[Image Classification] Resnet
이번에 리뷰하게 될 논문은 Deep Residual Learning for Image Recognition입니다. 이 논문은 ResNet이라고 알려져있습니다. 이 ResNet은 2015년도에 ILSVRC에서 우승을 하였고, 총 152개의 레이어를 가진 매우 Deep한 네트워크 모델입니다. 저희 벨로그에서 리뷰한 AlexNet과 VGGNet과 비교하였을 때 매우 깊은 네트워크임 알 수 있습니다. 이렇게 깊은 네트워크를 구성하게 된다면 많은 문제점이 있는데 ResNet에서는 이 문제점들을 어떻게 해결 할 수 있었는지 자세히 살펴보도록 하겠습니다.
Problem of Plain Network
Plain Network란 무엇일까요? 여기서 Plain Network이란 AlexNet과 VGGNet과 같이 skip/shortcut connection(뒤에서 다룰 예정)을 사용하지 않은 네트워크들을 말합니다. 이러한 네트워크들은 네트워크의 깊이가 점점 깊어질 수록 문제점이 있는데 바로 gradient vainishing(기울기 소실)과 gradient exploding(기울기 폭발)입니다.
Gradient vanishing/exploding은 무엇일까?
Neural Network에서는 기울기를 구하기 위해서 가중치에 해당하는 손실 함수의 미분을 오차 역전파(Back Propagation)을 통해서 구하게 됩니다. 이 과정에서 활성화 함수(Activation Function)의 편미분을 구하고 그 값을 곱해줍니다. 이것은 layer가 뒷단으로 갈수록 활성화 함수의 미분값이 0으로 수렴하거나 매우 큰 값으로 발산하게 됩니다.
이렇게 신경망이 깊어질 때, 작은 미분 값이 여러번 곱해지게 되면 0에 가까워 지는 현상을 Gradient Vanishing(기울기 소실)이라고 합니다. 그 반대로 큰 미분값이 여러번 곱해지게 되면 매우 큰 값을 가지게 되고 이를 Gradient Exploding(기울기 폭발)이라고 합니다.
앞서 두 논문리뷰(AlexNet과 VGGNet)에서 더 깊은 신경망이 더 좋은 예측을 한다고 말씀드렸습니다. 하지만 너무 깊은 plain network는 학습이 어렵습니다. 다음 그림을 먼저 보겠습니다.
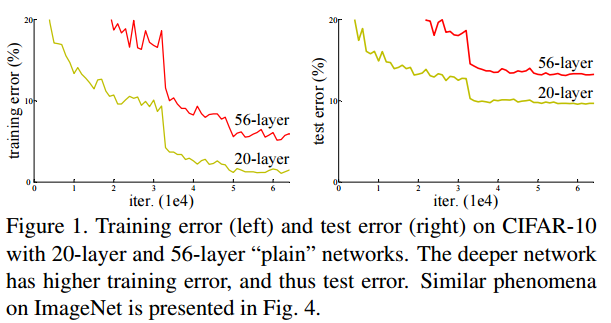
그림 1. deep plain network의 문제
더 깊은 56-layer의 network의 error rate가 20-layer의 error rate 보다 높은 이유는 본 논문에서는 degradation이라고 말하고 이는 위에서 설명한 gradeint vanishing과 동일한 문제입니다.
해당 논문에서는 layer를 깊게 쌓되 많은 layer들이 identity mapping으로 이루어지도록 만든다면 깊은 모델이 얕은 모델에 비해 높은 training error를 가지면 안되는 것이 gradient vanishing 문제를 해결하기 위한 핵심 idea라고 했습니다. 논문에서는 이러한 방법을 deep residual learning framework로 제시하였다.
Residual Learning

그림2 기존 네트워크의 학습방식
- 기존의 Neural Network의 underlying mapping이 H(x)라면, 즉 H(x)를 최소시키는 것이 학습의 목표였다면 해당 논문에서의 목표는 F(x) = H(x) - x 를 최소화시키는 Residual mapping으로 H(x)를 재정의 하였다.

