1. 앙상블

앙상블(Ensemble): 다양한 학습 알고리즘을 결합 하여 더 강력하고 안정적인 모델을 만드는 방법. 앙상블은 단일 모델보다 더 좋은 예측 성능을 달성하고 모델의 과적합을 줄인다. 분류(Classfication) 및 회귀(Regression)문제에서 사용된다.
- 설명
- 다양한 알고리즘 사용: 앙상블은 서로 다른 학습 알고리즘을 사용하는 여러 모델을 결합 ex) 결정 트리, 랜덤 포레스트, 그래디언트 부스팅
- 장점
- 예측 성능 향상: 여러 모델의 예측을 결합하기 때문에 단일 모델보다 높은 예측 성능을 제공할 수 있다.
- 과적합 감소: 다양한 모델을 결합하면 과적합(Overfitting)을 줄일 수 있다.
- 안정성 향상: 앙승블은 모델의 안정성을 높인다.
- 종류
- 랜덤 포레스트, 그래디언트 부스팅, 에이다부스트, 배깅
2. voting
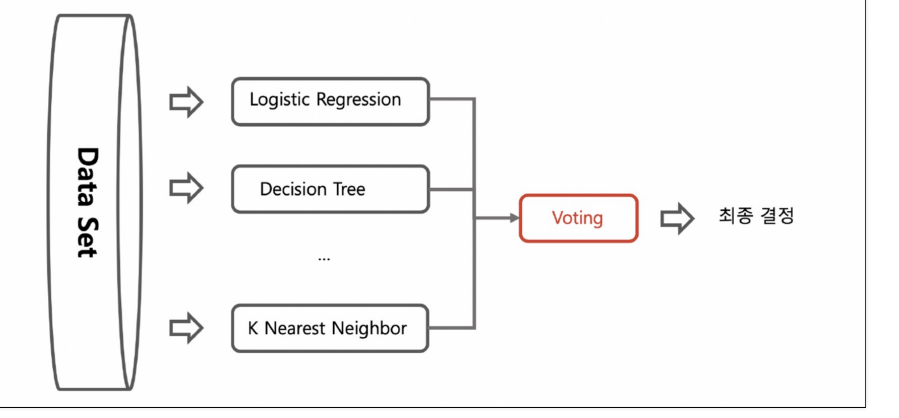
앙상블 투표(voting)는 앙상블 학습 기법중 하나이며 다른 모델 예측을 결합하여 최종 예측을 만드는 방법이다. 이 방법은 분류(Classification)문제에서 사용되며
여러 모델로부터 얻은 예측 결과를 투표를 통해 다수결 원칙에 따라 최종예측을 선택
- 투표 종류
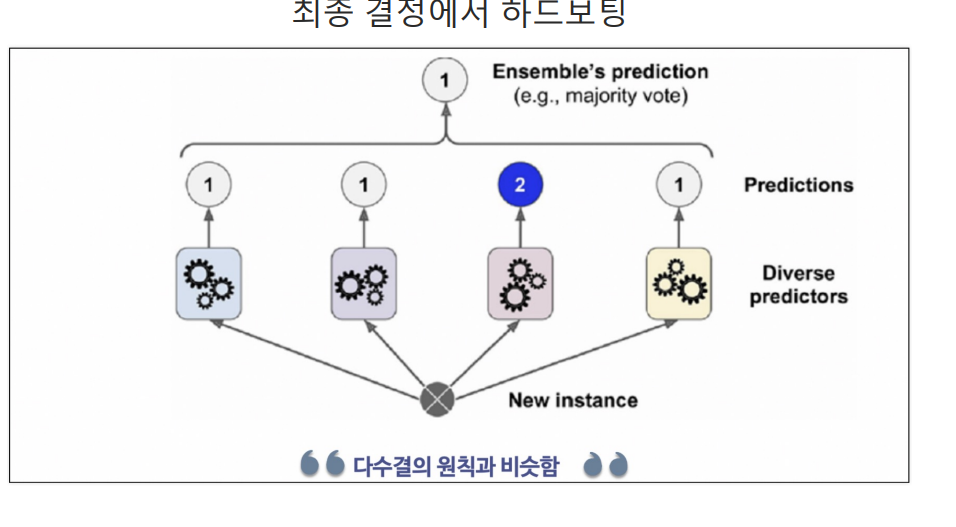
- 하드 투표(Hard Voting): 다수의 모델 중에서 가장 많은 모델이 예측한 클래스 레이블을 최종 예측으로 선택 이 방식은 이진 분류 문제나 다중 클래스 분류 문제에서 사용
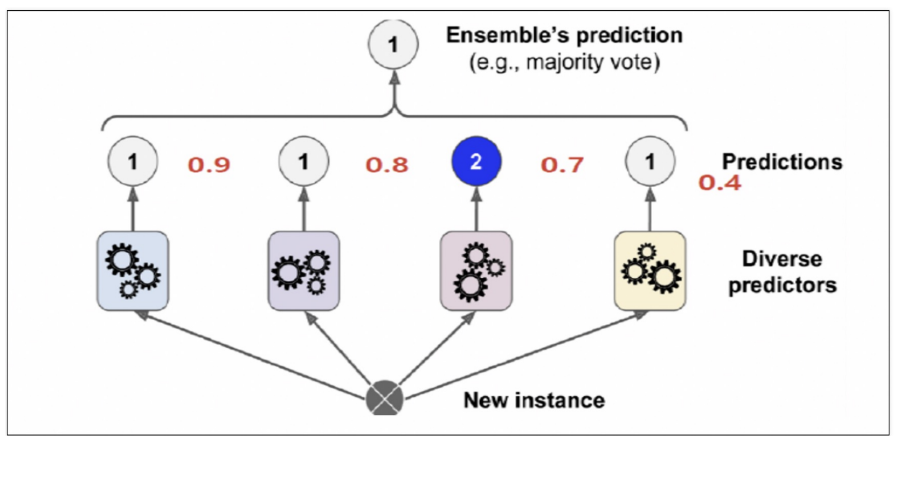
