
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. Yolo v1 Loss_fn 대비 개선사항
이전 포스트인 인공지능 고급(시각) 강의 예습 - 19. Yolo v1 (2) Loss 함수 설계에서 기재한
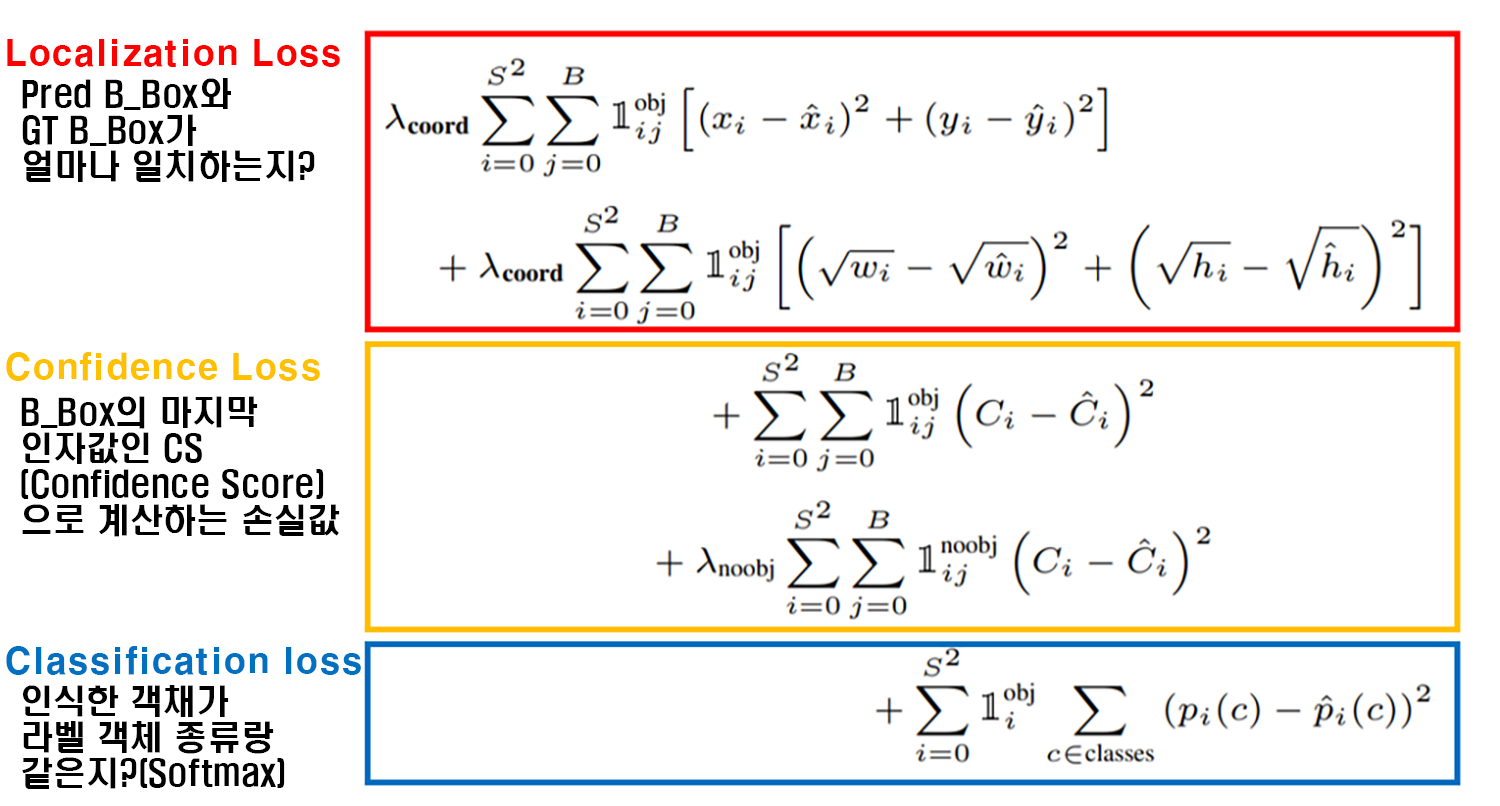
위치 손실 (Localization Loss)
객체성 손실(Objectness Loss)
분류 손실(Classification Loss) 3가지 지표가 적용되는 것은 동일하다.
단 Yolo v3에서는 손실의 계산 방식이 달라졌는데
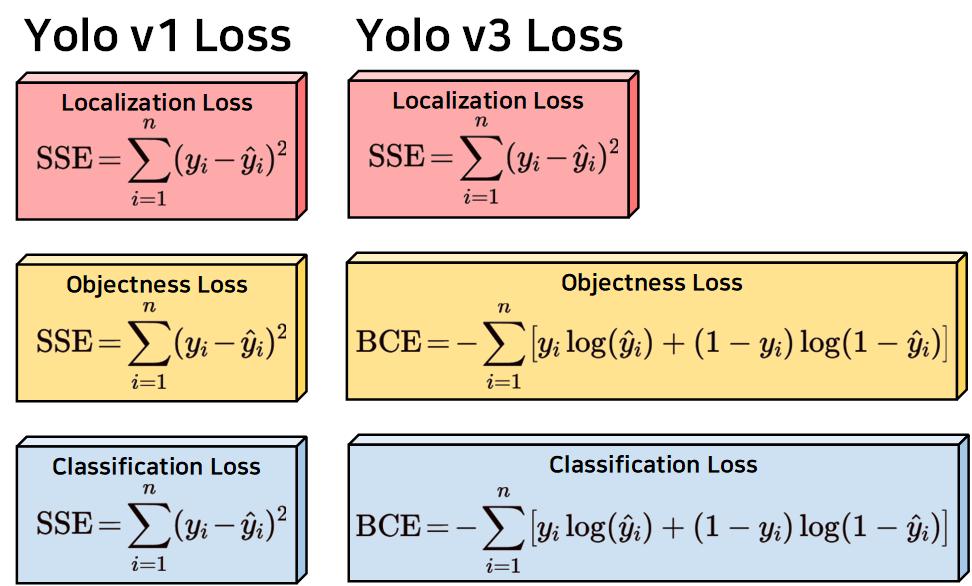
위 사진처럼 객체성 손실(Objectness Loss), 분류 손실(Classification Loss)의 손실 계산 방법론이
Sum Squared Error (SSE)에서 Binary Cross Entropy (BCE)로 변경되었다.
이는 객체성 손실(Objectness Loss), 분류 손실(Classification Loss)는 존재확률, 그리고 해당 클래스에 속할 확률을 다루는 문제이기에
확률 예측에 좀 더 적합한 손실 계산 방식인 BCE로 손실함수를 변경했다. 이렇게 보면 될 듯 하다.
따지고 보면 딥러닝의 손실함수 + 옵티마이저 조합에서도
BCE, CE를 주로 손실함수로 지정하니 이에 따른 옵티마이저가 좀 더 잘 동작하게 된다.. 이렇게 생각하면 될 듯 하다.
2. Yolo v3 Loss()
전체적으로 코드를 작성함에 있어서 이전에 포스트한
인공지능 고급(시각) 강의 예습 - 19. Yolo v1 (2) Loss 함수 설계
보다는 더 깔끔하고 짧게 코드 작성이 완료됬다.
