
본 포스팅은 elice의 2021 NIPA AI 온라인 교육을 듣고 개인 공부를 위해 정리한 것입니다.
1. 국내 코로나 환자 데이터를 활용한 데이터 분석
학습방법
- 파일 목록에 업로드 되어 있는 [p1]_코로나_데이터_분석_프로젝트.ipynb 파일을 클릭
- 해설 영상과 함께 코드 셀을 실행해보며 코로나 데이터 분석 프로젝트 진행
- 실행 하는 중간 중간 quiz를 풀고 하단의 채점까지 완료해야 이수 가능
나는 elice에서 제공하는 쥬피터 노트북뿐만아니라 PyCharm을 이용해서 직접 코드를 입력해 볼 계획이다.
프로젝트 목표
- 서울시 코로나19 확진자 현황 데이터를 분석하여 유의미한 정보 도출
- 탐색적 데이터 분석을 수행하기 위한 데이터 정제, 특성 엔지니어링, 시각화 방법 학습
프로젝트 목차
-
데이터 읽기: 코로나 데이터를 불러오고 Dataframe 구조를 확인
1.1. 데이터 불러오기 -
데이터 정제: 비어 있는 데이터 또는 쓸모 없는 데이터를 삭제
2.1. 비어있는 column 지우기 -
데이터 시각화: 각 변수 별로 추가적인 정제 또는 feature engineering 과정을 거치고 시각화를 통하여 데이터의 특성 파악
3.1. 확진일 데이터 전처리하기
3.2. 월별 확진자 수 출력
3.3. 8월 일별 확진자 수 출력
3.4. 지역별 확진자 수 출력
3.5. 8월달 지역별 확진자 수 출력
3.6. 월별 관악구 확진자 수 출력
3.7. 서울 지역에서 확진자를 지도에 출력
데이터 출처
프로젝트 개요
2020년 초에 발생한 코로나19 바이러스는 세계적으로 대유행하였고 이에 대한 많은 분석이 이루어지고 있습니다. 유행 초기엔 이를 분석할 데이터가 충분하지 않았지만 6개월 이상 지난 지금은 다양한 데이터 기관에서 코로나 관련 데이터를 공공으로 제공하고 있습니다.
이번 프로젝트에서는 국내 공공데이터 포털에서 제공하는 서울시 코로나19 확진자 현황 데이터를 바탕으로 탐색적 데이터 분석을 수행해보겠습니다. 국내 데이터 중 확진자 비율이 제일 높고 사람이 제일 많은 서울시의 데이터를 선정하였으며, 이를 바탕으로 코로나19의 확진 추이 및 환자 특성에 대해서 데이터를 바탕으로 알아봅시다.
1. 데이터 읽기
1.1 데이터 불러오기
필요한 패키지 설치 및 import한 후 pandas를 사용하여 데이터를 읽고 어떠한 데이터가 저장되어있는지 확인하기
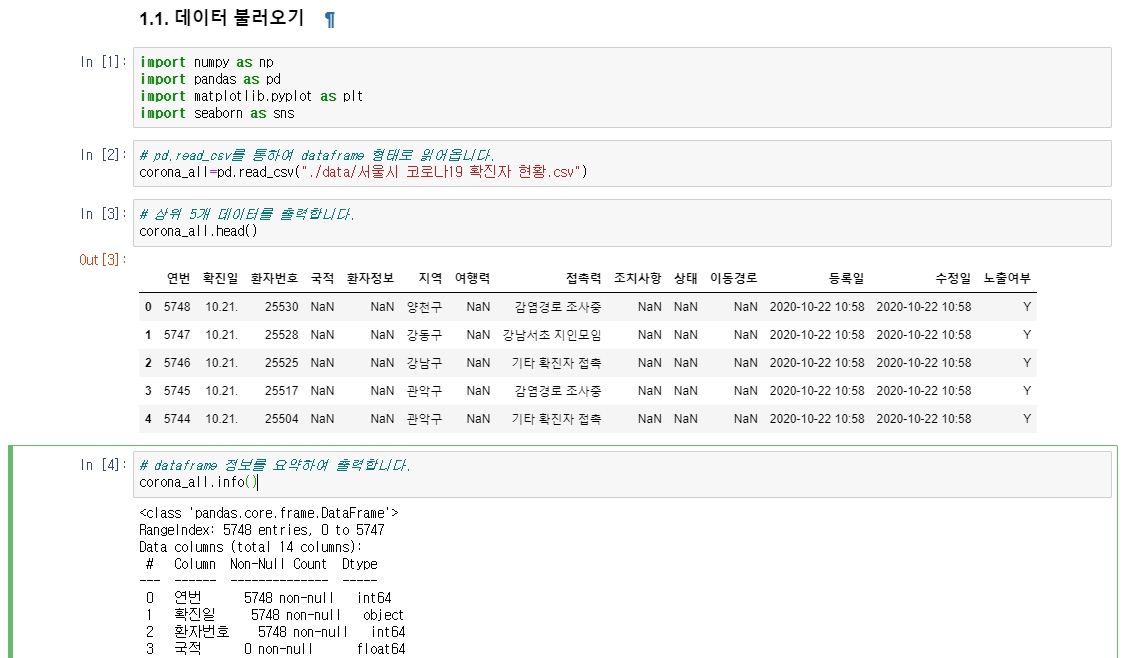
seaborn은 Matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화 패키지로 matplotlib 보다 다양하고 다채로운 시각화 모듈이다.
