0. Intro
2018년까지 GAN이 가진 근본적인 문제는 불안정한 학습과 긴 학습 시간이었다. 이 두 문제는 GAN이 고해상도의 이미지를 생성하는 것을 힘들게 만들었다. 128*128 짜리 이미지를 만드는 모델 학습에도 긴 시간이 소요되고, 학습 안정화를 위해 이것저것 신경써야 하는데, 해상도를 더 높이고자 conv 레이어를 더 넣으면 파라미터가 늘어나기 때문이다.
0-1. PGGAN
그래서 고해상도 이미지를 생성할 수 있는 PGGAN이 발표되었다.
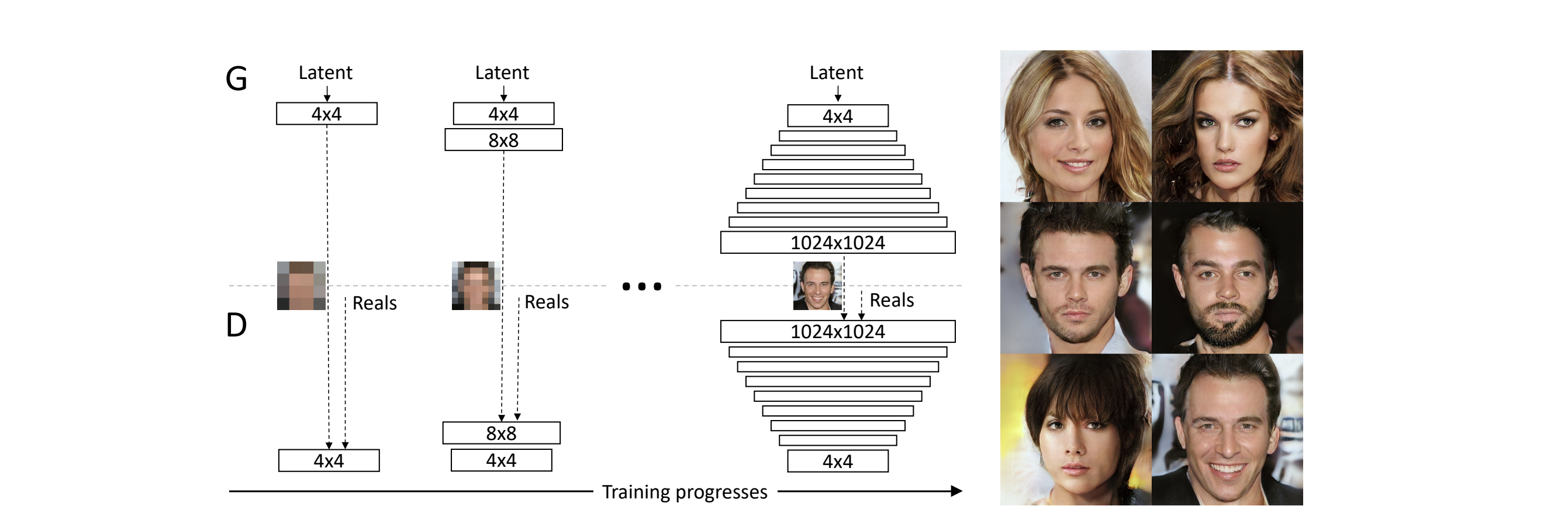
PGGAN은 위의 도표처럼 모델이 구성되어 있다. 일반적인 DCGAN의 경우 conv 레이어를 연속적으로 쌓아서 각 레이어마다 출력되는 이미지의 크기를 키우기만 한다. 하지만 PGGAN은 각 레이어는 이전 레이어에서 생성한 작은 이미지를 참고하여 더 큰 이미지를 생성한다.
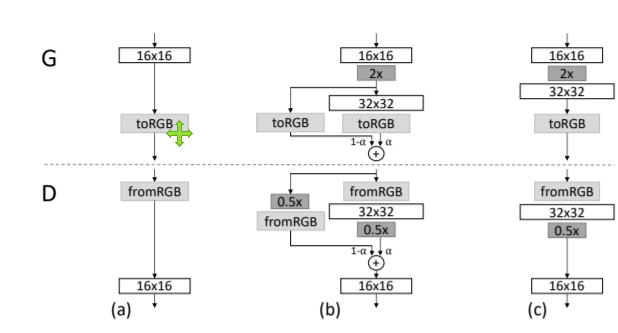
이를 자세히 살펴보면 위 그림과 같은데, 이전 레이어에서 32x32 크기의 이미지가 나온다고 하면, 32x32의 이미지를 upscaling하여 64x64의 이미지로 만든다. 그리고 32x32의 이미지는 다음 conv 레이어로 들어가서 64x64의 이미지로 만들어진다. 그러면 upscaling된 이미지와 conv 레이어를 통과한 이미지가 동일한 크기를 가지게 된다. 이 두 이미지를 와 의 비율로 element wise하게 더해주어 최종적인 해당 레이어의 이미지 출력을 만들게 된다.
이는 resnet block과 비슷한데, 이미지 해상도를 높이는 과정에서 단순히 upscaling하는 것에서 어떠한 부분을 수정해야 하는지 자연스럽게 해상도를 높일 수 있는지 conv 레이어가 관여하고 있는 것이다.
