
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
1. 이미지 추론 셋업하기
이전 포스트 인공지능 고급(시각) 강의 예습 - 22. (6) Yolo v3 모듈로 변환하기에서 Train / Val과정을 완수했고
학습된 가중치 정보 파일(Weights Files)인 Yolo_v3.pth을 생성했다.
이제 이 파일들을 기반으로 이미지 추론을 수행하는
infernece.ipynb파일을 작성해보자
 모듈화된 파일의 구성은 위와 같다.
모듈화된 파일의 구성은 위와 같다.
먼저 모듈화를 수행하기 전에 yolov3_model.py파일에 업데이트가 필요한 내역이 있다.
바로
# 로드한 yolo v3에 학습된 가중치 로드
model.load_weights("Yolo_v3.pth")이런식으로 load_weights 기능이 동작하게끔
load_weights 함수를 추가하고자 한다.
Yolov3_model.py
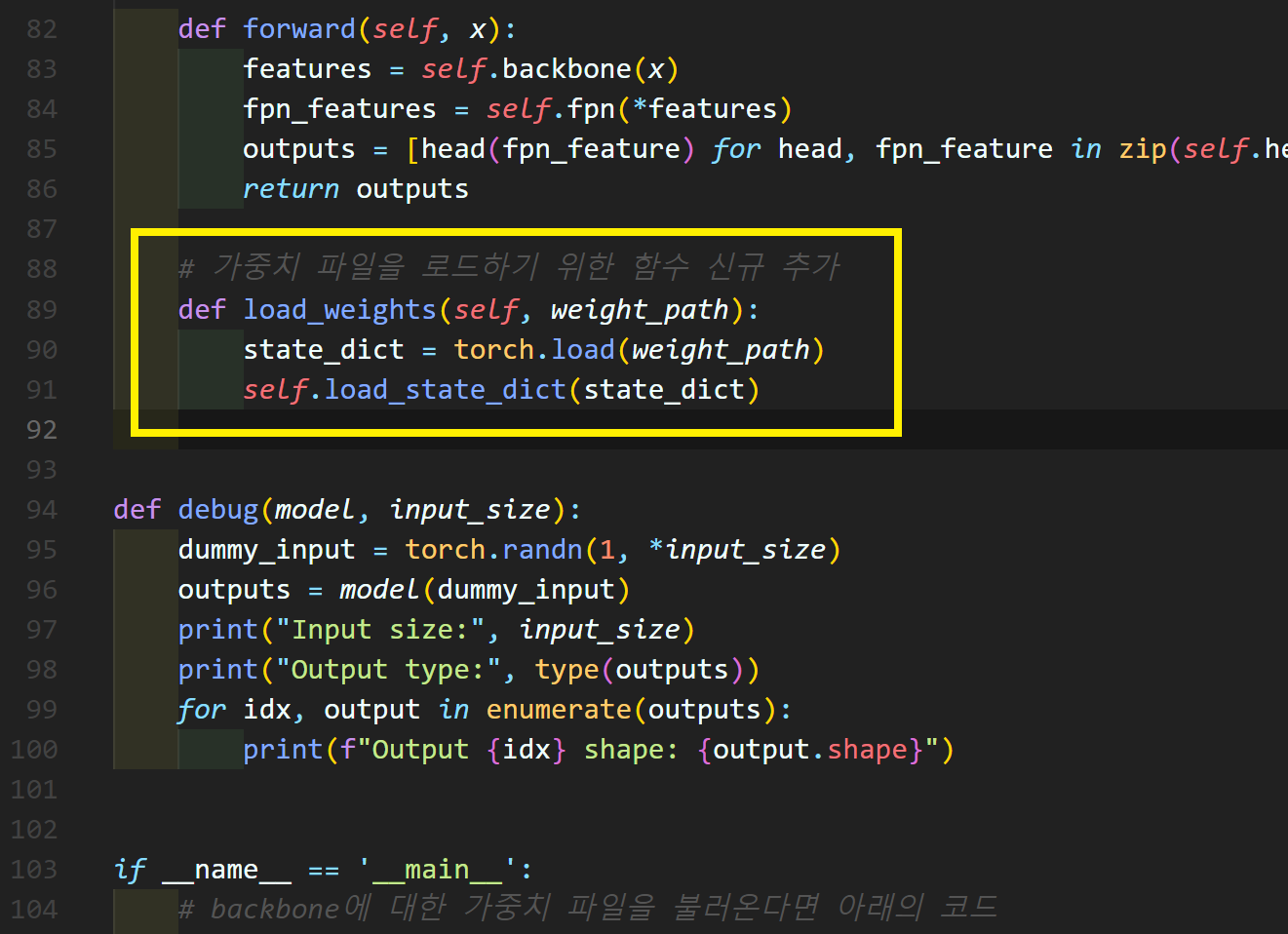 위 노란색 박스로 표기한
위 노란색 박스로 표기한
# 가중치 파일을 로드하기 위한 함수 신규 추가
def load_weights(self, weight_path):
state_dict = torch.load(weight_path)
self.load_state_dict(state_dict)부분만 추가해주면 된다.
이 과정을 수행한 뒤에는
이 이미지 추론 과정에서 가장 중요하다 할 수 있는
yolo_v3_nms.py파일을 작성해 보도록 하자.
2. yolo_v3_nms.py
이 코드에서 주요하게 다루는 기능은 non_max_Suppression과정으로 그림으로 설명하면 아래와 같다
 간단하게 쓸모없는
간단하게 쓸모없는 BBox를 지우고 의미있는 BBox를 남기는 과정이라 보면 된다.
이를 좀 체계화하여 설명하면 아래와 같다.
1) 점수 부여(Scoring) : 각 Bounding box에 대한 정량지표 산출
2) 정렬 (Sorting) 및 선택: BBox에 부여된 정량지표를 바탕으로 가장 높은 점수를 갖는 BBox가 맨 위에 오게 정렬 및 해당 BBox선택
4) 임계값 설정 : 부여한 정량지표가 일정값 이하 BBox는 탈락 + 높은 점수를 갖는 BBox와 IOU를 계산하여 너무 겹치는 BBox도 탈락(iou_th)
5) 반복 : 4번 항목의 반복
이 Non_Max_Suppression을 Yolo v3에 적용한다면 아래와 같은 방식으로 필터링이 이뤄진다 보면 된다.