이전에 v1 Loss 함수를 코드화 하면서 너무 곶통스러웠는데

원리를 알 만큼 안 상태에서 코드를 작성하니 더 쉬워진건지 뭐 아무튼
전체 코드를 붙이고 주요 항목별로 설명을 진행하도록 하겠다.
import torch
import torch.nn as nnclass Yolov3Loss(nn.Module):
def __init__(self, B=3, C=80):
super(Yolov3Loss, self).__init__()
# self.S = S # 그리드셀의 단위(52, 26, 13)
self.B = B # 이 값은 Anchor box의 개수로 인자 변환
self.C = C # class종류(Coco 데이터 기준 80)
self.lambda_coord = 5 # 실험적으로 구한 계수값
self.lambda_noobj = 0.5 # 실험적으로 구한 계수값
# Objectness loss 및 Classification Loss는 SSE에서 BCE로 변경
self.bce_loss = nn.BCELoss(reduction='sum')
def forward(self, predictions, target):
# Assert 구문을 활용하여 grid cell의 크기가 동일한지 확인
assert predictions.size(1) == predictions.size(2), "그리드셀 차원이 맞지 않음"
batch_size = predictions.size(0) # Batch_size의 사이즈 정보를 추출
S = predictions.size(2) # grid cell의 개수 정보를 추출
# [Batch_size, S, S, (5 + C) * B] -> [Batch_size, S, S, B, (5 + C)]로 변환
predictions = predictions.view(batch_size, S, S, self.B, 5 + self.C)
target = target.view(batch_size, S, S, self.B, 5 + self.C)
# 2) BBox좌표, OS, CS 정보 추출하여 재배치
pred_boxes = predictions[..., :4] # [batch_size, S, S, B, 4]
# target_boxex의 추출된 정보는 [sigtx, sig, ty, tw, th]이니
# 이것에 맞게 pred_boxe의 [tx, ty]도 [sigmoid(tx), sigmoid(ty)]처리
pred_boxes[..., :2] = torch.sigmoid(pred_boxes[..., :2])
# pred_boxes[..., :2] = torch.clamp(pred_boxes[..., :2], self.e, 1-self.e)
target_boxes = target[..., :4] # [batch_size, S, S, B, 4]
# Class scores에 sigmoid 적용 -> 이게 Yolo v3의 핵심임
pred_class = torch.sigmoid(predictions[..., 5:]) # [batch_size, S, S, B]
target_class = target[..., 5:] # [batch_size, S, S, B, C]
# 3) 마스크 필터 생성
coord_mask = target_obj > 0 # [batch_size, S, S, B]
noobj_mask = target_obj <= 0 # [batch_size, S, S, B]
# 예외처리 : 객체가 아에 없는 이미지에 대한
if coord_mask.sum() == 0:
return torch.tensor(0.0, requires_grad=True)
# 4) 마스크 필터를 적용해 Bbox의 데이터 필터링
# unsqueeze를 이용해 [batch_size, S, S, B] -> [batch_size, S, S, B, 1]
# 이후 expand_as를 이용해 [batch_size, S, S, B, 4]
# expand_as는 expand랑 거의 기능이 같다
coord_mask_box = coord_mask.unsqueeze(-1).expand_as(target_boxes)
# 5) Localization Loss 계산하기
# bbox의 값이 [tx, ty, tw, th]이니 한꺼번에 loss 계산
coord_loss = self.lambda_coord * (
(pred_boxes[coord_mask_box] - target_boxes[coord_mask_box]) ** 2
).sum()
# 6) OS(objectness Score)의 마스크 필터를 활용한 필터링
# 7) Objectness Loss 계산하기
obj_loss = self.bce_loss(pred_obj[coord_mask], target_obj[coord_mask])
cal = self.bce_loss(pred_obj[noobj_mask], target_obj[noobj_mask])
noobj_loss = self.lambda_noobj * cal
# 8) CP(Class Probabilities)에 대한 필터링 작업
# 9) Classification Loss 계산하기
# coord_mask는 자동으로 broadcasting이 되어서 expand_as를 안써도 된다.
class_loss = self.bce_loss(pred_class[coord_mask], target_class[coord_mask])
total_loss = coord_loss + obj_loss + noobj_loss + class_loss
return total_loss1) 클래스 도입부
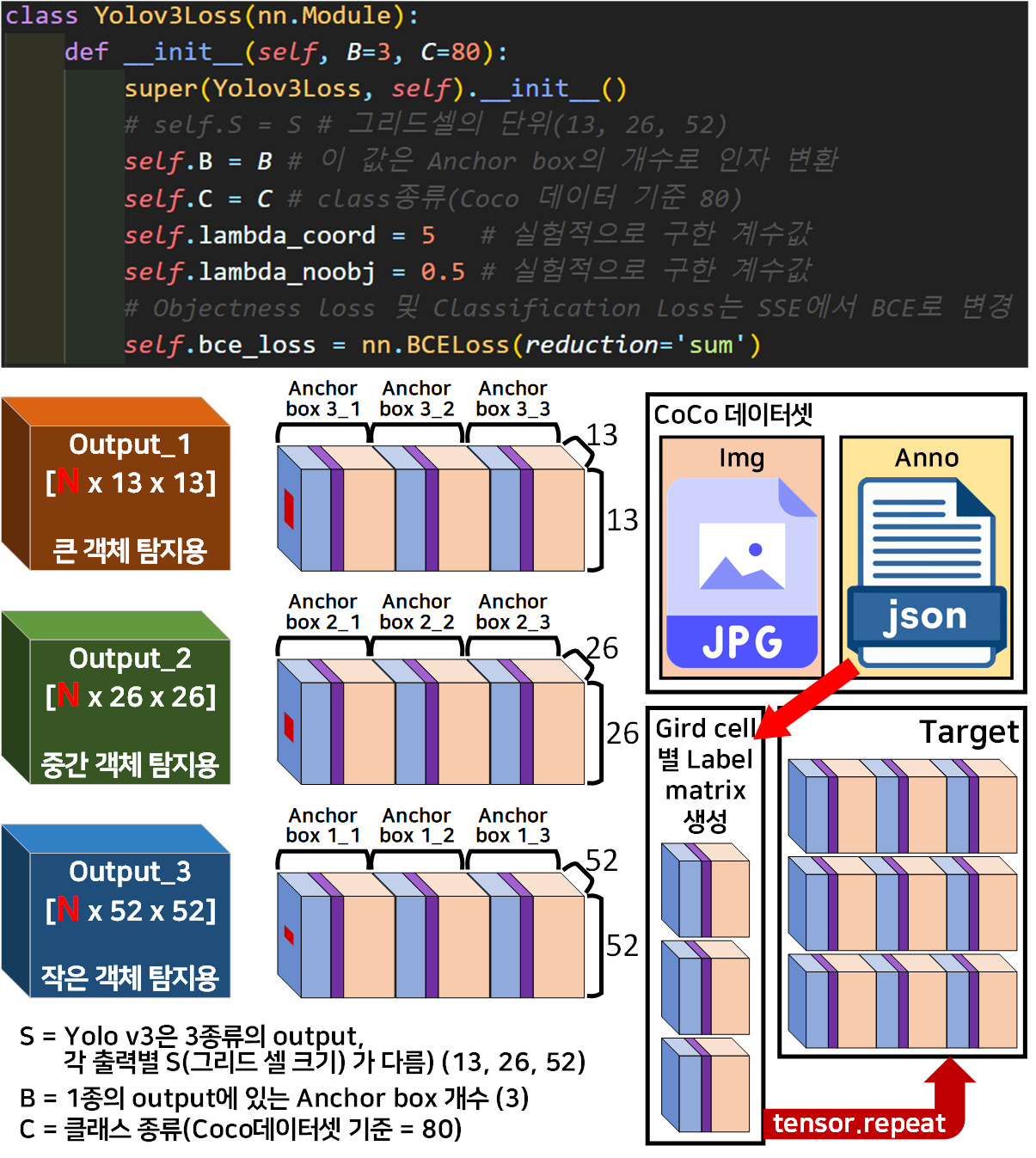
S (그리드셀의 단위)는 가변 단위가 되었기에 __init__메서드에서 관리하는 변수에서는 뺏으며,
객체성 손실(Objectness Loss), 분류 손실(Classification Loss)를 계산하는 BCE함수는 nn.BCELoss 메서드로 간단하게 구현이 가능하다.
이때 인자 옵션을 reduction=sum으로 처리하여 발생하는 모든 손실은 Mean이 아닌 Sum처리하도록 지정한다.