- seaborn에서만 제공되는 통계 기반 plot
- 특별하게 꾸미지 않아도 깔끔하게 구현되는 기본 color
- 더 아름답게 그래프 구현이 가능한 palette 기능
- pandas 데이터프레임과 높은 호환성
hue 옵션으로 bar 구분이 가능하며, xtick, ytick, xlabel, ylabel, legend 등이 추가적인 코딩 작업없이 자동으로 세팅된다.
😱😱😱 Error 주의 😱😱😱
elice에서 제공하는 쥬피터 노트북을 사용하면 에러가 없으나 파이참을 이용했더니 Error 발생😂
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbf in position 1: invalid start byte
pandas에서 read_csv, read_excel 등 파일을 불러올 때, 한글이 포함된다면 위와 같은 에러가 날 때가 있다.
이는 인코딩의 문제로 encoding='cp949' 또는 encoding='eun-kr'를 파라미터로 추가하면 해결된다.
👉 corona_all = pd.read_csv("./data/서울시 코로나19 확진자 현황.csv", encoding="cp949")
그런데! 나는 이게 문제가 아니었다😫!!! 그래서 공공 데이터 csv 파이썬 인코딩을 검색해서 아래와 같은 강같은 포스팅을 찾아 냈다.
https://teddylee777.github.io/pandas/%EA%B3%B5%EA%B3%B5%EB%8D%B0%EC%9D%B4%ED%84%B0-%ED%95%9C%EA%B8%80%EA%B9%A8%EC%A7%90%ED%98%84%EC%83%81-%ED%95%B4%EA%B2%B0%EB%B0%A9%EB%B2%95
그래서 엑셀에서 파일을 연 뒤 다른 이름으로 저장 - 파일 형식을 CSV UTF-8(쉼표로 분리) 로 지정해주었다.
이 과정을 거쳤더니 인코딩 에러는 떠나가고 딱 한 줄의 다른 에러가 등장했다.
sys:1: DtypeWarning: Columns (10) have mixed types.Specify dtype option on import or set low_memory=False.
dtype option으로 타입을 명시해주거나 low_memory = False로 지정해 주면 경고 메시지가 출력되지 않는다고 하여 나는 후자를 택했더니 드디어 더 이상의 에러는 발생하지 않았다.
corona_all = pd.read_csv("./data/서울시 코로나19 확진자 현황.csv", low_memory=False)
- PyCharm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns # 데이터 시각화를 지원하는 모듈
# pd.read_csv를 통하여 dataframe 형태로 파일 불러오기
corona_all = pd.read_csv("./data/서울시 코로나19 확진자 현황.csv", low_memory=False)
print(corona_all.head(), "\n") # 상위 5개 데이터 출력
print(corona_all.info(), "\n") # dataframe 정보 요약, 출력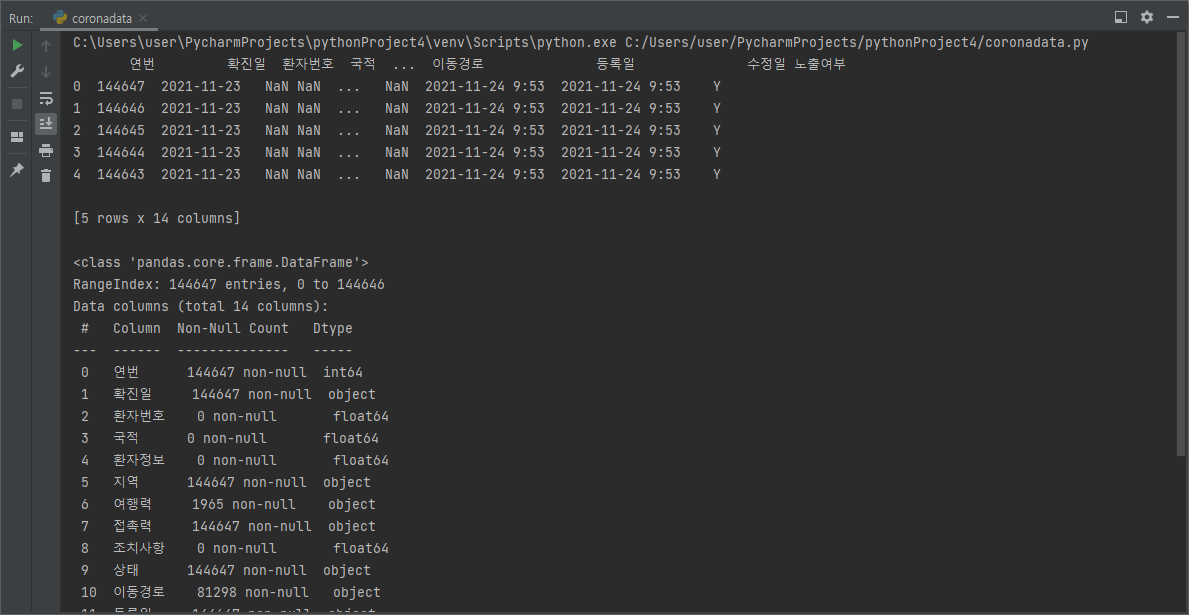
👉 나는 최신 데이터 파일을 다운받아서 elice에서 제공하는 데이터와 내용이 조금 다르다.