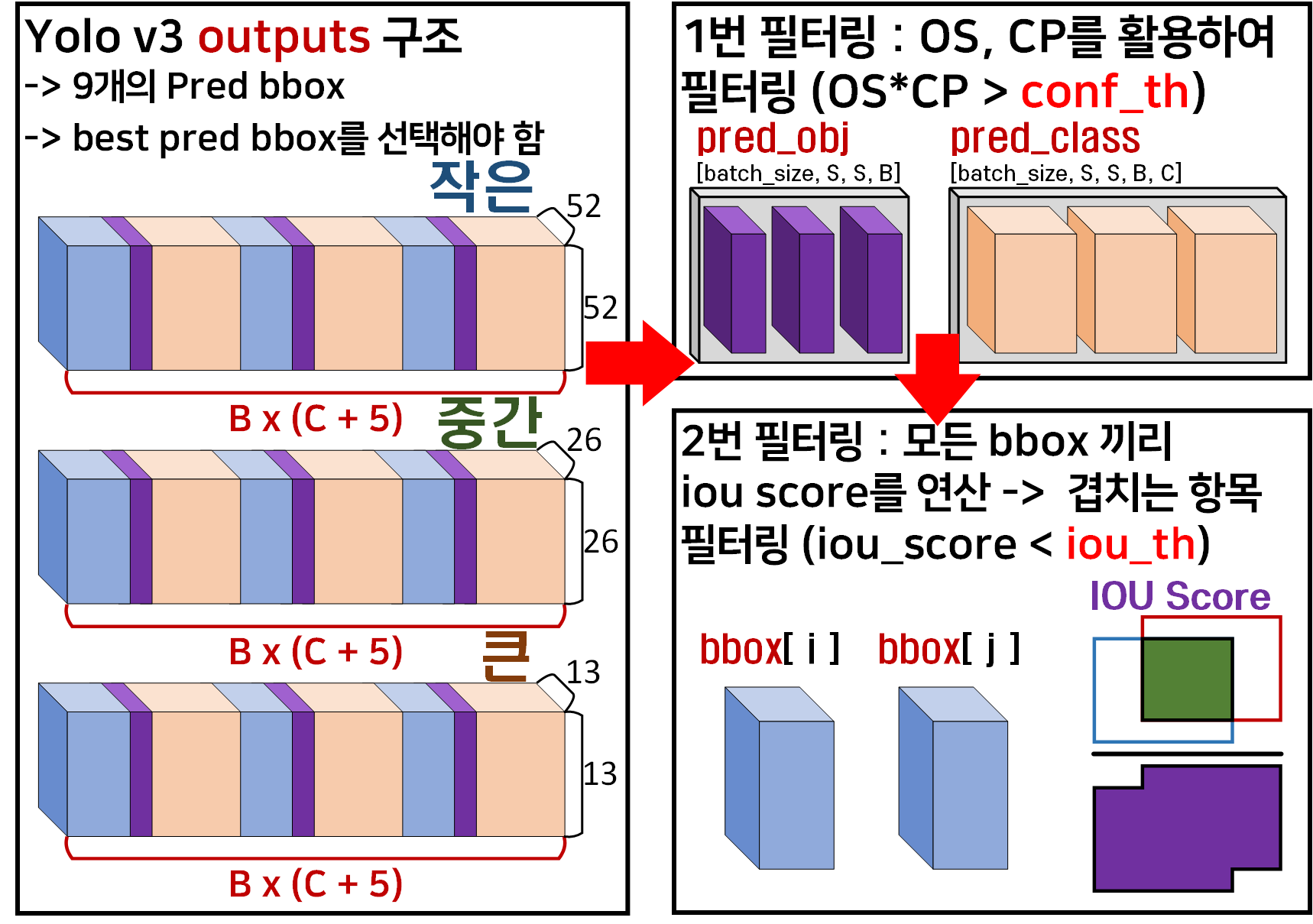
이 두개의 필터링을 거칠 때 2번째 필터링
iou score를 계산하려면 아래의
로 변환하는 과정을 수행해야 한다.
따라서 작성하는 yolo_v3_nms.py는 데이터 추출, 좌표변환, iou계산, 필터 마스크 등
이전에 작성한 코드에서 유사한 기능이 많이 보임을 알 수 있다.
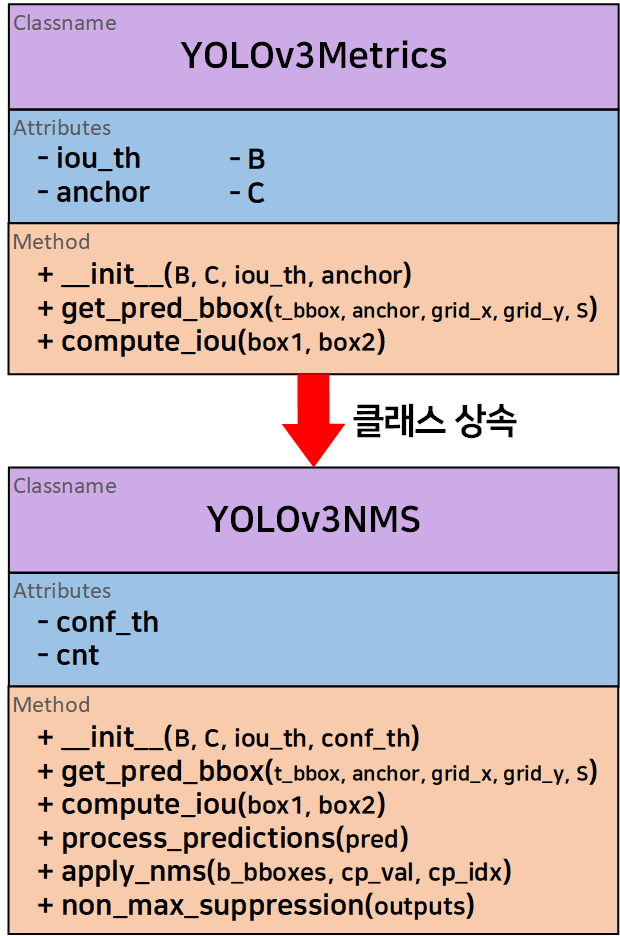
이 중 yolo_v3_metrics.py에서 재사용 할 코드가 가장 많았기에 해당 코드에서 설계한

이 클래스를 상속받고 일부 함수의 경우 재정의(Overriding)를 수행하고자 한다.
