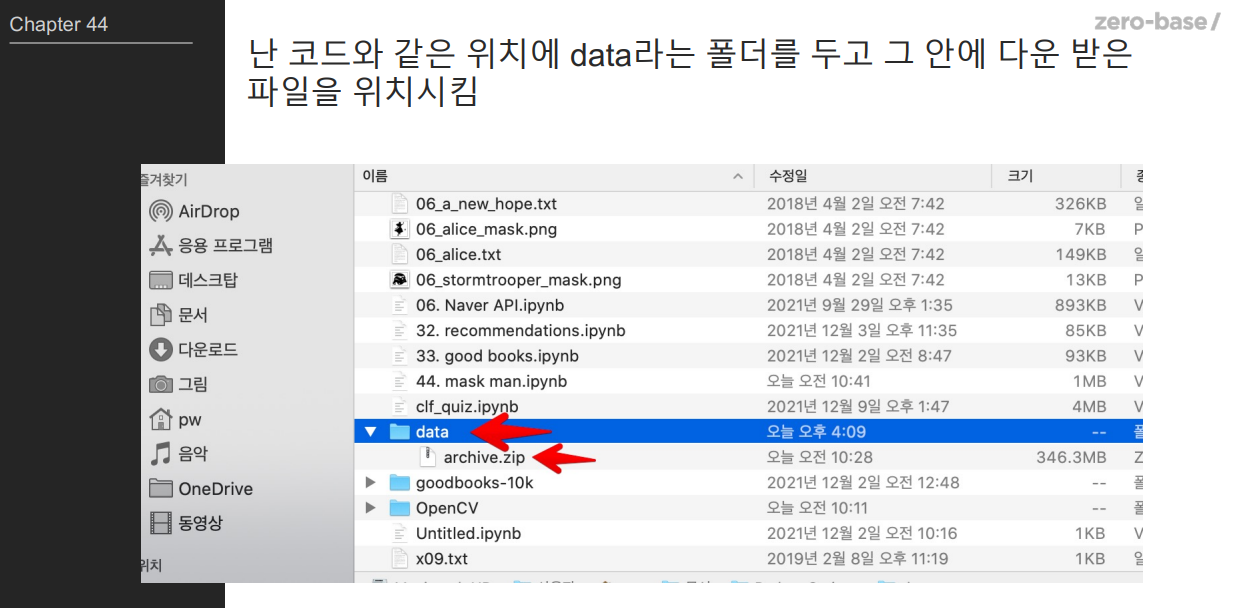
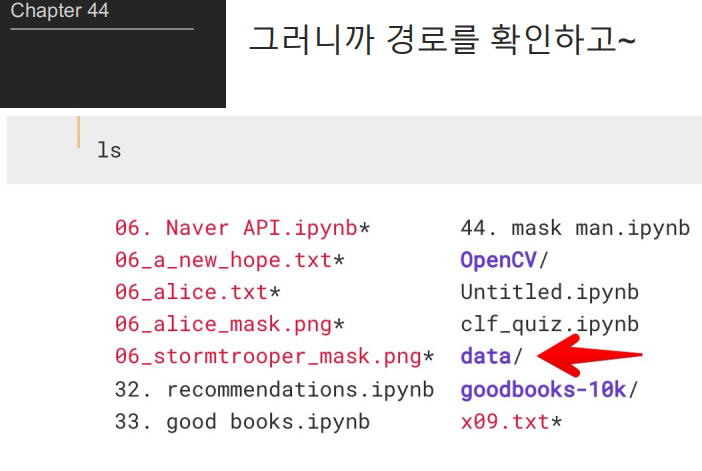
import numpy as np
import pandas as pd
import os
import glob
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import Sequential, models
from tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPool2D
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
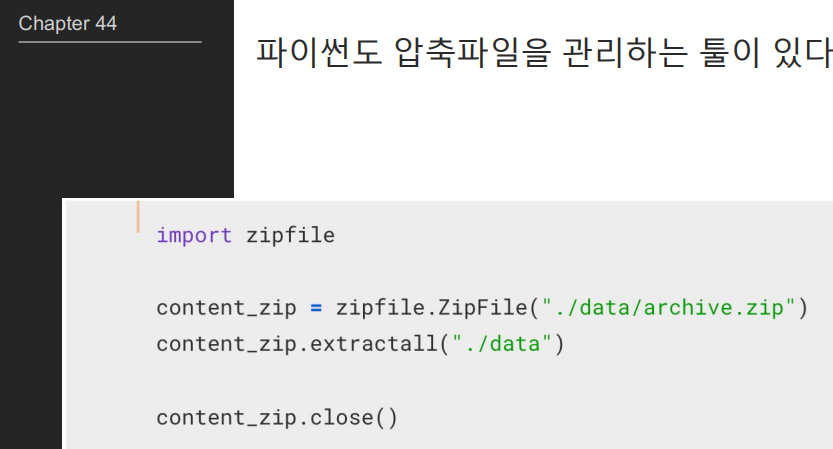
import zipfile
content_zip = zipfile.ZipFile('./data/archive (31).zip')
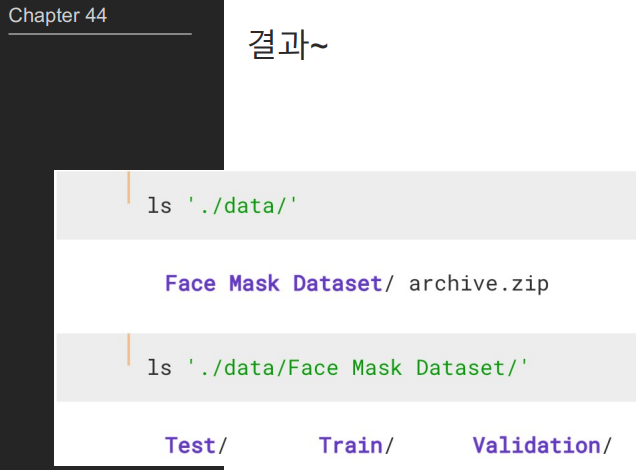
content_zip.extractall("./data")
content_zip.close()
1.특정 디렉토리 구조를 가진 이미지 데이터셋을 탐색하여, 이미지의 경로, 마스크 착용 상태, 이미지가 있는 위치를 저장한다.
path = "./data/Face Mask Dataset/"
#변수 초기화
dataset = {"image_path": [], "mask_status": [], "where": []}
for where in os.listdir(path):# path 디렉토리 내의 모든 하위 디렉토리를 순회한다. 각 하위 데렉토리는 where를 나타낸다.
for status in os.listdir(path + "/" + where):
for image in glob.glob(path + "/" + where + "/" + status + "/" + "*.png"):
#디렉토리 내의 모든 PNG 이미지 파일을 찾아서 순회한다. 여기서 glob.glob 함수를 사용하여 특정 패턴에 맞는 파일 경로를 찾는다.
dataset["image_path"].append(image)
dataset["mask_status"].append(status)
dataset["where"].append(where)
2. 추가하기
for where in os.listdir(path): # Train, Validation, Test