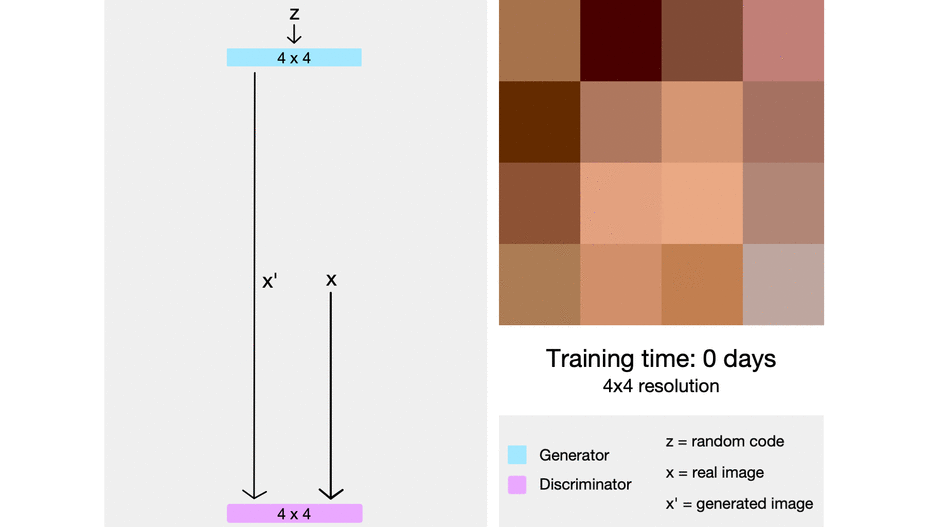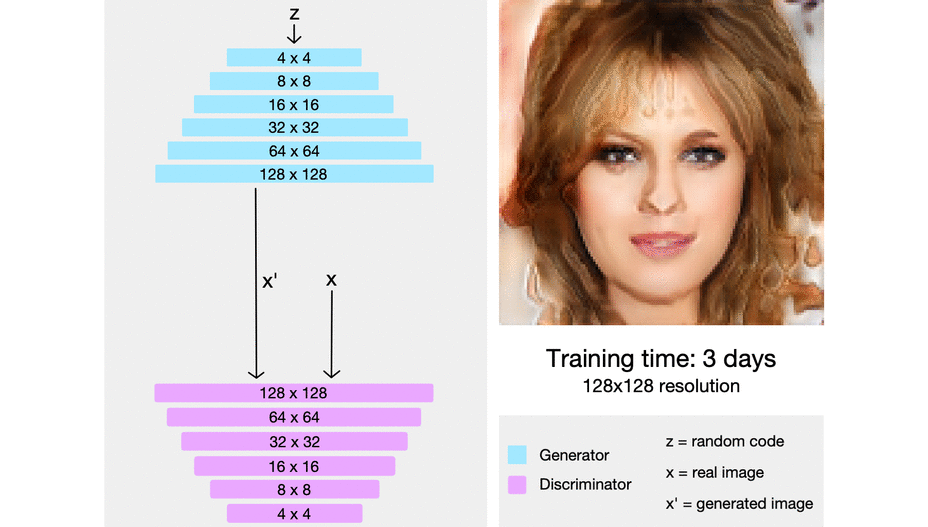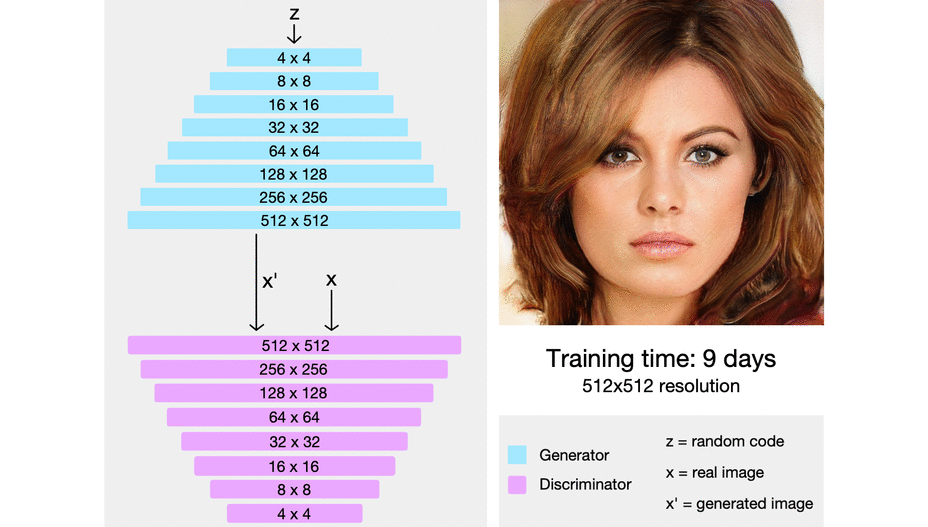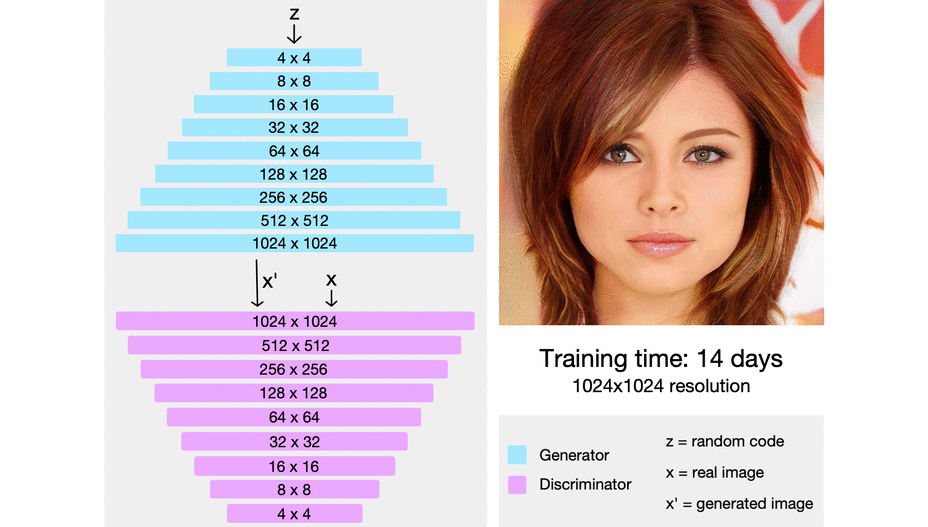
이를 시각적으로 살펴보면 위와 같은데, 점차적으로 해상도가 나아진 이미지가 생성되는 모습을 볼 수 있다. 이 모델에서 주목할 점은 해상도가 낮은 레이어는 이미지의 전반적인 요소(배경, 피부색, 머리카락 색 등)를 결정하게 되고, 해상도가 높은 레이어는 디테일한 요소(주름, 머릿결, 눈꼬리, 콧볼)을 결정하게 된다. 즉 레이어마다 맡은 역할이 달라지게 된다.
