
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. 모듈화 및 Git 등록
앞서 인공지능 고급(시각) 강의 예습 - 22.Yolo v3에 대해 충실하게 포스트를 따라서 코드 실습을 했다면
아마 독자분들의 머리가 터져나가지 않았을까 하는 조심스러운 예측이 있다.

이유는.. 코드 오류가 발생해서 중간중간 수정한게 많다.
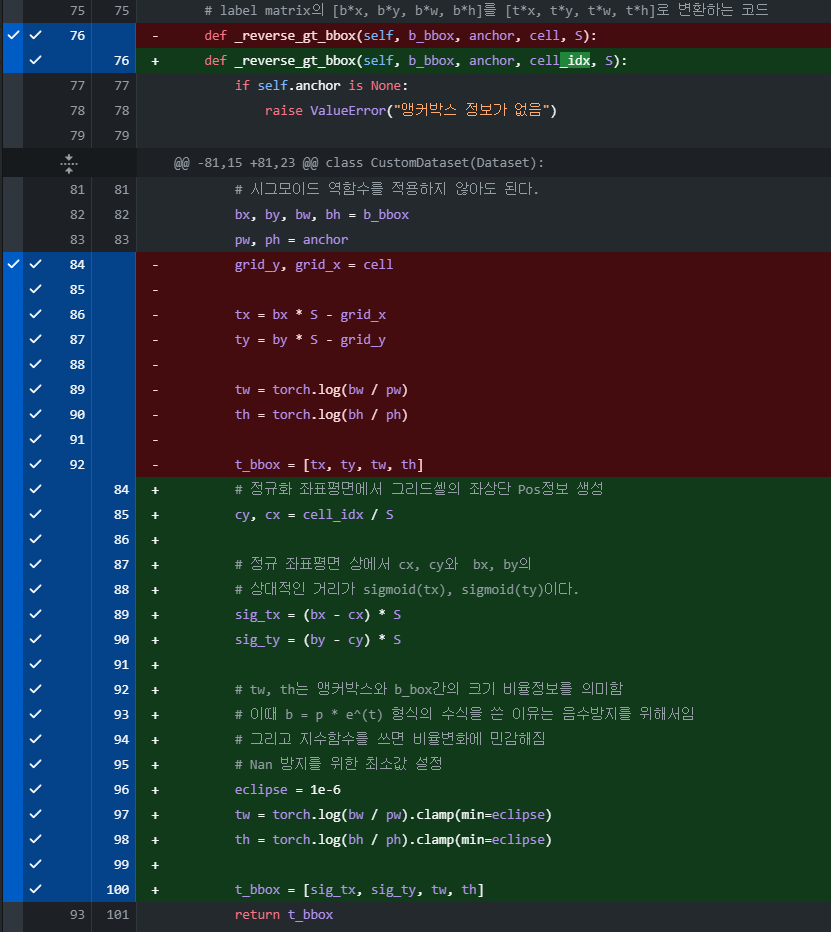



이런식으로 코드 오류 수정을 계속 해가면서 포스트 내용을 수정하느라 많이 힘들었다
특히
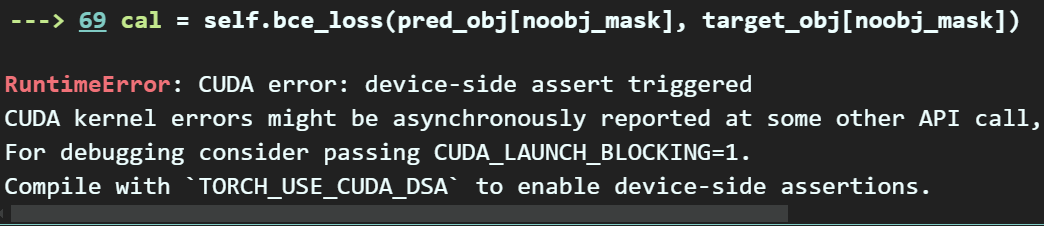
이 CUDA error: device-sizd assert triggered~~로 시작하는 오류가 발생해서 이 오류를 수정하는데 머리터지는줄 알았다.
좀 더 자세하게 컴파일 해보려면
import os
os.environ["TORCH_USE_CUDA_DSA"] = '1' # CUDA 커널 내부에서 assert 구문을 활성화이걸 적용해서 좀더 자세한 컴파일 옵션을 활성화 하라는데
이래도 문제를 찾기 어려웟다 ㅋㅋㅋ
Loss를 계산하는 BCE쪽에서 입력되는 인자값에 NaN이 포함되서 계산이 안된다는데
어디서 NaN값이 출력되는지 다 찾아봐야 해서 머리 터지는줄 알았다.
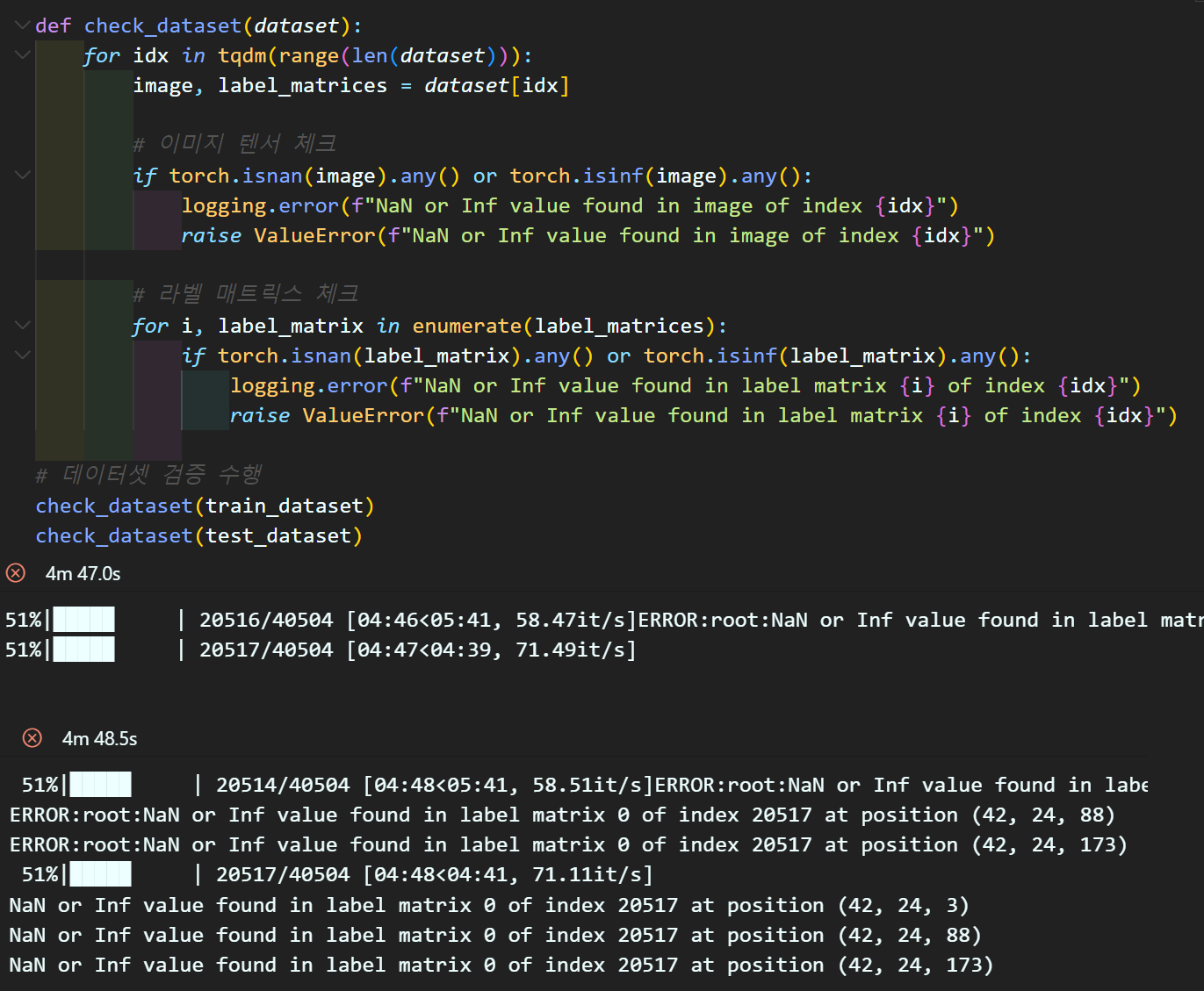
데이터셋을 생성하는 코드쪽에서 데이터를 전수검사를 해보니까
b_box 그러니까
로 변환하는 과정에서 NaN값이 발생했고
이 오류를 수정한 것이
 이 구문이 된다.
