
본 포스팅은 elice의 2021 NIPA AI 온라인 교육을 듣고 개인 공부를 위해 정리한 것입니다.
1. 제조/IoT 산업 내 AI 혁신과 스마트팩토리
제조 분야에서의 인공지능
1) 스마트팩토리
- 제조 생산을 위한 데이터의 수직적 통합 및 네트워크화된 제조 시스템을 갖춘 공장
- 제조 공정 및 운영 데이터와 통합
2) 산업 자동화
- ICT와 기계 기술 등을 활용하여 정해진 툴에 의해 자동 운전이 가능
- 제조 공정 자동화를 통한 인건비 및 운영비 절약
스마트팩토리
-
오작동 모니터링 (설비 혁신)
기계 설비의 오작동율은 환경(제조율, 습기, 온도 등)에 따라 다르다.
따라서 특정 센서 1~2개만으로 오작동을 예측하기에는 정확도에 한계가 따른다.
👉 다양한 데이터에 기반한 AI를 사용하여 한계를 극복, 오작동 시점을 예측할 수 있다! -
제품 성능 모의 실험 (품질 혁신)
Digital twin이라고도 한다.
실제 공장을 만들어 제품 생산을 테스트하는 데에는 막대한 시간과 비용이 소모된다.
데이터에 기반한 가상의 공장에서 모의 실험을 진행하여 제품 개발, 제품 개선, 유지 보수 등을 진행할 수 있다.🎈 지멘스의 전사 통합 자동화 플랫폼 TIA
지멘스는 독일의 유럽 최대 엔지니어링 회사로제품 설계 - 생산 계획 - 생산 엔지니어링 - 생산 - 서비스에 이르는 제조 과정을 통합한 TIA(Totally Integrated Automation, 전사 통합 자동화)로 digital twin을 실현하였다.
지멘스는 지난 20여년간 생산량을 13배 증가시켰으며, 인력은 그대로 유지하면서 제품 불량률을 0.000 9 % 수준으로 떨어뜨렸다. -
데이터 기반 의사결정 최적화 (운영 혁신)
스마트팩토리 내에서 창출되는 빅데이터 분석을 통하여 의사 결정을 최적화할 수 있다.
데이터 기반의 최적 운영 스케쥴링 등을 통해 전력 사용량 절감 등의 활용이 가능하다.
공정 자동화
-
공정 효율 증대
AI 기술을 활용하여 기존에 사람이 발견하지 못했던 비효율 등의 발견이 가능하다.
데이터 분석을 통해 병목 및 개선이 필요한 지점을 찾아 공정을 최적화시킬 수 있다.
👉 분석에 기반하여 이를 최적화할 수 있는 인공지능 솔루션을 적용할 수 있다. -
재고 관리 및 물류 자동화
데이터화 된 물류 자원을 공유하여 수요 및 공급을 예측하는 기술을 말한다.
사람의 도움 없이 하차, 검수, 적재, 분류, 상차에 대한 물류 전 과정을 자동화할 수 있다.
👉 기업의 수익성 개선에 큰 영향
인공지능 적용을 위해 필요한 점
- 해당 도메인에서의 확실한 목표 확립 ← 우리 회사에 맞게!
- 데이터 분석 전문가와의 지속적인 커뮤니케이션
↑ 데이터 분석 전문가를 통해 얻어낸 Insight를 산업에 전개하는 것은 관리자와 경영진의 몫! - 인공지능에 필요한 데이터를 확보할 수 있는 환경 조성
↑ 데이터가 없는 데이터 분석과 인공지능도 존재하지 않는다. 데이터 수집은 매우 중요!
실습✍ 데이터 확인하고 머신러닝 모델 학습하기
복잡한 현대 반도체 제조 공정은 일반적으로 센서 및 공정 측정 지점에서 수집된 신호 혹은 변수 모니터링을 통해 일관된 감시를 받는다.
그러나 이러한 모든 신호가 특정 모니터링 시스템에서 똑같이 가치가 있는 것은 아니다! 측정된 신호에는 유용한 정보, 관련 없는 정보 및 노이즈의 조합이 포함된다.
