본 게시글에 첨부한 이미지는 논문에서 발췌하였거나, 출처를 표기하였습니다.
0. Image-to-Image Translation
Image-to-Image Translation
- 이미지를 입력으로 받아 또다른 이미지로 변환하는 과정을 Translation이라고 합니다.
- Image-to-Image Translation은 Input 이미지와 Output 이미지 간 Mapping을 목표로 하는 생성모델의 한 분야입니다.
(이미지 간 도메인 변화를 다루는 분야)
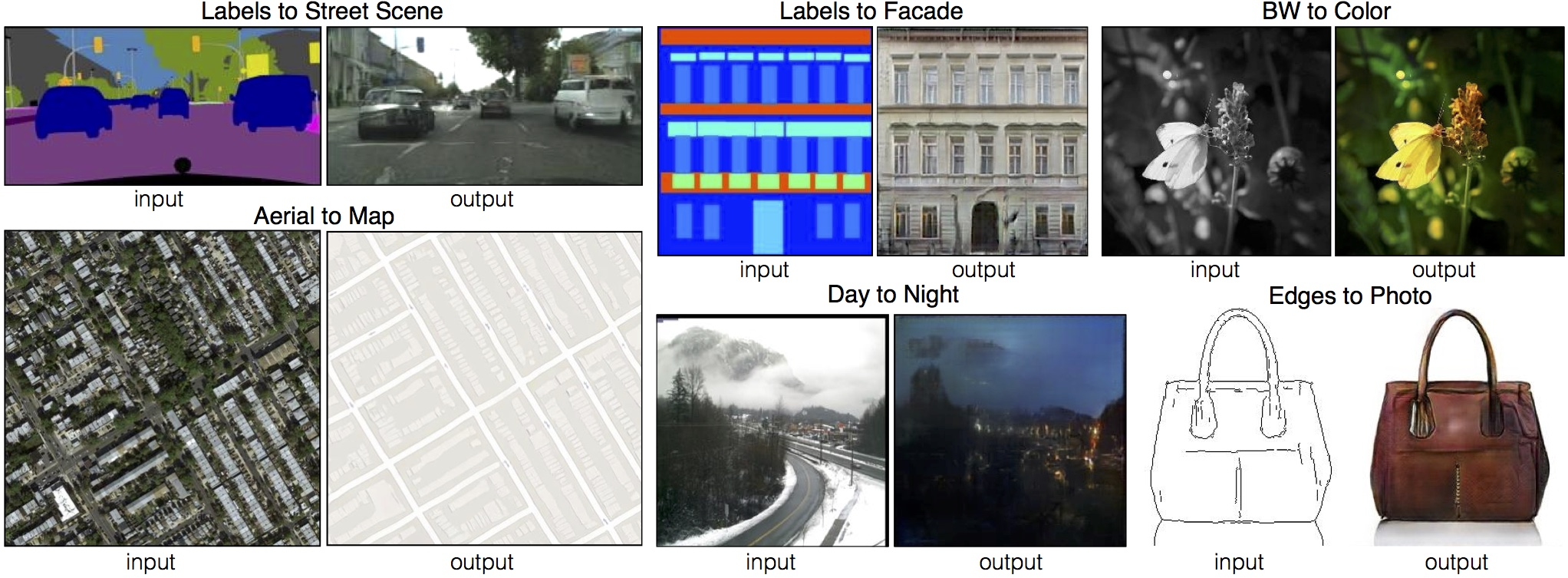
Examples
1. pix2pix
Introduction
Image Prediction 문제는 주로 Convolutional Neural Nets (이하 'CNN')를 활용하여 처리되어 왔습니다.
CNN에서는 minimize하고자 하는 Loss function을 직접 정의해주어야 합니다. 그런데, 최적의 Loss function을 정의하기 어려울 수 있고, naive하게 정의한다면 blurring 등의 문제가 발생할 수 있습니다.