그리고 Yolo v3 Loss함수는 모델의 예측값인 Output와 Anno 데이터로부터 추출하는 Target두가지 값이 필요한데
이 Target값의 생성은
데이터셋의 Anno 전처리를 통해 Label Matirx생성 생성한 Label Matrix를 Output와 차원을 맞추기 위해 데이터를 repeat
위 과정을 수행하여 데이터를 전처리한다.
물론 위 과정이 Yolo v3 Loss함수에 포함되는 것은 아니고
해당 과정은 데이터셋 전처리 포스트에 기재하도록 하겠다.
2) 차원전환 및 정보 추출
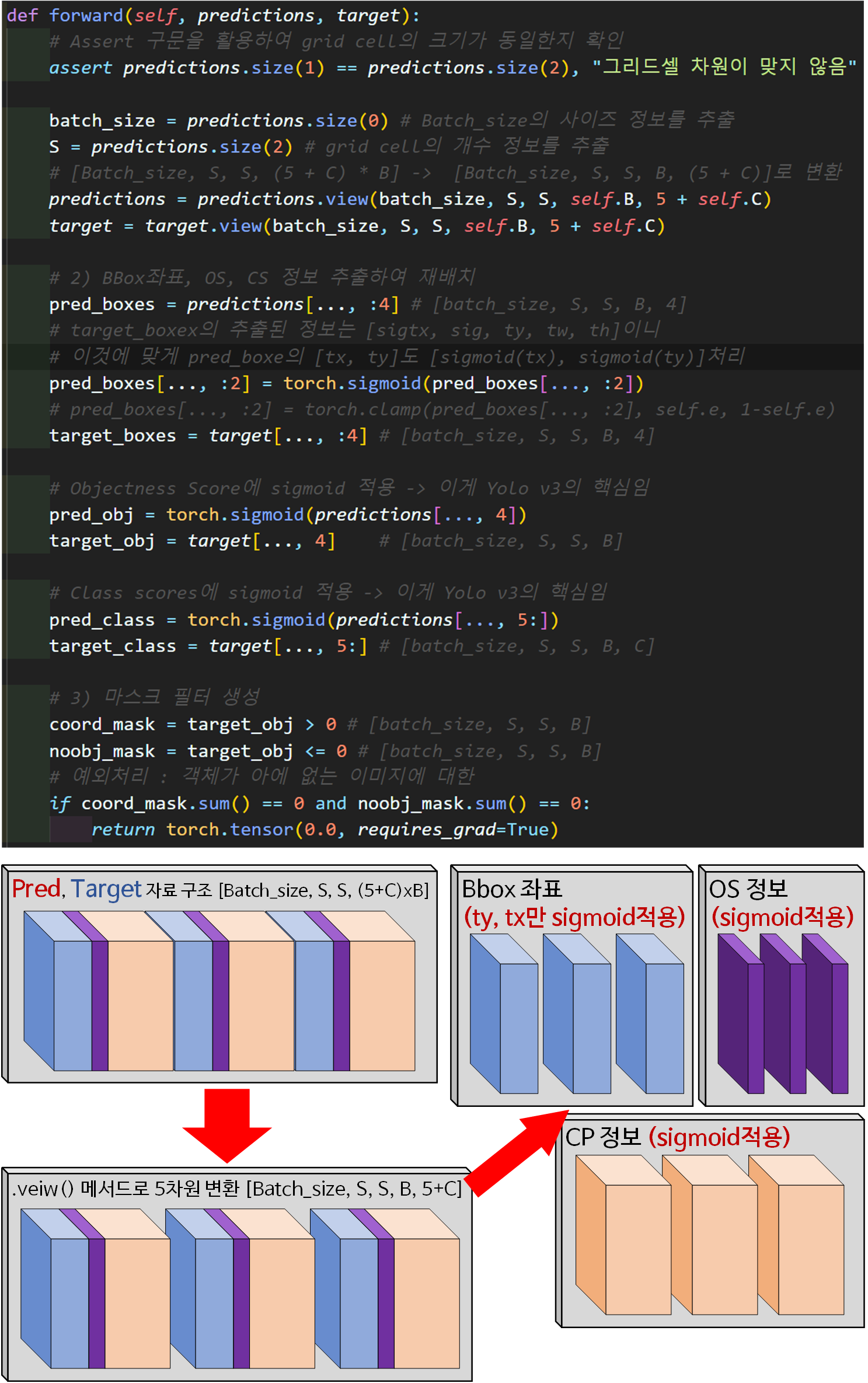
초기에 입력되는 Target, Pred(output)정보는 4차원 Tensor 자료형이나, 이를 view()메서드를 통해
[Batch_size, S, S, B, (5+C)]의 5차원 Tensor로 전환
이후 Bbox 좌표, OS(Objectness Score), CP(Class Probabilities) 3가지 데이터로 정보를 분할한다.
참고로 assert는 가정 설명문으로
정말 만약의 예외상황을 방지기 위한 방어적 프로그래밍 기법으로
그리드 셀의 [SxS] 가 맞지 않을 때는
AssertError에 해당하는 메세지
"그리드셀 차원이 맞지 않음"을 출력하라는 코드이다.
그리고 중요한 점은 [ty, tx], OS, CP는 모두 sigmoid를 적용해야
한다는 점 잊지말자. -> 그래야 값이 [0~1]로 스케일링
[tw, th]는 해당 함수를 적용하지 않는다.
OS, CP는 향후 적용하는 BCE함수가 제대로 동작하게끔 하기 위해,
[ty, tx]는 원활하게 [by, bx] [ty, tx] 좌표변환을 수행하려면 정규화를 위해 sigmoid를 적용한다 보면 된다.
3) 마스크 필터 생성
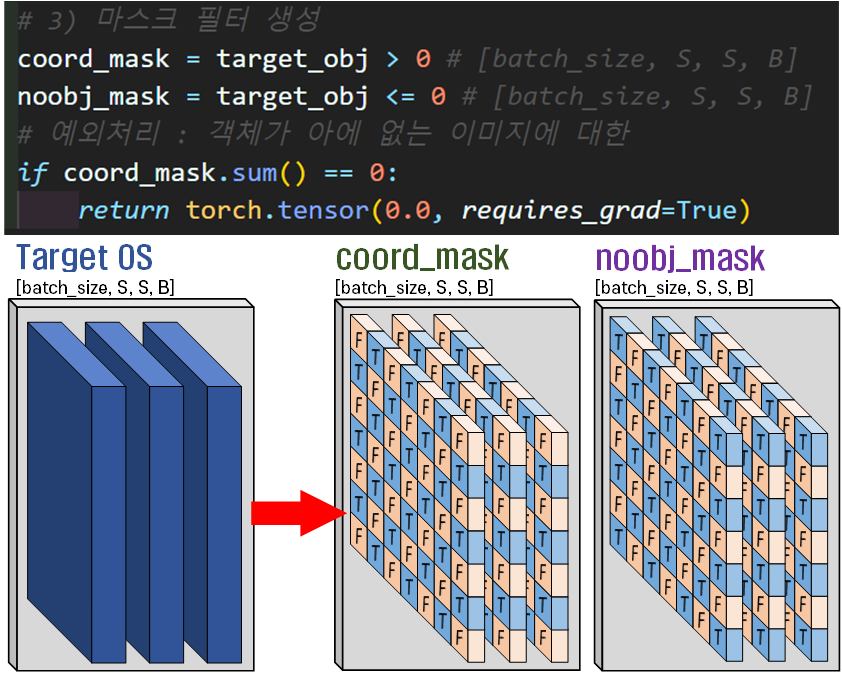 다음으로 필터링을 수행하기 위한 마스크 필터
다음으로 필터링을 수행하기 위한 마스크 필터 coord_mask, noobj_mask 2개를 생성하고 생성방식은 이전과 동일한 방식이다.