제조 과정에서 나올 수 있는 공정 이상을 머신러닝을 사용하여 예측해보자
- 실습 데이터
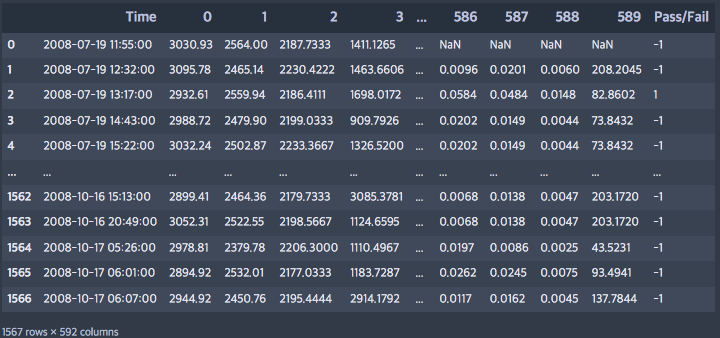
반도체를 제조하는 공정에서 590개의 센서가 시간 별로 기록한 데이터 샘플 1,567개
데이터 테이블은 592개의 column(1개의 시간 데이터, 590개의 센서, 1개의 테스트 통과 결과)과 1,567개의 row(행)로 구성되어 있다.
Pass/Fail 칼럼은 타임 스탬프 별로 간단한 통과 실패율을 나타내며 여기서 –1은 통과(정상)에 해당하고 1은 실패(이상)에 해당한다.
위 데이터를 기반으로 머신러닝 학습을 수행, 불량 반도체가 제조될 수 있는 공정 이상 유무를 예측해보자.
- 실습 코드
ma.preprocess()를 사용하여 데이터를 읽고 처리하는 과정을 수행해보세요.ma.train(x_train_us, y_train_us)를 사용하여 학습을 수행시켜보세요.
import machine as ma
def main():
"""
지시사항 1번. 데이터를 읽고 처리하는 코드를 작성해보세요.
"""
x_train_us, x_test_us, y_train_us, y_test_us = ma.preprocess()
"""
지시사항 2번. 학습을 수행시켜보세요.
"""
model = ma.train(x_train_us, y_train_us)
if __name__ == "__main__":
main()
실습✍ 학습 모델 평가하기
재현율(recall score) : 모델이 실제 예측할 값을 얼마나 정확히 예측(재현)했는지를 설명하는 지표로 재현율을 확인하는 것은 모델이 얼마나 정확히 값을 예측하는지를 평가하는 것이다. 높은 재현율은 높은 신뢰도를 수반한다.
=정확히 예측한 불량품 수량
=실제 불량품 수량
특성 중요도(feature importance) : 인공지능 모델이 기계의 이상 작동을 감지하는 데에 어떤 센서가 가장 중요했는지를 나타낸다.
- 예측 정확도 결과를 출력
실습 코드 :ma.evaluation()
import machine as ma
def main():
"""
지시사항 1번. 예측 정확도 결과를 출력해보세요.
"""
ma.evaluation()
if __name__ == "__main__":
main()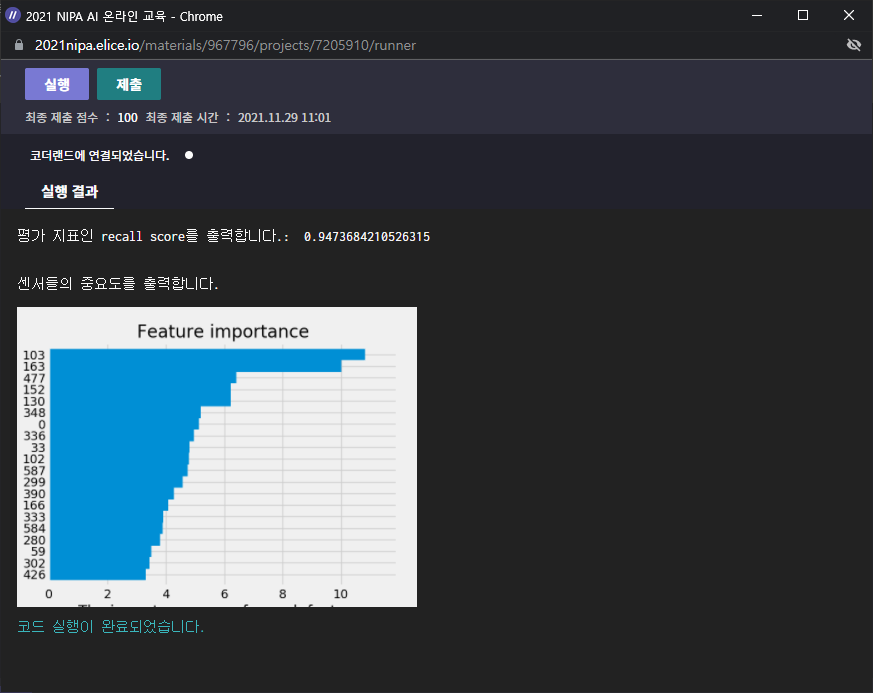
👉 103번과 163번 센서가 공정 이상을 탐지하는데 가장 중요한 것을 알 수 있다.