- ex) predicted pixels(예측값)와 ground truth pixels(Target, 실제값) 간 Euclidean distance를 최소화하는 방식으로 Loss function을 정의하는 경우
이러한 문제점을 해결한 모델이 바로 Generative Adversarial Networks (이하 'GAN')입니다. GAN의 생성자는 판별자가 생성 이미지와 실제 이미지를 잘 구분하지 못하는 방향으로, 판별자는 생성 이미지와 실제 이미지를 제대로 구분하는 방향으로 경쟁적으로 학습됩니다.
GAN에서 blurry한 image는 가짜로 판별되며, 데이터에 적합하게 Loss가 학습되기 때문에 여러 종류의 task에 적용할 수 있습니다.
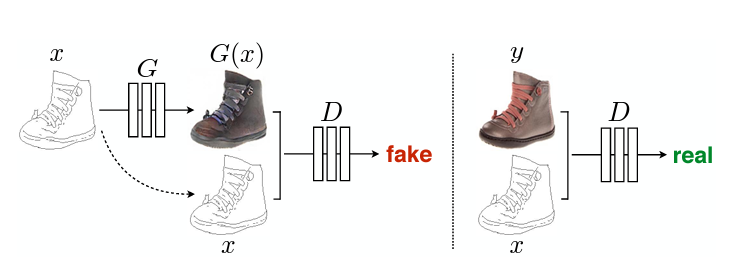
본 논문에서는 Image-to-Image Translation에 적합한 conditional GANs (이하 'cGAN')을 이용하여 광범위한 task에서 좋은 결과를 낼 수 있는 프레임워크인 pix2pix를 소개합니다.
Method
Objective
Notation
- : Generator
- : Discriminator
- : observed image (input image)
- : random noise vector
- : output image
cGAN의 Objective(이하 'Loss function')는 아래 식으로 표현됩니다.
cGAN의 목표는 아래의 adversarial loss를 최소화하는 것이며, 이때 는 minimize하는 방향, 는 maximize하는 방향입니다.
이때, 위의 loss만을 단일하게 사용하는 것보다는, L1 Distance나 L2 Distance와 같은 traditional loss를 Loss function에 추가함으로써 덜 blurry한 이미지를 생성할 수 있습니다.
L2 Distance보다는 L1 Distance(Manhattan Distance)를 추가했을 때 생성된 이미지의 품질이 더 좋다고 검증되어, 최종 Loss function은 아래와 같이 정의합니다.
- L1 Distance :
- Final Loss function :
(이때, 는 hyper parameter로, 이 를 조정함으로써 최적의 Loss function을 찾아나가게 됩니다.)
pix2pix의 Noise
Random noise vector 가 없는 경우에도 생성모델은 에서 로의 mapping을 학습할 수 있지만, 이 경우 출력이 deterministic하다는 문제점이 있습니다. (하나의 입력에 대해서 하나의 출력이 존재)
이러한 문제를 해결하고자 과거 GAN은 를 와 함께 입력했습니다.
그런데 본 논문의 실험에서는 입력된 noise가 무시되면서 학습되는 현상이 일어났고, 이를 효과적으로 해결할 strategy 또한 찾을 수 없었다고 합니다.
그래서 pix2pix는 오직 dropout의 형태로 noise를 주었고, 이 방식을 학습 시점과 테스트 시점에 모두 채택했습니다.
Network architectures - (1) Generator
Generator로는 Encoder-Decoder에 skip connections가 추가된 U-Net을 사용합니다.
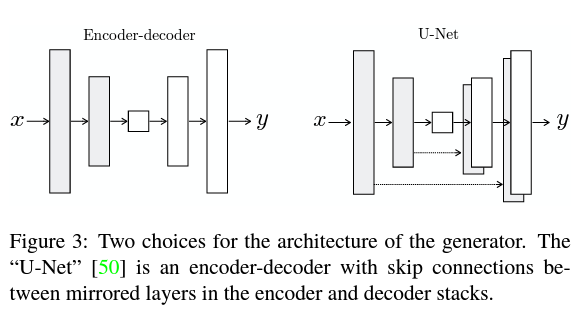
기존 Encoder-decoder는 input이 일련의 layer들을 통과하면서 점차 downsampling 되고, bottleneck layer를 기준으로 다시 반대 과정을 거치는 구조입니다.
