를 출력하고
exam_dataset데이터셋은 검증 대상인
first_label_boxes,
second_label_bbox
를 출력한다.
print(f"이미지 개수 :{len(exam_dataset)}")
idx_list = range(len(exam_dataset))
chosen_idx = random.choice(idx_list)
print(f"선택한 이미지 ID : {chosen_idx}")img, labels = exam_dataset[chosen_idx]
img_info = exam_dataset.get_img_info(chosen_idx)
for key, val in img_info.items():
print(f"{key} : {val}")
print()
for i, label in enumerate(labels):
print(f"{i}번째 label: {label.shape}")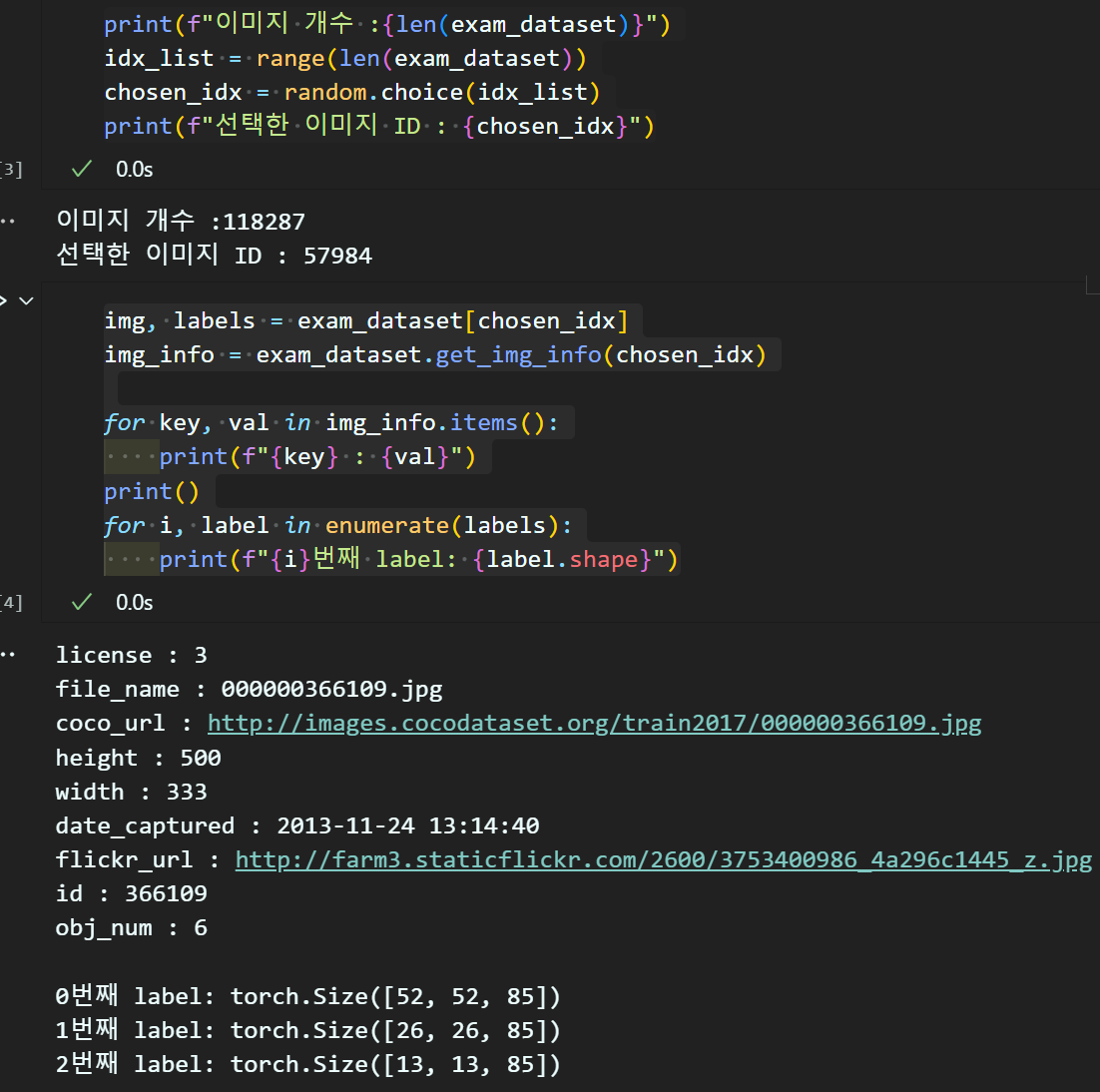
위 코드는 선택한 img, label, anno의 기초적인 정보를 확인하기 위한 코드이다.
1)
GT_boxes정보 검증
# 커스텀 데이터셋과 동일한 coco 데이터셋 에서 주석정보 추출
chosen_id = img_info['id']
ann_ids = coco.getAnnIds(imgIds=chosen_id)
anns = coco.loadAnns(ann_ids)
gt_boxes = []
for ann in anns:
bbox = ann['bbox']
# CP는 Class Probability이니 = Class ID
CP_idx = coco_data.real_class_idx[ann['category_id']]
x, y, w, h = bbox
# bbox 좌표 정규화
bx = (x + w / 2) / img_info['width']
by = (y + h / 2) / img_info['height']
bw = w / img_info['width']
bh = h / img_info['height']
gt_box = torch.tensor([bx, by, bw, bh, 1, CP_idx])
gt_boxes.append(gt_box)
gt_boxes = sorted(gt_boxes, key=lambda box: (box[5], box[2] * box[3]))
# 정규 좌표평면상으로 변환한 GT_b_series_bbox 좌표 리스트 출력
for gt_box in gt_boxes:
print(gt_box)coco 데이터셋에서 선택한 img와 매칭되는 Anno정보를 색인한 뒤 여기서 얻어낸 BBox정보를
정규 좌표평면상의 B_serise_BBox좌표 정보로 변환하는 과정을 수행하는 코드이다.
