
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. COCO 데이터셋 전처리
이전 포스트 인공지능 고급(시각) 강의 예습 - 22. (3) Yolo v3 Loss + Coco 데이터셋 에서 COCO(Common Objects in Context)에 대한 간단한 소개외 COCO API의 사용 방식에 대해 소개하였다.
따라서 이번 포스트에서는 COCO 데이터셋을 Yolo v3가 받아들일 수 있는 데이터 전처리 작업을 수행하고자 한다.
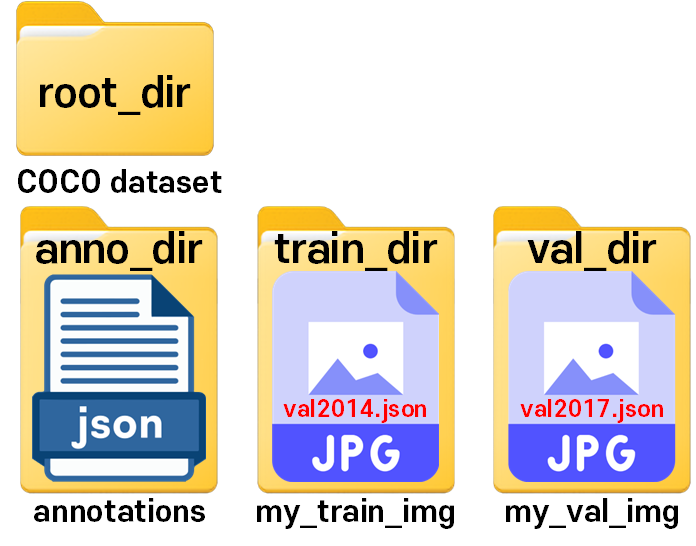 폴더의 구성은 위 사진과 같이 root_dir의 하위 폴더로
폴더의 구성은 위 사진과 같이 root_dir의 하위 폴더로
annotations, my_train_img, my_val_img 배치하여
사용하고자 하는 Anno, Img의 폴더구성을 진행했다.
이제 Yolo v3의 입력 요구사항을 만족하는 이걸 또 만들면 된다
이걸 또 만들면 된다

아우 지겨워
1)
__init__메서드
root_dir = '[COCO dataset]폴더'def __init__(self, root, img_set=None, transform=None,
S=[52, 26, 13], B=3, C=80,
anchor = None):
self.root = root #COCO 데이터셋의 메인 폴더 경로
self.img_set = img_set
self.transform = transform
self.S_list = S # Gird Cell사이즈 -> [13, 26, 52] -> 인자값으로 받기
self.B = B # anchorbox의 개수 : 3
self.C = C # COCO데이터셋의 클래스 개수 : 80
# Anchor_box_list를 관리하기 위한 변수
self.anchor = anchor
self.anno_path = os.path.join(root, 'annotations')
if img_set == 'train':
self.img_dir = os.path.join(root, 'my_train_img')
self.coco = COCO(os.path.join(self.anno_path, 'instances_val2014.json'))
elif img_set == 'val':
self.img_dir = os.path.join(root, 'my_val_img')
self.coco = COCO(os.path.join(self.anno_path, 'instances_val2017.json'))
elif img_set == 'test':
pass
else:
raise ValueError("이미지 모드 확인하기")
# 모드별 이미지 ID리스트 불러오기
self.img_ids = self.coco.getImgIds()CustomDataset을 구성하는데 필수적으로 사용되는
Attriibute인
root : 메인 데이터셋 경로
img_set : 해당 데이터셋을 Train? Val?, Test?
transform : 데이터셋의 전처리 방법론 적용을 위한 변수
3가지를 선언하고
S_list, B, C는 각각 Grid cell 크기값, Anchor box개수, COCO 데이터셋 클래스 종류
를 받는다.
참고로 C와 관련된 값으로 COCO dataset category_id값이 문제가 좀 있는데
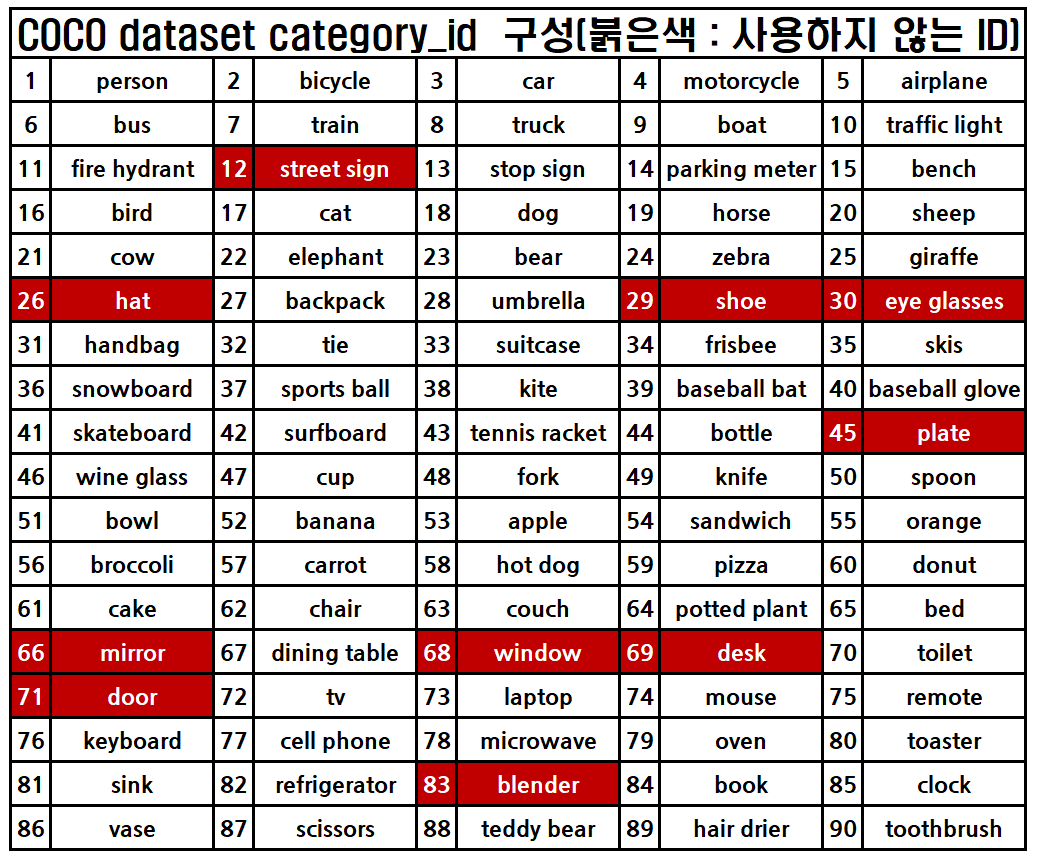 이전 포스트에서도 언급했다 싶이 COCO dataset category_id의 최대값은 COCO클래스 종류인 80이 아니라 10종 더 있는 90까지 되어있으며, 안쓰는
이전 포스트에서도 언급했다 싶이 COCO dataset category_id의 최대값은 COCO클래스 종류인 80이 아니라 10종 더 있는 90까지 되어있으며, 안쓰는 class ID번호가 존재한다.
따라서 이걸 필터링 해줘야 하는데 필터링 하는 코드는 아래와 같다.
