
1. Mnist 데이터 가져오기
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
X_train, X_test = x_train/255, x_test/255 #이미지 데이저 정규화 픽셀 값을 0~255 사이의 정수에서 0~1 사이의 부동소수점 숫자로 변환
#이미지 데이터의 형태로 변환한다.
#흑백 이미지 사용위해 채널 1로 설정
X_train = X_train.reshape((60000, 28, 28, 1))
X_test = X_test.reshape((10000, 28, 28, 1))
2. 구조를 간단히 가지고 오기
구조를 간단히 가지고 오기
#텐서플로 사용하여 (Convolutional Neural Network, CNN)모델 정의 한다.
from tensorflow.keras import layers, models
model = models.Sequential([
#CConv2D: 2D 컨볼루션 레이어
layers.Conv2D(3, kernel_size = (3,3), strides=(1,1),
padding='same', activation = 'relu',
input_shape =(28,28,1)),
#이 레이어는 입력 이미지에 3*3 크기의 필터 적용한다.
#3은 필터(커널)의 개수로, 이는 모델이 학습할 특징의 개수이다.
#strides(1,1)는 필터가 이미지 위를 이동할 때의 간격을 나타낸다.
#padding은 입,출 크기를 동이랗게 유지하기 위해 입력 주변에 패딩을 추가한다.
#activation은 활성화 함수로 ReLU를 사용한다.
layers.MaxPool2D(pool_size=(2,2), strides=(2,2)),
#최대 풀링 레이어
#이 레이어는 2*2 영역에서 최댓값을 선택하여 특징 맵의 크기를 줄인다.
#pool_size는 풀링 영역 크기를 나타낸다.
#strides는 풀링 영역이 이동할 때의 간격을 나타낸다.
layers.Dropout(0.25),
#드롭아웃 레이어 : 이 레이어는 모델을 학습할 때 무작위로 뉴런의 일부를 끊어 과적합을 방지한다.
#0.25는 드롭아웃 비율로ㅡ 각 업데이트에서 25%의 뉴런을 무작위로 끊는다.
layers.Flatten(),
#이 레이어는 다차원 특징 맵을 1차원으로 변환하여 완전 연결 레이어에 전달
layers.Dense(1000, activation='relu'),
layers.Dense(10, activation = 'softmax')
#Dense: 완전 연결 레이어
#첫 연결 레이어는 1000개의 뉴런을 가지고 있고 ReLU 활성화 함수 사용
#두 번째 완전 연결 레이어는 10개의 뉴런을 가지고 있고 softmax 활성화 함수 사용
])
3. 모델 구조 요약
model.summary()
#출력결과
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 28, 28, 3) 30
max_pooling2d_1 (MaxPoolin (None, 14, 14, 3) 0
g2D)
dropout_1 (Dropout) (None, 14, 14, 3) 0
flatten_1 (Flatten) (None, 588) 0
dense_2 (Dense) (None, 1000) 589000
dense_3 (Dense) (None, 10) 10010
#출력 결과 요약
#1. conv2d_1 (Conv2D) (None, 28, 28, 3) 30
# 이 레이어는 입력 이미지에 3*3 크기의 3개 필터 적용한다. 바비어스 항이 있으므로 총 파라미터 개수는 3*3*1*3+3 = 30개
#2. max_pooling2d_1 (MaxPooling2D)
#2*2 영역에서 최대값을 선택하여 크기를 줄인다. 출력의 크기는 입력의 절반이다.
#3. dropout_1 (Dropout) (None, 14, 14, 3) 0
# 학습중에 뉴런을 무작위로 끊어 과적합을 방지한다.
#4. flatten_1 (Flatten)
#이 레이어는 다차원 입력을 1차원으로 평탄화한다. 14 *14 *3 =588
# 5.dense_2 (Dense) (None, 1000) 589000
# 이 완전 연결 레이어는 588개 입력과 1000개의 출력 뉴런을 가지고 있다.
# 파라미터 개수는 588*1000 + 1000 =589000개
#6. dense_3 (Dense) (None, 10) 10010
#1000개의 입력과 10개의 출력 뉴런을 가지고 있다. 파라미터는 1000*10+10 = 10010개
4. 구성한 레이더 확인
model.layers
[<keras.src.layers.convolutional.conv2d.Conv2D at 0x2354b439790>,
<keras.src.layers.pooling.max_pooling2d.MaxPooling2D at 0x2354b439c40>,
<keras.src.layers.regularization.dropout.Dropout at 0x2354a934d30>,
<keras.src.layers.reshaping.flatten.Flatten at 0x2354b44b160>,
<keras.src.layers.core.dense.Dense at 0x2354b44b430>,
<keras.src.layers.core.dense.Dense at 0x2354b44b550>]
5. 가중치 평균, 표준 편차 계산
#아직 학습하지 않은 conv 레이어의 웨이트의 평균
#컨볼루션 뉴럴 네트워크 모델의 첫 번째 레이어의 가중치를 분석하는 코드이다.
