
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 커리큘럼 중 일부 항목에 대한 예습 자료입니다..
이전포스트 인공지능 고급(시각) 강의 예습 - 22. (7) Yolo v3 추론해보기에서
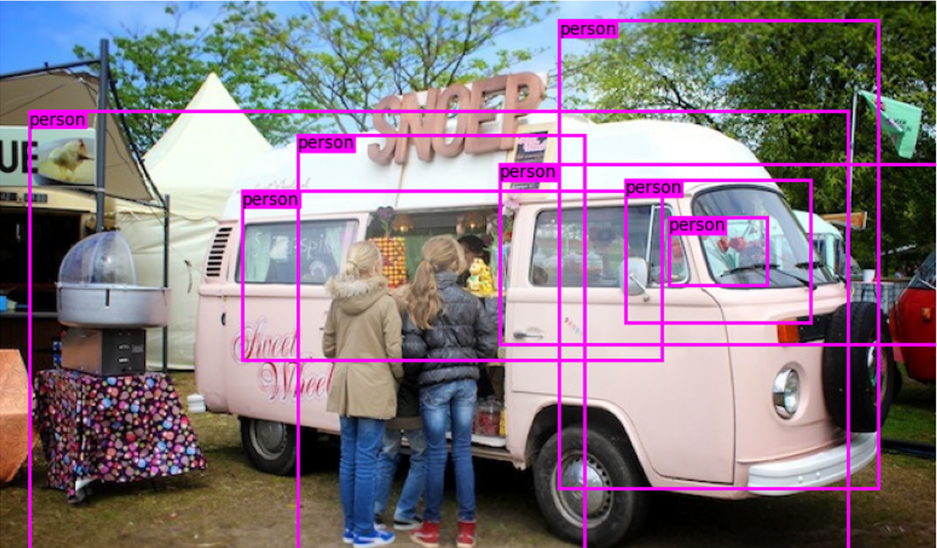 이같이 적절한 결과물을 얻지 못했으니, 이를 다른 코드 및 Yolo v3의 전체 Pre-trained model모델을 구해와서
이같이 적절한 결과물을 얻지 못했으니, 이를 다른 코드 및 Yolo v3의 전체 Pre-trained model모델을 구해와서
최종 이미지 추론 -> 이미지 학습 에 관련된 코드로 역순으로 코드 검증을 수행하고자 한다.
1. Full Pre-trained model
https://pjreddie.com/darknet/yolo/
Yolo 시리즈의 주 저자인 Joseph Redmon이 운영하는 홈페이지에 접속하여
Yolo v3에 대한 완전히 학습된 모델 구성정보(*.cfg) 및 학습된 가중치 파일(*.weights)를 다운로드 받도록 하자
파일의 다운로드는 인공지능 고급(시각) 강의 예습 - 22. (6) Yolo v3 모듈로 변환하기 포스트에서 언급한
01_chg_weights_down.ipynb 파일의 코드를 최대한 참조하여 아래와 같이 작성했다.
1) cfg 및 weight 파일 다운로드 코드
import requests, os
import wget
from tqdm import tqdmcfg_url = "https://raw.githubusercontent.com/pjreddie/darknet/master/cfg/yolov3.cfg"
cfg_filename = "yolov3.cfg"
weights_url = "https://pjreddie.com/media/files/yolov3.weights"
weights_filename = "YOLOv3-416.weights"# CFG 파일 다운로드
if not os.path.isfile(cfg_filename):
wget.download(cfg_url, cfg_filename)
print(f"\n{cfg_filename} has been downloaded.")
else:
print(f"{cfg_filename} already exists. Skipping download.")# WEIGHTS 파일 다운로드 준비 및 용량 출력
response = requests.get(weights_url, stream=True)
total_size = int(response.headers.get('content-length', 0))
print(f"File size: {total_size / (1024 * 1024):.2f} MB")with open(weights_filename, 'wb') as f, tqdm(
desc=weights_filename,
total=total_size,
unit='iB',
unit_scale=True,
unit_divisor=1024,
) as bar:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
bar.update(len(chunk))
print(f"{weights_filename} has been downloaded.")YOLOv3-416.weights: 100%|██████████|
237M/237M [01:46<00:00, 2.33MiB/s]
YOLOv3-416.weights has been downloaded.2) 가장 쉬운 이미지 추론 코드
OpenCV에서 제공하는 cv2.dnn 라이브러리를 사용하면
다운로드 받은
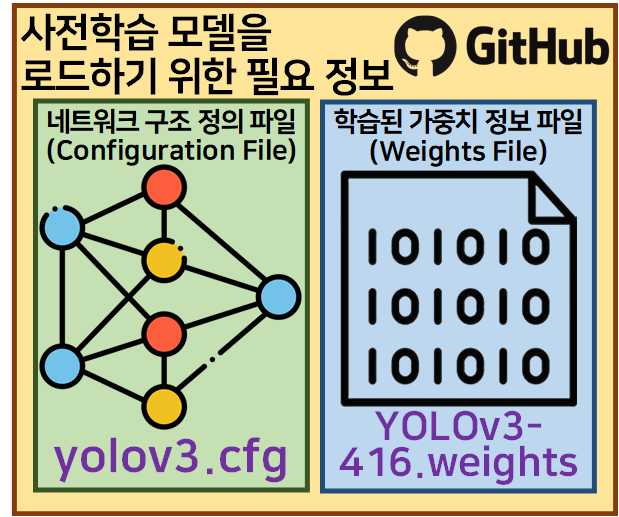 이 두개의 파일로 아주 간단하게 이미지 추론을 수행할 수 있다.
이 두개의 파일로 아주 간단하게 이미지 추론을 수행할 수 있다.
물론 추론과정을 수행하면서 Yolo v3이 어떻게 동작하는지에 대해서는 전혀 알 수 없는 코드이다.
import cv2, os
import numpy as np# classes = []
# f = open('/content/coco.names.txt','r')
# classes = [line.strip() for line in f.readlines()]
# colors = np.random.uniform(0,255, size=(len(classes),3))
root_dir = '[이미지 폴더가 있는 메인 경로]'
# Read the input image
image_name = '[이미지파일.jpg]'
img = cv2.imread(os.path.join(root_dir, image_name))
height, width, channels = img.shape
blob = cv2.dnn.blobFromImage(img, 1.0 / 256, (416, 416), (0, 0, 0), swapRB=True, crop=False)
yolo_model = cv2.dnn.readNet('YOLOv3-416.weights', 'yolov3.cfg')
layer_names = yolo_model.getLayerNames()
out_layers = [layer_names[i - 1] for i in yolo_model.getUnconnectedOutLayers()]
yolo_model.setInput(blob)
output3 = yolo_model.forward(out_layers)
class_ids, confidences, boxes = [], [], []
for output in output3:
for vec85 in output:
scores = vec85[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5:
centerx, centery = int(vec85[0] * width), int(vec85[1] * height)
w, h = int(vec85[2] * width), int(vec85[3] * height)
x, y = int(centerx - w / 2), int(centery - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
# text = str(classes[class_ids[i]]) + " %.3f" % confidences[i]
color = (255, 0, 0) # Set the box color to blue
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
# cv2.putText(img, text, (x, y + 30), cv2.FONT_HERSHEY_PLAIN, 2, colors[class_ids[i]], 2)
cv2.imshow('Object detection', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Yolo v3이 base에서 동작하는 더 상위 단계의 API를 설계한다면 해당 코드가 도움이 되지만
필자는 Yolo v3의 구동원리 학습 및 설계한 Yolo v3이 왜 학습이 제대로 되지 않았는지 코드검증을 하는 입장이기에
해당 코드는 다운로드 받은 yolov3.cfg, YOLOv3-416.weight 파일이 제대로 기능하는 파일임을 검증하는
그 이상의 가치를 갖기는 어려운 코드이다.
3) create_cfg_model 코드로 모델 객체화
위 2) 코드를 살펴본다면
yolo_model = cv2.dnn.readNet('YOLOv3-416.weights', 'yolov3.cfg')output3 = yolo_model.forward(out_layers)이 2개의 구문이 보일 것이다.