실습✍ 공정 이상 예측하기
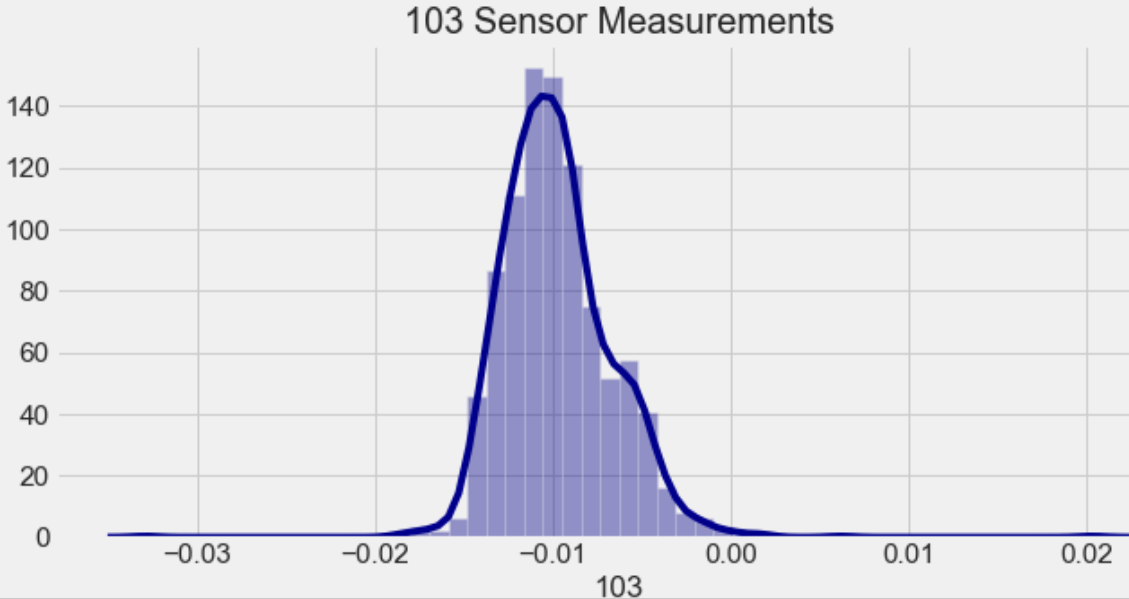
이전 실습의 학습 결과를 통하여 103번 센서의 관측 값이 중요하다는 것을 알았다.
103번 센서의 값을 조절 했을 때 공정 이상이 발생할 지를 학습된 인공지능 모델을 사용하여 예측하여 보자!
-
103번 센서의 관측치 값 분포도
-
실습 코드
- None을 지우고 103 번 센서의 관측치 값을 직접 입력하고자 합니다. value_103_sensor에 정상 범위의 값-0.02이상 0이하를 입력하세요.
import machine as ma
def main():
"""
지시사항 1번. 103번 센서값인 아래의 value_103_sensor 값을 바꾸어보세요.
