딥러닝 모델을 돌리다보면, 상당히 많이 볼 수 있는 에러중 하나인 CUDA Out Of Memeory가 있습니다.
이 에러는 모델 실행중 GPU 메모리 부족이 발생하였을 때 볼 수 있습니다. 메모리 부족이 일어나는 이유중 대부분의 이유는 높은 batch size가 있습니다.
batch size란 한번의 forward / backprop 를 위한 이미지의 수입니다. batch size가 학습에 큰 영향을 미치지 않는다면 상관이 없지만, batch size는 학습에 큰 영향을 줍니다. batch size가 큰 배치사이즈를 사용하는 이유는 학습시에 정보의 노이즈를 제거하고 더 나은 gradient decsent를 수행할수 있습니다. 하지만 많은 딥러닝을 공부하는 분들은 GPU 자원이 한정적이기 때문에 높은 batch size를 사용해서 학습하기에는 어려움이 있습니다.
이를 위한 해결책으로는 첫번째로는 batch size를 줄이는 방법이 있습니다. 두번째 방법은 nvidia-smi 로 실행중인 프로세스를 보고, 죽이는 방법이 있습니다. 이 방법은 만약 실행중인 프로세스가 없었다면 이 방법은 소용이 없습니다. 하지만 이렇게 두 방법의 경우 모델이 학습이 되도록 차선책을 제시하는것일 뿐 실질적으로 사용하고 싶은 batch size를 사용하지 못한다는 단점이 있습니다. 이번 포스팅에서는 gradient accumulation 방법을 통해서 위의 문제를 해결하는것을 확인해보겠습니다.
Gradient Accumulation
Gradient accumulation 의 동작원리를 사진을 통해서 보겠습니다.
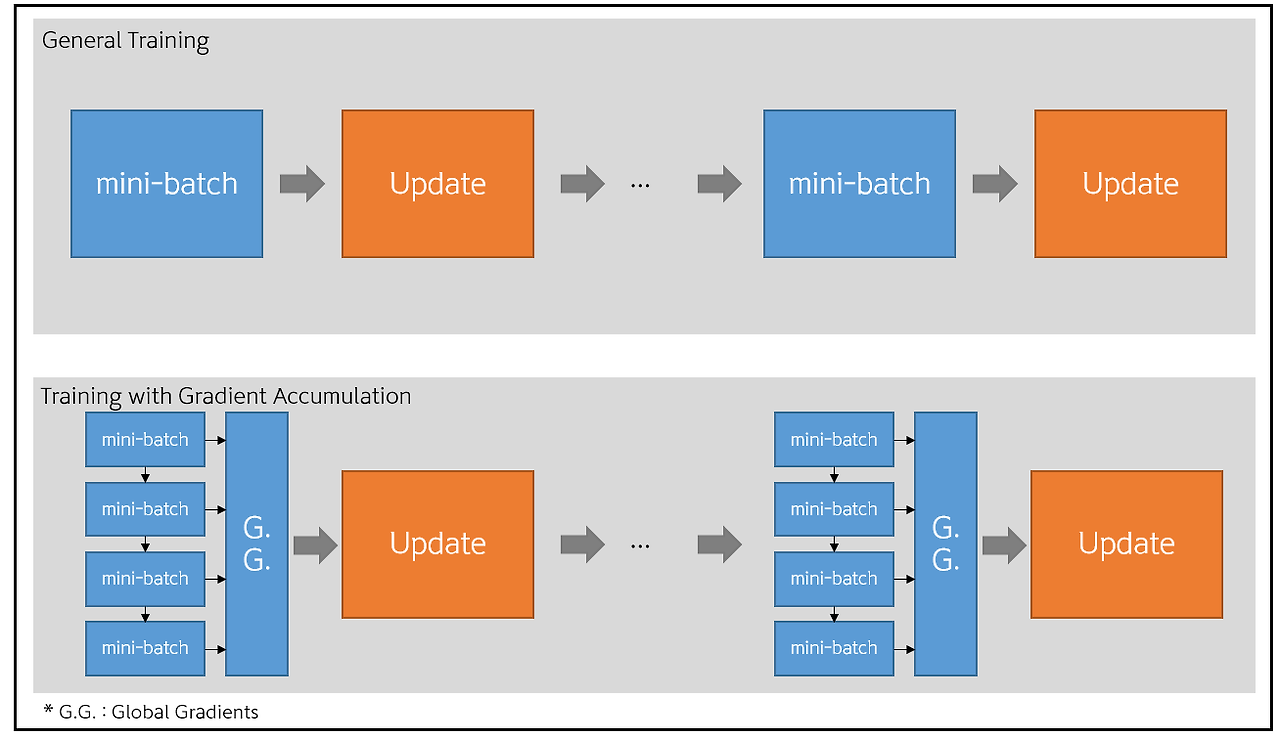 gradient accumulation의 동작
gradient accumulation의 동작
일반적인 방법
일반적인 방법은 batch size만큼의 이미지를 통해서 한번의 forward pass / back propagation를 진행합니다.
Gradient Accumulation 방법
Gradient Accumulation 방법은 미니 배치를 통해 구해진 gradient를 n-step동안 Global Gradients에 누적시킨 후, 한번에 업데이트하는 방법입니다. 예를 들어서 현재 batch size가 16이고 n-step 값이 16이면 batch size 16으로 16번의 gradient 축적을 통해서 한번의 forward/back propagation을 실행한다. 이렇게 되면 실제로 배치사이즈 256을 사용한 효과를 얻을 수 있으나, 훈련시간이 매우 길어질 수 있다는 단점이 있다.
적용전
# train my model
total_batch = len(data_loader)
model.train() # set the model to train mode (dropout=True)
print('Learning started. It takes sometime.')
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader:
# image is already size of (28x28), no reshape
# label is not one-hot encoded
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, avg_cost))
print('Learning Finished!')Gradient Accumulation 정확도(batch size 100)