그 사이에 몇개의 코드가 더 있지만 대충
학습된 모델로 인스턴스화
인스턴스화 한 모델의 데이터 출력
이 기능을 수행하는 코드라는 것은 알 것이다.
그렇다면 학습된 모델의 인스턴스화
이 기능을 수행하는 코드는
인공지능 고급(시각) 강의 예습 - 22. (0) Yolo v3 사전 학습 모델 이 포스트에서 작성한 이력이 있고
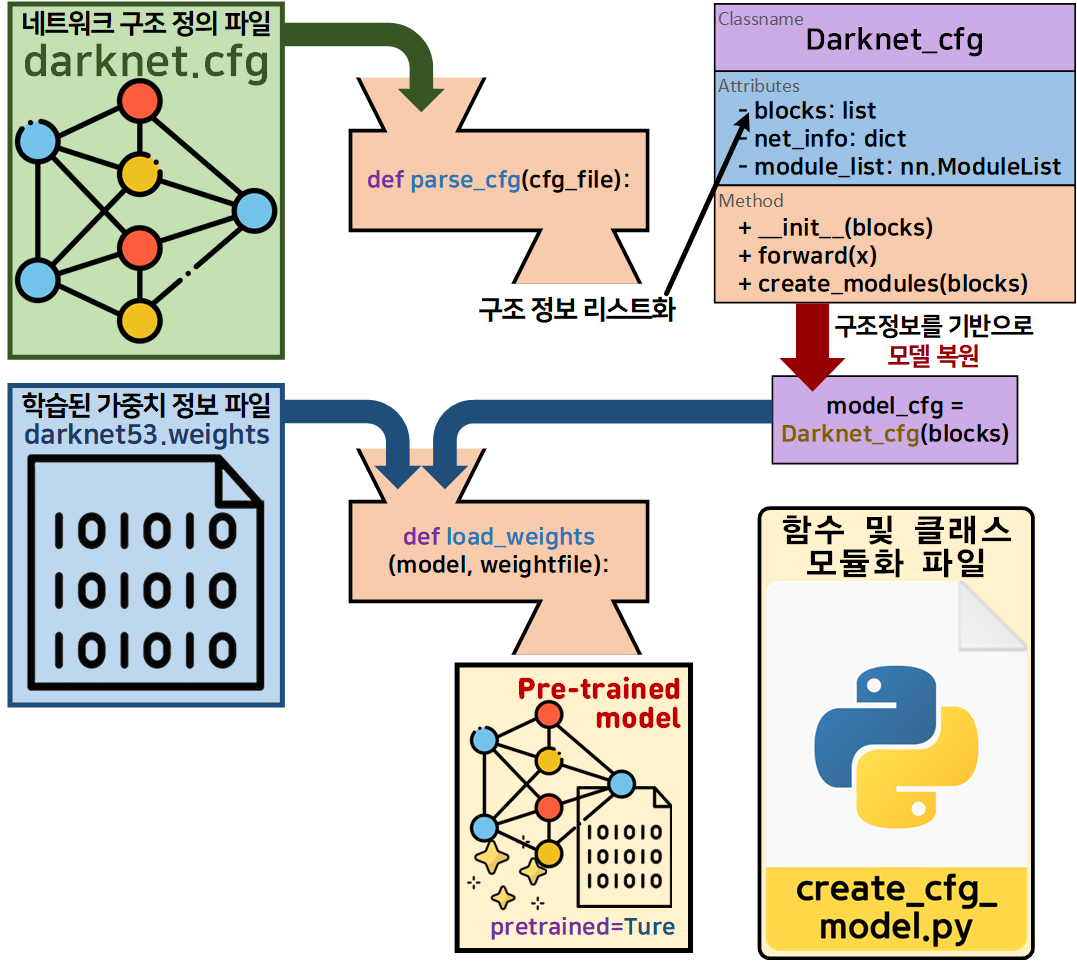 위 그림처럼 Darknet53에 대해서 학습된 모델의 인스턴스화를 모두 수행가능한 코드를
위 그림처럼 Darknet53에 대해서 학습된 모델의 인스턴스화를 모두 수행가능한 코드를
create_cfg_model.py로 작성했었다.
(인공지능 고급(시각) 강의 예습 - 22. (6) Yolo v3 모듈로 변환하기 참조)
따라서
create_cfg_model.py이 파일을 조금 조정해보면
yolo_model = cv2.dnn.readNet('YOLOv3-416.weights', 'yolov3.cfg')이 기능은 충분히 대체가 가능하다.
해당 코드는
https://github.com/tbvjvsladla/yolo_v3_pytorch
 여기에서 다운로드가 가능하며
여기에서 다운로드가 가능하며
코드 전체를 붙이면 너무 길어지기에
# Darknet53 모델
cfg_file = "darknet53.cfg"
weight_file = "darknet53.weights"
blocks = parse_cfg(cfg_file)
cfg_model = Darknet_cfg(blocks)
load_weights(cfg_model, weight_file)
print("Darknet53 모델 디버깅")
debug(cfg_model, input_size=(3, 256, 256))
# YOLOv3 모델
cfg_file = "yolov3.cfg"
weight_file = "YOLOv3-416.weights"
blocks = parse_cfg(cfg_file)
yolo_model = Yolo_v3_cfg(blocks)
load_weights(yolo_model, weight_file)
print("YOLOv3 모델 디버깅")
debug(yolo_model, input_size=(3, 416, 416))위 코드처럼 해당 모듈 파일을 다른 파일에서 import 하면
기존의 Darknet53 cfg 모델도 Pre-trained model로 인스턴스화가 가능하고
Yolo v3 cfg 모델도 Pre-trained model로 인스턴스화가 가능한 코드라 보면 된다.
따라서 아래처럼 코드를 작성할 수 있다.
import torch
# create_cfg_model.py파일 임포트
import create_cfg_model as cm# 기존 backbone인 Darknet53 인스턴스화 테스트
cfg_file = "darknet53.cfg"
weight_file = "darknet53.weights"
blocks = cm.parse_cfg(cfg_file)
# CFG 모델 인스턴스화
cfg_model = cm.Darknet_cfg(blocks)
# pre-trained weights로 CFG 모델 초기화
cm.load_weights(cfg_model, weight_file)# CFG 모델의 디버깅
cm.debug(cfg_model, input_size=(3, 256, 256))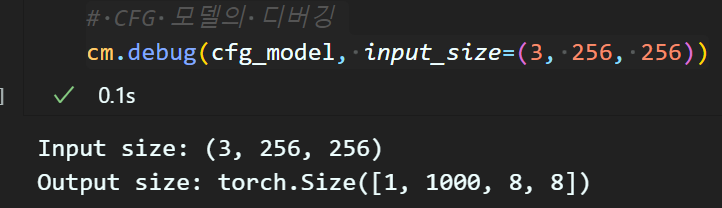 기존 기능이 잘 동작함을 확인했고
기존 기능이 잘 동작함을 확인했고
# 새로이 추가한 기능 - yolo v3 모델 인스턴스화
cfg_file = "yolov3.cfg"
weight_file = "YOLOv3-416.weights"
# CFG 정보 파싱
blocks = cm.parse_cfg(cfg_file)
# CFG 모델 인스턴스화
cfg_model = cm.Yolo_v3_cfg(blocks)
# pre-trained weights로 CFG 모델 초기화
cm.load_weights(cfg_model, weight_file)# CFG 모델의 디버깅
cm.debug(cfg_model, input_size=(3, 416, 416))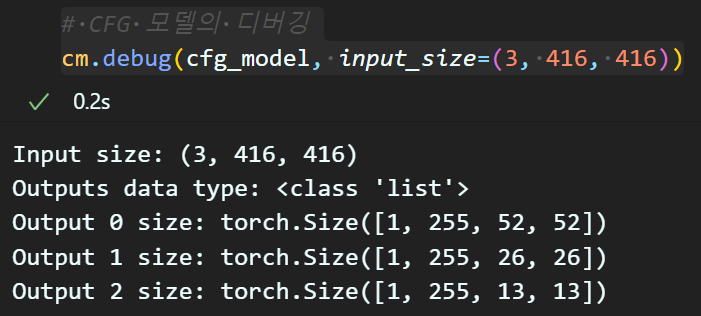 새로이 추가한 기능인 Yolo v3 cfg 모델도 Pre-trained model로 인스턴스화가 잘 수행됨을 알 수 있다.