Layer들을 통과하면서 입력된 이미지의 핵심적인 feature들은 추출되지만, low-level(detail)에 관해서는 정보 손실이 발생할 수 있습니다.
따라서, U-Net은 skip connections를 추가하여 detail이 전달될 수 있도록 했습니다.
- 총 layer 개수가 일 때,
- 번째 layer와 번째 layer에 있는 모든 channel을 concatenate함으로써 마지막까지 detail이 잘 전달됩니다.
U-Net Structure
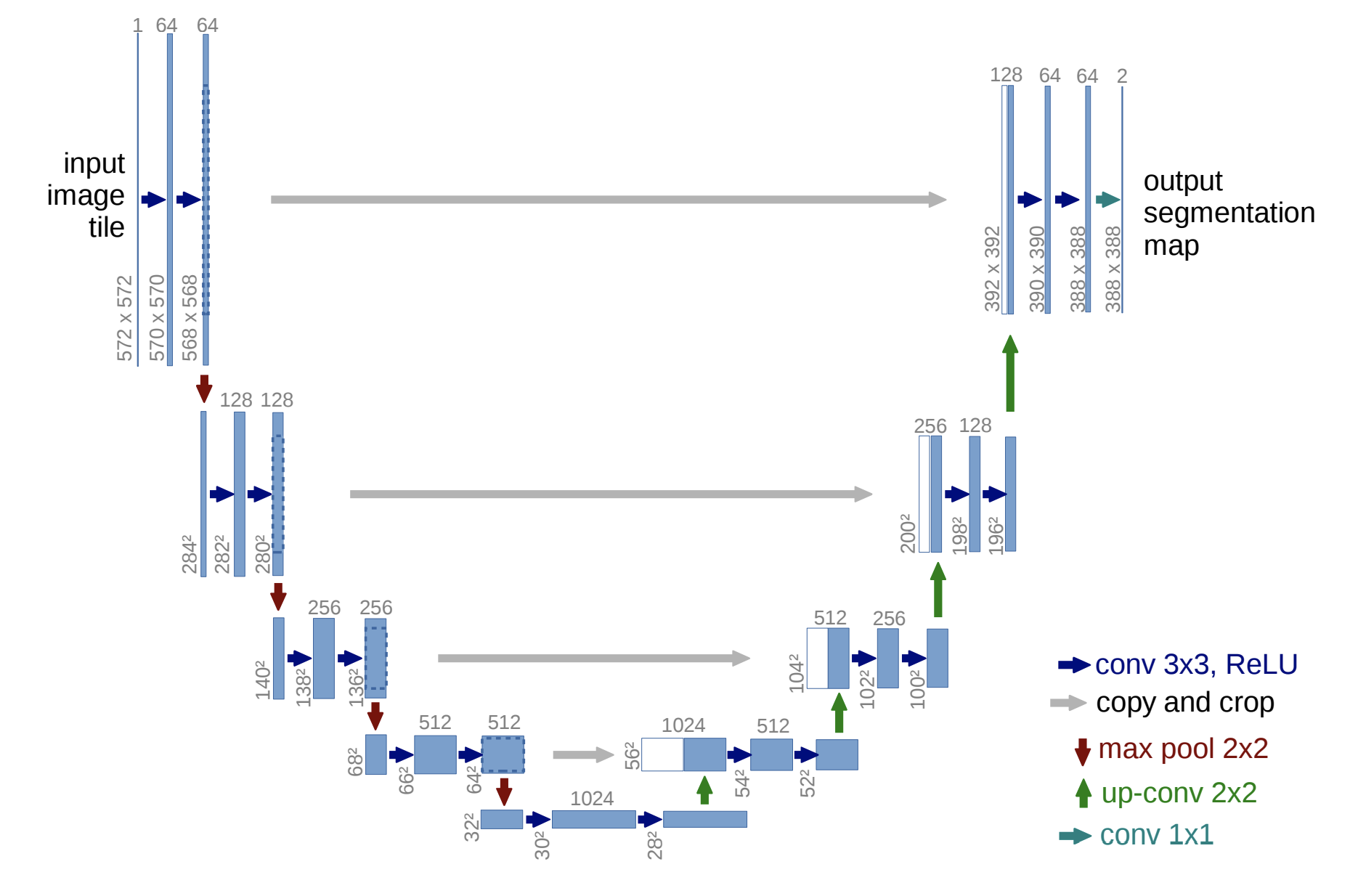
이미지 출처 : U-Net 논문 리뷰 — U-Net: Convolutional Networks for Biomedical Image Segmentation (https://medium.com/@msmapark2/u-net-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-u-net-convolutional-networks-for-biomedical-image-segmentation-456d6901b28a)
아래는 Cityscape generation에 대하여 Encoder-decoder와 U-Net을 비교한 결과입니다.
L1 loss만을 이용한 경우(왼쪽)와 L1 loss와 cGAN loss를 섞은 loss를 이용한 경우(오른쪽) 모두 U-Net이 더욱 realistic한 이미지를 생성해내고 있습니다.

Network architectures - (2) Discriminator