# 사용되지 않는 category_id를 제외한 딕셔너리 생성
used_categories = [
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,
23, 24, 25, 27, 28, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44,
46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88,
89, 90
]
real_class_idx = {cat_id: idx for idx, cat_id in enumerate(used_categories)}위 코드로 필터링된 real_class_idx의 정보를 추출해서 category_id의 이빨 빠진 class ID에 대응하고자 한다.
그 다음
self.anchor = anchor이 변수에 대한 내용은 후술하겠다.
img_set과 anno_path를 섞어서
COCO API를 핸들링하는 변수인 self.coco을 인스턴스화 하고
img_set의 모드에 맞춰 적합한 anno파일을 불러온다.
마지막으로 객체화가 완료된 self.coco를 기반으로
Img파일 ID리스트를 저장하는 img_ids를 정의한다.
2)
__len__,__str__메서드
def __len__(self):
return len(self.img_ids)
#예의 바르게 해당 클래스의 실행 결과를 불러오자
def __str__(self):
if len(self.img_ids) == 0:
message = f"Img 폴더 내 파일 못찾음"
else:
message = f"Img 폴더 찾은 *.jpg 개수: {len(self.img_ids)}"
return f"{message}"예의 있는 코드인 __str__메서드랑 필수 Method인 __len__은 img_ids의 리스트 길이정보를 반환하면 된다.
3)
__getitem__메서드
def __getitem__(self, idx):
img_id = self.img_ids[idx]
ann_ids = self.coco.getAnnIds(imgIds=img_id)
# ann_ids는 불러온 이미지와 관련된 Anno 리스트를 가져온다
anns = self.coco.loadAnns(ann_ids)
# 이미지의 기본 정보 추출하기 -> [0]붙이는거 까먹지말자
img_info = self.coco.loadImgs(img_id)[0]
# 찾은 이미지에 맞는 파일이름을 찾아서 출력할 Image에 할당
img_path = os.path.join(self.img_dir, img_info['file_name'])
image = Image.open(img_path).convert("RGB")
# 라벨 메트릭스 생성 [S, S, C+5=85]로 생성을 먼저함
label_matrix = [
torch.zeros((S, S, self.C+5)) for S in self.S_list
]
# 이제 Anno주석정보를 라벨 매트릭스에 기입하기
for ann in anns:
bbox = ann['bbox']
# CP는 Class Probability이니 = Class ID
CP_idx = real_class_idx[ann['category_id']]
x, y, w, h = bbox
# bbox 좌표 정규화
bx = (x + w / 2) / img_info['width']
by = (y + h / 2) / img_info['height']
bw = w / img_info['width']
bh = h / img_info['height']
#정규좌표평면에서 center point가 위치하는 그리드셀 탐색
for i, S in enumerate(self.S_list):
# 정규화된 좌표평면 상에서 grid_y, x의 idx를 구해야 한다.
grid_x = int(bx * S)
grid_y = int(by * S)
#탐색한 그리드셀이 비어있으면 아래 정보 기입
if label_matrix[i][grid_y, grid_x, 4] == 0:
# OS(Objectness Score) 정보 기입
label_matrix[i][grid_y, grid_x, 4] = 1
# BBox(bx, by, bw, bh) 정보 기입
label_matrix[i][grid_y, grid_x, :4] = torch.tensor(
[bx, by, bw, bh]
)
# CP(Class Probability) 정보 기입
label_matrix[i][grid_y, grid_x, 5 + CP_idx] = 1이 부분의 코드에서 Img 파일을 핸들링하는 코드는
# 이미지의 기본 정보 추출하기 -> [0]붙이는거 까먹지말자
img_info = self.coco.loadImgs(img_id)[0]
# 찾은 이미지에 맞는 파일이름을 찾아서 출력할 Image에 할당
img_path = os.path.join(self.img_dir, img_info['file_name'])
image = Image.open(img_path).convert("RGB")이 3줄로 끝나니까
가장 중요한 Label Matrix를 만드는 과정을 도식으로 설명하겠다.
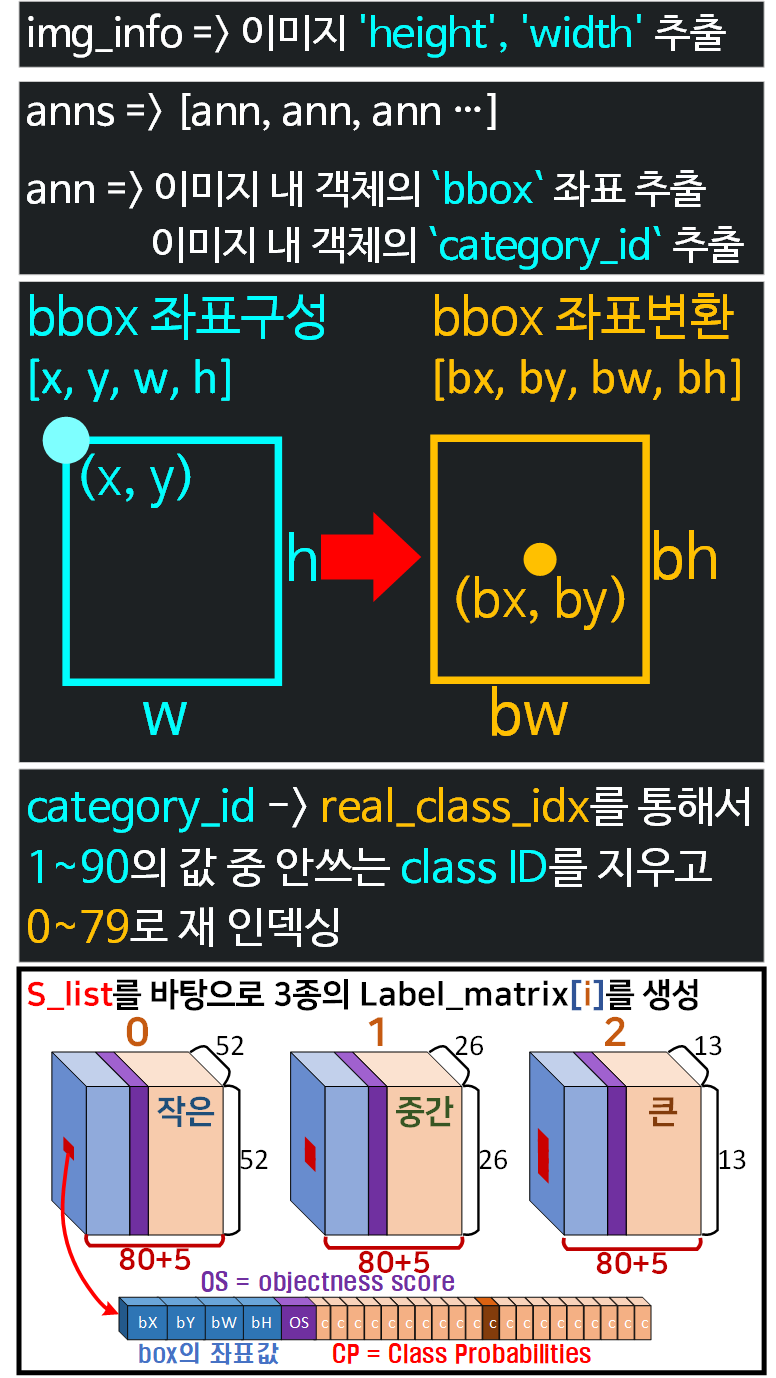
