예제1
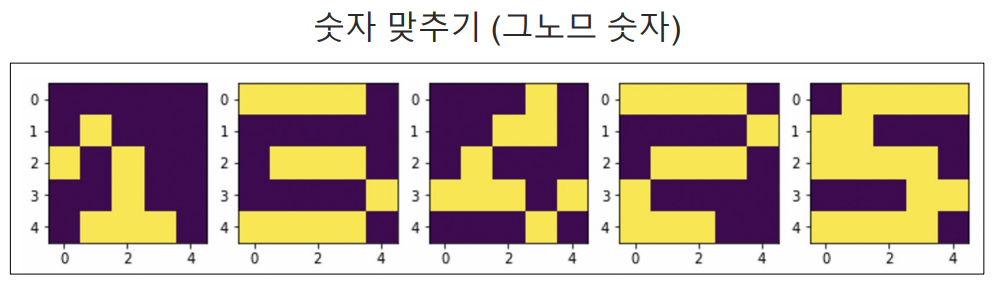
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm_notebook
def Softmax(x):
x = np.subtract(x, np.max(x))
ex = np.exp(x)
return ex / np.sum(ex)
X = np.zeros((5,5,5))
X[:, :, 0] = [[0,1,1,0,0], [0,0,1,0,0], [0,0,1,0,0], [0,0,1,0,0], [0,1,1,1,0]]
X[:, :, 1] = [[1,1,1,1,0], [0,0,0,0,1], [0,1,1,1,0], [1,0,0,0,0], [1,1,1,1,1]]
X[:, :, 2] = [[1,1,1,1,0], [0,0,0,0,1], [0,1,1,1,0], [0,0,0,0,1], [1,1,1,1,0]]
X[:, :, 3] = [[0,0,0,1,0], [0,0,1,1,0], [0,1,0,1,0], [1,1,1,1,1], [0,0,0,1,0]]
X[:, :, 4] = [[1,1,1,1,1], [1,0,0,0,0], [1,1,1,1,0], [0,0,0,0,1], [1,1,1,1,0]]
plt.figure(figsize=(12,4))
for n in range(5):
plt.subplot(1, 5, n+1)
plt.imshow(X[:,:,n])
plt.show()
예제2(ReLU 이용한 정방향 계산)
1. ReLU 함수 정의
import numpy as np
from tqdm.notebook import tqdm
def ReLU(x):
return np.maximum(0, x)
def Softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
2.ReLU를 이용한 정방향 계산
def calcOutput_ReLU(W1, W2, W3, W4, x):
v1 = np.matmul(W1, x)
y1 = ReLU(v1)
v2 = np.matmul(W2, y1)
y2 = ReLU(v2)
v3 = np.matmul(W3, y2)
y3 = ReLU(v3)
v = np.matmul(W4, y3)
y = Softmax(v)
return y,v1, v2, v3, y1, y2, y3
3. 역전파
def backpropagation_ReLU(d, y, W2, W3, W4, v1, v2, v3):
e = d - y
delta = e
e3 = np.matmul(W4.T, delta)
delta3 = (v3 > 0)*e3
e2 = np.matmul(W3.T, delta3)
delta2 = (v2 > 0) *e2
e1 = np.matmul(W2.T, delta2)
delta1 = (v1 > 0)*e1
return delta, delta1, delta2, delta3
4. 가중치 계산
def calcWs(alpha, delta, delta1, delta2, delta3, y1, y2, y3, x, W1, W2, W3, W4):
dW4 = alpha * delta * y3.T
W4 = W4 + dW4
dW3 = alpha * delta3 * y2.T
W3 = W3 + dW3
dW2 = alpha * delta2 * y1.T
W2 = W2 + dW2
dW1 = alpha * delta1 * x.T
W1 = W1 + dW1
return W1, W2, W3, W4
5. 가중치 업데이트
def DeepReLU(W1, W2, W3, W4, X, D, alpha):
for k in range(5):
x = np.reshape(X[:,:,k], (25,1))
d = D[k, :][:,np.newaxis]
y, v1, v2, v3, y1, y2, y3 = calcOutput_ReLU(W1, W2, W3, W4, x)
delta, delta1, delta2, delta3 = backpropagation_ReLU(d, y, W2, W3, W4, v1, v2, v3)
W1, W2, W3, W4 = calcWs(alpha, delta, delta1, delta2, delta3, y1, y2, y3, x, W1, W2, W3, W4)
return W1, W2, W3, W4
6. 학습하기
import tqdm
W1 = 2 * np.random.random((20,25)) - 1
W2 = 2 * np.random.random((20,20)) - 1
W3 = 2 * np.random.random((20,20)) -1
W4 = 2 * np.random.random((5,20)) - 1
alpha = 0.01
for epoch in tqdm.tqdm_notebook(range(10000)):
W1, W2, W3, W4 = DeepReLU(W1, W2, W3, W4, X, D, alpha)
7. 훈련 데이터 검증
def verify_algorithm(x, W1, W2, W3, W4):
v1 = np.matmul(W1, x)
y1 = ReLU(v1)
v2 = np.matmul(W2, y1)
y2 = ReLU(v2)
v3 = np.matmul(W3, y2)
y3 = ReLU(v3)
v = np.matmul(W4, y3)
y = Softmax(v)
return y
8. 결과
N = 5
for k in range(N):
x = np.reshape(X[:,:,k], (25,1))
y = verify_algorithm(x, W1, W2, W3, W4)
print("Y = {}:".format(k+1))
print(np.argmax(y, axis=0) + 1)
print(y)
print('--------')
Y = 1:
[1]
[[9.99961397e-01]
[1.39639399e-08]
[2.81797726e-05]
[7.19283051e-10]
[1.04086870e-05]]
--------
Y = 2:
[2]
[[6.85400057e-06]
[9.99975499e-01]
[9.74599451e-06]
[7.90080899e-06]
[5.09081220e-12]]
--------
Y = 3:
[3]
[[1.90029615e-05]
[7.06403933e-06]
[9.99942559e-01]
[3.13728426e-05]
[1.40261217e-09]]
--------
Y = 4:
[4]
[[3.94499217e-08]
[1.86645168e-05]
[1.98764111e-05]
[9.99961411e-01]
[8.48558374e-09]]
--------