1. StyleGan
이제 높은 해상도의 이미지를 만들 수 있었지만, 여전히 StyleGan의 저자들은 만족할 수 없었던 것 같다. 무엇보다 생성 모델을 조절하고 싶어한 것 같다. PGGAN이나 DCGAN 모두 결국 z 벡터에서 이미지를 생성해내는 모델인데, 우리는 여전히 z 벡터에 대해 미궁에 쌓여 있었다. 어떤 값을 어떻게 바꿔야 흑인이 백인이 되고, 안경을 낀 사람이 선글라스를 끼게 되는지 알지 못했다. 그래서 StyleGan은 생성된 이미지를 조절하고자 노력한 논문이라고 할 수 있다.
여기서 entanglement와 distanglement에 대한 간략한 이해가 필요하다.
- entanglement : feature들이 서로 얽혀 있는 상태. 즉, latent space 가 entangle되어 있다면 에서 조금 움직여도 여러 요소가 한번에 변하게 되어 사용자 입장에서 어떤 방향으로 움직일 때 이미지가 어떻게 변하는지 알 수 없음.
- distanglement : feature들이 서로 분리되어 있는 상태. 즉, latent space 가 distangle되어 있다면 에서 조금 움직였을 때 방향에 따라 이미지에서 변하는 요소가 달라진다. 첫번째 축에서 움직이면 안경이 생겼다가 사라지고, 두번째 축에서 움직이면 동양인에서 흑인이 되었다가 백인이 되는 식으로 사용자가 이미지를 조절할 수 있다.
생성모델의 직접적인 입력값은 상수입니다. (매우특이)
1-1. Architecture
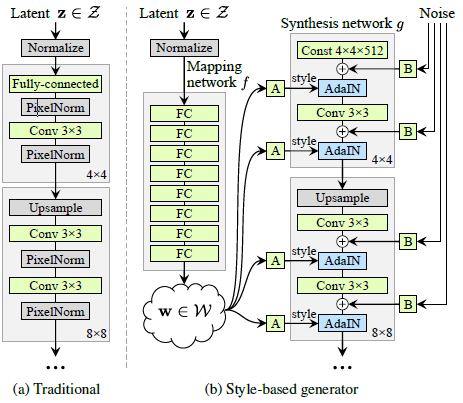
이전에 설명한 PGGAN의 구조는 오른쪽(a)에 나와 있듯이 z 벡터에서 직접 이미지를 생성한다. 하지만 이렇게 되면 생성 모델은 에서 다양한 feature를 복합적으로 생성하기 때문에 가 entangle되어 있는 상태로 모델이 만들어지게 됩니다.
그래서 StyleGan은 entangle한 을 풀어서 입력 벡터를 만들고, 이를 모델에 입력하기로 합니다. 그 결과 만들어진 StyleGan의 전체 구조는 오른쪽 그림(b)와 같습니다.
StyleGan의 요소들은 다음과 같습니다.
- Mapping network
- Synthesis network
- Noise
하나씩 살펴보도록 하겠습니다.
1-1-1. Mapping Network
맵핑 네트워크의 역할에 대해선 이미 설명했습니다. entangle한 를 풀어서 distangle하게 이미지를 생성할 수 있는 공간인 를 생성합니다.
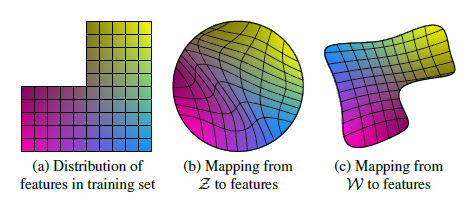
예를 들어서 위 그림의 왼쪽(a)과 같이 실제 이미지의 분포가 구성되어 있다고 해봅시다. 만약 에서 이미지를 생성하는 기존의 GAN 모델들을 들여다보면 에서 실제 이미지의 분포로 맵핑하기 위해 위와 같이 왜곡된 공간을 가지고 있을 것입니다. 즉, b의 공간에서 살짝 움직여도 실제 이미지 분포에선 무척 크게 이동한 결과가 나타날 수 있습니다. 흑인 할아버지가 안경을 끼고 있던 이미지가 백인의 파란 눈의 아이가 웃고 있는 사진이 될 수 있는 거죠.
