👨🏫학습목표
오늘은 Asynchronous Advantage Actor-Critic의 구조, 학습방법에 대해 배워볼 예정이다.
👨🎓강의영상: https://www.youtube.com/watch?v=YJi3sBv2fRg
📃Asynchronous Method 논문: https://arxiv.org/pdf/1602.01783
1️⃣ Asynchronous Advantage Actor-Critic

🔷 Asynchronous Advantage Actor-Critic
🔻 기본적인 구조
- Actor-Critic algorithm이다.
- Multiple Network로 이루어져 있다.
- Multiple Network는 global network와 multiple worker agent로 이루어져 있다.
- 각 multiple worker agent가 개별적으로 작동한 후, global network에서 통합되는 특징이 있다.
- 각 Agent는 개별적으로 sample data를 수집한 후 파라미터를 업데이트한다.
- 각 Agent는 자신의 업데이트를 마친 후 업데이트한 내용을 바탕으로 개별적으로 global network를 업데이트한다.
🔻 Parallelism의 장점
- A3C에서 가장 중요한 것은 global network의 파라미터 업데이트이다.
- 각 agent는 temporal correlation을 가진다.
- 하지만 agent 간에는 개별적으로 학습이 진행되기 때문에 temporal correlation이 크게 발생하지 않는다.
- 따라서 global network 입장에서는 temporal correlation 문제가 심각하지 않다.
- 일반적으로 temporal correlation 문제가 발생할 경우 DQN처럼 experience replay를 문제를 해결한다.
DQN에 대한 추가적인 내용은 아래 글에서 확인 가능하다.