이 구문이 된다.
진짜 찾기 힘든 오류 참 많다....
아무튼 현재 업로드 된 모든 코드(블로그 포스팅 된 내용까지) 코드 에러가 다 잡힌 완성된 코드라 볼 수 있다.
검증의 끝을 봤기에 하나의 *.ipynb파일로 작성하던 내용들은
6개의 *.py파일과 그것을 핸들링하는 단 하나의 main.ipynb파일로
모듈화를 완료했다.
완료한 모듈화 코드들의 모음은 아래의 git 저장소 페이지
https://github.com/tbvjvsladla/yolo_v3_pytorch
에 업로드를 완료했고
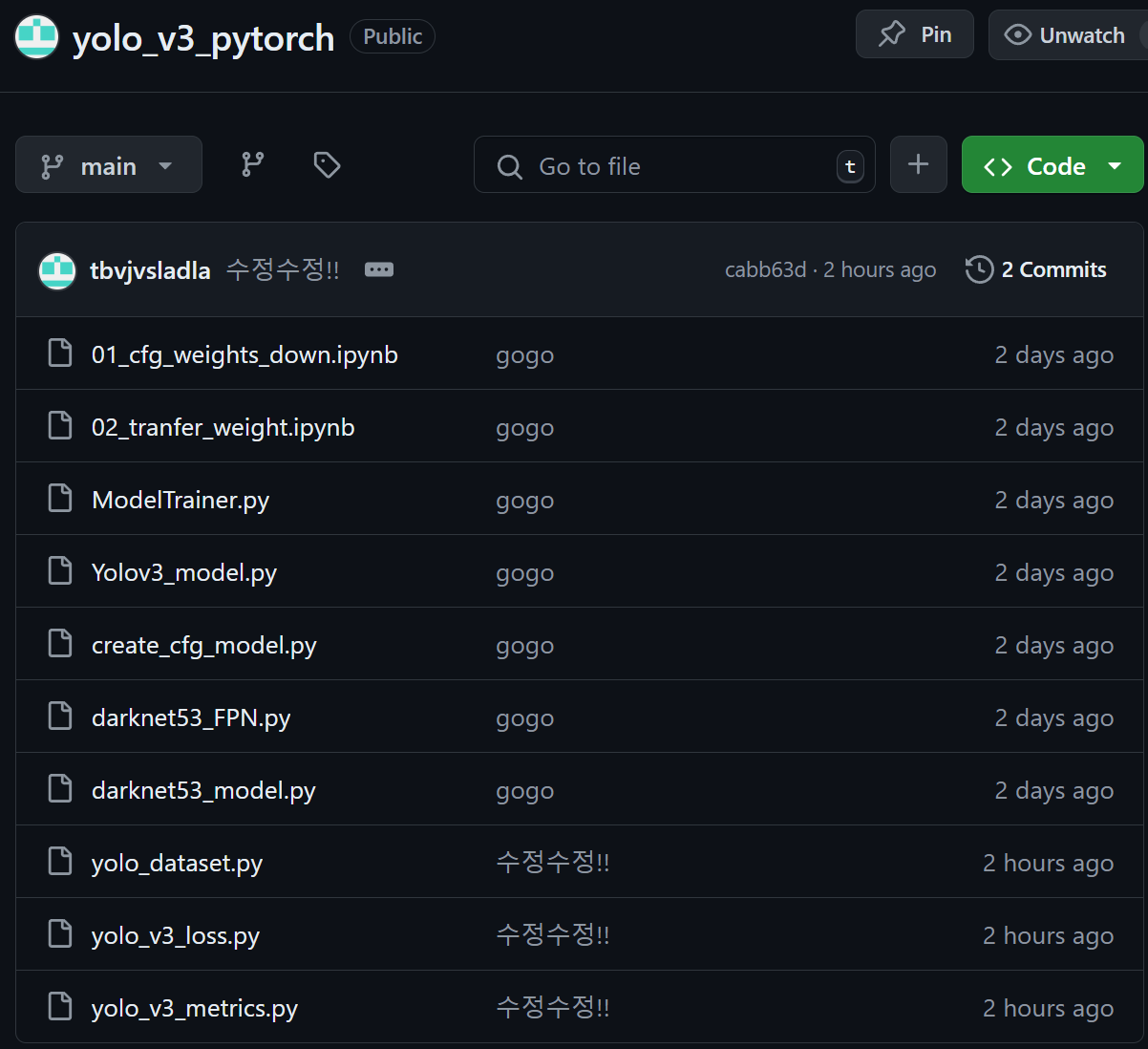
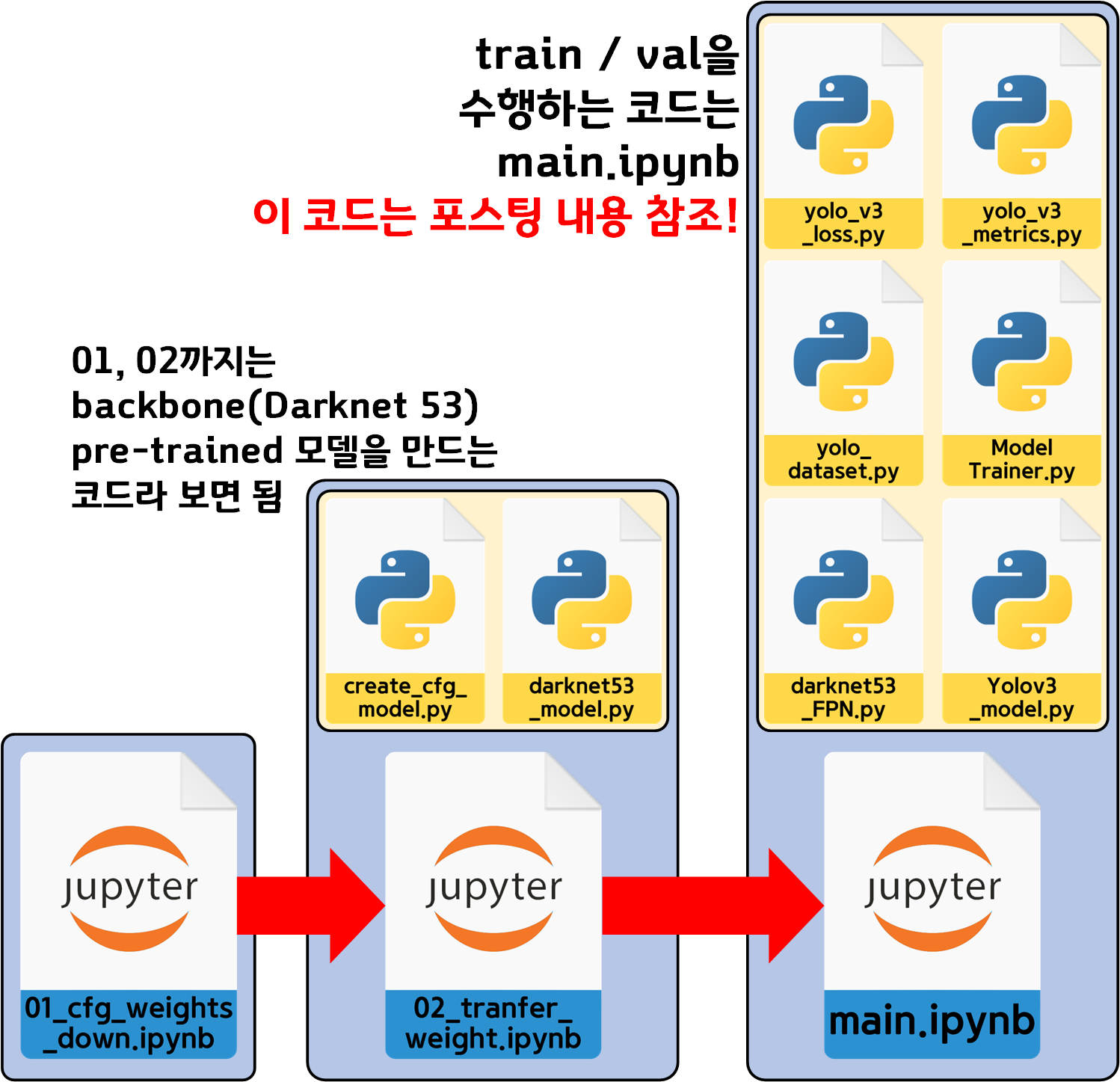
각 코드별 필요 *.py항목을 확인하기 바란다.
2. 01_cfg_weights_down
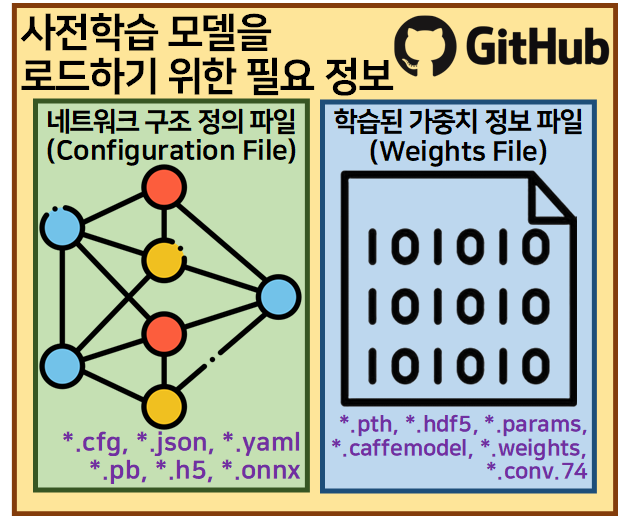
해당 파일은 Yolo v3의 주 저자 Joseph Redmon의 Yolo 소개 홈페이지 및 git 홈페이지에서 아래의 2개 파일
Configuration File : darknet53.cfg
Weights Files : darknet53.weights
파일을 다운로드하는 과정을 수행하는 코드이다.
import requests, os
import wget
from tqdm import tqdmcfg_url = "https://raw.githubusercontent.com/pjreddie/darknet/master/cfg/darknet53.cfg"
cfg_filename = "darknet53.cfg"
weights_url = "https://pjreddie.com/media/files/darknet53.weights"
weights_filename = "darknet53.weights"# CFG 파일 다운로드
if not os.path.isfile(cfg_filename):
wget.download(cfg_url, cfg_filename)
print(f"\n{cfg_filename} has been downloaded.")
else:
