
AIFFEL 노드에서 오차행렬이 나왔었는데 확실하게 이해가 가지 않아서 정리를 한번 해보려고 한다.
정리하고 여러번 보다보면 한번에는 이해하지 못하더라도 확실하게 이해는 할 수 있겠지..싶은 마음으로 :D
오차 행렬 (Confusion Matrix)
Test set에 대한 분류기의 성능을 평가하는 행렬로 혼동 행렬이라고도 한다.
행: 실제 클래스
열: 예측한 클래스
-
예측된 클래스 값과 실제 클래스 값을 기준으로 TRUE, FALSE로 분류
-
TN(True Negatives), FP(False Positives), FN(False Negatives), TP(True Positives) 로 분류하여 모델 예측 성능의 오류 발생 확인
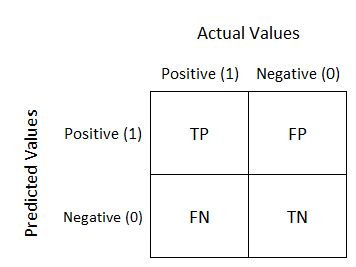
[https://kimdingko-world.tistory.com/173]-
TN: 예측값 Negative, 실제 값 Negative → 틀린 걸 틀렸다고 !
-
FP: 예측값 Positive, 실제 값 Negative → 틀린 걸 맞았다고 ! →
문제!! -
FN: 예측값 Negative, 실제 값 Positive → 맞은 걸 틀렸다고 ! →
문제!! -
TP: 예측값 Positive, 실제 값 Positive → 맞은 걸 맞았다고 !
성능 지표
오차 행렬을 통한 성능 지표는 아래와 같다.
-
Accuracy(정확도)
-
Sensitivity(민감도), Recall(재현율)
-
Precision(정밀도)
-
Specificity(특이도)
-
AUC
-
F1-score
Accuracy
예측값 중 정확한 예측을 어느정도로 했는지 확인하는 지표.
높을수록 예측 정확도가 높다.
하지만, 데이터에 따라 Accuracy만으로 모델의 성능을 판단하기에 어려울 수 있다.
그렇다면 어떠한 경우에 accuracy 만을 사용하고, 다른 지표를 사용해야할까?
그 기준은 데이터의 균형 정도를 기준으로 한다.
만약 사용한 데이터가 불균형 하다면 accuracy만이 아니 다른 지표를 함께 고려하여 성능을 판단해야한다.
-
균형 데이터(balanced) → accuracy를 평가 척도로 사용해도 괜찮음
-
불균형 데이터(imbalanced) → accuracy 만으로 성능 판단 X, 다른 지표도 함께 볼 것
Sensitivity
Recall 값으로, 실제 Positie를 얼마나 잘 예측했는지를 나타내는 지표
🤔 예시로 생각해보기
- 어떠한 사람이 환자인지 아닌지를 예측하는 모델을 만들었다고 하자.
- 실제 환자를 환자라고 예측한 값 → TP
- 실제 환자를 환자가 아니라고 예측한 값 → FN
- 민감도: 실제 환자에 대한 결과 값만 보는 것
- 그렇기 때문에 이 예시에서의 민감도는 실제 사람에 대한 예측값 중 실제 환자를 맞춘 값을 나타내는 지표 ! → 진짜 환자(Actual Positive) 기준
- 예시를 이해하고 다시 수식 다시보기 !!
Precision
긍정으로 예측한 것 중 실제로 맞춘 비율
🤔 예시로 생각해보기
- 위와 같이 어떠한 사람이 환자인지 아닌지를 예측하는 모델을 만들었다고 하자.
- 실제 환자를 환자라고 예측한 값 → TP
- 환자가 아닌 사람을 환자라고 예측한 값 → FP
- 정밀도: 모델이 환자라고 예측한 값만 보는 것
- 그렇기 때문에 이 예시에서의 정밀도는 모델이 환자라고 예측한 값 중 실제 환자를 맞춘 값을 나타내는 지표 ! → 모델이 예측한 환자(Predict Positive) 기준
- 예시를 이해하고 다시 수식 다시보기 !!
Specificity
실제 Negative를 얼마나 잘 예측 했는지 나타내는 지표
🤔 예시로 생각해보기
- 위와 같이 어떠한 사람이 환자인지 아닌지를 예측하는 모델을 만들었다고 하자.
- 환자가 아닌 사람을 환자라고 예측한 값 → FP
- 환자가 아닌 사람을 환자가 아니라고 예측한 값 → TN
- 특이도: 실제 환자가 아닌 사람에 대한 데이터를 보는 것
- 그렇기 때문에 이 예시에서의 특이도는 실제 환자가 아닌 사람을 환자가 아니라고 잘 예측했는지를 나타내는 지표 ! → 실제 환자가 아닌 사람 (Actual Negative) 기준
- 예시를 이해하고 다시 수식 다시보기 !!
F1 Score
불균형 분류 문제에 평가 척도로 많이 사용된다.
Sensitivity와 Precision을 이용하여 조화평균을 구하는 것으로 평가 척도 구성
-
불균형 데이터를 조화평균 하는 이유
-
큰 값의 크기에 대한 가중치 낮춤
-
작은 값에 가중치를 더 맞춤
-
위 과정을 통해 크기 차이를 상대적으로 상쇄
-
참고 자료
이 글은 아래 링크의 자료들을 참고하여 작성하였습니다.
분류 성능 - 오차 행렬(confusion matrix)과 정밀도(precision), 재현율(recall), F1 score(F-measure)
