InceptionNet-v1
2013년도 ZFNet : 11x11 -> 7x7 visualization 해서 제일 좋을 것이라고 진단을 하고 나서 씀
Hebb's Rule : 가장 도움이 되는 것에 weight가 커질 것. 어떤 weight가 가장 클 것 -> 3x3 convoultion인지 5x5 convolution인지 학습을 통해서 알 수 있을 것
즉, 학습을 통해 가장 중요한 것의 weight가 커진다는 것이 기본 생각
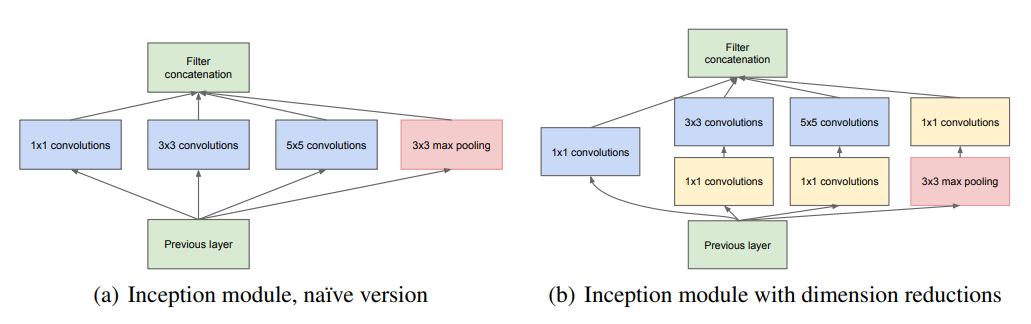
NIN에서 차원을 맞추지 않으면 갯수가 안 맞아서 더하기 어려운 것을 확인했기 때문에 차원을 맞추는 테크닉이 필요함.
concatenate를 통해 여러 convolution을 계산함. pooling은 당연히 다를 수 밖에 없음. 1x1 convolution 은 차원만 줄이는 역할을 하는데, 1x1으로 차원을 먼저 줄임. pooling을 한 뒤 1x1 convolution을 하게 되면 차원이 축소 된 다음에 학습을 하는 위험성을 줄임.
VGG-Net
1) 의의
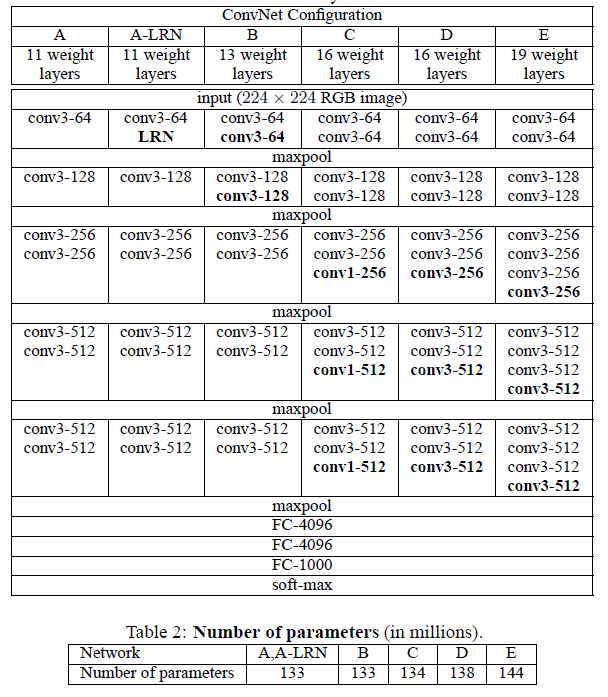
1. A vs A-LRN : LRN이 성능이 있는지 없는지를 확인하고자 LRN을 추가로 넣어서 성능을 비교함
-> 실험 결과 LRN은 전혀 결과 향상에 도움이 되지 않음
2. A vs B : layer를 2개 더 추가하여 성능이 좋은지 비교
-> B가 좋음
3. B vs C : 차원을 바꾸지 않고 1x1 Convolution을 추가
-> activation이 많으면 성능이 좋음(Universal Aproximation Theorem)
4. C vs D : 3x3 Convolution 추가하여 비교
-> layer가 많으면 많을 수록 좋음
향후 1번째 layer를 제외하고 모두 3x3으로 쓰는 계기가 됨
LeRU의 등장으로 인하여 layer가 여러개여도(deep해도) 학습이 되기 때문에, parameter 전체 수가 줄어들고 activation 여러개로 성능이 더 좋아짐
-> layer 1개 더 붙이는게 이득이라는 것을 확인함
보통 GPU 병렬처리 할 때 2의 배수로 병렬처리 하는 것이 제일 빠르고 resource 낭비가 없기 때문에 보통은 2의 배수로 filter 배수로 잡음
- 3x3이 항상 좋은가?
layer를 여러개 사용함에 따라 activation을 여러번 사용하게 됨. 또한 7x7을 한 번 사용하는 것보다 3x3을 2개 사용하는 것이 parameter 수를 더 많이 감소시켜 더 큰 receptive field를 대체할 수 있음.