📃자료: https://velog.io/@tina1975/Deep-Reinforcement-Learning-17강-DQN-1
🔻 Advantage의 의미
- Actor-critic algorithm은 Actor Network와 Critic Network로 나뉜다.
- Critic Network는 value function을 출력하는데 이때 사용되는 value function이 advantage function이다.
🔸 Advantage를 구하는 방법
- 일반적으로 Advantage function을 출력하기 위해서는 와 를 출력하는 Network가 필요한다.
🔸 실제 A3C 모델이 구하는 것
- 하지만 기술적인 이유로 대신 n-step return 를 사용한다.
- n-step return 은 수집한 데이터로 구하기 때문에 추가적인 Network가 필요하지 않다.
🔻 A3C의 특징
- Actor-Critic은 policy gradient를 사용하기 때문에 continuous action space를 처리할 수 있다.
- Atari game에서 Dueling, Prioritized, Double DQN보다 더 좋은 성능을 발휘한다.
- 로보틱스와 같은 모터 조작 task에서도 뛰어난 성능을 발휘한다.
🔸 대표적인 DRL 모델
- DQN : 입력으로 continuous state space를 처리할 수 있지만, output으로는 discrete action space를 처리한다.
- A3C : 입력으로 continuous state space를 처리할 수 있고, output으로도 continuous action space를 처리할 수 있다.
2️⃣ Asynchronous
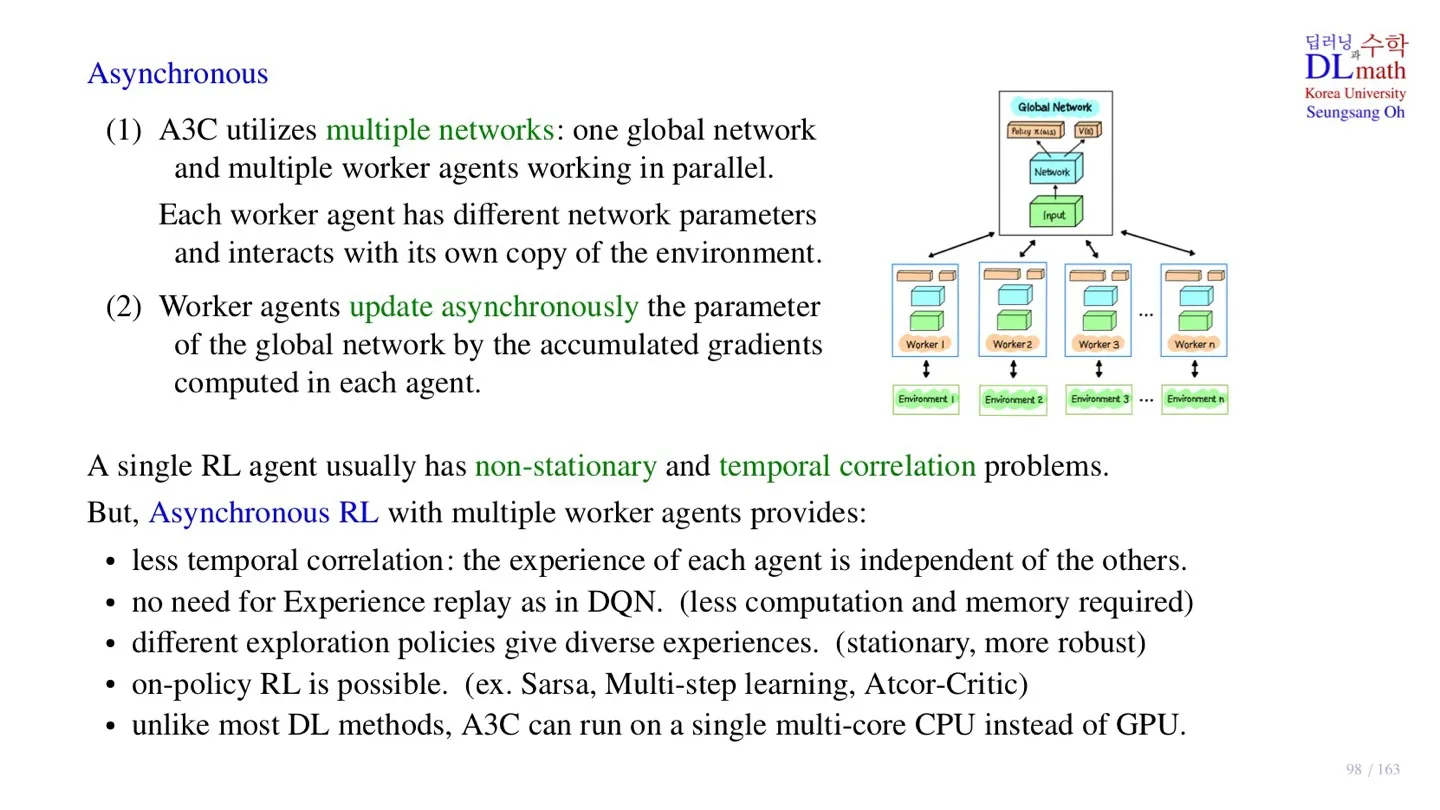
🔷 Asynchronous
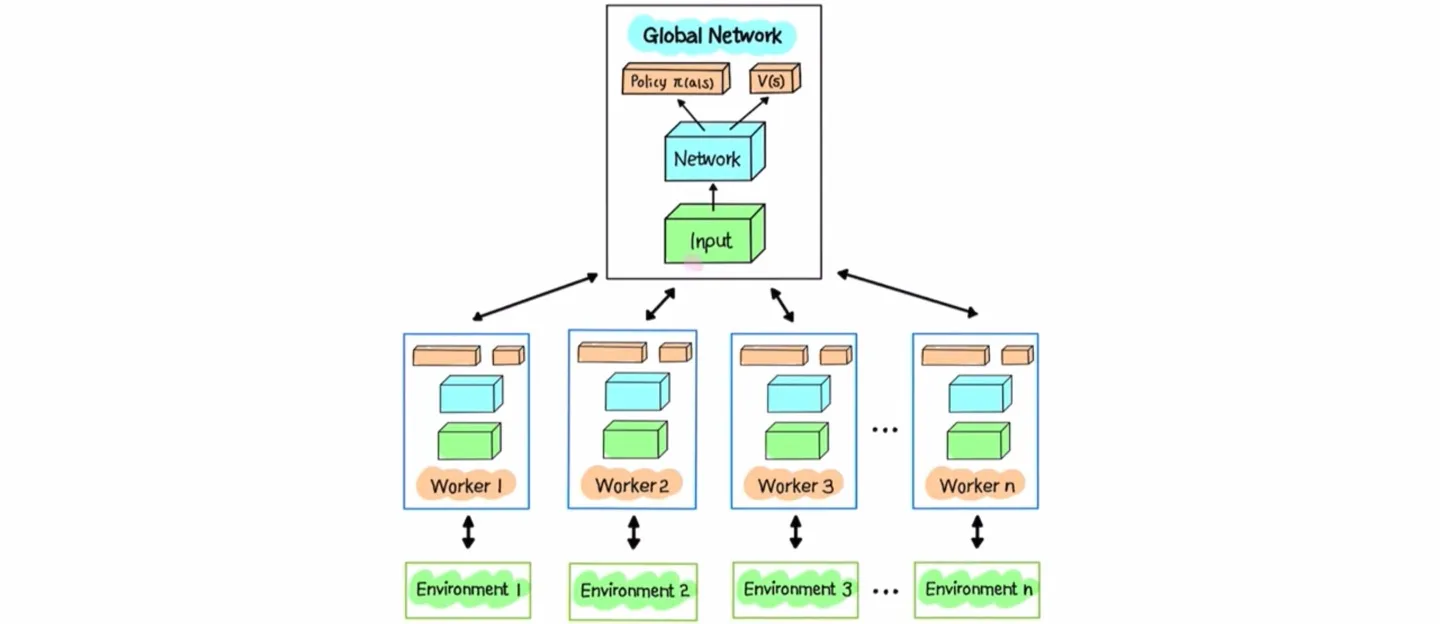
- 하나의 Global Network와 여러 개의 worker agent를 가진다.