where_path = os.path.join(path, where)
if os.path.isdir(where_path):
for status in ['WithMask', 'WithoutMask']:
status_path = os.path.join(where_path, status)
if os.path.isdir(status_path):
for image in glob.glob(status_path + "/*.png"):
dataset["image_path"].append(image)
dataset["mask_status"].append(status)
dataset["where"].append(where)
3. 데이터 프레임
dataset = pd.DataFrame(dataset)
dataset.head()
4. With Mask와 Without Mask 갯수 확인
print('With Mask:', dataset.value_counts("mask_status")[0])
print('Without Mask:', dataset.value_counts("mask_status")[1])
sns.countplot(x=dataset["mask_status"]);
#출력 개수
#With Mask: 11818
#Without Mask: 11766
- WithMask와 WithoutMask

Mask man2
- 어떤 이미지들이 존재하는지 확인해보자
1. 이미지 확인
# 랜덤하게 어떤 그림들이 있느지 보자
import cv2
plt.figure(figsize=(15, 10))
for i in range(9):
random = np.random.randint(1, len(dataset))
plt.subplot(3, 3, i + 1)# 3*3 격자의 i +1 번쨰 위치에 서브플롯 생성
plt.imshow(cv2.imread(dataset.loc[random, "image_path"]))#OpenCV의 imread 함수를 사용하여 데이터셋에서 무작위로 선택된 이미지를 읽어온다.
plt.title(dataset.loc[random, "mask_status"], size=15)
#제목은 데이터셋에서 무작위로 선택된 행으 ㅣmask_status컬럼 값을 사용한다.
plt.xticks([])
plt.yticks([])
plt.show()

- 데이터 프레임
Train / test / validation으로 나눌 필요는 없다.
