
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. 평가지표 코드 구현
이전 포스트 인공지능 고급(시각) 강의 예습 - 19. Yolo v1 (4) 평가지표 설계 + Train/val 수행에서 다뤘던
평가지표 선정 및 선정한 평가지표에 대한 코드 구현을 수행하고자 한다.
이걸 먼저 끝내야 Train / Val 작업 때 멘탈이 터지지 않는다
하지만 이미 필자는 코드 작성하느라 마음이 무너졌다.

shape맞추느라 ㄷㅈㄴㅈㅇㅇㅇ...
아무튼 평가지표는 이전에 선정한 4가지
iou, precision, recall, top-1 error 이고 Loss까지 합치면 5개가 된다.
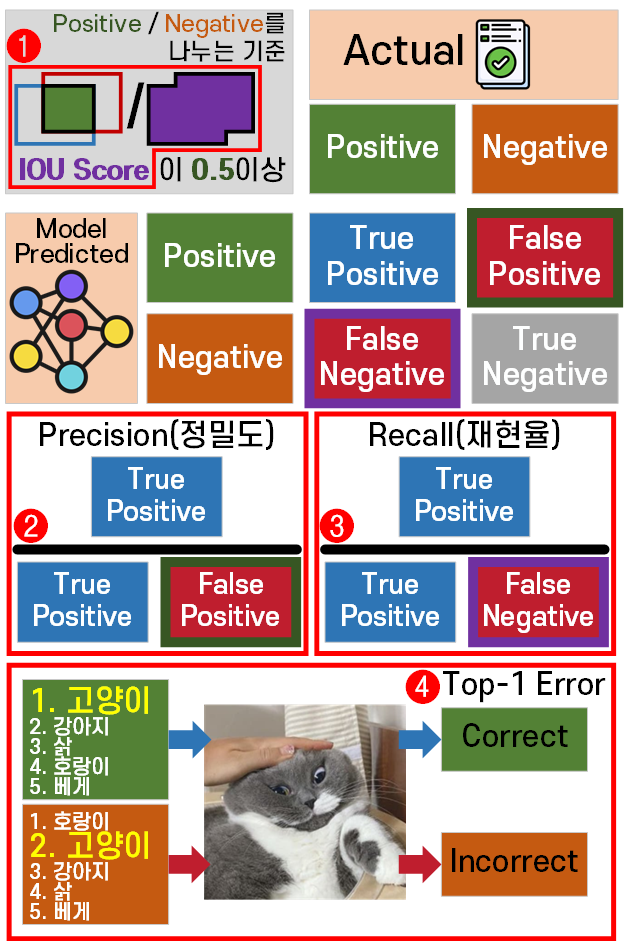
Loss 지표는 Train / Val 과정을 수행하면 자연스럽게 출력되는 항목이지만
iou, precision, recall, top-1 error이 4개의 지표를 출력하려면 별도의 코드를 작성해야 한다.
인공지능 고급(시각) 강의 예습 - 19. Yolo v1 (4) 평가지표 설계 + Train/val 수행 에서는 함수 여러개를 써서 각 지표의 연산을 수행했지만
이번 포스트에서는 CLASS로 통합관리를 수행하려 한다.
따라서 설계하는 Clsss의 다이어그램을 그리면 아래와 같다
 음.. 이게 이전에 함수로 파편화 되어 있던 것들을 억지로 class로 묶음처리를 하다 보니 코드가 많이 지저분하다
음.. 이게 이전에 함수로 파편화 되어 있던 것들을 억지로 class로 묶음처리를 하다 보니 코드가 많이 지저분하다
 그러나 기존 v1용 평가지표 함수를 v3용으로 변환하는 과정이 너무나도 험난해서 공을 들일 수가 없었다
그러나 기존 v1용 평가지표 함수를 v3용으로 변환하는 과정이 너무나도 험난해서 공을 들일 수가 없었다
그리고 공을 들여도.. 이게 함수가 유기적으로 융합이 되는건지도 잘 모르겟다
1.1 평가지표 코드 전체
평가지표에 대한 코드는 전체 코드를 먼저 기재 한뒤
하이라이트별 설명을 진행하겠다.
class YOLOv3Metrics:
def __init__(self, B=3, C=80, iou_th = 0.5,
anchor=None, device='cuda'):
self.B = B
self.C = C
self.device = device # 연산에 필요한 변수를 다 GPU로 올려야 함
self.iou_th = iou_th
# anchor 리스트 정보는 GPU로 올려야 함
self.anchor = anchor.to(device) if anchor is not None else None
def cal_acc_func(self, outputs, labels):
# outputs, labels가 리스트 데이터 이기에
# 원소별로 4가지 평가지표를 계산 후 덧셈한다.
sum_iou = 0
sum_precision = 0
sum_recall = 0
sum_top1_error = 0
# outputs와 labels를 GPU로 이전
self.outputs = [output.to(self.device) for output in outputs]
self.labels = [label.to(self.device) for label in labels]
# 리스트 내 원소가 0, 1, 2 3개니까 cnt는 0~2 를 순회한다.
self.cnt = 0 # compute_metrics 함수 수행 전 cnt 초기화
# 리스트 내 원소들을 추출한 후 연산 수행
for output, label in zip(self.outputs, self.labels):
# 실제 원소별 평가지표 연산은 `compute_metrics`함수에서 수행
element_metrics = self.compute_metrics(output, label)
sum_iou += element_metrics[0]
sum_precision += element_metrics[1]
sum_recall += element_metrics[2]
sum_top1_error += element_metrics[3]
self.cnt += 1
iou = sum_iou / self.cnt if self.cnt > 0 else 0
precision = sum_precision / self.cnt if self.cnt > 0 else 0
recall = sum_recall / self.cnt if self.cnt > 0 else 0
top1_error = sum_top1_error / self.cnt if self.cnt > 0 else 0
# YOLOv3Metrics클래스의 최종 리턴값이라 보면 된다.
cal_res = [iou, precision, recall, top1_error]
return cal_res
def compute_metrics(self, output, label):
# Assert 구문을 활용하여 grid cell의 크기가 동일한지 확인
assert output.size(1) == label.size(2), "그리드셀 차원이 맞지 않음"
batch_size = output.size(0) # Batch_size의 사이즈정보
S = output.size(2) # grid cell크기정보 추출
# 원소의 차원은 [batch_size, S, S, Bx(5+C)] 4차원으로 되어있음
# 이걸 [batch_size, S, S, B, 5+C] 5차원으로 차원전환
predictions = output.view(batch_size, S, S, self.B, 5 + self.C)
target = label.view(batch_size, S, S, self.B, 5 + self.C)
# BBox정보 추출(tx, ty, tw, th) + OS정보도 포함시킴
# 따라서 [batch_size, S, S, B, 5]
pred_boxes = predictions[..., :5]
target_boxes = target[..., :5]
# BBox의 [tx, ty, tw, th] -> [bx, by, bw, bh]로 좌표변환
b_pred_boxes, b_target_boxes = self.convert_b_bbox(pred_boxes, target_boxes)
# 좌표변환된 b_pred_boxes, b_target_boxes의 차원은
# pred_boxes, target_boxes에서 OS정보만 빠짐 [batch_size, S, S, B, 4]
# 1번 평가지표 = 원소 IOU연산하기
# 입력차원 : [batch_size, S, S, B, 4]
ious = self.compute_iou(b_pred_boxes, b_target_boxes)
iou_score = ious.mean().item()
# IOU 임계값을 이용하여 TP, FP, FN 계산
pred_os = (ious > self.iou_th).float()
target_os = (target_boxes[..., 4] > 0).float()
TP = (pred_os * target_os).sum().item()
FP = (pred_os * (1 - target_os)).sum().item()
FN = ((1 - pred_os) * target_os).sum().item()
# 2,3번 평가지표 원소 정밀도(precision), 원소 재현율(recall) 계산
precision = TP / (TP + FP) if (TP + FP) > 0 else 0
recall = TP / (TP + FN) if (TP + FN) > 0 else 0
# 클래스 확률 정보(Class Probability) 추출 후 차원전환
# [Batch_size, S, S, C] -> [Batch_size*S*S, C]
# 원래는 pred_cp에 sigmoid를 적용해야 하나 패스...
pred_cp = predictions[..., 5:].reshape(-1, self.C)
target_cp = target[..., 5:].reshape(-1, self.C)
# Softmax 적용 -> pred만 적용하면 됨
pred_cp = F.softmax(pred_cp, dim=1)
# Class 확률 정보에서 가장 높은 값을 갖는 idx 정보 추출
pred_classes = torch.argmax(pred_cp, dim=1)
target_classes = torch.argmax(target_cp, dim=1)