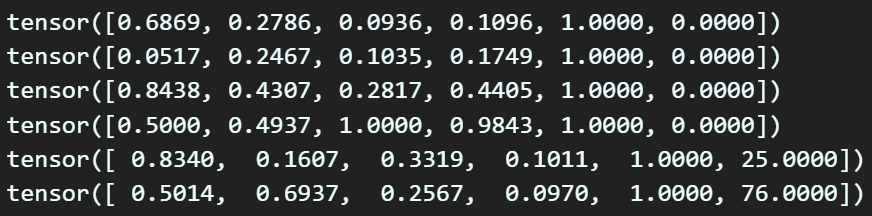
선택한img에는 총 6개의 객체정보가 담겨있으니 그에 맞춰 6개의 데이터가 좌표변환됨을 알 수 있다.
2) first_label_boxes 정보 검증
 이 데이터를 검증하기 위한 코드이다.
이 데이터를 검증하기 위한 코드이다.
# 커스텀 데이터셋에서 1차 좌표변환 B_serise_bbox좌표정보 추출
first_label_boxes = []
for label in labels:
S = label.size(0)
# label = label.view(S, S, 3, -1)
if label.size(2) != 85:
raise ValueError(f"차원확인")
bbox = label[..., :4]
obj_s = label[..., 4]
cla_s = label[..., 5:]
cp_val, cp_id = torch.max(cla_s, dim=-1)
coord_mask = obj_s > 0
f_bbox = bbox[coord_mask]
f_obj_s = obj_s[coord_mask]
f_cp_id = cp_id[coord_mask]
for i in range(f_bbox.size(0)):
element = torch.cat([f_bbox[i], f_obj_s[i].unsqueeze(0), f_cp_id[i].unsqueeze(0)])
first_label_boxes.append(element)
first_label_boxes = sorted(first_label_boxes, key=lambda box: (box[5], box[2] * box[3]))
# 정규 좌표평면상으로 변환한 Label_b_series_bbox 좌표 리스트 출력
for label_bbox in first_label_boxes:
print(label_bbox)코드는 1) 코드랑 유사하나 examdataset의 labels 정보로부터 bbox, OS, CP 3가지 정보를 추출해내는 과정이 다르고
그 이후는 같다.
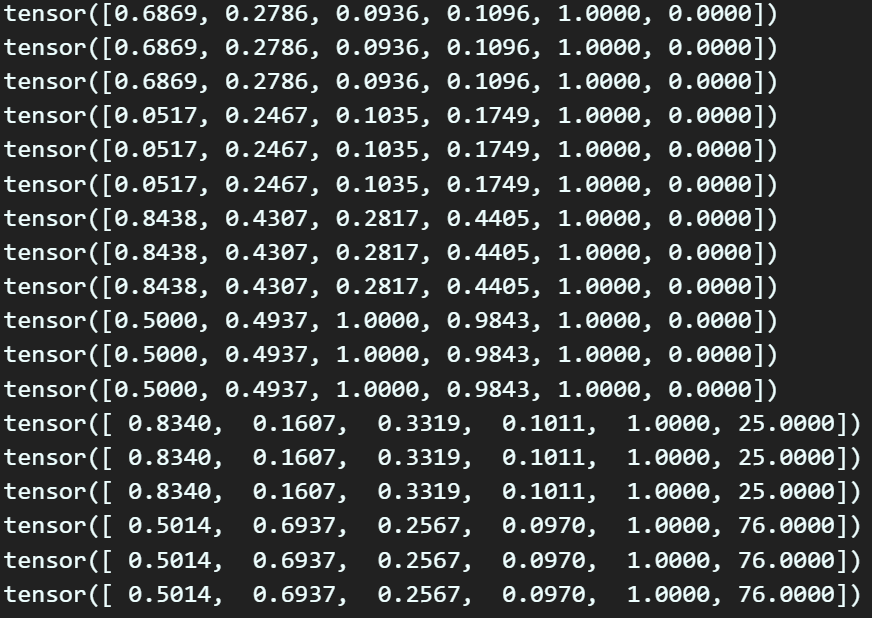
1차 좌표변환의 코드에는 Grid cell의 종류
[52, 26, 13] 에 따라서 GT정보가 배치되기에
따지고 본다면 Ground Truth 정보가 3배로 복제됨을 의미한다.
따라서 출력되는 first_label_boxes 정보는 인식한 객체 X 3배이다.
3) 2차 좌표변환 transformation 수행
# 커스텀 데이터셋에 tr을 적용하여 t_series bbox 좌표로 전환 수행
exam_dataset.anchor = coco_data.anchor_box_list
from torchvision.transforms import v2
transforamtion = v2.Compose([
v2.Resize((416, 416)), #이미지 크기를 416, 416로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
# v2.Normalize(mean=coco_val[0], std=coco_val[1]) #데이터셋 정규화
])
exam_dataset.transform = transforamtion# t_series_bbox로 전환된 라벨 정보 추출
img, t_labels = exam_dataset[chosen_idx]
t_labels = [t_label.unsqueeze(0) for t_label in t_labels]
for t_label in t_labels:
print(t_label.shape)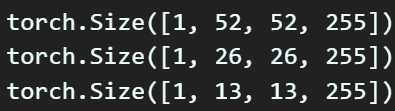
Transformation 메서드가 트리거가 되서
B_series_bbox( 정보를
T_series_bbox( 로 변환하기에
출력되는 Labels도 원소 Label_matrix가 데이터량이 3배 증가함을 알 수 있을 것이다.