print(f"{cfg_filename} already exists. Skipping download.")
# CFG 파일 다운로드
if not os.path.isfile(cfg_filename):
wget.download(cfg_url, cfg_filename)
print(f"\n{cfg_filename} has been downloaded.")
else:
print(f"{cfg_filename} already exists. Skipping download.")# WEIGHTS 파일 다운로드 준비 및 용량 출력
response = requests.get(weights_url, stream=True)
total_size = int(response.headers.get('content-length', 0))
print(f"File size: {total_size / (1024 * 1024):.2f} MB")File size: 158.87 MBwith open(weights_filename, 'wb') as f, tqdm(
desc=weights_filename,
total=total_size,
unit='iB',
unit_scale=True,
unit_divisor=1024,
) as bar:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
bar.update(len(chunk))
print(f"{weights_filename} has been downloaded.")darknet53.weights: 100%|██████████| 159M/159M
[01:12<00:00, 2.30MiB/s]
darknet53.weights has been downloaded.이렇게 네트워크 구조 정의 파일(Configuration File), 학습 파라미터 파일(Weights Files)의 다운로드 부터 시작하는 이유는 첫번째 포스트 내용부터 모듈화를 진행하는게 옳은 듯 하고...
아무래도 해당 과정은 다시 한번 더 수행해야 할 것 같은 불길한 기분이 들어서 이다... 라고 생각해두자..