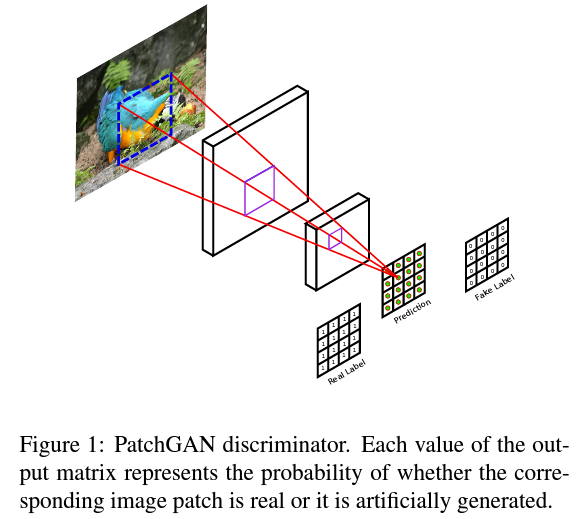
Discriminator로는 PatchGAN을 사용합니다.

위 Figure는 서로 다른 loss로 학습된 결과입니다.
L1 loss를 이용하는 경우, blurry하기는 하지만 low-frequency 성분들을 비교적 잘 검출해냅니다.
따라서, low-frequency 성분 검출을 위해 L1 loss는 그대로 두고, Discriminator는 high-frequency structure만을 이용해 모델링합니다.
이때 high-frequency 성분 검출은 전체 이미지가 아닌 local image patch를 이용해도 충분하다고 합니다.
PatchGAN Discriminator
- 이미지를 X으로 조각내어 각 patch별 response 값(real인지 fake인지에 대한 확률값)을 평균하여 최종 결과값 를 산출합니다.
- 적은 수의 Parameter로 빠르게 훌륭한 결과를 낼 수 있습니다. 또 임의의 큰 사이즈의 이미지에도 적용할 수 있습니다.
이미지 출처 : Patch-Based Image Inpainting with Generative Adversarial Networks
Experiments
cGAN의 generality를 테스트하기 위해, 본 논문에서는 다양한 task와 데이터셋에 cGAN을 적용한 실험들을 소개하고 있습니다.







대체로 좋은 성능을 보이고 있으나, 맨 하단(failure cases)과 같이 input image가 sparse하거나 unusual한 경우에는 이상하거나 blurry한 이미지가 생성되기도 했습니다.