하지만 우리가 원하는 것은 이미지가 서서히 변하는 것을 원하는 겁니다. 맵핑 네트워크 를 이용해서 에서 로 맵핑한 공간에서 이미지를 생성하게 되면, 는 distangle한 공간을 생성하도록 를 맵핑하는 방향으로 학습됩니다. 그 과정은 아래에서 살펴보도록 하고, 이렇게 맵핑된 공간 에서는 조금 움직이게 되면 실제 분포와 유사한 분포를 가질 수 있게 되어 이미지도 조금 변화하게 됩니다. 흑인 할아버지가 안경을 끼고 있던 이미지가 흑인 할아버지가 안경을 벗은 이미지가 될 수 있는 것이죠.
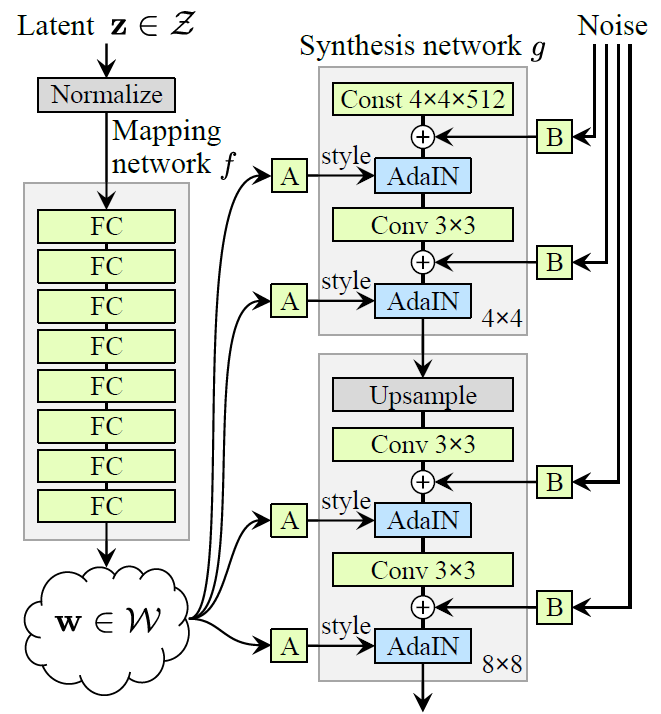
이렇게 새로 생겨난 공간 의 벡터 w는 이제 생성 모델 의 각 레이어마다 style로서 삽입되게 됩니다.
1-1-2. AdaIn
style이 생성 네트워크에 삽입되는 방식은 정규화를 이용하게 됩니다.
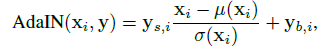
여기서 벡터 형태였던 style은 아핀 변환되어 생성한 두 스칼라 로 변하게 됩니다. 는 conv 레이어 사이의 각 이미지의 픽셀값들입니다. 와 는 channel wise하게 계산됩니다. 정규화 방식을 통해 style이 삽입되는 이유는 다음과 같습니다.
-
학습 안정화 : 레이어가 깊어지게 되면 covariacne shift가 발생하여 학습이 불안정해집니다. 이는 학습 과정에서 초기 레이어의 파라미터 변화로 출력되는 분포가 달라져서 학습이 불안정해지는 것을 의미합니다. 이를 방지하고자 Batch Normalization이나 파생된 여러 정규화 방법론을 사용하게 됩니다. StyleGan에서는 이를 style을 이용해 정규화했습니다.
-
다양한 스타일 학습 : 정규화는 매 레이어마다 들어갑니다. 즉, style 역시 매 레이어마다 들어가게 됩니다. 만약 레이어마다 다른 style을 삽입한다면 더 정교하게 이미지를 조작할 수 있게 됩니다. 이에 관해서는 아래에서 자세히 다루겠습니다.
1-1-3. Noise Input
StyleGan은 특이하게도 입력값으로 style 외에도 노이즈를 받고 있습니다. 이 노이즈는 가우시안 분포에서 추출되는 2차원 이미지 형태를 가지고 있습니다. 이 이미지가 각 레이어에서 생성하는 이미지 크기에 맞게 upscailng되어 형태를 맞춰주어 본래 이미지에 더해주게 됩니다. 예를 들어 가장 위에서 삽입되는 노이즈는 이미지와 동일한 4x4x512의 shape을 가지고 있게 됩니다.
이를 통해 기대할 수 있는 효과는 다음과 같이 두가지입니다.
Stochastic variation
노이즈는 각 픽셀마다 개별적인 값이 입력됩니다. 이를 통해 아주 미세한 변화들을 표현하는 역할을 해내게 됩니다. 이미지를 생성할 때, 자연스럽기 위해서는 불규칙한 변화들이 필요합니다. 예를 들면 머릿결은 동일한 인물조차도 사진마다 다르게 표현될 것입니다. 노이즈는 픽셀마다 입력되기 때문에 이러한 변화를 표현하기에 적절합니다.