하지만 3x3은 연산을 많이 해야 한다는 단점이 존재함. operation 횟수가 많아지기 때문에 memory가 많이 필요함. 따라서 3x3이 항상 좋은 것이 아님
memory 낭비를 줄이기 위하여 첫번째 layer에서는 5x5나 7x7을 보통 사용함
cf. Rethinking the Inception Architecture for Computer Vision 논문에서 Factorizing convolution이라고 명명하여 차후 InceptionNet에서 사용함
ResNet
인간을 뛰어넘은 첫 모델
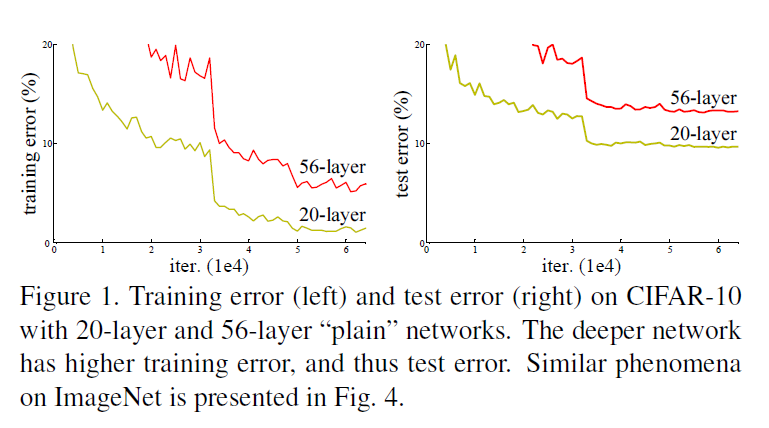
당시 InceptionNetv1에서 왜 layer를 20개 밖에 안 쌓았는 가에 대해, 실험적으로 밝혀냄. layer가 깊어질수록 underfitting 문제가 발생하였기 때문에 성능이 안 좋았던 것임
2014년도 당시 더 깊은 layer는 학습하기 어려웠음. 따라서 unreferenced function대신 Residual function을 사용함 (shortcut connection)
깊이에 대한 표현은 엄청나게 중요함
해결책 : LeRU에 의해 학습이 안 되는 gradient vanishing 문제를 해결함
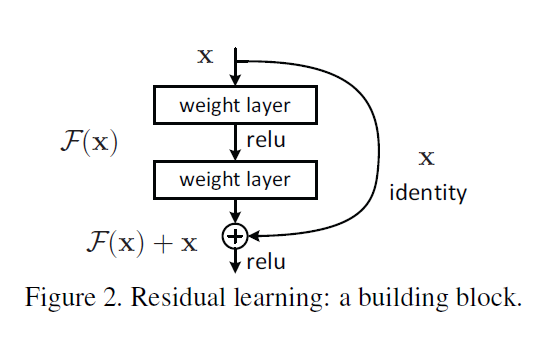
바로 몇 칸 뒤를 뛰어 넘는 shortcut을 통해 자신의 값을 계속 더하게 하여 목표 자체가 바뀌지 않도록 함. LSTM의 input gate와 InceptionNet에서 영향을 받은 구조.
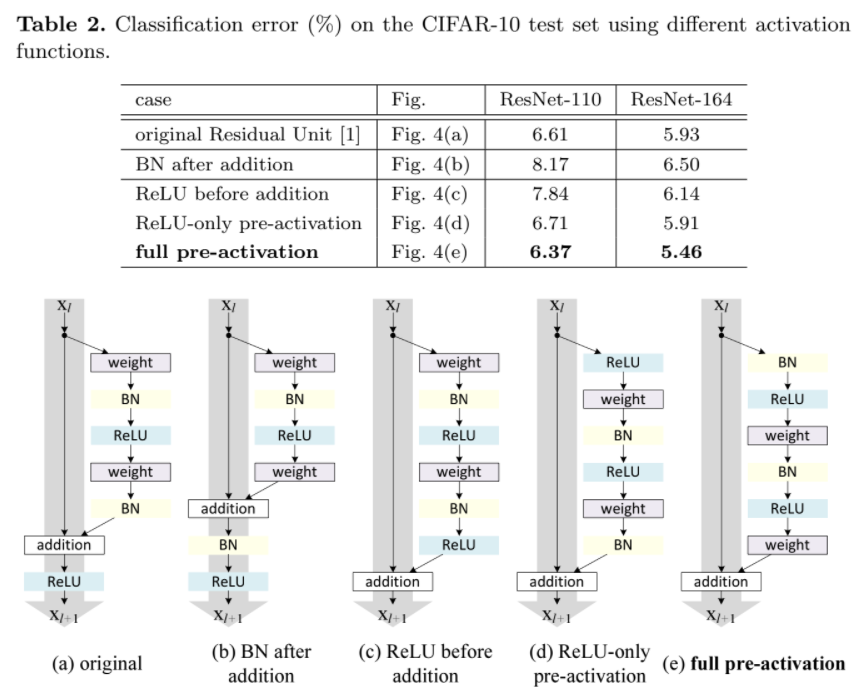
향후 모델인 Identity Mappings in Deep Residual Networks에서 어떤 module이 성능이 좋은지를 밝혀냄. (e)full pre-activation이 성능이 제일 좋게 나왔지만, ResNet 구조가 아니면 shortcut connection의 성능이 떨어질 때도 있음
Batch Normalization(BN)을 사용함. BN은 underfitting을 막아주기 때문에 Drop out을 안 사용하는 계기가 됨. Activation 들어가기 전에 씀으로써 값이 벗어나지 않게 해주는 효과가 있음
BN 사용 플로우
- 2012 AlexNet LRN
- 2013 ZFNet LCN : 왜 LCN을 사용했는가에 대한 언급이 없었음
- 2014 InceptionNetv1 LRN / VGGNet LRN이 활용성이 없는 것을 밝히고 BN을 사용
- 2015 InceptionNetv2, v3 BN / ResNet BN : Dropout 필요 없음을 밝힘