그림3 ResNet의 Residual Learning
- 이러한 재정의 방식은 기존의 unreferenced mapping인 H(x)를 최적화 하는것보다 identity mapping 시킨 residual mapping F(x)가 더 최적화가 쉽다는 가정에서 시작하였다.
즉 H(x) = F(x) + x 로 정의가 됩니다. F(x) = 0이 되도록 학습하여 H(x) = 0+ x가 되도록 합니다. 이러한 방법의 특징은 위의 식을 미분하더라도 우항의 x가 미분되어 1이라는 값을 가지기 때문에 gradient vanishing 문제를 해결 할 수 있습니다. 이렇게 gradient vanishing를 문제를 해결하게 된다면 정확도가 감소되지 않고 신경망의 layer를 더욱 더 깊이 쌓을 수 있어 더 나은 성능의 신경망을 구축할 수 있습니다.
ResNet와 다른 네트워크의 구조 비교
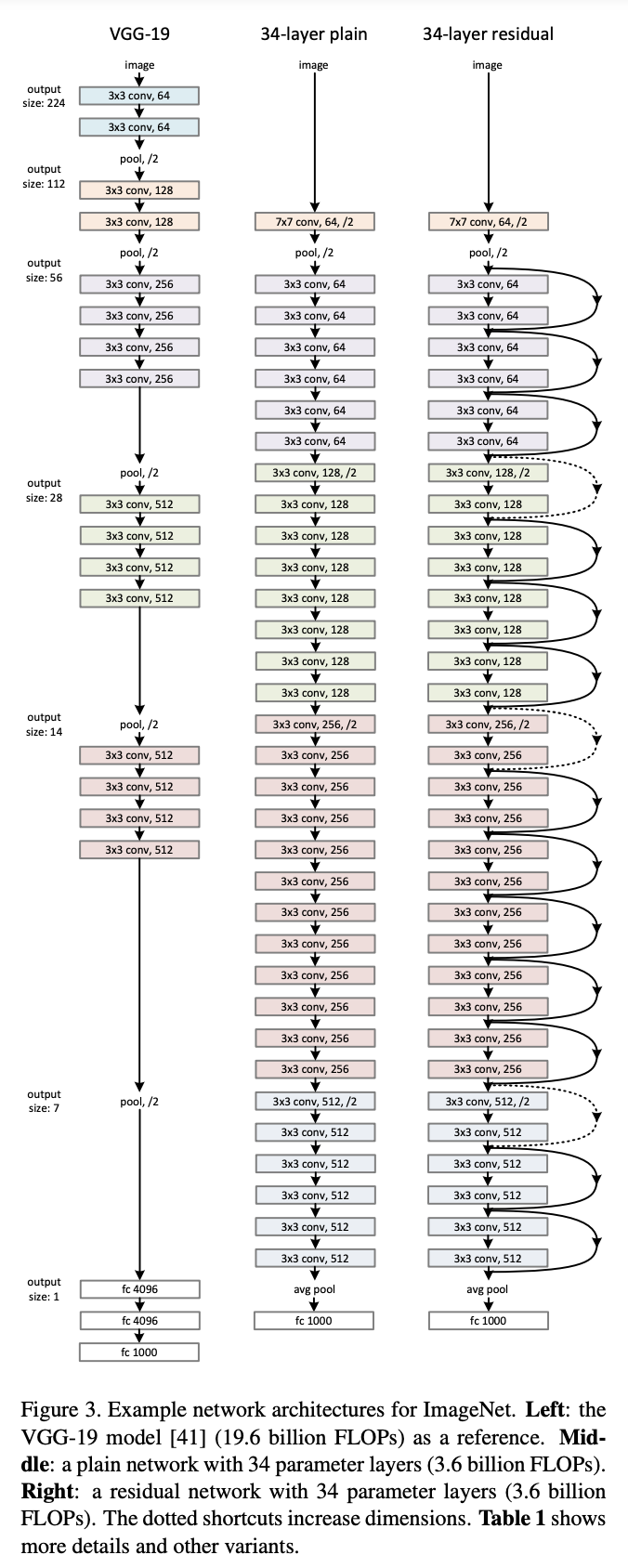
그림4 ResNet과 다른 네트워크와의 구조 비교
Architecture of Plain Networks
Plain baseline은 *VGG 에 영감을 받아 만들어졌다. 컨볼루션 레이어는 3x3 필터와 2개의 규칙으로 설계되었다.