그 결과 위와 같은 이미지를 얻을 수 있었다고 합니다. 노이즈 외의 요소를 고정하여 왼쪽과 같이 아기 사진과 교수님처럼 생긴 아저씨 사진을 생성해냈다고 합시다. 이때 노이즈가 픽셀마다 미세하게 영향을 주어 매번 다른 머릿결을 표현해내고 있는 모습을 보이고 있습니다.
이를 100번 반복하여 이미지에서 표준편차를 시각화하면 오른쪽 그림과 같습니다. 즉, 노이즈에 의해 많이 변화한 부분이 밝게 표시되고 있습니다. 머릿결, 주름, 옷깃의 그림자, 스카프의 문양 등 전반적인 형태를 유지하면서 불규칙한 변화들이 필요한 부분이 변화한 모습입니다.
Separation of global effects from stochasticity
노이즈는 각 픽셀마다 개별적인 값이 입력된다고 했습니다. 이는 style의 역할을 더욱 강화해줄 수 있습니다. style은 동일한 값이 전체 이미지에 적용됩니다. 즉, style은 이미지의 전체적인 형태를 정하게 되고, 노이즈가 불규칙한 변화를 정하도록 만드는 것입니다. 사용자가 의도하는 변화(인종, 나이, 악세서리)는 style을 통해 조절하고, 사용자가 세밀하게 조절할 필요가 없는 변화(머릿결, 주름, 패턴)는 노이즈가 조절하게 됩니다. 이러한 일을 모델이 내부적으로 학습한다는게 놀랍습니다.
1-1-4. Synthesis Network
생성모델 자체는 PGGAN과 거의 동일하게 됩니다. 이전 레이어의 출력 이미지를 받아서 1) upsampling하고 2) 노이즈를 pixel wise하게 더하고 3) style을 이용해 AdaIN을 하고 4) 이미지 크기를 유지하면서 conv 레이어를 통과하면 됩니다.
이 과정을 PGGAN과 연결시켜 이해해보자면 다음과 같을 것입니다.
- 이미지는 레이어를 통과하면서 해상도를 높인다.
- 노이즈를 더해주어 불규칙한 변화를 표현한다.
- 어떠한 style에 맞춘 이미지를 생성하기 위해 각 conv를 통과할 때마다 AdaIN 정규화를 거친다.
1-2. 단계별 조정
이때 노이즈나 style이 레이어마다 삽입되는데 PGGAN을 좀더 생각해볼 필요가 있습니다.
PGGAN에선 초기 레이어는 이미지의 전반적인 요소를 결정하고, 후기 레이어는 이미지의 디테일한 요소를 결정한다고 했습니다. StyleGan도 그럴까요? 정답은 그렇다. 입니다. 초기 레이어에 삽입된 style은 이미지에 큰 변화를 불러오고, 후기 레이어에 삽입된 style은 세밀한 변화를 일으키게 됩니다. 아래 동영상을 보시죠.

위 동영상에서 coarse style에 해당하는 style은 초기 레이어인 4x4 ~ 8x8 레이어에 삽입되었습니다. 그 결과 왼쪽 위의 사람과 매우 비슷한 모습이 사람이 생성되는 것을 알 수 있습니다. 그에 비해 fine style에 해당하는 style은 후기 레이어인 64x64 ~ 1024x1024에 삽입되었습니다. 그 결과 조명이나 피부색과 같은 세밀한 요소에만 영향을 미치고 있음을 알 수 있습니다.
이는 노이즈에서도 마찬가지입니다. 노이즈를 아예 지워버리면 그림과 같이 약간 뭉개진 이미지를 출력하게 됩니다. 이때 초기 레이어의 노이즈만 삽입하면 전체 머리의 형태 정도만 변화하게 됩니다. 크게 변해도 상관없는 불규칙한 요소를 표현하는 것이죠. 이에 비해 후기 레이어의 노이즈만 삽입하면 주름과 같이 아주 세밀하면서 불규칙한 요소를 표현하는 것을 볼 수 있습니다.
즉, 단계별로 노이즈와 style 모두 큰 요소에서 작은 요소에 이르기까지 제 역할을 수행하게 됩니다.
1-3. Mixing Regularization
그런데 한가지 문제가 있습니다. 우리는 인물 사진이 style의 변화에 따라 조금씩 변화기를 원하고 있습니다. 즉, 인물 사진의 모든 요소(인종, 피부색, 머리색, 눈동자 색, 배경, 주름 유무, 머리 길이 등등)이 에서 하나의 축을 맡으면 제일 좋은 상황일 것입니다. 그런데 어떤 요소들은 사진에서 매우 높은 상관관계를 보이고 있습니다. 예를 들어 대머리 아저씨가 선글라스를 항상 쓰고 있다면? 사실 대머리와 선글라스는 다른 요소이므로 에서 분리되어야 합니다. 하지만 실제 이미지에서 두 요소가 항상 같이 나타나면 에서 entangle되어 있을 겁니다. 이 모델이 원하는 방향이 아닙니다.
이를 해결하기 위해서 논문에선 두 개의 style을 층을 달리 하여 사용하고 있습니다. 초기 레이어에서느 a style을 사용하고 후기 레이어에선 b style을 사용하는 방식입니다. 이를 mixing regularization이라 하는데, 이를 통해 모델이 실제 분포에서 어쩔 수 없이 보이는 높은 상관관계의 요소들을 분리해낼 수 있다고 합니다.
