Face Recognition

What is face recognition
Face verification vs face recognition
Verification(1:1)
- input image, name/ID
- output whether the input image is that of the claimed person
얼굴 검증 문제는 입력 이미지와 어떤 사람의 이름 또는 ID가 주어지면, 시스템이 그 사람인지를 검증하는 것입니다.
Recognition(1:k)
- Has a database of K persons
- Get an input image
- output ID if the image is any of the K persons(or "not recognized")
만약, 한 사람에 대해 실수할 확률이 1%일 때 DB에 100명이 있으면, 얼굴 인식 은 실수할 확률이 100배가 됨. 즉, 100명의 DB에서 얼굴 인식이 잘 작동하기 위해선 각각의 사람에 대해 맞출 확률이 99%보다 더 높아야 함.
즉, 얼굴 검증 문제보다 얼굴 인식 문제가 더 어렵다!
앞으로 살펴 볼 내용은 구성 요소로서 얼굴 검증 시스템을 만드는 것. 정확도가 충분히 높으면 이를 인식 시스템에 활용할 수 있다.
One shot learning
원샷 학습 문제에선 하나의 예시를 통해서만 사람을 인식해야 함.
(대부분의 얼굴 인식 시스템이 이것이 필요. 보통 DB엔 직원 혹은 팀원의 사진이 하나밖에 없기 때문!)

접근 방법 중 하나는 출력 시 직원과 모르는 사람이라는 클래스를 추가해서 학습시키는 것.
하지만 이는 신경망을 훈련시키기에 충분하지 않기도 하고, 새로운 사람이 입사하게 되면 소프트맥스 유닛을 추가해서 다시 훈련 시켜야 함.
Learning a "similiarity" function
이 방법 대신 유사도 함수를 학습시키는 방법이 있다.
이는 신경망으로 하여금 두 이미지의 유사도를 구하는 함수를 학습시킴.
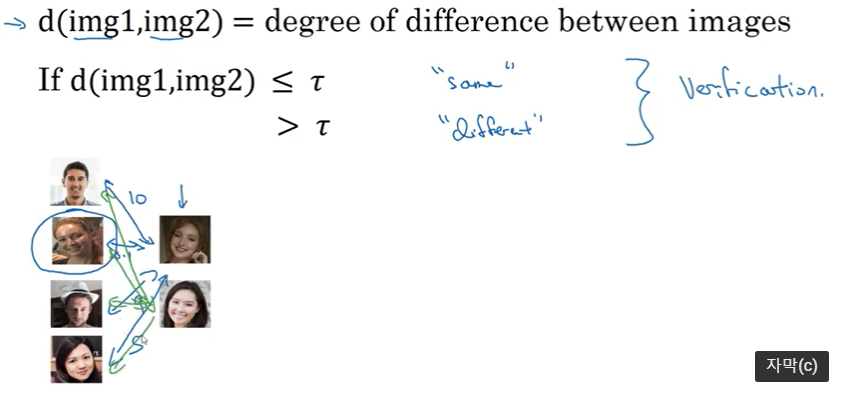
- 유사도 함수 : d(img1, img2) = 두 이미지의 차이
- 어떤 기준치 보다 크면 두 이미지가 서로 많이 다른 것이고, 작으면 비슷한 것
=> 이는 얼굴 검증 문제를 다루는 방식!
이 방식을 활용할 경우, DB에 새로운 사람을 추가해도 그대로 잘 작동한다!