"""
value_103_sensor = -0.01
# 예측을 진행하는 코드입니다.
ma.predict(value_103_sensor)
if __name__ == "__main__":
main()
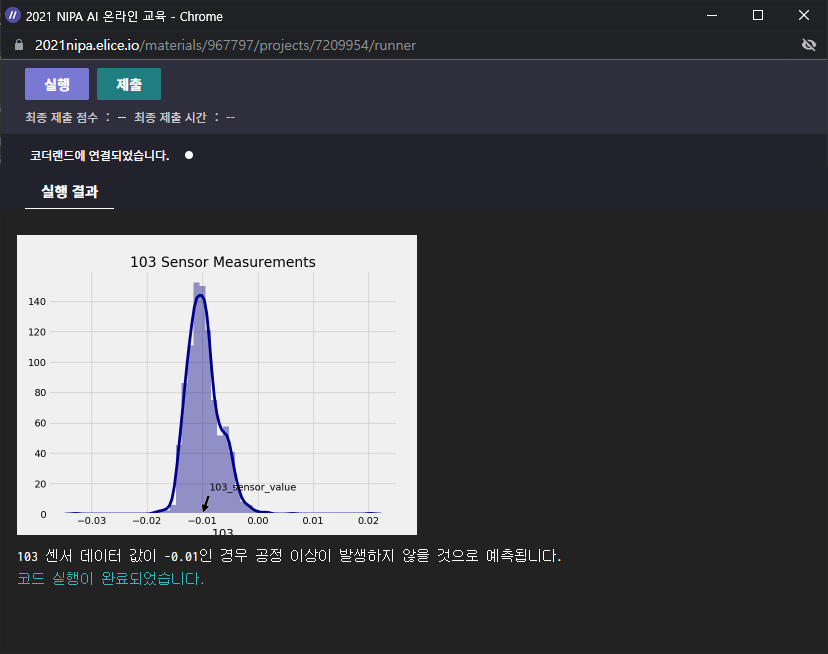
👉 공정 이상이 발생하지 않을 것으로 예측되었다.
- 만약 이상치를 넣는다면 어떻게 될까?
1.5입력
import machine as ma
def main():
"""
지시사항 1번. 103번 센서값인 아래의 value_103_sensor 값을 바꾸어보세요.
"""
value_103_sensor = 1.5
# 예측을 진행하는 코드입니다.
ma.predict(value_103_sensor)
if __name__ == "__main__":
main()
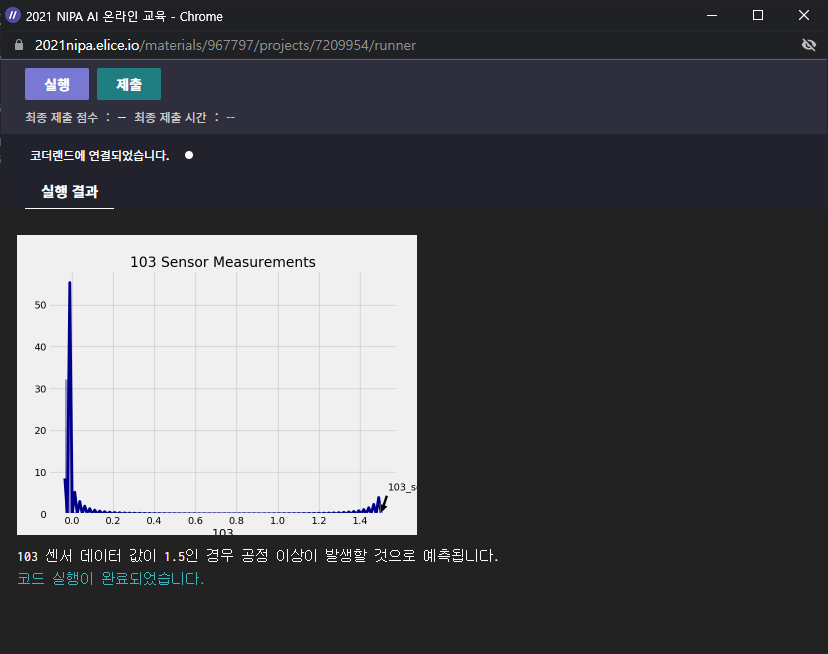
👉 공정 이상이 발생할 것으로 예측되었다.
이렇듯 이상 탐지 알고리즘을 제조 현장에서 활용하면 센서 데이터로부터 실제 어떤 공정 이상이 발생할 지 미리 예측하고 파악할 수 있기 때문에 관리자는 적절한 조치를 취해 최악의 손실이 일어나는 것을 방지할 수 있다.
수강 후 느낀 점
- 아직 머신러닝 수업을 안들어서 그런가 실습은 그냥 영상보고 따라하기만 했다. 머신러닝 시작하기를 듣고 다시 실습을 혼자 해봐야겠다.