그리고 이미지에 객체정보가 아에 없는 경우를 대처하기 위한
예외처리 코드로 if가 동작한다 보면 된다.
4), 5) Bbox의 필터링 + Localization Loss 연산
 앞서 3) 항목에서 마스크를 생성했으니 이전과 동일하게
앞서 3) 항목에서 마스크를 생성했으니 이전과 동일하게
해당 마스크로 데이터를 필터링 후 Localization Loss연산을 수행한다.
여기서 마스크 필터의 차원이 [Batch_size, S, S, B]로 되어 있고
필터링 대상 BBox의 차원이 [Batch_size, S, S, B, 4]이니
마스크 필터의 차원을 맞추기 위해 unsqueeze(), expand_as() 두개의 메서드를 사용했다.
6), 7) OS의 필터링 + Objectness Loss 연산
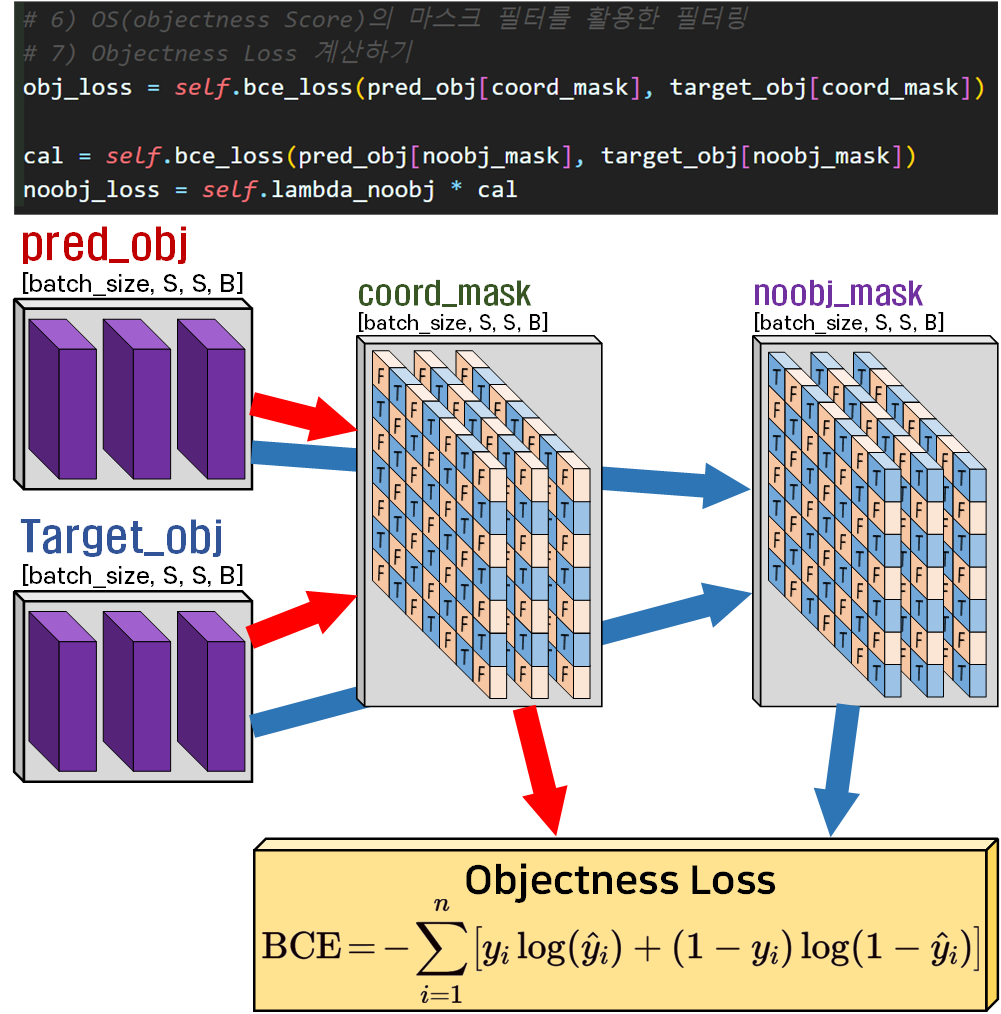 OS 정보를 기반으로 Objectness Loss을 연산하는데는 2종의 필터를 사용해 마스킹하는 것을 유의하도록 하자.
OS 정보를 기반으로 Objectness Loss을 연산하는데는 2종의 필터를 사용해 마스킹하는 것을 유의하도록 하자.
8) 9) CP의 필터링 + Classification Loss 연산
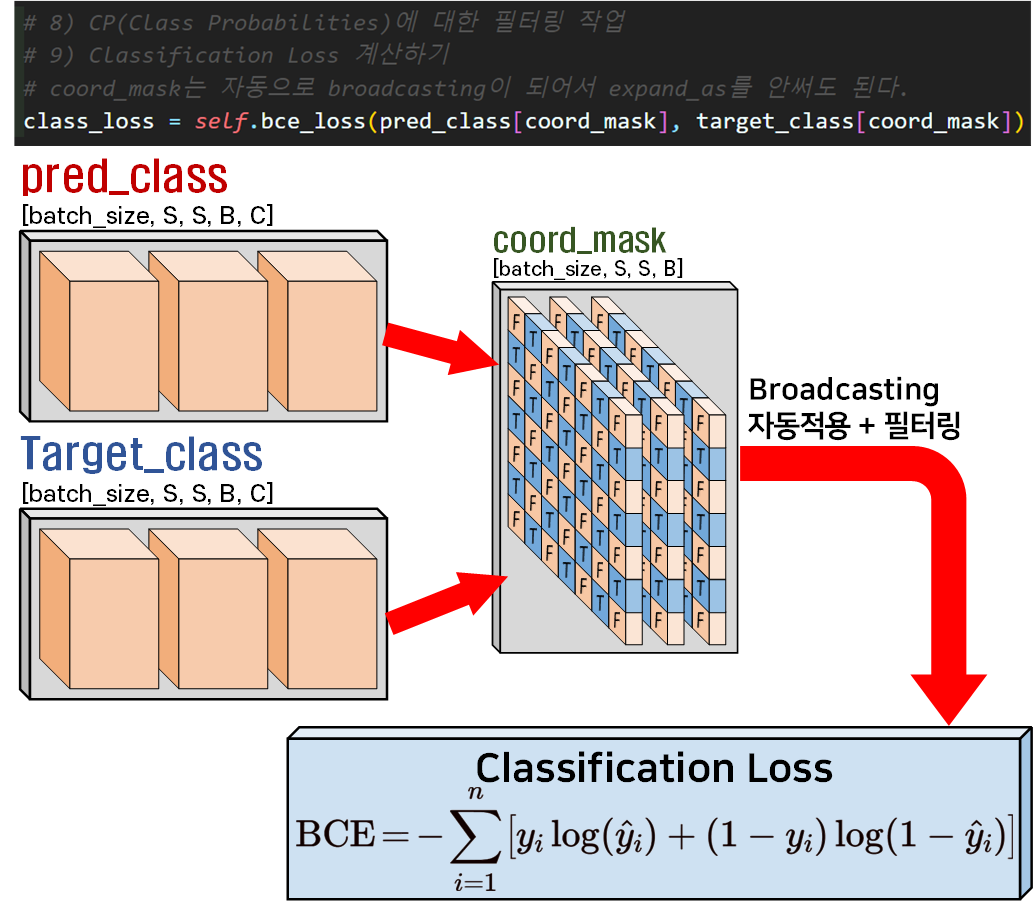 마지막 CP정보를 활용한 Classification Loss연산에는
마지막 CP정보를 활용한 Classification Loss연산에는
4), 5) Bbox의 필터링 + Localization Loss 연산에서 수행한
coord_mask의 차원변환 과정을 생략했는데
자동으로 boradcasting되서 필터링이 적용된다.