train_df = dataset[dataset["where"] =="Train"]
test_df = dataset[dataset["where"]== 'Test']
valid_df = dataset[dataset['where']=='Validation']
train_df.head(5)
- Train, Test, Validation 갯수 확인
plt.figure(figsize=(15,5))
plt.subplot(1, 3, 1)# 1행 3열 첫번째
sns.countplot(x=train_df['mask_status'])
plt.title('Training Dataset', size=10)
plt.subplot(1, 3, 2)#1행 3열 2번째
sns.countplot(x= test_df["mask_status"])
plt.title("Test Dataset", size=10)
plt.subplot(1, 3, 3)
sns.countplot(x=valid_df["mask_status"])
plt.title("Validation Dataset", size=10)
plt.show()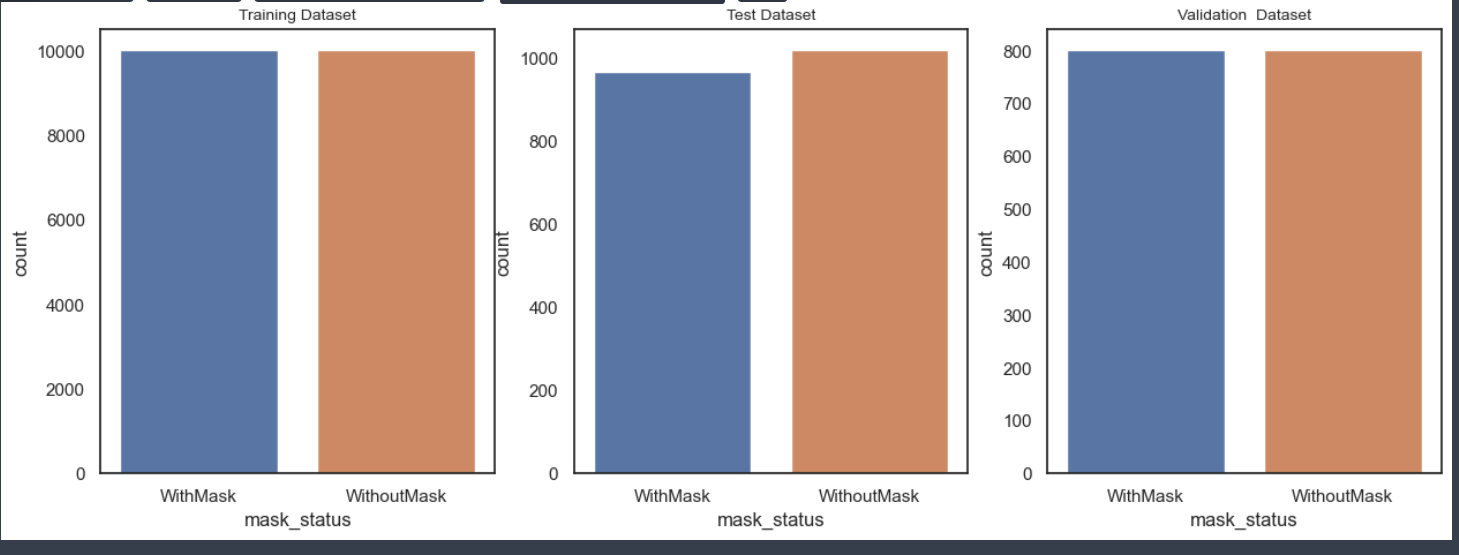
- 인덱스 정리
train_df = train_df.reset_index().drop('index', axis=1)
train_df.head()
1. 데이터 전처리
#이미지 데이터 전처리를 한다.
#주어진 학습 데이터 세트 train_df 내의 모든 이미지에 대해 다음과 같은 작업을 수행한다.
data= []
image_size =150
for i in range(len(train_df)):
img_array = cv2.imread(train_df['image_path'][i], cv2.IMREAD_GRAYSCALE) # i는 현재 처리중인 이미지의 위치를 나타낸다.
#OpenCV의 cv2.imread 함수를 사용하여 이미지를 읽는다.
#옵션은 이미지를 그레이스케일로 읽어들인다.
#읽어들인 이미지의 크기를 가로세로 조정
#150임으로 150*150 픽셀의 크기로 조정
# train_df['image_path'][i]
# image_path 컬럼의 i 즉 이미지를 가져온다
new_image_array = cv2.resize(img_array, (image_size, image_size))
#이미지 크기를 조정하는 역할을 한다.
#cv2.resize는 OpenCV의 함수로 첫 번째 인자로 주어진 이미지으 ㅣ크기를 두번째 인자로 주어진 크기로 조정한다.