👉 non-null을 통해 비어있지 않은 데이터의 개수를 알 수 있고, Dtype으로 데이터타입을 알 수 있다.
👉 여행력 1965는 무슨 뜻일까? 총 144647명 중 해외에서 온 사람이 1965명이라는 것
2. 데이터 정제
결측값(missing data), 이상치(outlier)를 처리해보기
2.1. 비어있는 column 지우기
corona_all.info()를 통하여 국적, 환자정보, 조치사항 에 해당하는 데이터가 존재하지 않는 것을 알 수 있다. (0 non-null)
.drop()를 사용하면 column의 데이터를 삭제할 수 있다!
비어있는 국적, 환자정보, 조치사항의 column 데이터를 삭제하고 이 dataframe을 corona_del_col에 저장해보자
필요한 정보만 남기기 위해 데이터를 지울 때는 원본에서 삭제하는 것이 아니라 반드시 새로운 변수로 정의하고 저장하는 것이 좋다!!

corona_del_col = corona_all.drop(columns = ["국적","환자정보","조치사항"])
print(corona_del_col.info(), "\n")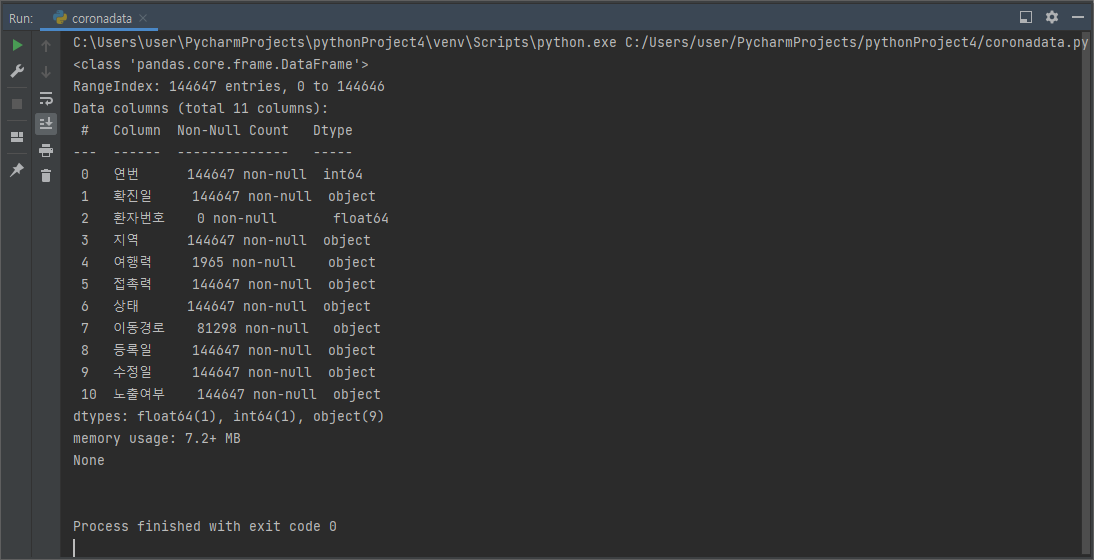
😢 파이참으로 최신 데이터를 이용해 따라하다보니 다른 부분이 많아 파이참은 개인적으로
실습해보고 포스팅은 elice 쥬피터 노트북에서 한 걸 올려야겠다.
3. 데이터 시각화
데이터 정제를 완료한 corona_del_col 데이터를 바탕으로 각 column의 변수별로 어떠한 데이터 분포를 하고 있는지 시각화하기
3.1. 확진일 데이터 전처리하기
corona_del_col['확진일']0 10.21.
1 10.21.
2 10.21.
3 10.21.
4 10.21.
...
5743 1.31.
5744 1.30.
5745 1.30.
5746 1.30.
5747 1.24.
Name: 확진일, Length: 5748, dtype: object👉 확진일 데이터가 월.일. 형태의 날짜 형식임을 확인할 수 있다.
월별, 일별 분석을 위해 문자열 형식의 데이터를 숫자로 변환해보자.
- 확진일 데이터를 month, day 데이터로 나누기
확진일에 저장된 문자열 데이터를 나누어 month, day column에 int64 형태로 저장
# dataframe에 추가하기 전, 임시로 데이터를 저장해 둘 list를 선언
month = []
day = []
for data in corona_del_col['확진일']:
# split 함수를 사용하여 월, 일을 나누어 list에 저장합니다.
month.append(data.split('.')[0])
day.append(data.split('.')[1])
# corona_del_col에 `month`, `day` column을 생성하며 동시에 list에 임시 저장된 데이터를 입력합니다.
corona_del_col['month'] = month
corona_del_col['day'] = day
corona_del_col['month'].astype('int64')
corona_del_col['day'].astype('int64')- 결과 (corona_del_col['day']출력)
0 21
1 21
2 21
3 21
4 21
..
5743 31
5744 30
5745 30
5746 30
5747 24
Name: day, Length: 5748, dtype: int64❓ 파이참에서도
corona_del_col['month'].astype('int64')이렇게 데이터 타입을 바꿔줬는데도 dtype: object라고 나온다. 뭐가 문제인걸까? 데이터의 문제일까 싶어서 elice의 csv를 받아서 똑같이 코드를 짰는데도 dtype: object라고 나온다.
