드디어 Intermediate Machine Learning의 마지막 Data Leakage이다..
배우는 입장에서는 아직 Data Leakage에 대해서는 배울 필요가 없어보이지만..
이 튜토리얼에서는 Data Leakage가 무엇이며 이를 방지하는 방법에 대해 알아봅니다.
Data Leakage를 방지하는 방법을 모른다면 미묘하고 위험한 방식으로 모델을 망칠 수 있습니다.
이것은 Data Scientist에게 가장 중요한 개념 중 하나입니다.
Introduction
Data Leakage는 학습 데이터에 대상에 대한 정보가 포함되어 있지만 모델을 예측에 사용할 때 유사한 데이터를 사용할 수 없을 때 발생한다. 이로인해 학습 세트(및 검증 데이터)의 성능은 높아지지만, 실제 운영 환경에서는 모델의 성능이 저하된다.
다시 말해, Data Leakage로 인해 모델을 사용하여 의사 결정을 내리기 전까지는 모델이 정확해 보이지만 그 후에는 모델이 매우 부정확해진다.
누수에는 두 가지 유형이 있다.
- Target Leakage
- Train-Test Contamination
Target Leakage
Target Leakage는 예측 시점에 사용할 수 없는 데이터가 예측에 포함될 때 발생
단순히 기능이 정확한 예측을 하는 데 도움이 되는지 여부가 아니라,
데이터를 사용할 수 있게 되는 시기 또는 시간 순서 측면에서 고려하는 것이 중요하다.
예시로 보면 이해가 쉬울 것이다..
어떤 사람이 폐렴에 걸릴지 예측하는 데이터
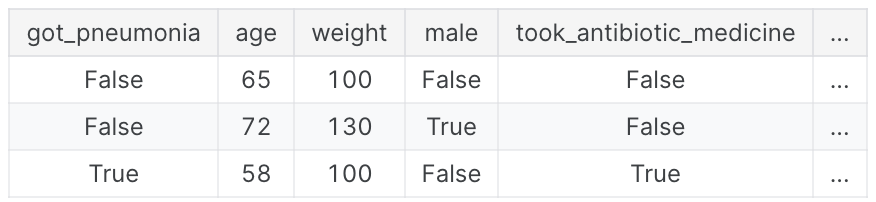
사람들은 폐렴에 걸린 후 회복을 위해 항생제 약을 복용한다. 원시 데이터는 이러한 열 간에 강력한 관계를 보여주지만, got_pneumonia의 값이 결정된 후 took_antibiotic_medicine이 자주 변경된다. 이것은 Target Leakage이다.
폐렴에 걸린 후에 약을 먹는다는 이야기이다.
이 모델에서는 took_antibiotic_medicine의 값이 False인 사람은 폐렴에 걸리지 않은 것으로 간주한다. 유효성 검사 데이터는 학습 데이터와 동일한 소스에서 가져오기 때문에 유효성 검사에서 패턴이 반복되고 모델의 유효성 검사에서는 점수가 높아진다.
하지만, 폐렴에 걸릴 환자라도 향후 건강 상태를 예측해야 할 때는 아직 항생제를 투여받지 않았을 수 있기 때문에 이 모델을 실제 환경에 배포하면 매우 부정확해질 수 있다.
이러한 유형의 Data Leakage를 방지하려면 목표 값이 실현된 후에 업데이트된 변수는 모두 제외해야 한다.
Train_Test Contamination
다른 유형의 유출은 학습 데이터와 검증 데이터를 구분하는 데 주의를 기울이지 않을 때 발생한다.
유효성 검사는 모델이 이전에 고려하지 않았던 데이터에 대해 어떻게 작동하는지 측정하기 위한 것을 기억해야 한다. 유효성 검사 데이터가 전처리 동작에 영향을 미치는 경우 이 프로세스가 미묘한 방식으로 손상될 수 있다. 이를 Train-Test Contamination 이라고 한다.
예를 들어, train_test_split()를 호출하기 전에 전처리(누락된 값에 대한 impute)를 실행한다고 가정해보면, 모델이 좋은 유효성 검사 점수를 받아 모델에 대한 신뢰도가 높을 수 있지만, 의사 결정을 위해 배포할 때는 성능이 저하될 수 있다.
결국 유효성 검사 또는 테스트 데이터의 데이터를 예측 방법에 통합했기 때문에 새로운 데이터로 일반화할 수 없더라도 특정 데이터에 대해서는 잘 작동할 수 있다. 이 문제는 더 복잡한 feature engineering을 수행할 때 훨씬 더 미묘하고 복잡해진다.
유효성 검사가 간단한 train-test split을 기반으로 하는 경우, 전처리 단계의 fitting을 포함한 모든 유형의 fitting에서 유효성 검사를 제외해야 한다. scikit-learn pipeline을 사용하는 경우 이 것이 더 쉽다.
교차 검증을 사용할 때는 pipeline 내부에서 전처리를 수행하는 것이 훨씬 더 중요하다.
Example
이 예제에는 Target Leakage를 탐지하고 제거하는 방법을 다룬다.