따지고 보면 4) 5)에서 차원변환 작업도 안해도 되지만
이런 방식도 있다... 라고 알아두자는 차원에서 기재하였다.
2.1 Yolo v3 Loss 함수 검증
# 예시: YOLOv3 모델의 출력값 (3개 스케일)
output_1 = torch.rand(1, 52, 52, 255)
output_2 = torch.rand(1, 26, 26, 255)
output_3 = torch.rand(1, 13, 13, 255)
# 타겟 텐서도 예시로 생성
target_1 = torch.rand(1, 52, 52, 255)
target_2 = torch.rand(1, 26, 26, 255)
target_3 = torch.rand(1, 13, 13, 255)# YOLOv3 손실 함수 인스턴스 생성
yolov3_loss = Yolov3Loss(B=3, C=80) # B와 C 값 설정# 각 출력값과 타겟값에 대해 손실 계산
loss_1 = yolov3_loss(output_1, target_1)
loss_2 = yolov3_loss(output_2, target_2)
loss_3 = yolov3_loss(output_3, target_3)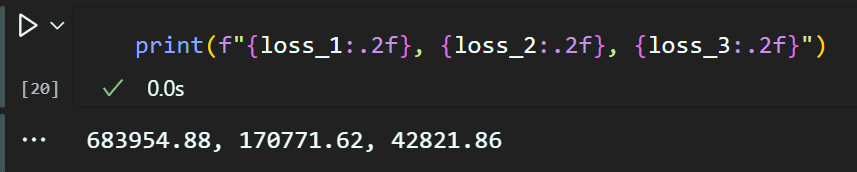 임의의
임의의 Output값과 Target값을 생성 후 Yolo v3 Loss 함수에 입력해서
전체적인 연산이 잘 동작하는지 검증하면
이제 이 과정은 끝난것이라 보면 된다.
3. COCO 데이터셋 개요
COCO(Common Objects in Context) 데이터셋은 Pascal VOC데이터셋과 같이 CV 연구에 자주 사용되는 데이터 셋이다.
 데이터셋의 관리는 Microsoft에서 맡고 있으며,
데이터셋의 관리는 Microsoft에서 맡고 있으며,
해당 데이터셋을 관리하기 위한 전용 API인 FIFTYONE을 제공하고 있고
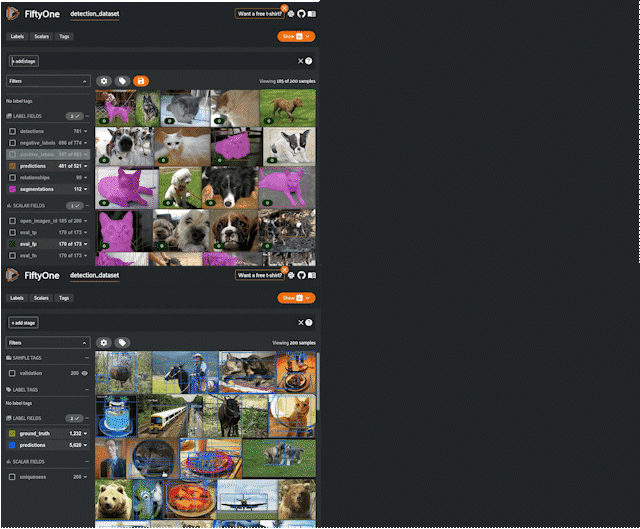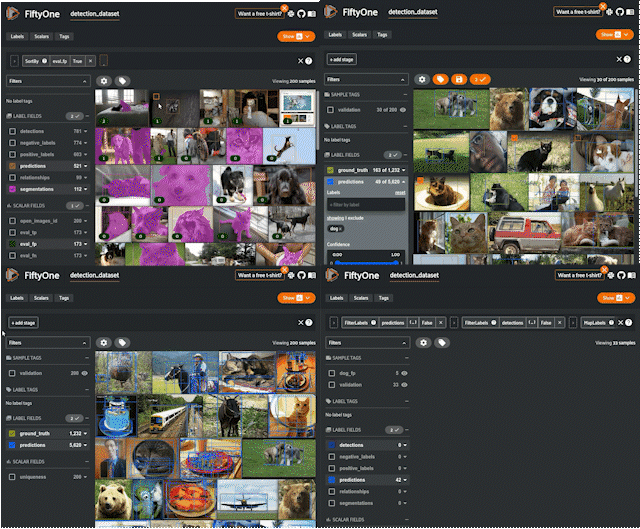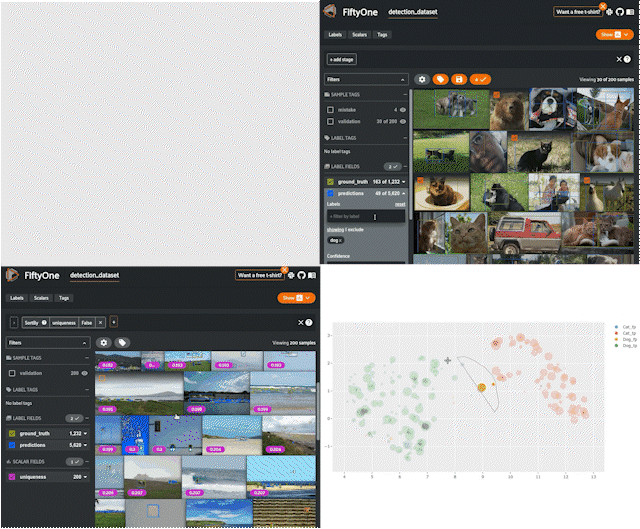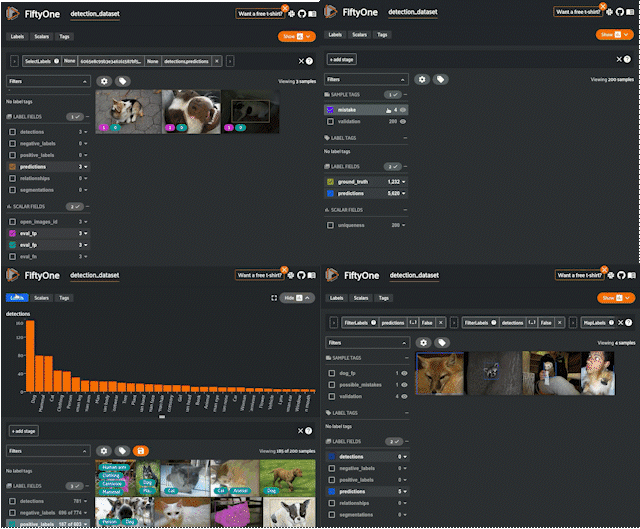 위 사진처럼 다양한 기능을 통해 데이터셋 관리 및 추출이 가능하다.
위 사진처럼 다양한 기능을 통해 데이터셋 관리 및 추출이 가능하다.
이것말고도 COCO API, MASK API를 제공하고 있는데
필자는 COCO API를 통해 데이터셋의 다운로드 및 관리를 수행하고자 한다.
3.1 COCO API

위 COCO API의 설치는 예전에는 무언가 좀 더 복잡하게 진행되었던 것 같지만 현재 시점에서는 CMD창에서 아래의 명령어만 수행하면 된다.
! pip install pycocotools위 명령어를 통해 COCO API를 설치하고 Python에서
아래의 라이브러리를 추가하면 곧바로 사용이 가능하다
from pycocotools.coco import COCO위 라이브러리를 활용하여 데이터를 다운로드 받는 방식은 아래와 같다.

 첫번째 작업은 Anno파일의 다운로드를 수행하는 것이다.
첫번째 작업은 Anno파일의 다운로드를 수행하는 것이다.
Train용으로 사용할 데이터는 '2014 Val Images'
Val용으로 사용할 데이터는 '2017 Val Images'
을 사용하고자 한다.
용량이 많이 나가는 문제도 있고
Backbone의 경우 Pre-trained model로 작업을 완료했으니
Downstream task를 수행하는데 Fine-turning dataset을 큰 데이터셋을 사용할 필요성은 없으리라 생각한다.