여기서 이미지의 좌표평면을 정규 좌표평면으로 스케일링 하는것을 잊지말자
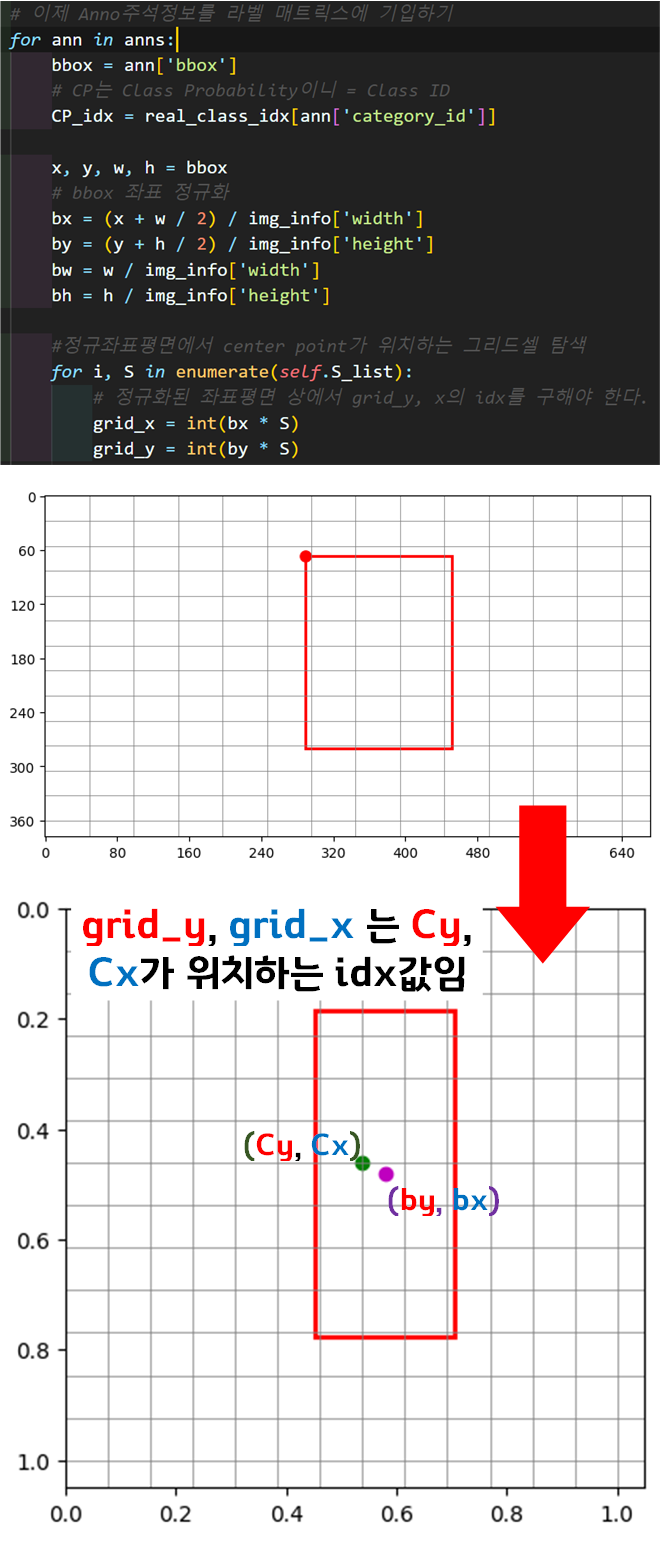
이제 CustomDataset을 인스턴스화 해보자
1.1 만들다 만 CustomDataset
import os
import torch
from pycocotools.coco import COCO
from torch.utils.data import Dataset
from PIL import Imageroot_dir = '[COCO dataset]루트 디렉토리 경로'
# 사용되지 않는 category_id를 제외한 딕셔너리 생성
used_categories = [
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,
23, 24, 25, 27, 28, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44,
46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88,
89, 90
]
real_class_idx = {cat_id: idx for idx, cat_id in enumerate(used_categories)}class CustomDataset(Dataset):
def __init__(self, root, img_set=None, transform=None,
S=[52, 26, 13], B=3, C=80,
anchor = None):
self.root = root #COCO 데이터셋의 메인 폴더 경로
self.img_set = img_set
self.transform = transform
self.S_list = S # Gird Cell사이즈 -> [13, 26, 52] -> 인자값으로 받기
self.B = B # anchorbox의 개수 : 3
self.C = C # COCO데이터셋의 클래스 개수 : 80
# Anchor_box_list를 관리하기 위한 변수
self.anchor = anchor
self.anno_path = os.path.join(root, 'annotations')
if img_set == 'train':
self.img_dir = os.path.join(root, 'my_train_img')
self.coco = COCO(os.path.join(self.anno_path, 'instances_val2014.json'))
elif img_set == 'val':
self.img_dir = os.path.join(root, 'my_val_img')
self.coco = COCO(os.path.join(self.anno_path, 'instances_val2017.json'))
elif img_set == 'test':
pass
else:
raise ValueError("이미지 모드 확인하기")
# 모드별 이미지 ID리스트 불러오기
self.img_ids = self.coco.getImgIds()
def __len__(self):
return len(self.img_ids)
#예의 바르게 해당 클래스의 실행 결과를 불러오자
def __str__(self):
if len(self.img_ids) == 0:
message = f"Img 폴더 내 파일 못찾음"
else:
message = f"Img 폴더 찾은 *.jpg 개수: {len(self.img_ids)}"
return f"{message}"
def __getitem__(self, idx):
img_id = self.img_ids[idx]
ann_ids = self.coco.getAnnIds(imgIds=img_id)
# ann_ids는 불러온 이미지와 관련된 Anno 리스트를 가져온다
anns = self.coco.loadAnns(ann_ids)
# 이미지의 기본 정보 추출하기 -> [0]붙이는거 까먹지말자
img_info = self.coco.loadImgs(img_id)[0]
# 찾은 이미지에 맞는 파일이름을 찾아서 출력할 Image에 할당
img_path = os.path.join(self.img_dir, img_info['file_name'])
image = Image.open(img_path).convert("RGB")
# 라벨 메트릭스 생성 [S, S, C+5=85]로 생성을 먼저함
label_matrix = [
torch.zeros((S, S, self.C+5)) for S in self.S_list
]
# 이제 Anno주석정보를 라벨 매트릭스에 기입하기
for ann in anns:
bbox = ann['bbox']
# CP는 Class Probability이니 = Class ID
CP_idx = real_class_idx[ann['category_id']]
x, y, w, h = bbox
# bbox 좌표 정규화
bx = (x + w / 2) / img_info['width']
by = (y + h / 2) / img_info['height']
bw = w / img_info['width']
bh = h / img_info['height']
#정규좌표평면에서 center point가 위치하는 그리드셀 탐색
for i, S in enumerate(self.S_list):