#이 코드는 모델이 아직 학습되지 않았을때, 평균과 펴준편차를 계산한다.
conv = model.layers[0]# 모델의 첫 레이어 가져온다.
conv_weights = conv.weights[0].numpy()# 컨볼루션 레이어의 가중치를 넘파이 배열로 변환
#weights[0]는 가중치 텐서, [1]은 바이어스 텐서를 반환한다.
#가중치 평균, 표준 편차 계산
conv_weights.mean(), conv_weights.std()
#평균 0.093, 가중치 0.23
(0.09303552, 0.23132293)
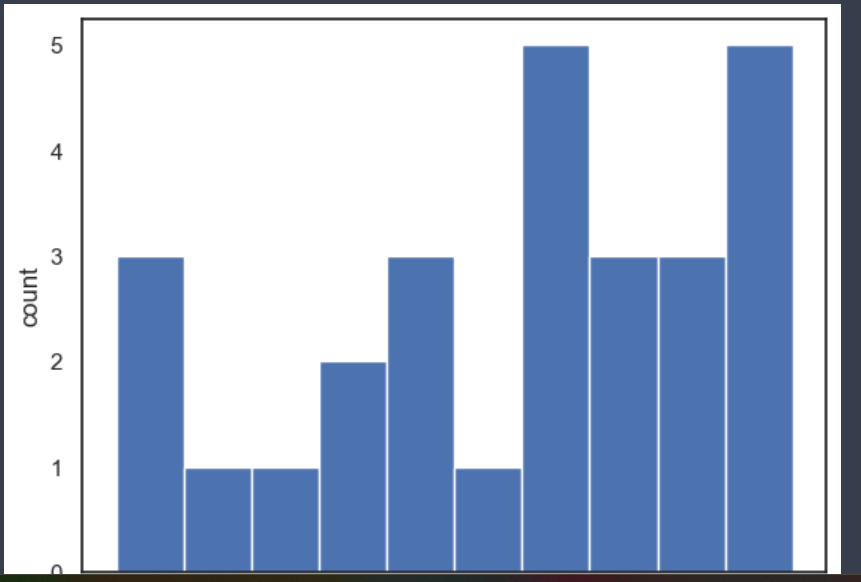
6. 가중치시각화
import matplotlib.pyplot as plt
plt.hist(conv_weights.reshape(-1,1))
plt.xlabel('weights')
plt.ylabel('count')
plt.show()
7. 가중치 시각화
fig, ax = plt.subplots(1,3, figsize=(15,5))
for i in range(3):
ax[i].imshow(conv_weights[:,:,0,i], vmin=-0.5, vmax=0.5)
ax[i].axis('off')
plt.show()

8. 컨볼루션 네트워크 모델 컴파일하고 학습하기
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
#최적화 알고리즘으로 Adam을 사용한다. adam은 경사 하강법의 변형으로 학습률을 자동으로 조정한다.
metrics= ['accuracy'])
#학습 과정에서 정확도를 평가 지표로 사용한다.
hist = model.fit(X_train, y_train, epochs=5, verbose=1,
#verbose=1 학습 과정을 상세하게 출력, 0은 출력하지 않음, 1은 진행 막대와 함께 출력, 2는 에포크당 한 줄씩 출력을 의미
validation_data = (X_test, y_test))
9. 학습 후 convfilte의 변화
#컨볼루션 레이어의 필터 가중치 시각화
fig, ax = plt.subplots(1,3, figsize=(15,5))
for i in range(3):
ax[i].imshow(conv_weights[:,:,0,i], vmin = -0.5, vmax = 0.5)
#imshow 함수는 2D 배열 압력으로 받아서 이미지 표시한다.
#ax[i]는 matplotlib의 subplot을 의미하며, i는 필터 인덱스이다.
#conv_weights[:, :, 0, i]: 컨볼루션 레이어의 가중치에서 i번째 필터를 선택합
#가중치는 (가로, 세로, 입력 채널, 필터 개수) 형태의 4차원 배열
ax[i].axis('off')
plt.show()
- 0번 데이터 5 plt.imshow(X_train[0], cmap='gray')

10. Conv 레이어에서 출력을 뽑는다.
inputs = X_train[0].reshape(-1, 28,28, 1)
conv_layer_output = tf.keras.Model(model.input, model.layers[0].output)
conv_layer_output.summary()
#출력
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1_input (InputLayer [(None, 28, 28, 1)] 0
)
conv2d_1 (Conv2D) (None, 28, 28, 3) 30
=================================================================
11. 입력에 대한 feature map을 뽑는다.
feature_maps = conv_layer_output.predict(inputs)
feature_maps.shape
#출력
1/1 [==============================] - 0s 19ms/step
(1, 28, 28, 3)
12.
feature_maps[0,:,:, 0].shape
# 출력(28, 28)
13.Feature map이 본 숫자 5
fig, ax = plt.subplots(1,3, figsize=(15,5))
for i in range(3):
ax[i].imshow(feature_maps[0, :, :, i])
ax[i].axis('off')
plt.show()