이 데이터에 관해서도 검증은
 위 사진처럼 데이터가 잘 배치되었는지 확인을 해봐야 한다.
위 사진처럼 데이터가 잘 배치되었는지 확인을 해봐야 한다.
데이터의 배치는 1차 좌표변환 코드에서 증가한 데이터의 idx만 주의해서 추출해내면 된다.
# 2차 좌표변환 t_series bbox 좌표 먼저 출력해보기
second_t_label_boxes = []
for label in t_labels:
bs = label.size(0)
S = label.size(1)
t_label_view = label.view(bs, S, S, 3, -1)
bbox = t_label_view[..., :4]
obj_s = t_label_view[..., 4]
cla_s = t_label_view[..., 5:]
cp_val, cp_id = torch.max(cla_s, dim=-1)
coord_mask = obj_s > 0
f_bbox = bbox[coord_mask]
f_obj_s = obj_s[coord_mask]
f_cp_id = cp_id[coord_mask]
for i in range(f_bbox.size(0)):
element = torch.cat([f_bbox[i], f_obj_s[i].unsqueeze(0), f_cp_id[i].unsqueeze(0)])
second_t_label_boxes.append(element)
second_t_label_boxes = sorted(second_t_label_boxes, key=lambda box: (box[5], box[2] * box[3]))
# 정규 좌표평면상으로 변환한 Label_t_series_bbox 좌표 리스트 출력
for label_t_bbox in second_t_label_boxes:
print(label_t_bbox)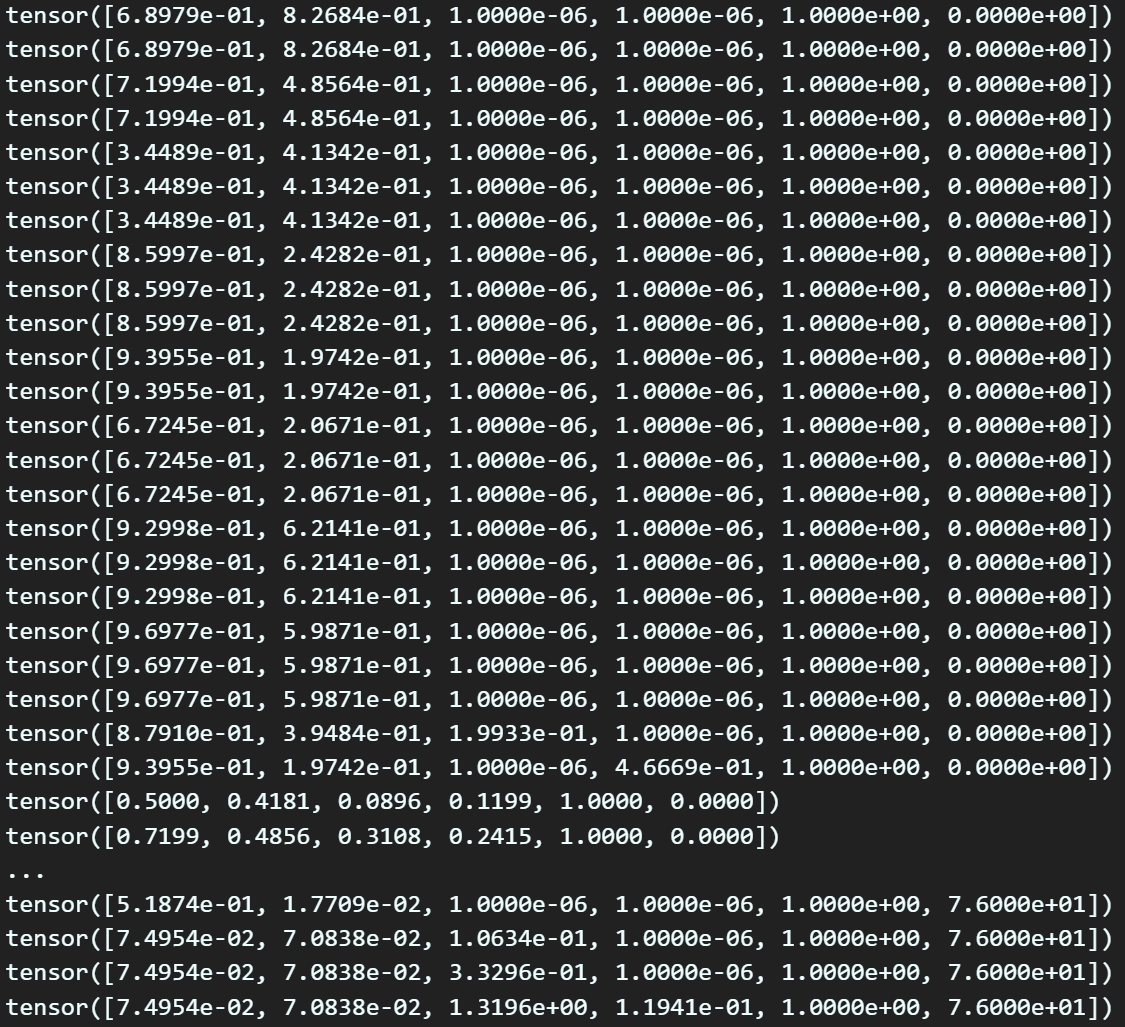
여기서는 1차 Label matrix의 bbox정보가 3배 더 늘어난 것이니
총 출력되는 데이터는
검지된 객체 x3 x3 하여 데이터가 9배 늘어난다.