# 추출 결과물은 [Batch_size*S*S] 1차원이 된다.
# 객체가 아에 검출되지 않는 예외현상을 처리하는 구문
non_zero_mask = target_classes != 0
f_pred_classes = pred_classes[non_zero_mask]
f_target_classes = target_classes[non_zero_mask]
# 4번 평가지표 원소 Top-1 Error 계산
top1_error = (~f_pred_classes.eq(f_target_classes)).float().mean().item()
#원소 평가지표 4가지를 리턴
element_metrics = [iou_score, precision, recall, top1_error]
return element_metrics
# [tx, ty, tw, th] -> [bx, by, bw, bh]의 수행을 준비하는 함수
def convert_b_bbox(self, pred_boxes, target_boxes):
# 마스크 필터 생성하기(yolo v3 Loss와 동일한 방식
target_obj = target_boxes[..., 4]
coord_mask = target_obj > 0
noobj_mask = target_obj <= 0
#예외처리 구문
if coord_mask.sum() == 0:
b_pred_boxes = torch.zeros_like(pred_boxes[..., :4])
b_target_boxes = torch.zeros_like(target_boxes[..., :4])
return b_pred_boxes, b_target_boxes
# 필터링의 응용 -> 의미없는 셀을 탈락시키지 말고 0으로 치환하기
pred_boxes[noobj_mask] = 0
target_boxes[noobj_mask] = 0
S = pred_boxes.size(1)
# 그리드 셀의 idx를 저장용 매쉬 그리드 행렬 생성
# 이 매쉬 그리드는 글로 설명하긴 어려운데 아무튼 idx을 저장하는 효율적인 행렬이다
grid_y, grid_x = torch.meshgrid(torch.arange(S), torch.arange(S), indexing='ij')
grid_y = grid_y.to(self.device).float()
grid_x = grid_x.to(self.device).float()
# 생성한 매쉬그리드는 CPU에 할당되서 GPU로 이전을 꼭 시켜줘야함
# 모델의 예측값 tx, ty는 사전에 sigmoid를 적용한다.
pred_boxes[..., 0] = torch.sigmoid(pred_boxes[..., 0])
pred_boxes[..., 1] = torch.sigmoid(pred_boxes[..., 1])
# [tx, ty, tw, th] -> [bx, by, bw, bh]의 실제 변환은 이 함수에서 수행됨
b_pred_boxes = self.get_pred_bbox(pred_boxes, self.anchor, grid_x, grid_y, S)
# [t*x, t*y, t*w, t*h] -> [b*x, b*y, b*w, b*h]의 실제 변환은 이 함수에서 수행됨
b_target_boxes = self.get_pred_bbox(target_boxes, self.anchor, grid_x, grid_y, S)
return b_pred_boxes, b_target_boxes
# [tx, ty, tw, th] -> [bx, by, bw, bh]변환을 실제로 수행하는 함수
# [t*x, t*y, t*w, t*h] -> [b*x, b*y, b*w, b*h]변환을 실제로 수행하는 함수
def get_pred_bbox(self, t_bbox, anchor, grid_x, grid_y, S):
# 여기에 들어오는 [tx], [ty], [tw], [th]는 모두
# [Batch_size, S, S, B] 형태임 -> B : [anchor1, 2, 3]
tx, ty = t_bbox[..., 0], t_bbox[..., 1]
tw, th = t_bbox[..., 2], t_bbox[..., 3]
# cnt는 작은 -> 중간 -> 큰 객체의 리스트를 순환하는 변수고
# anchor box list에서 cnt 값에 맞춰 객체 크기용
# box [3x2]를 가져옴 -> [3(B)], [3(B)]으로 나눠가짐
pw, ph = anchor[self.cnt][..., 0], anchor[self.cnt][..., 1]
# meshgrid로 정의된 grid_x, grid_x는 모두 [S, S]차원을 가짐
# [S, S] -> [1, S, S, 1] -> [batch_size, S, S, C+5]로 차원확장
grid_x = grid_x.unsqueeze(0).unsqueeze(-1).expand_as(tx)
grid_y = grid_y.unsqueeze(0).unsqueeze(-1).expand_as(ty)
# grid / s -> 이것은 그리드셀의 좌상돤 좌표값이 됨(cx, cy)
# tx, ty는 sigmoid처리돤 c_pos와 b_pos의 '상대적인 거리'
# 모두 정규화 좌표평면이니 t_pos도 1/s 처리 해줘야함
bx = (tx + grid_x) / S
by = (ty + grid_y) / S
bw = pw * torch.exp(tw)
bh = ph * torch.exp(th)
# 좌표변환이 완료된 [bx, by, bw, bh]은 스택으로 쌓아서 return
b_bbox = torch.stack([bx, by, bw, bh], dim=-1)
return b_bbox
# iou계산 함수는 뭐 딱히 어려울 건 없다.
def compute_iou(self, box1, box2):
box1_x1 = box1[..., 0] - box1[..., 2] / 2
box1_y1 = box1[..., 1] - box1[..., 3] / 2
box1_x2 = box1[..., 0] + box1[..., 2] / 2
box1_y2 = box1[..., 1] + box1[..., 3] / 2
box2_x1 = box2[..., 0] - box2[..., 2] / 2
box2_y1 = box2[..., 1] - box2[..., 3] / 2
box2_x2 = box2[..., 0] + box2[..., 2] / 2
box2_y2 = box2[..., 1] + box2[..., 3] / 2
inter_x1 = torch.max(box1_x1, box2_x1)
inter_y1 = torch.max(box1_y1, box2_y1)
inter_x2 = torch.min(box1_x2, box2_x2)
inter_y2 = torch.min(box1_y2, box2_y2)
inter_area = (inter_x2 - inter_x1).clamp(0) * (inter_y2 - inter_y1).clamp(0)
box1_area = (box1_x2 - box1_x1) * (box1_y2 - box1_y1)
box2_area = (box2_x2 - box2_x1) * (box2_y2 - box2_y1)
union_area = box1_area + box2_area - inter_area
return inter_area / union_area1)
__init__메서드
이전 포스트 인공지능 고급(시각) 강의 예습 - 22. (4) Yolo v3용 Coco 데이터셋 전처리와 공통된 변수도 있고 그렇지 않은 변수도 있다.
주요한 차이가 나는 변수는 CustomDataset 에서는 인자값으로
S=[52, 26, 13]를 기본인자값 처리한것에 비해
YOLOv3Metrics 클래스는 어차피 입력받는
outputs(모델의 출력데이터, pred)
lables(정답지, Anno처리데이터, target)이
[batch_size, S, S, B*(C+5)]의 차원으로 들어오고
이때 S가 S=[52, 26, 13]와 같은 값으로 가변되기에
해당 인자는 따로 정의하지 않고 입력받는 인자값에서 S를 추출한다.
다음으로 B, C인자는 CustomDataset와 동일하게 기능하는 인자값이고
이제 특이한 인자값으로
iou_th가 있는데 해당 인자값은 평가지표 2번 Precision, 3번 Recall을 나누는 기준값에 해당한다.
이게 yolo v1에서 0.5를 사용했고 이는 Yolo v3에도 동일하게 적용되었다.
다음으로 device항목이 있는데
YOLOv3Metrics 이 클래스가 기능하는 부분은 Train / Val 과정에서 기능하기에 입력받는 데이터가 기본적으로는 GPU에 올라가 있는 상태다
그러나 YOLOv3Metrics 클래스를 작성하면서 일부 변수의 경우 선언됨과 동시에 CPU의 메모리를 차지하는 경우가 왕왕 발생하고
추가로 anchor변수의 경우 초기 선언이 CPU 메모리에 할당되어 있기에 이를 명시적으로 GPU로 이전할 필요성이 있어 device 변수를 추가했다.
2) cal_acc_func 함수
def cal_acc_func(self, outputs, labels):
# outputs, labels가 리스트 데이터 이기에
# 원소별로 4가지 평가지표를 계산 후 덧셈한다.
sum_iou = 0
sum_precision = 0
sum_recall = 0
sum_top1_error = 0
# outputs와 labels를 GPU로 이전
self.outputs = [output.to(self.device) for output in outputs]
self.labels = [label.to(self.device) for label in labels]
# 리스트 내 원소가 0, 1, 2 3개니까 cnt는 0~2 를 순회한다.
self.cnt = 0 # compute_metrics 함수 수행 전 cnt 초기화
# 리스트 내 원소들을 추출한 후 연산 수행
for output, label in zip(self.outputs, self.labels):
# 실제 원소별 평가지표 연산은 `compute_metrics`함수에서 수행
element_metrics = self.compute_metrics(output, label)
sum_iou += element_metrics[0]
sum_precision += element_metrics[1]
sum_recall += element_metrics[2]
sum_top1_error += element_metrics[3]
self.cnt += 1
iou = sum_iou / self.cnt if self.cnt > 0 else 0
precision = sum_precision / self.cnt if self.cnt > 0 else 0
recall = sum_recall / self.cnt if self.cnt > 0 else 0
top1_error = sum_top1_error / self.cnt if self.cnt > 0 else 0
# YOLOv3Metrics클래스의 최종 리턴값이라 보면 된다.
cal_res = [iou, precision, recall, top1_error]
return cal_res 해당 함수의 가장 중요하다 볼 수 있는 YOLOv3Metrics의 주요 입력 인자값
해당 함수의 가장 중요하다 볼 수 있는 YOLOv3Metrics의 주요 입력 인자값 outputs, lables, cnt이다.
위 인자값을 받아서 출력하는 값의 구조는 아래의 도식으로 표현이 가능하다.