# 정규화된 좌표평면 상에서 grid_y, x의 idx를 구해야 한다.
grid_x = int(bx * S)
grid_y = int(by * S)
#탐색한 그리드셀이 비어있으면 아래 정보 기입
if label_matrix[i][grid_y, grid_x, 4] == 0:
# OS(Objectness Score) 정보 기입
label_matrix[i][grid_y, grid_x, 4] = 1
# BBox(bx, by, bw, bh) 정보 기입
label_matrix[i][grid_y, grid_x, :4] = torch.tensor(
[bx, by, bw, bh]
)
# CP(Class Probability) 정보 기입
label_matrix[i][grid_y, grid_x, 5 + CP_idx] = 1
# 이미지의 전처리 방법론이 수행될 때 label matrix도 같이 업데이트
if self.transform:
image = self.transform(image)
return image, tuple(label_matrix)# 위 CustomDataset의 인스턴스화
train_dataset = CustomDataset(root=root_dir, img_set='train')
test_dataset = CustomDataset(root=root_dir, img_set='val')print(train_dataset) -> Img 폴더 찾은 *.jpg 개수: 40504
print(test_dataset) -> Img 폴더 찾은 *.jpg 개수: 5000img, labels = train_dataset[0]
print(type(labels))
for label in labels:
print(label.shape)<class 'tuple'>
torch.Size([52, 52, 85])
torch.Size([26, 26, 85])
torch.Size([13, 13, 85])이렇게 코드를 반쪽짜리만 만들고 인스턴스화 하는데는 당연한 이유가 존재한다.
2. K-mean Clustering
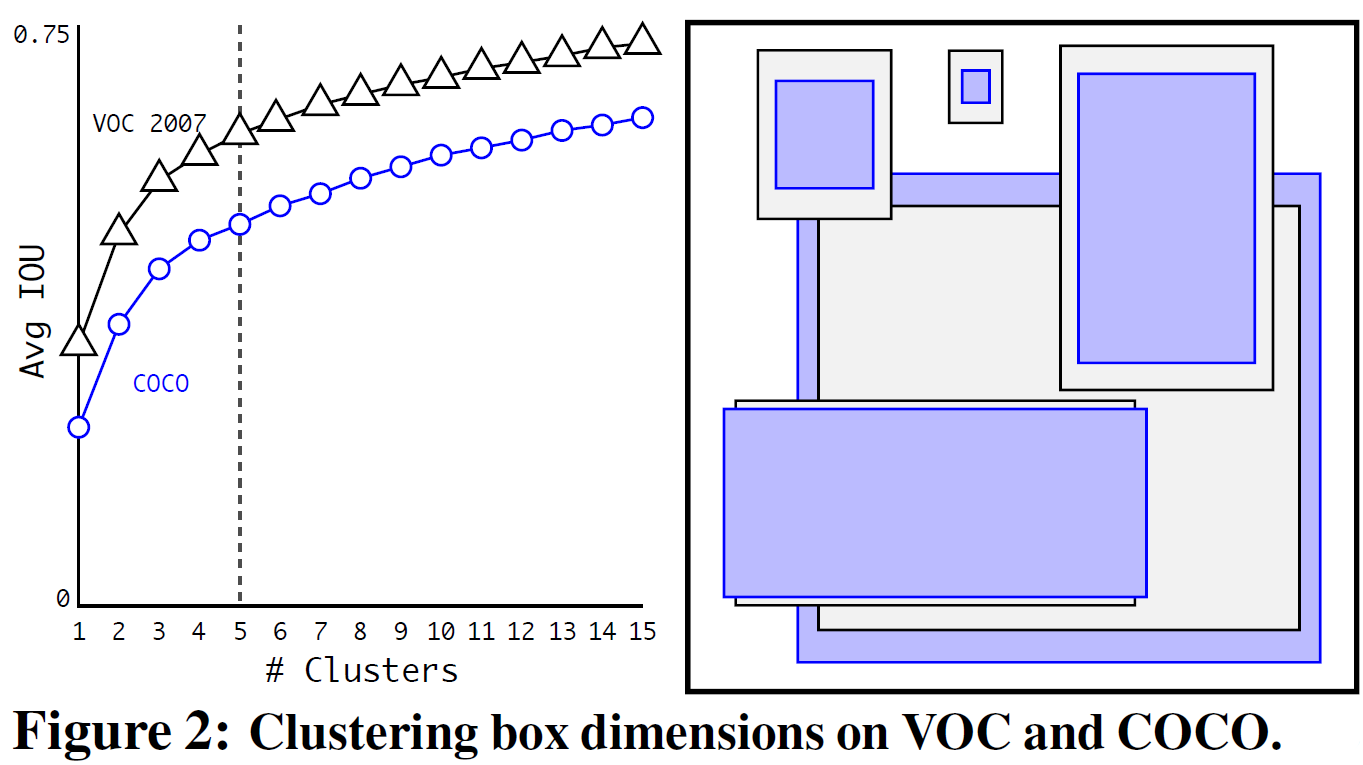 Yolo v2, Yolo v3의 Anchor box List를 만드는
Yolo v2, Yolo v3의 Anchor box List를 만드는
방법론인 K-mean clustering을 수행하기 위해서
반쪽짜리 CustomDataset를 만든것이다.
K-mean clustering의 원리부터 설명하는건 너무 TMI니까 넘어가고

sklearn 라이브러리를 통해 손쉽게 KMeans를 구현이 가능하니 코드첨부를 통해 아래 일련의 코드를 구동하도록 하겠다.
import numpy as np
from sklearn.cluster import KMeans
from tqdm import tqdm #훈련 진행상황 체크# 모든 bbox 정보를 추출하는 함수
def extract_bboxes(dataset):
bboxes = []
for i in tqdm(range(len(dataset))):
# 커스텀데이터셋은 리턴이 img, label이니 img는 뺀다.
_, label_matrix = dataset[i]
for S_idx, S in enumerate(dataset.S_list):
label_mat = label_matrix[S_idx]
# OS정보가 1인 값만 필터링
obj_indices = (label_mat[..., 4] == 1).nonzero(as_tuple=True)
# 필터링 후 [bx, by, bw, bh]에서 bw, bh만 추출
if len(obj_indices[0]) > 0:
bboxes.extend(label_mat[obj_indices][:, 2:4].tolist())
return np.array(bboxes)# bbox 정보 추출
bboxes = extract_bboxes(train_dataset)
print(f"Extracted {len(bboxes)} bounding boxes")
# k-means 클러스터링을 수행하여 9개의 anchor box 추출
kmeans = KMeans(n_clusters=9, random_state=0, n_init='auto').fit(bboxes)
anchors = kmeans.cluster_centers_
# Anchor boxes를 크기 순으로 정렬
areas = anchors[:, 0] * anchors[:, 1]
sorted_indices = np.argsort(areas)
sorted_anchors = anchors[sorted_indices]
print(sorted_anchors)Yolo v3는 9개의 Anchor box가 [3x3]으로 구성되어야 하고
Small -> Medium -> Large 순으로 배치를 해야 하기에
찾아낸 Anchor box의 리스트도 sorted를 통해 정렬을 진행한다.