3. 02_transfer_weight
이 실행파일은
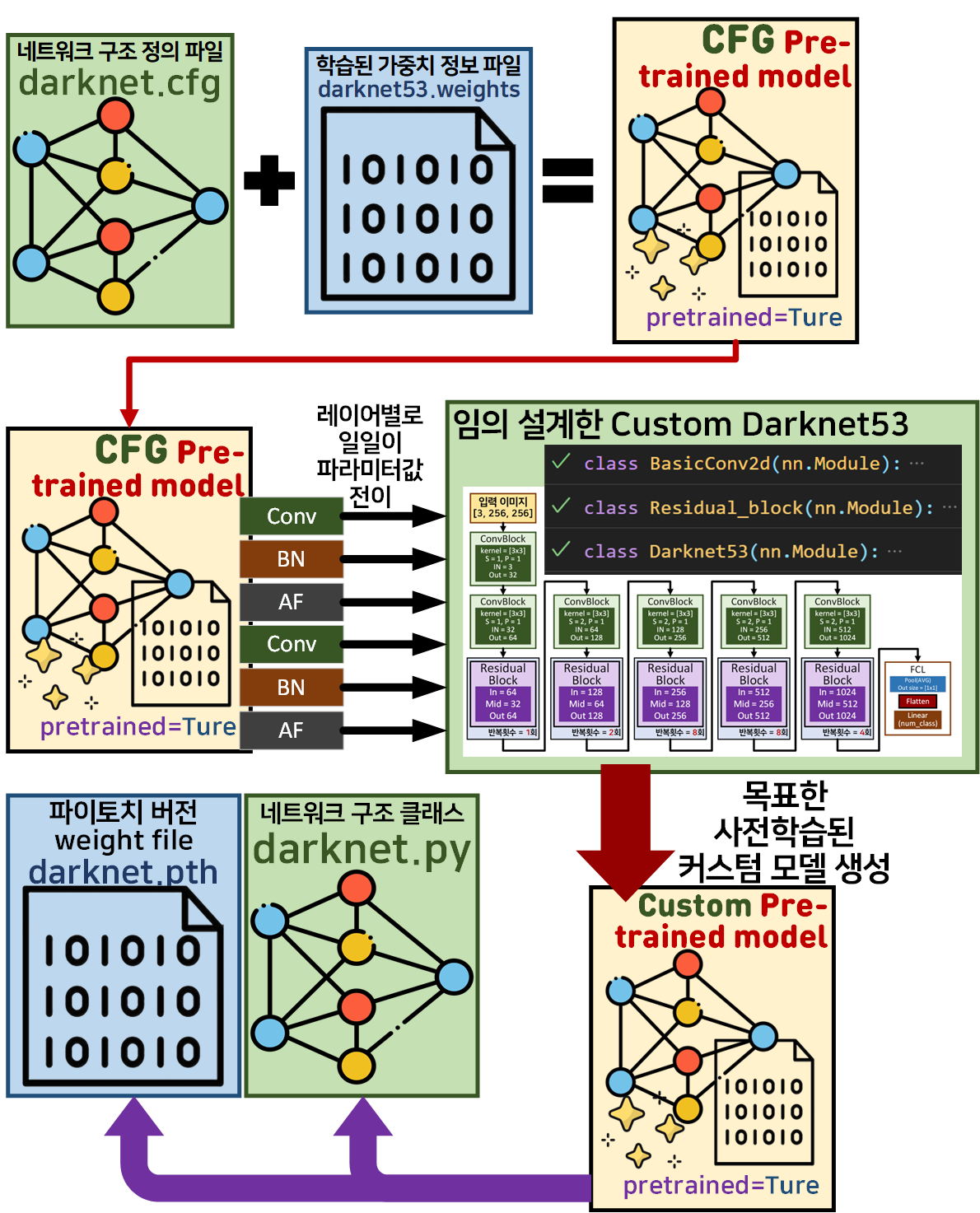 이전 포스트
이전 포스트 인공지능 고급(시각) 강의 예습 - 22. (0) Yolo v3 사전 학습 모델의 결과물이라 볼 수 있는
사용이 용이한 네트워크 구조 정의 파일(Configuration File), 학습 파라미터 파일(Weights Files)를 만드는 과정이라 보면 된다.
import torch
# cfg 파일을 읽어서 모델을 복원하는 파일
import create_cfg_model as cm
#사용이 용이한 darknet53 구조 정의 파일
import darknet53_model as darknet53 cfg_file = "darknet53.cfg"
weight_file = "darknet53.weights"
# CFG파일 파싱
blocks = cm.parse_cfg(cfg_file)
# CFG 모델 인스턴스화
cfg_model = cm.Darknet_cfg(blocks)
# pre-trained weights로 CFG 모델 초기화
cm.load_weights(cfg_model, weight_file)# CFG 모델의 디버깅
cm.debug(cfg_model, input_size=(3, 256, 256))Input size: (3, 256, 256)
Output size: torch.Size([1, 1000, 8, 8])# 사용이 용이한 네트워크 구조 정의 파일로 모델 인스턴스화
model = darknet53.Darknet53()# 사용이 용이한 모델의 디버깅
darknet53.debug(model, input_size=(3, 256, 256))Input size: (3, 256, 256)
Output size: torch.Size([1, 1000])# cfg_model의 가중치를 추출하여 사용이 용이한 모델에 붙여넣기
def transfer_weights(cfg_model, custom_model):
cfg_params = list(cfg_model.named_parameters())
custom_params = list(custom_model.named_parameters())
for (name_cfg, param_cfg), (name_custom, param_custom) in zip(cfg_params, custom_params):
if param_cfg.data.shape == param_custom.data.shape:
param_custom.data = param_cfg.data.clone()
# print(f"{name_cfg}의 레이어 파라미터를 {name_custom}로 전이")
else:
print(f"{name_cfg}레이어 파라미터를 {name_custom}에 붙여넣지 못함")# 가중치 전이 함수 실행
transfer_weights(cfg_model, model)module_list.76.conv_76.weight레이어 파라미터를 fc.2.weight에 붙여넣지 못함가중치 전이 결과를 보면 사실상 필요 없는 레이어인
fc(classifier)에 해당하는 레이어만 전이 실패를 했고
그 이전의 Feature Extractor에 해당하는 레이어는 모두 가중치 전이에 성공했다.
#전이 완료된 모델 저장하기
MODEL_NAME='DarkNet53'
torch.save(model.state_dict(), f'{MODEL_NAME}.pth')여기까지 수행을 완료했다면
사용이 용이한
네트워크 구조 정의 파일(Configuration File)
학습 파라미터 파일(Weights Files)
파일 생성이 완료된 것이다.