새로이 추가한 기능인 Yolo v3 cfg 모델도 Pre-trained model로 인스턴스화가 잘 수행됨을 알 수 있다.
4) create_cfg_model로 이미지 추론 실습
다음으로는 3) 과정에서 cfg 모델의 인스턴스화가 잘 됨을 확인했으니 해당 코드로 동일하게
이미지 추론 과정을 수행해 보도록 하겠다.
# 필요 파일 로드
cfg_file = "yolov3.cfg"
weight_file = "YOLOv3-416.weights"
# cfg버전 Yolo v3의 인스턴스화
blocks = cm.parse_cfg(cfg_file)
yolo_model = cm.Yolo_v3_cfg(blocks)
cm.load_weights(yolo_model, weight_file)
# 불러온 모델을 평가모드로 전환
yolo_model.eval()root_dir = '[이미지 폴더가 있는 메인 경로]'
# Read the input image
image_name = '[이미지파일.jpg]' # 업로드된 이미지 경로
img = cv2.imread(os.path.join(root_dir, image_name))
height, width, channels = img.shape
# 이미지 처리 -> 기존 코드와 동일
blob = cv2.dnn.blobFromImage(img, 1/255.0, (416, 416), swapRB=True, crop=False)# cfg 모델 입력 메서드 yolo_model.setInput(blob) 가 아래 코드로 전환됨
blob = torch.from_numpy(blob).float()
blob = blob.permute(0, 2, 3, 1).squeeze(0) # (1, 3, 416, 416) -> (416, 416, 3)
blob = blob.permute(2, 0, 1).unsqueeze(0) # (416, 416, 3) -> (1, 3, 416, 416)# 모델에 이미지 입력 후 outputs 출력
with torch.no_grad():
outputs = yolo_model(blob)
# 모델의 출력 형태가 [1, 255, S, S] 형태이기에
# 이를 [1, S, S, 255]로 순번 재배치
outputs = [output.permute(0, 2, 3, 1) for output in outputs]def draw_boxes(img, outputs, conf_threshold=0.9, nms_threshold=0.5):
class_ids, confidences, boxes = [], [], []
# 여기는 outputs에서 bbox, os, cp를 추출하는 코드임
# outputs의 출력 형태가 변화되어 코드가 살짝 수정됨
for output in outputs:
S = output.size(1)
output = output.squeeze(0).view(S, S, 3, -1)
bbox = output[..., :4]
class_score = output[..., 5:]
cp_val, cp_id = torch.max(class_score, dim=-1)
conf_mask = cp_val > conf_threshold
f_bbox = bbox[conf_mask]
f_cp_val = cp_val[conf_mask]
f_cp_id = cp_id[conf_mask]
center_x = f_bbox[:, 0] * width
center_y = f_bbox[:, 1] * height
w = f_bbox[:, 2] * width
h = f_bbox[:, 3] * height
x = center_x - w / 2
y = center_y - h / 2
bboxes = torch.stack([x, y, w, h], dim=1).type(torch.int)
for i in range(f_bbox.size(0)):
boxes.append(bboxes[i].tolist())
confidences.append(float(f_cp_val[i].item()))
class_ids.append(int(f_cp_id[i].item()))
# 여기부터는 기존의 NMS 코드를 그대로 사용
indexes = cv2.dnn.NMSBoxes(boxes, confidences, conf_threshold, nms_threshold)
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
# text = str(classes[class_ids[i]]) + " %.3f" % confidences[i]
color = (255, 0, 0) # Set the box color to blue
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
# cv2.putText(img, text, (x, y + 30), cv2.FONT_HERSHEY_PLAIN, 2, colors[class_ids[i]], 2)# 이미지 추론 결과 display
draw_boxes(img, outputs)
cv2.imshow('Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()코드는 크게 변화된 부분이 없다.
2) 항목에서
output3 = yolo_model.forward(out_layers)의 출력 형태가
with torch.no_grad():
outputs = yolo_model(blob)
# 모델의 출력 형태가 [1, 255, S, S] 형태이기에
# 이를 [1, S, S, 255]로 순번 재배치
outputs = [output.permute(0, 2, 3, 1) for output in outputs]여기서 출력되는 형태와 살짝 다르기에
이에 따른 bbox, os, cp 정보 추출의 과정만 다를 뿐
그 이후 마지막 단계는 동일하게 구동한다.
이제 실행 결과를 확인해보자.
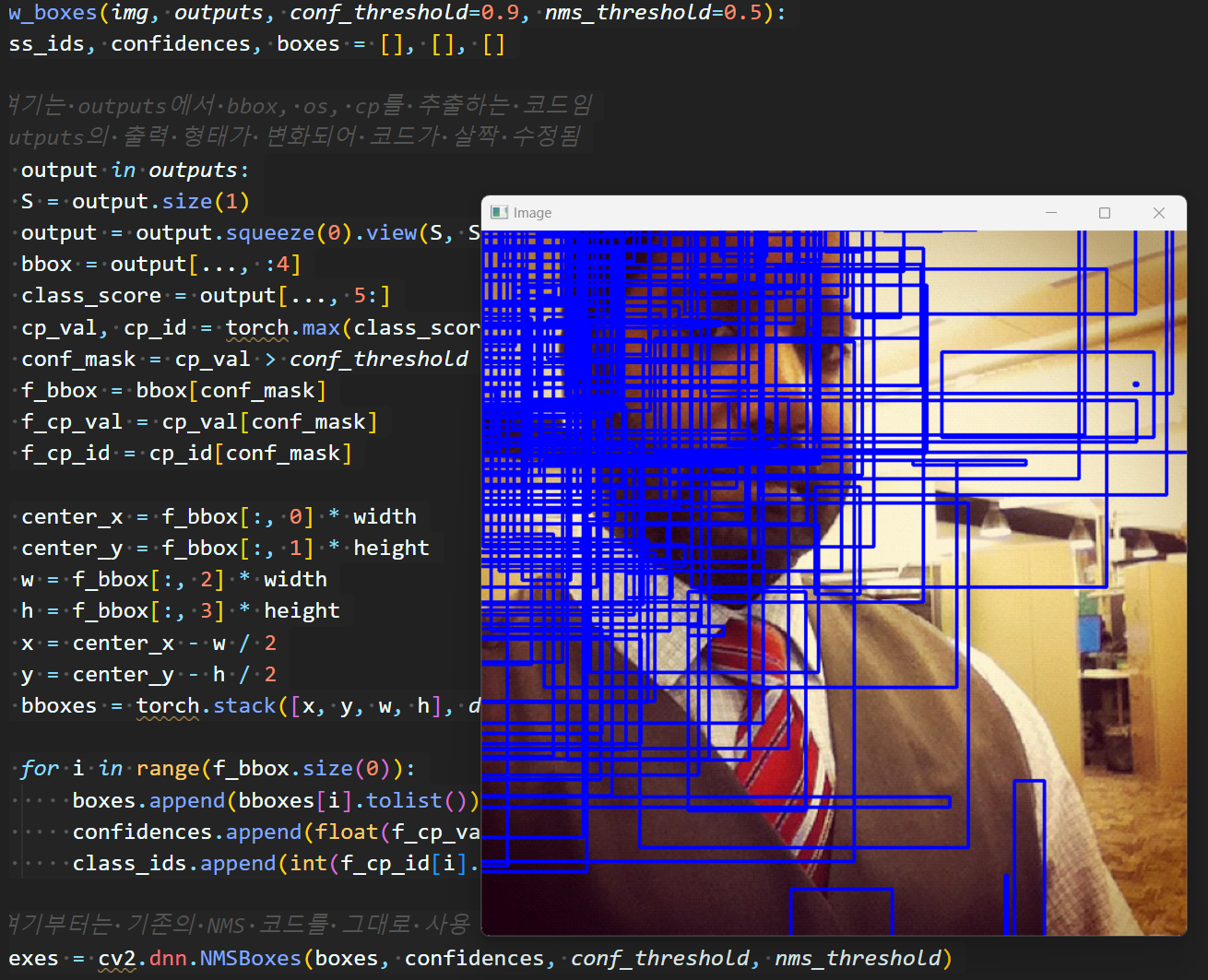

음.. 뭐가 다른데?