1-4. Truncation trick in
우리는 에서 style을 만들고 있습니다. 그리고 생성모델은 을 실제 이미지로 맵핑하고 있습니다. 그러다보면 약간 문제가 생길 수 있습니다. 에서 어떠한 부분은 실제 이미지에 거의 존재하지 않는 부분일 수 있습니다. 예를 들면 외계인을 이미지로 표현하려면 필요한 부분공간일 것입니다. 이러한 부분공간은 해당하는 이미지 자체가 적기 때문에 제대로 학습이 되지 않습니다. 그래서 제대로 이미지가 생성되지 않고, 모델의 성능을 떨어트립니다.
이에 저자들은 이러한 부분공간을 제외하기 위한 트릭을 사용합니다. 그 과정은 다음과 같습니다.
- 우선 가장 밀집되어 있는 지점을 찾습니다.
- 실제 w를 밀집된 공간 근처로 이동합니다. 이때 입니다.
이때 이라면 가장 평균적인 이미지가 나올 것입니다. 얼굴 데이터로 학습했다면, 학습데이터 상의 가장 평균적인 얼굴이 등장하게 됩니다.

논문에서 언급하는 재밌는 점은 이러한 트릭을 통해서 정반대의 얼굴 역시 구할 수 있다는 점입니다. 모든 점에서 정반대인 사람 얼굴을 말이죠.
1-5. Result
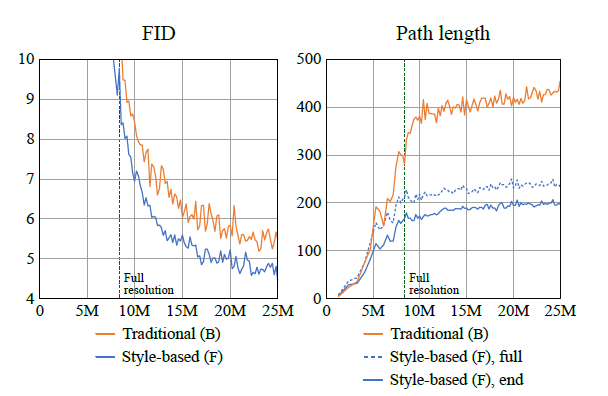
그 결과는 위와 같습니다. 기존의 PGGAN에 비해 빠르게 학습하는 것을 볼 수 있습니다. 여기서 path length는 이 논문에서 제시한 metric으로 w를 아주 조금 변화시킨 두 이미지를 vgg16에 넣어서 얻은 임베딩 벡터의 거리입니다. 만약 가 disentangle하다면 에서 조금 변화한 이미지는 vgg16의 임베딩 공간에서도 아주 작은 거리를 가질 것입니다. 즉, path length를 통해 실제로 가 disentangle한지 볼 수 있습니다.
2. GauGan
2-1. Semantic Image Synthesis
StyleGan은 사용자가 생성될 이미지의 요소들을 조절할 수 있지만, 전체 이미지를 결정할 순 없습니다. 선글라스를 쓰고 있는 이미지에서 선글라스를 벗기는 정도를 수행할 수 있습니다. 그렇다면 사용자가 원하는 이미지를 생성할 수도 있을까요?
GauGan은 이를 다루는 모델입니다. 정확히는 대략적인 이미지의 윤곽에 해당하는 정보를 입력하는 이에 맞는 이미지를 생성해주는 모델입니다. Semantic Image Synthesis라고 불리는 이 태스크에 대해 조금 더 이야기해보면 다음과 같습니다.
우선 입력으로 아래 그림과 같은 segmentation map을 받습니다.

이는 이미지에서 각각의 사물이 다른 레이블(정수)로 표시되어 있는 상태입니다. 위 segmentation map에선 하늘과 나무, 초원이 표시되어 있습니다.
그리고 이를 모델이 입력으로 받아 이미지를 생성하면 아래 그림과 같습니다.

segmentation map과 유사하게 사물들이 위치한 이미지인 것을 알 수 있습니다.
기존의 연구들에선 pix2pix와 같은 모델들이 이를 수행했습니다. 인코더-디코더 구조를 취하고 인코더에 실제 이미지나 segmentation map을 넣어서 수행했습니다. 하지만 이렇게 되면 모델 내부의 batch normalization과 같은 normalization 레이어로 인해 정보들이 희석된다는 문제점이 있습니다. GauGan은 이를 개선해서 segmentation map의 정보를 최대한 모델에 잘 전달하는데 최선을 다하고 있습니다.
2-2. Model Architecture
2-2-1. SPADE(Spatially-adaptive denormalization)
GauGan은 segmentation map을 모델의 초반에 삽입하지 않고, 중간 중간 계속 삽입해줍니다. StyleGan에서 style을 계속 삽입해준 것과 같은 맥락입니다. 그리고 그 과정은 SPADE라 하는 블록을 통해서 이루어집니다.
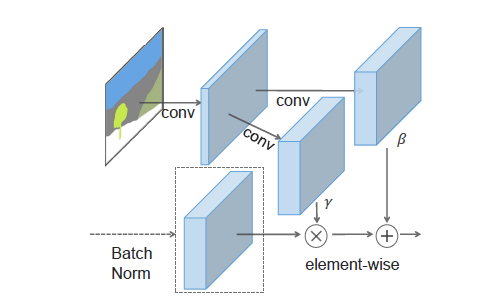
SPADE는 위와 같은 구조로 이루어져 있습니다.