❕❕ 해당 컬럼에 저장을 안해서 생긴 문제다!
corona_del_col['month'] = corona_del_col['month'].astype('int64')이라고 저장을 해줘야 데이터 타입이 변환된다!!
3.2. 월별 확진자 수 출력
나누어진 month의 데이터를 바탕으로 월별 확진자 수를 막대그래프로 출력
참고로 데이터가 20년도 1월부터 10월까지의 데이터를 담고 있어서 order list는 1~10까지🙄
- seaborn의 countplot :
sns.countplot(x, data, palette, order)
데이터의 개수를 확인할 수 있다. x축은 month, 월별로 data를 count하는데 이 data가 corona_del_col, palette는 그래프의 색깔 타입, order는 순서!
# 그래프에서 x축의 순서를 정리하기 위하여 order list를 생성합니다.
order = []
for i in range(1,11):
order.append(str(i))
# order = ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10']# 그래프의 사이즈를 조절합니다.
plt.figure(figsize=(10,5))
# seaborn의 countplot 함수를 사용하여 출력합니다.
sns.set(style="darkgrid")
ax = sns.countplot(x="month", data=corona_del_col, palette="Set2", order = order)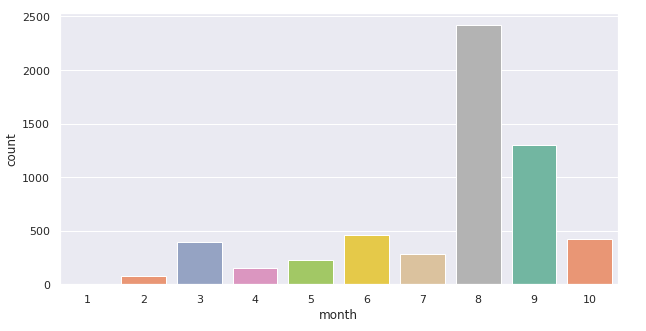
파이참에서 그래프가 안뜨길래 계속 코드를 여기저기 건드려보다 알게된 사실🙄
dtype이 object가 아니면 시각화가 되지 않는 것을 발견했다! 아까 앞에서 month의 dtype을 int64로 저장해줬는데 이렇게 되니 그래프가 그려지지 않고 빈 박스가 나왔다.
이 부분을 다시 원래dtype = object로 돌려준 후plt.show()를 했더니 그래프가 나왔다.
그러나 그것도 10월에만!! 이건 또 무슨 문제일까 고민을 했더니 x축의 문제였다!
최신 데이터 파일은 2021-03-21 이런식으로 월(month)이01, 02, 03,...이렇게 저장되어있어서for i in range(1,11)로 얻은 order 리스트1, 2, 3, ...와 다르다.
그래서order = ["01", "02", "03", .... ,"12"]를 하니 내가 원하던 예쁜 그래프가 나왔다.
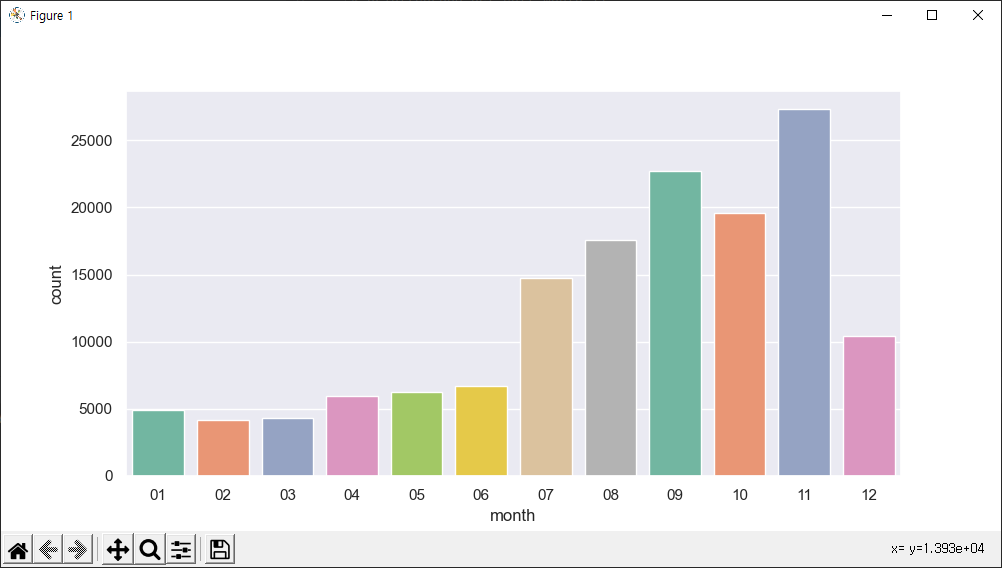
- Pandas 모듈에서 series의 plot 함수를 사용한 출력
corona_del_col['month'].value_counts().plot(kind='bar')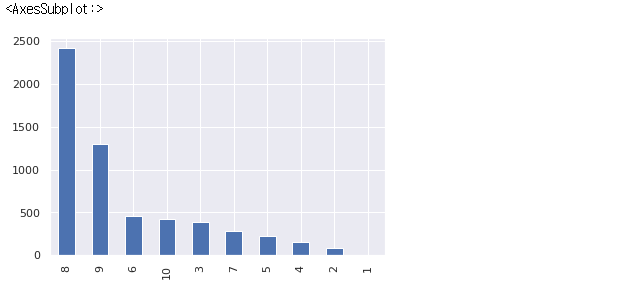
👉 내림차순으로 출력되네?value_counts() 가 각 데이터를 세어서 내림차순으로 정리하는 함수!