4)
cv2.dnn.readNet와 cfg 모델 객체화의 다른점
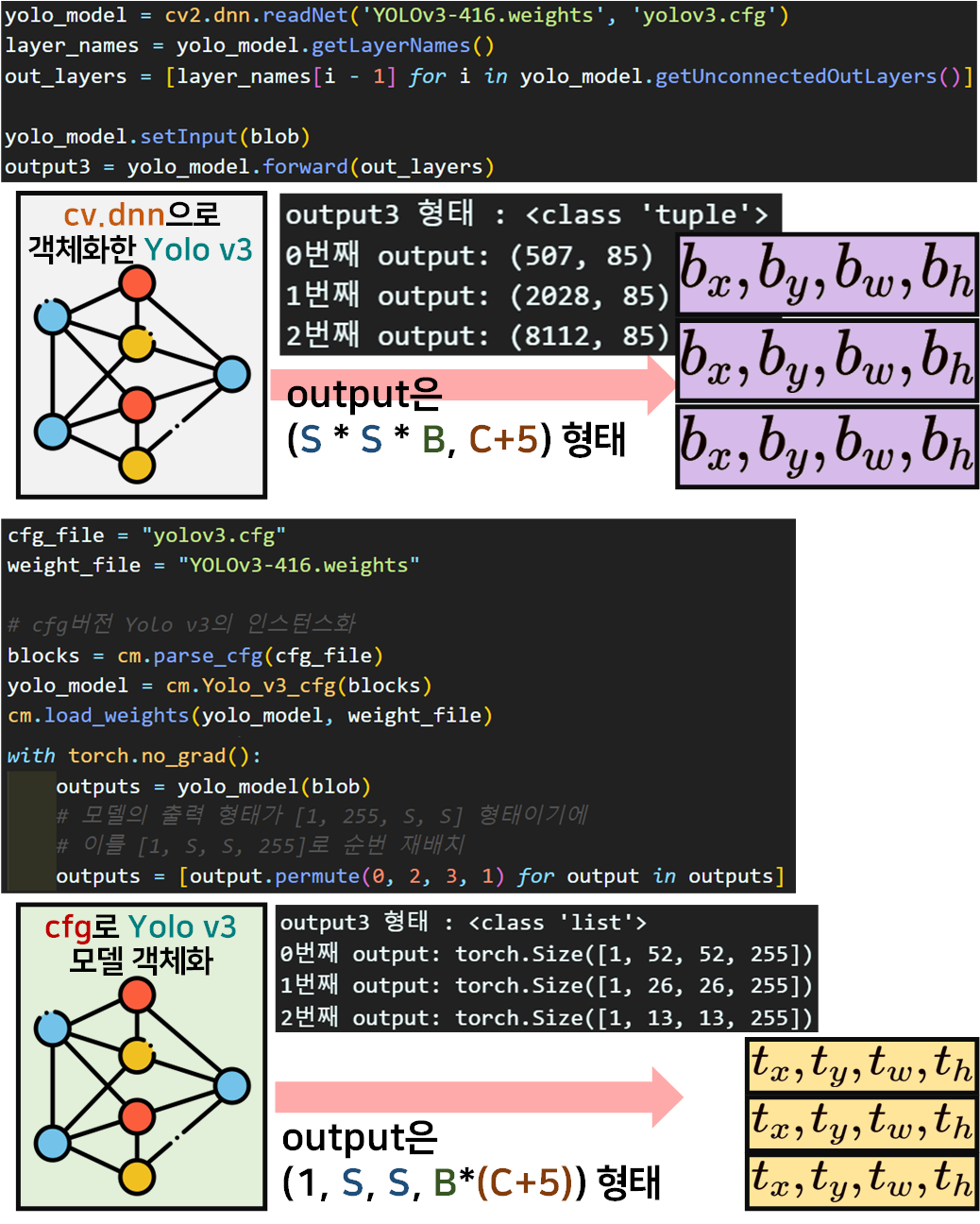
코드와 함께 출력물을 도식화 해보면 위와 같다.
cv.dnn 라이브러리를 사용하면
이미지에 직접 bbox를 그리는데 사용되는
로 값을 출력하지만
cfg 모델로 객체화 한 뒤 모델의 출력정보를 본다면
일반적인 Yolo v3가 출력하는 데이터인로 값을 출력한다.
이 차이가 발생하기에 cfg 모델에서는 아래의 그림처럼 좌표변환을 수행해야 한다.
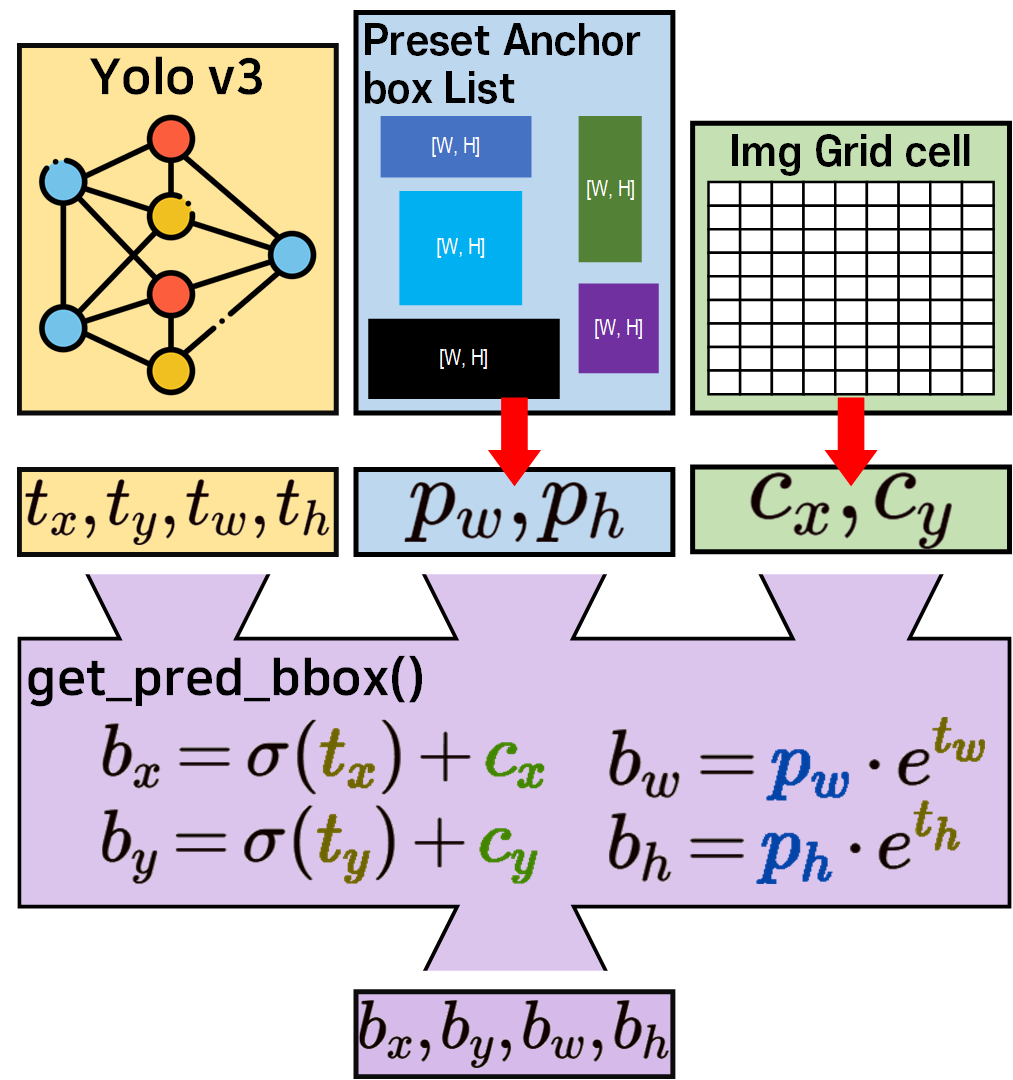
그렇다면 이 기능을 수행하는
get_pred_bbox()함수가 관여된 파일은
2개가 존재하며, 각각 설명 및 포스팅을 완료했다.