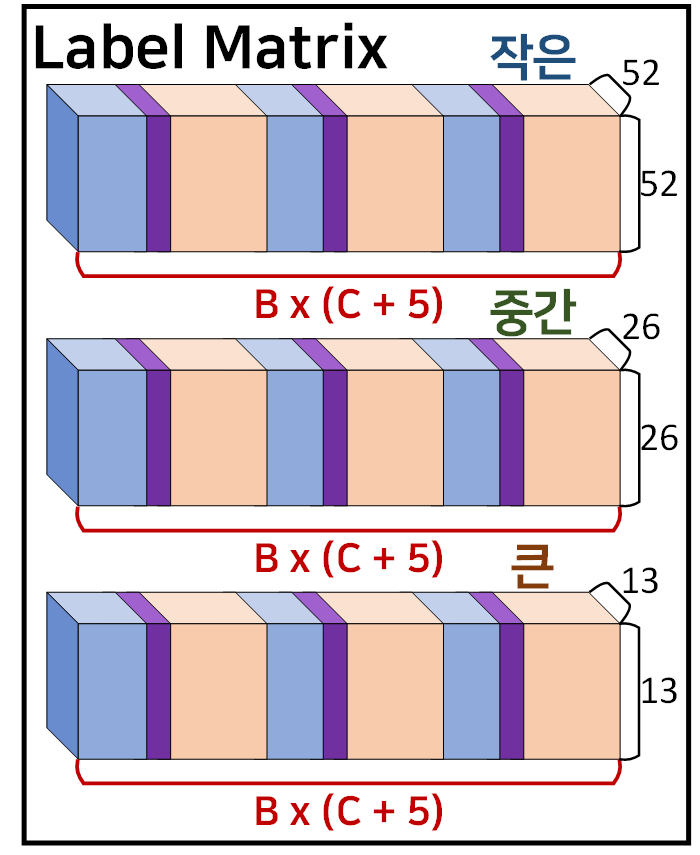 이게 커스텀 데이터셋이 출력하는
이게 커스텀 데이터셋이 출력하는 Label_Matrix라 보면 된다.
4)
second_label_bbox데이터 생성하기
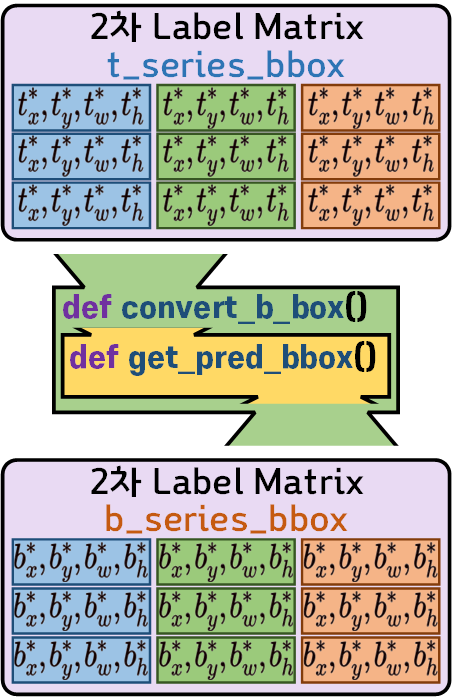 위 그림 과정을 수행하는 부분이라 보면 된다.
위 그림 과정을 수행하는 부분이라 보면 된다.
from yolo_v3_metrics import YOLOv3Metrics
# YOLOv3Metrics의 convert_b_box 함수를 사용하기 위해 인스턴스화
metrics = YOLOv3Metrics(anchor=coco_data.anchor_box_list, device='cpu')# 2차 좌표변환 t_series bbox 좌표를 b_series_bbox로 convert_b_bbox 함수로 복원
second_label_bbox = []
for label in t_labels:
bs = label.size(0)
S = label.size(1)
label = label.view(bs, S, S, 3, -1)
label_boxes = label[..., :5]
_, bbox = metrics.convert_b_bbox(label_boxes, label_boxes)
obj_s = label[..., 4]
cla_s = label[..., 5:]
cp_val, cp_id = torch.max(cla_s, dim=-1)
coord_mask = obj_s > 0
f_bbox = bbox[coord_mask]
f_obj_s = obj_s[coord_mask]
f_cp_id = cp_id[coord_mask]
for i in range(f_bbox.size(0)):
element = torch.cat([f_bbox[i], f_obj_s[i].unsqueeze(0), f_cp_id[i].unsqueeze(0)])
second_label_bbox.append(element)
second_label_bbox = sorted(second_label_bbox, key=lambda box: (box[5], box[2] * box[3]))
# 정규 좌표평면상으로 변환한 원복 Label_b_series_bbox 좌표 리스트 출력
for label_bbox in second_label_bbox:
print(label_bbox)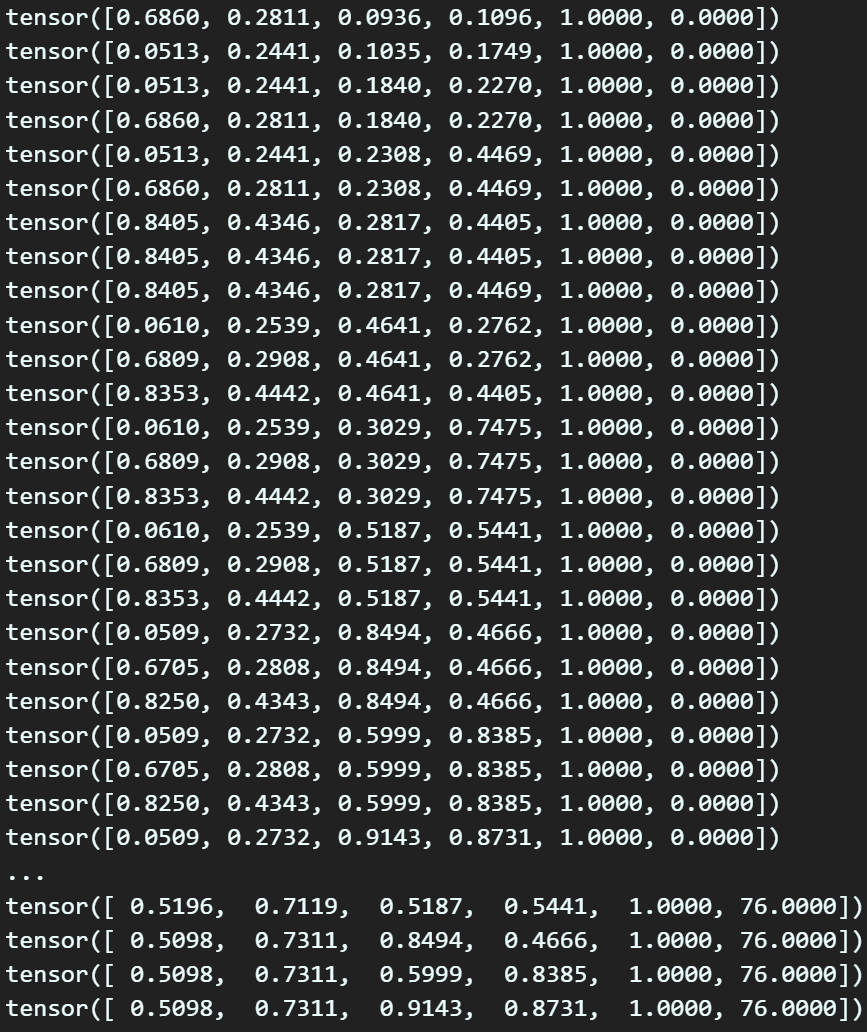 뭔가 데이터가 많이 출력되었는데
뭔가 데이터가 많이 출력되었는데
검출된 6개의 객체에 대하여
9배 증가된 54개의 데이터를 출력하는 것이니
숫자만 봐서는 문제가 있는지 없는지 알기가 어렵다
이거는 디스플레이를 해봐야 알 수 있는 내용이다.
5) 결과물 시각화 후 검토
import cv2, random, os
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
# 이미지 텐서를 다시 numpy 배열로 변환
image_np = img.squeeze(0).permute(1, 2, 0).numpy() * 255.0
image_np = image_np.astype(np.uint8)