Siamese Network
: 두 개의 입력에 대해 독립적으로 두 개의 합성곱 신경망을 실행한 뒤 비교하는 아이디어
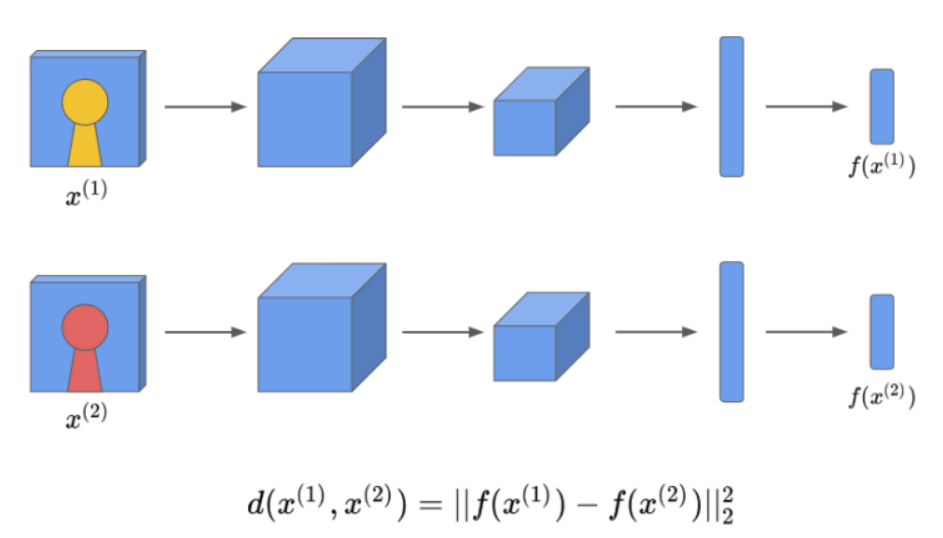
- 하나의 이미지를 신경망에 넣어서 얻은 FC의 결과를 "x1의 인코딩"이라고 하자. 즉, 해당 이미지를 어떤 작은 차원의 벡터로 표현한 것.
- 다른 사진과 비교하기 위해서, 이 이미지의 FC 결과인 "x2의 인코딩"을 구함. 만약 두 인코딩 벡터가 해당 이미지를 잘 표현하고 있다면, 두 벡터 사이의 거리 d를 구할 수 있다.
- 여기서 거리는 두 벡터 사이의 norm으로 정의.
- d(x1, x2) = IIf(x1) - f(x2)II
- 따라서 두 개의 입력에 대해 독립적으로 두 개의 합성곱 신경망을 실행한 뒤, 비교하는 아이디어를 샴 네트워크라고 한다! (두 신경망은 같은 파라미터를 가짐.)
- 샴 네트워크의 학습 방법
- 두 네트워크에 두 사진을 입력으로 넣고, 합성곱 신경망으로 인코딩을 시킴.
- 만약에 두 사람이 비슷한 사람이라면, 인코딩 사이의 거리 값은 작아야 함.
- 만약에 두 사람이 다른 사람이라면, 인코딩 사이의 거리 값은 커야 함.
- 위 조건을 만족시키도록 학습 시킴.
Triplet loss
Learning Objective
삼중항 손실 함수는 항상 하나의 이미지를 기준으로, 같은 사람인 것을 뜻하는 "긍정 이미지"와 다른 사람인 "부정 이미지"의 거리를 구한다. 즉, 한 번에 3개의 이미지를 보게 됨!

- 기준이 되는 이미지를 A, 긍정 이미지를 P, 부정 이미지를 N으로 두자.
우리의 목적은 A와 P와의 거리가 항상 A와 N사이의 거리보다 작거나 같게 만드는 것!
Loss function
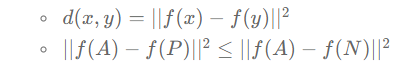
이는 아래와 같이 변형할 수 있음.
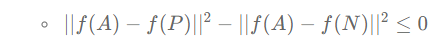
위의 식을 만족하는 자명한 방법 중에 하나는 두 거리가 모두 0이 되는 것. 따라서 신경망이 무조건 0을 반환하지 않게 하기 위해, 신경망으로 하여금 모든 인코딩이 같지 않다는 것을 알려줘야 함.
따라서, 목적 함수를 약간 수정함.