- 각 agent는 자신만의 파라미터를 가지고 각자의 environment에서 학습을 수행한다.
- 각자 학습을 마치면 개별적으로 Global Network를 업데이트한다.
- 업데이트 방식은 각 worker agent가 일정 기간 동안 축적한 gradient를 전달하는 것이다.
- 학습이 마친 후 실제 추론 단계에서는 Global Network만 사용한다.
🔷 Multiple Agent의 장점
🔻 Single Agent의 한계
- Non-stationary : Target Network가 계속 움직이면 stationary하게 학습할 수 없다.
- Temporal correlation : 국소적인 영역에서 적합되는 문제가 발생한다.
🔻 Multipe Agent
- 각 agent가 asynchronous하게 업데이트를 진행할 때, 각 agent 사이에는 temporal correlation이 존재하지 않기 때문에 temporal correlation 문제를 해결할 수 있다.
- 따라서 experience replay를 사용할 필요가 없다.
- 각 agent마다 파라미터가 다르기 때문에 더 다양한 경험을 학습할 수 있다.
- 하나의 multi-core CPU로도 작동할 수 있다.
- Agent의 수가 많아질수록 학습속도가 빨라진다.
3️⃣ Asychronous Implementation

🔷 Asynchronous를 구현하는 방법
🔻 Global Network의 파라미터
- Actor 파라미터
- Critic 파라미터
🔻 파라미터 업데이트
- 각 Agent가 각자의 학습을 마친 후 즉시 Global Network의 파라미터를 업데이트한다.
- 축적된 gradient를 전달 후 agent는 업데이트된 를 그대로 가져온다.
- Agent는 새로운 파라미터를 가지고 학습을 시작한다.
- 학습은 step 동안 진행한다.
🔻 Acumulated Gradient 계산
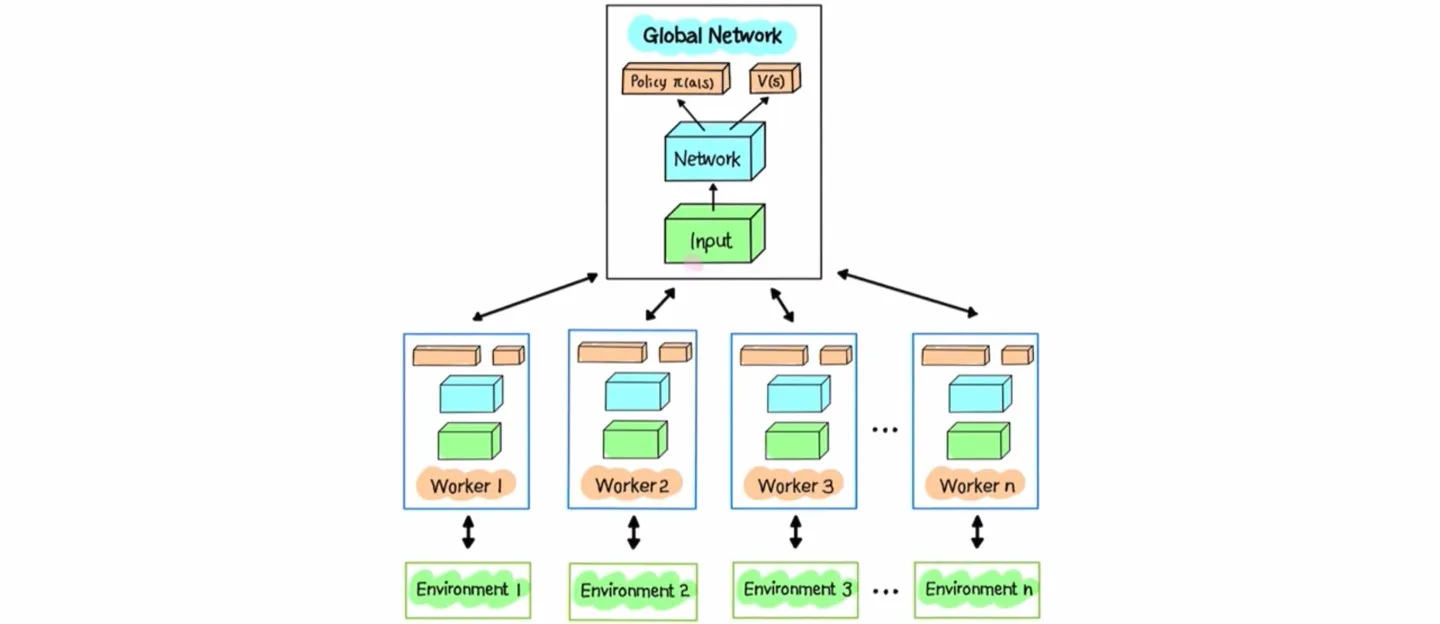
🔸 Agent Actor Network
- 해당 과정을 step 동안 반복한다.