이 과정에 대한 전체 코드를 먼저 첨부한 뒤 중요항목에 대해 기술하도록 하겠다.
import torch
from yolo_v3_metrics import YOLOv3Metrics, anchor_box_list# non_max_suppression과정은 YOLOv3Metrics의 함수를 재사용하자.
class Yolov3NMS(YOLOv3Metrics):
def __init__(self, B=3, C=80, iou_th=0.4, conf_th=0.5):
super().__init__(B, C, iou_th=iou_th, anchor=anchor_box_list)
self.conf_th = conf_th #NMS의 첫번째 필터링 -> OS를 필터링하는 인자값
# YOLOv3Metrics의 2개 함수 get_pred_bbox, compute_iou를 재사용한다.
# get_pred_bbox는 재정의 해야함 -> 디바이스 문제...
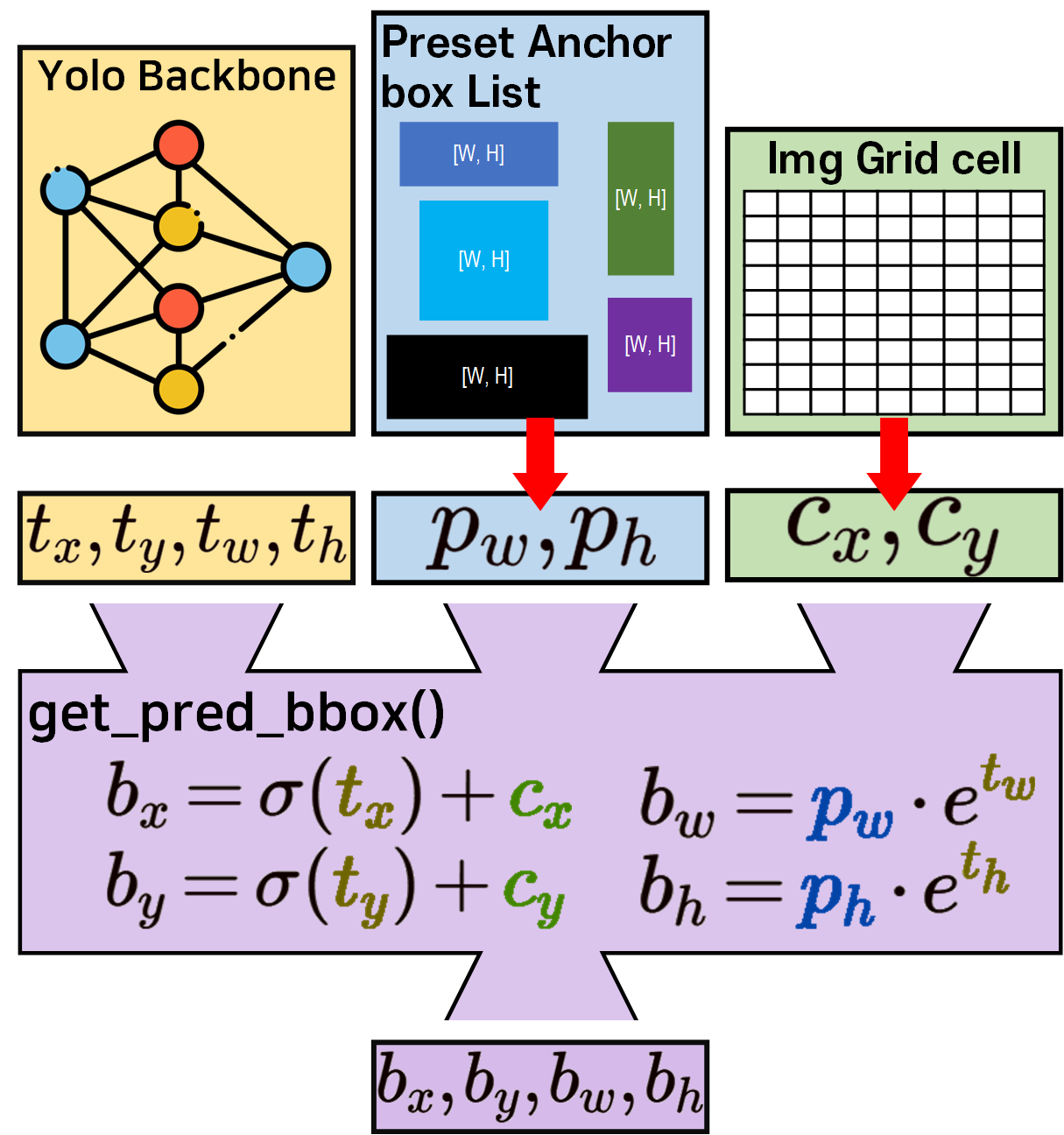
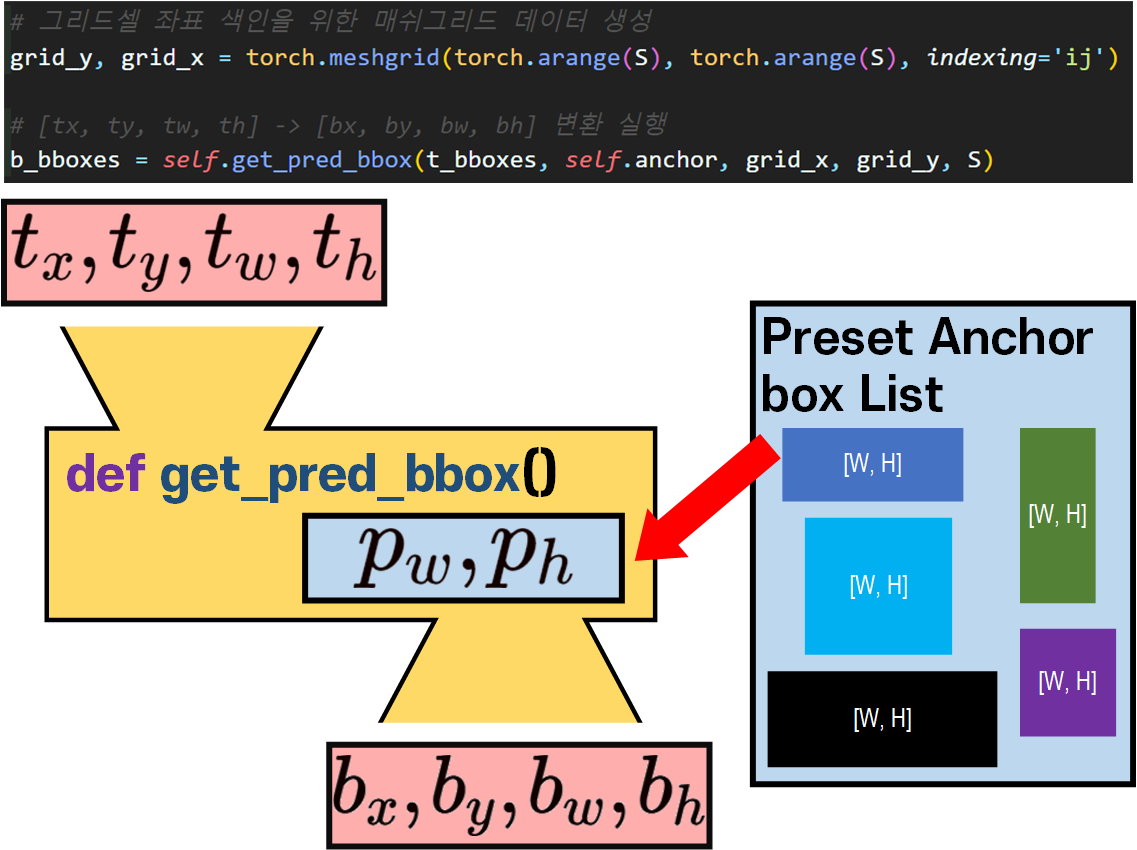
def get_pred_bbox(self, t_bbox, anchor, grid_x, grid_y, S):
# 모든 텐서를 동일한 디바이스로 이동
device = t_bbox.device
anchor = anchor.to(device)
grid_x = grid_x.to(device)
grid_y = grid_y.to(device)
# 여기에 들어오는 [tx], [ty], [tw], [th]는 모두 [Batch_size, S, S, B] 형태
tx, ty = t_bbox[..., 0], t_bbox[..., 1]
tw, th = t_bbox[..., 2], t_bbox[..., 3]
# cnt는 작은 -> 중간 -> 큰 객체의 리스트를 순환하는 변수
# anchor box list에서 cnt 값에 맞춰 객체 크기용 box [3x2]를 가져옴
pw, ph = anchor[self.cnt][..., 0], anchor[self.cnt][..., 1]
# meshgrid로 정의된 grid_x, grid_x는 모두 [S, S] 차원을 가짐
# [S, S] -> [1, S, S, 1] -> [batch_size, S, S, B]로 차원 확장
grid_x = grid_x.unsqueeze(0).unsqueeze(-1).expand_as(tx)
grid_y = grid_y.unsqueeze(0).unsqueeze(-1).expand_as(ty)
# grid / S -> 그리드셀의 좌상단 좌표값이 됨(cx, cy)
# tx, ty는 sigmoid 처리된 c_pos와 b_pos의 '상대적인 거리'
# 모두 정규화 좌표 평면이니 t_pos도 1/S 처리 해줘야 함
bx = (tx + grid_x) / S
by = (ty + grid_y) / S
bw = pw * torch.exp(tw)
bh = ph * torch.exp(th)
# 좌표 변환이 완료된 [bx, by, bw, bh]은 스택으로 쌓아서 return
b_bbox = torch.stack([bx, by, bw, bh], dim=-1)