- 이전 레이어에서 이미지가 전달되면, Batch Norm을 통과시킵니다.
- segmentation map은 정수로 되어 있으므로 우선 conv레이어를 통해 임베딩됩니다. 그 결과는 3차원 텐서가 됩니다.
- 임베딩된 3차원 텐서를 다시 2개의 conv 레이어에 각각 통과시켜 와 를 생성합니다. 이때, 는 입력된 이미지와 동일한 크기를 가지게 됩니다.
- 를 이용해 이미지에 대한 normalization을 수행합니다. 구체적인 수식은 아래와 같습니다.
여기서 노테이션은 다음과 같습니다.
- i : 레이어 숫자
- N : 미니배치
- H, y : 높이, y 좌표
- W, x : 폭, x 좌표
- h : normalization 이전 픽셀 값
- c: 채널
즉, 픽셀 별로 정규화를 시행하는데, 이때 segmentation map의 정보인 를 픽셀 별로 이용하고 있습니다.

사실 이 식은 배치 정규화 식과 매우 유사합니다. 배치 정규화와 다른 점은 배치 정규화에선 와 를 학습을 통해 최적화하지만, GauGan에선 segmentation map을 기반으로 하고 있다는 점입니다.
조금 더 자세히 SPADE를 살펴보면 아래와 같은 구성입니다.
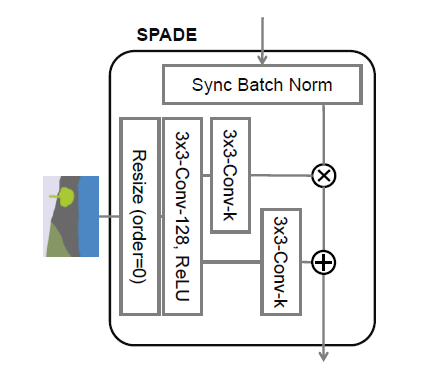
먼저 각 레이어마다 다루는 이미지의 크기가 다르므로 그에 맞게 segmentation map을 리사이즈 하고 conv에 통과시켜서 와 를 만들어내는 모습입니다. 이제 이 과정을 SPADE라고 부르겠습니다.
SPADE가 작동하는 이유는 단순합니다. segmentation map의 정보를 정규화하지 않기 때문입니다. 기존의 모델들(pix2pix 등)은 segmentation map을 입력으로 하여 이를 반복적으로 정규화하면서 처리했습니다.

그런데 위와 같이 극단적인 상황, 이미지의 모든 부분이 동일한 마스크로 되어 있다면, 정규화 과정에서 모든 정보가 사라집니다. 이를 논문에선 wash away semantic information이라고 표현합니다.
하지만 SPADE는 입력된 이미지를 정규화하여 학습을 안정화시키는 동시에, 그 과정에서 segmentation map을 이용해 scale하고 bias를 만들어서 반복적으로 semantic information을 전달하고 있습니다.
2-2-2. SPADE Generator
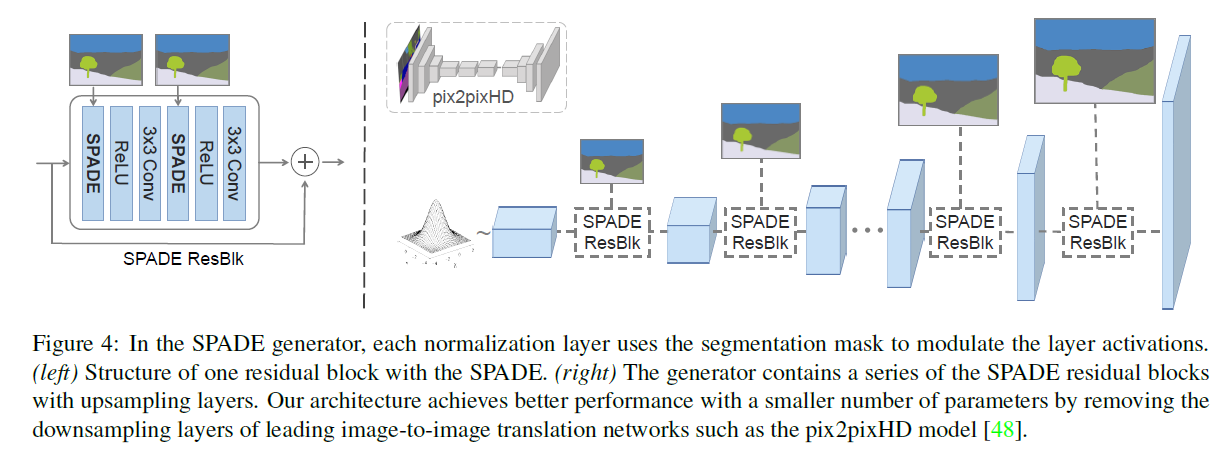
SPADE를 이용해 구성한 생성 모델은 사실 resnet의 구조와 매우 유사합니다. 블록 내부에서도 SPADE를 사용하고 블록도 SPADE를 이용해 연결하고 있습니다.