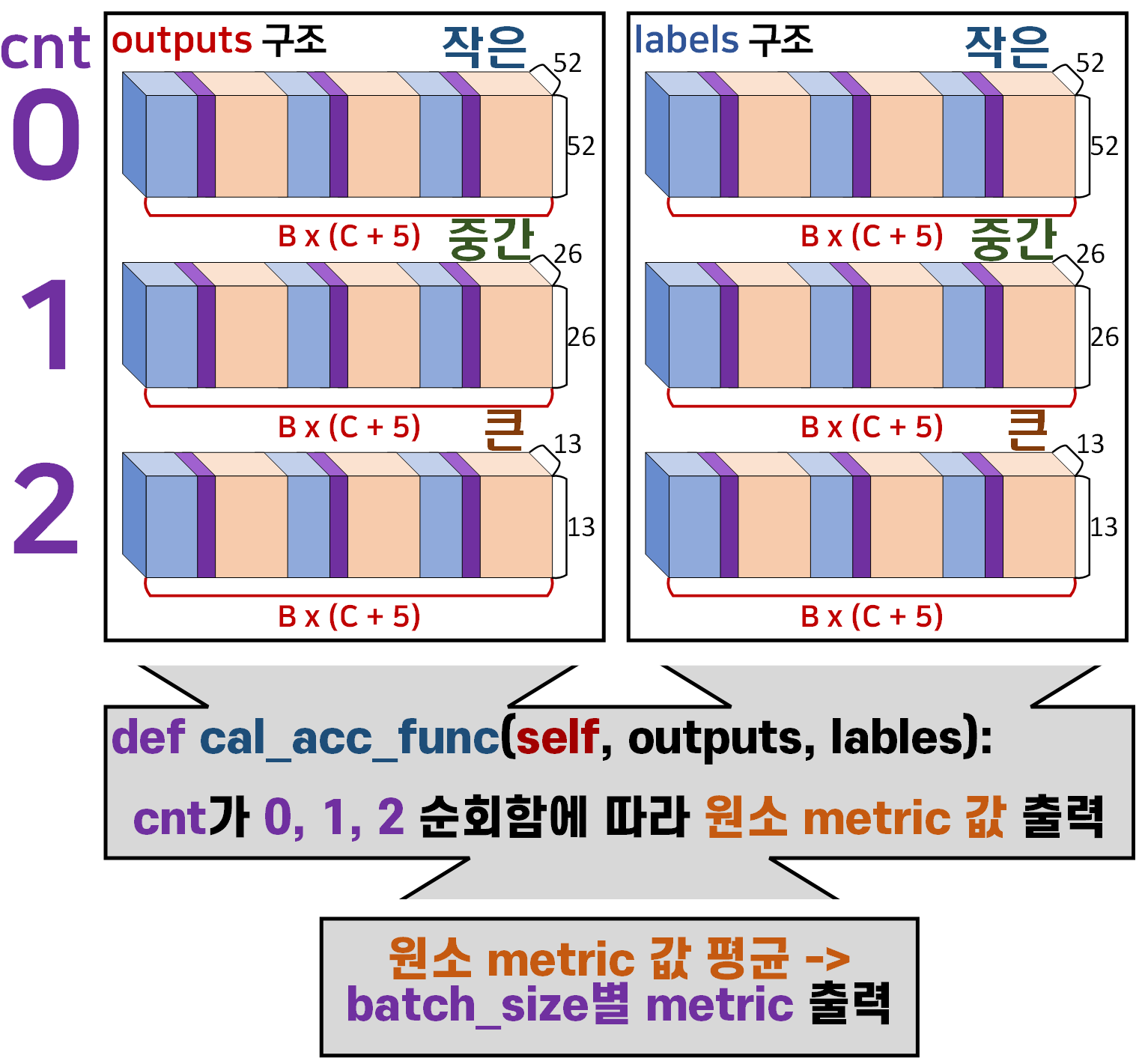
라벨의 첫번째 인덱스변수로 활용되는 cnt에 주의하자.
이 함수가 return하는 cal_res이 최종출력값이고
이 출력값은 Train / Val을 수행하면서 1개의 mini_batch에 대한 metric 값임을 잊지말자
따라서 Train / Val과정에서도 해당 함수의 출력값을 받아서 지속적으로
이동평균 필터를 적용한다.
3) compute_metrics 함수
def compute_metrics(self, output, label):
# Assert 구문을 활용하여 grid cell의 크기가 동일한지 확인
assert output.size(1) == label.size(2), "그리드셀 차원이 맞지 않음"
batch_size = output.size(0) # Batch_size의 사이즈정보
S = output.size(2) # grid cell크기정보 추출
# 원소의 차원은 [batch_size, S, S, Bx(5+C)] 4차원으로 되어있음
# 이걸 [batch_size, S, S, B, 5+C] 5차원으로 차원전환
predictions = output.view(batch_size, S, S, self.B, 5 + self.C)
target = label.view(batch_size, S, S, self.B, 5 + self.C)
# BBox정보 추출(tx, ty, tw, th) + OS정보도 포함시킴
# 따라서 [batch_size, S, S, B, 5]
pred_boxes = predictions[..., :5]
target_boxes = target[..., :5]
# BBox의 [tx, ty, tw, th] -> [bx, by, bw, bh]로 좌표변환
b_pred_boxes, b_target_boxes = self.convert_b_bbox(pred_boxes, target_boxes)
# 좌표변환된 b_pred_boxes, b_target_boxes의 차원은
# pred_boxes, target_boxes에서 OS정보만 빠짐 [batch_size, S, S, B, 4]
# 1번 평가지표 = 원소 IOU연산하기
# 입력차원 : [batch_size, S, S, B, 4]
ious = self.compute_iou(b_pred_boxes, b_target_boxes)
iou_score = ious.mean().item()
# IOU 임계값을 이용하여 TP, FP, FN 계산
pred_os = (ious > self.iou_th).float()
target_os = (target_boxes[..., 4] > 0).float()
TP = (pred_os * target_os).sum().item()
FP = (pred_os * (1 - target_os)).sum().item()
FN = ((1 - pred_os) * target_os).sum().item()
# 2,3번 평가지표 원소 정밀도(precision), 원소 재현율(recall) 계산
precision = TP / (TP + FP) if (TP + FP) > 0 else 0
recall = TP / (TP + FN) if (TP + FN) > 0 else 0
# 클래스 확률 정보(Class Probability) 추출 후 차원전환
# [Batch_size, S, S, C] -> [Batch_size*S*S, C]
# 원래는 pred_cp에 sigmoid를 적용해야 하나 패스...
pred_cp = predictions[..., 5:].reshape(-1, self.C)
target_cp = target[..., 5:].reshape(-1, self.C)
# Class 확률 정보에서 가장 높은 값을 갖는 idx 정보 추출
pred_classes = torch.argmax(pred_cp, dim=1)
target_classes = torch.argmax(target_cp, dim=1)
# 추출 결과물은 [Batch_size*S*S] 1차원이 된다.
# 객체가 아에 검출되지 않는 예외현상을 처리하는 구문
non_zero_mask = target_classes != 0
f_pred_classes = pred_classes[non_zero_mask]
f_target_classes = target_classes[non_zero_mask]
# 4번 평가지표 원소 Top-1 Error 계산
top1_error = (~f_pred_classes.eq(f_target_classes)).float().mean().item()
#원소 평가지표 4가지를 리턴
element_metrics = [iou_score, precision, recall, top1_error]
return element_metrics해당 함수의 기능은 1) cal_acc_func 함수가 요구하는
원소별 metric 값을 출력하는 함수이다.