#image_size, image_size)) 조정할 이미지의 새로운 크기를 나타낸다.
if train_df['mask_status'][i] == "WithMask":
#i번째 이미지가 마스크를 착용하고 있다면 라발 1을 data리스트에 추가
data.append([new_image_array, 1])
else:
data.append([new_image_array, 0])
2.data(이미지)를 한개 숫자로 출력해보자
data[0]
#출력
[array([[238, 238, 238, ..., 199, 199, 199],
[238, 238, 238, ..., 197, 197, 197],
[237, 237, 238, ..., 194, 194, 195],
...,
[236, 236, 236, ..., 151, 151, 152],
[235, 235, 235, ..., 151, 152, 152],
[235, 235, 235, ..., 151, 152, 152]], dtype=uint8),
1]
3. data 이미지를 무작위로 섞고 섞인리스트의 첫 번째 요소를 출력
np.random.shuffle(data)
data[0]
#출력
[array([[254, 254, 254, ..., 93, 147, 194],
[254, 254, 254, ..., 78, 129, 176],
[254, 254, 254, ..., 63, 108, 152],
...,
[249, 249, 250, ..., 111, 159, 197],
[249, 250, 250, ..., 59, 105, 146],
[250, 250, 250, ..., 22, 61, 101]], dtype=uint8),
0]
#4. 이미지가 섞여있는지 확인해보자
#저장된 이미지 데이터를 시각화하기 위한 것
fig, ax = plt.subplots(2, 3, figsize=(10, 6))
for row in range(2):
for col in range(3):
#2행 3열의 서브플롯 순회한다. row는 행인덱스, col은 열 인덱스
image_index = row * 100 + col# 사용할 이미지 인덱스 계산 이경우 행마다 100개씩 건너뛰어 이미지를 선택한다.
ax[row, col].axis('off')# 현재 서브플롯의 축을 끈다. 틱 레이블과 테두리를 제거하기위함
ax[row, col].imshow(data[image_index][0], cmap = 'gray')# 현재서브플롯에 이미지 표시 (인덱스 0에 해당하는 원소를 가져온다.)
if data[image_index][1] == 0:
ax[row, col].set_title("Without Mask")
else:
ax[row, col].set_title("With Mask")
- X,y 데이터로 저장
X = []
y = []
for image in data:
X.append(image[0])
y.append(image[1])
X = np.array(X)
y = np.array(y)
- 트레인 데이터로 다시 나누기
#트레인 데이터로 다시 나누기
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2,
random_state= 13)
mask man 3
1.Convolutional Neural Network (CNN) 모델을 구축
from tensorflow.keras import layers, models
#Convolutional Neural Network (CNN) 모델을 구축
model = models.Sequential(
[
layers.Conv2D( #Conv2D Layer: 32개의 필터와 5x5 크기의 커널을 사용하는 convolutional layer
32, kernel_size=(5,5), strides= (1,1), padding = "same",
activation = "relu", input_shape = (150, 150, 1)),
#strides=(1, 1)은 컨볼루션 연산 시 필터의 이동 간격
#padding="same"은 입력 이미지의 크기를 유지하기 위해 패딩을 추가
#activation="relu"는 ReLU 활성화 함수
#input_shape=(150, 150, 1)는 모델이 받아들일 수 있는 입력 이미지의 크기와 채널 수를 지정
layers.MaxPooling2D(pool_size=(2,2), strides=(2,2)),
#MaxPooling2D Layer: 또 다른 최대 풀링 레이어로, 2x2 크기의 풀링 윈도우를 사용
layers.Conv2D(64, (2, 2), activation = "relu", padding="same"),
#Conv2D Layer: 64개의 필터와 2x2 크기의 커널을 사용하는 또 다른 convolutional layer입니다. activation="relu"와 padding="same"는 이전과 동일
layers.MaxPooling2D(pool_size=(2,2)),
#MaxPooling2D Layer: 또 다른 최대 풀링 레이어로, 2x2 크기의 풀링 윈도우를 사
layers.Dropout(0.25),
Dropout Layer:# 과적합을 방지하기 위해 뉴런의 일부를 무작위로 비활성화하는 드롭아웃 레이어
layers.Flatten(),
#Flatten Layer: 다차원의 피처맵을 1차원으로 변환하여 완전 연결된 레이어에 전달
layers.Dense(1000, activation = 'relu'),