# 원래 크기로 다시 크기 조정
original_height = img_info['height']
original_width = img_info['width']
image_restored = cv2.resize(image_np, (original_width, original_height))# 결과 시각화 함수
def plot_boxes(image, boxes, labels):
plt.figure(figsize=(10, 10))
plt.imshow(image)
ax = plt.gca()
# 정규 좌표값 boxes를 원래 값으로 복원
scale_y = image.shape[0] # height
scale_x = image.shape[1] # width
boxes = [[box[0] * scale_x, # x_center * width
box[1] * scale_y, # y_center * height
box[2] * scale_x, # w * width
box[3] * scale_y, # h * height
box[4], box[5]] for box in boxes]
for box in boxes:
x_center, y_center, w, h, conf, label = box
# bbox를 그리는데 좌 상단 좌표, width, hight 필요
x1 = x_center - w / 2
y1 = y_center - h / 2
# 라벨의 텍스트 좌표 및 bbox의 색깔 정하기
label = int(label)
superclass = coco_data.cls_map[label]
color = coco_data.cls_color[superclass]
rect = Rectangle((x1, y1), w, h, linewidth=2, edgecolor=color, facecolor='none')
ax.add_patch(rect)
plt.text(x1, y1, s=labels[label], color='black', verticalalignment='top',
bbox={'color': color, 'pad': 0})
plt.axis('off')
plt.show()
결과물을 보면 알 수 있듯이
first_label_boxes, 1차 BBox 좌표변환 과정은
정상적으로 기능함을 알 수 있으나
second_label_bbox, 2차 BBox 좌표변환 과정은 완전히 틀어짐을 확인할 수 있었다.
4. 원인 분석 & 문제해결
문제를 해결하려 이리저리 코드를 검토한 결과
1) anchor_box_list의 해상도 문제
2) CustomDataset의 _reverse_gt_bbox 함수 코드 오류
이렇게 두가지가 발생했다.
1)
anchor_box_list의 해상도 문제
이전 포스트 인공지능 고급(시각) 강의 예습 - 22. (4) Yolo v3용 Coco 데이터셋 전처리에서
K-mean clustering을 수행하면서 나온 결과값
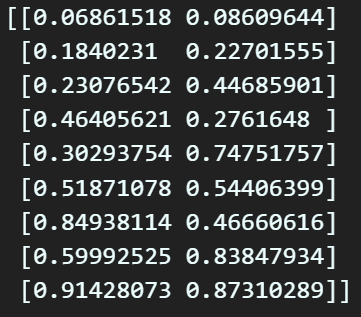
이 정보를 아래와 같이 저장했는데
딱 봐도 소수점 4째자리 이후의 데이터는 다 유실되었다
보면 된다...
딥러닝 과정에서 사용되는 Tensor 자료형은 기본형이
float32의 정밀도까지 지원하니
해상도가 높은 데이터로
anchor_box_list를 업데이트 할 필요성이 있다.