return b_bbox
def compute_iou(self, box1, box2):
return super().compute_iou(box1, box2)
# NMS를 수행하는 준비과정인 데이터 추출 및 필터링 함수
def process_predictions(self, pred):
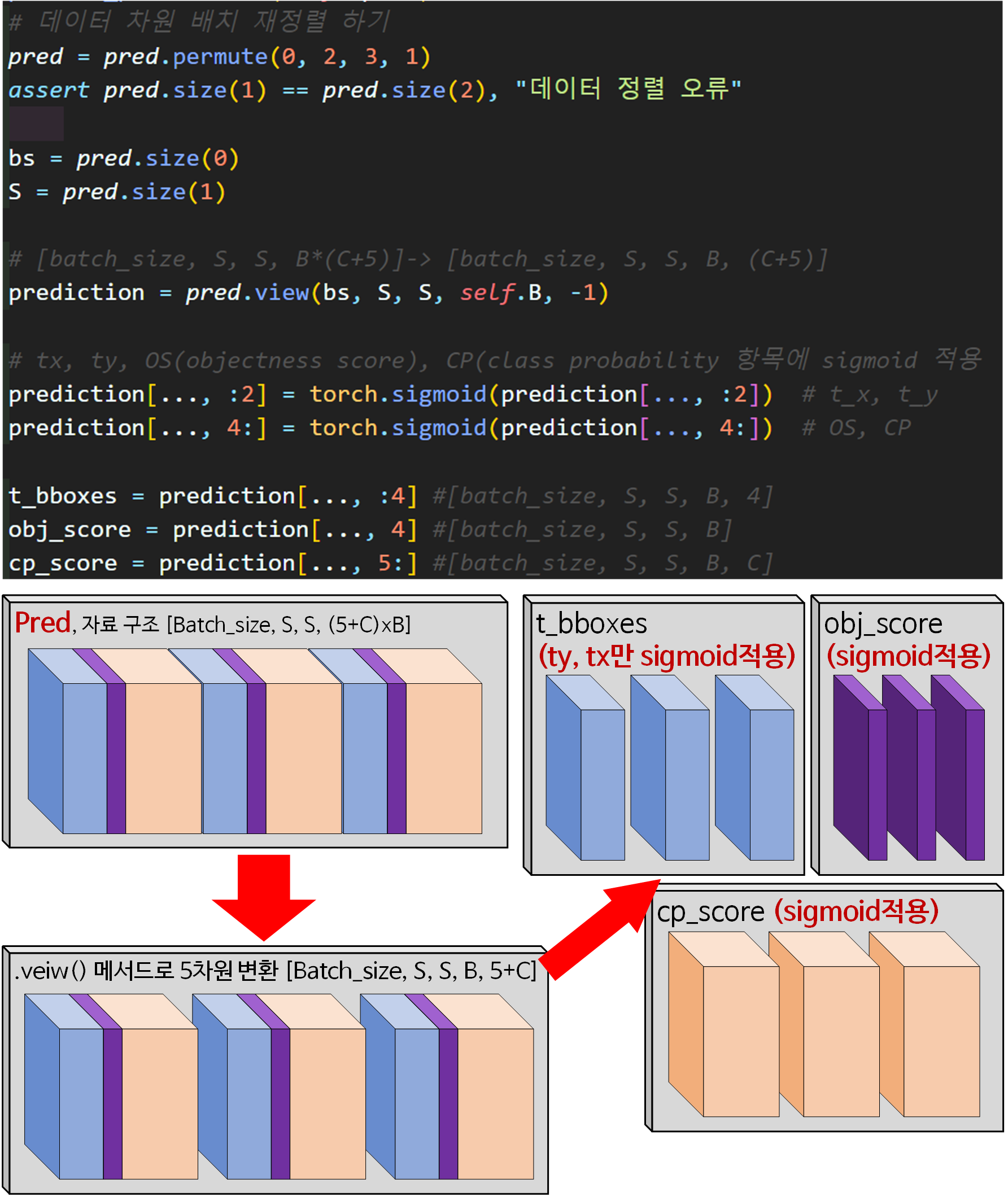
# 데이터 차원 배치 재정렬 하기
pred = pred.permute(0, 2, 3, 1)
assert pred.size(1) == pred.size(2), "데이터 정렬 오류"
bs = pred.size(0)
S = pred.size(1)
# [batch_size, S, S, B*(C+5)]-> [batch_size, S, S, B, (C+5)]
prediction = pred.view(bs, S, S, self.B, -1)
# tx, ty, OS(objectness score), CP(class probability 항목에 sigmoid 적용
prediction[..., :2] = torch.sigmoid(prediction[..., :2]) # t_x, t_y
prediction[..., 4:] = torch.sigmoid(prediction[..., 4:]) # OS, CP
t_bboxes = prediction[..., :4] #[batch_size, S, S, B, 4]
obj_score = prediction[..., 4] #[batch_size, S, S, B]
cp_score = prediction[..., 5:] #[batch_size, S, S, B, C]
# 그리드셀 좌표 색인을 위한 매쉬그리드 데이터 생성
grid_y, grid_x = torch.meshgrid(torch.arange(S), torch.arange(S), indexing='ij')
# [tx, ty, tw, th] -> [bx, by, bw, bh] 변환 실행
b_bboxes = self.get_pred_bbox(t_bboxes, self.anchor, grid_x, grid_y, S)
# OS 정보를 conf_th로 필터링 (1차)
# 각각 마스크 필터를 통과하여 [N, ~~] 차원으로 변환된다.
conf_mask = obj_score > self.conf_th
b_bboxes = b_bboxes[conf_mask] # [N, 4]
obj_score = obj_score[conf_mask] # [N]
cp_score = cp_score[conf_mask] # [N, C]
# class confidence 곱하기
# 이때 obj_score는 broadcasting이 안되기에 맨 뒤에 차원 추가
cp_score *= obj_score.unsqueeze(-1)
# 클래스와 스코어 정보로 필터링(2차)
cp_val, cp_idx = torch.max(cp_score, -1)
conf_mask = cp_val > self.conf_th
b_bboxes = b_bboxes[conf_mask]
cp_val = cp_val[conf_mask]