이 02_tranfer_weight.ipynb파일이 요구하는 *.py파일은
https://github.com/tbvjvsladla/yolo_v3_pytorch
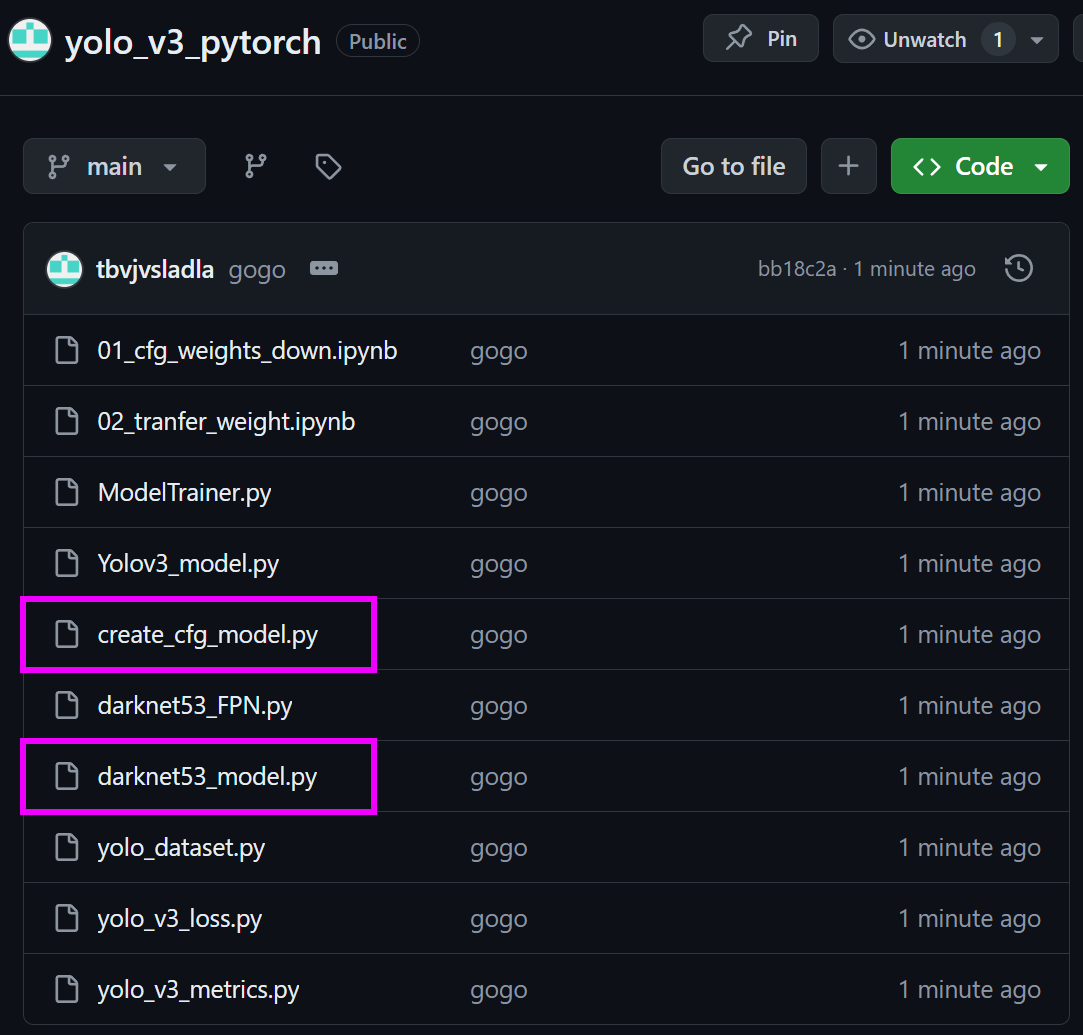
위 저장소에서 보라색 표시한 2개의 파일을 다운받으면 된다.
4. main.ipynb
이제 Train / Val을 본격적으로 수행하는 main.ipynb파일의 코드작성이다.
앞서 도식화된 모듈 정보에서도 알 수 있듯이
해당 파일은 6개의 *.py파일을 필요로 한다.
https://github.com/tbvjvsladla/yolo_v3_pytorch
1) import 부
import torch
import darknet53_FPN as darknet53
from Yolov3_model import YOLOv3, FPN, features_shape, debug
from yolo_dataset import CustomDataset, anchor_box_list
from yolo_v3_loss import Yolov3Loss, loss_debug
# yolo_v3_metrics파일은 ModelTrainer.py에 import되기에 여기서는 추가 안해도 됨
# from yolo_v3_metrics import YOLOv3Metrics, anchor_box_list, metrics_debug
from ModelTrainer import ModelTrainer이 중 yolo_v3_metrics.py는 ModelTrainer.py에 import되어 동작하기에 main.ipynb에는 포함시키지 않아도 된다.
2) 모델 선언부
# 모델 초기화(backbone는 사전학습모델 로드)
backbone = darknet53.Darknet53(pretrained=True)
fpn = FPN(channels_list=features_shape)
yolov3 = YOLOv3(backbone, fpn, num_classes=80)Yolo v3의 모델 클래스 구조가 backbone, fpn, yolohead 3개의 클래스로 나누어 볼 수 있지만
yolohead이 레이어는 YOLOv3 모델 클래스 안에서 nn.ModuleList로 클래스 설계도를 가져오기에
backbone, fpn만 따로 인스턴스화 한다.
이때 Pre-trained model은 backbone(DarkNet53) 1종 뿐이니 해당 모델만 인자 옵션 pretrained=True을 적용한다.
# 백본 파라미터 Freeze
for param in backbone.parameters():
param.requires_grad = False그리고 위 코드를 기입하여 전체 Yolo v3의 모델 레이어 중 Pre-trained 처리된 backbone부분의 Parm만을 Freeze적용한다.
3) 데이터셋 전처리 부
다음으로 Train / Val의 대상 Img, Anno파일들을 불러와서 전처리 작업을 수행한다.
# coco데이터셋의 메인 루트 디렉토리
root_dir = '[COCO dataset]루트 디렉토리'
# 데이터셋 생성
train_dataset = CustomDataset(root=root_dir, img_set='train', anchor=anchor_box_list)
test_dataset = CustomDataset(root=root_dir, img_set='val', anchor=anchor_box_list)from torchvision.transforms import v2
coco_val = [[0.4678, 0.4454, 0.4067], [0.2379, 0.2329, 0.2363]]
# 데이터셋 전처리 방법론 정의
transforamtion = v2.Compose([
v2.Resize((416, 416)), #이미지 크기를 416, 416로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=coco_val[0], std=coco_val[1]) #데이터셋 정규화
])여기서 데이터셋의 Normalize를 수행하기 위해 사전에 추출해야 할 mean, std정보를 생성하는 방법은
인공지능 고급(시각) 강의 복습 - 21. 주요 CNN알고리즘 구현 : (2) 전이학습과 미세조정 포스트를 참조 바란다.
# 데이터셋 전처리 방법론 적용
train_dataset.transform = transforamtion
test_dataset.transform = transforamtionfrom torch.utils.data import DataLoader
BATCH_SIZE = 128
# 전처리가 완료된 데이터셋의 데이터로더 전환
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False)여기까지 수행하면 모델을 학습시키기 위한 DataLoader을 성공적으로 생성했다 볼 수 있다.
4) 하이퍼 파라미터 정의
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 앞서 선언한 모델의 GPU이전
backbone.to(device)
fpn.to(device)
yolov3.to(device)먼저 하이퍼 파라미터 정의 전 앞서 선언한 모델들은 GPU로 이전 작업을 수행하고
from torch.optim import AdamW
from torch.optim.lr_scheduler import CosineAnnealingLR
# 손실 함수 설정 (YOLOv3 손실 함수)
criterion = Yolov3Loss()
# 옵티마이저 설정 (프리즈되지 않은 파라미터만)
optimizer = AdamW(filter(lambda p: p.requires_grad, yolov3.parameters()), lr=1e-3, weight_decay=1e-4)
# 스케줄러 설정 (50 에폭 기준 Cosine Annealing)
scheduler = CosineAnnealingLR(optimizer, T_max=70)손실함수, 옵티마이저, 스케줄러 등을 정의한다.