그리고 검은색으로 줄을 그은 데이터셋은 Boundingbox 데이터를
제공하지 않는 단순 이미지 파일이다.
멋 모르고 이 test에 해당하는 데이터셋 다운받았다가 anno파일 열었더니 아무것도 없어서 시간만 낭비햇....

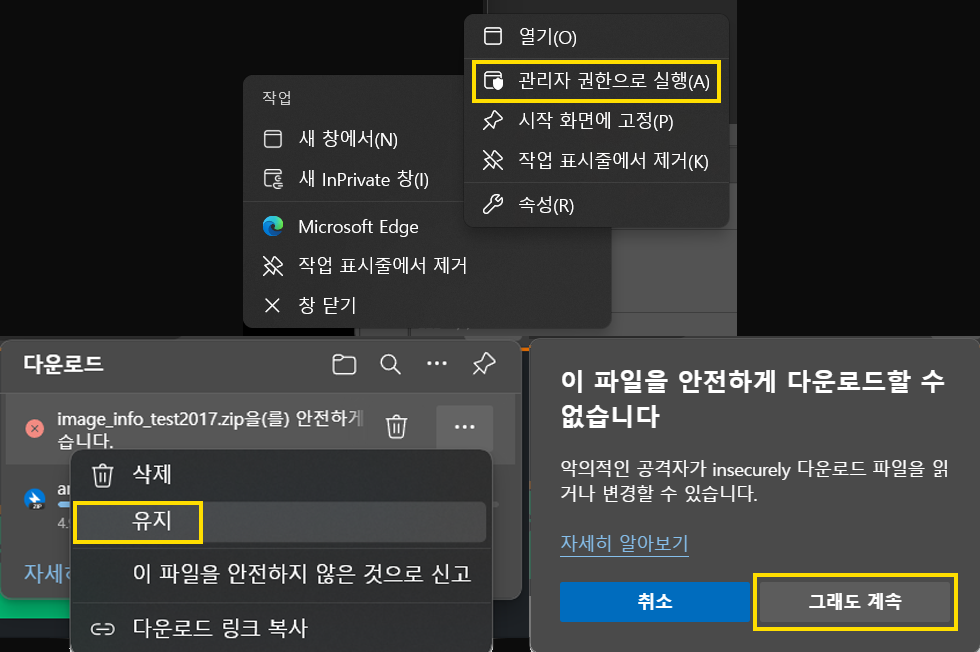 참고로 해당 파일의 경우 그냥 다운로드 버튼 링크 있다고 눌러대면
참고로 해당 파일의 경우 그냥 다운로드 버튼 링크 있다고 눌러대면
아무런 반응도 안한다.
브라우저를 '관리자 권한'으로 실행하고 안전하지 않은 파일도 다운로드 한다고 설정해줘야 재대로 Anno파일을 다운로드 받을 수 있다.
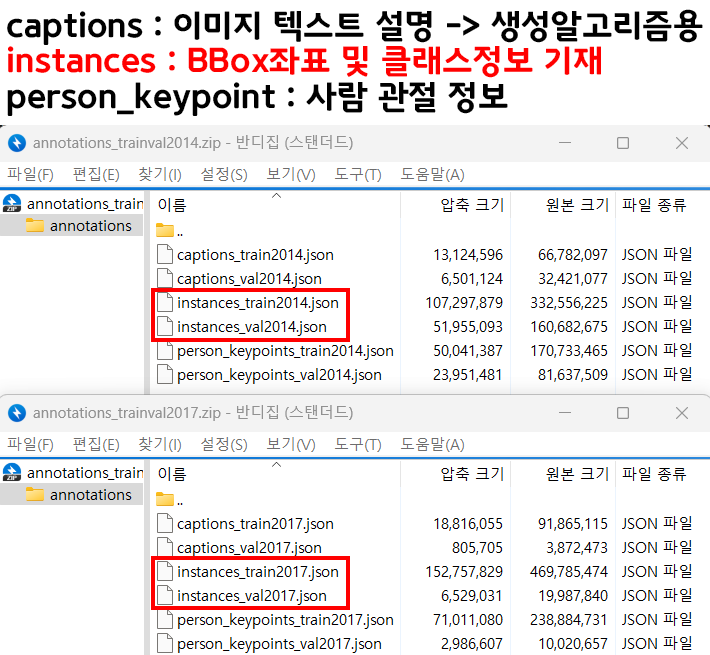 여러 종류의 json파일이 나를 반기지만 이번 Yolo v3 API구현에 필요한 파일은
여러 종류의 json파일이 나를 반기지만 이번 Yolo v3 API구현에 필요한 파일은 instances_val파일이다.
이제 코드를 작성해서 이미지 파일을 다운로드 받아보자.
from pycocotools.coco import COCO
import os
import requests
from tqdm import tqdmanno_dir = '[압축풀고 anno.json 파일이 위치한 폴더]'
train_dir = '[훈련용 이미지를 다운받아 저장할 폴더]'
val_dir = '[검증용 이미지를 다운받아 저장할 폴더]'# 예의있게 폴더는 미리 만들어두자
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)# 내 프로젝트에서 훈련용으로 사용할 이미지는 instances_val2014 이다.
# 해당 데이터셋은 총 6GB정도에 4만여장 정도 이미지가 포함되어 있음
coco_train = COCO(os.path.join(anno_dir, 'instances_val2014.json'))
# 내 프로젝트에서 검증용으로 사용할 이미지는 instances_val2017 이다.
# 해당 데이터셋은 약 1GB정도에 5천장 정도 이미지가 포함되어 있음
coco_val = COCO(os.path.join(anno_dir, 'instances_val2017.json'))# 훈련용으로 쓸 이미지의 ID정보만 추출함
train_img_ids = coco_train.getImgIds()
# 검증용으로 쓸 이미지의 ID정보만 추출함
val_img_ids = coco_val.getImgIds()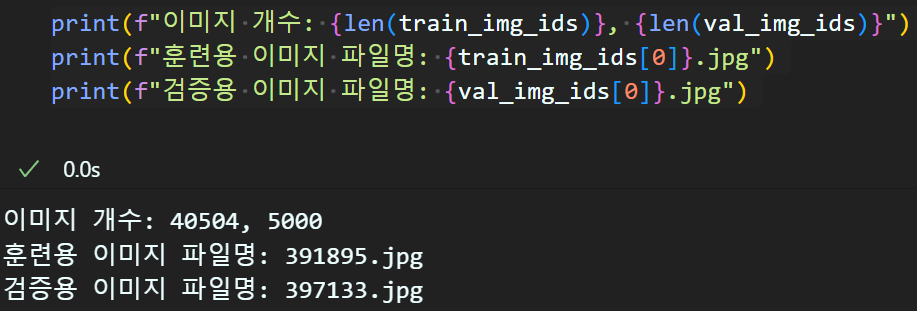 위
위 getImgIds()메서드는 딱 이미지 이름만 추출한다.
그리고 이제 다운로드를 실행하면 되는데 아래와 같이 함수를 선언하고 수행하도록 하자
def down_img(coco, img_ids, save_dir):
for img_id in tqdm(img_ids):
img_info = coco.loadImgs(img_id)[0]
img_url = img_info['coco_url']
img_path = os.path.join(save_dir, img_info['file_name'])
# 이미지를 이미 다운받았으면 넘어간다.
if os.path.exists(img_path):
continue
# 다운 안받은 이미지는 다운로드 실행
img_data = requests.get(img_url).content
with open(img_path, 'wb') as handler:
handler.write(img_data)
# Download images
down_img(coco_train, train_img_ids, train_dir)
down_img(coco_val, val_img_ids, val_dir) 이게 지금 포스팅을 하면서 다시 다운로드 받다 보니까
이게 지금 포스팅을 하면서 다시 다운로드 받다 보니까
파일을 엄청 빨리 다운받은 것처럼 보이지
실제로는 한나절은 족히 걸린다.