인공지능 고급(시각) 강의 예습 - 22. (5) Yolo v3 평가지표 + Train/Val 코드검증 여기서 사용한
yolo_v3_metrics.py
코드와
인공지능 고급(시각) 강의 예습 - 22. (7) Yolo v3 추론해보기 여기에 포스팅한
yolo_v3_nms.py
코드이다.
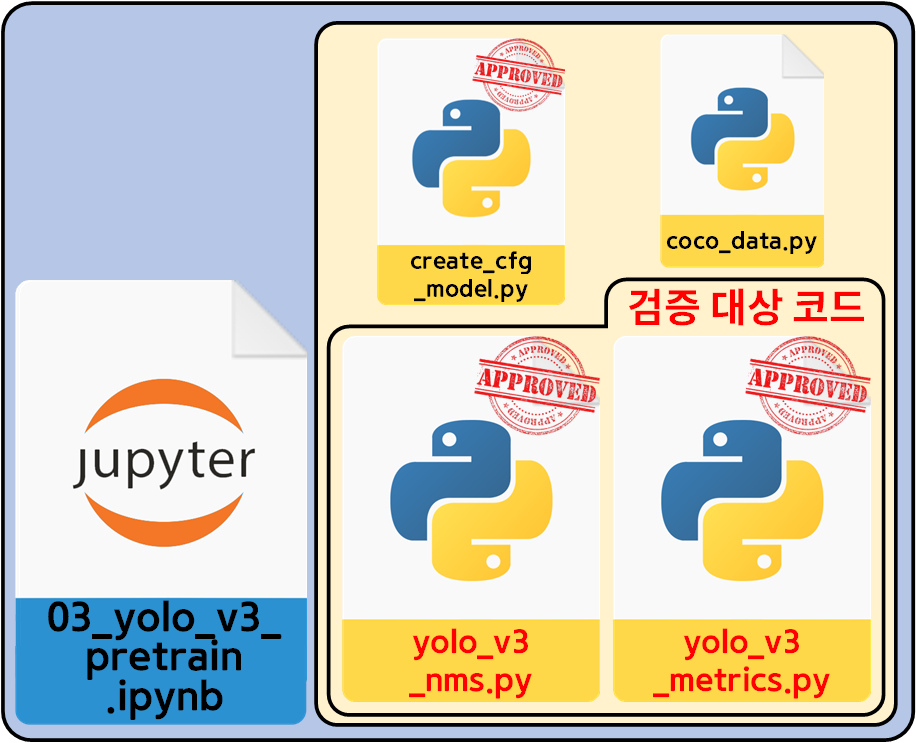
2. cfg 모델로 코드검증 1차
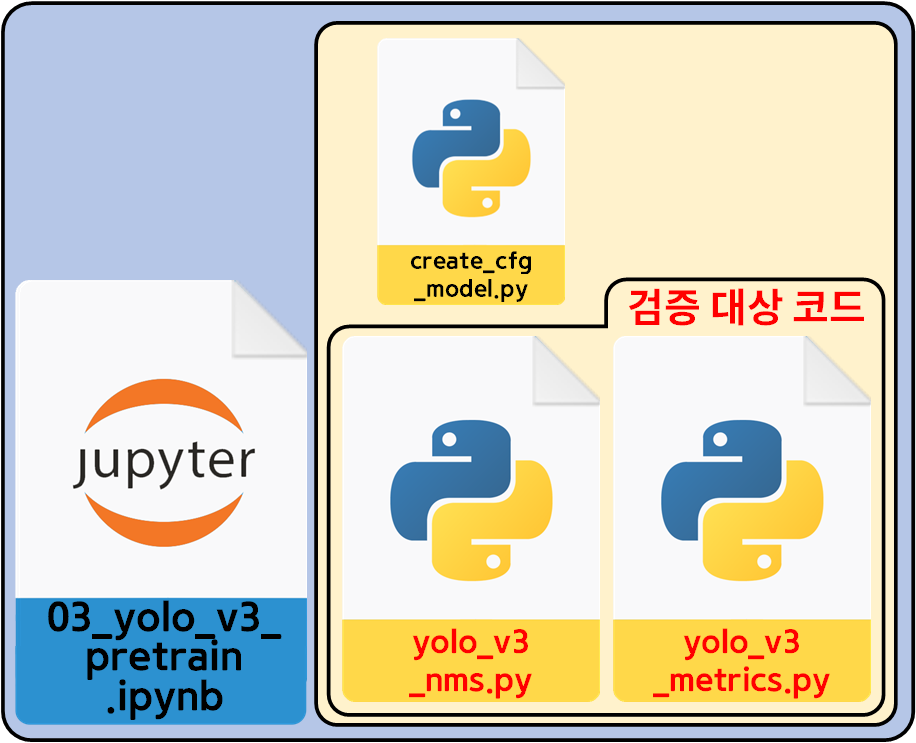 코드를 검증하기 위한 모듈의 구성은 위 사진과 같다.
코드를 검증하기 위한 모듈의 구성은 위 사진과 같다.
이미 검증된 cfg 형식 Yolo v3 모델을 불러 온 뒤(create_cfg_model.py)
해당 모델로
1) cv2.dnn.NMSBoxes 기능을 구현한 yolo_v3_nms.py
코드에 대한 검증
2) T_series_bbox좌표 -> B_series_bbox좌표 변환을 수행하는 get_pred_bbox() 함수의 검증(yolo_v3_metrics.py)
이 두가지를 수행한다 보면 된다.
전체적인 workflow는 아래와 같다.
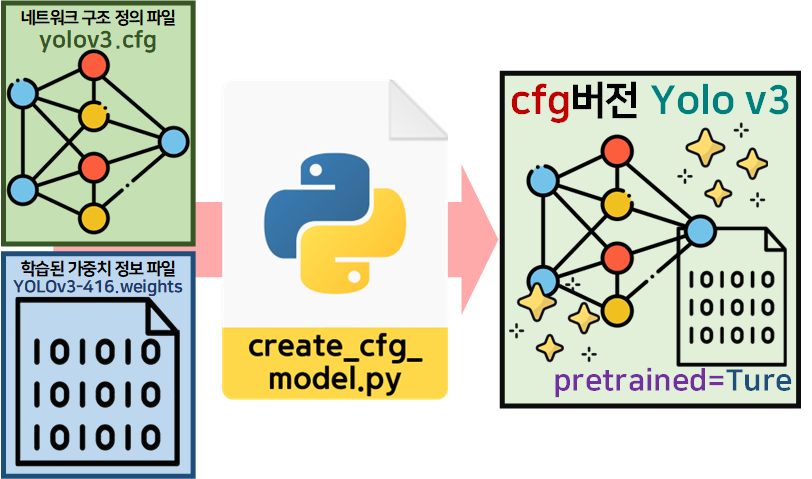 제일 먼저 수행하는 것은 cfg 형식 Yolo v3를 객체화 하는 것이다.
제일 먼저 수행하는 것은 cfg 형식 Yolo v3를 객체화 하는 것이다.
이 과정은 앞선 단계에서 검증이 완료되었기에 문제가 없는 구간이다. 그 다음 수행할 내용이 주요 검증 내용이라 볼 수 있다.