2. CycleGAN
Introduction
위에서 소개한 pix2pix 모델의 경우, image pairs로 학습이 진행되었습니다. 하지만 일반적으로 paired training data(=Supervised setting) 구하기 어렵고 비용도 많이 듭니다.
Paired data vs Unpaired data
Paired data(왼쪽)는 와 간 대응 관계가 존재하는 반면,
Unpaired data(오른쪽)는 어떤 가 어느 와 대응되는지에 대한 정보가 없습니다.
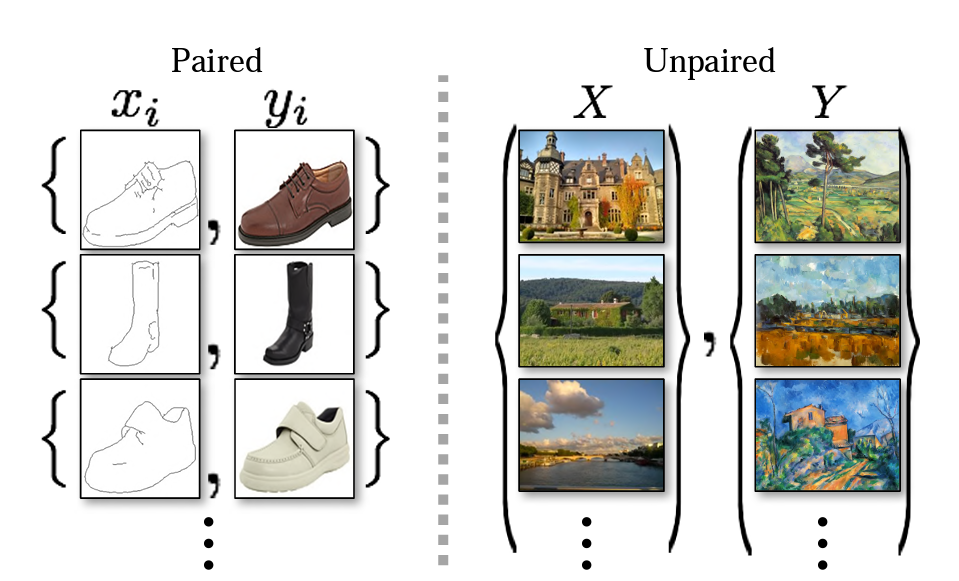
따라서, 본 논문에서는 paired input-output이 없어도 translation을 수행할 수 있는 알고리즘을 찾고자 합니다.
즉, 서로 다른 domain (source domain)와 (target domain)의 image set이 주어졌을 때, 에서 로의 mapping인 를 학습하는 방법을 다룹니다.
- : →
Formulation
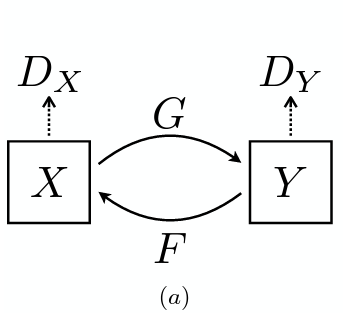
CycleGAN은 두 개의 mapping(GAN)으로 이루어져 있습니다.
- : → & Discriminator
- : → & Discriminator
는 와 translated image 를 판별하고, 는 와 translated image 를 판별합니다.
Adversarial Loss
두 개의 mapping에 모두 adversarial loss를 적용합니다.
: → & Discriminator 에 대한 loss는 아래와 같습니다.
- 는 위의 loss를 minimize, 는 maximize하고자 합니다. →
: → & Discriminator 에 대한 loss()도 같은 방식으로 정의됩니다.