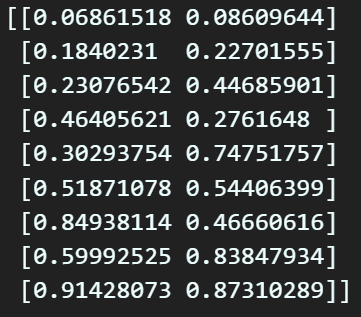
anchor_box_list = torch.zeros(3,3,2)
for i in range(3):
for j in range(3):
anchor_box_list[i, j] = torch.tensor(sorted_anchors[i * 3 + j])
print(anchor_box_list) 마지막으로 위 사진처럼 tensor의 [3, 3, 2]차원 자료형으로 바꿔주면
마지막으로 위 사진처럼 tensor의 [3, 3, 2]차원 자료형으로 바꿔주면
Anchor box List를 성공적으로 얻어낼 수 있다.
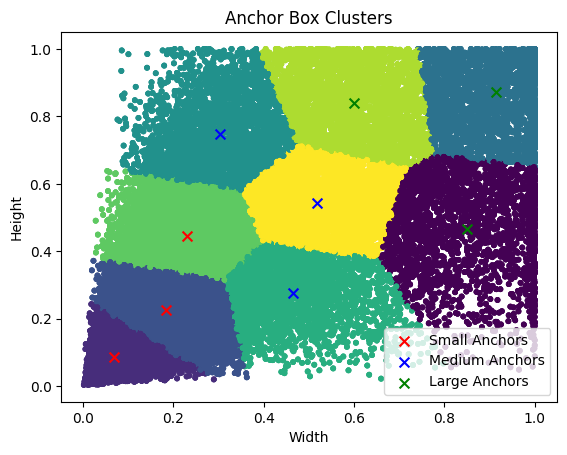 예의상
예의상
K-mean Clustering의 결과값도 도식화 해보자
# K-mean Clustering을 수행하여 얻은 9개의 anchorbox
# 해당 데이터는 정규화 좌표평면에서 얻은 Anchorbox 크기값이다.
anchor_box_list = torch.tensor([[[0.0686, 0.0861],
[0.1840, 0.2270],
[0.2308, 0.4469]],
[[0.4641, 0.2762],
[0.3029, 0.7475],
[0.5187, 0.5441]],
[[0.8494, 0.4666],
[0.5999, 0.8385],
[0.9143, 0.8731]]])매번 K-mean Clustering를 할 수는 없으니
전역변수로 해당 값을 저장해두자
3. 완성한 CustomDataset
이제 __init__메서드에 포함한 self.anchor = anchor
이 K-mean Clustering과정을 통해 얻은 anchor_box_list를 인자값으로 받는 것을 알게 되었을 것이다.
이 다음 할 내용은
__getitem__ 메서드의
if self.transform:이 전처리 방법론이 적용됬을 때 수행할 내용들이다.
if self.transform:
image = self.transform(image)
for i, S in enumerate(self.S_list):
b_boxes = label_matrix[i][..., :4]
# 정보가 있는 matrix탐색 -> 마스크 필터링을 활용
mask = label_matrix[i][..., 4] == 1
b_boxes = b_boxes[mask]
# 정보가 있는 그리드셀의 idx를 다시 서치
grid_cells = torch.nonzero(mask, as_tuple=False)
# repeat를 사용하여 [S, S, C+5] -> [S, S, B*(C+5)]
label_matrix[i] = label_matrix[i].repeat(1, 1, self.B)
for b in range(self.B):
anchor = self.anchor[i][b]
# 마스크 필터를 통과한 정보가 있는 데이터만 찾아야함
for j in range(len(b_boxes)):
cell_idx = grid_cells[j]
t_bbox = self._reverse_gt_bbox(b_boxes[j], anchor, cell_idx, S)
# 계산된 t_bbox정보를 해당 셀에 맞춰 치환
idx = (self.C+5) * b
label_matrix[i][cell_idx[0], cell_idx[1], idx:idx+4] = torch.tensor(t_bbox) # label matrix의 [b*x, b*y, b*w, b*h]를 [t*x, t*y, t*w, t*h]로 변환하는 코드
def _reverse_gt_bbox(self, b_bbox, anchor, cell_idx, S):
if self.anchor is None:
raise ValueError("앵커박스 정보가 없음")
# [b*x, b*y, b*w, b*h]는 0~1범위로 스케일링 되었으니
# 시그모이드 역함수를 적용하지 않아도 된다.
bx, by, bw, bh = b_bbox
pw, ph = anchor
# 정규화 좌표평면에서 그리드셀의 좌상단 Pos정보 생성
cy, cx = cell_idx / S
# 정규 좌표평면 상에서 cx, cy와 bx, by의
# 상대적인 거리가 sigmoid(tx), sigmoid(ty)이다.
sig_tx = (bx - cx) * S
sig_ty = (by - cy) * S
# tw, th는 앵커박스와 b_box간의 크기 비율정보를 의미함
# 이때 bw, bh, pw, ph가 [0~1] 정규좌표평면상의 데이터여서
# 역함수 t = ln(b/p)를 수행 시 NaN이 발생할 수 있다.
# 따라서 스케일링 + 0 이 되는것 방지 두개의 안전장치를 걸어둔다.
bw_scaled = bw * 416 + 1e-6
bh_scaled = bh * 416 + 1e-6
pw_scaled = pw * 416 + 1e-6
ph_scaled = ph * 416 + 1e-6
tw = torch.log(bw_scaled / pw_scaled)
th = torch.log(bh_scaled / ph_scaled)
t_bbox = [sig_tx, sig_ty, tw, th]
return t_bbox해당 코드의 부분도 도식으로 표현하도록 하겠다.

첫번째로 라벨 데이터의 OS와 bbox좌표가 담겨있는 셀에서 의미 있는 정보를 추출하는 첫번째 과정이다.
이 과정은 마스크 필터링 과정과 유사하며,
torch.nonzero는 OS=1이 담겨있는 cell의 idx를 추출하는 메서드이다.
이 정보를 통해서 값이 있는[grid_y, grid_x]의 idx를 찾아낼 수 있다.