value_counts()
corona_del_col['month'].value_counts()8 2416
9 1304
6 460
10 425
3 391
7 281
5 228
4 156
2 80
1 7
Name: month, dtype: int64👉 dtype : int64 주의하기
3.3. 8월 일별 확진자 수 출력
월별 확진자 수를 살펴보니 8월에 확진자가 가장 많았다!! 8월의 일별 확진자 수를 확인해보자🙄
- 8월 일별 막대그래프
data=corona_del_col[corona_del_col["month"]=="8"]8월 확진자 데이터
# 그래프에서 x축의 순서를 정리하기 위하여 order list를 생성합니다.
order2 = []
for i in range(1,32):
order2.append(str(i))
# order2 = ['1', '2', ..., '31']plt.figure(figsize=(20,10))
sns.set(style="darkgrid")
ax = sns.countplot(x="day", data=corona_del_col[corona_del_col["month"]=="8"],
palette="rocket_r", order = order2)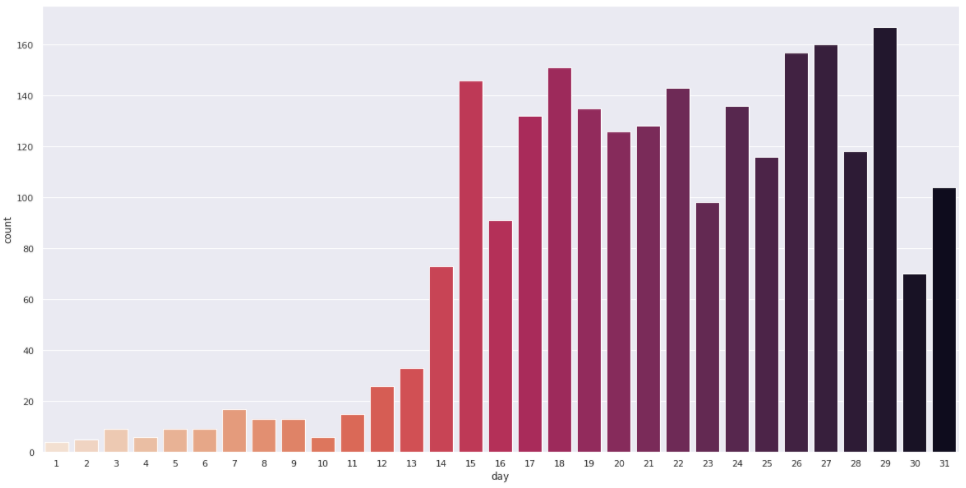
✍ quiz 1. 8월 평균 일별 확진자 수를 구하세요. (8월 총 확진자/31일)
# 둘 다 답
corona_del_col[corona_del_col['month'] == '8']['day'].count()/31
corona_del_col[corona_del_col['month'] == '8']['day'].value_counts().mean()77.935483870967743.4. 지역별 확진자 수 출력
지역데이터를 간단히 출력해보면 oo구 형태의 문자열 데이터임을 알 수 있다.
이번에는 지역별로 확진자가 얼마나 있는지 막대그래프로 출력해보자🙄
- 지역별 확진자 수 막대그래프로 출력하기
한글 깨짐 방지를 위한 폰트 지정하기
rc={"axes.unicode_minus":False}코드는 축의 값이 마이너스 값이면 마이너스 부호가 깨질 수 있어서 이를 방지하기 위해 False로 설정해주는 것
import matplotlib.font_manager as fm
font_dirs = ['/usr/share/fonts/truetype/nanum', ]
font_files = fm.findSystemFonts(fontpaths=font_dirs)
for font_file in font_files:
fm.fontManager.addfont(font_file) # 폰트 추가
plt.figure(figsize=(20,10))
# 한글 출력을 위해서 폰트 옵션을 설정합니다.
sns.set(font="NanumBarunGothic",
rc={"axes.unicode_minus":False},
style='darkgrid')
ax = sns.countplot(x="지역", data=corona_del_col, palette="Set2")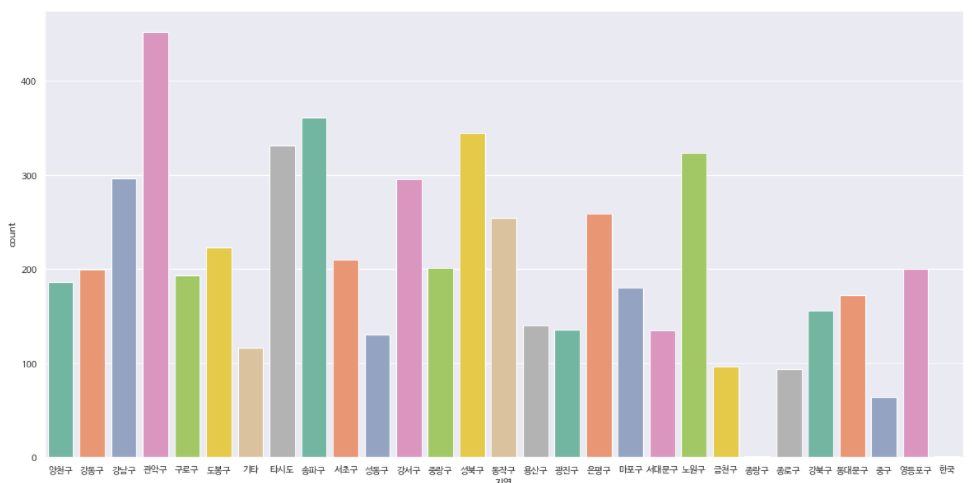
파이참에서는 한글 폰트 설정이 아무리해도 안된다... 경로를 다르게 설정해주었는데도... 언젠가는 방법을 찾겠지?