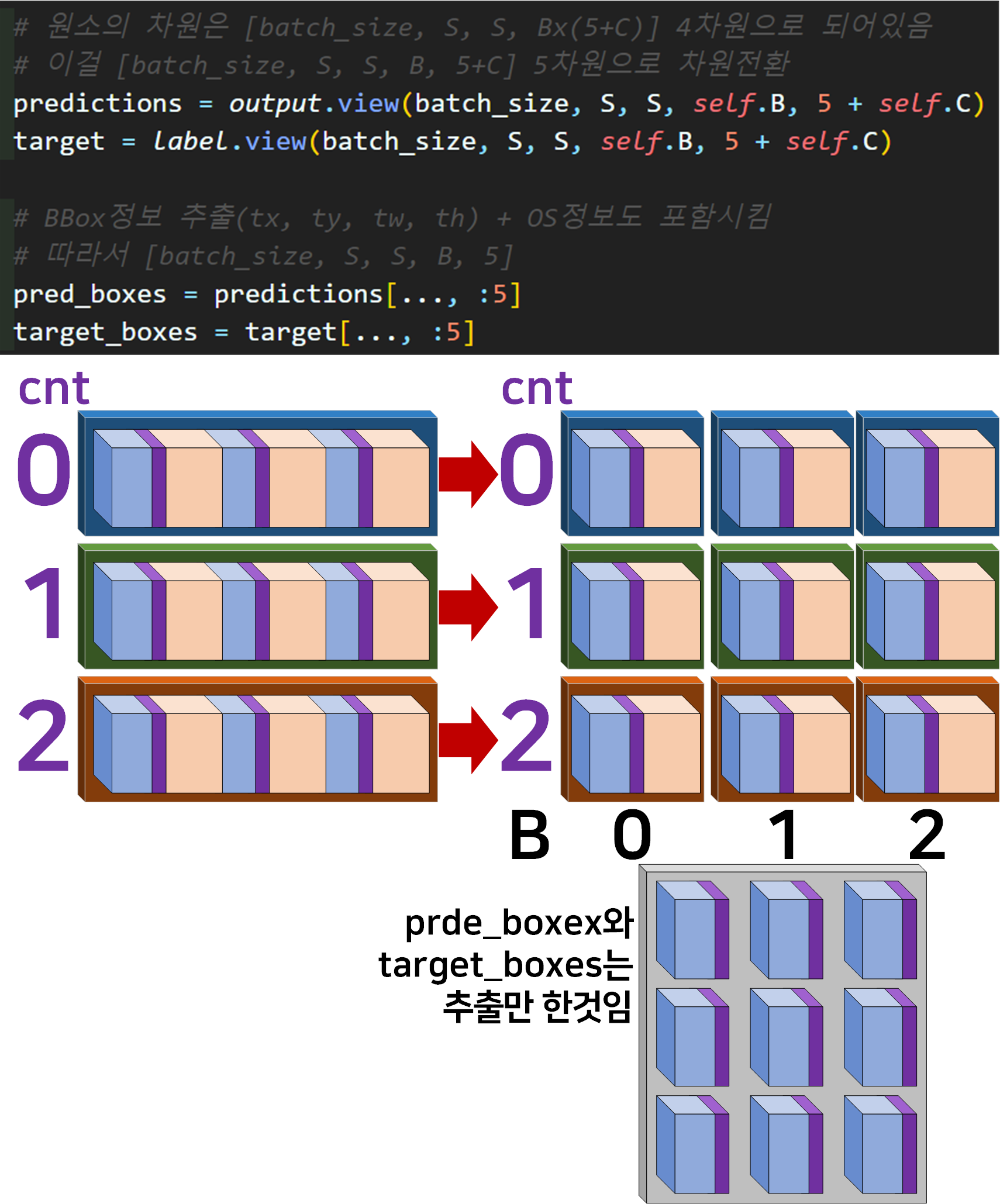 이 부분은 해당 함수에서 처음 수행하는 차원변환 + 데이터 추출 작업이라 보면 된다.
이 부분은 해당 함수에서 처음 수행하는 차원변환 + 데이터 추출 작업이라 보면 된다.
4차원 -> 5차원으로 늘리고, 늘어난 차원에 Anchor box의 인덱싱이 가능한 B를 배치했다 라고 보면 된다.
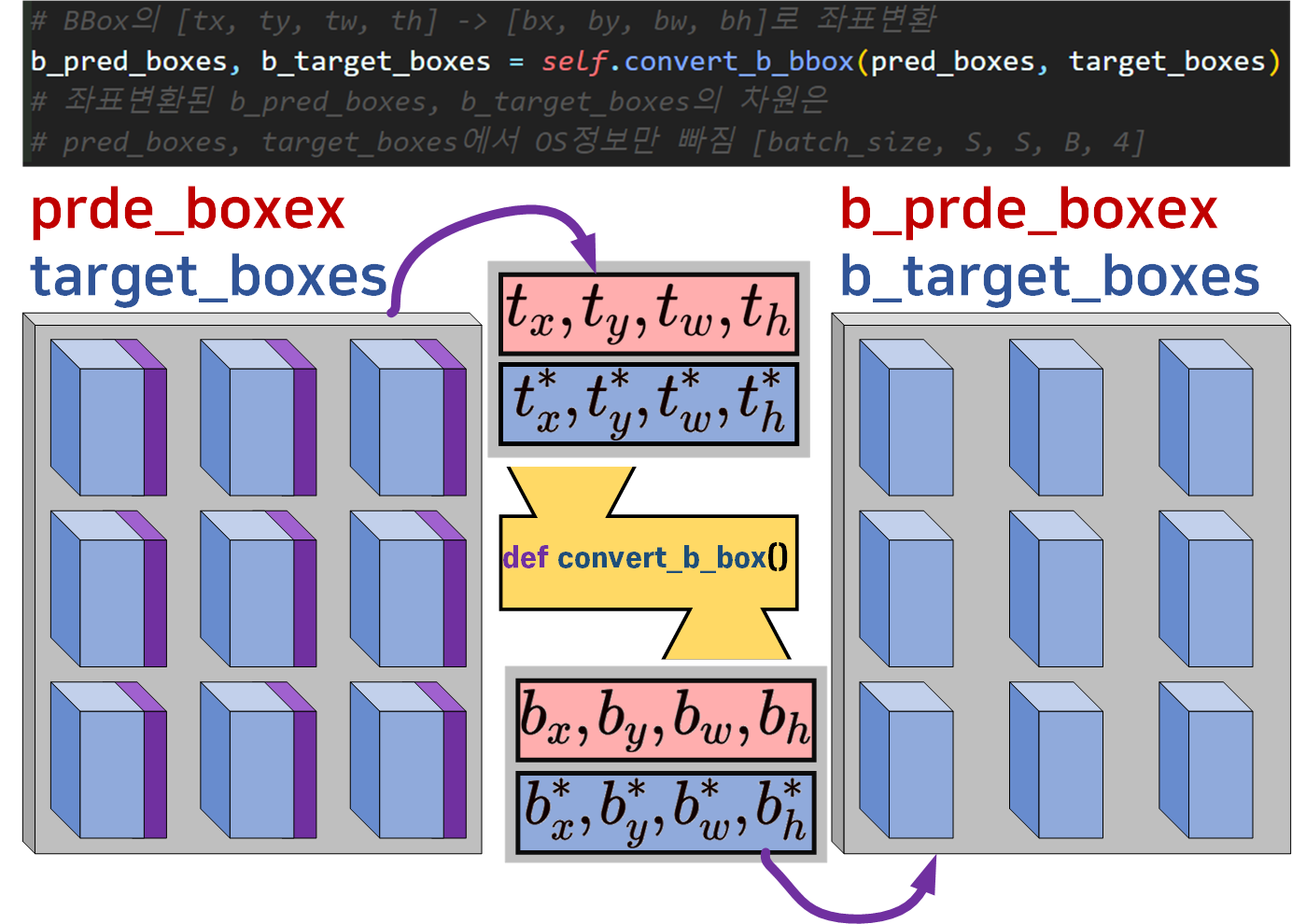 다음으로 2중으로 함수가 연계되는 부분인
다음으로 2중으로 함수가 연계되는 부분인 convert_b_box 함수이다.
간단하게 모델의 출력(output)값과 라벨 메트릭스(target)의
BBox좌표
이 과정을 수행한 것이라 보면 된다.
여기서
output =
target =
임을 잊지말자
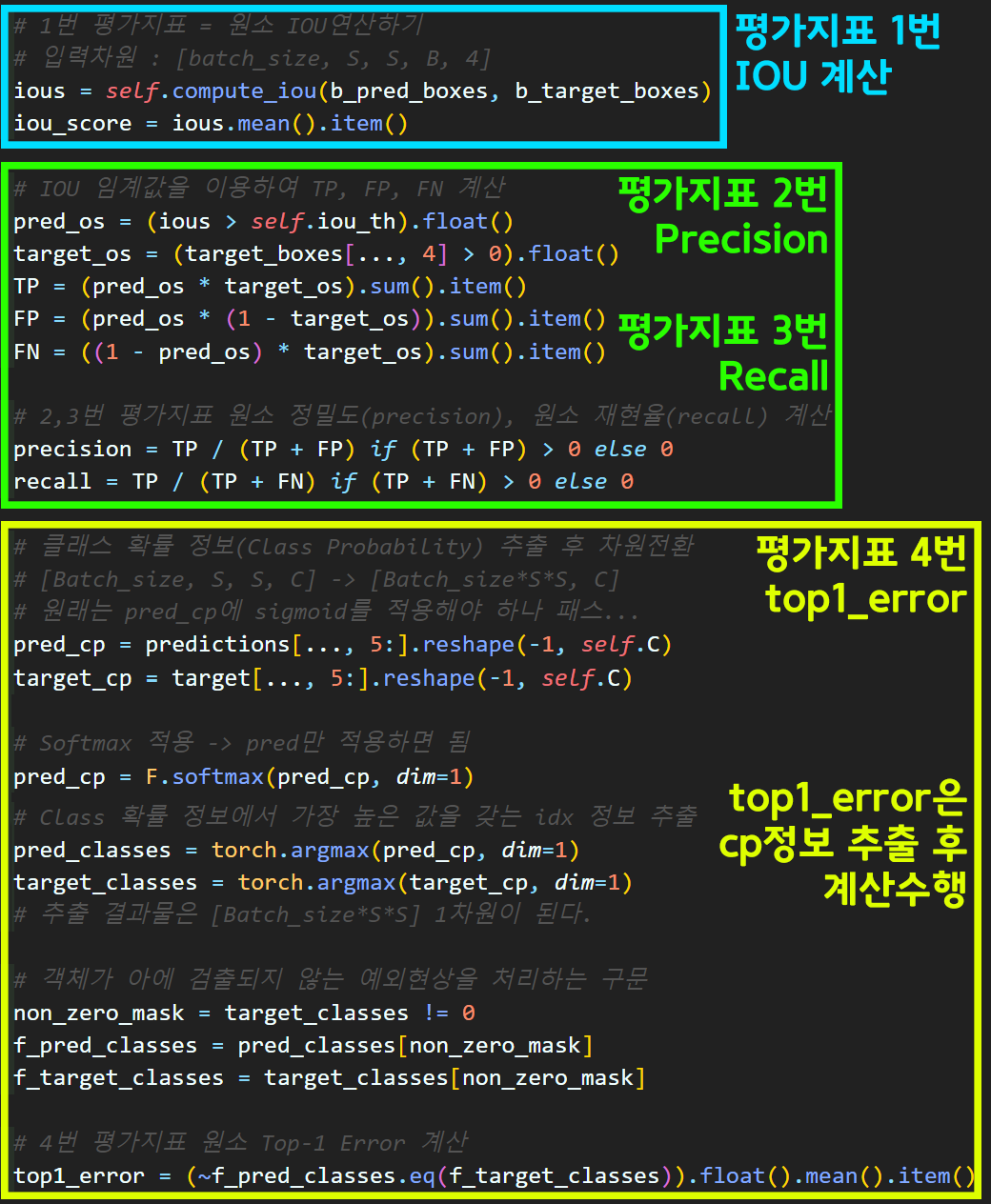
마지막 원소별 metric 값연산부분은 딱히 큰 의미가 있는 코드는 별로 없기에 항목별로 분류 후 넘어가도록 하겠다.