- 같은 output feature의 map size와 같은 크기의 필터
- 만약 feature map의 size가 절반으로 줄어들면 filter의 depth가 2배로 늘어나서 시간복잡도를 보존함.
합성곱 레이어에서 stride 2로 down sampling하고 모델의 마지막엔 global average pooling, 1000 way fc layer, softmax를 사용하였다.
Architecture of Residual Network
Plain Network를 기반으로 하여 shortcut connection이 추가되었다.
Residaul Network는 input과 ouput을 같은 크기로 맞추어 주어야한다. 그렇게 하기 위해서 2가지를 고려해 볼 수 있다.
- zero padding을 통한 사이즈 맞춤(parameter 그대로)
- projection을 이용한 사이즈 맞춤
Implementation
- Scale Segmentation : 짧은 쪽 기준으로 256 ~ 480 size로 random resize, 각 이미지마다 224 x 224로 random crop 혹은 상하로 뒤집은 10장의 데이터를 사용함.
- 가중치 초기화
- SGD
- mini batch :256개
- learning rate : 0.1
- iterations : 60 x 10^4
- weight decay : 0.0001
- momentum : 0.9
- No Dropout
Experiments
Imagenet Classification**
 Table 1
Table 1
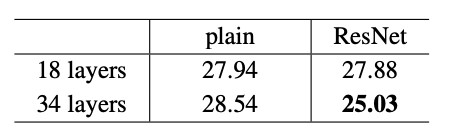
plain network의 경우 34-layer가 18-layer보다 성능이 좋지 않았다. 반면 ResNet은 34-layer가 18-layer보다 더 좋은 성능을 내는것을 확인 할 수 있다.
위 실험을 토대로 Residual network가(오른쪽 그래프) plain network(왼쪽 그래프)의 degradation 문제를 해결한 것을 나타내며 초기의 수렴 속도도 빠른것을 볼 수 있고 이를 통해 resnet의 optimization이 쉽다는 것을 알 수 있다.
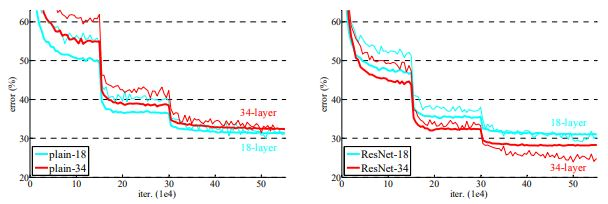
그림5. ResNet 결과
Table 1에서 50-layer 이상부터 구조가 조금 달라진 것을 볼 수 있었는데 이는 layer가 많아질 수록 parameter가 많아지게되며 FLOP 수가 늘어나 연산량이 많아지게되어 complexity가 높아져 이를 해결하기위해 bottleneck architecture를 사용하였다.

그림6 Bottle Neck 구조
Bottleneck은 기본적으로 연산량을 줄이기 위해 사용하며 GoogLeNet의 Inception구조 처럼 demension을 줄이기 위해 1x1 conv를 통해 channel수를 줄였다가 3x3 conv를 거친 후 다시 1x1 conv를 통해 channel수를 늘려주는 방식으로 위 그림에서 보다시피 연산량은 줄임으로서 complexity도 낮추었고 추가로 non-linear(ReLU)도 추가로 수행하여 학습에 도움을 주게된다.

위 tabel4를 통해 ImageNet에 대한 single model의 error rate가 resnet의 network가 깊어질 수록 낮아진다는 것을 보여주며 table5를 통해 esemble을 적용하면 성능이 더 좋아지는 것을 보여준다.
이렇게 이번 포스팅에서는 ResNet 논문을 읽고 구조와 특징에 대해서 살펴보게 되었고, 이 ResNet을 기반으로 하여금 더 좋은 성능을 내며 깊은 네트워크를 만들 수 있는 초석이 만들어져 많은 발전을 이룰 수 있었다고 생각이 든다.
참조