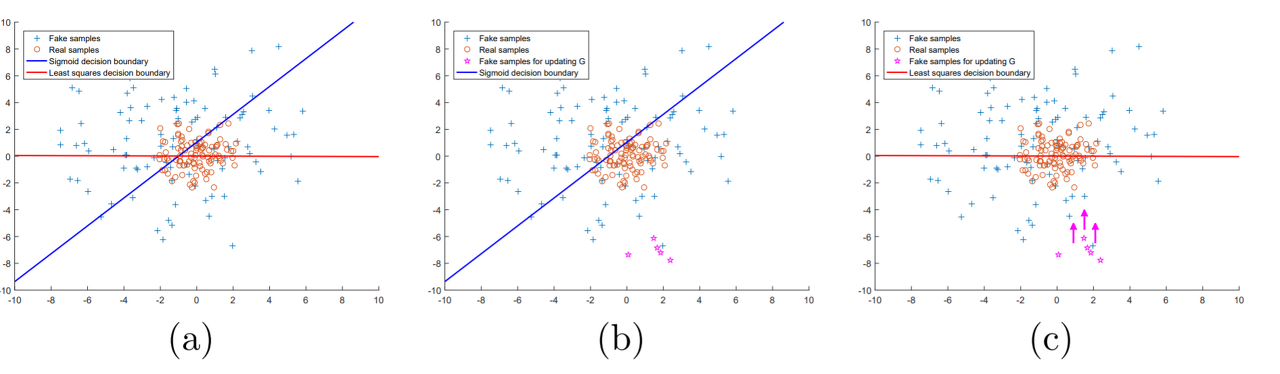
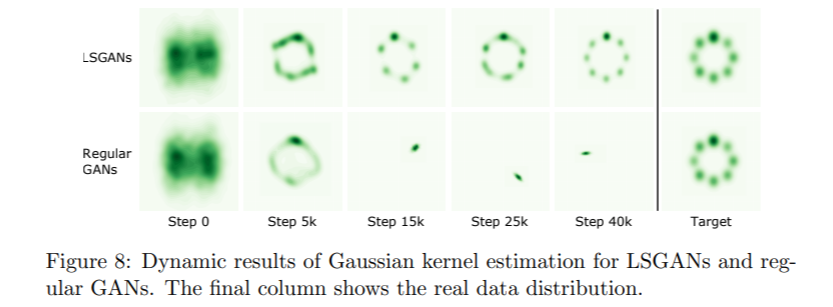
왜 Least Squares Loss를 쓸까?
- GAN보다 높은 품질(high quality)의 이미지를 생성할 수 있고,
- 학습 과정 안정화에 도움이 됩니다. (vanishing gradients 문제 해결)
출처 : [논문 리뷰] LSGAN (Least Squares Generative Adversarial Networks)
Cycle Consistency Loss
Adversarial loss만을 이용하는 경우, Mode collapse 문제(input에 관계없이 동일한 output으로 mapping, 최적화 실패)가 발생할 수 있습니다.
따라서 위의 loss에 cycle consistency loss를 추가함으로써 loss function을 보완할 수 있습니다.
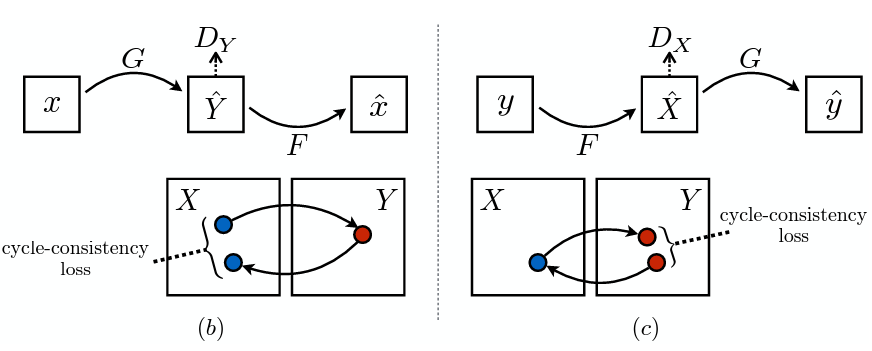
Possible mapping function의 space를 줄이기 위해, 위의 (b), (c)와 같이 mapping function은 cycle-consistent해야 합니다.