여기서 중요한 부분은
filter(lambda p: p.requires_grad, yolov3.parameters())
이 부분으로
Freeze레이어의 Parm은 불러오지 않고
오직 Trainable상태에 해당하는 레이어의 Parm만을 Filtering하여 가져와야 한다.
Pytorch의 옵티마이저는 Freeze / Trainable상태의 구분 없이 모든 레이어의 Parm을 불러와서 최적화를 수행하기에 어차피 Freeze되어서 값의 변화가 발생하지 않는 레이어의 Parm까지 불러올 필요가 전혀 없다.
이 과정이 매우 중요한 이유는
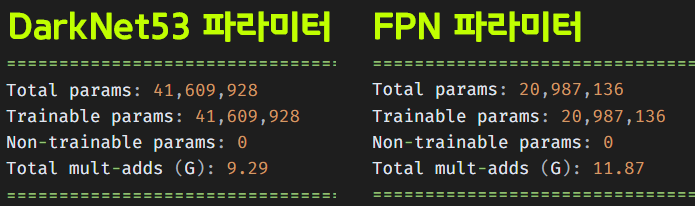
Freeze 상태의 backbone 파라미터 개수는 4천만개
Trainable 상태의 나머지 레이어 파라미터 개수는 대략 2천3백만 개로
Freeze 상태 파라미터까지 모두 불러오면
GPU의 VRAM이 매우 비효율적인 데이터로 꽉 차버린다.
이것이 Transfer Learning / Fine-Turning의
Freeze / Trainable 레이어 비율을 정하는 두번째 잡기술.. 이라 볼 수 있을 듯 하다.
어차피 Transfer Learning을 수행할 때 최대한 모든 레이어를 Trainable 상태로 두면 과적합만 조심한다면 성능이 올라갈 텐데
왜 Freeze / Trainable 레이어 비율을 조정하나 했드만
Freeze레이어의 parm은 옵티마이저 때 불러오면 안되는 것이었다.

5) Train / Val 실행
# Train / eval(Val)을 수행하는 클래스 인스턴스화
epoch_step = 5
trainer = ModelTrainer(epoch_step=epoch_step)ModelTrainer은 Train / Val을 수행하는 model_train, model_evalute 두 함수를 묶어서 클래스로 처리하고 이를 다시 py파일로 작성한 것이다.
이게 좀 더 관리가 쉬워서 묶음 처리했다 보면 된다.
# 학습과 검증 손실 및 정확도를 저장할 리스트
his_loss = []
his_KPI = []
num_epoch = 50
for epoch in range(num_epoch):
# 훈련 손실과 훈련 성과지표를 반환 받습니다.
train_loss, train_KPI = trainer.model_train(yolov3, train_loader,
criterion, optimizer, scheduler,
device, epoch)
# 검증 손실과 검증 성과지표를 반환 받습니다.
test_loss, test_KPI = trainer.model_evaluate(yolov3, test_loader,
criterion, device, epoch)
# 손실과 성능지표를 리스트에 저장
his_loss.append((train_loss, test_loss))
his_KPI.append((train_KPI, test_KPI))
# epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"Training loss: {train_loss:.4f}")
print(f"Train KPI[ IOU: {train_KPI[0]:.4f}, "+
f"Precision: {train_KPI[1]:.4f}, "+
f"Recall: {train_KPI[2]:.4f}, "+
f"Top1_err: {train_KPI[3]:.4f} ]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"Test loss: {test_loss:.4f}")
print(f"Test KPI[ IOU: {test_KPI[0]:.4f}, "+
f"Precision: {test_KPI[1]:.4f}, "+
f"Recall: {test_KPI[2]:.4f}, "+
f"Top1_err: {test_KPI[3]:.4f} ]")이제 여기까지 작성하고 실행해보니
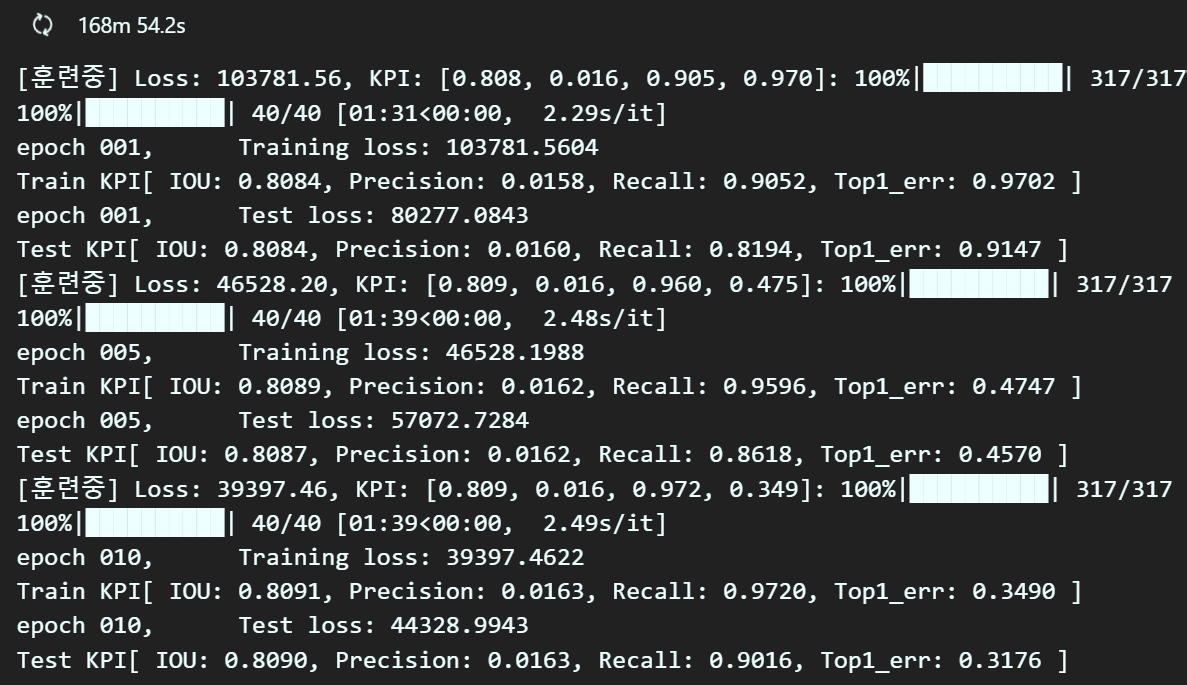
그동안 오류를 수정한게 제대로 반영이 되는 듯 하다.
특히 Precision, Recall항목은 0.0에서 전혀 미동도 없던 값들인데
의미있게 변화하고 있다.
1 epoch를 수행할 때 대략 10분 넘게 걸려서 학습하는데 오래걸리는 문제가 있지만
이정도면 Yolo v3에 대한 전체 Pre-trained model은 안 구해도 되지 않을까 한다.
