Hands-on ML Ch 11: Deep Neural Network
Gradient Exploding and Vanishing
Activation Function and Weight Initialization
신경망의 위쪽으로 갈수록 층을 지날 때마다 분산이 계속 커져 가장 높은 층에서는 활성화 함수가 0이나 1로 수렴함.
- 예시: logistic regression 에서 입력이 커지면 0이나 1로 수렴해서 기울기가 거의 0에 가까워지기 때문에 이 거의 없는 gradient 가 backprop 되면서 아래쪽 층에는 아무것도 전달되지 않게 됨.
- 각 층의 연결 가중치를 무작위로 초기화 하는 방법을 제안 (Xavier Initialization)
ReLU activation function 의 경우 He Initialization 을 사용.
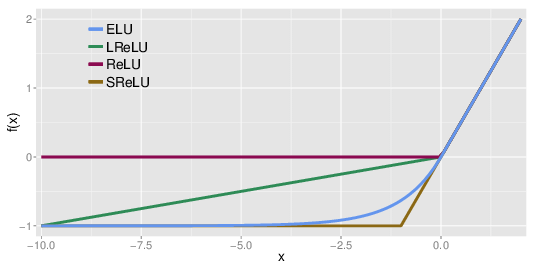
ReLU 사용시에 일부 뉴런이 0이외의 값을 출력하지 않는 현상이 발생하여 음수 구간에서도 작은 기울기를 가질 수 있는 LeakyReLU 가 등장
Batch Normalization
각 층에서 activation fn 을 통과하기 전에 연산을 추가. Normalize 후에 scale 을 조정하고 shift.
Inference 시에는 보통 1장 단위로 입력을 넣기에, batch-wise mean, std dev 를 구할 수 없는 문제가 있음.
- 훈련이 끝난 후 전체 훈련 세트를 신경망에 통과시켜 batchNorm 층의 각 입력에 대한 평균과 표준편차를 저장. 이를 inference 에 사용.
- 대부분은 입력 평균과 표준편차의 moving average 를 사용해 훈련하는 동안 최종 통계를 추정.
Transfer Learning
출력층 등 상위에 해당하는 층만 재학습하고 나머지는 다른 모델에서 가져온 layer를 freeze 하여 학습에 사용
재사용 층에서 unfreeze 할때는 learning rate 를 줄이는 것이 도움이 된다.
keras 에서 모델 A를 B로 transfer 하는 경우 B 학습시에 A도 영향을 받기 때문에 A를 clone 해준다.
model_A = keras.models.load_model("my_model.h5")
model_B = keras.models.Sequential(model_A.layers[:-1])
model_B.add(keras.layers.Dense(2, activation = "sigmoid")
model_A_clone = keras.models.clone_model(model_A)
model_A_clone.set_weights(model_A.get_weights())
# layer 를 freeze 한 후 compile 할 것
for layer in model_B.layers[:-1]:
layer.trainable = False
model_B.compile(loss = "binary_crossentropy", optimizer = "sgd", metrics = ["loss"])Unsupervised Pretraining
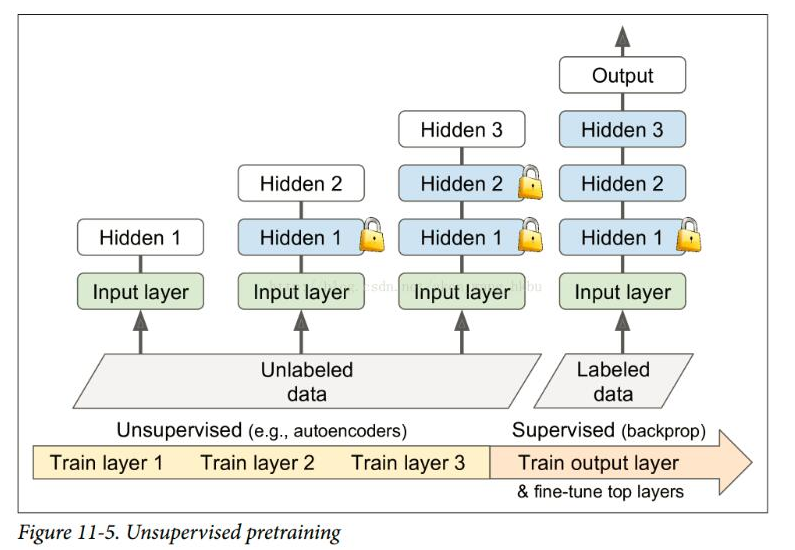
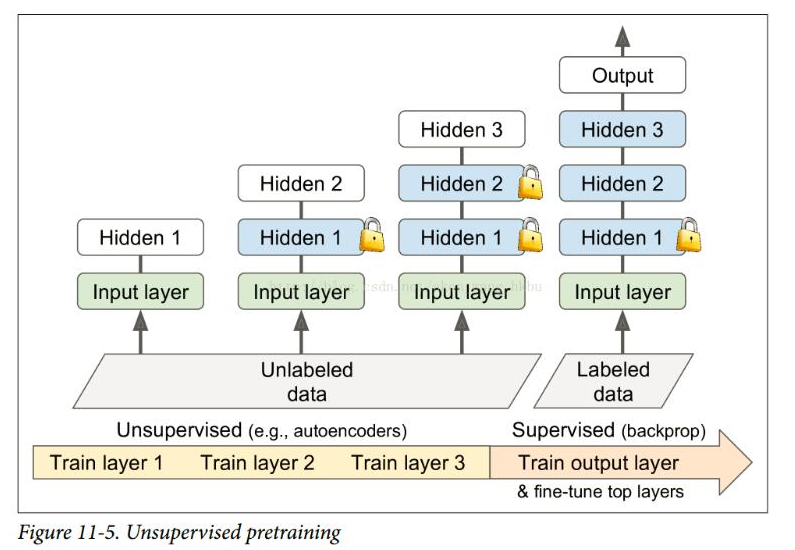
먼저 unlabeled data 를 unsupervised 방식으로 (GAN) train 하고 supervised 방식으로 마지막 출력층만 fine-tune
Optimizer
Momentum SGD
이전 기울기가 얼마였는지를 고려하여 기울기를 가속도와 같은 개념으로 사용.
처음에는 느리게 출발하지만 점점 가속되는 방식.
Nesterov Momentum
현재 위치가 아닌 모멘텀의 방향으로 조금 앞선 theta + beta*momentum 에서 cost function 의 gradient 를 계산.
최적값에 조금 더 금방 가까워지기 때문에 기존 모멘텀 방식보다 더 빠름.
AdaGrad
가장 가파른 차원을 따라 gradient vector 의 스케일을 감소시켜 전역 최적점 쪽으로 정확한 방향을 잡도록 설계.
Learning rate decay 에 있어 경사가 완만한 차원보다 가파른 차원에 대해 더 빠르게 감소.
딥러닝에는 사용하지 않고 regression 에 종종 사용.
RMSProp
AdaGrad 는 너무 빨리 느려져서 global minima 에 수렴하지 못하는 위험이 있음.
그래서, 시작부터의 모든 gradient 가 아닌 최근 반복에서 비롯된 gradient 만 누적함으로써 이 문제를 해결.
Adam
Adaptive Moment Estimation
Momentum 방식과 RMSProp 방식의 결합
optimizer = keras.optimizers.SGD(lr = 0.001, momentum = 0.9, nesterov = True)
optimizer = keras.optimizers.RMSProp(lr = 0.001, rho = 0.9)
optimizer = keras.optimizers.Adam(lr = 0.001, beta_1 = 0.9, beta_2 = 0.999)