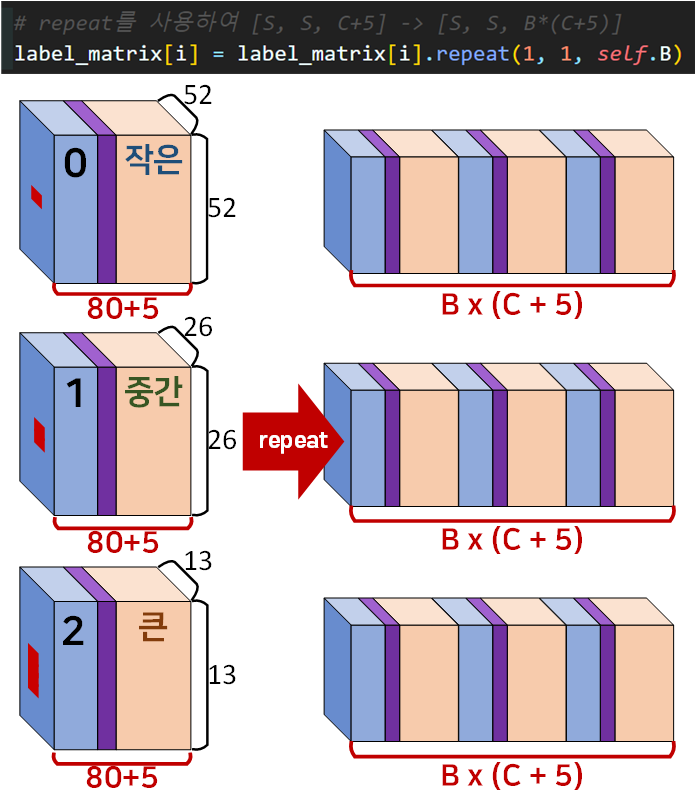
다음으로 Label Matrix를 repeat메서드를 통하여 데이터를 복제하여 붙여 넣은 뒤
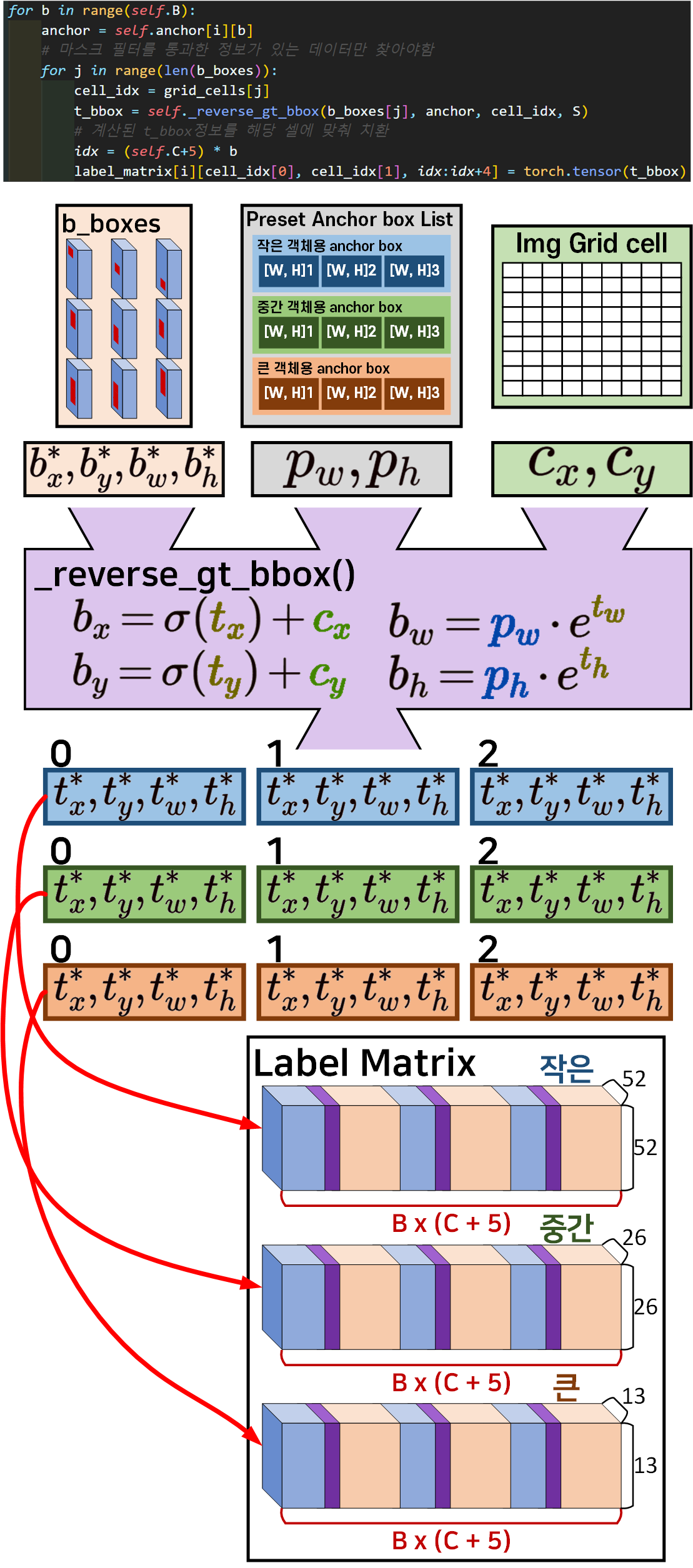
코드는 짧지만 앞단에 붙은 2개의 for문을 생각한다면 위 사진처럼
로 좌표정보를 변환시켜 의미있는 Grid cell(OS = 1) 인 곳에 변환된 좌표정보가 덮어쓰기 됨을 알 수 있을 것이다.
이때 사용되는 _reverce_gt_bbox()의 코드는 아래와 같다.
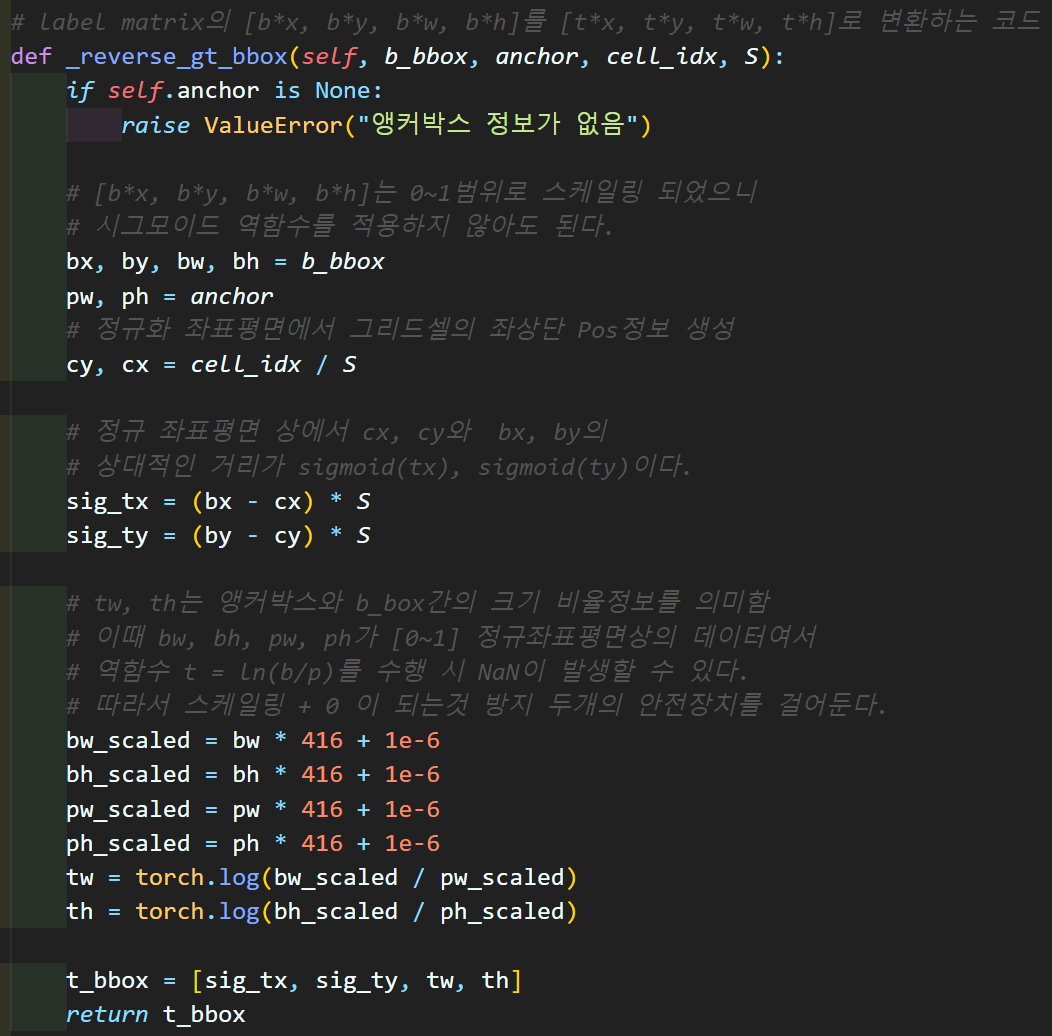
위 함수에서 주의해야 할 내용은
1) 모든 좌표는 정규 좌표평면위에서 움직인다.