5. Train / Val 결과분석
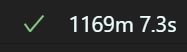 일단 80epoch로 학습을 하는데 20시간 덜 되게 소요되었고
일단 80epoch로 학습을 하는데 20시간 덜 되게 소요되었고
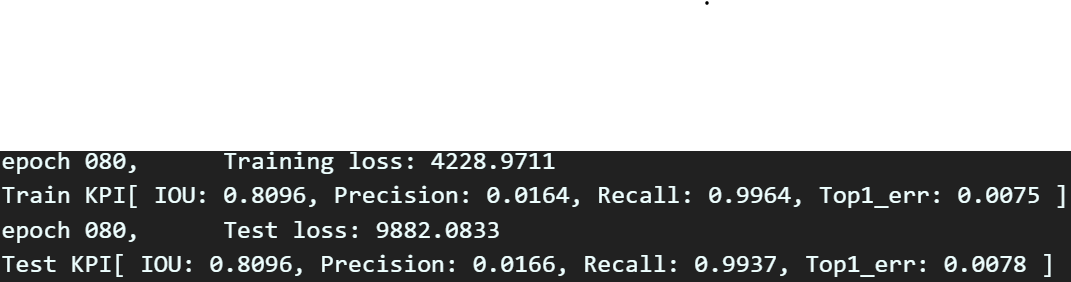 가장 마지막 epoch를 보면.. 음..
가장 마지막 epoch를 보면.. 음..
논문에서도 Yolo v3의 mAP 성능이 각각 31, 55가 나왔으니
맞는건가?

일단 학습이 완료되었으니
MODEL_NAME="Yolo_v3"
torch.save(yolov3.state_dict(), f'{MODEL_NAME}.pth')학습된 파라미터 정보는 저장을 해두자
괜히 날려먹으면 20시간을 더 쏟아야 하니 Save는 필수다.
그리고 아래의 코드를 작성하여
그래프 별로 좀 더 크게크게 확인을 해보자
import numpy as np
import matplotlib.pyplot as plt
#histroy는 [train, test] 순임
#KPI는 [iou, precision, recall, top1_error] 순임
np_his_loss = np.array(his_loss)
np_his_KPI = np.array(his_KPI)
# his_loss에서 손실 데이터 추출
train_loss, val_loss = np_his_loss[..., 0], np_his_loss[..., 1]
# his_KPI에서 각 성능 지표 추출
train_iou, val_iou = np_his_KPI[..., 0, 0], np_his_KPI[..., 1, 0]
train_precision, val_precision = np_his_KPI[..., 0, 1], np_his_KPI[..., 1, 1]
train_recall, val_recall = np_his_KPI[..., 0, 2], np_his_KPI[..., 1, 2]
train_top1_errors, val_top1_errors = np_his_KPI[..., 0, 3], np_his_KPI[..., 1, 3]
# 1x2 로 그래프 그리기
plt.figure(figsize=(8, 14))
# Train-Val Loss
plt.subplot(2, 1, 1)
plt.plot(train_loss, label='Train Loss')
plt.plot(val_loss, label='Val Loss')
plt.xlabel('Training Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Train-Val Loss')
# Train-Val Top-1 Error
plt.subplot(2, 1, 2)
plt.plot(train_top1_errors, label='Train Top-1 Error')
plt.plot(val_top1_errors, label='Val Top-1 Error')
plt.xlabel('Training Epochs')
plt.ylabel('Top-1 Error')
plt.legend()
plt.title('Train-Val Top-1 Error')
plt.tight_layout()
plt.show()
# 1x3로 그래프 그리기
plt.figure(figsize=(8, 20))