4) convert_b_bbox, get_pred_bbox 함수
이 두 함수의 경우 도식화를 하자면
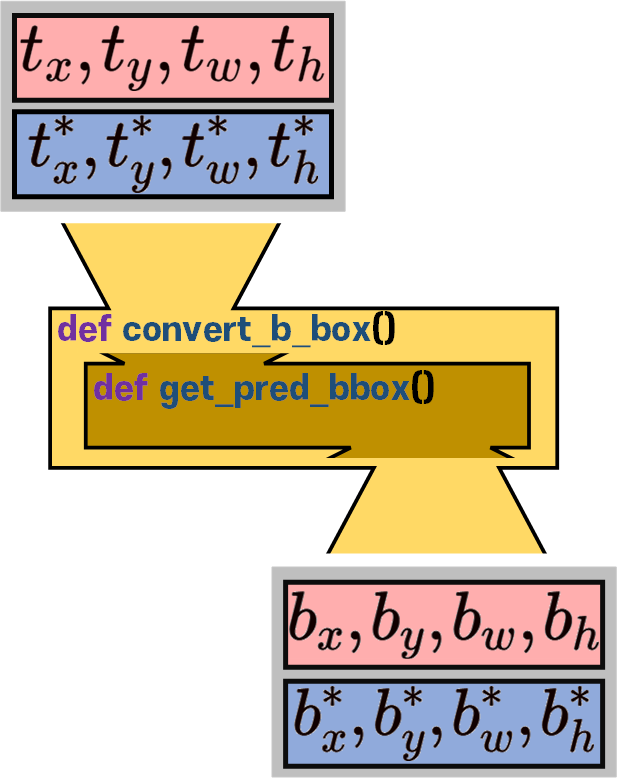
이런 식으로 함수 안에 함수가 하나 더 있는 식으로 되어 있다..
뭐 앞서 3) convert_b_bbox도 이 convert_b_bbox, get_pred_bbox를 품은 구주긴 하지만
convert_b_bbox, get_pred_bbox 이 두함수는 특히 더 연계된 부분이 많아서 한번에 설명하고자 한다.
# [tx, ty, tw, th] -> [bx, by, bw, bh]의 수행을 준비하는 함수
def convert_b_bbox(self, pred_boxes, target_boxes):
# 마스크 필터 생성하기(yolo v3 Loss와 동일한 방식
target_obj = target_boxes[..., 4]
coord_mask = target_obj > 0
noobj_mask = target_obj <= 0
#예외처리 구문
if coord_mask.sum() == 0:
b_pred_boxes = torch.zeros_like(pred_boxes[..., :4])
b_target_boxes = torch.zeros_like(target_boxes[..., :4])
return b_pred_boxes, b_target_boxes
# 필터링의 응용 -> 의미없는 셀을 탈락시키지 말고 0으로 치환하기
pred_boxes[noobj_mask] = 0
target_boxes[noobj_mask] = 0
S = pred_boxes.size(1)
# 그리드 셀의 idx를 저장용 매쉬 그리드 행렬 생성
# 이 매쉬 그리드는 글로 설명하긴 어려운데 아무튼 idx을 저장하는 효율적인 행렬이다
grid_y, grid_x = torch.meshgrid(torch.arange(S), torch.arange(S), indexing='ij')
grid_y = grid_y.to(self.device).float()
grid_x = grid_x.to(self.device).float()
# 생성한 매쉬그리드는 CPU에 할당되서 GPU로 이전을 꼭 시켜줘야함
# 모델의 예측값 tx, ty는 사전에 sigmoid를 적용한다.
pred_boxes[..., 0] = torch.sigmoid(pred_boxes[..., 0])
pred_boxes[..., 1] = torch.sigmoid(pred_boxes[..., 1])
# [tx, ty, tw, th] -> [bx, by, bw, bh]의 실제 변환은 이 함수에서 수행됨
b_pred_boxes = self.get_pred_bbox(pred_boxes, self.anchor, grid_x, grid_y, S)
# [t*x, t*y, t*w, t*h] -> [b*x, b*y, b*w, b*h]의 실제 변환은 이 함수에서 수행됨
b_target_boxes = self.get_pred_bbox(target_boxes, self.anchor, grid_x, grid_y, S)
return b_pred_boxes, b_target_boxes
# [tx, ty, tw, th] -> [bx, by, bw, bh]변환을 실제로 수행하는 함수
# [t*x, t*y, t*w, t*h] -> [b*x, b*y, b*w, b*h]변환을 실제로 수행하는 함수
def get_pred_bbox(self, t_bbox, anchor, grid_x, grid_y, S):
# 여기에 들어오는 [tx], [ty], [tw], [th]는 모두
# [Batch_size, S, S, B] 형태임 -> B : [anchor1, 2, 3]
tx, ty = t_bbox[..., 0], t_bbox[..., 1]
tw, th = t_bbox[..., 2], t_bbox[..., 3]
# cnt는 작은 -> 중간 -> 큰 객체의 리스트를 순환하는 변수고
# anchor box list에서 cnt 값에 맞춰 객체 크기용
# box [3x2]를 가져옴 -> [3(B)], [3(B)]으로 나눠가짐
pw, ph = anchor[self.cnt][..., 0], anchor[self.cnt][..., 1]
# meshgrid로 정의된 grid_x, grid_x는 모두 [S, S]차원을 가짐
# [S, S] -> [1, S, S, 1] -> [batch_size, S, S, C+5]로 차원확장
grid_x = grid_x.unsqueeze(0).unsqueeze(-1).expand_as(tx)
grid_y = grid_y.unsqueeze(0).unsqueeze(-1).expand_as(ty)
# grid / s -> 이것은 그리드셀의 좌상돤 좌표값이 됨(cx, cy)
# tx, ty는 sigmoid처리돤 c_pos와 b_pos의 '상대적인 거리'
# 모두 정규화 좌표평면이니 t_pos도 1/s 처리 해줘야함
bx = (tx + grid_x) / S
by = (ty + grid_y) / S
bw = pw * torch.exp(tw)
bh = ph * torch.exp(th)
# 좌표변환이 완료된 [bx, by, bw, bh]은 스택으로 쌓아서 return
b_bbox = torch.stack([bx, by, bw, bh], dim=-1)
return b_bbox음.. 여기서 중요하게 설명할 법한 코드는

torch.meshgrid라는 메서드인데
위 사진처럼 진짜 idx만을 위한 matrix 2개를 생성하겠다
라는 뜻이라고 보면 된다.
각잡고 매트릭스 데이터의 idx를 핸들링 하고 싶다면
torch.meshgrid를 이용하라..
라고 만든 의지가 보이는 메서드다.
이때 [y, x]순으로 순서를 정해서 만들어야 한다.
그래야 나중에 좌표변환에 해당 값들을 사용할 때 안꼬인다.