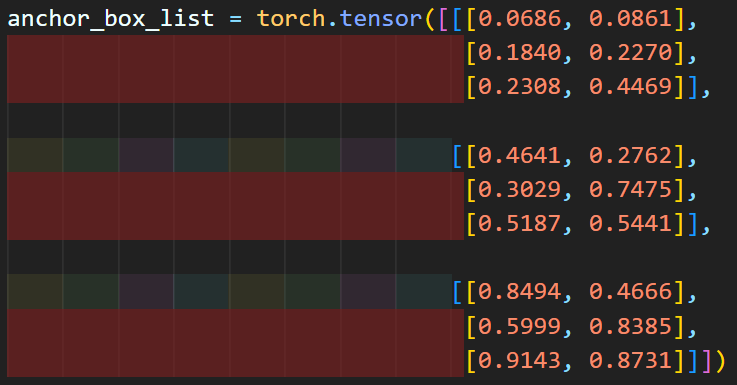
이거때문에 k-mean clustering을 다시 수행해야 해서
아에 04_k_mean_cluster.ipynb 파일을 작성하여 해당 코드를
https://github.com/tbvjvsladla/yolo_v3_pytorch 에 업로드하였다.
코드의 경우 이전 포스트에서 설명을 했으니
중복하여 기재하지는 않고
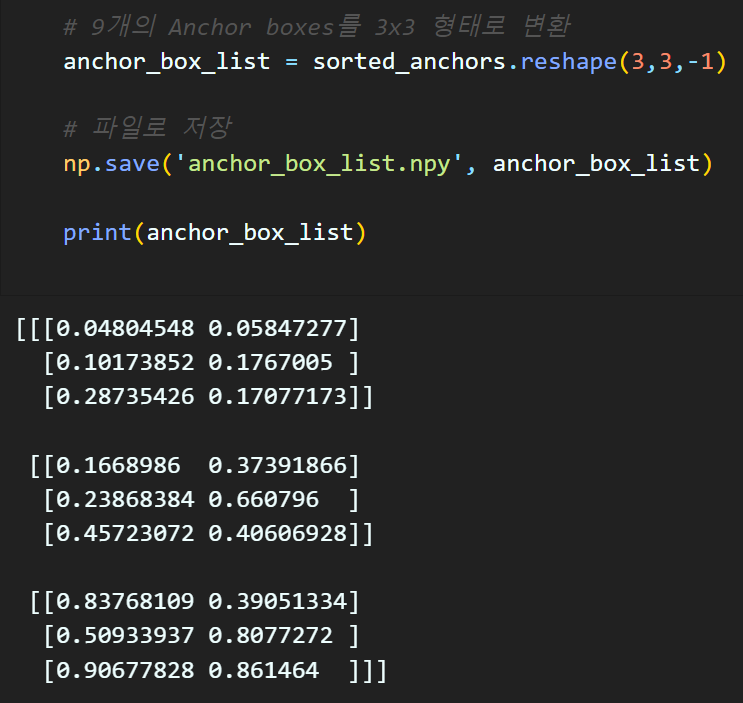 아에 위 코드처럼
아에 위 코드처럼
anchor_box_list 변수값을 *.npy
numpy에서 제공하는 matrix 변수 저장&관리 확장자 파일로 저장한다
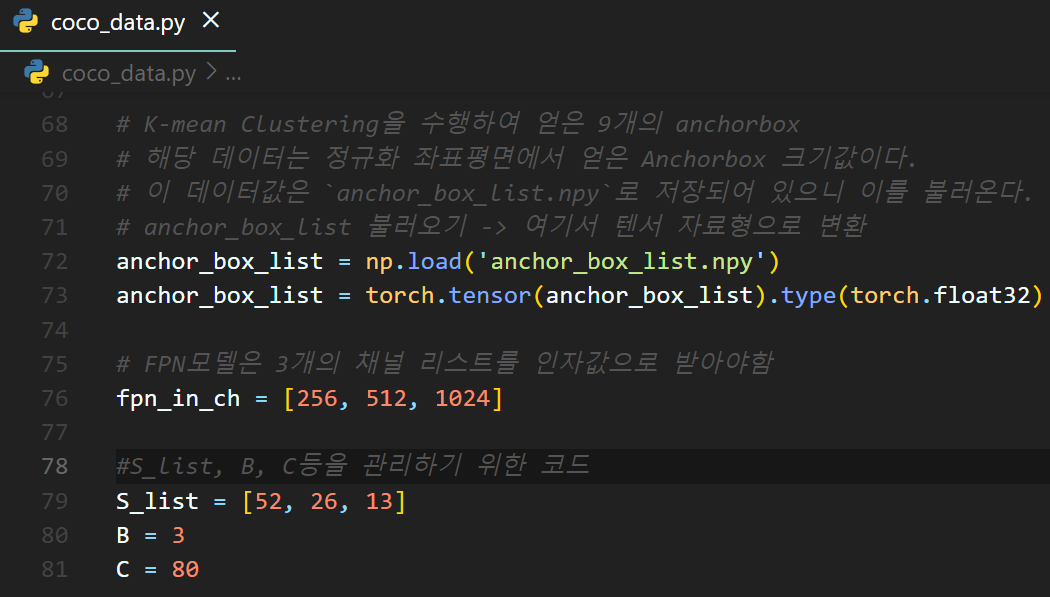
이후 coco_data.py파일에서
저장한 anchor_box_list.npy를 로드하여
anchor_box_list를 해상도 손실 없이 불러오게 코드를 작성한다.
2)
CustomDataset의_reverse_gt_bbox함수 코드 오류
다음으로 yolo_dataset.py코드에 포함되어 있는
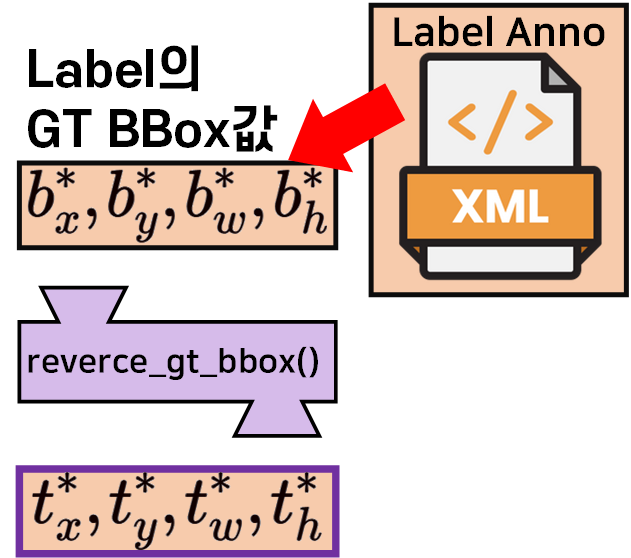
이 2차 좌표변환 기능을 수행하는 reverse_gt_bbox() 함수를 디버그하면 된다.