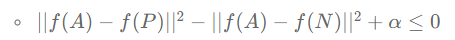
(alpha는 하이퍼파라미터. 마진이라고 불리기도 함. 마진의 역할을 두 거리의 값이 차이가 충분한 거리를 갖게 만드는 것. 왜냐면 A와 P의 거리에 알파를 더한 값보다 A와 N의 거리가 같거나 크게 만드니까!)
단일 손실함수는 아래와 같음.
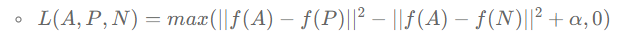
(여기서 max함수의 역할은 거리의 차이값이 얼마나 음수인지는 신경쓰지 않게 하기 위함! => 즉, A와 P와의 거리가 A와 N과의 거리보다 작을 경우엔 신경 쓰지 않음. 맞게 계산된 거니까!)
즉, 이 목적 함수는 A와 P와의 거리가 A와 N과의 거리보다 충분히 작아서(마진만큼), max( ... , 0)을 했을 때 0이 도출되도록 함.
전체 손실 함수는 아래와 같음.
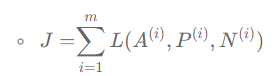
만약 천 명의 사람에 대한 만 개의 이미지 훈련 세트가 있다면 만 개의 사진을 사용해서 삼중항을 만들고, 삼중항에 대해 정의도니 비용 함수에 경사 하강법을 적용해서 신경망을 훈련시켜야 함.
삼중항 데이터셋을 정의하기 위해서 A와 P의 쌍들이 필요함. 같은 사람에 대한 쌍! 따라서 시스템을 훈련시키기 위해서 같은 사람에 대한 많은 이미지의 데이터셋이 필요하다. 그래서, 예시로 천 명의 사람에 대해 만 개의 이미지를 예로 든 것.
이를 적용해서 시스템을 훈련시킨 다음에 얼굴 인식 시스템의 원샷 학습 문제에 적용할 수 있다!
Choosing the triplets A,P,N
어떻게 삼중항을 생성할 수 있을까?
훈련 세트인 A, P, N을 무작위로 고르면 제약식을 쉽게 달성하게 됨. 왜냐면, 무작위로 뽑힌 두 장의 사진에서 확률적으로 A,N이 A,P보다 훨씬 다를 것이기 때문. 즉, d(A,N)이 d(A,P)+alpha보다 클 확률이 높다(N은 A와 다른 사람이니까!).
따라서, 훈련 세트를 만들 때 학습하기 어렵게 만들어야 함.
- d(A,P)가 d(A,N)과 비슷하면 어렵게 만드는 효과를 얻을 수 있음.
- 대부분의 경우에 제약식을 만족하지 않게 훈련 세트를 만드는 것은 경사 하강법이 더 효율적으로 일을 하게 함.
==> 랜덤으로 고르지 말고, A와 유사한 N을 찾아서 삼중항으로 만들자!
Triplet Selection(추가)
참고 : https://deep-learning-study.tistory.com/681, https://omoindrot.github.io/triplet-loss
논문에서는 hard negative, hard positive method를 제안함. 학습하기 어려운 positive와 negative sample을 추출하여 모델이 어려운 환경에서 학습되도록 함. 학습 초기에는 hard example 방법이 모델의 불안정함을 유발하므로 초기에는 all positive sample로 학습을 진행함.