- 지역 이상치 데이터 처리
위의 출력된 데이터를 보면 종랑구라는 잘못된 데이터와 한국이라는 지역과는 맞지 않는 데이터가 있다. 종랑구 → 중랑구, 한국 → 기타로 데이터를 변경해보자🙄
drop함수로 삭제하지말고 replace 함수를 사용하여 해당 데이터를 변경하고, 새로운 Dataframe으로 저장하자! (원본은 소중하게..💚)
corona_out_region = corona_del_col.replace({'종랑구':'중랑구', '한국':'기타'})👉 replace 함수의 ({}) 소괄호, 중괄호 사용한 거 꼭 명심하기!!
# 이상치가 처리된 데이터를 다시 출력해 봅시다.
plt.figure(figsize=(20,10))
sns.set(font="NanumBarunGothic",
rc={"axes.unicode_minus":False},
style='darkgrid')
ax = sns.countplot(x="지역", data=corona_out_region, palette="Set2")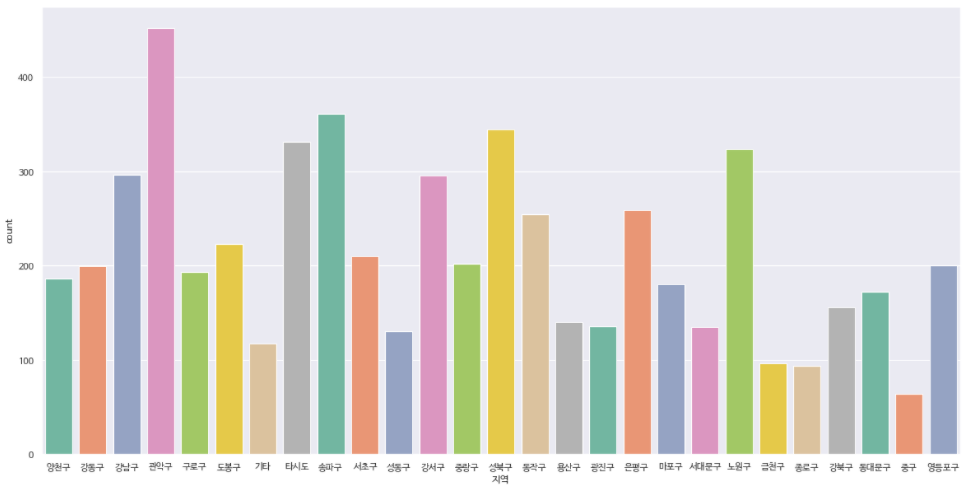
3.5. 8월달 지역별 확진자 수 출력
감염자가 가장 많았던 8월에는 지역별로 확진자가 어떻게 분포되어 있는지 확인해보자🙄
- 논리연산을 이용한 조건에 맞는 데이터 출력
corona_out_region[corona_del_col['month'] == '8']
- 그래프 출력
data=corona_out_region[corona_del_col['month'] == '8']로 했지만data=corona_out_region[corona_out_region['month'] == '8']도 상관없을 듯
plt.figure(figsize=(20,10))
sns.set(font="NanumBarunGothic",
rc={"axes.unicode_minus":False},
style='darkgrid')
ax = sns.countplot(x="지역", data=corona_out_region[corona_del_col['month'] == '8'], palette="Set2")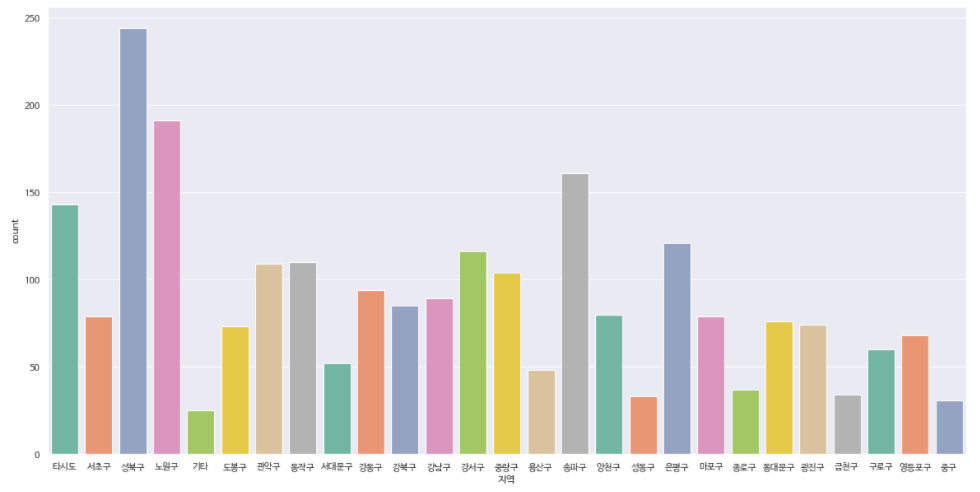
3.6. 월별 관악구 확진자 수 출력
확진자가 가장 많았던 관악구 내의 확진자 수가 월별로 어떻게 증가했는지 확인해보자🙄
# 해당 column을 지정하여 series 형태로 출력할 수 있습니다.
corona_out_region['month'][corona_out_region['지역'] == '관악구']3 10
4 10
6 10
7 10
8 10
..