여기서 문제가 되는 부분은
eclipse = 1e-6
tw = torch.log(bw / pw).clamp(min=eclipse)
th = torch.log(bh / ph).clamp(min=eclipse) 이 부분이다.
이게.. 스토리를 풀어가자면
학습 코드를 동작시켰을 때 좌표 변환한 tw, th에서
NaN이 발생해서
chat GPT한테 NaN을 방지하는 방안을 알려달라고 하니까
저렇게 clamp로 min값을 설정하라고 한건데...
이게 대단히 잘못된 코드이다.
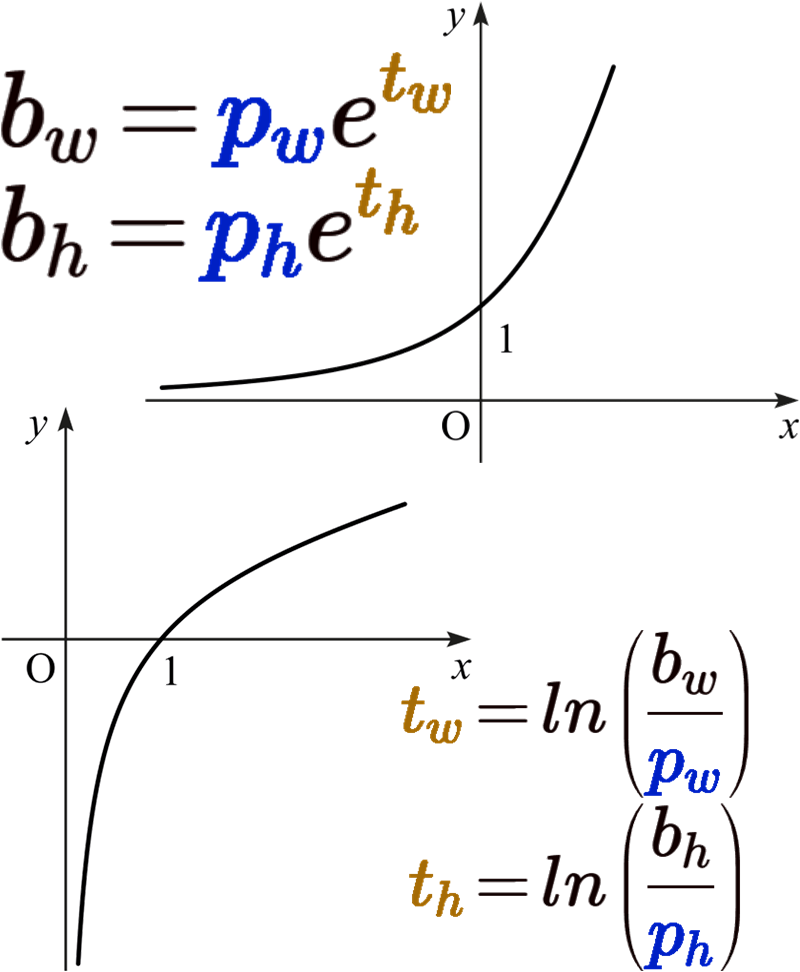 위 사진처럼 지수함수와 로그함수로 표현가능한
위 사진처럼 지수함수와 로그함수로 표현가능한
과정에서
로그함수는 충분히 음수값이 나오는데 그걸 clamp(min=eclipse)로 제한을 걸어버리니
이에 대한 대참사가 난 것이다;;
왜 노마드코더가 깃허브 코파일럿 쓰지말라고 하는지 알거같다...
너무 Chat GTP에 의존하니 감다뒤

하지만 그렇다고 clamp(min=eclipse) 이 구문을 없앤다고 문제가 해결되는 것은 아니다
clamp(min=eclipse) 이 구문으로 NaN을 방지했으니
어떻게든
이 함수를 구동할 때 NaN이 나오지 않게 해야한다.
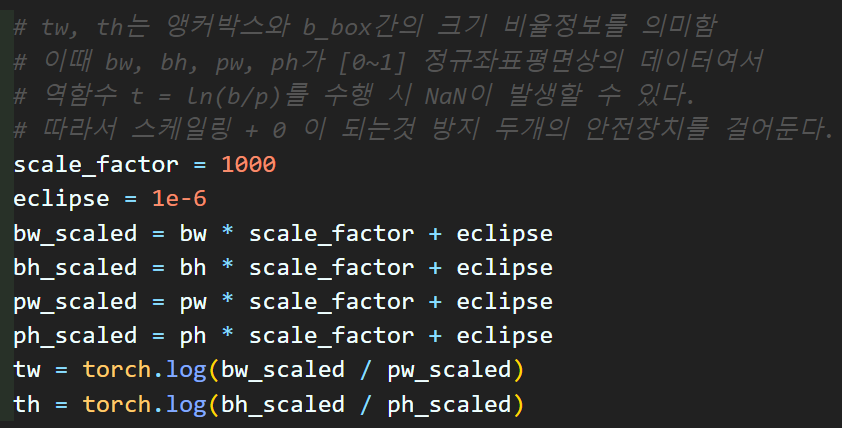
필자가 해결한 방법은 로그함수에 입력되는 분자, 분모값을 충분히 스케일링한 뒤, 여기에 정말 작은 양수값을 더해서
NaN이 발생하는 가능성을 차단했다.