cp_idx = cp_idx[conf_mask]
return b_bboxes, cp_val, cp_idx
# 필터링 + 내림차순을 거친 데이터를 기반으로 의미있는 bbox만 선택
def apply_nms(self, b_bboxes, cp_val, cp_idx):
keep_boxes = []
while b_bboxes.size(0):
# 신뢰도값이 가장 큰 단 1개의 데이터만 추출
chosen_box = b_bboxes[0].unsqueeze(0) #[1, 4]
chosen_val = cp_val[0].unsqueeze(0).unsqueeze(0) #[1, 1]
chosen_idx = cp_idx[0].unsqueeze(0).unsqueeze(0) #[1, 1]
keep_boxes.append(torch.cat((chosen_box, chosen_val, chosen_idx), dim=-1))
if b_bboxes.size(0) == 1:
break
# 신뢰도값이 가장 큰 box랑 나머지 bbox를 비교하여 iou 연산
# 연산하여 iou가 겹치는 bbox 항목을 제거한다.
ious = self.compute_iou(chosen_box, b_bboxes[1:])
b_bboxes = b_bboxes[1:][ious < self.iou_th]
cp_val = cp_val[1:][ious < self.iou_th]
cp_idx = cp_idx[1:][ious < self.iou_th]
return keep_boxes
def non_max_suppression(self, outputs):
f_b_bboxes = []
f_cp_val = []
f_cp_idx = []
# outputs 리스트 정보를 원소로 분해
for cnt, pred in enumerate(outputs):
self.cnt = cnt # 리스트 순회값으로 cnt 초기화
b_bboxes, cp_val, cp_idx = self.process_predictions(pred)
f_b_bboxes.append(b_bboxes)
f_cp_val.append(cp_val)
f_cp_idx.append(cp_idx)
# 리스트 원소를 concat하기
nms_bboxes = torch.cat(f_b_bboxes, dim=0)
nms_val = torch.cat(f_cp_val, dim=0)
nms_idx = torch.cat(f_cp_idx, dim=0)
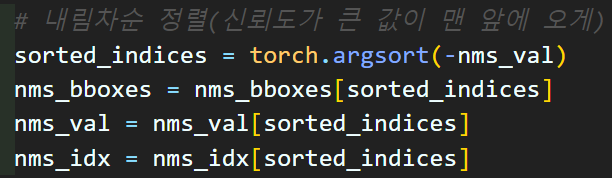
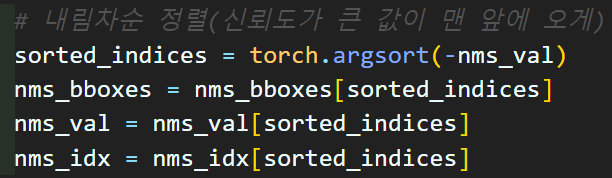
# 내림차순 정렬(신뢰도가 큰 값이 맨 앞에 오게)
sorted_indices = torch.argsort(-nms_val)
nms_bboxes = nms_bboxes[sorted_indices]
nms_val = nms_val[sorted_indices]
nms_idx = nms_idx[sorted_indices]
# NMS 적용
res_boxes = self.apply_nms(nms_bboxes, nms_val, nms_idx)