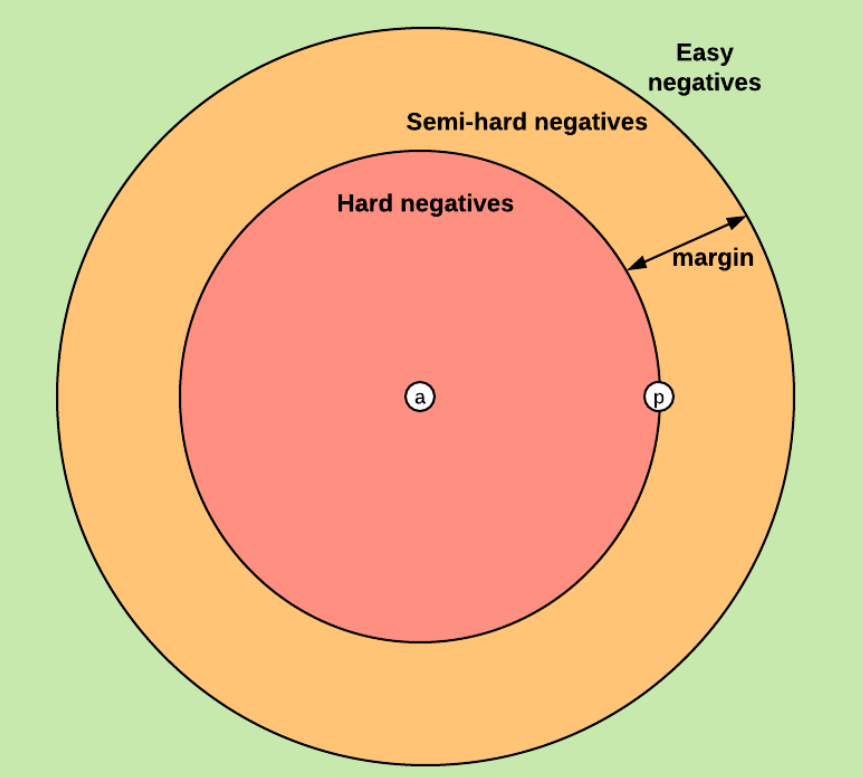
- easy triplets : triplets which have a loss of 0, because d(a,p) + margin < d(a,n)
- hard triplets : triplets where the negative is closer to the anchor than the positive, i.e. d(a,n) < d(a,p)
- semi-hard triplets : triplets where the negative is not closer to the anchor than the positive, but which still have positive loss. i.e. d(a,p) < d(a,n) < d(a,p) + margin
hard positive sample은 다음의 조건을 만족하는 sample을 의미.
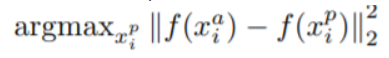
위 수식을 보면, anchor와 positive사이의 embedding거리가 최대인 sample을 의미. 일정 임계점 거리 이상이면 negative로 분류되는데, negative로 분류되기 전까지의 거리가 최대인 sample을 의미
hard negative sample은 다음의 조건을 만족.
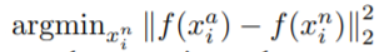
negative sample이 되는 임계점에 가까운 negative sample은 hard negative sample임.
모델이 positive인지 negative인지 판별하기 어려운 sample로 학습한다면 더 좋은 성능을 나타낸다.
즉, mini-batch안에서 가장 큰 d(a,p)과 가장 작은 d(a,n)의 조합을 선택해서 모델을 좀 더 좋게 학습시킬 수 있음.
Face Verification
Learning the similarity functioon
샴 네트워크를 훈련시키는 다른 방법은 인코딩들의 차이를 로지스틱 회귀 유닛에 입력해서 예측을 하면 됨! (같은 사람일 경우 1, 다른 사람일 경우 0)
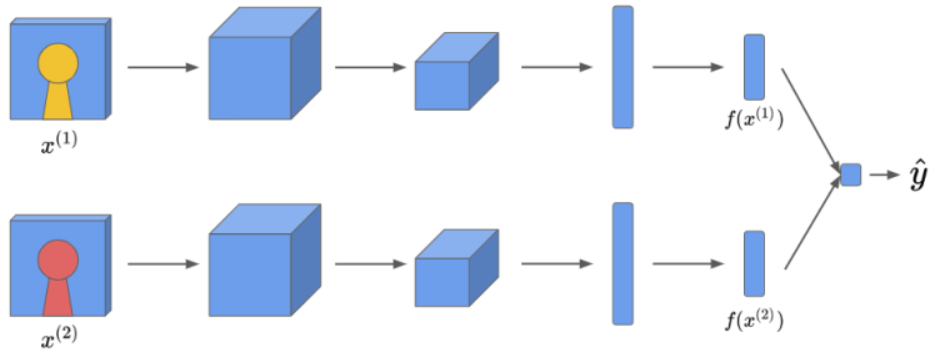
샴 네트워크의 훈련 방법
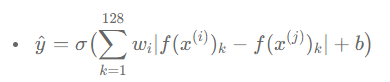
- 로지스틱의 역할은 두 인코딩과의 차를 이용하여 두 이미지가 같은 사람인지 아닌지 판단하는 것. 두 인코딩간의 차이는 여러가지 방식으로 구할 수 있음.(둘의 차를 제곱해서 각각의 합으로 나눌 수도 있음 - 카이 제곱 방식)
- 훈련 세트도 한 쌍의 이미지로 만듦. 같은 사람일 경우 라벨을 1로 지정하고, 다를 경우 0으로 만듭니다.