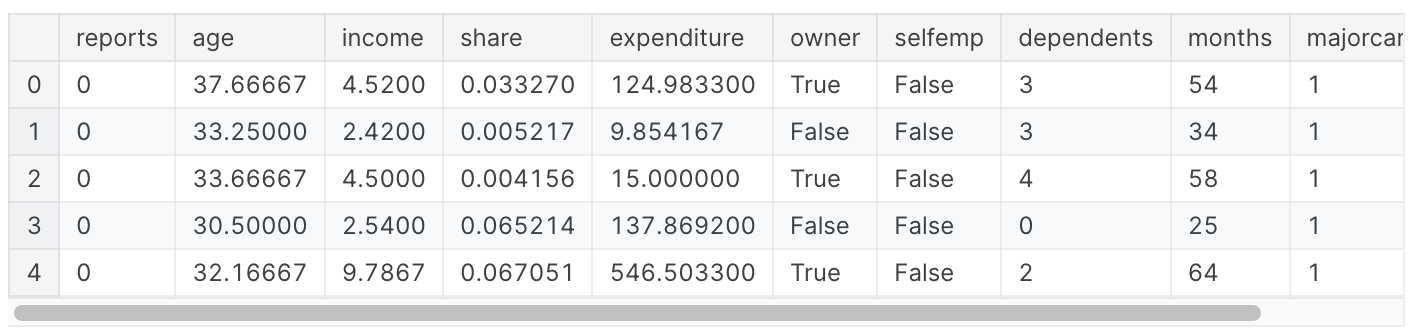
신용카드 신청에 대한 dataset이다. 최종 결과는 각 신용카드 신청에 대한 정보가 DataFrame X에 저장되고, 어떤 신청이 승인되었는지 시리즈 Y에서 예측한다.
import pandas as pd
data = pd.read_csv(filepath)
y = data.card
X = data.drop(['card'], axis=1)
print("Number of rows in the dataset:", X.shape[0])
X.head()
작은 데이터셋이기 때문에, cross-validation으로 모델 품질을 정확하게 측정할 것이다.
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
#전처리 할 것이 아니라 pipeline은 크게 쓰이지 않음
my_pipeline = make_pipeline(RandomForestClassifier(n_estimators=100))
cv_scores = cross_val_score(my_pipeline, X, y,
cv=5,
scoring='accuracy')
print("Cross-validation accuracy: %f" % cv_scores.mean())
경험을 통해 98%의 정확도를 자랑하는 모델은 매우 드물다. 간혹 발생하지만 드물기 때문에 Target Leakage가 있는지 면밀히 검사해야 한다.
다음은 데이터 탭에서도 확인할 수 있는 데이터 요약이다.
card: 신용카드 신청 수락된 경우 1, 아닌 경우 0reports: 주요 비하 신고 건수age: 나이 n에 1년의 12분의 1을 더한 값income: 연간 소득(10,000으로 나눈 값)share: 연간 소득 대비 월별 신용카드 지출 비율expenditure: 월 평균 신용카드 지출액owner: 주택 소유인 경우 1, 임차인인 경우 0selfempl: 자영업자인 경우 1, 그렇지 않은 경우 0dependents: 1 + 부양가족 수months: 현재 주소에서 거주한 개월 수majorcards: 보유한 주요 신용카드 수active: 활성 신용 계정 수
몇 가지 변수가 의심스러워 보인다. 예를 들어, 지출이 이 카드의 지출을 의미할까? 아니면 신청 전에 사용한 카드의 지출을 의미할까?
이 시점에서 기본적인 데이터 비교는 매우 유용할 수 있다.
expenditures_cardholders = X.expenditure[y]
expenditures_noncardholders = X.expenditure[~y]
print('Fraction of those who did not receive a card and had no expenditures: %.2f'
\ %((expenditures_noncardholders == 0).mean()))
print('Fraction of those who received a card and had no expenditures: %.2f'
\ %((expenditures_cardholders == 0).mean()))

위와 같이 카드를 받지 않은 사람은 모두 지출이 없었고, 카드를 받은 사람 중 2%만이 지출이 없었다. 지출은 신청한 카드의 지출을 의미하는 것으로 보인다.
점유율(share)은 부분적으로 지출에 의해 결정되므로 이 역시 제외해야 한다. active 및 majorcards 변수는 조금 덜 명확하지만 설명을 보면 우려스럽다. 대부분의 상황에서 데이터를 생성한 사용자를 추적하여 자세한 내용을 파악할 수 없는 경우 후회하는 것보다 안전한 것이 낫다...고 한다.
다음과 같이 타겟 유출이 없는 모델을 실행한다.
# Leaky predictors를 drop 한다.
potential_leaks = ['expenditure', 'share', 'active', 'majorcards']
X2 = X.drop(potential_leaks, axis=1)
# Leaky predictors를 없앤 것을 evaluate
cv_scores = cross_val_score(my_pipeline, X2, y,
cv=5,
scoring='accuracy')
print("Cross-val accuracy: %f" % cv_scores.mean())
정확도가 낮아서 실망스러울 수 있다. 그러나 새 신청(데이터)에 사용할 경우 80%의 경우 정확도를 기대할 수 있는 반면, 누수 모델은 교차 검증에서 더 높은 점수를 받았음에도 불구하고 그보다 너 나쁠 가능성이 높다.
Conclusion
Data Leakage는 많은 데이터 과학에서 있는 실수이다.
train data와 validation data를 주의 깊게 분리하면 Train-Test contamination을 방지할 수 있으며, Pipeline은 이러한 분리를 구현하는 데 도움이 될 수 있다.
잘 살펴보라는 얘기인 듯 하다..