- 소프트 투표(Soft Voting): 다수의 모델로부터 얻은 확률 예측값을 평균하거나 가중 평균하여 가장 높은 확률을 가진 클래스 레이블을 최종 예측으로 선택
- 가중 투표(Weighted Voting): 다수의 모델의 예측에 각각 가중치를 부여하고, 가중 평균을 통해 최종 예측을 선택 이 방식은 모델의 신뢰도에 따라 가중치를 조절할 때 사용
hard voting
soft voting
3. bagging
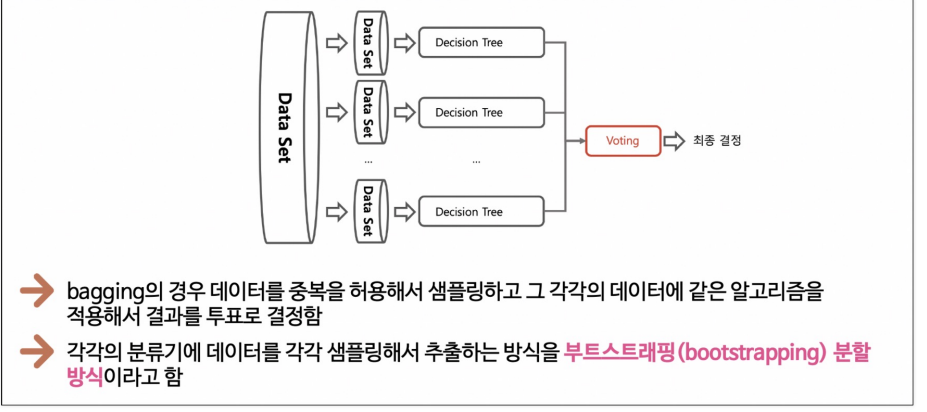
bagging(Bootstrap Aggregating)은 앙상블 학습(Ensemble Learning) 기법 중 하나로, 동일한 기계 학습 알고리즘을 사용하는 여러 모델을 훈련시키고, 이들 모델의 예측 결과를 결합하여 좀더 안정적인 모델을 만드는 방법이다. 주로 과적합을 줄이고 예측 성능 향상
- 설명
- 표본 복원 샘플링(Bootstrap Sampling): 배깅은 원래 데이터셋에서 부트스트랩 샘플(Bootstrap Sample)을 생성하여 각 모델을 훈련한다. 부트스트랩 샘플링은 무작위로 원본 데이터에서 샘플을 선택하고, 선택한 샘플을 다시 원본 데이터셋에 반환하는 방식으로 이루어진다. 이로써 각 모델이 서로 다른 훈련 데이터를 가지게 된다
- 병렬 처리: 배깅은 병럴 처리에 적합하므로, 다수의 모델을 동시에 훈련시키는 데 효과적이다. 모델은 서로 독립적으로 훈련되기 때문에 병렬 실행 가능
- 모델 다양성: 각 모델은 부트스트랩 샘플에 따라 다르게 훈련되므로 다양한 관점에서 데이터를 학습한다. 모델 간의 다양성이 높아지며 모델 예측 성능 향상한다.