- 가 accumulated gradient다.
🔸 Agent Critic Network
- 해당 과정을 step 동안 반복한다.
- 가 accumulated gradient다.
🔸 파라미터 업데이트
- 계산된 gradient로 agent를 실제로 학습하지는 않고, Global Network로 전달하여 업데이트를 진행한다.
- Actor Network 는 gradient ascent로 업데이트한다.
- Critic Network 는 gradient descent로 업데이트한다.
🔻 프로세스
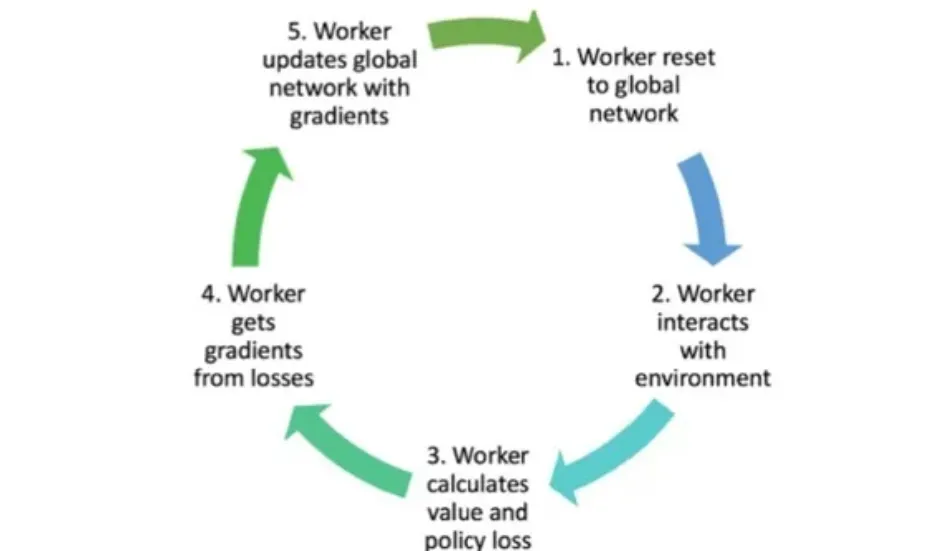
- 각 Agent가 Global Network의 파라미터를 가져온다.
- 각 Agent는 주어진 환경에서 데이터를 수집한다.
- 수집한 데이터를 통해 value function와 policy의 loss를 구한다.
- step동안 반복하여 accumulated gradient를 구한다.
- Accumulated gradient를 통해 Global Network를 업데이트한다.
4️⃣ 정리
🔷 24강에서 배운 내용은 아래와 같다.
- Asychronous Advantage Actor-critic은 policy gradient 방식이기 때문에 continuous action space를 처리할 수 있다.
- Asychronous Advantage Actor-critic은 Global Network와 multiple worker agent로 이루어져 있다.
- 실제 모델 학습 시 target network로 n-step return 을 사용한다.
- n-step return 에 를 빼서 baseline 역할을 수행한다.
- 모델 업데이트 시 각 agent가 개별적으로 Global Network를 업데이트한다.
- 각 Agent는 step동안 gradient를 축적하여 Global Network에 전달한다.

I'm curious about AI