- 정밀도(Precision): 모델이 양성 클래스로 예측한 샘플 중 실제로 양성 클래스에 속한 샘플의 비율을 나타낸다.
- 재현율(Recall): 재현율은 실제로 양성 클래스에 속한 샘플 중 모델이 양성 클래스로 올바르게 예측한 샘플의 비율을 나타낸다.
- 트레이드 오프: 정밀도와 재현율은 서로 상충 관계에 있으며 한 지표를 높이려면 다른 지표가 낮아진다. 이것이 정밀도와 재현율의 트레이드 오프이다.
- 임계값 증가: 임계값을 높이면 정밀도(Precision)증가하고 재현율(Recall)감소
- 임계값 감소: 모델의 임계값을 낮추면 재현율(Recall) 증가하고 정밀도(Precision) 감소한다.
#데이터분리
import pandas as pd
red_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv'
white_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv'
white_wine = pd.read_csv(white_url, sep=';')
red_wine = pd.read_csv(red_url, sep=';')
red_wine['color'] = 1.
white_wine['color'] = 0.
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'],axis=1)
y = wine['taste']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train,y_test = train_test_split(X, y, test_size=0.2, random_state=13
#간단한 로지스틱 회귀 적용
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(solver='liblinear', random_state=13) #solver=liblinear (로지스틱 회귀의 최적화 문제 해결)lr = LogisticRegression(solver='liblinear', random_state=13) #solver=liblinear (로지스틱 회귀의 최적화 문제 해결)
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train) # 위에서 X_train을 학습했는데 왜 또하느냐.... 수치를 확인하기 위함이다!
y_pred_test = lr.predict(X_test)
print('Train Acc :' ,accuracy_score(y_train, y_pred_tr))
print('Test Acc :' ,accuracy_score(y_test, y_pred_test))
#Train Acc : 0.7427361939580527
#Test Acc : 0.7438461538461538
from sklearn.metrics import classification_report
print(classification_report(y_test, lr.predict(X_test))) #모델 분류 성능 요약 보고서 출력
#출력
#macro avg 평균이라고 생각
precision recall f1-score support
0.0 0.68 0.58 0.62 477
1.0 0.77 0.84 0.81 823
accuracy 0.74 1300
macro avg 0.73 0.71 0.71 1300
weighted avg 0.74 0.74 0.74 1300
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, lr.predict(X_test))
)
# [275, 202] --> 0을 275개 1을 202개 (0 갯수를 제대로 못맞춤)
# [131, 692] 1을 692개 맞춤
#출력
#[[275 202]
#[131 692]]
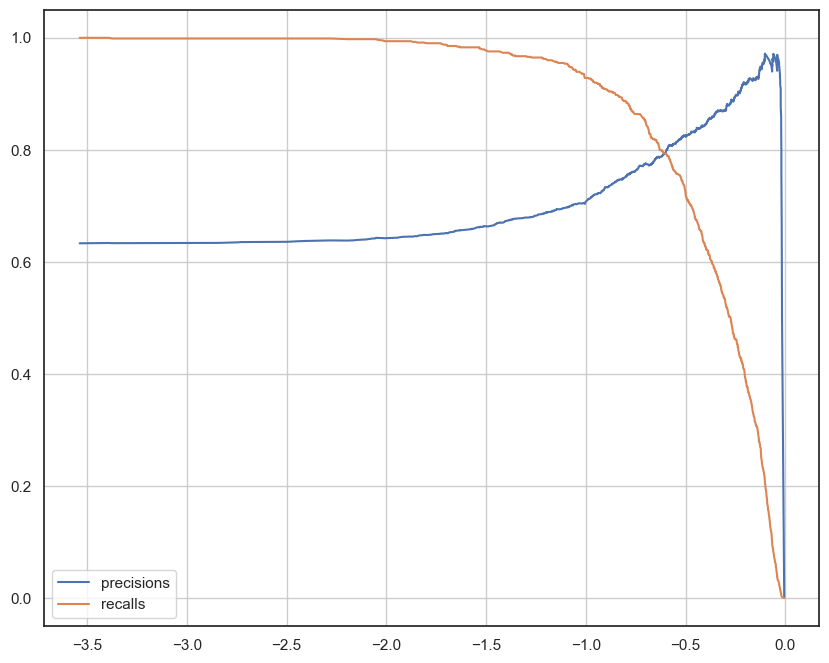
Precision_recall curver
Precision=Recall Curver(정밀도 -재현율 곡선): 분류 모델 성능을 시각적으로 평가하기 위한 그래프이다. 이 곡선은 임계값(threshold)에서 정밀도와 재현율의 값을 나타낸다.