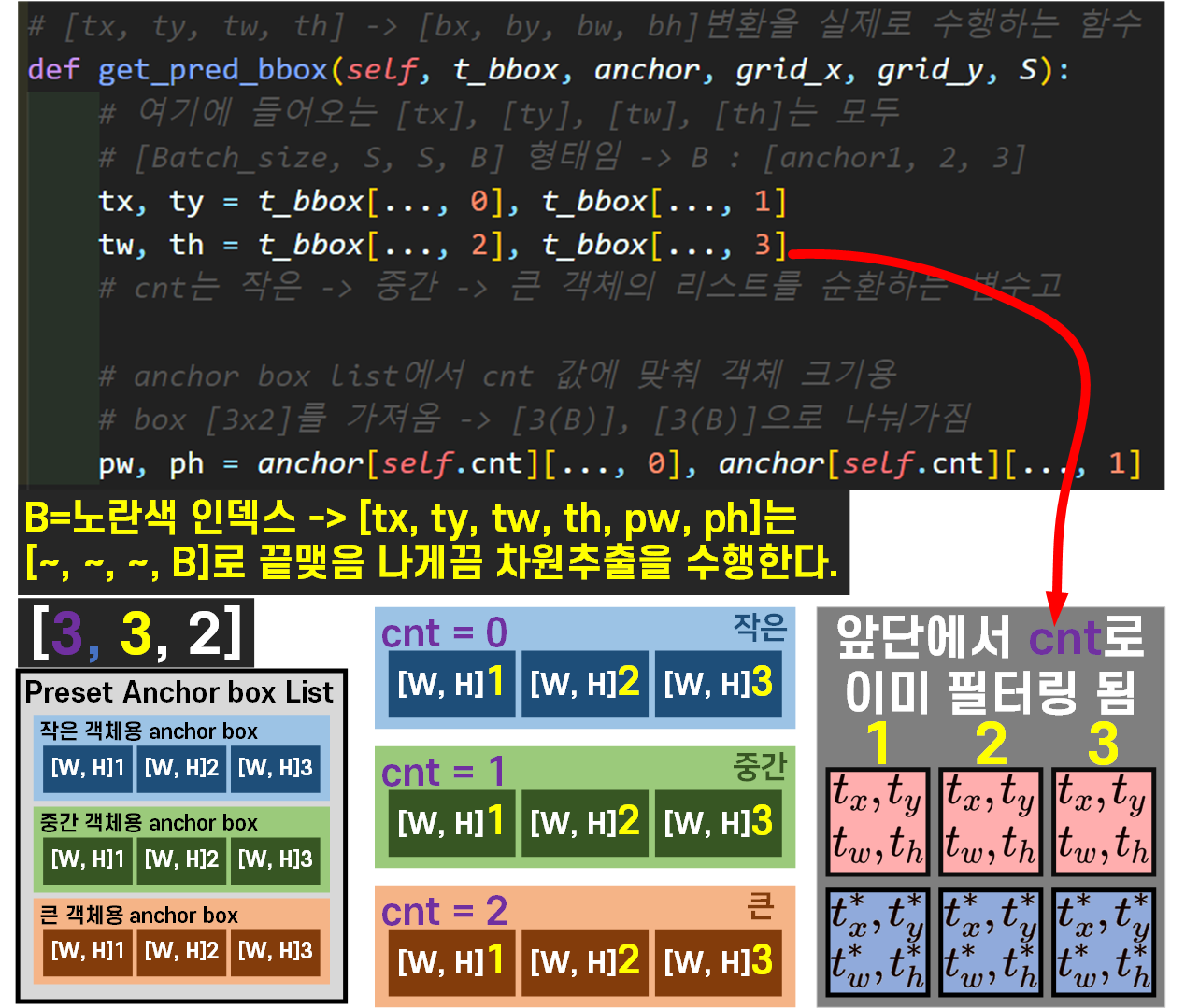
두번째로 anchor_box_list는 cnt변수로 필터링 받는 시점이 굉장히 늦기때문에
조금 헤메는 경우가 발생한다.
따라서 이 부분에 대해서는 그림으로 표현한다.
결론만 말하자면 tx, ty, tw, th에 입력되는 값은
한참 전에 cnt로 필터링이 완료된 값이고
anchor_box_list는 위 사진에서 최초로 cnt필터링을 적용받는다.. 이렇게 보면 될것 같다.
음.. 이정도면 YOLOv3Metrics에서 설명할 주요 항목들은 다 한거 같다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
metrics = YOLOv3Metrics(anchor=anchor_box_list, device=device.type)이렇게 적절한 타이밍에 인스턴스화 해주고
metric_res = metrics.cal_acc_func(outputs, labels)위 코드처럼 가장 main 함수 구문이라 볼 수 있는
cal_acc_func메서드에 필요한 인자값 outputs, labels를 넣어주면
해당 클래스가 평가지표 4종
iou, precision, recall, top-1_error을 출력한다.
2. Train / Val 함수 설계
이전 포스트 인공지능 고급(시각) 강의 예습 - 19. Yolo v1 (4) 평가지표 설계 + Train/val 수행
에서 소개한
3) train, evaluate 함수 설계를 거의 그대로 사용했지만 중대한 차이점이 존재한다.
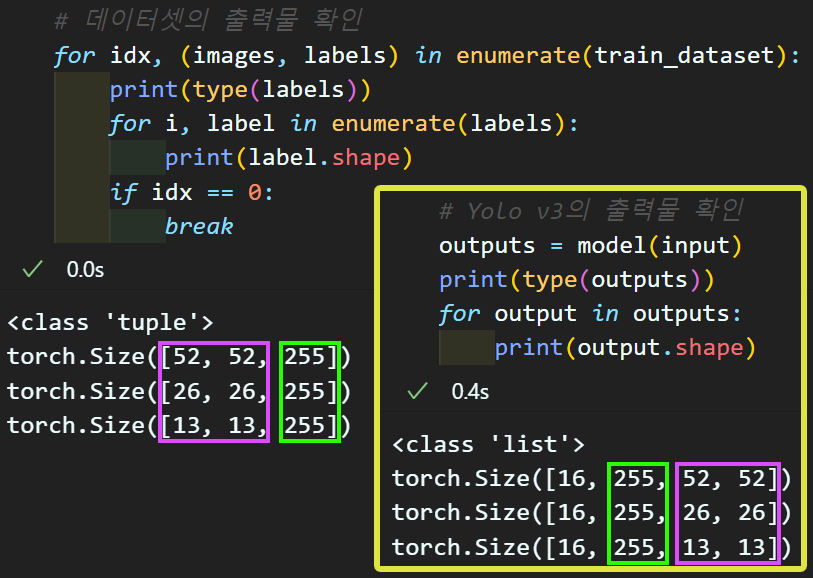
위 사진은 Yolo v3의 모델 출력인 outputs의 shape 정보와
데이터의셋의 처리 완료 상태인Dataloader의 출력 labels의 shape 정보를 출력한 것이다.
labels은 [batch_size, S, S, B*(5+C)] 이고
outputs은 [batch_size, B*(5+C), S, S] 이다.
차원의 순번이 서로 다르다

Yolo v3로 넘어오면서 모델의 출력 차원 배치가 Yolo v1과는 달라졌는데
데이터셋은 그대로 Yolo v1버전의 차원배치를 그대로 쓰다보니
발생한 참사다;;;
그래도 다행스럽게도 tensor 라이브러리는
차원배치에 관해서는 좋은 라이브러리르 많이 제공한다
torch.permute(0, 2, 3, 1)이 명령어 하나면
Yolo v3의 꼬여있는 차원을 내가 원하는 차원정보로 변환이 가능하다.
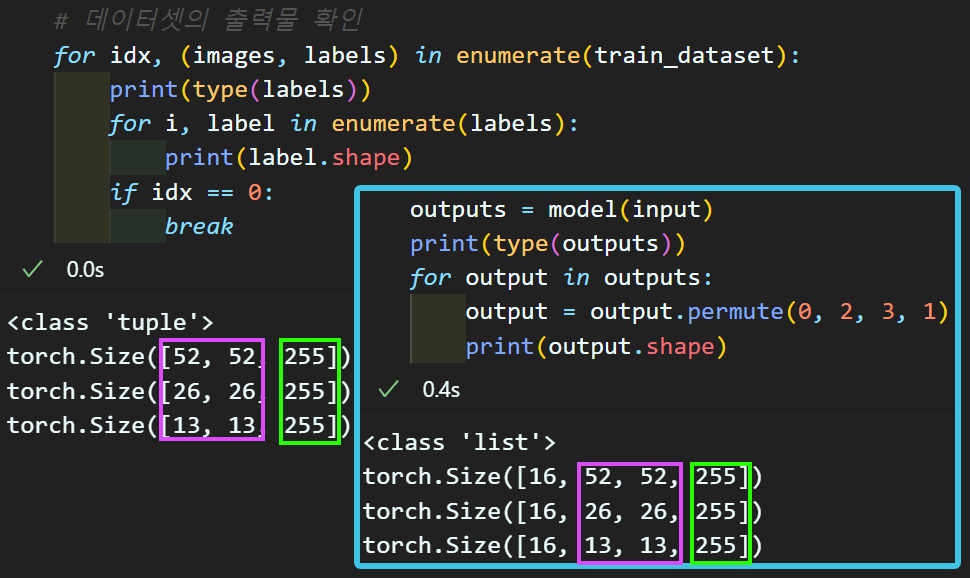

이 부분을 왜 설명하냐면
model_train / model_evaluate 함수에서 해당 코드가 필수적으로 적용되고
또 필자의 경우 저 문제로 인한 차원오류가 아주 박터지게 나서
내상을 많이 입어서 이다....
아무튼 model_train / model_evaluate 함수의 코드를 첨부하면 아래와 같다.
from tqdm import tqdm #훈련 진행상황 체크
#tqdm 시각화 도구 출력 사이즈 조절 변수
epoch_step = 3def model_train(model, data_loader,
loss_fn, optimizer_fn, scheduler_fn,
processing_device, epoch):
model.train() # 모델을 훈련 모드로 설정
global epoch_step
# loss와 accuracy를 계산하기 위한 임시 변수를 생성
run_size, run_loss, = 0, 0
#Yolo v1의 성능지표는 아래의 4개 항목으로 출력된다.