2) tw, th는 지수함수의 역함수인 log함수가 적용되기에 NaN이 발생
-> NaN 발생을 막기위한 인자값 스케일링 + 양수화
따라서 위 과정을 전체로 포함한 CustomDataset의 코드는 아래와 같다.
class CustomDataset(Dataset):
def __init__(self, root, img_set=None, transform=None,
S=[52, 26, 13], B=3, C=80,
anchor = None):
self.root = root #COCO 데이터셋의 메인 폴더 경로
self.img_set = img_set
self.transform = transform
self.S_list = S # Gird Cell사이즈 -> [13, 26, 52] -> 인자값으로 받기
self.B = B # anchorbox의 개수 : 3
self.C = C # COCO데이터셋의 클래스 개수 : 80
# Anchor_box_list를 관리하기 위한 변수
self.anchor = anchor
self.anno_path = os.path.join(root, 'annotations')
if img_set == 'train':
self.img_dir = os.path.join(root, 'my_train_img')
self.coco = COCO(os.path.join(self.anno_path, 'instances_val2014.json'))
elif img_set == 'val':
self.img_dir = os.path.join(root, 'my_val_img')
self.coco = COCO(os.path.join(self.anno_path, 'instances_val2017.json'))
elif img_set == 'test':
pass
else:
raise ValueError("이미지 모드 확인하기")
# 모드별 이미지 ID리스트 불러오기
self.img_ids = self.coco.getImgIds()
def __len__(self):
return len(self.img_ids)
#예의 바르게 해당 클래스의 실행 결과를 불러오자
def __str__(self):
if len(self.img_ids) == 0:
message = f"Img 폴더 내 파일 못찾음"
else:
message = f"Img 폴더 찾은 *.jpg 개수: {len(self.img_ids)}"
return f"{message}"
# label matrix의 [b*x, b*y, b*w, b*h]를 [t*x, t*y, t*w, t*h]로 변환하는 코드
def _reverse_gt_bbox(self, b_bbox, anchor, cell_idx, S):
if self.anchor is None:
raise ValueError("앵커박스 정보가 없음")
# [b*x, b*y, b*w, b*h]는 0~1범위로 스케일링 되었으니
# 시그모이드 역함수를 적용하지 않아도 된다.
bx, by, bw, bh = b_bbox
pw, ph = anchor
# 정규화 좌표평면에서 그리드셀의 좌상단 Pos정보 생성
cy, cx = cell_idx / S
# 정규 좌표평면 상에서 cx, cy와 bx, by의
# 상대적인 거리가 sigmoid(tx), sigmoid(ty)이다.
sig_tx = (bx - cx) * S
sig_ty = (by - cy) * S
# tw, th는 앵커박스와 b_box간의 크기 비율정보를 의미함
# 이때 bw, bh, pw, ph가 [0~1] 정규좌표평면상의 데이터여서
# 역함수 t = ln(b/p)를 수행 시 NaN이 발생할 수 있다.
# 따라서 스케일링 + 0 이 되는것 방지 두개의 안전장치를 걸어둔다.
bw_scaled = bw * 416 + 1e-6
bh_scaled = bh * 416 + 1e-6
pw_scaled = pw * 416 + 1e-6
ph_scaled = ph * 416 + 1e-6
tw = torch.log(bw_scaled / pw_scaled)
th = torch.log(bh_scaled / ph_scaled)
t_bbox = [sig_tx, sig_ty, tw, th]
return t_bbox
def __getitem__(self, idx):
img_id = self.img_ids[idx]
ann_ids = self.coco.getAnnIds(imgIds=img_id)
# ann_ids는 불러온 이미지와 관련된 Anno 리스트를 가져온다
anns = self.coco.loadAnns(ann_ids)
# 이미지의 기본 정보 추출하기 -> [0]붙이는거 까먹지말자
img_info = self.coco.loadImgs(img_id)[0]
# 찾은 이미지에 맞는 파일이름을 찾아서 출력할 Image에 할당
img_path = os.path.join(self.img_dir, img_info['file_name'])
image = Image.open(img_path).convert("RGB")
# 라벨 메트릭스 생성 [S, S, C+5=85]로 생성을 먼저함
label_matrix = [
torch.zeros((S, S, self.C+5)) for S in self.S_list
]
# 이제 Anno주석정보를 라벨 매트릭스에 기입하기
for ann in anns:
bbox = ann['bbox']
# CP는 Class Probability이니 = Class ID
CP_idx = real_class_idx[ann['category_id']]
x, y, w, h = bbox
# bbox 좌표 정규화
bx = (x + w / 2) / img_info['width']
by = (y + h / 2) / img_info['height']
bw = w / img_info['width']
bh = h / img_info['height']
#정규좌표평면에서 center point가 위치하는 그리드셀 탐색
for i, S in enumerate(self.S_list):