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
plt.figure(figsize=(10, 8))
pred = lr.predict_log_proba(X_test)[:, 1] # 클래스별로 확률 계산
#log_proba 로그(X_test) 확률을 예측한다.
#[:,1] 로그 확률에서 두번째열을 선택하는 부분() 0또는1)
precisions, recalls, thresholds = precision_recall_curve(y_test, pred)
#정밀도, 재현율, 임계값
plt.plot(thresholds, precisions[:len(thresholds)], label='precisions')
#x좌표 thresholds y좌표 precisions label은 선또는 점에대한 레이블을 지정한다.
plt.plot(thresholds, recalls[:len(thresholds)], label='recalls')
plt.grid()
plt.legend()
#예측결과 확인
#예측결과 확인 (0또는 1)
pred_proba = lr.predict_proba(X_test)
pred_proba[:3]
#0에속할확률 0.405
#1에속할확률 0.594
#왼쪽은 0에속할확률 오른쪽은 1에속할 확률이다
#출력
#array([[0.40526731, 0.59473269],
# [0.50957556, 0.49042444],
# [0.10215001, 0.89784999]])
pred_proba
#array([[0.40526731, 0.59473269],
# [0.50957556, 0.49042444],
# [0.10215001, 0.89784999],
# ...,
# [0.22540242, 0.77459758],
# [0.67366935, 0.32633065],
# [0.31452992, 0.68547008]])
y_pred_test.reshape(-1,1).shape #reshape를 사용하는이유는 pred_proba 옆에다 추가를 해야하는데
#pred_proba가 리스트가 2개로 구성되어있는 형태라서 예측값(y_pred_test)도 리스트로 만들어주는 작업이다.
#코드해석: -1은 차원의 크기를 자동으로 계산하라는 의미이며 1은 열의개수를 1로 지정한다.(배열의 원래 모양을 유지하되 열 벡터로 재구조화 하라는 의미)
# 위에 y_pred_test.shape를 (1300,1)로 나오게끔 만들기
#pred_proba 옆에다 y_pred_test(예측값) 추가하기
import numpy as np
np.concatenate([pred_proba, y_pred_test.reshape(-1,1)], axis=1)
#array([[0.40526731, 0.59473269, 1. ],
# [0.50957556, 0.49042444, 0. ],
# [0.10215001, 0.89784999, 1. ],
# ...,
# [0.22540242, 0.77459758, 1. ],
# [0.67366935, 0.32633065, 0. ],
# [0.31452992, 0.68547008, 1. ]])
threshold 바꿔보기 Binarizer
Binarizer: 연속형(continuous)데이터를 이진(binary)형식으로 변환하며
Binarizer를 사용하면 특정 임계값(threshold)을 기준으로 입력 데이터를 이진 형태로 변환한다.
#Binarizer 클래스를 사용하여 예측 확률을 이진화하는 작업 수행
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=0.6).fit(pred_proba) #쓰레스홀드 매개변수를 0.6으로 설정하여 임계값 0.6으로 지정
#proba --> 예측 확률을 이진화
pred_bin = binarizer.transform(pred_proba)[:,1]#transform 메소드를 사용하여 pred_proba의 예측 확률을 이진화한다.
pred_bin
# 예측 확률을 0또는 1로변환 예측 확률이 임계값(0.6)보다 크면1 작으면 0으로 변
# 출력 array([0., 0., 1., ..., 1., 0., 1.])
#replort 사용
print(classification_report(y_test, lr.predict(X_test)))
# precision recall f1-score support
#
# 0.0 0.68 0.58 0.62 477
# 1.0 0.77 0.84 0.81 823
#
# accuracy 0.74 1300
# macro avg 0.73 0.71 0.71 1300
#weighted avg 0.74 0.74 0.74 1300