#이때 성능지표는 이동평균 필터로 계산한다.
avg_iou, avg_precision, avg_recall, avg_top1_error = 0, 0, 0, 0
n = 0 # 값의 개수
# 특정 에폭일 때만 tqdm 진행상황 바 생성
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar = tqdm(data_loader)
else:
progress_bar = data_loader
# label은 리스트이니 labels로 이름변경함
for image, labels in progress_bar:
# 입력된 데이터를 먼저 GPU로 이전하기
image = image.to(processing_device)
# 라벨이 리스트 정보이기에 한개씩 떼어낸다.
labels = [label.to(processing_device) for label in labels]
# 전사 과정 수행
outputs = model(image)
# 여기서 출력되는 outputs도 리스트 -> 그리고 원소의 차원위치 변환해줘야함
# [batch_size,(C+5),S,S] 출력을 [batch_size,S,S,(C+5)]로 변환
outputs = [output.permute(0, 2, 3, 1) for output in outputs]
loss = 0
# 원소별 output, label에 대한 원소별 손실을 구한 뒤 합산
for output, label in zip(outputs, labels):
loss_elemnet = loss_fn(output, label)
loss += loss_elemnet
#backward과정 수행
optimizer_fn.zero_grad()
loss.backward()
optimizer_fn.step()
# 스케줄러 업데이트
scheduler_fn.step()
#현재까지 수행한 loss값을 얻어냄
run_loss += loss.item() * image.size(0)
run_size += image.size(0)
#성능지표 계산하기 -> 리스트이니 outputs, labels임을 유의하자.
metric_res = metrics.cal_acc_func(outputs, labels)
iou_score, precision, recall, top1_error = metric_res
# 이동평균 필터로 성능지표 계산하기
n += 1
avg_iou = avg_iou + (iou_score - avg_iou) / n
avg_precision = avg_precision + (precision - avg_precision) / n
avg_recall = avg_recall + (recall - avg_recall) / n
avg_top1_error = avg_top1_error + (top1_error - avg_top1_error) / n
#tqdm bar에 추가 정보 기입
if (epoch + 1) % epoch_step == 0 or epoch == 0:
desc = (f"[훈련중] Loss: {run_loss / run_size:.2f}, "
f"KPI: [{avg_iou:.3f}, {avg_precision:.3f}, "
f"{avg_recall:.3f}, {avg_top1_error:.3f}]")
progress_bar.set_description(desc)
# avg_accuracy = correct / len(data_loader.dataset)
avg_loss = run_loss / len(data_loader.dataset)
avg_KPI = [avg_iou, avg_precision, avg_recall, avg_top1_error]
return avg_loss, avg_KPIdef model_evaluate(model, data_loader, loss_fn,
processing_device, epoch):
model.eval() # 모델을 평가 모드로 전환 -> dropout 기능이 꺼진다
# batchnormalizetion 기능이 꺼진다.
global epoch_step
# 초기값 설정
run_loss = 0
avg_iou, avg_precision, avg_recall, avg_top1_error = 0, 0, 0, 0
n = 0 # 값의 개수
# gradient 업데이트를 방지해주자
with torch.no_grad():
# 특정 에폭일 때만 tqdm 진행상황 바 생성
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar = tqdm(data_loader)
else:
progress_bar = data_loader
for image, labels in progress_bar: # 이때 사용되는 데이터는 평가용 데이터
# 입력된 데이터를 먼저 GPU로 이전하기
image = image.to(processing_device)
# 라벨이 리스트 정보이기에 한개씩 떼어낸다.
labels = [label.to(processing_device) for label in labels]
# 평가 결과를 도출하자
outputs = model(image)
# 여기서 출력되는 outputs도 리스트 -> 그리고 원소의 차원위치 변환해줘야함
# [batch_size,(C+5),S,S] 출력을 [batch_size,S,S,(C+5)]로 변환
outputs = [output.permute(0, 2, 3, 1) for output in outputs]
loss = 0
# 원소별 output, label에 대한 원소별 손실을 구한 뒤 합산
for output, label in zip(outputs, labels):
loss_elemnet = loss_fn(output, label)
loss += loss_elemnet
# 배치의 실제 크기에 맞추어 손실을 계산
run_loss += loss.item() * image.size(0)
#성능지표 계산하기 -> 리스트이니 outputs, labels임을 유의하자.
metric_res = metrics.cal_acc_func(outputs, labels)
iou_score, precision, recall, top1_error = metric_res
# 이동평균 계산
n += 1
avg_iou = avg_iou + (iou_score - avg_iou) / n
avg_precision = avg_precision + (precision - avg_precision) / n
avg_recall = avg_recall + (recall - avg_recall) / n
avg_top1_error = avg_top1_error + (top1_error - avg_top1_error) / n
#tqdm bar에 추가정보 기입은 eval은 뺀다... 귀찮음
# accuracy = correct / len(data_loader.dataset)
avg_loss = run_loss / len(data_loader.dataset)
avg_KPI = [avg_iou, avg_precision, avg_recall, avg_top1_error]
return avg_loss, avg_KPI3. 실행 및 코드 검토
지금까지 작성한 코드가 재대로 동작하는지?
그리고 설계한 평가지표가 적절한 값을 출력하는지?
확인을 해보도록 하자

데이터셋 선언, 모델 및 평가지표 클래스 GPU이전
하이퍼 파라미터 설정
이 3가지 과정을 거친 후
# 학습과 검증 손실 및 정확도를 저장할 리스트
his_loss = []
his_KPI = []
num_epoch = 30
for epoch in range(num_epoch):
# 훈련 손실과 훈련 성과지표를 반환 받습니다.
train_loss, train_KPI = model_train(model, train_loader,
criterion, optimizer, scheduler,
device, epoch)
# 검증 손실과 검증 성과지표를 반환 받습니다.
test_loss, test_KPI = model_evaluate(model, test_loader,
criterion, device, epoch)
# 손실과 성능지표를 리스트에 저장
his_loss.append((train_loss, test_loss))
his_KPI.append((train_KPI, test_KPI))
# epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"Training loss: {train_loss:.4f}")
print(f"Train KPI[ IOU: {train_KPI[0]:.4f}, "+
f"Precision: {train_KPI[1]:.4f}, "+
f"Recall: {train_KPI[2]:.4f}, "+
f"Top1_err: {train_KPI[3]:.4f} ]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"Test loss: {test_loss:.4f}")
print(f"Test KPI[ IOU: {test_KPI[0]:.4f}, "+
f"Precision: {test_KPI[1]:.4f}, "+
f"Recall: {test_KPI[2]:.4f}, "+
f"Top1_err: {test_KPI[3]:.4f} ]")실행코드를 돌려보자
숱한 코드 오류가 발생했었고
일일이 디버깅 과정을 다 거치고 나니
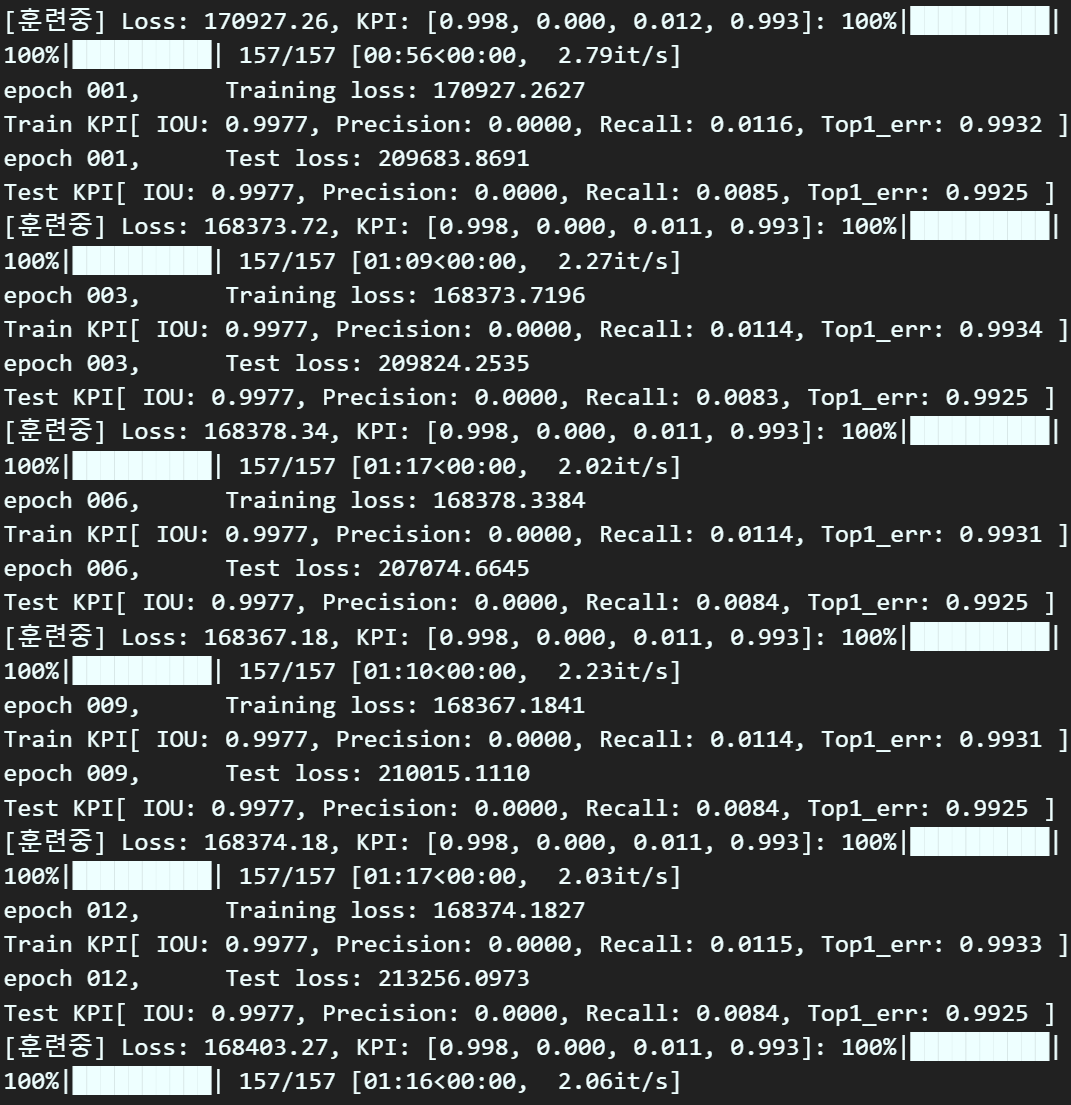 재대로 동작함을 확인했다.