#Dense Layer: 1000개의 뉴런을 가지는 완전 연결된 레이어입니다. 활성화 함수로는 ReLU
layers.Dense(1, activation = 'sigmoid'),
#Dense Layer: 1개의 뉴런을 가지는 완전 연결된 레이어로, 활성화 함수로는 시그모이드가 사용
#이 레이어는 최종 출력을 생성하며, 시그모이드 함수를 사용함으로써 출력값은 0과 1
]
)
#2. 컴파일
#신경망 모델을 컴파일 최적화 알고리즘, 손실 함수, 평가 지표를 설정
model.compile(
optimizer="adam", loss = tf.keras.losses.BinaryCrossentropy(),
#optimizer: 최적화 알고리즘을 설정합니다. 여기서는 "adam" 최적화 알고리즘을 사용
#Adam은 경사 하강법의 변형으로, 학습률을 조정하면서 모델의 가중치를 업데이트
#loss: 손실 함수를 설정 이진 분류 문제에 적합한 BinaryCrossentropy 손실 함수를 사용
metrics= ["accuracy"]
# metrics: 모델의 성능을 평가하는 데 사용할 지표를 설정. 여기서는 "accuracy" (정확도)를 사용하여 모델의 예측이 얼마나 정확한지 평가
)
3.신경망 모델을 학습시키기 전 데이터를 전처리하고 그 다음 모델을 학습시키는 과정
X_train = X_train.reshape(len(X_train), X_train.shape[1], X_train.shape[2], 1)
#X_train은 훈련 데이터의 피처(이미지)를 담고 있는 넘파이 배열
#reshape 함수는 배열의 형태를 변경합니다. 이 경우, 각 이미지의 형태를 (높이, 너비, 채널)로 변경
#흑백 이미지의 경우 채널 수는 1이므로 마지막 차원을 1로 설정
#len(X_train)은 훈련 데이터의 샘플 수를 나타냅니다.
#X_train.shape[1]과 X_train.shape[2]는 각각 이미지의 높이와 너비
X_val = X_val.reshape(len(X_val), X_val.shape[1], X_val.shape[2], 1)
history = model.fit(X_train, y_train, epochs=4, batch_size=32)
4. 모델 성능 평가 확인
# Validation accuracy가 나쁘지 않다.
# model.evaluate 함수는 신경망 모델의 성능을 평가하는 데 사용
# 모델이 얼마나 잘 예측하는지를 측정하기 위해 손실 함수의 값을 계산하고, 추가로 설정된 평가 지표(예: 정확도)를 계산
model.evaluate(X_val, y_val)
#X_val: 검증 데이터 세트의 피처(이미지)
#y_val: 검증 데이터 세트의 실제 라벨
#첫 번째 요소는 모델의 손실값으로, 낮을수록 좋다
#두 번째 요소는 모델의 정확도로, 0에서 1 사이의 값이며 높을수록 좋다
#출력
[0.31497207283973694, 0.8675000071525574]
5.precision, recall, f1-score support 확인
#상대적으로 0에 대한 recall이 조금 떨어진다.
#이 코드는 훈련된 신경망 모델을 사용하여 검증 데이터 세트 X_val에 대한 예측을 수행하고, 이 예측의 성능을 평가
prediction = (model.predict(X_val) > 0.5).astype("int32")
#model.predict(X_val)은 X_val에 있는 각 이미지에 대해 모델이 마스크를 착용하고 있다고 예측하는 확률을 반환
#확률이 0.5보다 큰 경우를 True (1)로, 그렇지 않으면 False (0)로 변환
print(classification_report(y_val, prediction))
#모델의 성능을 평가하기 위해 주로 사용되는 여러 지표를 계산하여 출력
print(confusion_matrix(y_val, prediction))
#confusion_matrix는 모델의 성능을 평가하기 위한 혼동 행렬을 계산하여 출력
#혼동 행렬은 실제 라벨과 예측 라벨의 관계를 나타낸다.
#출력
125/125 [==============================] - 10s 82ms/step
precision recall f1-score support
0 0.98 0.75 0.85 2010
1 0.80 0.98 0.88 1990
accuracy 0.87 4000
macro avg 0.89 0.87 0.87 4000
weighted avg 0.89 0.87 0.87 4000
[[1516 494]
[ 36 1954]]
6. 틀린것 추리기
#틀린것만 추리기
#위 X_val 코드를 실행하지 않아서 강의와 결과값이 다르다.
wrong_result = []
for n in range(0, len(y_val)):
if prediction[n] != y_val[n]:
wrong_result.append(n)
len(wrong_result)
# 530이 나오는데 이것슨 정답이 아니다.
7. 이미지 시각화
import random
samples = random.choices(population = wrong_result, k = 6)
plt.figure(figsize=(14,12))
for idx, n in enumerate(samples):
plt.subplot(3, 2, idx + 1)
plt.imshow(X_val[n].reshape(150, 150), interpolation = "nearest")
plt.title(prediction[n])
plt.axis("off")
plt.show()