5630 3
5661 2
5674 2
5695 2
5711 2
Name: month, Length: 452, dtype: object👉 관악구의 총 확진자는 452명임을 알 수 있다.
# 그래프를 출력합니다.
plt.figure(figsize=(10,5))
sns.set(style="darkgrid")
ax = sns.countplot(x="month", data=corona_out_region[corona_out_region['지역'] == '관악구'],
palette="Set2", order = order)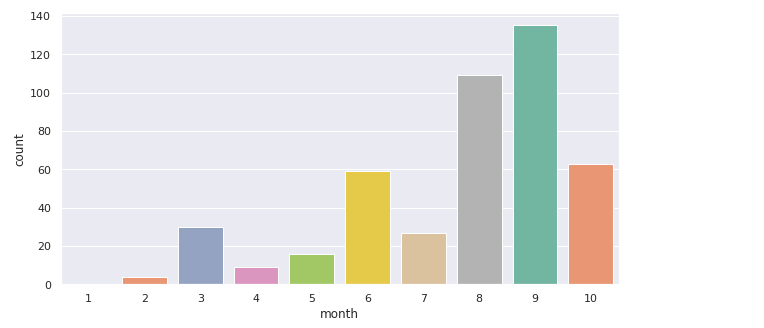
3.7. 서울 지역에서 확진자를 지도에 출력
지도를 출력하기 위한 라이브러리로 folium을 사용해보자🙄
folium : open street map(osm)과 같은 지도 데이터에 'Leaflet.js’를 이용하여 위치정보를 시각화하는 파이썬 라이브러리
folium.map을 이용한 지도 출력
# 지도 출력을 위한 라이브러리 folium을 import 합니다.
import folium
# Map 함수를 사용하여 지도를 출력합니다.
map_osm = folium.Map(location=[37.529622, 126.984307], zoom_start=11)
# (location=[위도, 경도], zoom_start=초기화면의 크기)
map_osm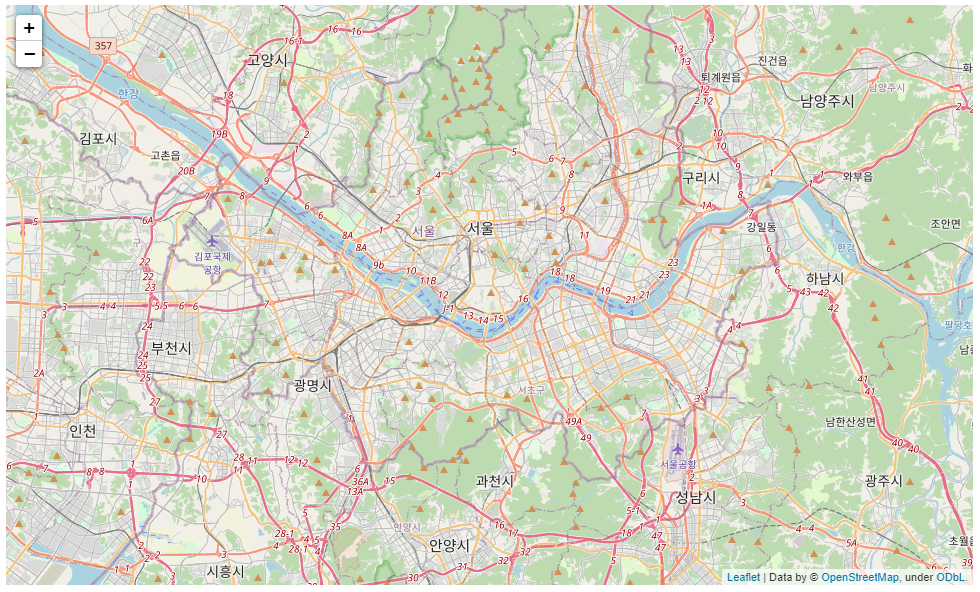
지역마다 지도에 정보를 출력하기 위해서는 각 지역의 좌표정보가 필요하다.
이를 해결하기 위해서 서울시 행정구역 시군 정보 데이터를 불러와 사용할 것이다.