- 결합 방법: 각 모델로 얻은 예측 결과를 평균하거나 다수결 원칙에 따라 최종 예측을 결정한다. 분류 문제에선느 하드 투표 방식을 주로 사용하며, 회귀 문제에서는 평균 예측 값을 사용할 수 있다.
4. Random Forest
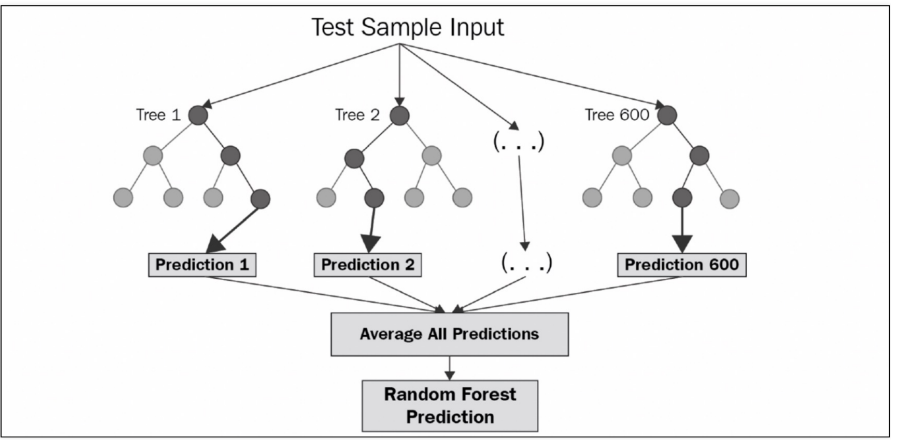

랜덤 포레스트 :결정 트리(Decision Tree)를 기반으로 하는 앙상블(Ensemble Learning)기법 중 하나이다. 다수의 결정 트리를 생성하고 이들을 조합하여 안정적인 모델을 만든다. 분류(Classification)와 회귀(Regression)문제에 적용
- 설명
- 부트스트랩 샘플링(Bootstrap Sampling): 랜덤 포레스트는 원본 데이터셋으로부터 복원 샘플(부트스트랩 샘플)을 생성 각 부트스트랩 샘플은 원본 데이터셋에서 무작위로 선택한 샘플로 구성 이로써 각 결정 트리 모델이 다른 훈련 데이터를 가지게 된다.
- 랜덤 특성 선택(Random Feature Selection): 각 결정 트리를 훈련할 때, 특성(변수)을 무작위로 선택하거나 일부 특성을 제외하여 트리의 다양성을 높인다. 이는 과적합을 줄이고 모델의 안정성을 향상한다.
- 다수결 투표(Majority Voting): 랜덤 포레스트는 생성된 다수의 결정 트리로부터 예측을 수집하고, 다수결 원칙에 따라 최종 예측을 만든다. 분류 문제에서는 각 트리의 예측 클래스 레이블 중 가장 많이 나온 클래스가 최종 예측 클래스가 된다.
- 앙상블의 안정성과 일반화 능력 향상: 랜덤 포레스트는 다수의 결정 트리를 결합하여 모델의 예측 성능을 높이고 과적합을 방지한다. 각 트리는 서로 다른 훈련 데이터와 특성을 가지며, 이로 인해 모델의 다양성과 안정성이 증가.
5. HAR(Human Activity Recognition)
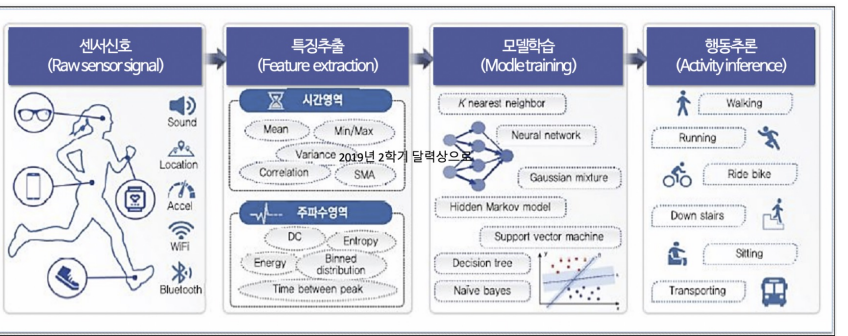
HAR: 머신 러닝 패턴 인식 기술을 사용하여 사람의 활동, 동작을 자동으로 감지하고 분류하는 기술 주로 센서 데이터와 머신 러닝 알고리즘을 결합하여 사용된다.