이 값들이
모두 정규화된 값으로 스케일링 되어 있다보니([0~1])
값이 한번 작아지면 한없이 0에 가까워지는 문제가 있는 것으로 보인다.
따라서 적절한 값으로 값들의 크기를 키워준 뒤
모두 무조건 양수값을 갖게 elipse를 더해줬다


음...
이정도로 만족해야 할거같다
이게 음..
이미지 bbox -> 정규 좌표평면 -> b_series_bbox
-> t_series_bbox -> b_series_bbox -> 정규 좌표평면
-> 원래 이미지 크기로 리사이징
이렇게 7단계 거쳐가면서 좌표변환을 소수단위로 수행하는데
좌표가 안틀어지는게 더 이상하다.
아마도
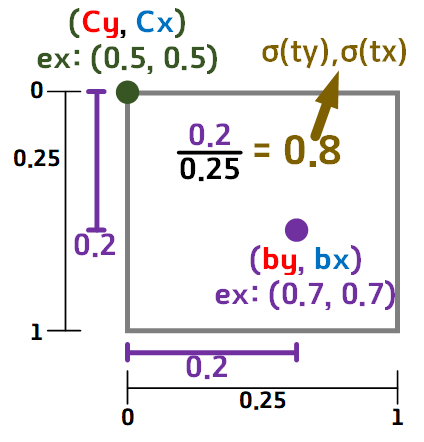
여기 과정에서 뭔가 해상도 문제가 나는거 같은데..
음.. 이정도 오차는 그냥 앉고 가기로 했다 ㅎㅎ;;;
이 오류를 수정하기에는
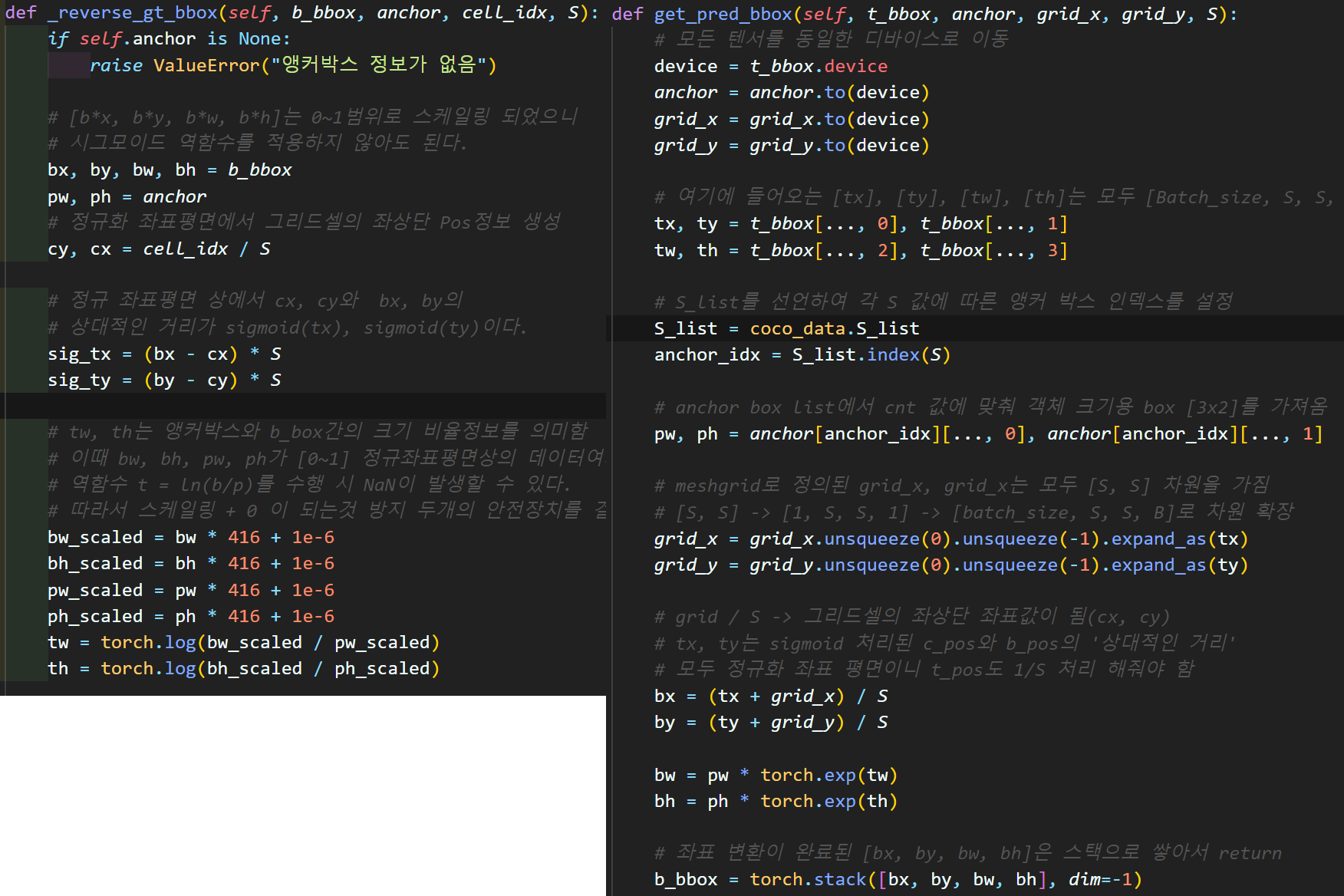
해당 좌표변환에 관여하는 두개의 함수가
너무 정직하다...
아무튼 검증 완료