# 정규화된 좌표평면 상에서 grid_y, x의 idx를 구해야 한다.
grid_x = int(bx * S)
grid_y = int(by * S)
#탐색한 그리드셀이 비어있으면 아래 정보 기입
if label_matrix[i][grid_y, grid_x, 4] == 0:
# OS(Objectness Score) 정보 기입
label_matrix[i][grid_y, grid_x, 4] = 1
# BBox(bx, by, bw, bh) 정보 기입
label_matrix[i][grid_y, grid_x, :4] = torch.tensor(
[bx, by, bw, bh]
)
# CP(Class Probability) 정보 기입
label_matrix[i][grid_y, grid_x, 5 + CP_idx] = 1
# 이미지의 전처리 방법론이 수행될 때 label matrix도 같이 업데이트
if self.transform:
image = self.transform(image)
for i, S in enumerate(self.S_list):
b_boxes = label_matrix[i][..., :4]
# 정보가 있는 matrix탐색 -> 마스크 필터링을 활용
mask = label_matrix[i][..., 4] == 1
b_boxes = b_boxes[mask]
# 정보가 있는 그리드셀의 idx를 다시 서치
grid_cells = torch.nonzero(mask, as_tuple=False)
# repeat를 사용하여 [S, S, C+5] -> [S, S, B*(C+5)]
label_matrix[i] = label_matrix[i].repeat(1, 1, self.B)
for b in range(self.B):
anchor = self.anchor[i][b]
# 마스크 필터를 통과한 정보가 있는 데이터만 찾아야함
for j in range(len(b_boxes)):
cell_idx = grid_cells[j]
t_bbox = self._reverse_gt_bbox(b_boxes[j], anchor, cell_idx, S)
# 계산된 t_bbox정보를 해당 셀에 맞춰 치환
idx = (self.C+5) * b
label_matrix[i][cell_idx[0], cell_idx[1], idx:idx+4] = torch.tensor(t_bbox)
# [S, S, C+5, B]차원의 원소 Label_matrix를 [S, S, B*(C+5)]로 concat
# label_matrix[i] = torch.cat(
# [label_matrix[i][..., j] for j in range(label_matrix[i].shape[-1])], dim=-1
# )
return image, tuple(label_matrix)3.1 완성한 CustomDataset 검증
위에서 완성한 CustomDataset에 anchor_box_list를 인자값으로 전달하여
다시 인스턴스화를 시키자
train_dataset = CustomDataset(root=root_dir, img_set='train', anchor=anchor_box_list)
test_dataset = CustomDataset(root=root_dir, img_set='val', anchor=anchor_box_list)img, labels = train_dataset[0]
for label in labels:
print(label.shape)torch.Size([52, 52, 85])
torch.Size([26, 26, 85])
torch.Size([13, 13, 85])여기까지 수행한다면 이전 코드와 동일한 shape로 구성되어 있지만
from torchvision.transforms import v2
transforamtion = v2.Compose([
v2.Resize((416, 416)), #이미지 크기를 416, 416로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
# v2.Normalize(mean=VOC_VAL[0], std=VOC_VAL[1]) #데이터셋 정규화
])#전처리 방법론 적용
train_dataset.transform = transforamtion
test_dataset.transform = transforamtion위 코드처럼 전처리 방법론만 적용한다면
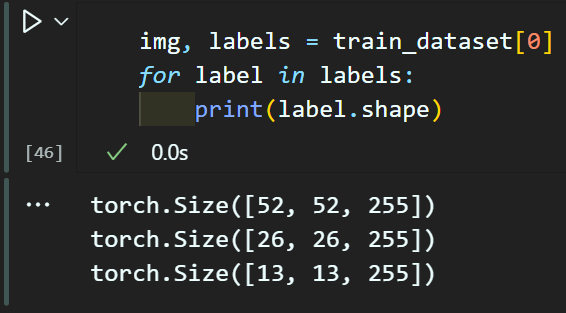 동일한 코드를 다시 실행했음에도
동일한 코드를 다시 실행했음에도
LabelMatrix의 shape이 3배 증가했으니
의 좌표변환도 이뤄졌음을 알 수 있을 것이다.
from torch.utils.data import DataLoader
BATCH_SIZE = 16
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False)이제 마지막으로 Yolo v3에 입력되는 데이터 형테인 DataLoader로 마지막 전환을 시켜주자
# 데이터로더 정보를 출력하는 함수
def print_dataloader_info(dataloader, loader_name):
print(f"\n{loader_name} 정보:")
for batch_idx, (images, labels) in enumerate(dataloader):
print(f"배치 인덱스: {batch_idx}")
print(f"이미지 크기: {images.size()}")
print(f"라벨의 데이터타입: {type(labels)}", end="\n\n")
for i, label in enumerate(labels):
print(f"{i}번째 라벨")
print(f"{i}번째 라벨의 총 크기: {label.size()}")
print(f" 배치 라벨의 shape: {label[0].size()}")
print(f" 배치 라벨의 데이터 타입: {label.dtype}", end="\n\n")
if batch_idx == 0: # 첫 번째 배치 정보만 출력
break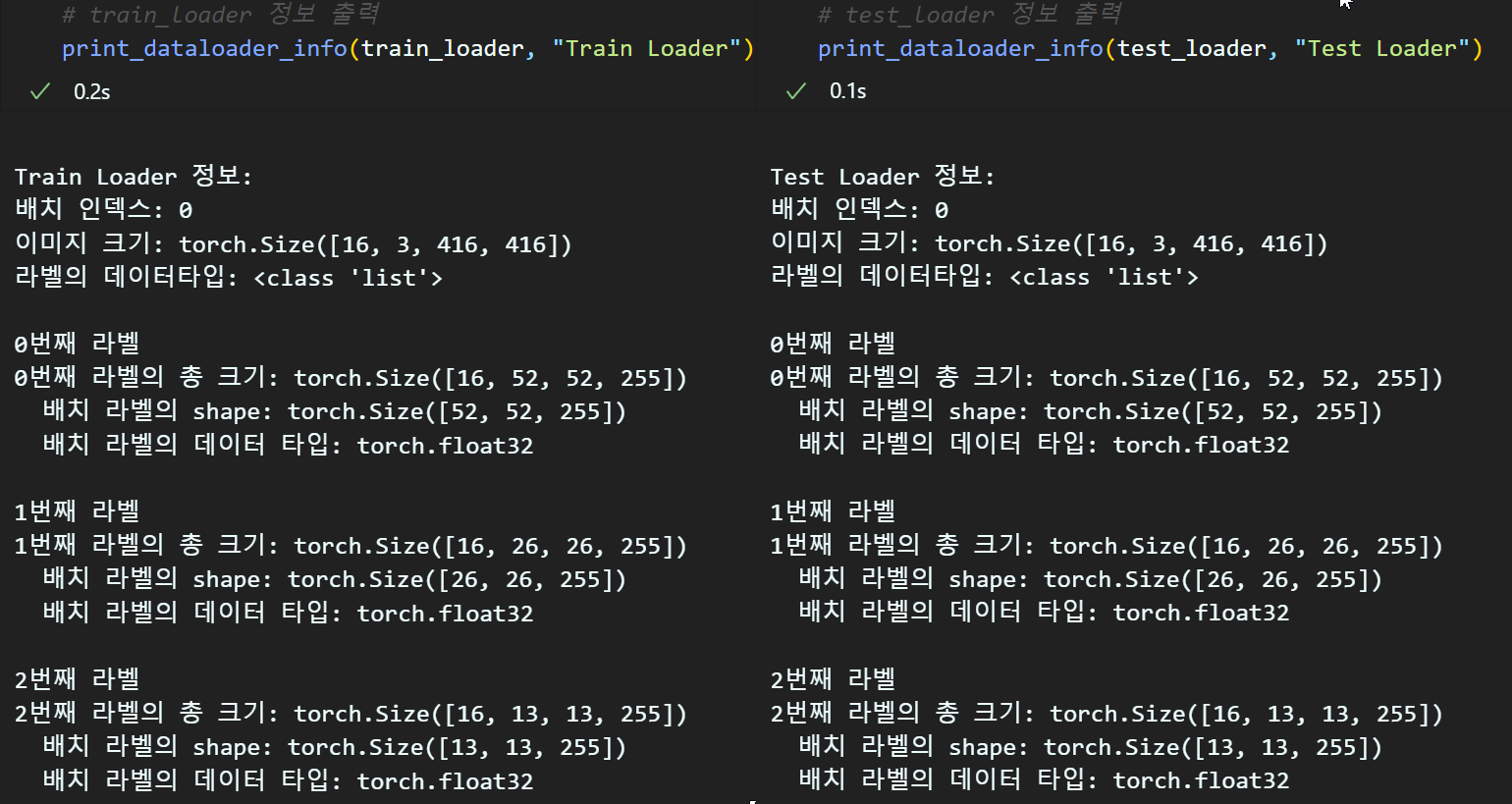
마지막 DataLoader까지 입력 가능한 데이터 형태로 잘 전환된 것을 확인할 수 있다.

나름 최약체에 해당하는 CustomDataset 설계를 완료했다...