따라서 위 명령어로 이미지 파일을 다운받는 것은 좀.. 비 효율적이고 홈페이지에서 쌩으로 zip파일 다운받아서 압축푸는게 훨 낫다
다들 고수처럼 코드를 짜자...
3.2 COCO API 메서드 탐구
원래는 짧게 하고 넘어가려 했으나 내용이 중요해서 좀 더 포스팅을 하고자 한다.
우선 첫번째로
# 훈련용으로 쓸 이미지의 ID정보만 추출함
train_img_ids = coco_train.getImgIds()
# 검증용으로 쓸 이미지의 ID정보만 추출함
val_img_ids = coco_val.getImgIds()이 코드를 통해 train_img_ids, val_img_ids에는
이미지의 ID정보 만 리스트로 기재되고 있다.
이제 이 ID정보를 받아서 이미지의 info 정보를 출력해보자
img_info = coco_train.loadImgs(train_img_ids[0])[0]
for key, value in img_info.items():
print(f"{key}: {value}")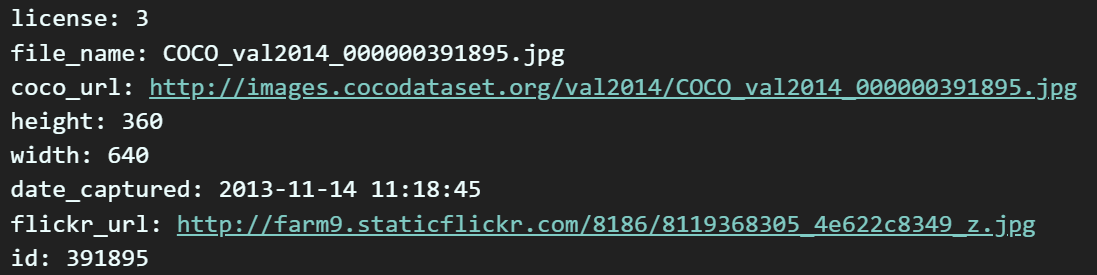
load_imgs 메서드에 이미지의 ID중 하나를 인자로 넘기면
출력되는 정보는 딕셔너리 자료형으로 되어있다.
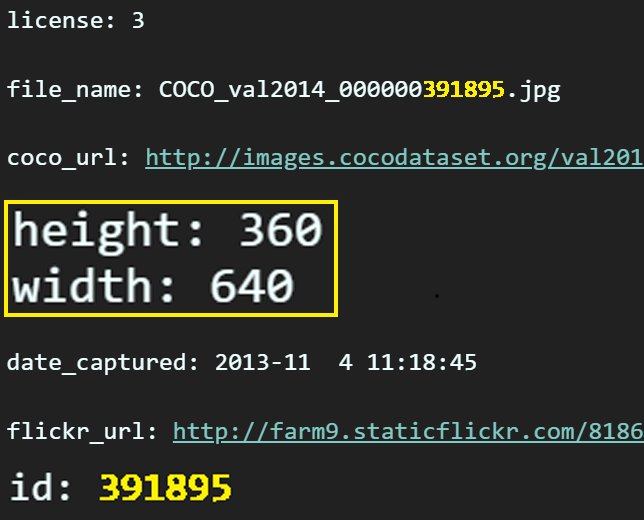 img_info를 통해 얻을 수 있는 의미있는 데이터는
img_info를 통해 얻을 수 있는 의미있는 데이터는
height, width, id이 3가지 정보다.
다음으로 getAnnIds 메서드이다.
ann_ids = coco_train.getAnnIds(img_info['id'])
print(ann_ids)[151091, 202758, 1260346, 1766676]해당 메서드는 img_info의 id정보(train_img_ids[0]와 같은값)를 입력 할 시 리스트로 정리된 숫자정보가 출력되는데
이는 해당 이미지와 연계된 Anno데이터의 헤드값이다.
지금 list로 출력된 데이터가 4개이니
해당 이미지에는 객체가 4개가 있음을 유추해 볼 수 있다.
anns = coco_train.loadAnns(ann_ids)앞서 ann_ids여기에 저장된 데이터가 리스트의 Anno이기에 loadAnns메서드로 리스트 내 원소값의 Anno 정보를 다 불러와야 한다.
이때 출력되는 anns의 자료형은
[딕셔너리, 딕셔너리, 딕셔너리....]
이런식으로 리스트 자료형에, 각 원소는 딕셔너리 형태로 되어있다.