# 최종 출력되는 res boxes는
# 1) 신뢰도 값이 가장 높은 boxes 정보이다.
# 2) 그리고 서로 겹치지 않는다(iou로 필터링됨)
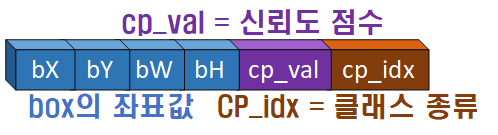
# 마지막에 출력되는 res_boxes의 원소값은 모두 [1,6]형태이니 [6]으로 차원축소
# [bbox좌표, 신뢰도값, 클래스 id] 순이다.
res_boxes = [box.squeeze(0) for box in res_boxes]
return res_boxes1)
__init__메서드
 상위클래스인
상위클래스인 YOLOv3Metrics에서 상속받을 변수들이랑, 신규로 정의할 변수에 대한 선언이 이뤄지는 부분이다.
여기서 중요한 항목은
iou_th, conf_th로 이 두개 인자값의 조정을 통해
NMS의 필터 결과치가 달라진다 볼 수 있다.
conf_th는 OS, CP정보를 바탕으로 해당 값들이 conf_th 미만인 정보들을 필터링 하는 1차 필터의 역할을 수행한다.
다음으로 iou_th는 2차 필터의 임계값으로 bbox끼리 너무 겹치는 항목들을 필터링 해주는 역할을 수행한다.
YOLOv3Metrics에서의 iou_th는 Precision / Recall 평가지표 계산시 IOU_score의 Posiive / Negative를 나누는 지표값이었지만 여기서는 성격이 많이 달라짐을 알 수 있다.
2) non_max_suppression 함수

Yolov3NMS의 주 기능을 수행하는 함수라 보면 된다.
해당 코드에서는
Yolo v3의 출력값인 outputs가
list 형태이니 이를 원소단위로 꺼내고
(원소는 [batch, B*(C+5), S, S] 텐서 자료형)
해당 원소 데이터로 1종 필터를 거쳐서 값을 추출한 뒤
 해당 코드를 통해 1종 필터를 거친 값들을 내림차순 정렬(sorting)을 수행한다.
해당 코드를 통해 1종 필터를 거친 값들을 내림차순 정렬(sorting)을 수행한다.
그 이후 2종 필터를 거쳐서 최종 bbox를 출력하는 코드라 보면 된다.
이때 최종 출력물 res_boxes의 각 원소별 정보는 아래와 같다
3) process_predictions 함수
 역시 첫번째로 할 일은 데이터 추출 후 종류별로 재배치 이고
역시 첫번째로 할 일은 데이터 추출 후 종류별로 재배치 이고
 데이터 재 배치후 좌표변환 수행
데이터 재 배치후 좌표변환 수행
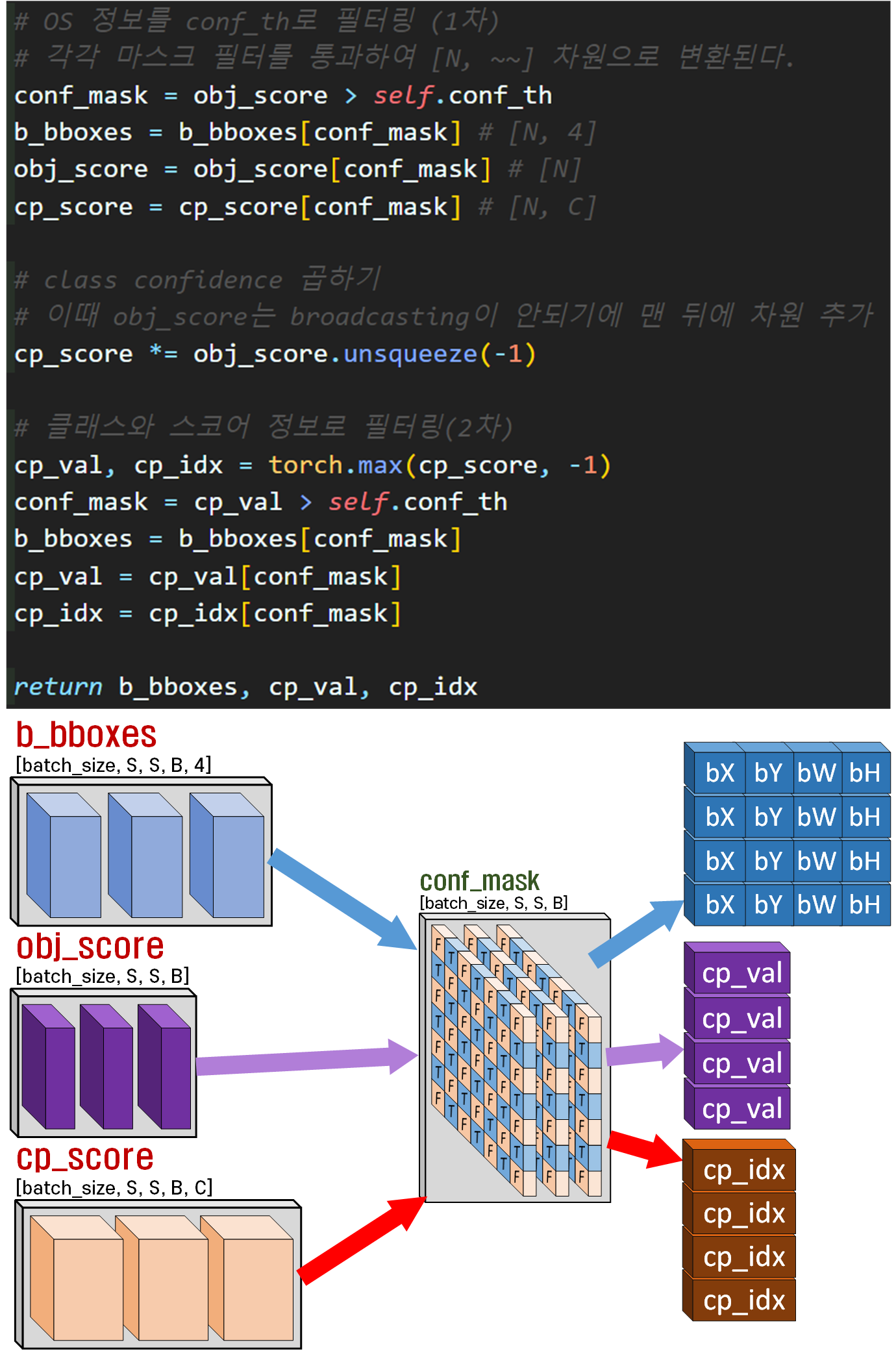 필터링 과정으로 데이터 추출
필터링 과정으로 데이터 추출
이렇게 3가지 기능을 수행하는 함수이다.