-
(b) : forward cycle consistency ▶
-
(c) : backward cycle consistency ▶
-
아래에서 cycle consistency loss를 도입했을 경우 재건된 이미지 가 입력 이미지 와 비교적 유사함을 확인할 수 있습니다.
(참고로, 예비 실험에서 L1 loss를 도입해본 결과, 성능 향상은 관찰되지 않았다고 합니다.)

Full Objective
완성된 Loss function은 아래와 같습니다.
- Final Loss function :
이때 는 첫 번째 term()과 두 번째 term()의 상대적 중요도(relative importance)에 따라 결정됩니다.
우리의 목표는 를 최적화하는 와 를 구하는 것입니다.
Results
이제는 위에서 정의한 full objective를 adversarial loss만 사용할 때, cycle consistency loss만 사용할 때와 비교합니다.
그리고 경험적으로 두 objective 모두 중요한 역할을 하고 있다는 것을 밝힙니다.
- Evaluation Metrics : AMT perceptual studies, FCNscore, Semantic segmentation metrics
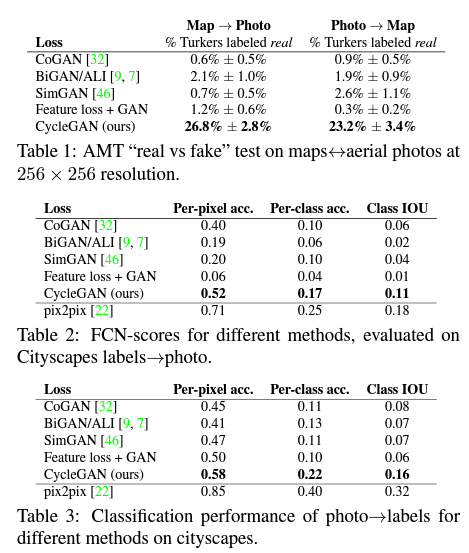
- Ablation Study : Loss function을 다양하게 바꾸어가며 실험 진행

Limitations and Discussion
CycleGAN은 다양한 task에서 우수한 성능을 낼 수 있지만, 아래(failure cases)와 같은 한계가 존재합니다.
- Gemetric changes : Little successes... 😥
예를 들어, 사과를 오렌지로, 개를 고양이로 translate하는 task에서 미미한 변화만 있었을 뿐 모양을 변화시키지는 못했습니다. - 학습 데이터셋의 분포 문제 : 예를 들어, 말에 탄 사람을 얼룩말에 탄 사람으로 translate하는 task에서 사람에게까지 얼룩이 생성된 것은 학습 데이터셋에 '말에 탄 사람' 이미지가 없었기 때문입니다.

Reference
투빅스 13기 & 14기 생성모델 세미나 - Image to Image Translation (pix2pix, CycleGAN)
pix2pix
[논문] https://arxiv.org/pdf/1611.07004.pdf
[pix2pix 논문리뷰] https://sensibilityit.tistory.com/515
[pix2pix 논문리뷰] http://www.navisphere.net/5932/image-to-image-translation-with-conditional-adversarial-networks/
[U-Net 논문리뷰] https://medium.com/@msmapark2/u-net-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-u-net-convolutional-networks-for-biomedical-image-segmentation-456d6901b28a
[patchGAN 관련] https://brstar96.github.io/mldlstudy/what-is-patchgan-D/
CycleGAN
[논문] https://arxiv.org/pdf/1703.10593.pdf
☆ Finding connections among images using CycleGAN
[CycleGAN 논문리뷰] https://comlini8-8.tistory.com/9
[Least Squares Loss 관련] https://www.coursera.org/lecture/apply-generative-adversarial-networks-gans/cyclegan-least-squares-loss-aEI89

강의 잘 들었습니다 !
pix2pix
CycleGAN