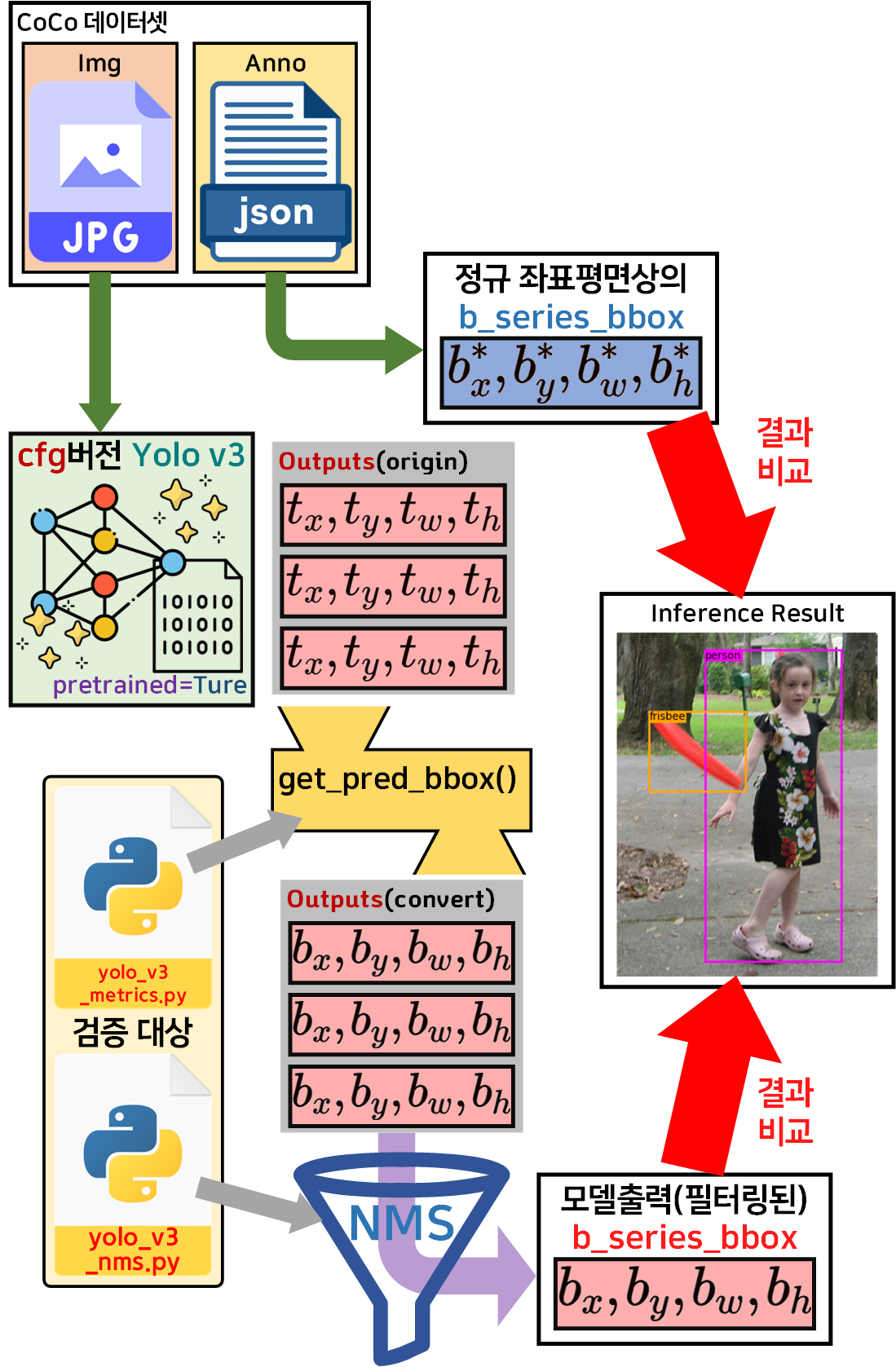 바로 이것이 이번 챕터에서 수행하고자 하는 주요 Task라 볼 수 있다.
바로 이것이 이번 챕터에서 수행하고자 하는 주요 Task라 볼 수 있다.
모델이 출력한 좌표변환을 수행한 뒤
NMS 필터링을 거쳐 의미있는 B_series_bbox좌표와
coco 데이터셋의 Anno 정보를 활용해 생성한
Ground Truth B_series_bbox을 서로 비교하여
두 결과물 Bounding Box이 좌표와 크기가 합당한 수준까지 일치한다면
yolo_v3_nms.py, yolo_v3_metrics.py이 정상동작한다 볼 수 있는 것이다.
1) yolov3.cfg 파일 수정
위 코드검증 과정을 수행하기 직전에 다운로드 받은
yolov3.cfg 파일에 대한 수정이 있어야 한다.

yolov3.cfg파일을 열람하면 모델을 설계하기 위한 정보 외에도 하이퍼 파라미터 정보를 더 찾아 볼 수 있는데
위 사진처럼 width, height, anchors에 대한 정보이다.
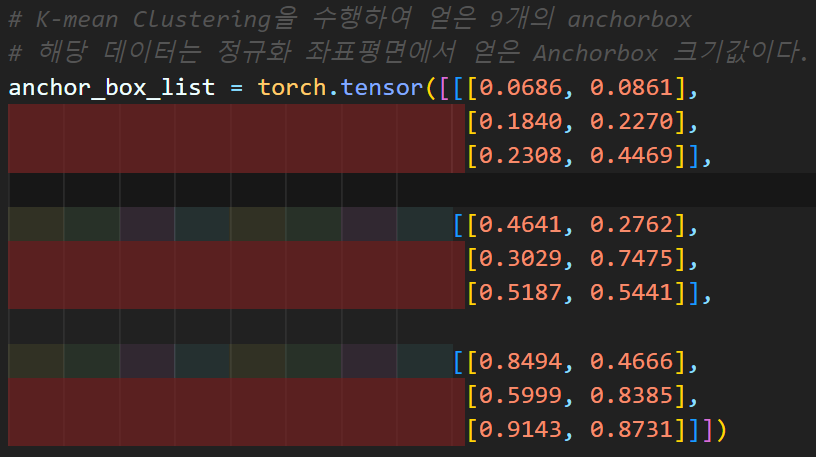 이 3가지 정보를 혼합한다면
이 3가지 정보를 혼합한다면
인공지능 고급(시각) 강의 예습 - 22. (4) Yolo v3용 Coco 데이터셋 전처리에서 포스팅 했던
위 사진의 anchor_box_list 생성이 가능해진다.
이 정규 좌표평면상의 anchor_box_list를 만드는 코드는
create_cfg_model.py 파일에 아래와 같이 함수화 했다.