재대로 동작함을 확인했다.

import numpy as np
import matplotlib.pyplot as plt
#histroy는 [train, test] 순임
#KPI는 [iou, precision, recall, top1_error] 순임
np_his_loss = np.array(his_loss)
np_his_KPI = np.array(his_KPI)
# his_loss에서 손실 데이터 추출
train_loss, val_loss = np_his_loss[..., 0], np_his_loss[..., 1]
# his_KPI에서 각 성능 지표 추출
train_iou, val_iou = np_his_KPI[..., 0, 0], np_his_KPI[..., 1, 0]
train_precision, val_precision = np_his_KPI[..., 0, 1], np_his_KPI[..., 1, 1]
train_recall, val_recall = np_his_KPI[..., 0, 2], np_his_KPI[..., 1, 2]
train_top1_errors, val_top1_errors = np_his_KPI[..., 0, 3], np_his_KPI[..., 1, 3]
# 2x3 플롯 설정
plt.figure(figsize=(10, 5))
# Train-Val Loss
plt.subplot(1, 2, 1)
plt.plot(train_loss, label='Train Loss')
plt.plot(val_loss, label='Val Loss')
plt.xlabel('Training Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Train-Val Loss')
# Train-Val Top-1 Error
plt.subplot(1, 2, 2)
plt.plot(train_top1_errors, label='Train Top-1 Error')
plt.plot(val_top1_errors, label='Val Top-1 Error')
plt.xlabel('Training Epochs')
plt.ylabel('Top-1 Error')
plt.legend()
plt.title('Train-Val Top-1 Error')
plt.tight_layout()
plt.show()
plt.figure(figsize=(16, 6))
# IOU
plt.subplot(1, 3, 1)
plt.plot(train_iou, label='Train IOU')
plt.plot(val_iou, label='Val IOU')
plt.xlabel('Training Epochs')
plt.ylabel('IOU')
plt.legend()
plt.title('IOU')
# Precision
plt.subplot(1, 3, 2)
plt.plot(train_precision, label='Train Precision')
plt.plot(val_precision, label='Val Precision')
plt.xlabel('Training Epochs')
plt.ylabel('Precision')
plt.legend()
plt.title('Precision')
# Recall
plt.subplot(1, 3, 3)
plt.plot(train_recall, label='Train Recall')
plt.plot(val_recall, label='Val Recall')
plt.xlabel('Training Epochs')
plt.ylabel('Recall')
plt.legend()
plt.title('Recall')
plt.tight_layout()
plt.show()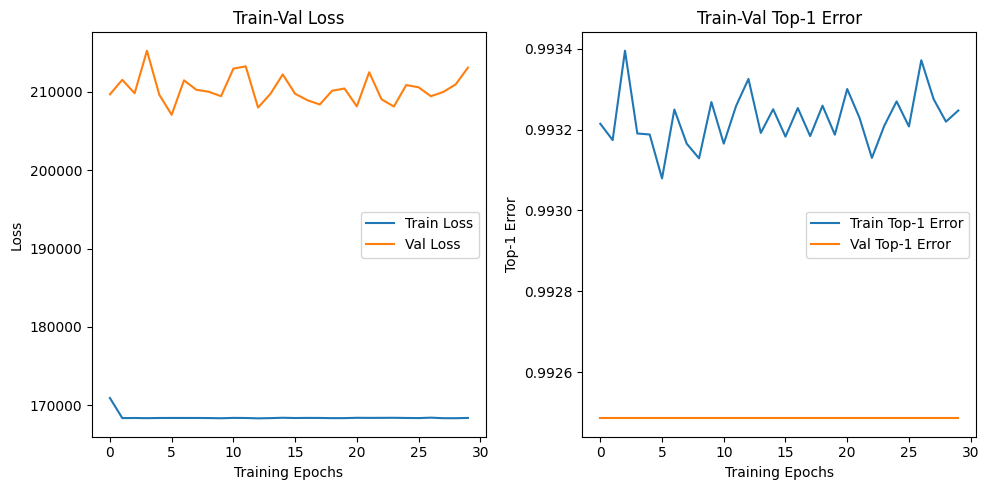
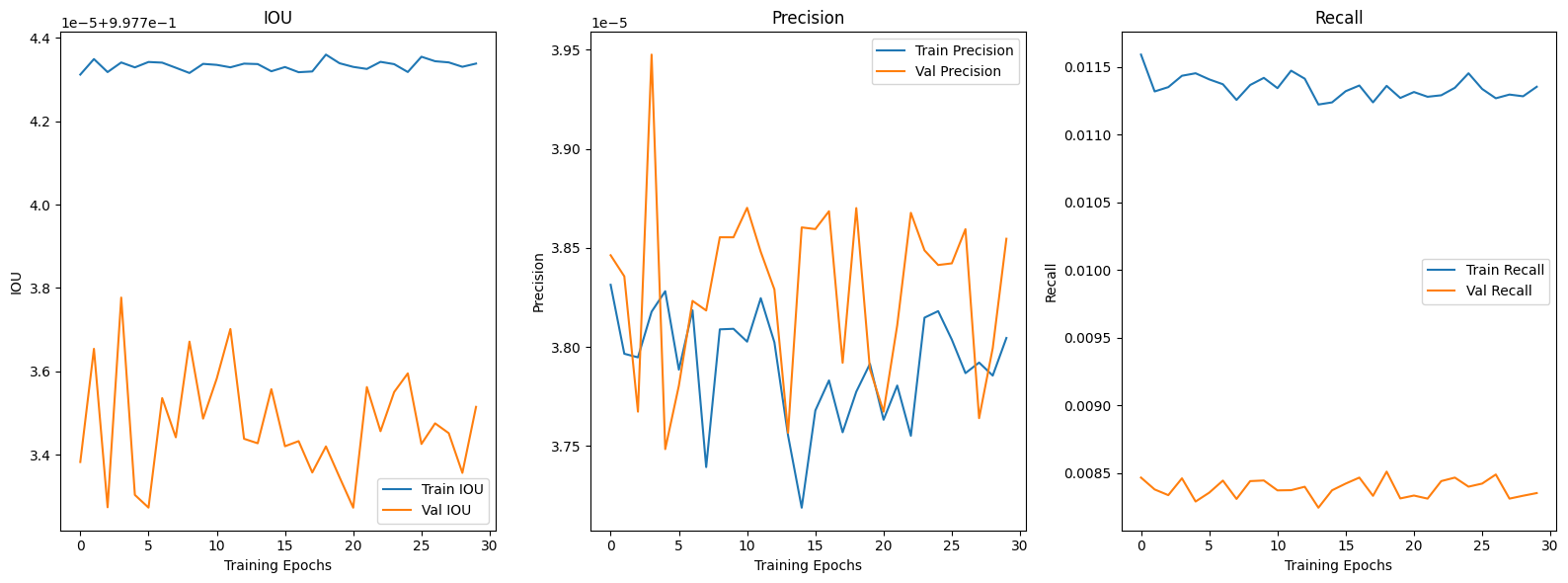
설계한 평가지표도 epoch가 진행되면서 값의 변동이 발생하는 것을 보니
작성한 모든 함수가 논리에러가 없이 잘 동작하는 것을 확인할 수 있었다.
이제 아래 두개의 큰 산을 넘으면 된다
- 모듈화
- Pretrained Model 적용

이제 그동안 작성한 나쁜 코드를 좋은 코드로 변환하는 작업을 수행하면 된다
고지가 눈앞이다.