이때 생성하는 conf_mask는 conf_th의 임계값을 기준으로 마스크가 생성된다
4) apply_nms 함수
이 코드를 통해 정렬된 bbox, cp_val, cp_idx행렬을 받아서
2차 필터링을 진행하는 함수라 보면 된다.
 2차 필터링은 위 사진처럼 반복문을 통해 지속적으로 겹치지 않는 bbox정보들만 추출해낸다 보면 된다.
2차 필터링은 위 사진처럼 반복문을 통해 지속적으로 겹치지 않는 bbox정보들만 추출해낸다 보면 된다.
 이때 위 사진처럼
이때 위 사진처럼 YOLOv3Metrics에서 정의한 compute_iou함수를 상속받아서 IOU_score를 계산한다.
3. inference.ipynb
위 yolo_v3_nms.py코드가 수행하는 non_max_Suppression기능을 바탕으로 이미지 추론작업을 수행한다.
그 전에 yolo_v3_nms.py코드를 완성하고, 디버깅 기능을 포함하도록 하자.
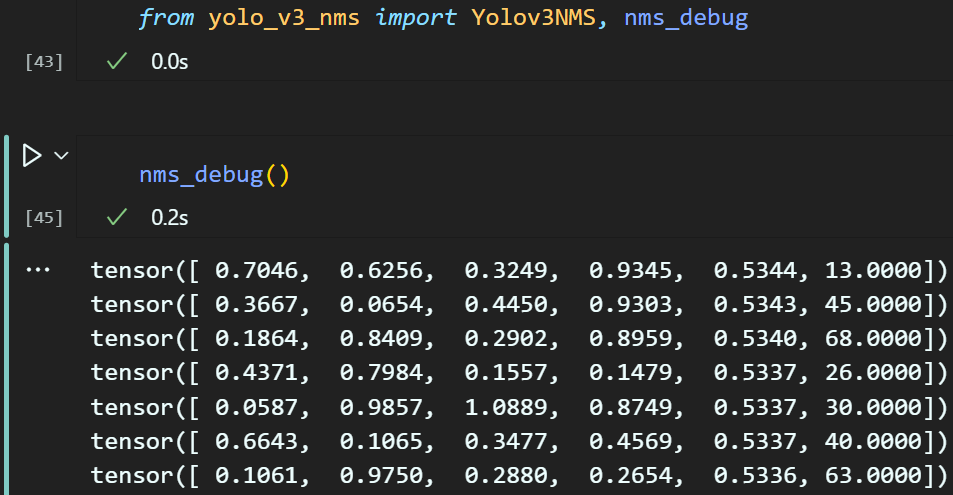
# 디버깅을 위한 nms_debug 함수
def nms_debug():
S_list = [52, 26, 13]
outputs = []
for S in S_list:
output = torch.rand(1, 255, S, S)
outputs.append(output)
nms = Yolov3NMS()
boxes = nms.non_max_suppression(outputs)
for box in boxes:
print(box)
if __name__ == '__main__':
nms_debug()위 코드를 작성하여 아래처럼 import후 디버깅 함수를 구동하면 필터를 거친 bbox값이 출력됨을 확인할 수 있다.
https://github.com/tbvjvsladla/yolo_v3_pytorch
작성한 코드는 위 git저장소에 업로드를 하였으며
 위 하늘색 코드가
위 하늘색 코드가 inference.ipynb를 구동하는데 필요한 코드라 보면 된다.
해당코드는 크게 3가지 파트로 나누어 볼 수 있다.
1) 학습된 가중치 정보 파일(Weights Files) 다운로드 부
import gdown
import os# 파일 ID 추출
file_id = "1-4LeXHvCtCvx3k4fgfjVRznulnGU6Hmx"
# 다운로드 링크 생성
download_url = f"https://drive.google.com/uc?id={file_id}"# 파일 다운로드
output_file = "Yolo_v3.pth"# 파일 다운로드
if not os.path.exists(output_file):
gdown.download(download_url, output_file, quiet=False)
print("다운로드 완료")
else:
print("파일이 이미 존재함")필자는 이전 포스트 인공지능 고급(시각) 강의 예습 - 22. (6) Yolo v3 모듈로 변환하기
에서 학습된 가중치 파일 : yolo_v3.pth를
https://drive.google.com/file/d/1-4LeXHvCtCvx3k4fgfjVRznulnGU6Hmx/view?usp=drive_link
에 업로드 하였다.
이 파일을 쉽게 다운받을 수 있도록 gdown 라이브러리를 사용하여 다운로드 코드를 작성했다.
2) Pre-trained model : Yolo v3
import torch
from darknet53_FPN import Darknet53
from Yolov3_model import YOLOv3, FPNbackbone = Darknet53(pretrained=False)
fpn = FPN(channels_list=[256, 512, 1024])
# yolo v3 모델 로드
model = YOLOv3(backbone, fpn, num_classes=80)
# 로드한 yolo v3에 학습된 가중치 로드
model.load_weights("Yolo_v3.pth")
드디어 Yolo v3에 대한 Pre-trained model를 사용가능한 수준으로 만들었다.