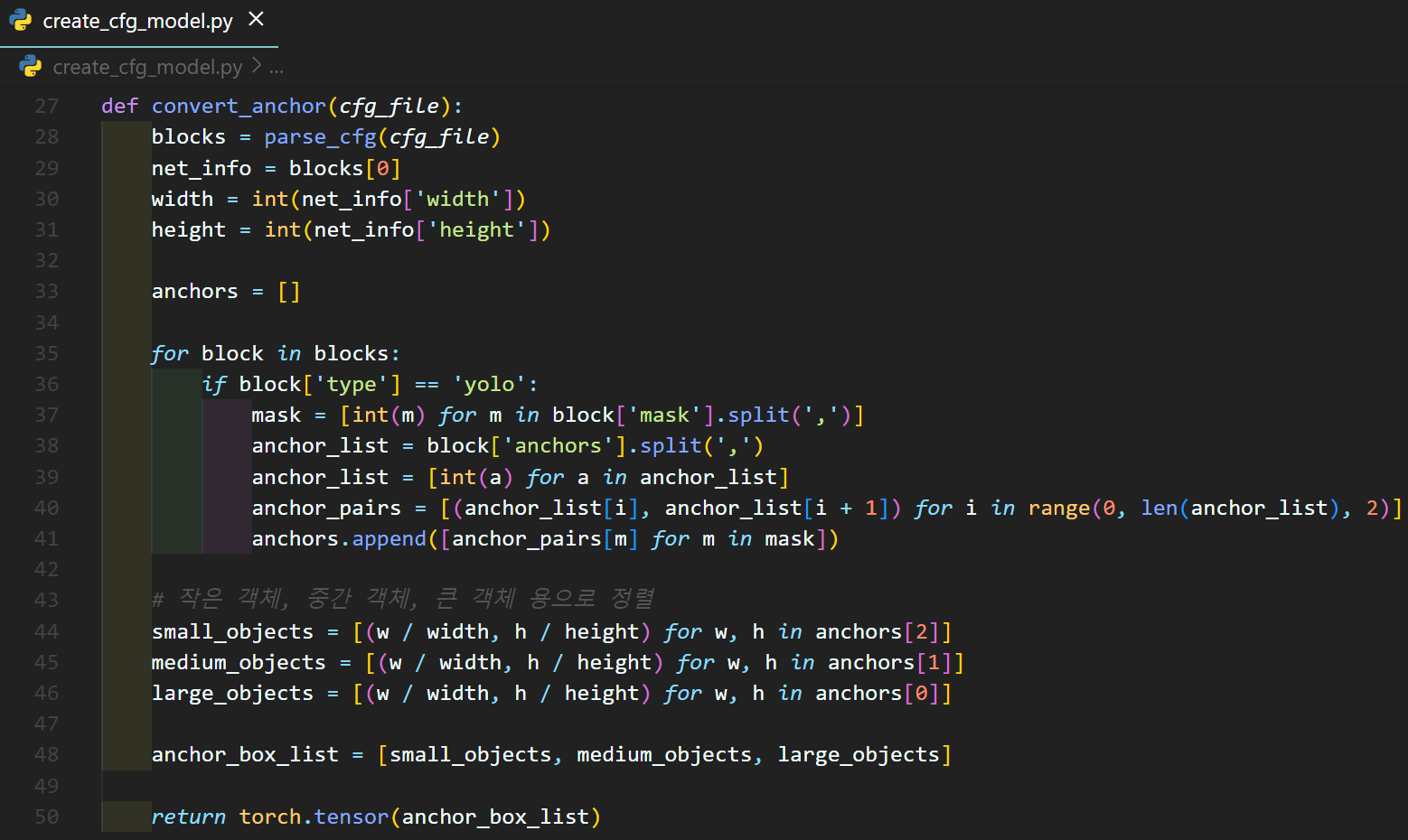 이때 정규좌표 평면상의
이때 정규좌표 평면상의 anchor_box_list를 만드는데
yolov3.cfg width, height 정보를 참조하기에
해당 값들을 608이 아닌 416으로 바꿔주자
yolov3.cfg에 포함되어있는
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326이 좌표정보는 이미지가 [416x416] 사이즈 일 경우 사용되는 Anchor box 좌표값이다.
따라서 정규 좌표평면상에서 제대로 동작하는
anchor_box_list를 생성하려면 width, height정보를 수정해줘야 한다.
이 오류때문에 하루 날렸다.

2) coco_data.py 파일 만들기
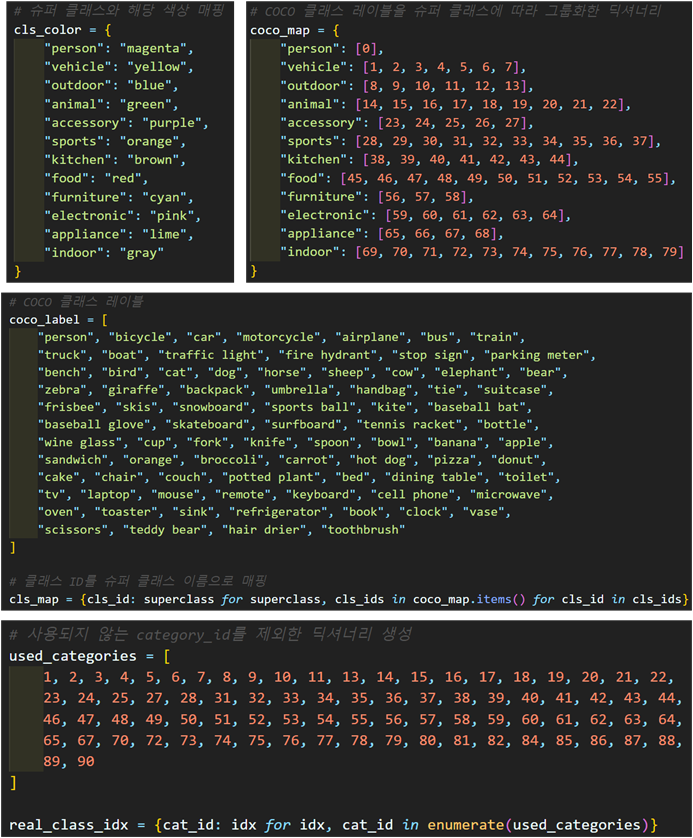 위 사진처럼 coco데이터셋을 기준으로 뭔가 좀..
위 사진처럼 coco데이터셋을 기준으로 뭔가 좀..
필요한 정보들이 많다...
이걸 coco_data.py 파일로 관리하는게 코드 재사용에도 유용하니 따로 관리를 하자
3)
03_yolo_v3_pretrain.ipynb전체 코드
import torch
import create_cfg_model as cm
import coco_data #사전에 로드해야할 변수 데이터 # 새로이 추가한 기능 - yolo v3 모델 인스턴스화
cfg_file = "yolov3.cfg"
weight_file = "YOLOv3-416.weights"
# CFG 정보 파싱
blocks = cm.parse_cfg(cfg_file)
# CFG 모델 인스턴스화
cfg_model = cm.Yolo_v3_cfg(blocks)
# pre-trained weights로 CFG 모델 초기화
cm.load_weights(cfg_model, weight_file)# create_cfg_model.py에 구현한
# anchorbox의 좌표를 정규좌표평면에 위치하도록
# 좌표 변환을 해주는 함수
cfg_anchor_box_list = cm.convert_anchor(cfg_file)
print(cfg_anchor_box_list)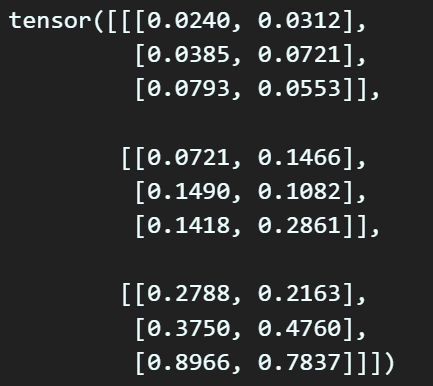
cm.convert_anchor() 위 함수를 수행하면 앞서 언급한 Yolo v3의 논문에서 사용한 Anchor box를 정규 좌표평면상에 위치하도록 스케일링이 가능하다.
import cv2, random, os
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
# 모델의 출력 outputs의 bbox를 필터링하는 nms 클래스
from yolo_v3_nms import Yolov3NMS
from pycocotools.coco import COCO# coco데이터셋의 메인 루트 디렉토리
root_dir = './COCO dataset'
anno_path = os.path.join(root_dir, 'annotations')
load_anno = 'val2014'
json_file = 'instances_' + load_anno + '.json'
coco = COCO(os.path.join(anno_path, json_file))참고로 COCO데이터의 폴더 구성을 조금 변경했는데
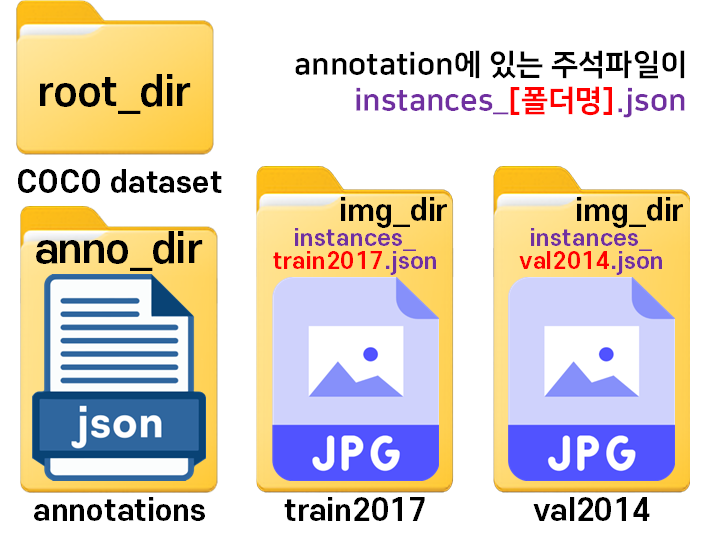
위 사진처럼 annotations폴더에 있는 coco데이터의 anno 주석파일의 이름중 일부를 빼와서
img_dir의 폴더명으로 삼았다.