=> 이렇게 이진 분류로 학습을 할 경우, DB에 있는 이미지는 미리 임베딩 값을 계산하고, 새로운 이미지에 대해서만 인코딩 값을 계산해 미리 계산된 인코딩과 비교.
만약 직원 DB가 아주 큰 경우 모든 직원에 대해 매번 인코딩을 계산할 필요가 없으므로, 계산량을 상당히 줄일 수 있다.
(이 방식은 위와 같은 샴 신경망과 삼중항 손실 함수를 사용하여 인코딩을 학습하는 경우 모두 적용 가능.)

3개의 댓글

안녕하세요 16기 김경준입니다.
- Face Recognition이란 N명의 사람 중 어떤 사람의 얼굴인지 인식하는 알고리즘으로 여러 사람이 있기 때문에 검증보다 어렵다.
- 회사에서 Face ID를 사용한다고 할 때 DB에는 사원의 사진이 하나 밖에 없는 경우가 많으므로 One shot learning이 효과적이다.
- 외부인에 대한 클래스를 추가하여 학습시킬 수 있으나 훈련시키기에 데이터셋이 충분하지 않으며, 새로운 사람이 입사할 때마다 softmax의 유닛을 추가하여 재학습시켜야 한다는 단점이 있다.
- 따라서, 두 이미지의 차이를 나타내는 유사도 함수를 이용하며 대표적인 모델로 Siamese Network가 있다.
- Siamese Network에서는 두 개의 이미지를 공유하는 CNN을 거쳐 특징 벡터를 뽑은 뒤 벡터 사이의 거리를 비교하여 학습시킨다.
- Triplet loss에는 Anchor, Positive, Negative가 존재하여 Anchor 이미지가 Positive 이미지와의 거리는 최소가 되게, Negative 이미지와의 거리는 최대가 되게 학습한다.

15기 이윤정입니다.
- Face Verification은 입력 이미지와 어떤 사람의 ID가 주어지면, 시스템이 그 사람 인지 검증하는 것이며 (1:1), Face Recognition은 이미지가 주어지면 해당 사람의 ID를 도출하는 task이다. (1:k)
- One shot learning은 하나의 예시를 통해 사람을 인식하므로, 신경망을 훈련시키기에 충분하지 않으며 새로운 사람이 들어오면 다시 훈련 시켜야 한다.
- 이를 보완하기 위해 유사도 함수를 통해 두 이미지의 차이를 계산하는 방식을 적용할 수 있다.
- Siamese Network는 두 개의 입력에 대해 독립적으로 두 개의 합성곱 신경망을 실행한 뒤 비교하는 방식으로 두 신경망은 같은 파라미터를 가진다.
- Triplet loss는 하나의 이미지를 기준으로 긍정 이미지 (같은 사람)와 부정 이미지 (다른 사람)의 거리를 구한다. (즉, 3개의 이미지를 보게 됨)
투빅스 16기 박한나입니다.