3) 이미지 추론
import cv2, random
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
# 모델의 출력 outputs의 bbox를 필터링하는 nms 클래스
from yolo_v3_nms import Yolov3NMSimg_dir = '[추론을 수행할 다양한 이미지가 담긴 폴더]'
# 폴더 내 모든 이미지 파일 가져오기
image_files = [f for f in os.listdir(img_dir) if os.path.isfile(os.path.join(img_dir, f))]
random_image = random.choice(image_files)
# 이미지 불러오기 및 전처리
image_path = os.path.join(img_dir, random_image) #여기에 추론하고 싶은 이미지 경로 기입
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_resized = cv2.resize(image_rgb, (416, 416))
image_tensor = torch.from_numpy(image_resized).permute(2, 0, 1).unsqueeze(0).float() / 255.0입력할 예시 이미지 파일을 전처리 해준 뒤 모델 추론을 시작하자.
# 모델 추론
with torch.no_grad():
outputs = model(image_tensor)
# NMS 적용
nms = Yolov3NMS(conf_th=0.9)
boxes = nms.non_max_suppression(outputs)
# 추출된 bbox정보 display
for box in boxes:
print(box)참고로 Yolov3NMS의 경우 conf_th인자값 조정을 통해 필터링할 bbox항목을 조정을 해야 한다.
이 값이 너무 낮으면 bbox가 많이 필터를 통과한다.
Yolo v3 논문에서는 conf_th = 0.5를 사용했지만
그래도 통과하는 bbox정보가 많아서 필자는 conf_th = 0.9로 높여서 사용했다.
tensor([0.7754, 0.6599, 0.3305, 0.7917, 0.9703, 0.0000])
tensor([ 0.3335, 0.9422, 0.5140, 0.5439, 0.9028, 32.0000])그러면 위 코드처럼 필터를 통과한 의미있는 bbox정보가 출력됨을 확인할 수 있다.
4) 추론 정보 시각화
# 슈퍼 클래스와 해당 색상 매핑
cls_color = {
"person": "magenta",
"vehicle": "yellow",
"outdoor": "blue",
"animal": "green",
"accessory": "purple",
"sports": "orange",
"kitchen": "brown",
"food": "red",
"furniture": "cyan",
"electronic": "pink",
"appliance": "lime",
"indoor": "gray"
}
# COCO 클래스 레이블을 슈퍼 클래스에 따라 그룹화한 딕셔너리
coco_map = {
"person": [0],
"vehicle": [1, 2, 3, 4, 5, 6, 7],
"outdoor": [8, 9, 10, 11, 12, 13],
"animal": [14, 15, 16, 17, 18, 19, 20, 21, 22],
"accessory": [23, 24, 25, 26, 27],
"sports": [28, 29, 30, 31, 32, 33, 34, 35, 36, 37],
"kitchen": [38, 39, 40, 41, 42, 43, 44],
"food": [45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55],
"furniture": [56, 57, 58],
"electronic": [59, 60, 61, 62, 63, 64],
"appliance": [65, 66, 67, 68],
"indoor": [69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79]
}
# COCO 클래스 레이블
coco_label = [
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train",
"truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter",
"bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear",
"zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase",
"frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat",
"baseball glove", "skateboard", "surfboard", "tennis racket", "bottle",
"wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
"sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut",
"cake", "chair", "couch", "potted plant", "bed", "dining table", "toilet",
"tv", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave",
"oven", "toaster", "sink", "refrigerator", "book", "clock", "vase",
"scissors", "teddy bear", "hair drier", "toothbrush"
]필자가 학습시킨 Yolo v3는 coco dataset을 기준으로 하기에
해당 데이터셋이 제공하는 클래스 분류 ID(80종)에 대한 기재와
해당 클래스를 또 분류하는 SuperClass
그리고 SuperClass별로 검출된 BBox의 색상을 달리하기 위하여
cls_color 딕셔너리를 생성했다.
# 클래스 ID를 슈퍼 클래스 이름으로 매핑
cls_map = {cls_id: superclass for superclass, cls_ids in coco_map.items() for cls_id in cls_ids}이를 토대로 매핑정보가 담긴 딕셔너리를 생성한다.
# 결과 시각화 함수
def plot_boxes(image, boxes, labels):
plt.figure(figsize=(10, 10))
plt.imshow(image)
ax = plt.gca()
for box in boxes:
x_center, y_center, w, h, conf, label = box
# 중심 좌표와 크기를 좌상단, 우하단 좌표로 변환
x1 = x_center - w / 2
y1 = y_center - h / 2
label = int(label)
superclass = cls_map[label]
color = cls_color[superclass]
rect = Rectangle((x1, y1), w, h, linewidth=2, edgecolor=color, facecolor='none')
ax.add_patch(rect)
plt.text(x1, y1, s=labels[label], color='black', verticalalignment='top',
bbox={'color': color, 'pad': 0})
plt.axis('off')
plt.show()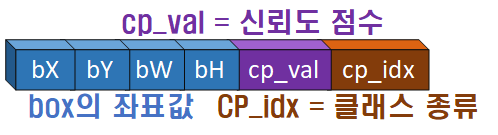 결과 시각화 코드를 수행할 때 bbox의 좌표정보가
결과 시각화 코드를 수행할 때 bbox의 좌표정보가
[x_center, y_center, w, h]임을 잊지말자.
# 원본 이미지로 시각화하기 위해 박스 좌표를 원래 이미지 크기로 변환
scale_y = image.shape[0] # height
scale_x = image.shape[1] # width
boxes = [[box[0] * scale_x, # x_center * width
box[1] * scale_y, # y_center * height
box[2] * scale_x, # w * width
box[3] * scale_y, # h * height
box[4], box[5]] for box in boxes]그리고 [x_center, y_center, w, h]이 좌표정보가 정규 좌표평면상에서 계산된 값이기에
이를 이미지의 크기에 맞게 스케일링 하는것도 잊으면 안된다.
# 결과 시각화
plot_boxes(image_rgb, boxes, coco_label)

클래스 종류는 잘 예측하는거 같은데
바운딩박스 쳐지는 꼴이 흠..

왠만한 오류는 다 잡은거 같은데
허허...
왜 다른사람들이 yolo 구현했다고 하면 그냥 공식 git에서 라이브러리 다운받아 쓰는지 알거 같다.