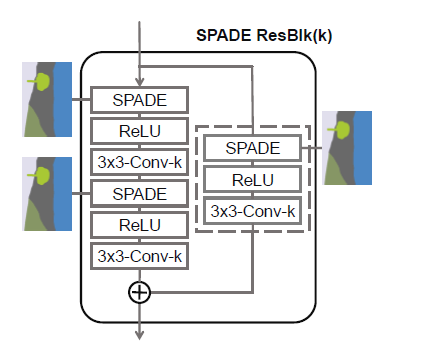
SPADE ResBlock을 확대하면 이와 같은 모습을 하고 있습니다. 그냥 SPADE를 계속 반복하는 모습입니다. 위에서도 이야기했지만, 더이상 segementation map이 모델의 초기 입력값으로 들어갈 필요가 없어졌습니다. SPADE를 통해 중간중간 계속 삽입하고 있기 때문입니다. 이는 기존의 segmentation map이나 실제 이미지를 representation으로 만들기 위해 필요했던 인코더 부분이 필요없어졌다는 말이 되었습니다. 즉, 인코더-디코더 구조에서 이제 디코더만 가져오면 됩니다. 모델이 매우 경량화되었습니다. 또한 입력값으로 가우시안 분포를 가지는 랜덤 벡터 를 가지게 됩니다.
multi modal synthesis
이렇게 입력값에서 자유로워지면서 multi modal에 대한 가능성이 열렸습니다. 즉, 가우시안 분포에서 랜덤 추출하지 않고, 임의의 데이터에서 representation을 생성하여 입력값으로 사용할 수 있습니다. 예를 들면 "저 푸른 초원 위에 그림 같은 집을 짓고"라는 문장을 rnn으로 representation으로 만들고 사용자가 원하는 대략적인 모습을 segmentation map으로 삽입하면 text를 입력으로 하는 multi modal synthesis가 가능해지게 됩니다.
이에 대한 조금 더 구체적인 예시로 논문에선 실제 이미지를 입력으로 하는 모델을 들고 왔습니다. (multi modal 이라고 하곤 다시 이미지를 가져온 것이 아쉽기는 합니다.)

제일 왼쪽 열이 이미지의 분위기만 따올 실제 이미지이고 제일 상단의 행이 사용자가 원하는 segmentation map 입니다. 이를 이용해 사용자가 원하는 이미지를 생성하면서 기존의 이미지가 가지고 있는 스타일 혹은 분위기를 이용할 수 있게 되었습니다.
2-3. Result
2-3-1. GauGan Performance

결과를 살펴보면 다른 모델에 비해 훨씬 좋은 이미지를 생성하고 있는 것을 알 수 있습니다. 이전의 SOTA라 평가받던 pix2pix HD 도 위의 이미지들은 잘 만들지 못하는데, GauGan은 그럴듯한 모습을 보이고 있습니다.

다양한 물체가 공존하는 ADE20K outdoor and Cityscapes 데이터셋에 대해서도 좋은 모습을 보이고 있습니다. 특히 pix2pixHD가 artifact을 생성해내는 모습을 보이지만 GauGan은 그렇지 않습니다.

생성된 이미지를 잘 훈련된 segmentation model에 모델에 넣어 실제 이미지와 얼마나 유사하게 segmentation map이 형성됐는지 평가하는 mIoU와 accu, 생성된 이미지 자체의 질을 평가하는 FID를 기반으로 여러 모델과 비교해보았을 때, GauGan이 거의 모든 데이터셋, 모든 메트릭에서 SOTA를 달성했습니다. SIMS가 Citiscapes에서 FID가 더 낫긴 하지만, SIMS는 실제 segmentation map을 사용한다고 합니다. 즉, 활용에 제약이 가해집니다.
2-3-2. SPADE Performance
그럼 진짜 SPADE가 GauGan의 성능 향상에 중요했는지 살펴보기 위해 이전 SOTA 모델과 비교해봅시다.
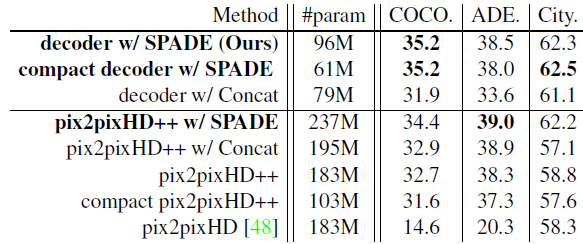
기존의 pix2pixHD에 저자들이 발견한 모든 성능 개선안을 도입한 모델이 pix2pixHD++이고, 여기에 SPADE를 사용하거나 중간에 segmentation map을 그대로 concat한 모델들을 이용해 실험했습니다. 그 결과 당연하게도 SPADE를 사용하는 것이 성능 향상에 도움을 주는 것을 볼 수 있었습니다. 단순히 segmentation map을 concat한 경우에는 SPADE 만큼의 성능을 보이지 못하며 SPADE가 효과적인 구조임을 보이고 있습니다. 특히 레이어 수를 줄인 compact 버전이 pix2pixHD 보다 파라미터는 1/3 가량으로 적은데 성능이 월등히 높은 모습입니다.
참고
Loner님의 PGGAN 리뷰
Loner님의 StyleGan 리뷰
고재영님의 StyleGan 리뷰
갓진수님의 GauGan 리뷰
Analyzing how StyleGAN works: style incorporation in high-quality image generation

강의 잘 들었습니다 !
Style GAN
GauGAN(SPADE)