# IOU
plt.subplot(3, 1, 1)
plt.plot(train_iou, label='Train IOU')
plt.plot(val_iou, label='Val IOU')
plt.xlabel('Training Epochs')
plt.ylabel('IOU')
plt.legend()
plt.title('IOU')
# Precision
plt.subplot(3, 1, 2)
plt.plot(train_precision, label='Train Precision')
plt.plot(val_precision, label='Val Precision')
plt.xlabel('Training Epochs')
plt.ylabel('Precision')
plt.legend()
plt.title('Precision')
# Recall
plt.subplot(3, 1, 3)
plt.plot(train_recall, label='Train Recall')
plt.plot(val_recall, label='Val Recall')
plt.xlabel('Training Epochs')
plt.ylabel('Recall')
plt.legend()
plt.title('Recall')
plt.tight_layout()
plt.show()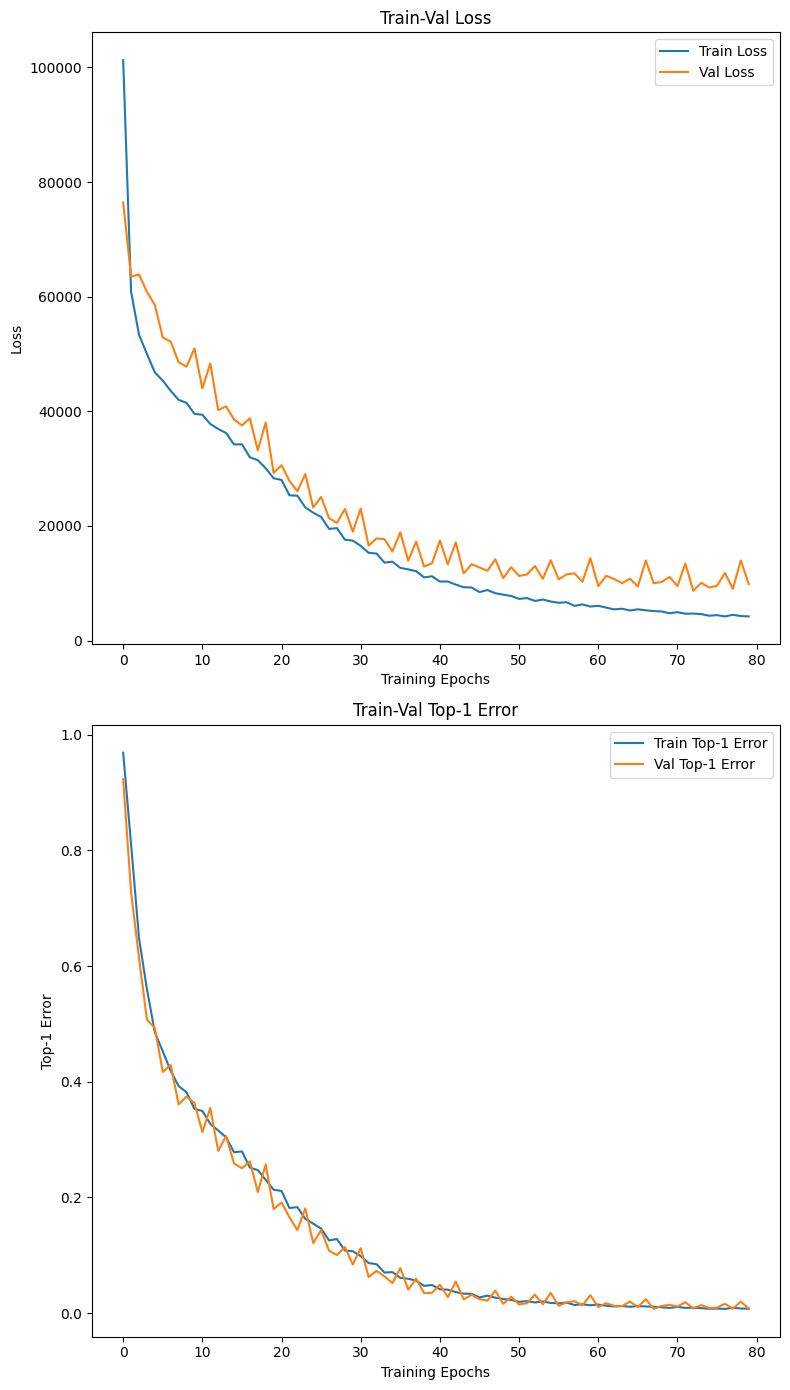
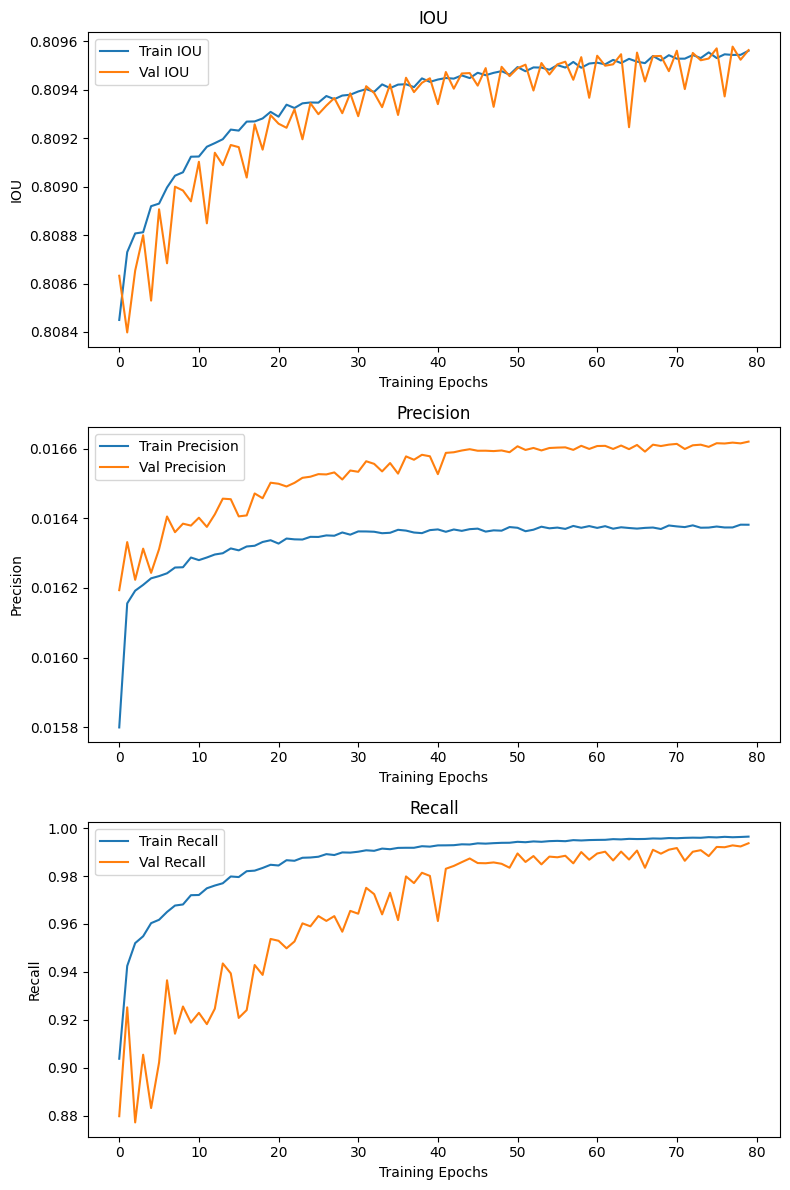
나름의 Train / Val결과에 대해 분석을 해보자면
1) 현재 과적합은 발생한 상태이다.
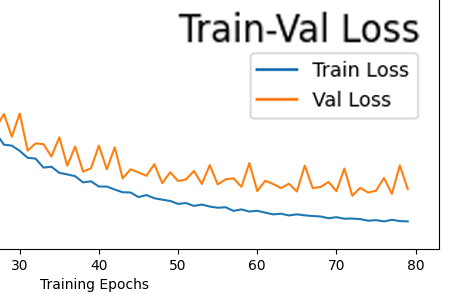 Loss를 측정한 결과값을 본다면 말단 epoch에서
Loss를 측정한 결과값을 본다면 말단 epoch에서
Val Loss항목과
Train항목을 본다면 점점 그래프 값의 차이가 벌어짐을 확인할 수 있다.
이것이 과적합의 전형적인 증상이다.
2) iou의 연산 방식의 문제점

도식으로 표현을 하는게 이해가 빠를 것 같아서 그려봤는데
위 방식대로 Yolo v3이
예측하는 9개의 Pred BBox 정보 중 가장 잘 예측한 단 하나의 BBox만을 빼 낸 뒤 이것과 GT Box간의 IOU_score를 연산하는 것이 더 옳은 방법이었나?
라는 생각이 든다.
기존의 방식은 9개의 Pred BBox와 9개로 데이터를 복제한 GT Box 모두에 대하여 IOU_score를 연산해 냈기에
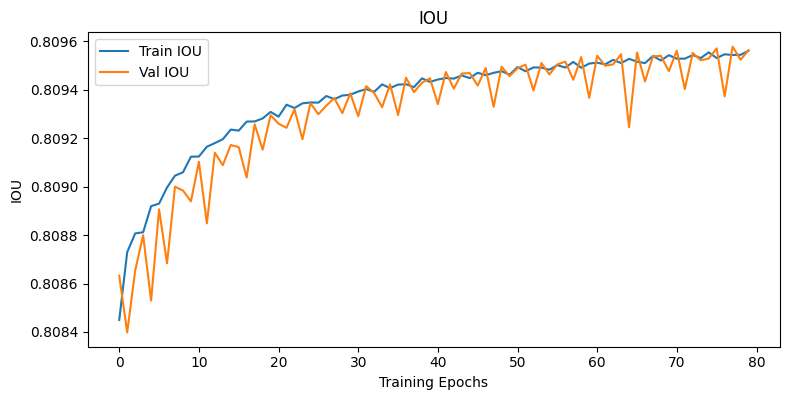 위 사진처럼
위 사진처럼 IOU_score의 성능변화가 거의 없지 않았나.. 라는 생각이 든다.
그러나 Loss function에서는 9개의 Pred BBox, GT Box에 대한 Localization Loss을 연산하는 식으로 함수정의를 했기에
무엇이 옳은 방법인지는 필자는 확신하기 어렵다.
추론 과정을 통해 잘 동작하는지 눈으로 봐야 감이 오지 않을 듯 싶다.
아무튼 작성이 완료된
학습된 가중치 정보 파일(Weights Files) : Yolo_v3.pth은
https://drive.google.com/file/d/1-4LeXHvCtCvx3k4fgfjVRznulnGU6Hmx/view?usp=drive_link
해당 링크를 통해 다운로드가 가능하다.
