더 나은 모델 성능 측정을 위한 Cross-Validation. 교차 검증 되시겠다.
Introduction
머신 러닝은 반복적인 과정임
어떤 변수를 사용할지, 어떤 모델을 사용할지, 어떤 인수를 제공할지 등에 여러 선택에 직면하게 된다.
지금까지는 검증 집합으로 모델 품질을 측정하여 데이터 기반 방식으로 이러한 선택을 해옴
그러나 이러한 방식의 단점이있다. 5000개의 행이 있는 데이터 집합이 있다고 가정한다.
일반적으로 데이터의 약 20%, 즉 1000개의 행을 validation dataset으로 유지한다. 하지만 이렇게 하면 모델 점수를 결정할 때 무작위적인 확률이 생김.
즉 어떤 모델이 1000개의 행으로 구성된 한 세트에서는 잘 작동하더라도 다른 1000개의 행에서는 부정확할 수 있음.
극단적으로는 validation dataset에 데이터 행이 1개만 있다고 상상할 수 있다. 대체 모델을 비교하면 어떤 모델이 단일 데이터 포인트에 대해 가장 정확한 예측을 하는지는 대부분 운의 문제임
일반적으로, validation set이 클수록 모델 품질 측정에 무작위성(일명 'noise')이 줄얻르고 신뢰도가 높아진다. 안타깝게도 훈련 데이터에서 행을 제거해야만 큰 validation dataset을 얻을 수 있으며, 훈련 데이터 집합이 작을 수록 모델이 더 나빠진다.
What is Cross-Validation?
cross-validation에서는, 우리는 여러 하위 집합에 대해 모델링 프로세스를 실행하여 모델 품질에 대한 여러 측정값을 얻음
예를 들어, 데이터를 전체 데이터 집합의 20%씩 5개로 나누는 것으로 시작할 수 있음.
이 상황에서, 우리는 데이터를 5겹(fold)로 나눈다 고 말할 수 있다.
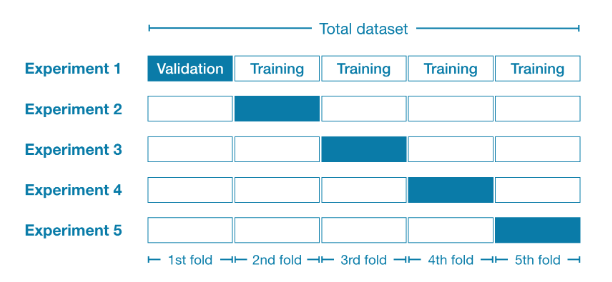
그 후 다음 각 fold에 대해 실험을 진행한다.
- 실험 1에서는 첫 번째 fold를 홀드아웃 집합으로 사용하고 나머지는 모두 training data로 사용한다. 이렇게 하면 20% 홀드아웃 집합을 기준으로 모델 품질을 측정할 수 있다.
- 실험 2에서는 두 번째 fold의 데이터를 홀드아웃 집합으로 사용하고 이를 제외한 모든 데이터를 모델 훈련에 사용한다. 그 다음 홀드아웃 집합을 사용하여 모델 품질에 대한 두 번째 추정치를 얻는다.
- 모든 fold를 홀드아웃 세트로 한 번씩 사용하여 이 과정을 반복한다. 이를 종합하면, 어느 시점에서 데이터의 100%가 홀드아웃으로 사용되며, 데이터 집합의 모든 행을 기반으로 하는 모델 품질 측정값을 얻게 된다(모든 행을 동시에 사용하지 않더라도)
When should you use Cross-Validation?
Cross-Validation은 모델 품질을 보다 정확하게 측정할 수 있으며, 이는 많은 모델링 결정을 내리는 경우 특히 중요하다.
그러나 여러 모델을 추정하기 때문에 실행 시간이 더 오래 걸릴 수 있다(각 fold당 하나씩).
그렇다면 이 장단점을 고려할 때, 각 접근 방식을 언제 사용해야 할까?
- 추가 계산 부담이 크지 않은 소규모 dataset 의 경우
- 대규모 dataset 의 경우 single validation 검사 집합으로도 충분하다.
- 코드가 더 빠르게 실행되고 홀드아웃을 위해 일부 데이터를 재사용할 필요가 없을 정도로 충분한 데이터가 있을 수 있음.
대규모 dataset과 소규모 dataset을 구분하는 간단한 임계값은 없음
하지만 모델을 실행하는 데 몇 분 이하가 걸리는 경우 Cross-Validation으로 전환하는 것이 좋음
또는 Cross-Validation을 실행하여 각 실험의 점수가 비슷하게 보이는지 확인할 수 있다. 각 실험에서 동일한 결과가 나오면 single validation set으로 충분할 수 있음.
Example
import pandas as pd
# Read the data
data = pd.read_csv(filepath)
# Select subset of predictors
cols_to_use = ['Rooms'. 'Distance', 'Landsize', 'BuildingArea', 'YearBuilt']
X = data[cols_to_use]
# Select target
y = data.Price결측값 -> Pipeline
모델 -> random forest
Pipeline을 안 쓰고도 Cross-Validation을 사용할 수도 있는 반면, 꽤 어려움
웬만하면 쓰라네요
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
my_pipeline = Pipeline(steps=[('preprocessor', SingleImputer()), ('model', RandomForestRegressor(n_estimators=50, random_state=0))])Cross-Validation 점수를 scikit-learn의 cross_val_score() 를 사용하여 얻을 수 있음
fold의 개수는 cv parameter로 설정할 수 있음
from sklearn.model_selection import cross_val_score
# Multiply by -1 since sklearn calculates negative MAE
scores = -1 * cross_val_score(my_pipeline, X, y, cv=5, scoring='neg_mean_absolute_error')
print("MAE scores:\n", scores)
scoring parameter는 보고할 모델 품질 측정값을 선택한다. 이 경우 음의 평균의 절대 오차(MAE)를 선택했다. scikit-learn의 문서 옵션에 나온다고 함
Negative MAE를 지정한 것은 조금 의외라고 한다. Scikit-learn에는 모든 metrics가 정의되는 규칙이 있으므로 수치가 높을 수록 좋다. 여기서 음수를 사용하면 이 규칙과 일관성을 유지할 수 있지만, 다른 곳에서는 음수 MAE를 거의 찾아볼 수 없음
우리는 일반적으로 대체 모델을 비교할 때 모델 품질에 대한 단일 측정값을 원한다. 따라서 실험 전체의 평균을 구한다.
print("Average MAE score (across experiments):")
print(scores.mean())
Conclusion
Cross-Validation을 사용하면 모델 품질을 훨씬 더 잘 측정할 수 있으며, 코드를 정리할 수 있는 추가적인 이점이 있다. 더 이상 별도의 training 및 validation dataset을 추적할 필요가 없다는 점에 유의해야 한다. 따라서, 소규모 dataset의 경우 큰 도움이 된다.