이렇게 관리하는게 코드 작성에 더 편리하여 해당 방식으로 폴더 구성을 조금 수정했다.
# 임의의 이미지 하나 선택하기
img_ids = coco.getImgIds()
chosen_img = random.choice(img_ids)
img_info = coco.loadImgs(chosen_img)[0]
img_file_name = img_info['file_name']
print(img_file_name)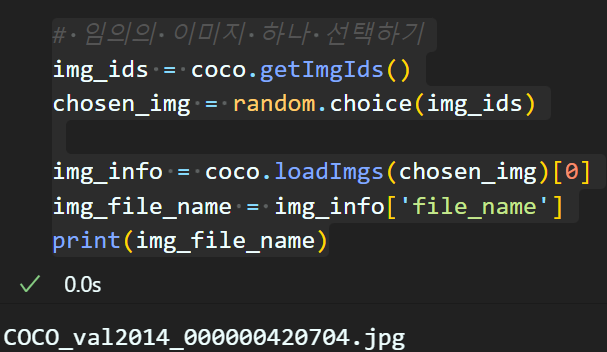 데이터셋 폴더 구성에 맞춰 이미지 파일 리스트 중 랜덤으로 하나의 이미지 파일을 불러오는 코드를 작성한다.
데이터셋 폴더 구성에 맞춰 이미지 파일 리스트 중 랜덤으로 하나의 이미지 파일을 불러오는 코드를 작성한다.
# 이미지 불러오기 및 전처리
image_path = os.path.join(root_dir, load_anno, img_file_name)
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_resized = cv2.resize(image_rgb, (416, 416))
image_tensor = torch.from_numpy(image_resized).permute(2, 0, 1).unsqueeze(0).float() / 255.0# gt_box 정보 추출하기
ann_ids = coco.getAnnIds(imgIds=chosen_img)
anns = coco.loadAnns(ann_ids)
gt_boxes = []
for ann in anns:
bbox = ann['bbox']
# CP는 Class Probability이니 = Class ID
CP_idx = coco_data.real_class_idx[ann['category_id']]
x, y, w, h = bbox
# bbox 좌표 정규화
bx = (x + w / 2) / img_info['width']
by = (y + h / 2) / img_info['height']
bw = w / img_info['width']
bh = h / img_info['height']
gt_box = torch.tensor([bx, by, bw, bh, 1, CP_idx])
gt_boxes.append(gt_box)
gt_boxes = sorted(gt_boxes, key=lambda box: (box[5], box[2] * box[3]))
# 정규 좌표평면상으로 변환한 GT_b_series_bbox 좌표 리스트 출력
for gt_box in gt_boxes:
print(gt_box)그 다음 불러온 이미지에 대하여 매칭되는 주석 정보를 확인한 뒤
해당 주석 정보의 bbox를 정규 좌표평면상의
GT_b_series_bbox가 되도록 좌표변환을 수행한다.
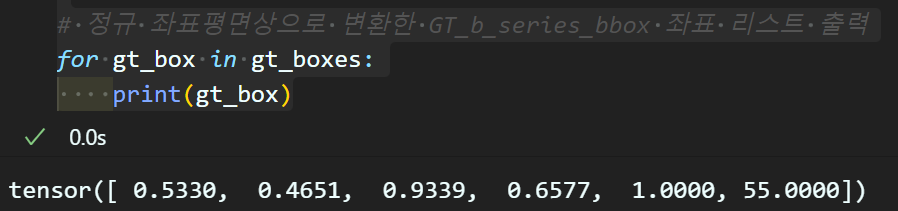
이미지에 객체가 많으면 위 GT_b_series_bbox 정보가 많이 나오는데 그건 너무 난잡해서
한개의 객체만 있는 이미지가 걸리게끔 랜덤 선택 코드를 여러번 돌렸다.
# 모델 추론
with torch.no_grad():
outputs = cfg_model(image_tensor)
# NMS 적용을 위한 nms 클래스 인스턴스화
# 이때 `anchor` 변수는 앞서 정규 좌표평면의 anthor_box_list를 인자로
nms = Yolov3NMS(conf_th=0.4, anchor=cfg_anchor_box_list)
# 아래의 메서드가 수행되면 [tx, ty, tw, th] -> [bx, by, bw, bh] 좌표변환
# 그 이후 NMS 필터가 한번에 다 돌아감
boxes = nms.non_max_suppression(outputs)
boxes = sorted(boxes, key=lambda box: (box[5], box[2] * box[3]))
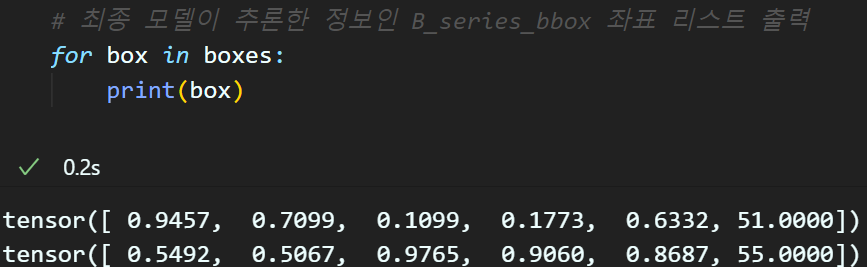
# 최종 모델이 추론한 정보인 B_series_bbox 좌표 리스트 출력
for box in boxes:
print(box)다음으로 모델이 추론한
좌표를
로 변환하고
(yolo_v3_metrics.py)
이를 NMS 필터링을 수행한다.
(yolo_v3_nms.py)
참고로 yolo_v3_nms.py에서 yolo_v3_metrics.py를 import하여 함수를 사용하기에
이 좌표변환 NMS필터링은 하나의 메서드로 한큐에 수행된다.
# 결과 시각화 함수
def plot_boxes(image, boxes, labels):
plt.figure(figsize=(10, 10))
plt.imshow(image)
ax = plt.gca()
# 정규 좌표값 boxes를 원래 값으로 복원
scale_y = image.shape[0] # height
scale_x = image.shape[1] # width
boxes = [[box[0] * scale_x, # x_center * width
box[1] * scale_y, # y_center * height
box[2] * scale_x, # w * width
box[3] * scale_y, # h * height
box[4], box[5]] for box in boxes]
for box in boxes:
x_center, y_center, w, h, conf, label = box
# bbox를 그리는데 좌 상단 좌표, width, hight 필요
x1 = x_center - w / 2
y1 = y_center - h / 2
# 라벨의 텍스트 좌표 및 bbox의 색깔 정하기
label = int(label)
superclass = coco_data.cls_map[label]
color = coco_data.cls_color[superclass]
rect = Rectangle((x1, y1), w, h, linewidth=2, edgecolor=color, facecolor='none')
ax.add_patch(rect)
plt.text(x1, y1, s=labels[label], color='black', verticalalignment='top',
bbox={'color': color, 'pad': 0})
plt.axis('off')
plt.show()마지막으로 결과 시각화 함수를 설계한뒤 디스플레이를 해주자
이 결과 시각화 함수에는 정규 좌표폄면상의
B_series_bbox좌표를 원래 이미지의 크기에 맞게 스케일링하는 코드가 함께 첨부되어 있다.
# 모델 추론 결과 -> B_series좌표변환 -> NMS 필터 후 결과 시각화
plot_boxes(image_rgb, boxes, coco_data.coco_label)
# Ground_Truth 좌표에 대한 결과 시각화
plot_boxes(image_rgb, gt_boxes, coco_data.coco_label)
이정도면
yolo_v3_nms.py, yolo_v3_metrics.py코드는 검증이 완료되었다 볼 수 있다.
이런식으로 작성한 *.py파일에 대한 코드검증을 수행하고자 한다.