해당 원소의 딕셔너리의 key값은 아래와 같다.
segmentation, area, iscrowd, image_id, bbox, category_id, id,이 중 segmentation항목은 출력되는 픽셀정보가 엄청 많아서 해당 정보만 걸러내고 데이터를 출력하겠다.
for ann in anns:
for key, value in ann.items():
if key == "segmentation":
continue
print(f"{key}: {value}")
print("\n")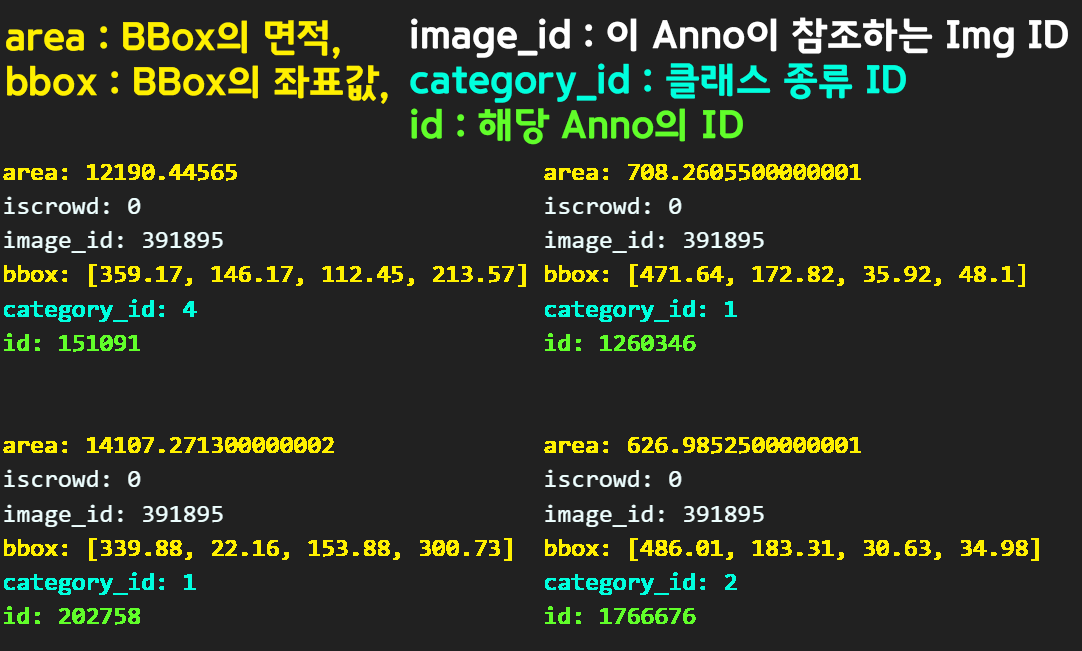
설명이 글의 나열이기에 알아보기가 참 힘들다
이제 COCO API를 통해 데이터를 취득하는 과정을 도식화 해보자
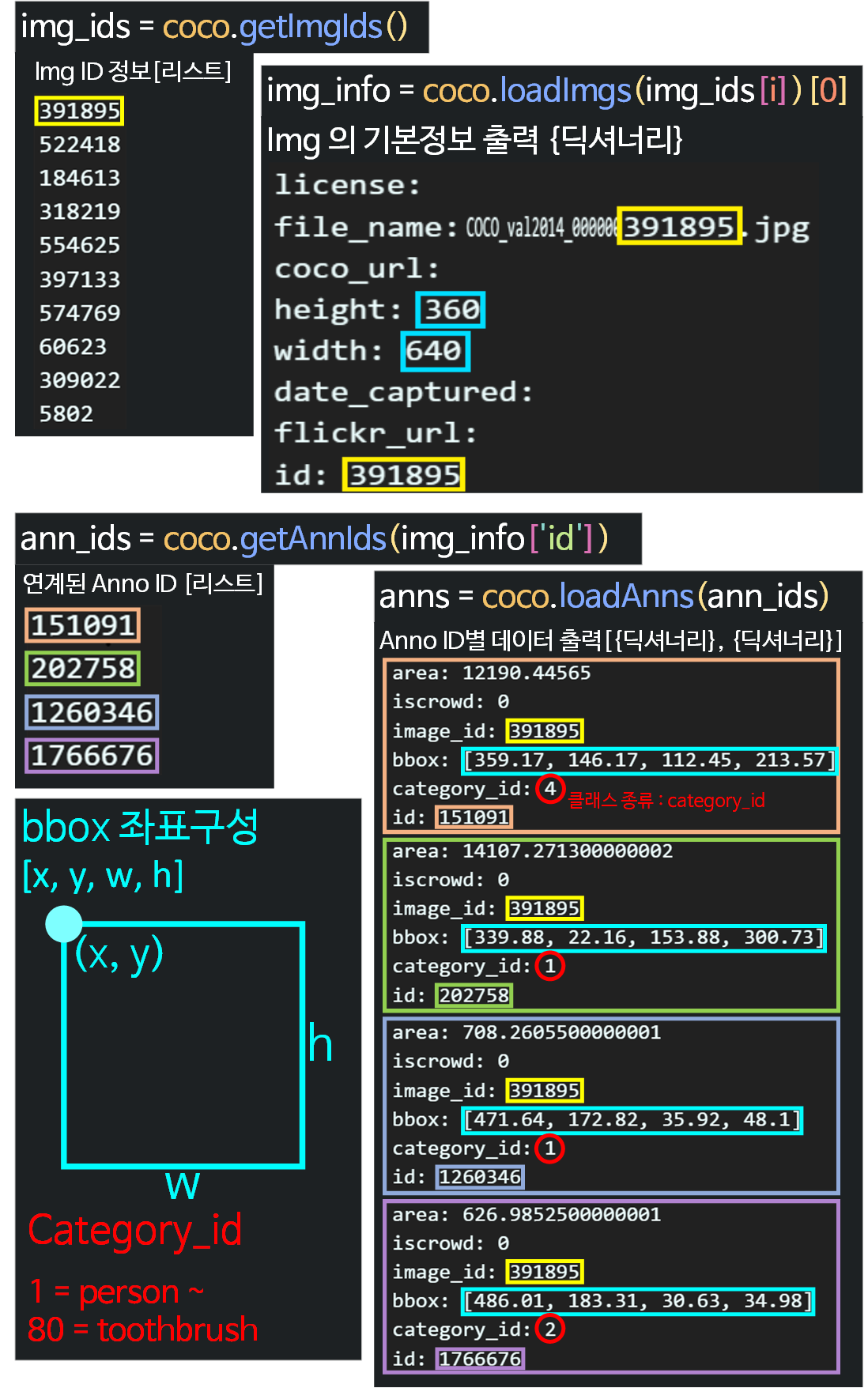 위 사진처럼 4개의 메서드
위 사진처럼 4개의 메서드 getImgIds(), loadImgs(), getAnnIds(), loadAnns()를 활용해야만
진정으로 COCO dataset의 Img와 Anno 정보를
핸들링 하고 있다...
이렇게 볼 수 있겠다.
마지막으로 정보 핸들링이 끝났으니 실제 이미지에 BBox를 도식화 해보는 것으로 검증을 완료하겠다.
 Train용 '2014 Val Images'
Train용 '2014 Val Images'
Val용 '2017 Val Images' 모두 정상적으로 이미지 출력 및 해당 이미지에 대한 Bounding box를 그리고 있다.
이제 데이터셋 생성(Label Matrix 생성) 및 훈련/검증/실행
에 관한 포스트를 진행하도록 하겠다.
추가사항
coco dataset의 Category_id를 실제로 출력해보면 1~80의 범위를 가져야 하는데
실제로는 1~90의 범위를 갖는다.
이것때문에 좀 헤멧는데 내부에서 10개의 사용하지 않는 class가 존재한다
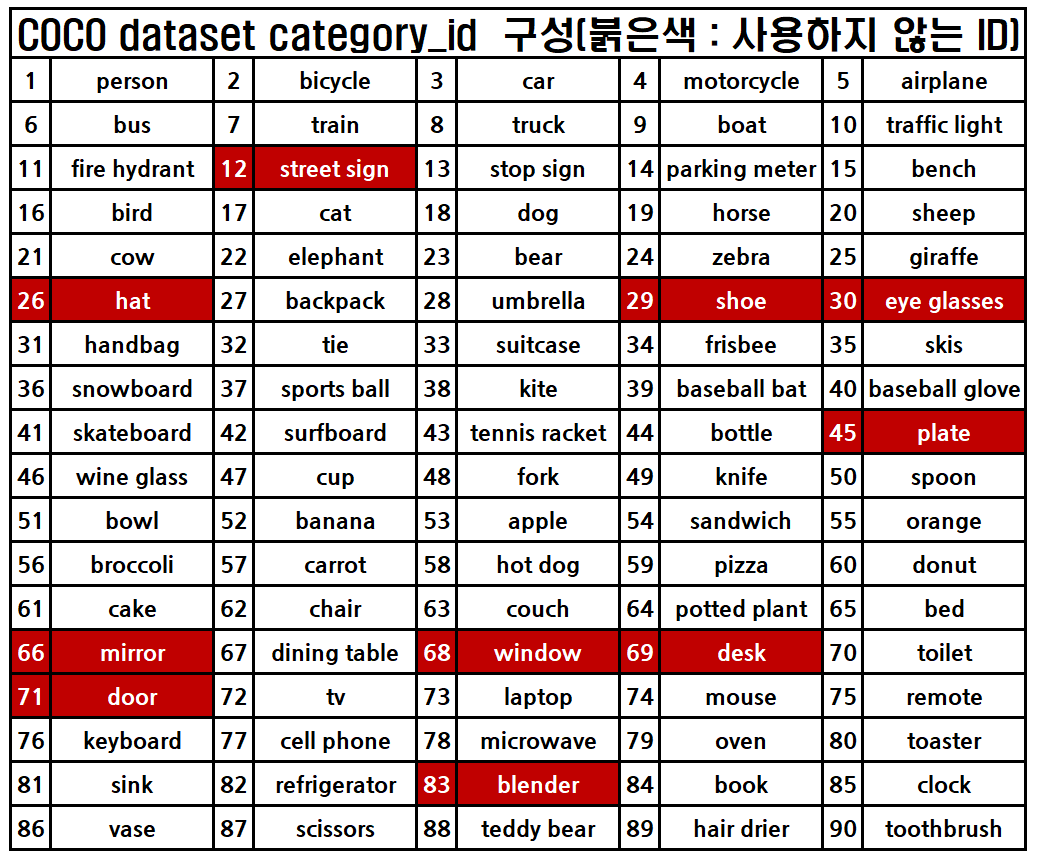
위 사진처럼 [12, 26, 29, 30, 45, 66, 68, 69, 71, 83] 번호의 클래스는 사용하지 않는 정보이며,
실제로도 데이터셋에도 해당 정보로 라벨링된 데이터는 없다.
문제는 이 자리만 차지하는 번호들 때문에 Category_id의 최대값이 90이니 이걸 적절하게 처리해주는 코드를 작성해야한다.
그래서 무작정 C=80으로 선언하고 idx 찾는 것을 Category_id으로 해버리면 낭패가 발생한다.