데이터 출처: https://data.seoul.go.kr/dataList/OA-11677/S/1/datasetView.do
- 데이터 저장
# CRS에 저장합니다.
CRS=pd.read_csv("./data/서울시 행정구역 시군구 정보 (좌표계_ WGS1984).csv")
CRS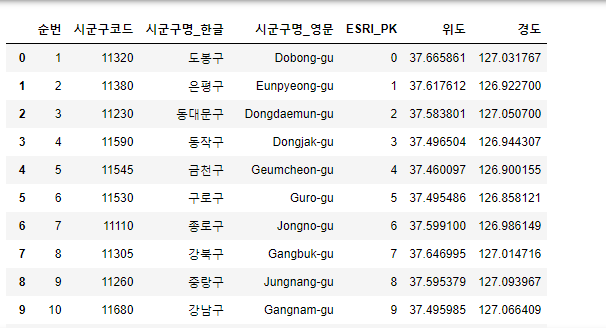
- "중구" 데이터 찾기
CRS[CRS['시군구명_한글'] == '중구']
- for 문을 사용하여 지역마다 확진자를 원형 마커로 지도에 출력
# corona_out_region의 지역에는 'oo구' 이외로 `타시도`, `기타`에 해당되는 데이터가 존재 합니다.
# 위 데이터에 해당되는 위도, 경도를 찾을 수 없기에 삭제하여 corona_seoul로 저장합니다.
corona_seoul = corona_out_region.drop(corona_out_region[corona_out_region['지역'] == '타시도'].index)
corona_seoul = corona_seoul.drop(corona_out_region[corona_out_region['지역'] == '기타'].index)
# 서울 중심지 중구를 가운데 좌표로 잡아 지도를 출력합니다.
map_osm = folium.Map(location=[37.557945, 126.99419], zoom_start=11)
# 지역 정보를 set 함수를 사용하여 25개 고유의 지역을 뽑아냅니다.
for region in set(corona_seoul['지역']):
# 해당 지역의 데이터 개수를 count에 저장합니다.
count = len(corona_seoul[corona_seoul['지역'] == region])
# 해당 지역의 데이터를 CRS에서 뽑아냅니다.
CRS_region = CRS[CRS['시군구명_한글'] == region]
# CircleMarker를 사용하여 지역마다 원형마커를 생성합니다.
marker = folium.CircleMarker([CRS_region['위도'], CRS_region['경도']], # 위치
radius=count/10 + 10, # 범위
color='#3186cc', # 선 색상
fill_color='#3186cc', # 면 색상
popup=' '.join((region, str(count), '명'))) # 팝업 설정
# 생성한 원형마커를 지도에 추가합니다.
marker.add_to(map_osm)
map_osm👉 radius = count/10 + 10 → 해당 지역의 확진자 수(count)에 비례해서 원의 크기를 만들어 줌, +10은 원의 크기가 너무 작을까봐 더해준 것!
👉 각 지역구의 확진자 인원을 가시적으로 나타내기 위해 popup 설정!
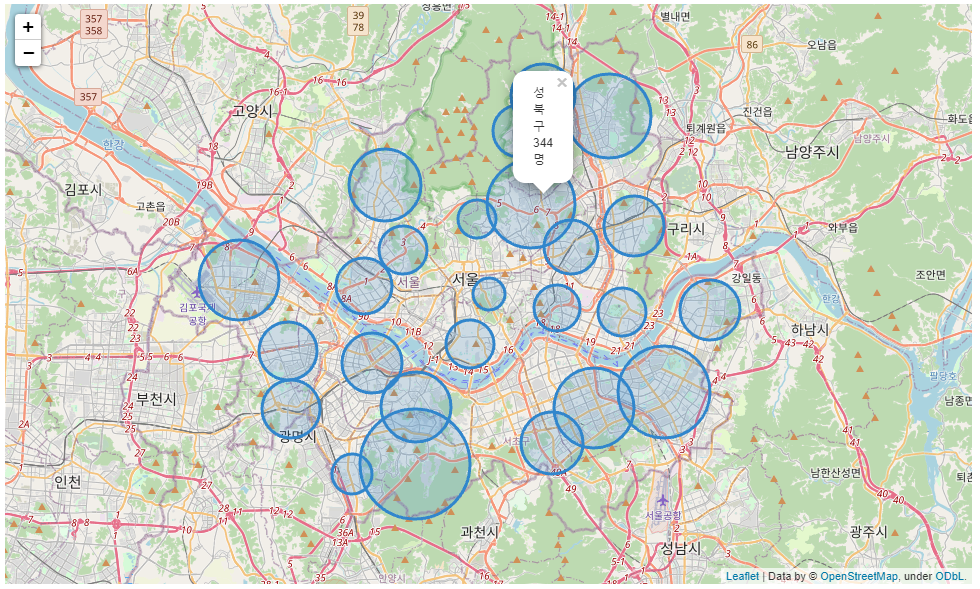
✍ quiz 2. 6월에 확진자가 가장 많이 나온 지역을 구하세요.
corona_out_region[corona_del_col['month'] == '6']['지역'].value_counts()관악구 59
구로구 45
도봉구 43
양천구 43
강서구 33
영등포구 29
타시도 23
은평구 18
금천구 17
서초구 15
중랑구 14
노원구 13
동작구 13
용산구 12
마포구 12
강동구 11
강북구 10
성동구 9
서대문구 8
강남구 7
송파구 7
성북구 4
동대문구 4
광진구 3
종로구 3
중구 3
기타 2
Name: 지역, dtype: int64- 답안
top = corona_out_region[corona_out_region["month"]=="6"]["지역"].value_counts()
top.index[0] # '관악구', value_counts()는 내림차순으로 데이터를 정렬하니까 제일 큰 값이 맨 앞에 있다
# 6월에 확진자가 가장 많이 나온 지역을 구하여 quiz_2 변수에 저장합니다.
# 문자형으로 저장합니다.
quiz_2 = top.index[0]
quiz_2 # '관악구'

파일이 어디있나요?