# train my model
accumulation_steps = 20 #gradient accumulation step
total_batch = len(data_loader)
model.train() # set the model to train mode (dropout=True)
print('Learning started. It takes sometime.')
for epoch in range(training_epochs):
avg_cost = 0
#model().zero_grad()
for i, (X, Y) in enumerate(data_loader): #코드 변경
# image is already size of (28x28), no reshape
# label is not one-hot encoded
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost = cost / accumulation_steps
cost.backward()
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad()
avg_cost += cost / total_batch
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, avg_cost))
print('Learning Finished!')accumulation_steps =10 적용시 정확도 accumulation_steps =20 적용시 정확도
accumulation_steps =20 적용시 정확도
accumulation_step를 10 적용시에는 batch_size를 1000으로 설정한것과 같은 효과를 볼 수 있었고, accumulation_step를 20 적용시에는 batch_size를 2000으로 설정한것과 같은 효과를 볼 수 있었다.
정확도 측면에서는 accumulation_step이 높을 수록 더 높은 정확도를 보였다. 무조건 높은 배치사이즈가 더 좋은 성능을 내는것은 아니지만 이번 포스팅을 위한 실험에는 좋은 성능을 낼 수 있었고, 배치사이즈 문제로 OOM이 발생한다면, 시도해볼만 하다고 느꼈다.
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() 참고자료
nawnoes님 블로그
towards data science
대학원생이 쉽게 설명해보기님 블로그
마키나락스 류원탁님 블로그

3개의 댓글

글 잘 봤습니다 ㅎㅎ 감사합니다. 그런데 optimizer.zero_grad() 가 accumulation이 쌓이고 optimizer.step() 이 일어난 다음에만 사용돼야 하지 않나요? loss.backward() 로 gradient 가 accumulation step까지 쌓여야 하는데 매번 gradient 를 0으로 만들어서 안 쌓일 것 같습니다.
accumulation_step이 높을 수록 더 높은 정확도를 보이면 batch_size의 크기에 따라 상관이 없나요?
답변 부탁드립니다.